人机交互方式演进
命令行交互 -> GUI图形界面交互-> GUI+触摸.声音等 -> 沉浸式

语义交互
智能硬件 :无人机智能家居
汽车: 车载语音智能汽车
个人助理 : 订餐出行
咨询类机器人: 导诊机器人电商客服
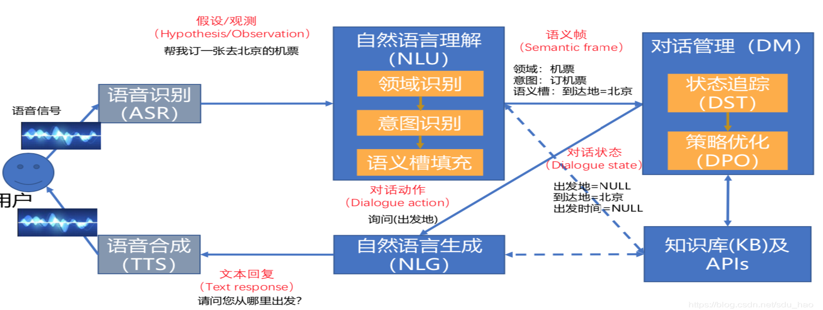
对话系统
|--------|---------------|-----------|---------|
| | 任务型 | 问答型 | 聊天型 |
| 目的 | 完成特定任务 | 回答问题,提供信息 | 闲聊 |
| 领域 | 垂直领域 | 垂直&开放领域 | 开放领域 |
| 以轮数为评价 | 越少越好 | 越少越好 | 越多越好 |
| 应用 | 业务办理,订机票,客户回访 | 客服,培训,搜索等 | 闲聊,情感陪伴 |
以轮数为评价的意思是,类似于游戏的日活,人越喜欢就是互动越频繁
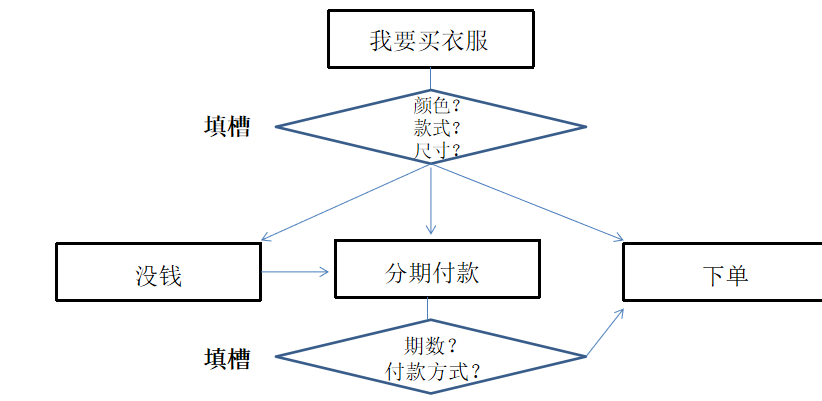
任务型对话
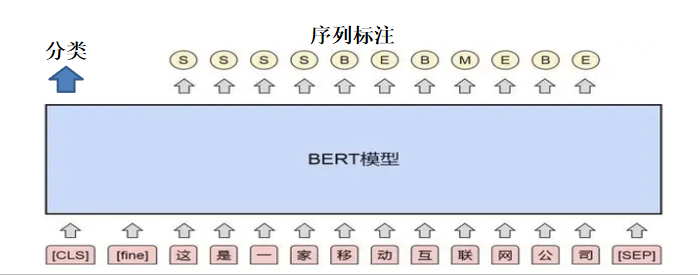
NLU模块
模块分为 领域识别 意图识别 语义槽填充
分类问题 序列标注问题
|----|-------|-----------------|-----------------|
| 领域 | 意图 | 语义槽 | 举例 |
| 火车 | 查询 | 出发地,到达地 | 厦门到福建建阳的火车是几点 |
| 火车 | 预定 | 出发地,到达地,出发时间,车次 | 订一张明天哈尔滨到北京的Z15 |
| 地图 | 路线 | 出发地,到达地 | 南山医院到北大医院路线 |
| 地图 | 位置 | POI | 北京西站在哪 |
| 短信 | 发消息 | 接收人,内容 | 发短信给叶少云晚上要不要出去玩 |
| 短信 | 发生联系人 | 接收人,联系人 | 把哥哥的电话发给殷龙 |其中领域 和 意图 可以理解为分类问题,语义槽可以理解为序列标注问题 分类问题有两种方式:比如上图 一种 就是 直接6分类到意图 第二种就是先进行领域的分类,然后再二分类 这两者方法需要结合业务情况去考虑,如果分类目标很多就是第二种,同时要用上子模型,就是每个领域都有一个子模型迭代优化不影响其他的
