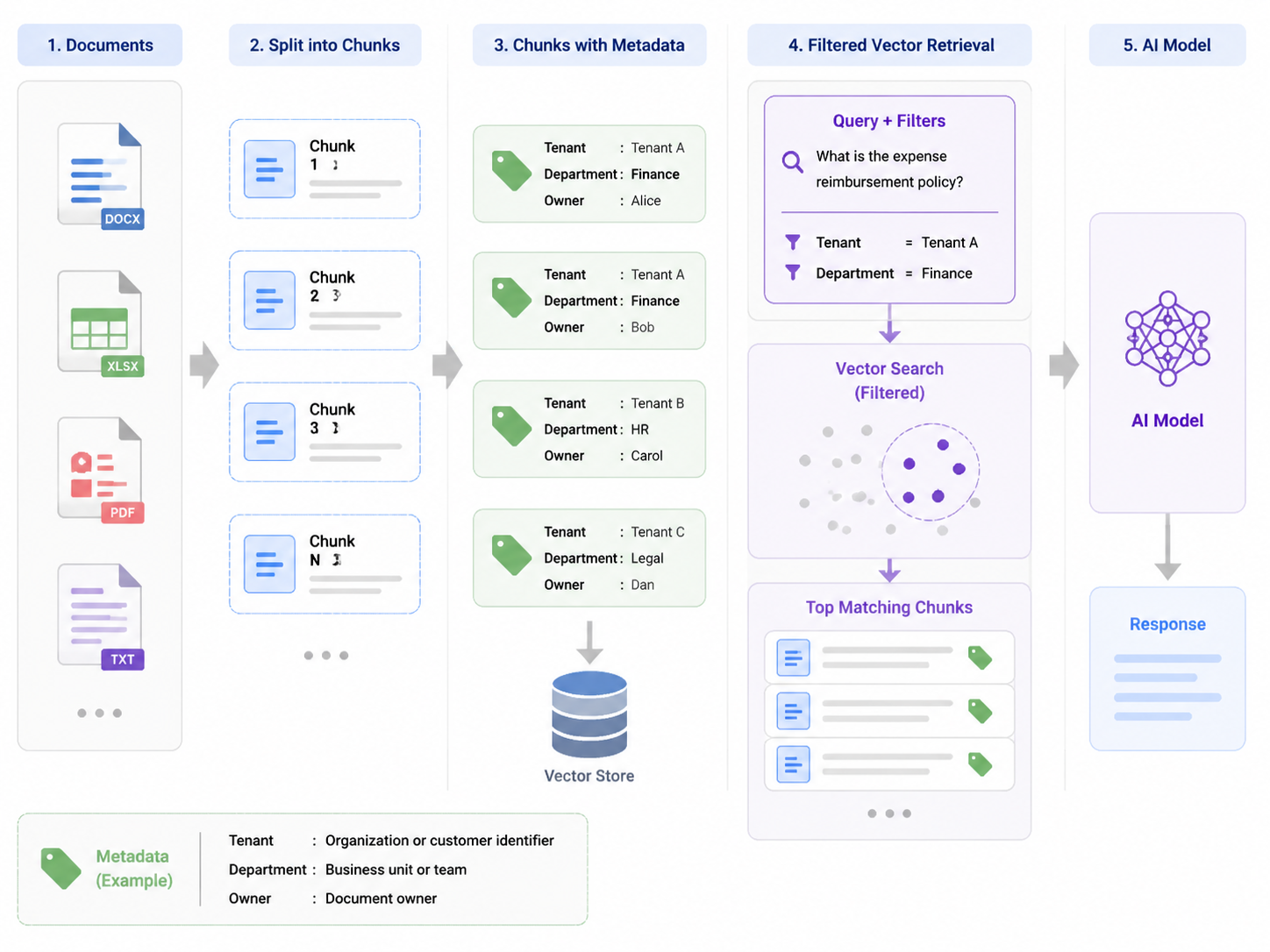
很多团队第一次做企业知识库问答时,流程都差不多:文档入库、切分、向量化、接一个 ChatClient,再用 RAG 把检索结果塞给大模型。Demo 很快能跑通,但一旦进入真实项目,最先暴露的问题往往不是"模型答得不聪明",而是"它不该看到的内容也被召回了"。
对 Java 后端开发者来说,这个问题很好理解:权限不能只写在页面上,也不能只写在提示词里。RAG 的权限边界应该尽量前置到检索阶段,而不是等文档片段已经进入上下文之后,再祈祷模型遵守"不要回答无权限内容"。
问题不在向量库,而在召回边界
假设一个公司知识库里有三类文档:
- HR 制度:所有员工可见
- 财务流程:财务部门可见
- 客户合同:销售和法务可见,且按客户归属隔离
如果只做语义检索,用户问"报销审批需要几级领导确认",向量库可能召回财务制度,也可能召回某个项目合同里的付款条款。它们在语义上都相关,但权限上完全不是一回事。
很多人会在 Prompt 里加一句:
XML
你只能根据用户有权限的资料回答问题。这句话有用,但它不是权限控制。因为模型看到的上下文已经包含了敏感片段,风险已经发生了。更合理的做法是:在向量检索时就用 metadata filter 把候选文档缩小到用户可访问范围内。
给每个 Chunk 带上权限元数据
RAG 工程里,文档切分后的每个 chunk 都应该携带元数据。LangChain4j 文档也明确提到,Metadata 可以用于记录文档来源、更新时间、owner 等信息,也可以在搜索时按元数据过滤。Spring AI 的 QuestionAnswerAdvisor 也支持通过 SearchRequest 或运行时 advisor 参数设置过滤表达式。
一个较实用的元数据设计可以从这几个字段开始:
| 字段 | 示例 | 用途 |
|---|---|---|
| tenant_id | t_1001 | 多租户隔离 |
| doc_id | policy_2026_001 | 溯源、更新、删除 |
| visibility | public / dept / private | 可见范围 |
| dept | finance | 部门权限 |
| owner_id | u_7788 | 个人归属 |
| source | wiki / crm / oss | 来源审计 |
不要把权限信息只存在业务数据库里,而 chunk 入库时丢掉。否则检索阶段就只剩"语义相关",没有"访问合法"。
Spring AI 中的最小实现思路
以下示例只展示关键链路:查询前根据当前登录用户拼出过滤表达式,再把它传给 RAG advisor。具体向量库、模型和依赖版本请以 Spring AI 官方文档为准。
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
java
@Service
public class KnowledgeQaService {
private final ChatClient chatClient;
public KnowledgeQaService(ChatModel chatModel, VectorStore vectorStore) {
this.chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.similarityThreshold(0.75)
.topK(6)
.build())
.build())
.build();
}
public String ask(CurrentUser user, String question) {
String filter = buildFilter(user);
