
在多模态机器学习领域,如何让模型仅通过少量标注样本就快速适配新任务,是长期以来的核心挑战。DeepMind 于 2022 年提出的 Flamingo 系列视觉语言模型(VLM),通过创新性的架构设计和训练策略,成功实现了这一目标。
原文链接:https://arxiv.org/pdf/2204.14198
代码链接:https://github.com/mlfoundations/open_flamingo(供参考,非原文代码)
沐小含将持续分享前沿算法论文,欢迎关注...
一、论文核心概览
1.1 研究背景与痛点
传统视觉语言模型存在两大关键局限:
- 微调依赖大量标注数据:主流范式需在特定任务上微调数千甚至数万标注样本,且需精细调参,资源消耗巨大;
- 任务适配能力有限:对比学习类模型仅能提供文本 - 图像相似度评分,无法处理开放式任务;而生成类模型在低数据场景下性能不佳。
1.2 核心贡献
Flamingo 的三大核心贡献彻底改变了多模态少样本学习的格局:
- 提出通用视觉语言模型家族:支持图像 / 视频与文本的任意交织输入,能通过少量示例快速适配分类、字幕生成、视觉问答等多种任务;
- 创新架构设计:实现预训练视觉模型与语言模型的高效桥接,保留原有模型知识的同时,新增模块仅需轻量训练;
- 突破性能边界:在 16 个多模态基准测试中,6 个任务超越全量微调的 SOTA 模型,9 个任务刷新少样本学习记录,仅需 32 个任务相关样本即可实现匹敌数万样本微调的效果。
1.3 模型定位与应用场景
Flamingo 本质是视觉条件下的自回归文本生成模型,核心优势在于 "零微调适配"。其应用场景覆盖:
- 开放式任务:视觉问答(VQA)、图像 / 视频字幕生成、多图像视觉对话;
- 封闭式任务:多选视觉问答、仇恨 meme 检测、动作识别等分类任务;
- 低资源场景:缺乏大规模标注数据的小众领域视觉理解任务。
二、核心架构深度解析
Flamingo 的架构设计围绕 "高效复用预训练模型能力" 展开,核心由三大模块构成:视觉编码器、Perceiver Resampler、带门控交叉注意力的语言模型,整体架构如图 3 所示。
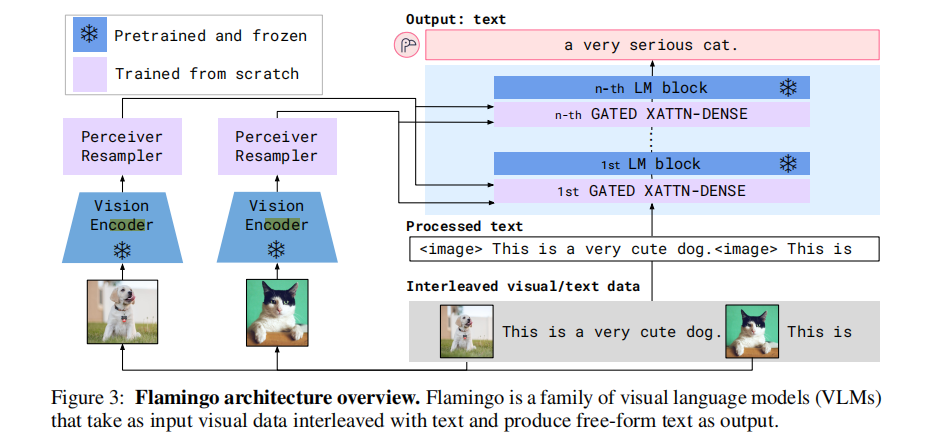
图 3:Flamingo 架构示意图。模型接收交织的视觉数据与文本作为输入,输出自由形式的文本结果。
2.1 视觉处理流水线:从像素到视觉令牌
2.1.1 视觉编码器(Vision Encoder)
- 基础模型:采用预训练并冻结的 Normalizer-Free ResNet(NFNet-F6),通过对比学习在图像 - 文本对上预训练;
