如何批量下载特定站点的DAHITI水位数据产品?
- 具体流程:
1)从 DAHITI API 拿到全部站点(dahiti_id + lon + lat)
2)读取所需 CSV 站点(lon/lat)
3)用 距离匹配(Haversine) 把所需点和 DAHITI 站点关联
4)输出匹配表(所需点 ID → dahiti_id → 距离 → 经纬度)
5)批量下载匹配到的 DAHITI 水位数据
- 代码:
bash
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import os
import sys
import json
import requests
import pandas as pd
from haversine import haversine
# ====================== 配置设置 ======================
API_KEY = 'your API_KEY'
INPUT_CSV_PATH = r'D:\VS_List.csv'
VS_FID_COLUMN = 'VS_FID'
LON_COLUMN = 'lon'
LAT_COLUMN = 'lat'
MAX_ALLOWED_DISTANCE_KM = 5
OUTPUT_FORMAT = 'csv'
OUTPUT_DIR = r'D:\dahiti_river_data'
# ======================================================
os.makedirs(OUTPUT_DIR, exist_ok=True)
# ------------------- 1. 获取DAHITI全部站点 -------------------
print("正在获取DAHITI全站元数据...")
url_list = "https://dahiti.dgfi.tum.de/api/v2/list-targets/"
payload_list = {"api_key": API_KEY}
response = requests.post(url_list, data=payload_list)
if response.status_code != 200:
print("站点列表请求失败")
sys.exit(1)
targets = json.loads(response.text)["data"]
print(f"DAHITI总站点数:{len(targets)}")
dahiti_stations = []
for target in targets:
dahiti_stations.append({
"dahiti_id": int(target["dahiti_id"]),
"lon": float(target["longitude"]),
"lat": float(target["latitude"])
})
dahiti_df = pd.DataFrame(dahiti_stations)
# ------------------- 2. 读取输入站点(含 VS_FID) -------------------
input_df = pd.read_csv(INPUT_CSV_PATH)
input_df = input_df.rename(columns={
LON_COLUMN: "lon",
LAT_COLUMN: "lat",
VS_FID_COLUMN: "vs_fid"
})
# 【关键】强制转换为正确类型,杜绝浮点型
input_df["vs_fid"] = input_df["vs_fid"].astype(int)
input_df["lon"] = input_df["lon"].astype(float)
input_df["lat"] = input_df["lat"].astype(float)
input_df = input_df[["vs_fid", "lon", "lat"]].dropna()
# ------------------- 3. 空间匹配(最近站点+5km筛选) -------------------
print("正在进行空间匹配与距离筛选...")
match_records = []
for _, input_row in input_df.iterrows():
vs_fid = int(input_row["vs_fid"])
input_lon = input_row["lon"]
input_lat = input_row["lat"]
min_distance = 99999.0
best_dahiti_id = None
for _, dahiti_row in dahiti_df.iterrows():
dahiti_lon = dahiti_row["lon"]
dahiti_lat = dahiti_row["lat"]
distance = haversine((input_lat, input_lon), (dahiti_lat, dahiti_lon))
if distance < min_distance:
min_distance = distance
best_dahiti_id = int(dahiti_row["dahiti_id"])
if min_distance <= MAX_ALLOWED_DISTANCE_KM:
match_records.append({
"vs_fid": vs_fid,
"input_lon": input_lon,
"input_lat": input_lat,
"dahiti_id": best_dahiti_id,
"distance_km": round(min_distance, 3)
})
match_df = pd.DataFrame(match_records)
match_df.to_csv("dahiti_matched_result.csv", index=False, encoding="utf-8")
print(f"匹配完成,结果已保存")
print(f"符合{MAX_ALLOWED_DISTANCE_KM}km条件的站点数:{len(match_df)}")
# ------------------- 4. 批量下载水位数据(按 VS_FID 命名) -------------------
download_url = "https://dahiti.dgfi.tum.de/api/v2/download-water-level/"
for _, row in match_df.iterrows():
vs_fid = int(row["vs_fid"])
dahiti_id = int(row["dahiti_id"])
file_path = os.path.join(OUTPUT_DIR, f"{vs_fid}.csv")
print(f"正在下载 VS_FID={vs_fid} | DAHITI_ID={dahiti_id}")
download_payload = {
"api_key": API_KEY,
"dahiti_id": dahiti_id,
"format": "csv"
}
response = requests.post(download_url, json=download_payload)
