大数据系统分析与设计------架构、应用系统结构化分析核心知识点
第一部分 大数据系统原理与架构
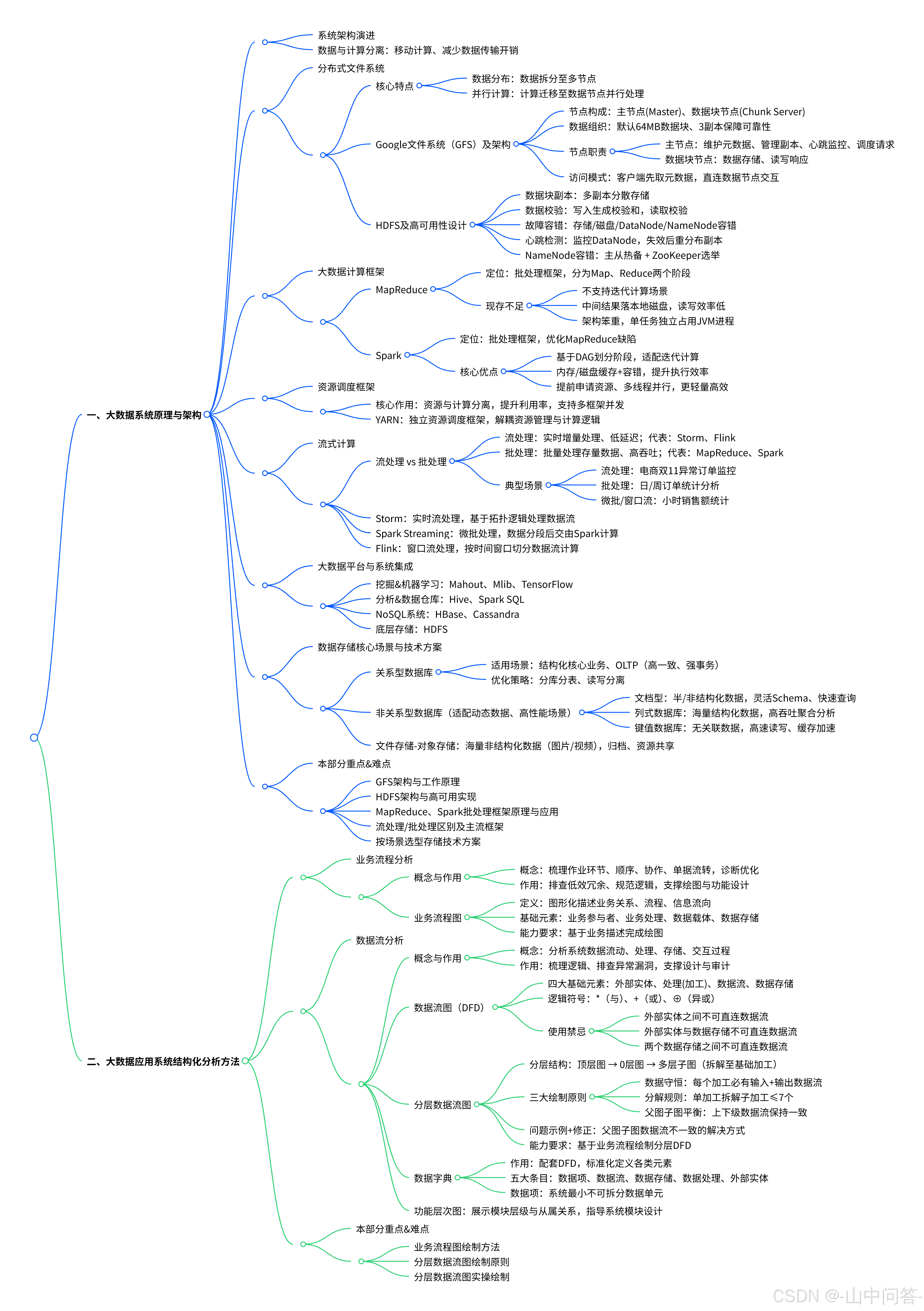
一、 系统架构演进
数据与计算分离:大数据系统倾向于移动计算而非数据,以减少数据移动带来的开销。
二、分布式文件系统
1. 分布式文件系统特点
- 数据分布:数据被分布到多个节点上。
- 并行计算:计算移动到数据节点,实现并行处理。
2. Google文件系统(GFS)及架构:
- 节点构成:主节点(Master)、数据块节点(Chunk Server)。
- 数据组织:文件拆分为 64MB 固定数据块,默认 3 副本保证数据可靠。
- 主节点:维护元数据、管理数据块与副本;心跳监控节点状态,故障时重建副本/迁移数据;对接客户端调度请求。
- 数据块节点:负责实际数据存储与读写响应。
- 访问模式:客户端先向主节点获取元数据,再直连数据节点传数据,减轻主节点压力。
3. HDFS文件系统及高可用性设计:
- 数据块副本:文件分割成数据块,每个块有多个副本分布在不同节点。
- 数据块校验:写入时计算校验和,读取时验证校验和。
- 故障容错:包括数据存储、磁盘、DataNode和NameNode故障容错。
- 心跳检测:监控DataNode状态,失效时重新分布数据块副本。
- NameNode故障容错:主从热备机制,通过ZooKeeper选举。
三、大数据计算框架
1. MapReduce
批处理计算框架,通过map和reduce阶段处理数据。
MapReduce计算框架的不足:
- MapReduce计算状态过于简单,没有考虑到迭代计算场景。
- Map任务计算的中间结果存储到本地磁盘,数据读写效率差。
- MapReduce先提交任务、运行时申请资源,架构笨重,每个并行任务独立占用一个 JVM 进程。。
2. Spark
批处理计算框架,改进了MapReduce的不足,支持迭代计算,提供缓存和容错策略。
Spark优点:
- 基于DAG划分任务阶段,适配迭代计算场景。
- 内置缓存与容错机制,中间数据可存于内存或磁盘,大幅提升 Stage执行效率。
- 任务启动时提前申请资源,多线程实现并行,比MapReduce更轻量高效。
四、资源调度框架
1. 作用
