
大家好,我是子昕。
第一眼看到 Claude Fable 5 的榜单,我真愣了一下。
FrontierCode,29.3 分。
GPT-5.5,5.7 分。
超过 5 倍。
说实话,这种差距很难让一个天天用 AI 写代码的人保持冷静。
但我把发布文章、319 页系统卡、价格和安全机制看完之后,反而意识到:现在还没法下结论。
Fable 5 可能是 Anthropic 这半年最值得开发者关注的模型。
可它贵、限制多,而且真正最强的地方还没有经过我的项目验证。
这篇不复述发布会。我只想回答一个问题:
现在主力用 GPT-5.5 的开发者,要不要切 Fable 5?
我的答案是:光看榜单判断不了。
Fable 5 天然就需要放进复杂项目里深度测试。
趁免费窗口拿一个大项目跑一遍,再决定它能不能接替现有主力。
这次跑分,确实有点夸张
先看 Anthropic 的官方榜单。
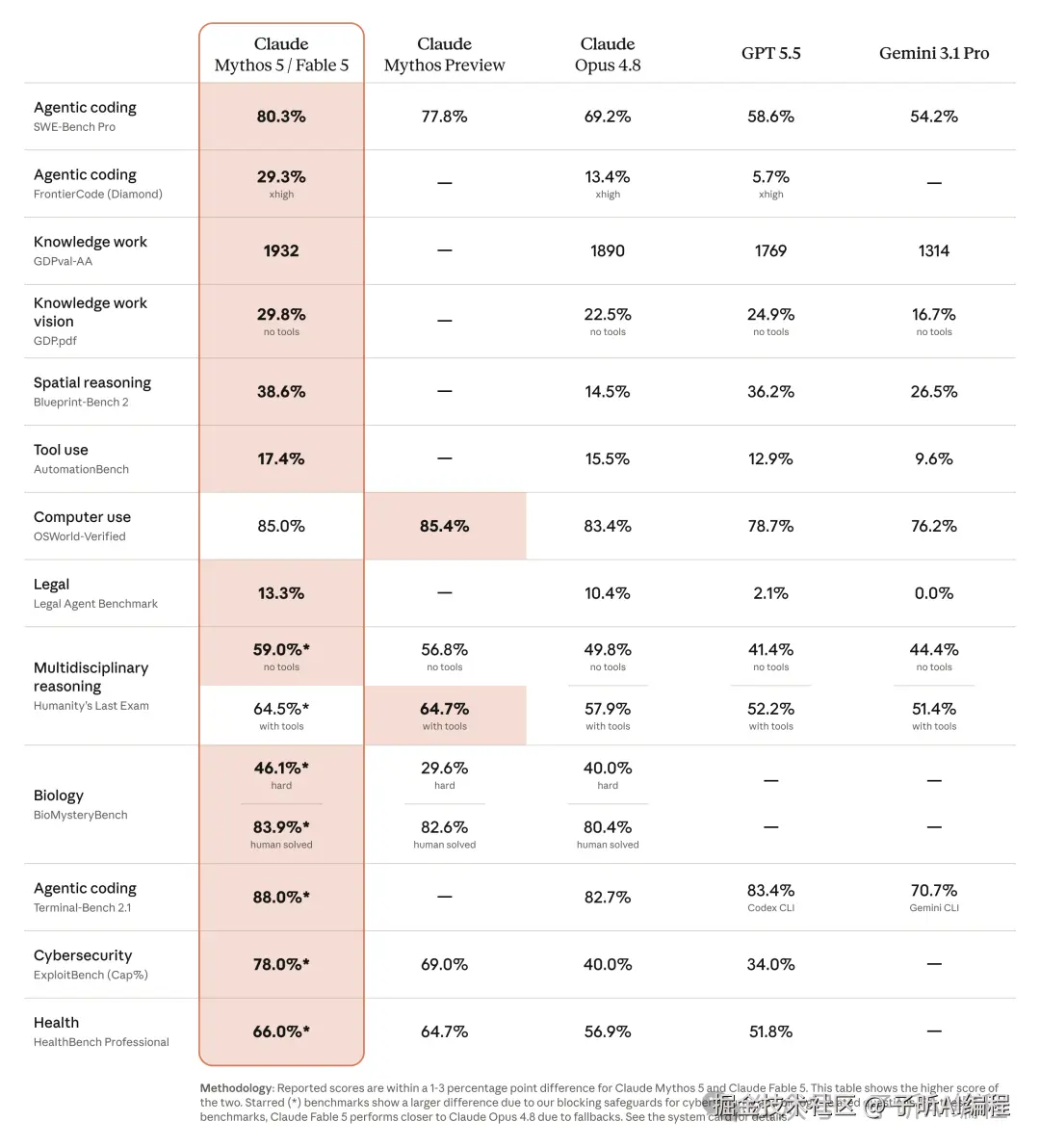
这里有个非常容易看错的地方。
第一列写的是 Claude Mythos 5 / Fable 5,不是 Fable 5 单独成绩。
官方说明,多数评测里两者相差 1-3 个百分点,图上展示较高的那个分数。
带星号的项目差距可能更大,因为 Fable 5 会受到安全阻断和回退影响。
所以我又回到系统卡,把 Fable 5 单独成绩拆了出来:
| 评测 | Fable 5 单独成绩 | GPT-5.5 | 差距 |
|---|---|---|---|
| SWE-bench Pro | 80.0 | 58.6 | +21.4 |
| FrontierCode Diamond(xhigh) | 29.3 | 5.7 | 约 5.1 倍 |
| Terminal-Bench 2.1 | 84.3 | 83.4 | +0.9 |
这三行放在一起看,结论和"全面碾压"完全不一样。
复杂代码修复和可合并代码质量,Fable 5 确实拉开了。
但到了终端任务,84.3 对 83.4,基本是同一水平。
第一眼看到 29.3 对 5.7,我有点兴奋。
看到 Terminal-Bench 只差 0.9,我又冷静了一半。
Fable 5 不是每个编程场景都把 GPT-5.5 按在地上摩擦。它的优势更集中在复杂、长链路、最终代码质量要求高的任务。