if response.status_code == 200:
# 修复分号分隔问题,Excel正常打开
csv_content = response.text.replace(';', ',')
with open(file_path, "w", encoding="utf-8") as f:
f.write(csv_content)
print(f"下载成功:VS_FID={vs_fid}")
else:
print(f"下载失败:VS_FID={vs_fid} 状态码:{response.status_code}")
print("\n===== 全部任务完成 =====")效果显示:成功下载所需数据
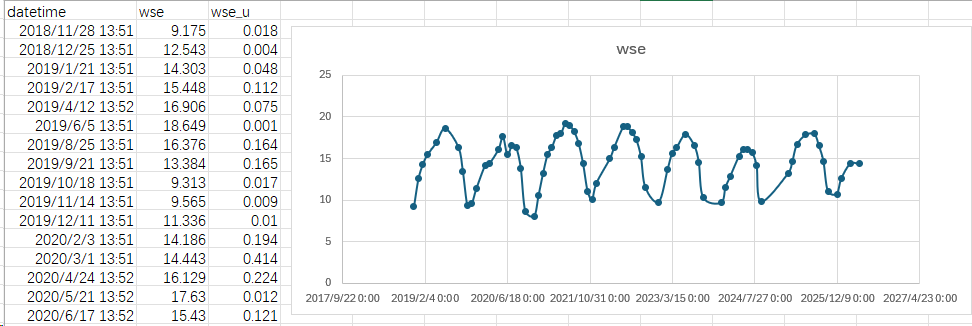
打开数据,查看水位时间序列:
如果想要获取自己的虚拟站点与dahiti中站点位置信息以及距离,可以用下面的代码来实现:
bash
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import os
import json
import requests
import pandas as pd
from haversine import haversine
# ====================== 配置设置 ======================
API_KEY = 'API'
INPUT_CSV_PATH = r'D:\VS_List.csv'
VS_FID_COLUMN = 'VS_FID'
LON_COLUMN = 'lon'
LAT_COLUMN = 'lat'
MAX_ALLOWED_DISTANCE_KM = 5
# ======================================================
# ------------------- 1. 获取 DAHITI 全站信息 -------------------
print("正在获取 DAHITI 全站元数据...")
url_list = "https://dahiti.dgfi.tum.de/api/v2/list-targets/"
payload_list = {"api_key": API_KEY}
response = requests.post(url_list, data=payload_list)
if response.status_code != 200:
print("获取站点列表失败")
exit(1)
targets = json.loads(response.text)["data"]
print(f"DAHITI 总站点数:{len(targets)}")
dahiti_stations = []
for target in targets:
dahiti_stations.append({
"dahiti_id": int(target["dahiti_id"]),
"dahiti_lon": float(target["longitude"]),
"dahiti_lat": float(target["latitude"])
})
dahiti_df = pd.DataFrame(dahiti_stations)
# ------------------- 2. 读取你的 VS_FID + 经纬度 -------------------
input_df = pd.read_csv(INPUT_CSV_PATH)
input_df = input_df.rename(columns={
LON_COLUMN: "input_lon",
LAT_COLUMN: "input_lat",
VS_FID_COLUMN: "vs_fid"
})
# 强制类型安全
input_df["vs_fid"] = input_df["vs_fid"].astype(int)
input_df["input_lon"] = input_df["input_lon"].astype(float)
input_df["input_lat"] = input_df["input_lat"].astype(float)
input_df = input_df[["vs_fid", "input_lon", "input_lat"]].dropna()
# ------------------- 3. 空间匹配(输出 DAHITI 真实经纬度) -------------------
print("正在匹配最近站点...")
match_result = []
for _, input_row in input_df.iterrows():
vs_fid = int(input_row["vs_fid"])
input_lon = input_row["input_lon"]
input_lat = input_row["input_lat"]
min_dist = 99999.0
best_id = None
best_lon = None
best_lat = None
for _, dahiti_row in dahiti_df.iterrows():
d_id = dahiti_row["dahiti_id"]
d_lon = dahiti_row["dahiti_lon"]
d_lat = dahiti_row["dahiti_lat"]
dist = haversine((input_lat, input_lon), (d_lat, d_lon))
if dist < min_dist:
min_dist = dist
best_id = d_id
best_lon = d_lon
best_lat = d_lat
if min_dist <= MAX_ALLOWED_DISTANCE_KM:
match_result.append([
vs_fid,
input_lon,
input_lat,
best_id,
best_lon,
best_lat,
round(min_dist, 3)
]) # 这里修复了缺失的括号
# ------------------- 4. 输出完整匹配表 -------------------
output_df = pd.DataFrame(match_result, columns=[
"VS_FID",
"input_lon",
"input_lat",
"dahiti_id",
"dahiti_lon",
"dahiti_lat",
"distance_km"
])
output_df.to_csv("dahiti_matched_result.csv", index=False, encoding="utf-8")
print("=" * 60)
print("匹配完成!文件已保存为:dahiti_matched_result.csv")
print(f"有效匹配数量:{len(output_df)} 个")
print("文件包含字段:VS_FID, input_lon, input_lat, dahiti_id, dahiti_lon, dahiti_lat, distance_km")
print("=" * 60)效果展示:最后数据对应站点的坐标信息以及计算的距离。注意该距离是地表最短球面直线距离,利用Haversine 公式 计算得到的是地球表面两点间的大圆距离。