- 特征提取:对图像输出 2D 空间特征网格并展平为 1D 序列;对视频按 1FPS 采样帧,独立编码后添加时序嵌入,最终形成 3D 时空特征网格并展平;
- 关键设计:冻结预训练权重以保留视觉感知能力,避免重新训练的巨大计算开销。
2.1.2 Perceiver Resampler:视觉特征降维与统一
由于视觉编码器输出的特征数量不固定(随图像分辨率、视频帧数变化),无法直接输入语言模型,Perceiver Resampler 应运而生:
- 核心功能:将可变长度的视觉特征映射为固定数量(64 个)的视觉令牌;
- 实现机制:借鉴 Perceiver 架构,学习一组预定义的潜在查询,通过 Transformer 交叉注意力机制与视觉特征交互;
- 优势:相比简单 Transformer 或 MLP,在降低计算复杂度的同时保留关键视觉信息,实验证明该模块能显著提升跨模态对齐效果。
其处理流程如图 5 所示,通过时序嵌入添加和特征展平,将不同长度的视觉输入统一为固定维度的令牌序列。
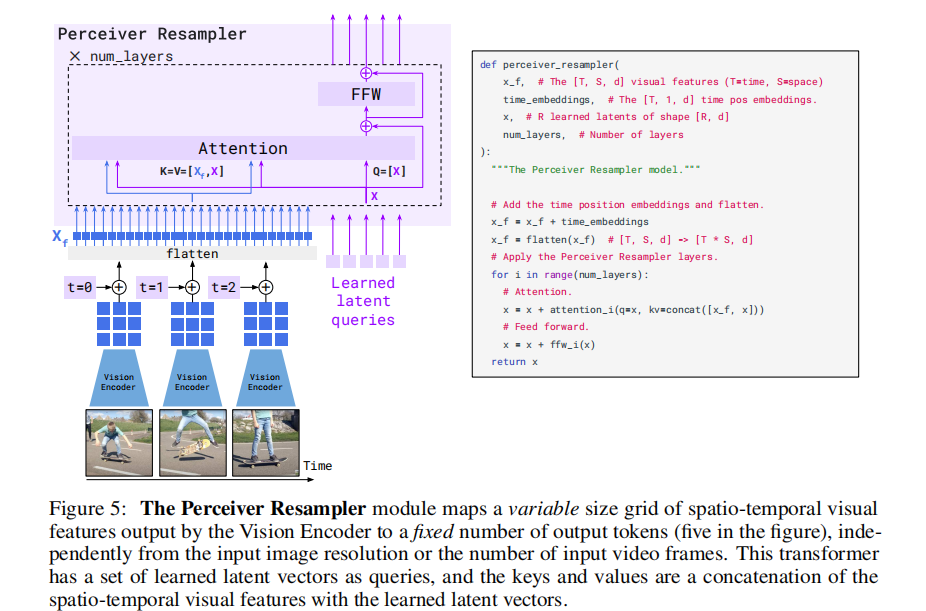
图 5:Perceiver Resampler 模块将视觉编码器输出的时空特征映射为固定数量的输出令牌,不受输入分辨率或帧数影响。
2.2 语言模型适配:门控交叉注意力机制
Flamingo 选用预训练的 Chinchilla 语言模型作为基础,通过新增模块实现视觉信息的融合,核心是 GATED XATTN-DENSE 层:
2.2.1 模块设计原理
- 插入位置:在冻结的语言模型层之间插入新的可训练层;
- 双门控结构:包含门控交叉注意力(Gated Cross Attention)和门控前馈网络(Gated Feed Forward),如图 4 所示;
- 初始化策略:使用 tanh 门控机制,初始权重设为 0,确保训练初期模型输出与原始语言模型一致,提升训练稳定性。
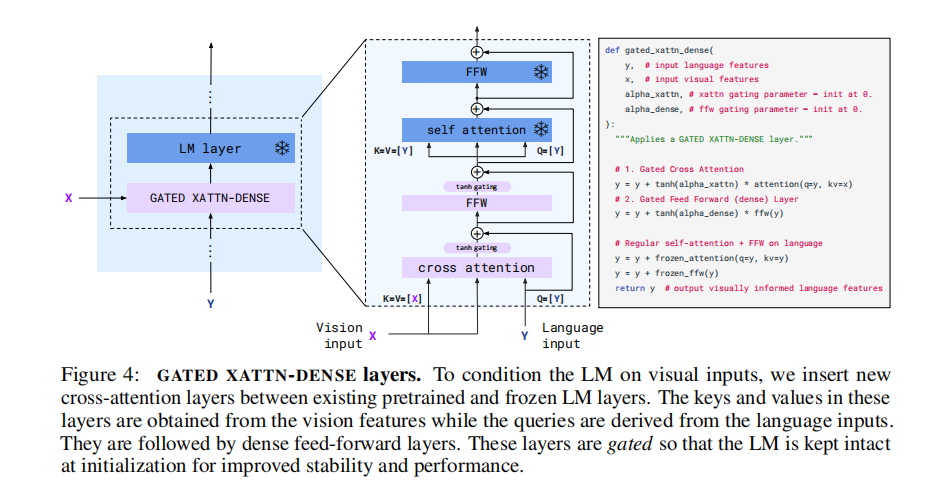
图 4:GATED XATTN-DENSE 层结构。通过交叉注意力将视觉特征注入语言模型,门控机制保证训练稳定性。
2.2.2 关键优势
- 视觉 - 语言交互:交叉注意力的键和值来自视觉令牌,查询来自语言输入,实现精准的跨模态交互;
- 避免灾难性遗忘:冻结原始语言模型权重,仅训练新增层,防止模型忘记预训练的语言能力;
- 效率与表达力平衡:通过控制插入频率(如每 4 层或 7 层插入一个),在计算开销和性能间取得最优 trade-off。
