微信的 sync 协议、Telegram 的 MTProto、WhatsApp 基于 Signal Protocol 的二进制格式------你会发现所有亿级 IM 产品没有一个用 JSON 做传输协议。这不是巧合,而是带宽和延迟的数学题。
IM 系统里每条消息都要在长连接上跑,高频、高并发、高实时。如果你还在用 JSON 做序列化,等于每条消息多扛 60% 的带宽开销、多等 3-5 倍的序列化时间。这篇讲我从 JSON 切到 Protobuf 的完整实战:信封模式设计、字段级二进制优化、chatId 干脆不传了------所有内容基于真实项目源码,直接上代码。
先说结论
一条 C2C 聊天消息,JSON 协议和 Protobuf 协议的体积对比:
bash
JSON 一条消息: ~380 字节
Protobuf 一条消息: ~130 字节
体积缩减: 约 66%这不是我编的数据,这是同一套 IM 系统里同一个 sendTextMessage 跑出来的真实结果。字段一样、内容一样,就是序列化方式不同。
你可能觉得一条消息省 250 字节算什么?算笔账:单节点 10 万连接,每秒 1 万条消息,每条省 250 字节 = 2.5MB/s 带宽节省。一个月下来就是 6.4TB。这不是理论推演,这是带宽账单上的真金白银。
你可能会问:为什么要对每条消息的体积抠到字节级?
因为 IM 系统和普通 HTTP API 不一样------普通 API 一天调几次,IM 消息是高频、持续、永远不停的。用户打开 App 就在线,每秒可能收发几十条消息(群聊场景)。这意味着:
-
带宽成本是线性增长的 :每条消息多 250 字节,10 万用户每秒 1 万条 = 2.5MB/s。一年下来就是 75TB 额外带宽 。云厂商按流量计费,这是真金白银。微信日均消息 1000 亿条,如果每条多 250 字节,一年多花的带宽费是数亿级别。
-
存储成本是复利增长的 :消息不只传一次就没了------它要存 MongoDB(消息记录)、ES(搜索索引)、Redis(重试队列、离线消息)。一份膨胀在传输层,三份膨胀在存储层。 10 亿条消息,每条多 250 字节 = 额外 250GB 存储。加上三份副本和索引膨胀,实际多占 1TB+。
-
内存是实时占用的:Redis 里的离线消息队列(ZSet + Hash)、会话列表(Hash)、未读计数------全是热数据常驻内存。消息体积大 = Redis 内存大 = 服务器贵。第 17 篇会专门讲我如何把 Redis 内存从 1.1GB 压到 575MB,但前提是消息本身够小。
-
移动端电量消耗 :每多传 250 字节 = 多开无线电模块的时间。移动端 IM 最敏感的不是带宽,是电量。微信团队公开分享过:网络请求是手机耗电 Top 3 的元凶。消息体积小 = 传输时间短 = 无线模块早关 = 省电。
-
弱网体验 :在丢包 30% 的移动网络下,一条 380 字节的消息需要分 2-3 个 TCP 包传输,任何一个包丢了都要重传。而 130 字节的消息一个包就搞定。体积小 = 重传概率低 = 消息延迟低。
所以这篇不是"为了优化而优化"------每省一个字节,带宽省钱、存储省钱、内存省钱、用户省电、弱网更快。IM 系统的消息体积优化,是投入产出比最高的优化之一。
一、为什么 IM 不能用 JSON