实现资源管理与计算分离,提高资源利用率,支持多种计算框架并发执行。
2. Yarn
将资源管理与计算框架分开,成为独立的资源调度框架,解决MapReduce服务器集群资源调度和执行过程耦合的问题。
五、流式计算
1. 流处理与批处理的区别
- 流处理
实时处理持续产生的数据流,采用增量式处理,数据进入系统后立即被处理并输出结果,强调低延迟响应,典型技术有Storm、Flink; - 批处理
处理已存储的静态数据集,采用批量式处理,需等待数据积累到一定规模后统一处理,强调高吞吐量,典型技术有MapReduce、Spark。 - 应用场景
电商双11活动异常订单监控(流处理);日/周订单统计分析(批处理);小时销售额在线统计(微批处理,如Spark Streaming;或窗口流处理,如Flink)。
2. Storm
实时数据流处理框架,通过定义拓扑逻辑关系处理数据流。
3. Spark Streaming
将实时数据分段,当成一批数据交给Spark处理(微批处理)。
4. Flink
将数据流切分到window窗口里进行计算(流处理)。
六、大数据平台与系统集成
- 大数据挖掘与机器学习:使用Mahout、Mlib、TensorFlow等工具。
- 大数据分析与大数据仓库:使用Hive、Spark SQL等。
- NoSQL系统:如HBase、Cassandra。
- 大数据存储:主要使用HDFS。
七、数据存储核心场景与技术方案
- 关系型数据库
主要用于存储结构化核心业务数据(如用户信息、交易记录)并支持高一致性、强事务性的联机事务处理(OLTP)场景。
数据库优化策略:分库分表、读写分离 - 非关系型数据库
主要用于非关系型动态数据及高性能场景
文档型非关系数据库:主要用于存储半结构化或非结构化数据(如产品详情、用户画像)并支持灵活数据模型(如多属性动态Schema)与快速查询的场景。 - 列式数据库
列式数据库主要用于存储海量结构化或半结构化数据(如用户行为、销售报表数据)并支持高吞吐量的复杂分析查询与大规模数据聚合计算的场景。 - 键值数据库
主要用于存储无复杂关联的数据(如用户会话、购物车缓存数据),依托主键可实现高速单点读写,内存型键值数据库还广泛承担缓存加速的作用。 - 文件存储
