ChatGPT 之后,大模型评测开始变得越来越奇怪。
模型在律师考试里刷分,在医学题库里刷分,在数学竞赛题里刷分。榜单看起来越来越漂亮,分数越来越接近"专家水平"。但你把它从考场里拎出来,丢进真实世界,让它查一个网页、读一个表格、确认一个日期、再给出一个不能含糊的答案,它反而开始露怯。
这件事很反直觉。
我们习惯把"更难"理解成更专业、更抽象、更接近博士资格考试。但对一个真正的 AI 助手来说,难题未必是解一道奥数题,而是完成一串普通人每天都在做的小动作------找资料、核来源、算结果、看文件、别瞎编。
于是 GAIA 出现了。
它不是给模型再出一套更变态的考试题,而是把问题拉回一个朴素标准:一个通用 AI 助手,能不能像普通人一样,稳稳地完成真实世界里的简单任务?
答案有点冷。
1. AI刷爆考试题之后,评测反而失灵了
先看大背景。
今天的大模型,已经很会"考试"。MMLU 这类覆盖 STEM、人文、社科的综合题库,曾经被视为大模型能力的硬门槛;但 GPT-4 在 MMLU 上已经做到 86.4%,接近论文引用的人类专家水平 89.8%。非专业人类在这个测试上的准确率只有 34.5%。
换句话说,在很多专业知识题上,模型已经像一个"会背题、会推理、会答卷"的高手。
但这也带来一个尴尬问题:如果榜单不断被刷爆,评测还剩多少信息量?
更麻烦的是,越复杂的开放式任务越难评。你让 AI 写一本书,谁来判断它写得好不好?你让 AI 解一道全球只有少数人能验证的数学题,普通评测员怎么验?如果让另一个更强模型来打分,那评测又变成"模型审模型"------它可能有偏见,也可能根本不够强。
这就像学校发现学生都会做卷子了,于是不断把考试变成更偏、更怪、更专业的竞赛题。
但社会真正需要的,不一定是竞赛冠军。
社会需要的是一个靠谱助理。
GAIA 的切入点就在这里:不要再追逐"对人类也越来越难"的题,而是设计一批对人类概念上很简单、对 AI 却非常难的真实任务。人类看一眼就知道该怎么做,只是过程有点烦;AI 看上去很聪明,却容易在中间某一步断掉。
这不是智商测试。
这是可靠性测试。
要测的不是"模型懂不懂知识",而是"模型能不能把知识、工具和行动串起来"。
这才是通用助手最难的地方。
2. GAIA的题目为什么"人类简单、AI困难"
GAIA 一共构造了 466 个问题。
这些问题看上去并不吓人。它们通常只要求一个短答案:一个数字、一个城市名、几个用逗号隔开的词,或者一个精确到小数点后的结果。没有长篇作文,没有主观评分,也没有"请展开论述"。
但真正的难点藏在过程里。
比如论文给出的 Level 1 样例:去 NIH 网站查一项 2018 年 1 月到 5 月关于 H. pylori 和 acne vulgaris 的临床试验,实际 enrollment count 是多少?