2.3 多视觉输入支持:图像因果掩码机制
为处理任意数量的交织图像 / 视频输入,Flamingo 设计了图像因果掩码策略:
- 核心规则:每个文本令牌仅能关注其之前最近出现的视觉输入,而非所有历史视觉输入;
- 实现方式:通过掩码交叉注意力矩阵,限制文本令牌的视觉注意力范围;
- 优势:即使训练时最多处理 5 个图像,推理时也能无缝扩展到 32 个图像 / 视频样本,完美适配少样本学习的多示例输入场景。
这种机制既保证了模型对可变数量视觉输入的兼容性,又通过语言模型的自注意力间接保留了所有历史视觉信息的依赖关系,如图 7 所示。

图 7:交织视觉数据与文本的处理流程。通过掩码机制实现文本令牌与最近视觉输入的精准对齐。
2.4 模型规模变体
Flamingo 提供三个不同参数规模的模型,核心差异在于基础语言模型大小和 GATED XATTN-DENSE 层的插入频率:
| 模型版本 | 基础 LM 参数 | 视觉编码器 | 可训练参数 | 总参数 | 插入频率 |
|---|---|---|---|---|---|
| Flamingo-3B | 1.4B(Chinchilla) | 冻结 NFNet-F6 | 1.8B | 3.2B | 每层插入 |
| Flamingo-9B | 7B(Chinchilla) | 冻结 NFNet-F6 | 2.2B | 9.3B | 每 4 层插入 |
| Flamingo-80B | 70B(Chinchilla) | 冻结 NFNet-F6 | 10B | 80B | 每 7 层插入 |
三、训练方法与数据集
Flamingo 的少样本能力源于精心设计的训练数据和优化策略,核心是 "无标注网页数据 + 多目标训练"。
3.1 训练数据集组合
模型训练采用三种类型的网页爬取数据,无需任何机器学习标注数据:
3.1.1 M3W(MultiModal MassiveWeb)
- 数据规模:4300 万个网页,包含 1.85 亿张图像和 182GB 文本;
- 数据格式:提取网页中交织的文本和图像,根据 DOM 结构确定图像位置,在文本中插入
<image>标签和<EOC>(end of chunk)特殊令牌; - 采样策略:每个文档随机采样 256 个令牌序列,最多保留前 5 个图像;
- 关键作用:提供自然的跨模态交织数据,是少样本学习能力的核心来源。
3.1.2 图像 - 文本对数据集
- ALIGN:18 亿对图像 - 文本,基于 alt-text 构建,规模大但噪声较高;
