影刀RPA实操指南:淘宝天猫商品数据自动化采集完整流程
淘宝天猫和拼多多最大的区别:它有评价体系、有SKU、有双价格(原价和券后价),而且很多数据需要登录后才能看。
这篇文章不是泛泛讲采集,而是聚焦淘宝天猫特有的坑和解决方案。前提是你已经掌握了基础的元素捕获和循环逻辑。
一、淘宝登录的特殊性
淘宝的登录比拼多多严格。短信验证、滑块验证出现的频率高很多。
建议策略
不要每次都重新登录。淘宝的Cookie有效期比较长(大概15~30天),保存Cookie复用,比次次登录靠谱得多。
python
# 淘宝登录态检测的特征元素
# 已登录 → 页面顶部有"你好,xxx"或"我的淘宝"
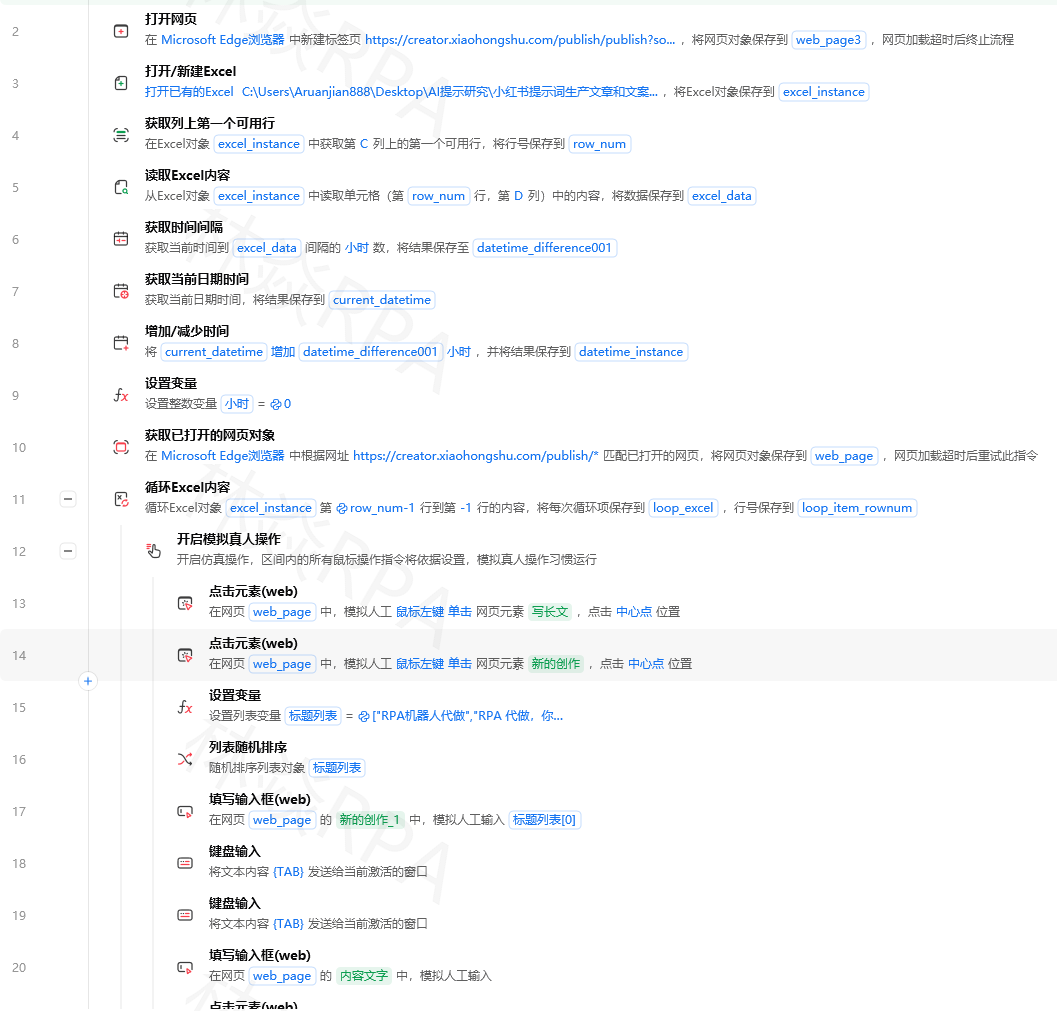
# 未登录 → 显示"请登录"
判断元素是否存在("已登录用户名") -> 登录状态
如果不满足 登录状态:
调用子流程("A_淘宝登录")淘宝登录的元素要注意:它的登录框可能是iframe嵌套的,记得先切换框架。
二、搜索入口与URL结构
拼多多店群自动化报活动上架!