答案只有一个数字:90。
人类怎么做?打开网页,搜关键词,进 clinical trials,确认日期,切到 tabular view,找到 Actual Enrollment。
这不难。
但它需要你连续做对很多小事。
对 AI 来说,这就是麻烦。它不能只靠训练记忆猜答案,也不能看到题目就开始"语言补全"。它必须浏览网页,定位可信来源,理解页面结构,提取正确字段,再按照格式输出一个精确数字。
这就像让一个学生不要写作文,而是去办一件真实世界里的小事:查航班、填表格、核账单、找文件。每一步都简单,但每一步都不能错。
论文用三道样例题直接展示了 GAIA 的核心味道:题面不吓人,答案也很短,但中间必须完成搜索、核验、计算、多模态理解等一串动作。

图1
图1:GAIA 的三档样例问题。它们不是专业知识难题,而是需要模型在真实世界中连续执行多步操作的任务。
GAIA 的问题大多遵循这个逻辑:答案很短,路径很长;概念很简单,执行很脆。
论文把它类比成 Proof of Work------工作量证明。验证答案很容易,但得到答案必须完成一串真实操作。你不能靠蒙,也不能靠背。
这也是 GAIA 和传统 benchmark 最大的区别。
传统考试题经常把难度放在"脑子里":复杂公式、专业概念、隐含知识。GAIA 把难度放在"行动链"里:你要用工具,要查网页,要读文件,要处理图片、音频、表格,要把多个来源拼起来。
一句大白话总结就是------GAIA 不问 AI 会不会"讲道理",它问 AI 会不会"把事情办成"。
这一下就把通用助手的短板照出来了。
3. 四个设计原则:真实、可解释、难作弊、好评测
GAIA 最聪明的地方,不只是题目难,而是题目难得很克制。
它没有把评测做成一个庞大复杂的模拟世界,也没有要求模型在某个封闭环境里调用指定 API。相反,它用四个原则把任务钉住。
第一,问题必须来自真实世界。
题目会涉及网页浏览、多模态理解、代码执行、文件读取,以及日常个人任务、科学信息、通用知识等场景。它不是在一个玩具沙盒里考模型"会不会调用工具",而是让模型面对真实网页、真实文件和真实信息源。
这很关键。
因为很多 Agent 评测其实测的是"会不会适应这个评测环境"。给它一个固定 API、固定工具、固定步骤,它可能学会的是环境套路,而不是通用能力。GAIA 不规定工具路径,只规定最终答案。
第二,问题要能被普通人理解。
这听起来像降低难度,其实是在提高评测质量。因为如果题目本身非常专业,模型错了以后,你很难判断它是不会推理,还是不懂专业知识。GAIA 刻意让非专家也能接近满分,方便人类检查模型的推理轨迹。
第三,问题要难以被记住或污染。
GAIA 要求答案不能直接以明文形式存在于互联网上。多数问题需要组合多个来源,或者对信息做一次转换。比如从网页找到数据,再按某个标准计算;从图片或文件里提取信息,再和另一个来源对照。
这就减少了"模型在预训练里见过答案"的可能性。
第四,评测必须简单。
每道题只有一个简短、明确、事实性的正确答案。评分采用近似 exact match------也就是在必要规范化后,答案对就是对,错就是错。没有长篇主观判断,也不需要评委读半天。
这套设计像一个很窄的针眼。
题目要真实,但不能太开放;要简单,但不能容易蒙;要难倒 AI,但不能难倒人类;要能测复杂行动链,但最终答案又必须一眼可验。