- LTIP(Long Text & Image Pairs):3.12 亿对高质量图像 - 文本,文本描述更长(平均 20.5 个令牌 vs ALIGN 的 12.4 个);
- 预处理:统一添加
<image>标签和<EOC>令牌,与 M3W 格式对齐。
3.1.3 视频 - 文本对数据集(VTP)
- 数据规模:2700 万个短视频 - 文本对,视频平均时长 22 秒;
- 预处理:按 1FPS 采样帧,添加时序嵌入,文本描述与视频内容对齐。
三种数据集的组合如图 9 所示,覆盖了单图像、多图像交织、视频等多种模态输入场景。

图 9:训练数据集格式示意图。N 为单个样本的视觉输入数量,T 为视频帧数(图像 T=1)。
3.2 训练优化策略
3.2.1 多目标损失函数
最小化各数据集的文本负对数似然加权和:
其中为第 m 个数据集,
为权重(M3W:1.0, ALIGN:0.2, LTIP:0.2, VTP:0.03)。
3.2.2 关键训练技巧
- 梯度累积:跨所有数据集累积梯度,优于轮询(round-robin)方式;
- 数据增强:对 M3W 采用图像位置随机化(50% 概率关联前一个或后一个图像),提升泛化能力;
- 分辨率调整:训练时图像分辨率提升至 320×320(高于预训练的 288×288),提升视觉细节捕捉;
- 优化器:AdamW 优化器,权重衰减 0.1(Perceiver Resampler 除外),学习率线性预热后恒定。
3.2.3 计算资源
- 硬件:1536 个 TPUv4 芯片;
- 训练时长:最大模型(80B)训练 15 天;
- 混合精度:参数和优化器状态用 float32 存储,激活和梯度用 bfloat16 计算。
3.3 少样本适配机制
Flamingo 通过 "多模态提示工程" 实现少样本学习,无需任何任务特定微调:
- 提示构建:将任务示例(图像 / 视频 + 文本)与查询输入交织成多模态序列,如图 8 所示;
- 开放式任务:使用束搜索(beam size=3)生成文本,直到
<EOC>令牌; - 封闭式任务:计算所有候选答案的对数似然,按分数排序;
- 零样本适配:使用两个无图像的文本示例构建提示,避免 prompt engineering 的主观性。

图 8:少样本提示构建流程。将支持示例与查询输入交织,通过特定格式引导模型生成目标输出。
四、实验结果与分析
Flamingo 在 16 个多模态基准测试中进行了全面评估,涵盖图像 / 视频分类、字幕生成、视觉问答、视觉对话等任务,分为开发集(DEV)和无偏评估集两类。
4.1 少样本学习性能
4.1.1 核心结果概览