这反而更符合真实工程。
写一个接口,大家都能写。
难的是跨十几个模块改完之后,代码还能不能合并。
Fable 5 和 GPT-5.5,到底怎么选
我现在真实后端项目的主力仍然是 GPT-5.5。
不是因为它每项跑分都最高,而是我已经知道它在 Java 项目里什么时候靠谱、什么时候会漏、失败后该怎么继续追。
模型选型不是只看智商。
稳定预期,本身就是生产力。
把两边最影响开发者选择的参数放一起:
| 维度 | Claude Fable 5 | GPT-5.5 |
|---|---|---|
| API 上下文窗口 | 100 万 token | 105 万 token |
| 最大输出 | 12.8 万 token | 12.8 万 token |
| 标准 API 输入价格 | 10 美元/百万 token | 5 美元/百万 token |
| 标准 API 输出价格 | 50 美元/百万 token | 30 美元/百万 token |
| 输入超过 27.2 万后的价格 | 仍为 10 / 50 美元 | 10 / 45 美元 |
这里最容易混淆的是产品窗口和 API 窗口。
GPT-5.5 在 Codex 里是 40 万上下文,但 API 模型支持 105 万。两者不是同一个口径。
GPT-5.5 标准 API 价格是输入 5 美元、输出 30 美元。
还有一个容易漏掉的细节:当输入超过 27.2 万 token,GPT-5.5 整次会话会按 2 倍输入、1.5 倍输出计费,也就是输入 10 美元、输出 45 美元。
所以短上下文任务里,GPT-5.5 明显便宜。
真进入几十万 token 的长任务后,Fable 5 的 10/50 美元和 GPT-5.5 的 10/45 美元,价格已经非常接近。
这时候比的就不是谁单价低,而是谁能用更少的重试把项目做完。
Anthropic 自己的 FrontierCode 成本图也很直观。Fable 5 的分数明显更高,但每个任务花的钱也一路往上走。
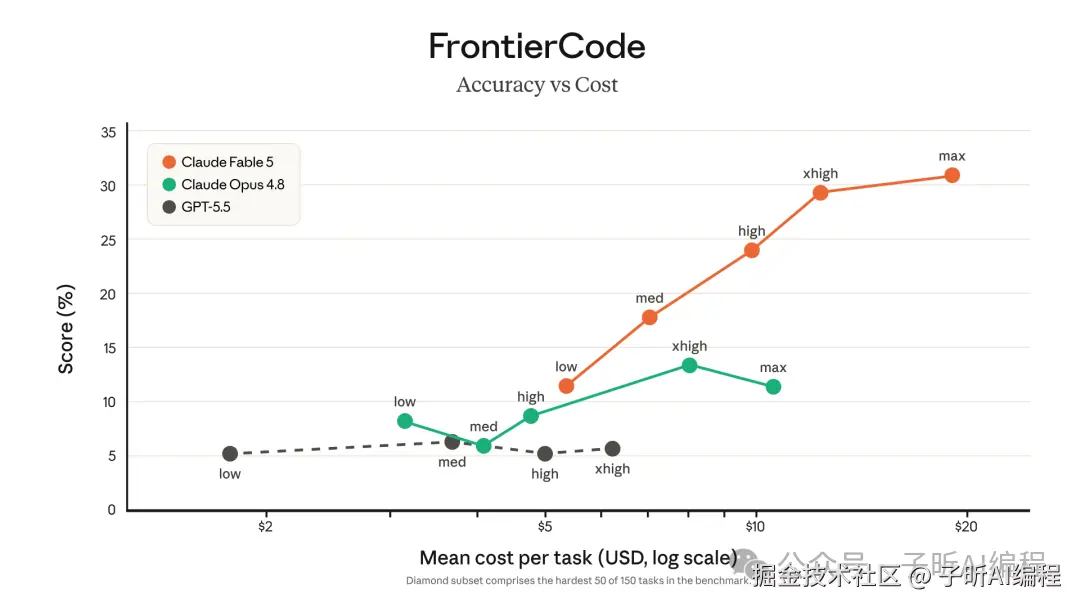
如果只是改 CRUD、补单测、解释代码,我不会用 Fable 5。
GPT-5.5 甚至更便宜的模型已经够了。