这就是 GAIA 的工程品味。
它不是把评测做大,而是把评测做准。
4. 三档难度:从五步以内到"近乎完美助手"
GAIA 把 466 个问题分成三个等级。
Level 1 通常不需要工具,或者最多一个工具,步骤不超过 5 步左右。它像一个普通网页查询任务:找一个事实,确认一个字段,输出一个短答案。
Level 2 开始变复杂。问题大约需要 5 到 10 步,并且往往要组合不同工具。比如既要浏览网页,又要读文件;既要理解图片,又要做计算。
Level 3 则是给"近乎完美通用助手"准备的。它可能需要很长的行动序列,任意数量的工具,以及对开放世界的持续访问。人类做起来也要花更久,但仍然不是概念上难到无法理解。
这里有个微妙点:GAIA 的难度不是按"题目看起来多吓人"划分,而是按行动链划分。
也就是说,它关心的不是大模型能不能解出一个漂亮公式,而是它能不能稳定完成一条越来越长的操作路径。
这很像真实工作。
一个助理最常见的失败,不是完全不知道要做什么,而是在第七步看错了来源,在第九步算错了单位,在第十二步忘了用户要求不要带百分号。
你可以把 GAIA 看成一套"长链路防抖测试"。链路越长,错误越容易积累;工具越多,接口越容易错配;来源越杂,幻觉越容易钻出来。
论文还统计了所需能力覆盖:web browsing 是最大头,有 355 个问题涉及;coding 有 154 个;multi-modality 有 138 个;diverse filetype reading 有 129 个。文件类型也很杂,包括 xlsx、png、pdf、txt、mp3、jpg、csv、docx、pptx、zip、xml、py、json、m4a 等。
如果只看文字定义,三档难度还像是人为划线。图3 更直观地把 GAIA 的"难"拆成了两件事:需要哪些能力,以及要走多少步、用多少工具。
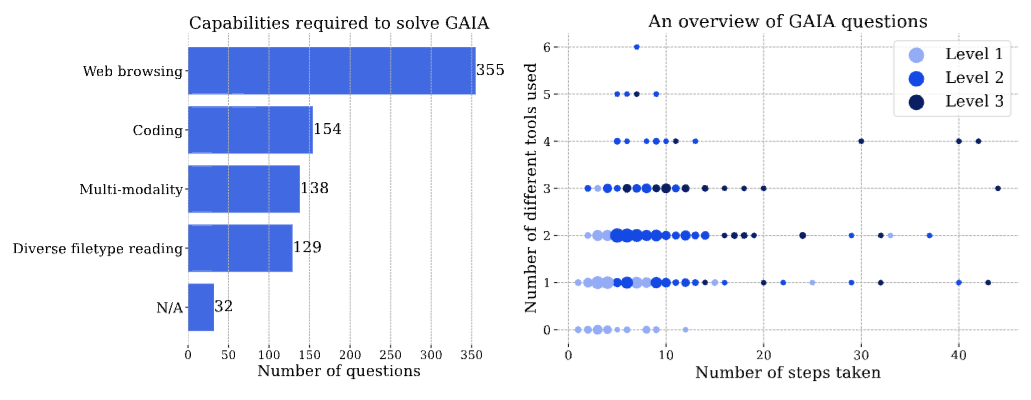
图2
图2:GAIA 问题的能力覆盖和难度分布。Web browsing 是最大头,同时大量问题需要代码、多模态和多文件类型读取。
这不是"问答题库"。
这是一个迷你真实世界。
而通用 AI 助手真正要过的,恰恰就是这种世界。
5. 数据怎么造:每道题背后都是人工打磨
GAIA 不是从现成数据集里拼出来的。
论文团队让人类设计问题,并要求每道题基于 source of truth------也就是可信事实来源。这个来源可以是 Wikipedia、arXiv、GitHub、NIH 之类相对稳定的网站,也可以是题目附带的文件,甚至可以是一个自包含的小谜题。
但只靠一个人写题还不够。
真正费工夫的是消歧。
GAIA 要求每道题只有一个正确答案。听起来简单,做起来很难。网页可能更新,版本可能不同,题目措辞可能让两个认真做题的人走向不同答案。于是团队让两个新的标注员独立回答每道题,用来验证问题是否无歧义。
如果原始出题者和两个新标注员都得到同一个答案,题目才算稳。如果出现分歧,能修就修,修不了就删。
这一步很硬。
论文报告的验证统计很说明问题:在 623 个新构造问题、1246 次验证标注里,只有 68% 的问题最终有效。Level 1 有效率是 75%,Level 2 是 68%,Level 3 只有 47%。