对象存储:主要用于存储海量非结构化数据(如商品图片、视频)并支持高扩展性、低成本长期归档与静态资源共享的场景。
八、重点和难点
- GFS架构及基本原理:理解架构中的主要节点类型及作用,以及它们之间的协作方式。
- HDFS架构与高可用性:理解HDFS的工作原理和如何实现数据的高可用性。
- 批处理计算框架:掌握MapReduce模型的计算过程,能够将简单的SQL查询转换为Map和Reduce操作;理解Spark框架对MapReduce的改进;理解批处理的应用场景。
- 流处理计算框架:理解流处理和批处理之间的区别,了解Storm、Spark Streaming和Flink的基本概念、原理和应用场景。
- 数据存储核心场景与技术方案:熟悉关系型数据库、非关系型数据库、文件存储的核心应用场景,能够根据场景和数据特点选择适当的存储技术方案。
第二部分 大数据应用系统结构化分析方法
一、业务流程分析
1. 业务流程分析的概念和作用
(1)概念
对组织现有业务的作业环节、执行顺序、岗位协作关系、单据流转过程进行全面梳理、诊断与优化的分析工作。
(2)作用
排查业务流程冗余与低效问题、规范业务逻辑,为业务流程图绘制和系统功能设计提供真实业务支撑。
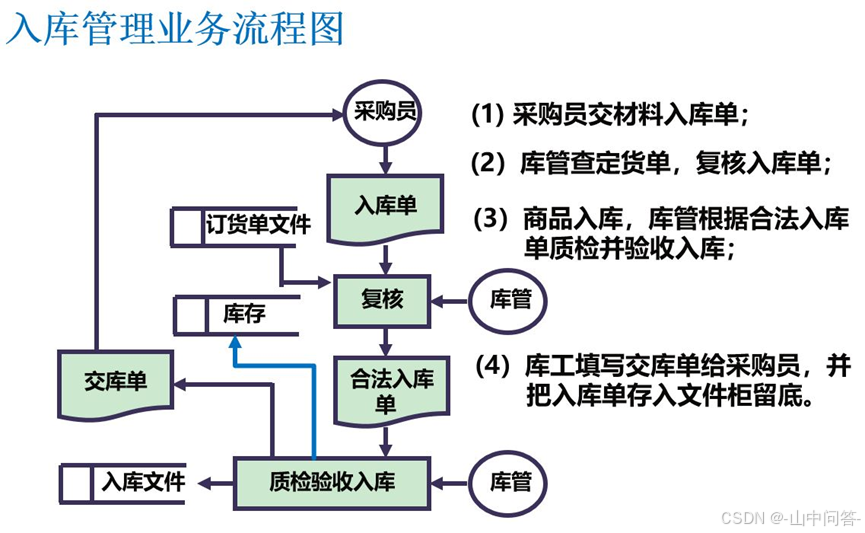
2. 业务流程图
(1)定义
业务流程图是用于描述系统内人员、部门、外部单位之间业务关系、作业顺序、单据与信息流向的图形化工具。
(2)基础组成元素
- 业务参与者:参与业务的人员、部门或外部单位;
- 业务处理:具体的操作、审核、执行等动作;
- 数据载体:各类业务单据、凭证;
- 数据存储:台账、档案、文件等静态数据存放载体。
(3)根据业务描述绘制业务流程图
能够在业务流程分析的基础上,正确采用业务流程图组成元素绘制业务流程图。
业务流程图示例如下:
二、数据流分析
1. 数据流分析的概念和作用
(1)概念
数据流分析是对信息系统中数据流动、处理、存储和交互过程的结构化分析方法。
(2)作用
用于理清业务逻辑,排查数据缺口、冗余和异常,发现权限及安全漏洞,为数据流图绘制、系统设计与运行审计提供依据。
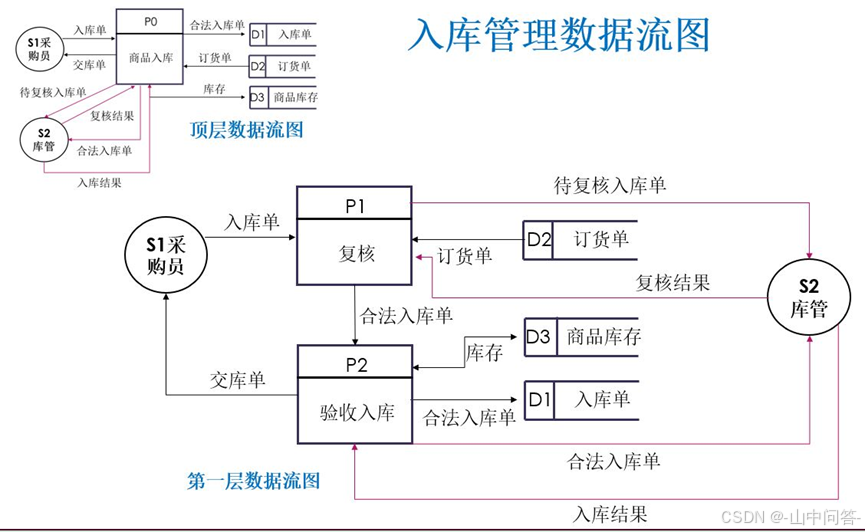
2. 数据流图(DFD)
数据流图是刻画系统数据流动、加工处理、数据存储的核心图形工具。