淘宝搜索页的URL有固定规律:
# 基础搜索
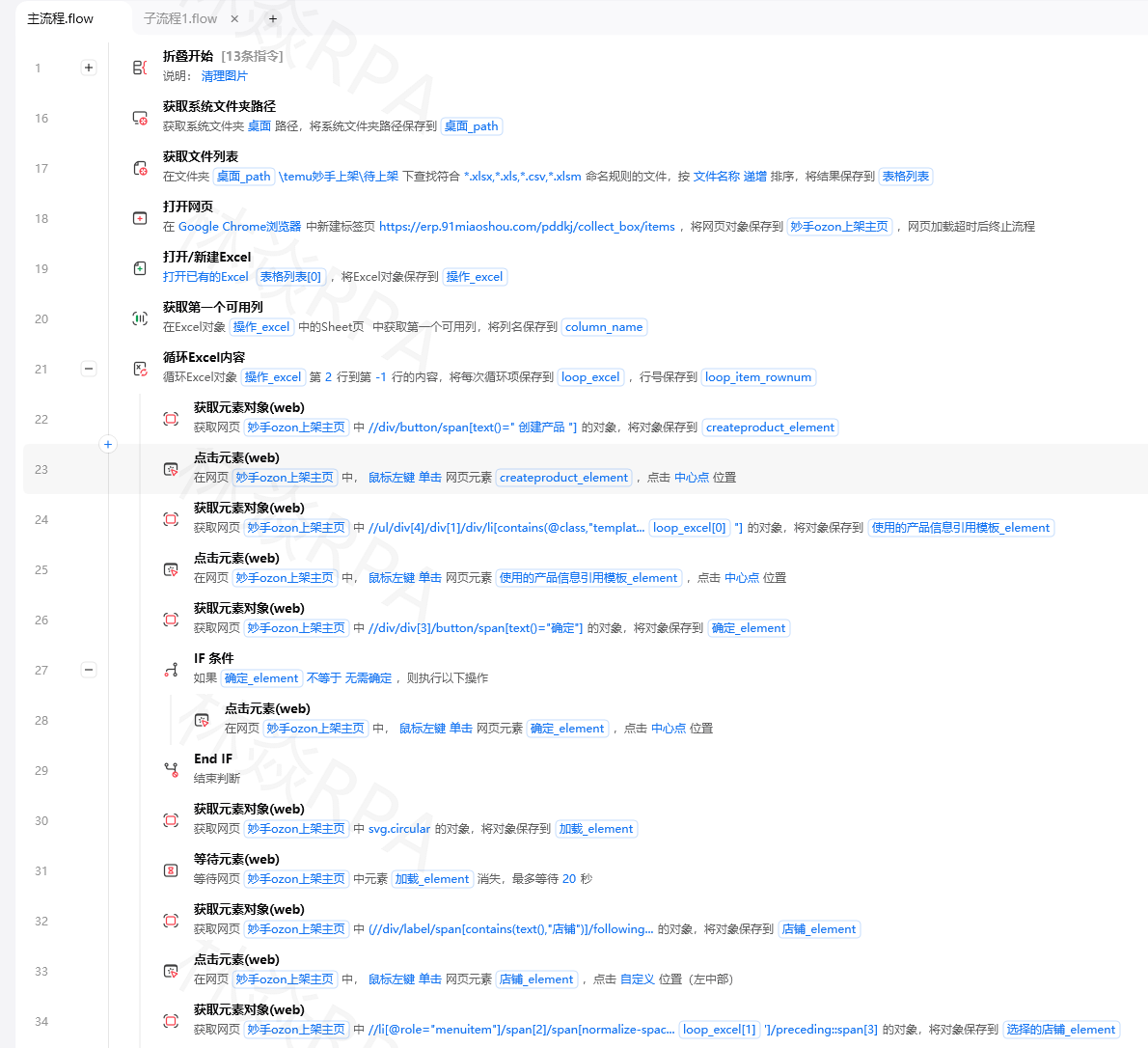
https://s.taobao.com/search?q=连衣裙
# 加筛选条件
https://s.taobao.com/search?q=连衣裙&sort=sale-desc (按销量排序)
https://s.taobao.com/search?q=连衣裙&filter=price-0-100 (价格筛选)
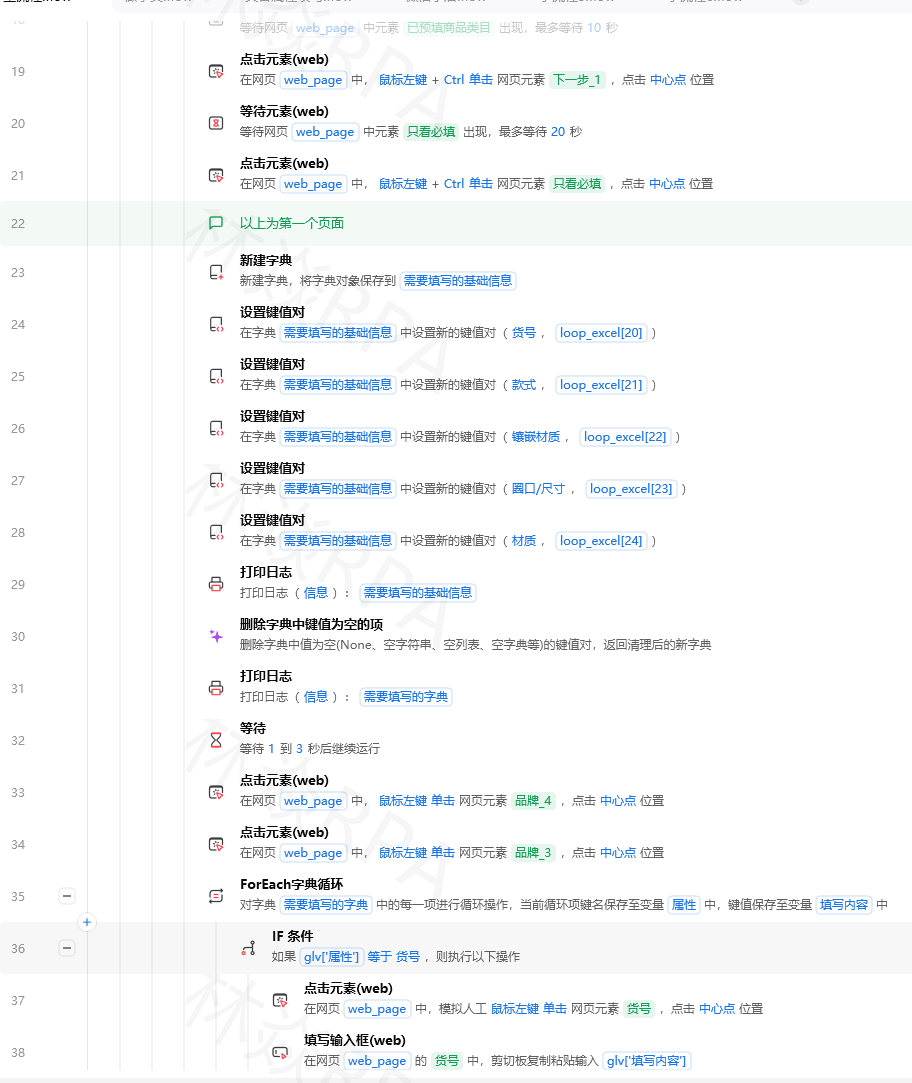
# 天猫搜索
https://list.tmall.com/search_product.htm?q=连衣裙可以直接拼接URL跳页,省去点击筛选按钮的步骤:
python
关键词 = "连衣裙"
页数 = 3
URL = f"https://s.taobao.com/search?q={关键词}&s={(页数-1)*44}" # 淘宝每页44条
打开网页(URL)淘宝的翻页参数是 s(offset),每页44条商品。第1页 s=0,第2页 s=44,依此类推。
三、价格提取的坑
淘宝价格不仅是一个数字,还有各种形式:

¥128.00 ← 正常