很多 IM 项目第一版都是 JSON 协议,我的系统也不例外。JSON 作为第一版原型没毛病,但一旦你的消息量上来,三个硬伤就暴露了:
1.1 体积膨胀
JSON 是文本格式,每个字段名、引号、逗号、花括号都是实打实的字节。来看一条 C2C 消息的 JSON 长什么样:
json
{
"url": "/c2c/send",
"body": {
"clientMsgId": "550e8400-e29b-41d4-a716-446655440000",
"msgId": "1988484031183061064",
"from": "1966479049087913984",
"to": "1966369607918948352",
"chatId": "100-1-1966369607918948352-1966479049087913984",
"format": 1,
"content": "你好",
"time": 1729987654321
}
}光字段名就占了 "clientMsgId"(12B)、"chatId"(6B)这些,加上引号和分隔符,一条简单文本消息的 JSON 直奔 380 字节。
而 Protobuf 是二进制格式,字段名在传输时被压缩成 1-2 字节的 field tag(字段编号 + wire type),没有引号、没有花括号、没有冗余的分隔符。
1.2 序列化开销
JSON 序列化要拼字符串、转义特殊字符、处理 Unicode。Protobuf 是直接往字节里写,没有中间过程。实测数据:
| 指标 | JSON (Jackson) | Protobuf | 提升倍数 |
|---|---|---|---|
| 序列化耗时 | ~2.5μs | ~0.5μs | 5x |
| 反序列化耗时 | ~3.8μs | ~0.7μs | 5.4x |
| 消息体积 | ~380B | ~130B | 节省 66% |
以上数据基于同一台机器、同一条消息内容、10万次迭代的平均值。测试代码在项目的
im-common/src/test/下。
每秒几万条消息的场景,JSON 序列化的 CPU 开销就不是"可以忽略"了。
1.3 类型安全缺失
JSON 字段是弱类型的,msgId 传成 string 还是 number 全靠自觉。一旦客户端和服务端理解不一致,bug 排查能让你怀疑人生。Protobuf 是编译时生成强类型代码,字段类型在 .proto 文件里定义死了,不匹配编译都过不了。
我的系统曾经出过一次这种 bug:SDK 把 format 传成了 string "1" 而不是 number 1,服务端解析后消息格式判断错误,图片消息被当文本存了。切到 Protobuf 后这类问题直接被编译器消灭在萌芽里。
所以,结论就是:IM 系统的 WebSocket 长连接上,JSON 根本不该出现在生产环境。
我在服务端代码里直接写死了------收到 TextWebSocketFrame 就断连:
java
// WebSocketServerHandler.java
// JSON 格式已废弃,仅支持 Protobuf 二进制消息
if ((frame instanceof TextWebSocketFrame)) {
log.warn("收到文本消息,但系统已切换为仅支持 Protobuf 二进制格式,请升级客户端");
ctx.close();
return;
}没得商量,要么升级到 Protobuf,要么别连。