但如果任务是跨仓迁移、老系统重构、连续几天的性能优化,Fable 5 的价格才可能值回来。
真正让我兴奋的,是它开始按"项目"干活
Anthropic 对 Fable 5 的定位不是"更会回答问题"。
而是能在数小时甚至数天的任务里保持方向。
它支持 100 万 token 上下文、12.8 万 token 输出。
官方提示词指南甚至建议,不要再把任务拆得过细,只要把目标和验收标准说清楚,让它自己探索、实现、测试和修正。
这句话对我冲击挺大。
以前我们把 AI 当一个随叫随到的编程助手。
现在 Anthropic 想把它变成一个能接完整项目的工程师。
Stripe 的早期案例更夸张:按照 Anthropic 的转述,一次约 5000 万行代码迁移,团队原本预计花几个月,Fable 5 一天跑完了主要工作。
这不是独立复现,我不会直接当真。
但说实话,我看到这里还是有点心动。
做后端这些年,最烦的从来不是某段代码不会写。
是那些明知道该做,却因为牵扯太多一直压着的活:老规则迁移、历史技术债、跨模块重构、性能瓶颈。
如果 Fable 5 真能把这种任务连续跑下去,它改变的不是写代码速度。
它会把以前排不上期的工程任务,重新变成可以做的事。
然后这张安全图,把我看冷静了
Fable 5 不是一个完全放开的模型。
Anthropic 给它加了额外安全机制。部分高风险任务会被阻断、拒答,或者回退到 Opus 4.8。
下面这张官方图很有意思。
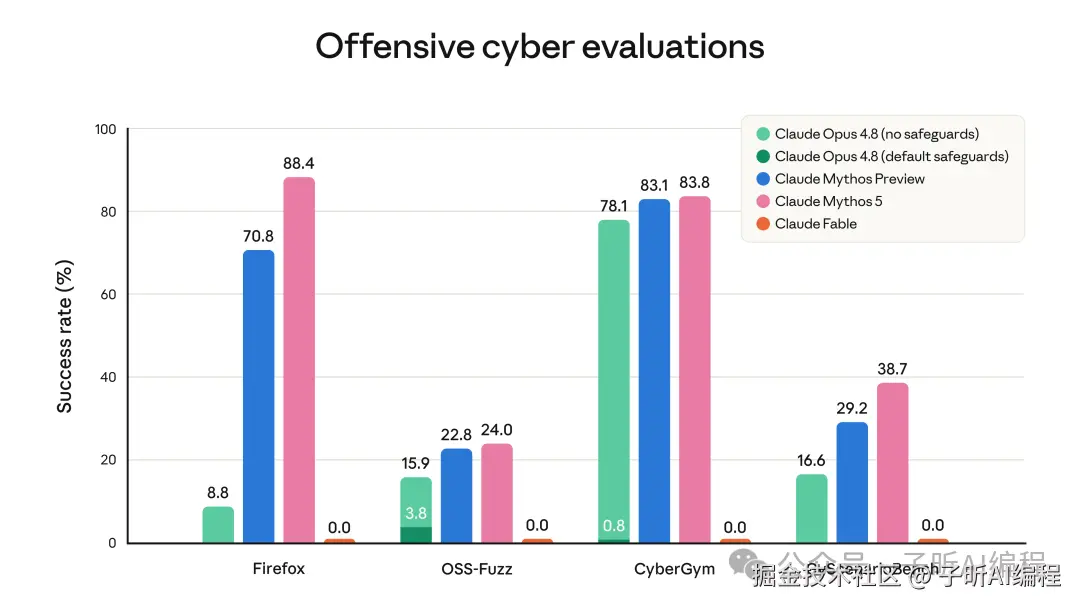
你会看到 Fable 5 在几项进攻性网络安全评测里直接是 0。
不是模型突然不会了。
是安全机制不让它做。
看到这里,我第一反应不是"安全做得真好",而是:
那普通企业代码里,哪些任务会误触发?跑了两小时后突然拒绝怎么办?
Claude 客户端里,部分请求会自动路由到 Opus 4.8。
Messages API 默认会返回结构化 refusal,开发者需要自己处理重试或 fallback。
这意味着同一个长任务,中途可能换模型,也可能直接停下来。
再加上 Fable 5 的提示词和输出需要为安全目的保留 30 天,不能继续按 Zero Data Retention 使用。
对个人项目问题不大。
对公司核心代码库,这不是一句"模型更强"就能绕过去的。