return chatClient.prompt()
.user(question)
.advisors(advisor -> advisor.param(
QuestionAnswerAdvisor.FILTER_EXPRESSION,
filter
))
.call()
.content();
}
private String buildFilter(CurrentUser user) {
return """
tenant_id == '%s' &&
(visibility == 'public' ||
dept == '%s' ||
owner_id == '%s')
""".formatted(user.tenantId(), user.dept(), user.userId());
}
}这段代码的重点不是字符串拼接,而是权限判断的位置:它发生在向量检索阶段。也就是说,无权限 chunk 不应该进入 topK 候选集,更不应该进入大模型上下文。
真实项目里不要直接拼接用户输入构造 filter。上面的 tenantId、dept、userId 应该来自服务端认证上下文,而不是前端参数。更稳妥的做法是把权限表达式封装成后端方法,并对字段值做白名单校验。
入库时要把权限模型想清楚
很多 RAG 问题看起来发生在问答阶段,本质却是入库阶段设计不完整。
比如一个 PDF 里前半部分是公开说明,后半部分是内部报价。如果整份文档只带一个 visibility=public,切出来的所有 chunk 都会被公开检索。更细的做法是:在解析文档时识别章节、目录、页码或业务标签,把权限元数据下沉到 chunk 级别。
一个可落地的流程是:
权限边界和语义边界不一定一致。为了回答效果,我们希望 chunk 语义完整;为了安全,我们又希望 chunk 权限单一。当两者冲突时,优先保证权限单一,再通过标题、摘要、上级路径等元数据补充上下文。
不要把 topK 当成质量保证
很多团队会把 topK 从 4 调到 10,再调到 20,期待答案更准。但在多租户知识库里,topK 越大,不代表越安全,也不代表越准确。
更合理的调试顺序是:
- 先确认 filter 是否正确,把无权限数据排除掉。
- 再看召回片段是否来自正确文档和正确章节。
- 再调 similarityThreshold 和 topK。
- 最后才调整 Prompt,让模型更好地引用上下文回答。
Spring AI 的 ChatClientResponse 可以访问 ChatClient 执行上下文,官方文档也提到它可用于获取 advisor 执行中的附加数据,例如 RAG 流程里的相关文档。实际项目中建议把召回的 doc_id、source、score、filter 表达式和用户 ID 记录到日志或 trace 中。否则线上出现"答错了"时,只能猜是模型问题、检索问题还是权限问题。
一个容易忽略的坑:权限变更后的旧向量
企业系统里的权限经常变化:员工转岗、客户归属调整、文档从内部改为公开、合同归档。业务库里的权限变了,不代表向量库里的 metadata 自动变了。
因此知识库系统至少要有三类同步能力:
- 文档内容变更:重新解析、切分、向量化。
- 权限元数据变更:更新对应 chunk 的 metadata。
- 文档删除或撤回:从向量库删除对应 doc_id 的全部 chunk。
如果向量库不方便局部更新,也要通过 doc_id 和版本号实现重建。不要只做"新增文档入库",那只是 Demo 级能力;能处理更新、删除和权限变化,才接近真实系统。
RAG 的工程难点不是把文本塞进向量数据库,而是让检索结果同时满足"相关、可见、可追踪、可更新"。对 Java 后端来说,最可靠的思路仍然是把它当成一个带权限、审计和数据生命周期的业务系统来设计,而不是一个 Prompt 技巧。