二、Protobuf 底层编码原理:为什么它这么小
在讲具体的协议设计之前,有必要先理解 Protobuf 的二进制编码原理。只有搞懂了底层,后面的优化决策你才能知其然也知其所以然。
2.1 Tag-Length-Value(TLV)编码
Protobuf 的核心编码思想是 TLV(Tag-Length-Value)------每个字段由三部分组成:
bash
┌──────────┬──────────┬─────────────────┐
│ Tag │ Length │ Value │
│ (1-2B) │ (varint) │ (字段的值) │
└──────────┴──────────┴─────────────────┘- Tag:由字段编号(field_number)和数据类型(wire_type)打包而成
- Length:只有变长类型(string、bytes、嵌套 message)才有,固定类型(fixed64、int32)不需要
- Value:字段的实际值
Tag 的计算方式:
bash
tag = (field_number << 3) | wire_type比如 C2CSendReq 里 fixed64 msgId = 2,field_number 是 2,wire_type 是 1(64-bit),所以 tag = (2 << 3) | 1 = 0x11,只占 1 个字节。
而 JSON 里 "msgId" 这个字段名是 5 个字节。一个字节的 Tag 替代了五个字节的字段名,这就是体积差距的根源之一。
2.2 Wire Type 一览
Protobuf 定义了 5 种 wire type,决定了 Value 部分怎么编码:
| Wire Type | 含义 | 适用类型 | Value 长度 |
|---|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum | 1-10 字节(变长) |
| 1 | 64-bit | fixed64, sfixed64, double | 固定 8 字节 |
| 2 | Length-delimited | string, bytes, 嵌套 message, repeated | 1+ 字节(有 Length 前缀) |
| 5 | 32-bit | fixed32, sfixed32, float | 固定 4 字节 |
理解 wire type 非常重要------它直接决定了你选什么字段类型。
2.3 Varint 编码:小数字省空间,大数字反而膨胀
Varint 是 Protobuf 里最精妙的编码方式。核心思想:用最少的字节表示一个整数,小数字用少字节,大数字用多字节。
每个字节的最高位(MSB)是"继续位":
- MSB = 1:后面还有字节
- MSB = 0:这是最后一个字节
举个例子,数字 1 只需要 1 个字节:0x01。而数字 300 需要 2 个字节:0xAC 0x02。
但这个特性对雪花 ID 是个陷阱。
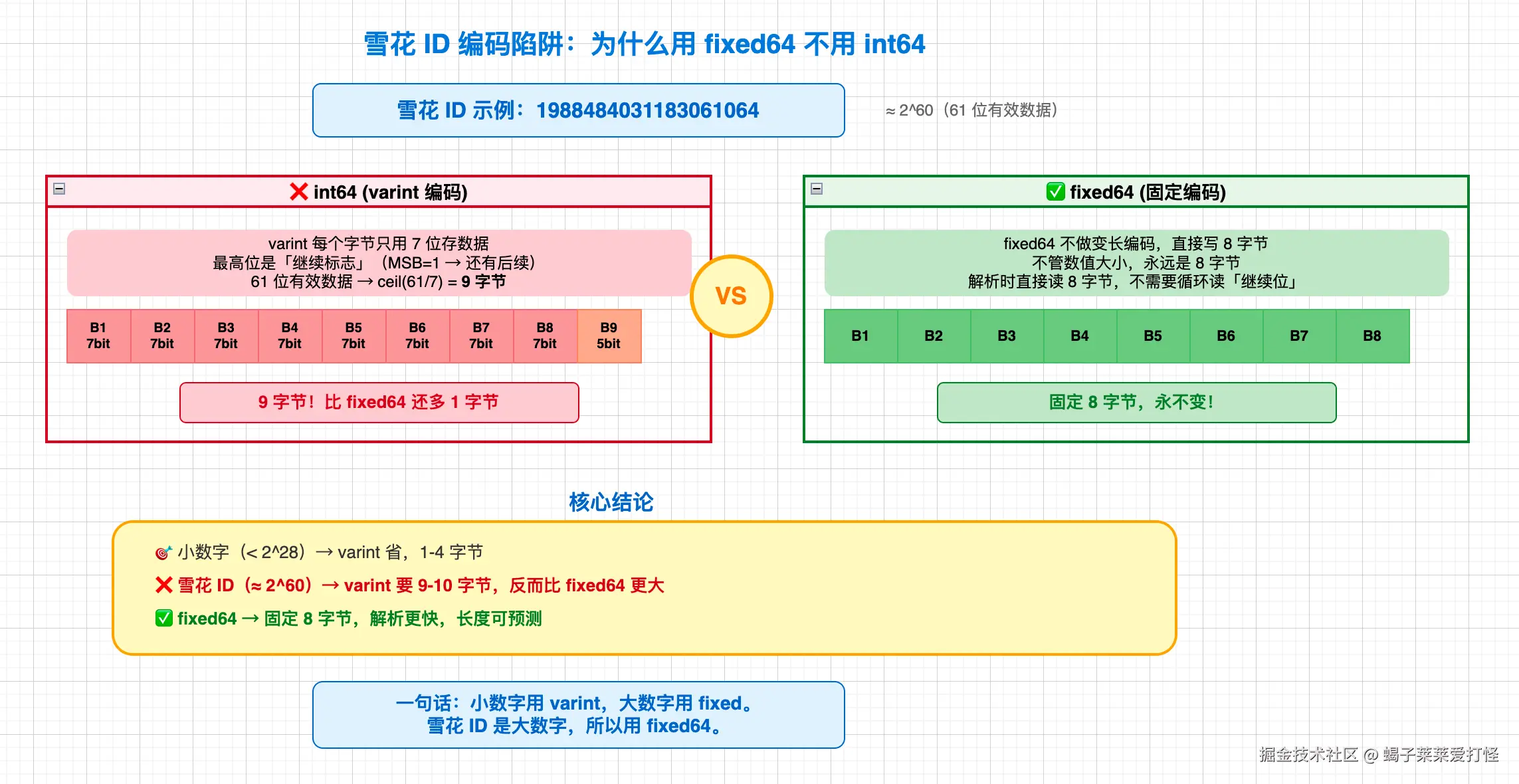
雪花 ID 的值通常在 2^41 到 2^63 之间(时间戳占 41 位 + 机器 ID + 序列号)。以 1988484031183061064 为例,转成二进制需要 61 位。Varint 编码后需要多少字节?