这组数据很适合单独看一眼。它说明 GAIA 最重的成本,不是想出问题,而是把问题打磨到"两个独立人类也能得到同一个答案"。

表1
表1:GAIA 问题验证阶段统计。越高难度的问题越难保持无歧义,Level 3 的有效率只有 47%。
越真实,越难无歧义。
这就是评测构造最容易被低估的成本。你不能随便抓几个网页问题就叫 benchmark。一个好问题要有稳定来源,要能防止答案直接泄露,要能让人类独立得到同一个结果,还要能让机器用短答案自动评分。
论文估计,创建一道题,包括两名额外标注员验证和必要修复,大约需要 2 小时标注时间。
这也是为什么 GAIA 只有 466 题,而不是 15000 题。
它走的是高密度路线。
这套数据构造方式其实传递了一个判断:未来真正有价值的 AI 评测,可能不再是海量选择题,而是一批小而硬、难污染、能复用、能解释的真实任务。
这比堆题更难。
6. 实验结果:人类92分,模型集体翻车
最刺眼的部分来了。
GAIA 上,人类标注员整体成功率约 92%。按难度拆开,Level 1 是 93.9%,Level 2 是 91.8%,Level 3 也有 87.3%。
这说明题目对人类确实不离谱。
但模型表现完全不是一个量级。
GPT-4 在 Level 1 只有 9.1%,Level 2 只有 2.6%,Level 3 是 0。GPT-4 Turbo 稍好一些,Level 1 到 13.0%,Level 2 到 5.5%,Level 3 还是 0。
AutoGPT 用 GPT-4 做后端,理论上更像一个自动工具使用 Agent,但结果也并不漂亮:Level 1 是 14.4%,Level 2 只有 0.4%,Level 3 仍然是 0。
最强的是 GPT-4 + plugins,但这里要特别小心:论文明确说,这个结果更像一个"oracle estimate",因为插件是人类根据任务手动挑的,而且当时 ChatGPT 插件生态变化很快,不容易复现。
即便如此,GPT-4 + plugins 也只做到 Level 1 的 30.3%、Level 2 的 9.7%、Level 3 的 0。按整体看,它大约只有 15%。
人类 92%,GPT-4 插件版 15%。
这不是小差距。
把这些数字画出来,差距会更刺眼:GAIA 不是让模型"略低于人类",而是把人类和当前 AI 助手拉成了两个层级。
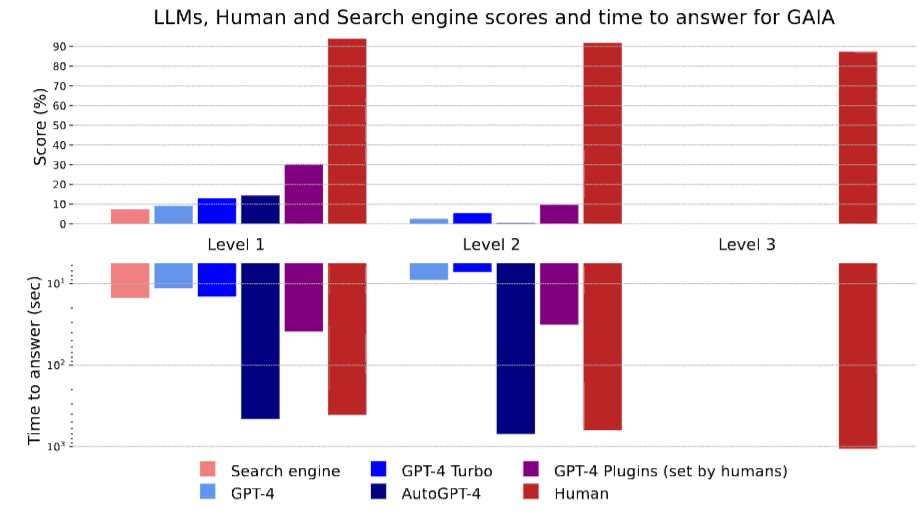
图3
图3:不同方法在 GAIA 三档任务上的得分和答题时间。人类在各级别都保持高分,而当前 LLM 助手在 Level 3 全部为 0。
如果图3给的是直觉冲击,表4则把差距压成了更硬的数字。尤其是 GPT-4 + plugins:即便有人类手动挑插件,Level 2 也只有 9.7%,Level 3 仍然归零。
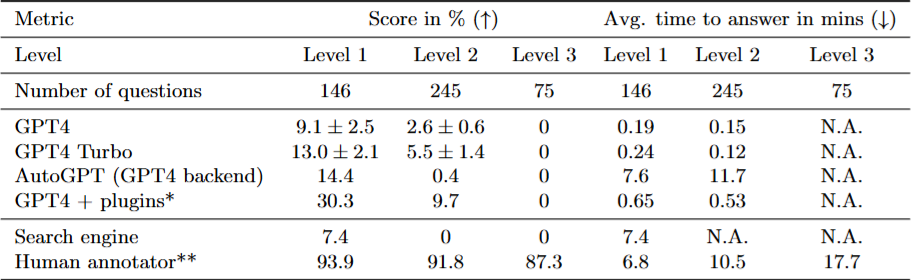
表2
表2:GAIA 各基线详细得分与平均答题时间。GPT-4 + plugins 的结果不能视为完全可复现结果,因为插件由人类按题目手动选择。
更尴尬的是,搜索引擎基线在 Level 1 有 7.4%,Level 2 和 Level 3 都是 0。这说明 GAIA 的答案并不是简单搜一下第一页就能捡到。模型如果只是把搜索当"外接记忆",仍然不够。