¥99.00 ¥199.00 ← 券后价和原价
¥128-168 ← 价格区间(多SKU)
2件9折 ← 活动价清洗逻辑
python
import re
def parse_taobao_price(price_text):
"""把各种淘宝价格格式统一成最小价格"""
if not price_text:
return 0.0
price_text = price_text.strip()
# 去掉¥符号和其他非数字字符
price_text = price_text.replace("¥", "").replace(" ", "")
# 处理"¥128-168"这种价格区间,取最小值
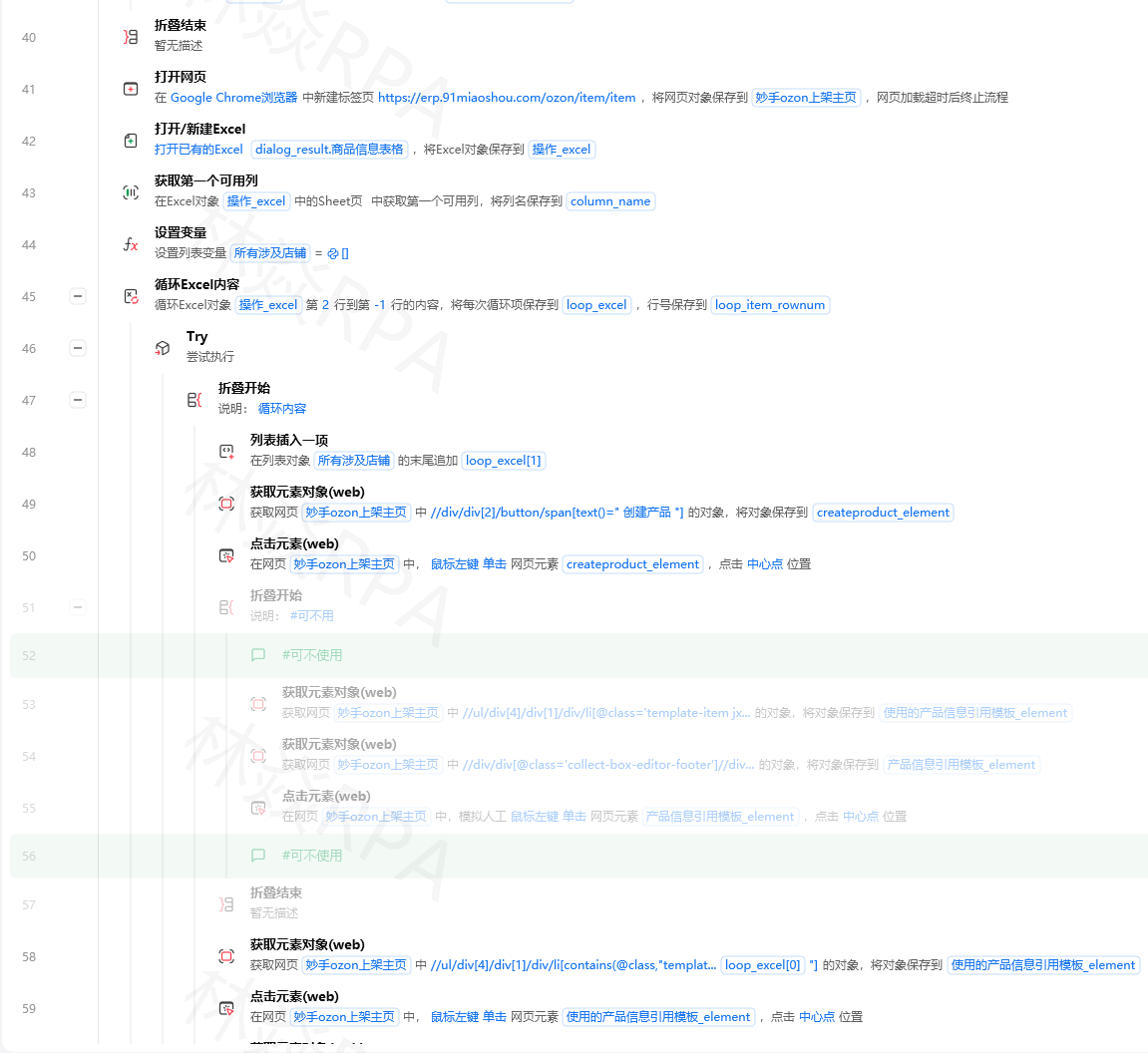
if "-" in price_text:
parts = price_text.split("-")
nums = []
for p in parts:
found = re.findall(r'\d+\.?\d*', p)
if found:
nums.append(float(found[0]))
return min(nums) if nums else 0.0