Varint 每个字节只有 7 位有效数据(最高位是继续位)。61 位需要 ceil(61/7) = 9 个字节。如果值更大接近 2^63,就需要 10 个字节。
而我用 fixed64 呢?固定 8 字节,永远不变。
这就是为什么我在协议里把所有雪花 ID 字段都选了 fixed64 而不是 int64------不是为了"固定长度好看",而是因为雪花 ID 的值域让 varint 编码反而比固定编码更浪费空间。
2.4 一条消息在网络上的真实模样
把理论落到实际。一条 "你好" 的 C2C 文本消息,经过 Protobuf 编码后在网络上的字节流长这样:
bash
C2CSendReq 编码(优化后):
┌─────┬──────┬─────────────────────────────────────┐
│ Tag │ Len │ Value │
├─────┼──────┼─────────────────────────────────────┤
│ 0x0A│ 0x10 │ [16字节UUID二进制] │ clientMsgId (bytes)
│ 0x11│ │ [8字节fixed64] │ msgId (fixed64, 无Length)
│ 0x19│ │ [8字节fixed64] │ from (fixed64)
│ 0x21│ │ [8字节fixed64] │ to (fixed64)
│ 0x28│ 0x01 │ [1字节int32] │ format = 1
│ 0x32│ 0x06 │ E4 BD A0 E5 A5 BD │ content = "你好" (UTF-8)
│ 0x39│ │ [8字节fixed64] │ time (fixed64)
└─────┴──────┴─────────────────────────────────────┘
总字节:1+1+16 + 1+8 + 1+8 + 1+8 + 1+1 + 1+1+6 + 1+8 = 62 字节再套上信封 ImProtoRequest:
bash
┌─────┬──────┬──────────────────────┐
│ 0x08│ 0x01 │ type = C2C_SEND │ MsgType enum (varint)
│ 0x12│ 0x3E │ payload = [62字节] │ C2CSendReq 序列化后
└─────┴──────┴──────────────────────┘
信封开销:2 + 2 = 4 字节
总计:4 + 62 = 66 字节等一下,不是说 130 字节吗?因为上面假设 msgId=0(客户端发的),并且没有 reply_info。实际服务端返回的 C2CMsgPush 会带上 msgId 和更多字段,加上信封里的 code 和 msg,总字节数在 120-140 之间浮动。
而 JSON 版本的同样消息是 380 字节。差距就是这么来的------每一个字段的 Tag 替代了字段名,每一个 ID 的 fixed64 替代了 19 字符的字符串,chatId 直接不存在。
三、信封模式:一种协议,管住所有消息
协议设计的第一步不是定义具体消息结构,而是先解决"怎么区分消息类型"的问题。这一步做不好,后面全是乱。
3.1 信封模式设计
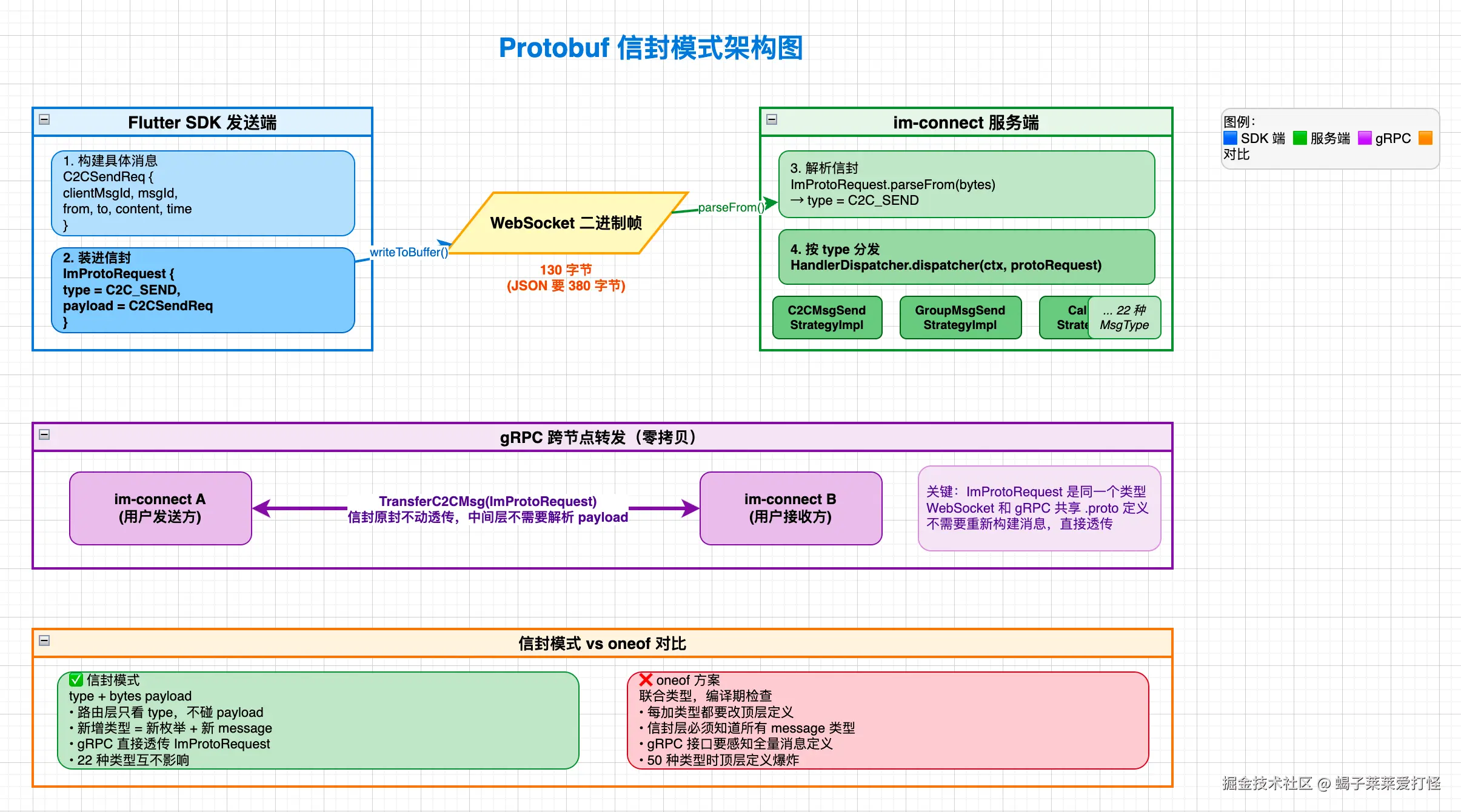
我用了信封模式(Envelope Pattern) ------定义一个通用的"信封",里面装一个 type 字段标识消息类型,一个 payload 字段装具体消息的二进制内容:
protobuf
// 客户端 → 服务端
message ImProtoRequest {