(1) 四大基础元素
外部实体、处理(加工)、数据流、数据存储。
(2) 附加逻辑符号
*:数据流同时满足(AND 关系);
+:数据流任选其一(OR 关系);
⊕:数据流互斥(XOR 关系)。
(3) 使用禁忌
数据流不能在两个外部实体之间直接流动;
数据流不能在外部实体与数据存储之间直接流动;
数据流不能在两个数据存储之间直接流动。
3. 分层数据流图及绘制原则
(1)分层结构
遵循自顶向下、由外向内的拆解规则,层级划分如下:
顶层数据流图 → 第一层(0 层)数据流图 → 下层子图,持续拆解至不可再拆分的基本加工为止。
(2)三大绘制原则
数据守恒:每一个加工必须至少包含 1 个输入数据流和 1 个输出数据流;
分解规则:单个加工拆解出的子加工数量适度,一般不超过 7 个;
父图与子图平衡:父图中某一加工的输入、输出数据流,必须和对应子图的输入、输出数据流完全一致。
例如:下图中的父图和子图就存在不平衡的情况
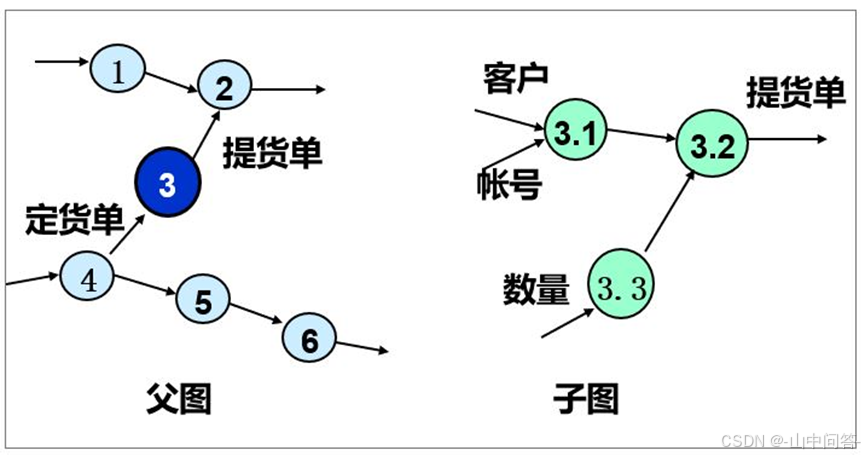
父图的处理3只有一个输入数据流(订货单),而子图则有三个输入数据流(客户、账号、数量),违反了父图-子图的平衡原则。
修改方法:子图增加一个子处理3.4,将输入数据流(订货单)分解后,再输出给3.1和3.3两个子处理。
(3)在业务流程分析的基础上绘制数据流图
能够在业务流程和业务流程图的基础上,正确采用数据流图组成元素,遵循数据流图分层绘制原则,绘制顶层数据流图和下层子图。
数据流图示例如下:
4. 数据字典
(1)作用
作为数据流图的配套说明文档,对数据流图中所有元素进行标准化定义、解释与补充说明。
(2)五大标准条目
数据项、数据流、数据存储、数据处理、外部实体。
数据项是系统中不可再拆分的最小数据单元。
数据字典示例如下:
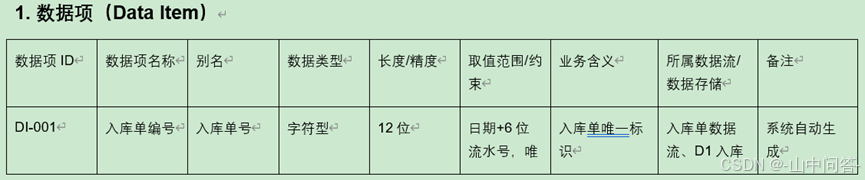
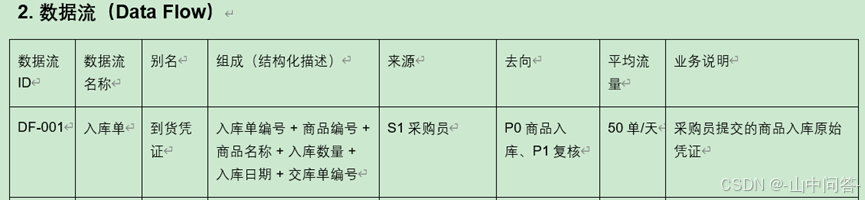
5. 功能层次图
以分层形式展示信息系统的整体模块、子模块及细分功能,直观体现功能从属关系与模块划分逻辑,主要用于指导系统模块设计与功能落地。
三、重点和难点
- 掌握业务流程图的绘制方法
- 理解分层数据流图的绘制原则
- 掌握分层数据流图的绘制方法