联合学习
分类(意图识别) + 序列标注()语义槽填充
类似于知识图谱的封闭式关系抽取
大模型Function Call
LLM做function call 也可以看做一种意图识别+槽位抽取
用户输入: 我想买北京去上海的机票
LLM输出: {'function':'BuyTicket','params':{'departure':'北京','arrival':'上海'}}
不同function本质上为不同意图,参数就是槽位
对话状态跟踪
就是用户有的时候很难一次性把槽位说全,比如帮我订一张去北京的机票,这句话中没有出发地
对话状态中,用户目标的达成状态,是对于对话现状的一种表示
如图上的过程就是对话状态跟踪
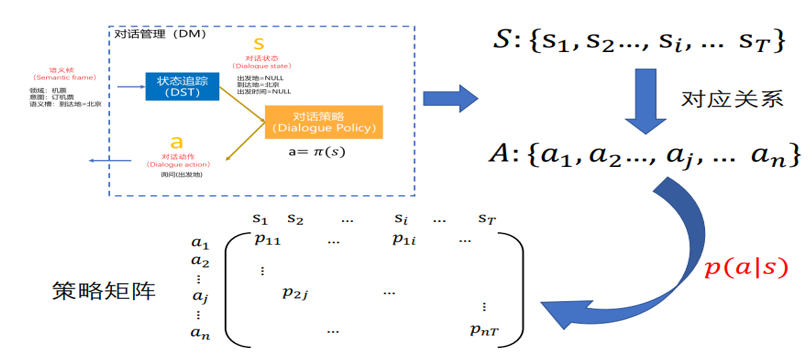
对话策略
根据当前的对话状态决定对话策略
对话策略包括: 反问获取信息,向用户确认,回答
状态->策略
策略矩阵,每种状态选哪种策略


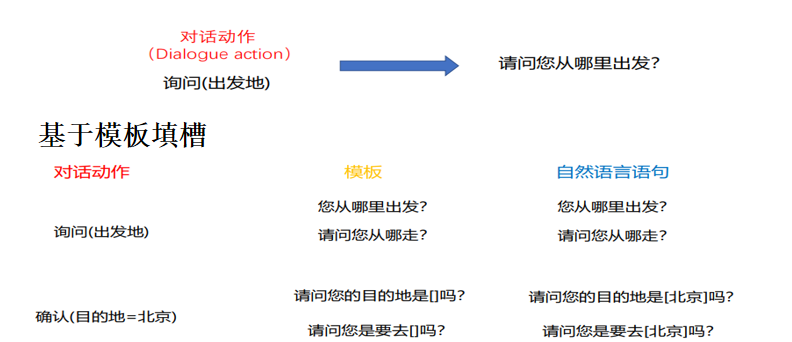
NLG(自然语言生成)
第一种 就是根据大模型,根据槽位的缺失,当成提示词给大模型,然后大模型给出相应的话术
第二种就是 基于模板填槽
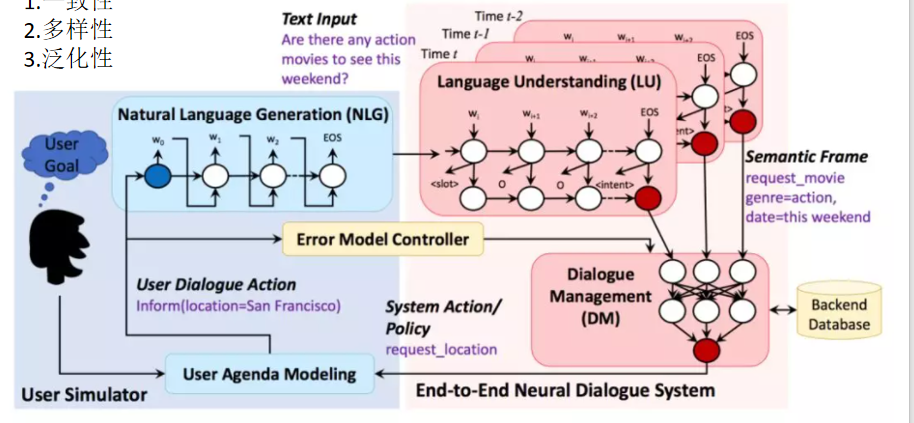
整体框架
常见的评估方式
模型层面: 意图识别准确率,槽填充准确率,模型效率
应用层面: 节点到达率,任务达成率,场景覆盖
功能层面: 新场景迁移效率,跨场景交互能力,人工复杂率
对话模拟器(解决测试的问题,任务型对话普遍是多轮的,用户需要不断补充,这样就导致测试很困难)
在实际工作中,比如修改了系统中的某一点东西,对整体都已潜在的影响,为了能测试完整的功能,于是需要对话模拟器不断发起请求,测试某个功能分支
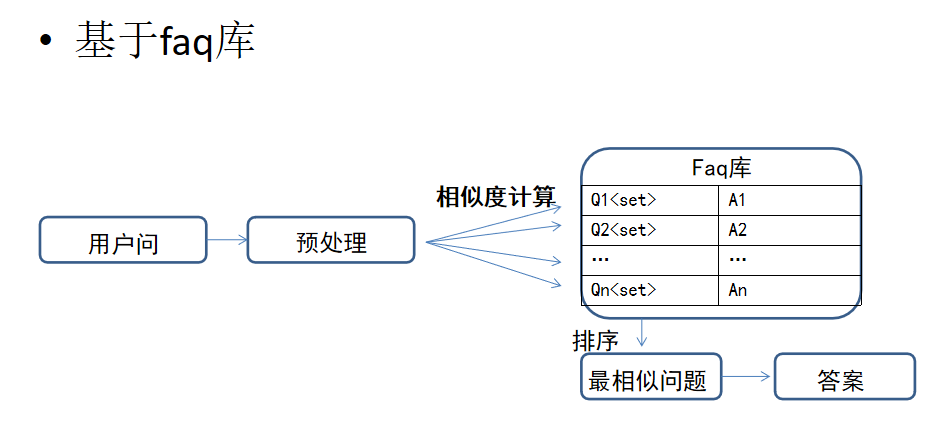
问答型对话机器人
基于faq库
准备很多问答对,然后用户问题来了,做相似度计算找到最相似的,找到就找到答案了,现在也可以用embedding来做,文本转向量的方式