MsgType type = 1; // 消息类型(枚举)
bytes payload = 2; // 具体消息体(根据 type 反序列化)
}
// 服务端 → 客户端
message ImProtoResponse {
MsgType type = 1; // 消息类型
bytes payload = 2; // 具体消息体
int32 code = 3; // 响应码(0=成功)
string msg = 4; // 错误信息(可选)
}这和 HTTP 协议的设计思路一模一样------HTTP 也是一条连接上跑多种请求(GET、POST、PUT),靠 method 字段区分。IM 也一样:一条 WebSocket 长连接上跑 22 种消息,靠 MsgType 枚举区分。
MsgType 是枚举,覆盖了系统里所有消息类型:
protobuf
enum MsgType {
MSG_TYPE_UNKNOWN = 0;
// 单聊
C2C_SEND = 1; // 发消息(上行)
C2C_ACK = 2; // 消息确认(上行/下行)
C2C_WITHDRAW = 3; // 撤回(上行/下行)
C2C_MSG_PUSH = 5; // 服务端推送消息(下行)
// 群聊
GROUP_SEND = 7;
GROUP_MSG_PUSH = 8;
GROUP_ACK = 9;
GROUP_WITHDRAW = 10;
// 好友
FRIEND_REQUEST = 11;
FRIEND_RESPONSE = 12;
// 已读回执
READ_RECEIPT = 14;
READ_RECEIPT_PUSH = 15;
// 输入状态
TYPING_STATUS = 16;
TYPING_STATUS_PUSH = 17;
// 音视频通话信令
CALL_OFFER = 20;
CALL_PUSH = 21;
CALL_ANSWER = 22;
CALL_REJECT = 23;
CALL_END = 24;
}22 个消息类型,覆盖了单聊、群聊、好友、已读回执、输入状态、音视频通话------全部走这一套信封协议。
3.2 为什么不用 Protobuf 的 oneof
Protobuf 本身提供了 oneof 关键字,可以实现类似的多态消息:
protobuf
// 方案 B:用 oneof 实现
message ImProtoRequest {
oneof payload {
C2CSendReq c2c_send = 1;
C2CAckReq c2c_ack = 2;
GroupSendReq group_send = 7;
CallOfferReq call_offer = 20;
// ... 22 个类型要列 22 个字段
}
}我评估过这个方案,最终没选它,原因有三:
-
扩展性差 :每新增一个消息类型,都要改这个顶层
oneof定义。22 个字段已经够多了,将来加到 40、50 个?信封模式只需要加一个枚举值 + 一个独立 message,互不影响。 -
信封模式解耦更彻底 :
type字段是纯路由信息,payload是纯业务数据。信封层(WebSocket Handler)只看type做分发,完全不碰payload。用oneof的话,信封层必须知道所有 message 类型才能解析,每一层都耦合了全量消息定义。 -
gRPC 复用 :我的 proto 文件同时定义了 WebSocket 信封和 gRPC 服务接口。gRPC 的
TransferC2CMsg方法直接接收ImProtoRequest做跨节点转发,信封模式让 gRPC 只需要透传type + payload,不需要关心内部是哪种消息。如果用oneof,gRPC 接口也得感知所有 message 类型。