如图 2 所示,Flamingo 的性能随模型规模和样本数量增长而显著提升:
- 左图:80B 模型在 6 个任务上超越全量微调 SOTA,9 个任务刷新少样本 SOTA;
- 右图:模型规模越大,对样本数量的利用效率越高,即使训练时最多处理 5 个图像,推理时 32 个样本仍能持续提升性能。
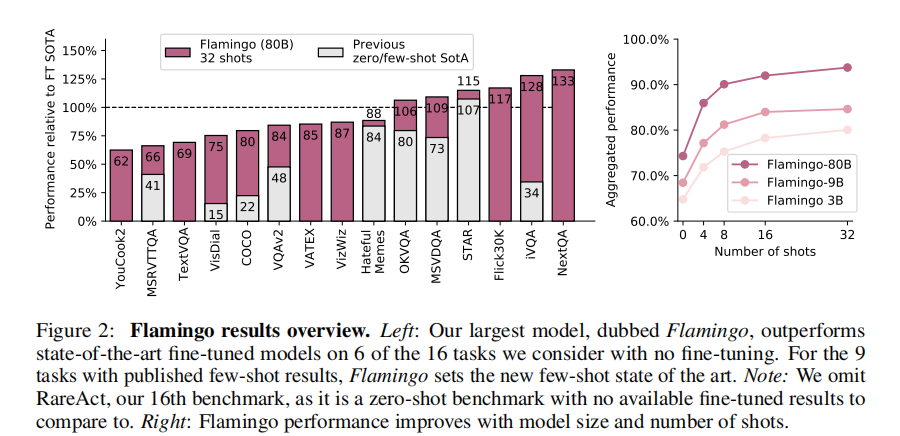
图 2:左图为 80B 模型与 SOTA 的对比,右图为不同模型规模和样本数量的性能变化。
4.1.2 详细对比数据
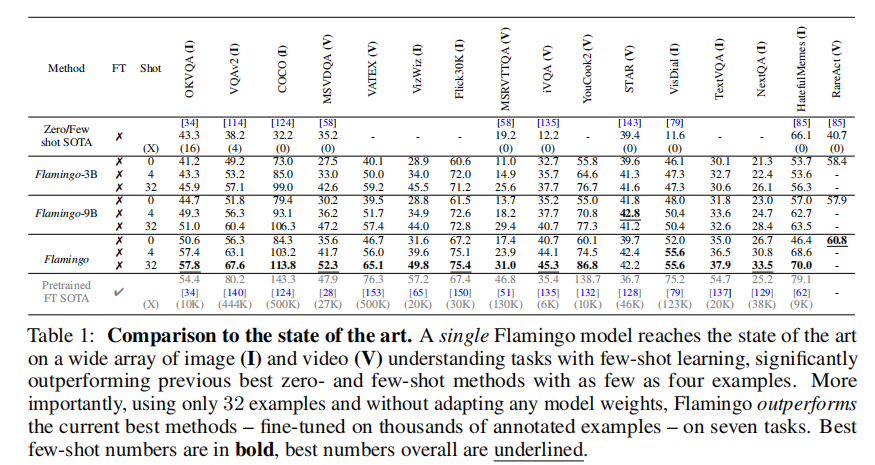
表 1 展示了 Flamingo 各版本在 16 个任务上的少样本性能,关键发现:
- 80B 模型(32-shot)在 OKVQA、VQAv2、COCO 等 6 个任务上超越需数万样本微调的 SOTA;
- 即使是 3B 小型模型,4-shot 性能也远超传统零 / 少样本方法;
- 视频任务(如 MSRVTTQA、VATEX)的性能提升尤为显著,证明时序特征处理的有效性。
4.2 微调性能
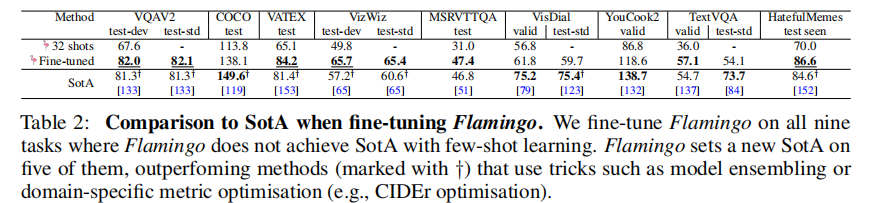
虽然 Flamingo 的核心优势是少样本学习,但微调后仍能进一步提升性能:
- 微调策略:解冻视觉编码器,提升输入分辨率至 480×480,使用小学习率微调;
- 结果:在 VQAv2、VATEX、VizWiz 等 5 个任务上刷新 SOTA,例如 VQAv2 达到 82.0%(超过之前的 81.3%);
- 优势:无需任务特定优化(如 CIDEr 优化),仅通过对数似然损失即可实现。
4.3 消融实验分析
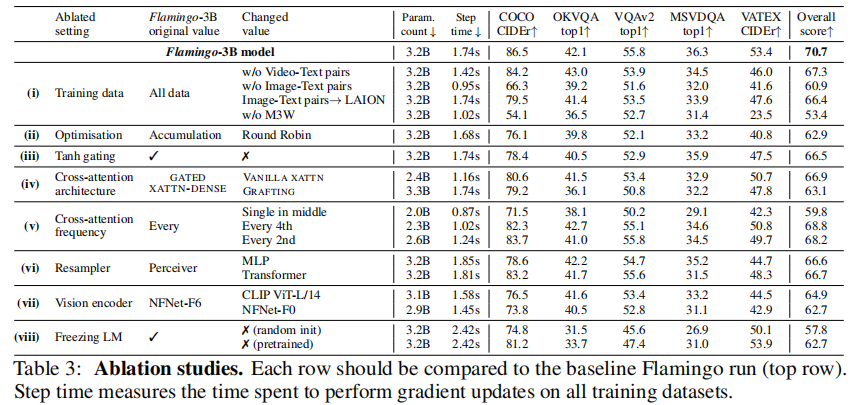
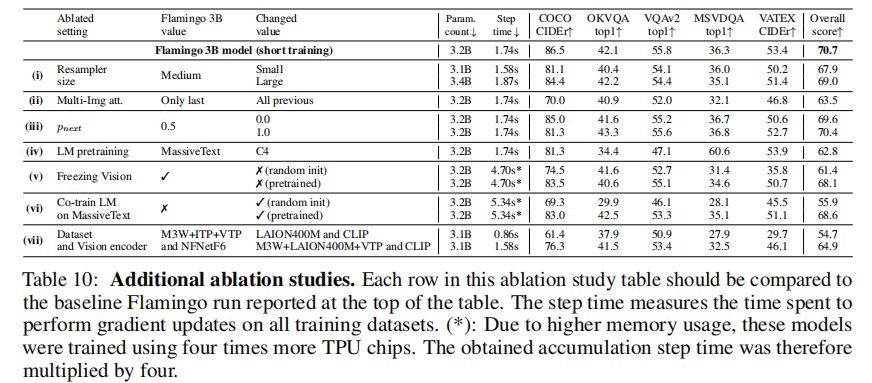
表 3 和表 10 的消融实验验证了各组件的必要性。
4.3.1 训练数据的重要性
- 移除 M3W 数据集:整体性能下降 17%,证明交织文本 - 图像数据对少样本能力的核心作用;
- 移除视频 - 文本对:视频任务性能显著下降,验证时序数据的价值;
- 替换图像 - 文本对为 LAION:性能轻微下降,说明 LTIP 的高质量文本描述更有效。
4.3.2 架构组件的必要性
- 无 tanh 门控:性能下降 4.2%,且训练不稳定;
- 替换 GATED XATTN-DENSE 为普通交叉注意力:性能下降 3.8%;
- 冻结语言模型:避免灾难性遗忘,若解冻微调性能下降 8.0%。