基于知识图谱
nl2sql的方式,同时也可以用大模型来做,给表结构和问题,让大模型做语句,然后执行
基于文档(机器阅读理解) MRC的方法 可以算是RAG的前身
逻辑为由文本片段,答案在文档中这是默认的,然后就会截取片段来作答,这个方法不需要对原始数据加工和处理,前两个,要加工QA,或构建知识图谱


闲聊型对话机器人
- 检索式
类似于faq问答,使用语料库进行匹配
- 生成式
类似于翻译,使用seq2seq模型做文本生成
检索+生成结合
大模型全黑盒处理
LLM多轮对话
常用方式
|---------------------|-------------------------------------|------------------------------------------|
| 常用方式 | 优点 | 缺点 |
| 拼接所有的历史对话,长度不够就进行截断 | 简单直接,完整存储了历史对话记录,对历史对话的理解肯定是对全面的 | token消耗大,内容冗余,超过限制回损失信息 |
| 对历史对话记录总结记录 | 相比直接记录历史对话减少了冗余内容,只抓关键点,大大增强了多轮对话能力 | 摘要效果取决于模型,模型不好可能回大量丢失关键信息且需要额外token去总结摘要 |
| 存储 | 增加记忆数据库,可以存储更多多轮对话的内容,在时间和容量上跨度很大 | 需要构建外部记忆系统,并需要具备对应的检索能力 |
| trunk&retrieval | 综合了上面方法的优点 | 效果取决于检索能力,关键点把握不住会存在语义偏差 |
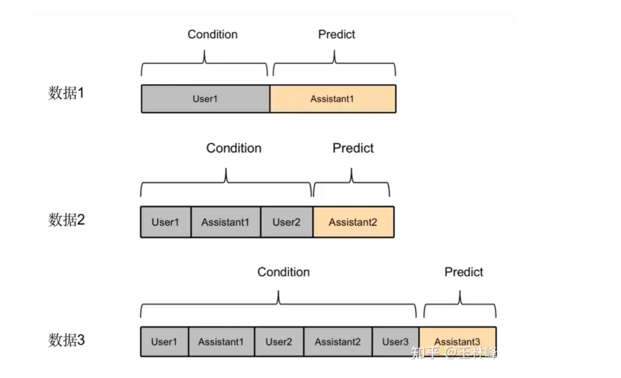
多轮训练方式
User1是我们问的问题,计算Assistant部分loss,然后拼接起来作输入再预测,计算loss
但是这种做法会出现冗余加浪费
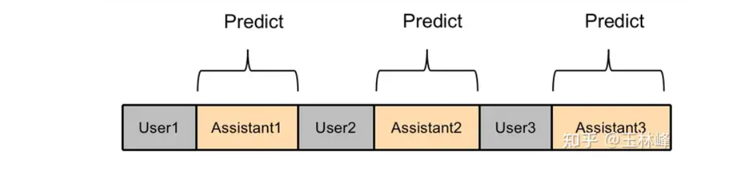
这样做,直接长文本,然后在Assistant计算loss
这里需要mask的设置,如图中的mask设置应该为
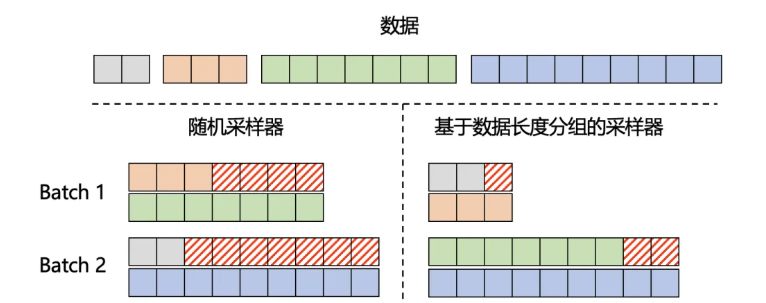
预训练数据时根据长度分组