信封模式 = 解耦。路由层只看信封,业务层只看 payload。IM 系统的消息类型会持续增长,解耦做得好,后面加功能才不会越改越乱。
3.3 为什么不用 JSON 里的 url 做路由
我早期 JSON 协议是这样设计的:
json
{
"url": "/c2c/send",
"body": { ... }
}用 url 字段做路由,类似 HTTP REST 风格。但 IM 不是 HTTP,每条消息都是长连接上的二进制帧,用字符串 URL 做路由有两个问题:
- 浪费空间 :
"/c2c/send"这个字符串每条消息都要传,11 个字节 - 路由效率低:字符串比较比枚举值判断慢得多
换成 MsgType 枚举后,一个 varint(1-2 字节)就够了,服务端用 switch 直接分发,O(1) 时间复杂度。
3.4 信封模式的编解码流程
SDK 端(Flutter)发送一条消息:
dart
// xzll_im_client.dart - sendTextMessage()
// 1. 构建具体消息
final sendReq = C2CSendReq(
clientMsgId: ProtoConverterUtil.uuidStringToBytes(effectiveClientMsgId),
msgId: Int64.ZERO,
from: ProtoConverterUtil.snowflakeStringToInt64(_currentUserId),
to: ProtoConverterUtil.snowflakeStringToInt64(toUserId),
format: 1,
content: content,
time: Int64(effectiveTimestamp.millisecondsSinceEpoch),
);
// 2. 包装为信封
final protoRequest = ImProtoRequest(
type: MsgType.C2C_SEND,
payload: sendReq.writeToBuffer(),
);
// 3. 序列化并发送
final bytes = protoRequest.writeToBuffer();
_channel?.sink.add(bytes);三步走:构建具体消息 → 装进信封 → 序列化为二进制。所有消息类型都走这一套流程,SDK 里的 15 个发送方法(文本、图片、语音、群聊、ACK、撤回、已读、通话信令......)全是一样的模式。
服务端解码:
java
// WebSocketServerHandler.java
ByteBuf content = ((BinaryWebSocketFrame) frame).content();
byte[] bytes = new byte[content.readableBytes()];
content.getBytes(content.readerIndex(), bytes);
// 一步解析信封
ImProtoRequest protoRequest = ImProtoRequest.parseFrom(bytes);
// 按 type 分发
handlerDispatcher.dispatcher(ctx, protoRequest);服务端的 HandlerDispatcher 维护了一个 Map<MsgType, ProtoMsgHandlerStrategy>,Spring 启动时自动发现所有策略实现类并注册:
java
// HandlerDispatcher.java
public void dispatcher(ChannelHandlerContext ctx, ImProtoRequest protoRequest) {