4.3.3 计算效率与性能 trade-off
- 每 4 层插入 GATED XATTN-DENSE:训练速度提升 66%,性能仅下降 1.9%;
- Perceiver Resampler:相比 MLP 和 Transformer,在相同参数下性能提升 4% 以上。
4.4 分类任务扩展
Flamingo 不仅擅长生成类任务,在分类任务上也表现出色:
- 采用 Retrieval-based In-Context Example Selection(RICES)方法,从大量支持样本中选择相似示例构建提示;
- ImageNet 分类:80B 模型(16-shot+RICES + 集成)达到 77.3%,接近对比学习模型的零样本性能;
- 优势:无需修改模型架构,仅通过提示工程即可适配分类任务。
五、局限性与社会影响
5.1 技术局限性
- 分类性能落后:在纯分类任务上不如专门的对比学习模型(如 CLIP),因目标函数未直接优化分类任务;
- 继承语言模型缺陷:存在幻觉现象、长序列泛化不佳、训练样本效率低等问题;
- 提示敏感性:少样本性能受示例顺序、格式影响较大,超过 32 个样本后性能趋于平稳。
5.2 社会影响与风险
- 潜在益处:降低低资源任务的技术门槛,非专业用户可通过少量示例构建视觉理解系统;
- 潜在风险:继承语言模型的偏见(性别、种族)、可能生成有害内容、视觉输入可能加剧偏见传播;
- 缓解策略:通过提示工程减轻偏见,开发专门的过滤模块,限制恶意应用场景。
六、总结与未来展望
Flamingo 通过 "冻结预训练模型 + 轻量跨模态模块" 的创新思路,为视觉语言模型的少样本学习提供了全新范式。其核心启示在于:
- 跨模态数据的质量比数量更重要:M3W 的交织文本 - 图像数据是少样本能力的关键,证明自然场景的多模态数据优于人工标注数据;
- 架构设计需平衡兼容性与效率:Perceiver Resampler 和 GATED XATTN-DENSE 层实现了视觉与语言模型的高效桥接,避免了重新训练的巨大开销;
- 提示工程是少样本适配的核心:多模态提示机制使模型能快速迁移到新任务,无需任务特定微调。
未来研究方向包括:
- 提升分类任务性能,实现生成与分类任务的统一;
- 缓解提示敏感性,提高少样本学习的稳定性;
- 扩展更多模态(如音频),构建更通用的多模态模型;
- 强化伦理安全机制,减少偏见和有害内容生成。
Flamingo 的出现,标志着视觉语言模型从 "单任务微调" 向 "通用少样本适配" 的跨越,为通用人工智能的发展奠定了重要基础。