价格,又泼了一盆冷水
Fable 5 输入 10 美元、输出 50 美元。
举个最简单的账:
- 100 万输入 + 5 万输出,约 12.5 美元。
- 100 万输入 + 12.8 万输出,约 16.4 美元。
这还只是一轮账面计算。
真实长任务会反复读文件、跑命令、修失败、重试、验证。跑几个小时之后,累计成本可能完全不是一个量级。
所以 Fable 5 很像一个收费极高的资深顾问。
小活找它,纯浪费。
大活找对了,可能一天把几个月的工作啃下来。
现在正好有一个试用机会。
到 6 月 22 日之前,Pro、Max、Team 和席位制 Enterprise 用户暂时可以在现有套餐里使用 Fable 5。
6 月 23 日之后会改为 usage credits,除非 Anthropic 延长窗口。
我准备怎么测
我不会拿它生成 Todo List,也不会测一个从零写 Demo。
我准备找一个真实的 Java 多模块老项目,给它一条完整业务链路:
- 从入口一路追到核心处理逻辑。
- 检查数据读写和异步任务。
- 修改规则并补齐测试。
- 自己运行验证,最后 review 全部 diff。
我最关心的不是它写了多少代码。
而是四件事:
- 第几个小时开始跑偏。
- 上下文压缩后还记不记得关键约束。
- 测试失败后能不能自己找回来。
- 最终代码我敢不敢合并。
最后一条最重要。
榜单再高,代码不敢进生产,都是热闹。
最后
看完 Fable 5,我的情绪其实转了三次。
看到 FrontierCode 29.3,我有点震住。
看到 Terminal-Bench 只领先 GPT-5.5 0.9,我冷静了一半。
再看到价格、安全回退和数据保留,我意识到是否切主力这件事,根本不能只靠榜单决定。
但我不会忽略它。
因为 Fable 5 真正想证明的,不是自己比 GPT-5.5 聪明多少。
它想证明的是:
AI 已经可以从"帮你完成一个任务",走到"替你推进一个项目"。
这件事如果在真实 Java 项目里成立,再认真讨论要不要换主力。
不成立,那它就是一个跑分很猛、价格很贵的高级实验品。
等我跑完再说。
如果这篇对你有帮助,欢迎关注微信公众号「子昕AI编程」,也顺手点个赞、在看,或者转发给同样在折腾 AI 编程工具的朋友。