# 处理"¥99.00 ¥199.00"这种双价格,取第一个(券后价)
nums = re.findall(r'\d+\.?\d*', price_text)
if nums:
return float(nums[0])
return 0.0
# 使用
原始价格 = get_element_text("price")
清洗后价格 = parse_taobao_price(原始价格)四、评价数据的获取
淘宝的评价数和商品列表页显示的不完全一致。列表页显示的是"收货人数"(已付款且确认收货),跟实际评价数有差异。
如果需要精确数据,进商品详情页的"累计评价"标签:
python
# 打开商品详情页
打开网页(商品链接)
# 找"累计评价"标签
# XPath: //a[contains(text(),'累计评价')]
判断元素是否存在("累计评价标签"):
点击元素("累计评价标签")
固定等待(2秒)
# 评价页可能有分页,也需要翻页处理
采集评价内容()五、天猫与淘宝的差异
| 特性 | 淘宝店铺 | 天猫店铺 |
|---|---|---|
| 店铺类型 | C店 | B店(品牌旗舰店) |
| 搜索域名 | s.taobao.com | list.tmall.com |
| 商品ID格式 | 纯数字长ID | 数字ID |
| 页面结构 | 相对简单 | 活动模块更多,DOM更复杂 |
| 价格字段 | price class |
可能嵌套在活动div里 |
天猫页面比淘宝多了很多营销模块(预热、预售、品牌专区),元素捕获时要更小心------同样的"价格"元素,可能出现在多个嵌套的div里。
建议用精确的XPath定位:
# 避开活动模块,直取核心价格
//div[@class='product']//span[contains(@class,'price')]
TEMU店群矩阵自动化运营核价报活动
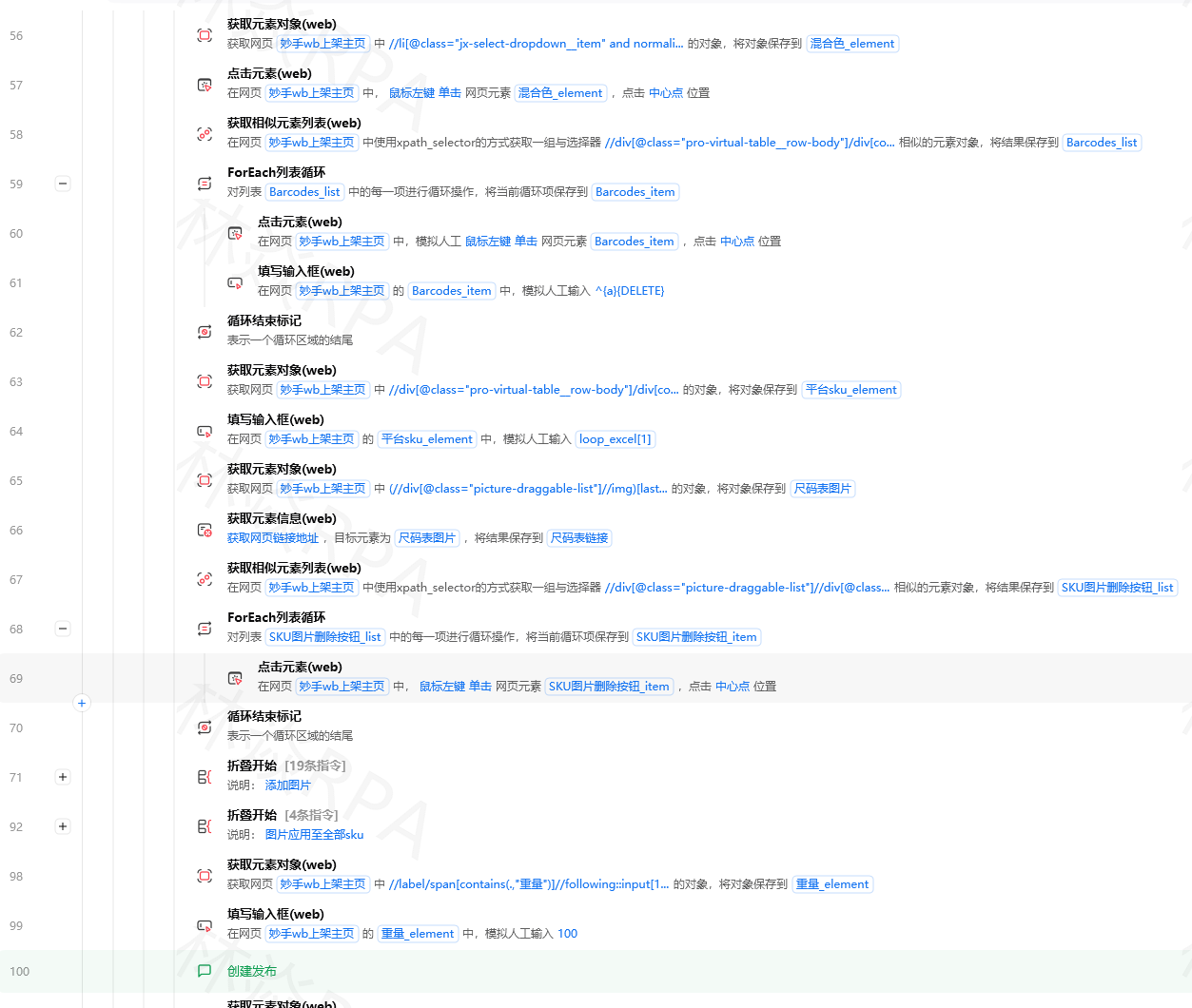
六、SKU信息的提取
淘宝和天猫的商品经常有多SKU(颜色/尺码)。列表页一般不展示完整的SKU,需要进详情页。
详情页的SKU区域可以用相似元素列表提取:
python
# 遍历SKU选项
获取相似元素列表("SKU颜色选项") -> 颜色列表

# XPath参考://li[contains(@class,'sku-line')]//span不过这种操作在自动化里不太实用------点每个SKU就会触发页面变化(价格变动、库存变动),而且操作太频繁容易触发风控。
实际建议:如果只是做市场调研,用列表页的数据就够了(价格范围、销量区间)。需要精确SKU数据的场景,考虑用淘宝开放平台的API,而不是页面爬取。