它必须会计划。
它必须会纠错。
它必须会在信息不完整时换查询词,在文件格式变化时换工具,在中间结果可疑时回头检查。
论文还观察到,GPT-4 + plugins 确实出现了一些更像助手的行为:比如搜索结果不满意时回溯、改写 query、继续执行更长计划。这说明工具增强方向有潜力。
但潜力不是能力。
一个能在 30% 情况下完成简单任务的助手,还不能放心托付真实工作。
这就是 GAIA 的冷水。
7. GAIA真正测的是"全自动"这件事
把 GAIA 放到更大的技术版图里,它最重要的不是"又出了一个榜单"。
它真正指出的是 partial automation 和 full automation 的鸿沟。
部分自动化很常见。AI 帮你查资料、写草稿、生成代码、整理表格,你在旁边盯着,错了就改。这已经很有用。但全自动化要求完全不同:你把任务交出去,它自己完成,中间不用你扶,最后答案必须对。
这两个世界可能只差几个百分点错误率,却代表完全不同的生产关系。
自动驾驶就是最典型的例子。一个系统 99% 情况下能开,不等于它能在真实道路上无人驾驶。因为那 1% 不是数学上的小尾巴,而是现实里的事故。
通用 AI 助手也是一样。
GAIA 的短答案机制,把这个问题压得很硬:最终答案没有"差不多"。数字错一位,城市名错一个,格式不符合要求,任务就是失败。
这对今天的大模型很不友好。
但对真实世界很诚实。
现实工作不是聊天竞技场。用户要的是发票金额、论文出处、文件里的结论、网页上的最新字段、Excel 里的总和。你不能靠一段听起来很合理的话糊过去。
也正因为如此,GAIA 不只是在测模型。
它也在测整个 Agent 架构:规划、工具选择、网页浏览、文件读取、多模态理解、代码执行、答案格式控制、错误恢复。任何一个环节脆,最后都会体现为一个错答案。
这比单点能力评测残酷得多。
因为系统能力不是各模块分数相加,而是最弱环节决定下限。
8. 局限也明显:GAIA不是通用助手的终局评测
GAIA 很漂亮,但它不是终点。
第一个局限是,它只评最终答案,不评过程轨迹。不同系统可能用不同路径得到正确答案,GAIA 暂时没有简单办法给计划质量、工具调用质量、来源可信度打分。答案对了,不代表过程可审计;答案错了,也不一定知道具体是哪一步坏掉。
第二个局限是,真实网页会变。
GAIA 尽量选择稳定来源,也会指定版本或日期,但只要评测依赖开放世界,就一定面对信息消失、页面更新、robots.txt 限制和数据污染。这也是静态 benchmark 的宿命------它们从发布那天起,就开始慢慢腐烂。
第三个局限是语言和文化覆盖不足。
GAIA 的问题都是标准英语,很多来源也主要来自英语网页。论文自己也承认,这无法验证 AI 助手对非英语用户、非英语互联网和方言变体的有用性。对全球大多数用户来说,这只是第一步。
但这些局限没有削弱它的价值。
恰恰相反,它们提醒我们:真正的通用助手评测,可能必须是动态的、开放的、持续维护的。不是发一个数据集就完事,而是像维护基础设施一样维护评测生态。
GAIA 更像一张路线图。
它告诉我们,未来的评测要从"模型能不能答题"转向"系统能不能办事";从"知识覆盖率"转向"行动可靠性";从"漂亮生成"转向"可验证完成"。
这一步很关键。