七、防限流策略(淘宝特有)
淘宝的反爬比一般电商平台更成熟。
python
# 策略1:页面停留时间随机化
固定等待(2 + random.random() * 3) # 2~5秒随机
# 策略2:搜索间隔
每采集完一页:
固定等待(5 + random.random() * 5) # 5~10秒休息
# 策略3:分时段
# 不要在短时间内大量请求
# 每采集10页停5分钟
# 策略4:检测验证码
判断元素是否存在("验证码或滑块") -> 需要验证
如果 需要验证:
输出日志("遇到风控,暂停30分钟")
固定等待(1800秒) # 30分钟淘宝遇到风控后,IP可能会被限制一段时间。不要硬刚。
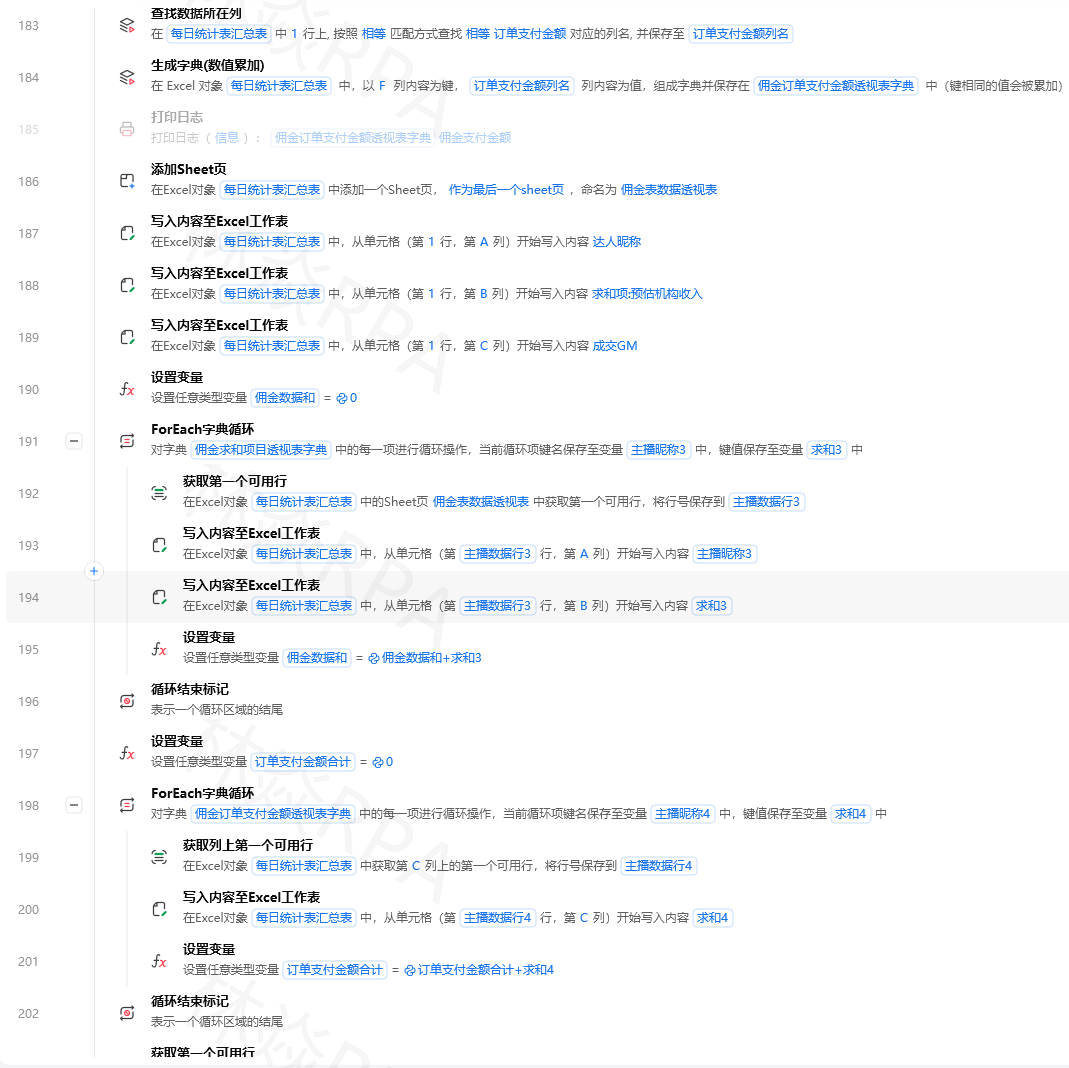
八、完整采集流程
python
# 淘宝关键词 → 商品列表采集
关键词列表 = ["连衣裙", "T恤男", "运动鞋女"]
遍历列表(关键词列表, 关键词):
输出日志(f"开始采集: {关键词}")
商品数据 = []
# 采集前5页
遍历范围(0, 5, 页数):
offset = 页数 * 44
URL = f"https://s.taobao.com/search?q={关键词}&s={offset}"
打开网页(URL)
固定等待(3秒)
# 获取商品列表
获取相似元素列表("商品卡片") -> 商品列表
遍历列表(商品列表, 卡片):
名称 = 获取元素文本(卡片 // 名称元素)
价格原始 = 获取元素文本(卡片 // 价格元素)
价格 = parse_taobao_price(价格原始)
销量原始 = 获取元素文本(卡片 // 销量元素)
店铺 = 获取元素文本(卡片 // 店铺元素)
商品数据.append({
"关键词": 关键词,
"商品名称": 名称,
"价格": 价格,
"销量文本": 销量原始,
"店铺名": 店铺,
"页码": 页数 + 1
})
输出日志(f"第{页数+1}页完成,共{len(商品数据)}条")
# 页间休息
固定等待(5秒)
# 保存
保存到Excel(商品数据, f"D:\\数据\\淘宝_{关键词}_{date}.xlsx")作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。