ProtoMsgHandlerStrategy handler = strategyMap.get(protoRequest.getType());
if (handler != null) {
handler.exchange(ctx, protoRequest);
}
}每个 MsgType 对应一个策略实现类,比如 C2C_SEND 对应 C2CMsgSendProtoStrategyImpl,GROUP_SEND 对应 GroupMsgSendProtoStrategyImpl,CALL_OFFER 对应 CallOfferProtoStrategyImpl。策略类从 payload 里解析出具体消息,各管各的业务逻辑。
这就是 信封模式 + 策略模式 的组合拳:协议层只管拆信封,业务层各自处理自己的消息类型,互不干扰。
3.5 同一个 Proto 文件,两种通信方式
我的 message_service.proto 里不仅定义了 WebSocket 消息结构,还定义了 gRPC 服务接口:
protobuf
// 消息转发服务(gRPC - 服务间调用)
service MessageService {
rpc TransferC2CMsg (ImProtoRequest) returns (WebBaseResponse) {}
rpc ResponseServerAck2Client (ServerAckPush) returns (WebBaseResponse) {}
rpc PushFriendRequest2Client (FriendRequestPush) returns (WebBaseResponse) {}
// ...
}这是很多人的盲区------同一个 .proto 文件可以同时生成 WebSocket 消息类和 gRPC Stub。
在我的架构里,这两种通信方式各有分工:
| 通信方式 | 用途 | 场景 |
|---|---|---|
| WebSocket + Protobuf | 客户端 ↔ 服务端 | 用户发消息、收推送、通话信令 |
| gRPC + Protobuf | 服务端 ↔ 服务端 | 跨节点消息转发、ACK 同步 |
关键设计:TransferC2CMsg 的参数类型就是 ImProtoRequest------和客户端发过来的 WebSocket 消息是同一个信封类型 。这意味着当节点 A 收到用户消息、发现目标用户在节点 B 时,不需要重新构建消息,直接把 ImProtoRequest 原封不动通过 gRPC 转发给节点 B。
java
// MessageServiceGrpcImpl.java
// 节点 A 收到消息,发现目标用户在节点 B,直接转发 ImProtoRequest
@Override
public void transferC2CMsg(ImProtoRequest request, StreamObserver<WebBaseResponse> responseObserver) {
// request 就是客户端发来的同一个 ImProtoRequest
// 不需要解析 payload,直接透传给 HandlerDispatcher
handlerDispatcher.receiveAndSendMsg(request);
responseObserver.onNext(WebBaseResponse.newBuilder().setCode(1).build());
responseObserver.onCompleted();
}零拷贝式转发------信封模式的另一个好处:中间层不需要理解内部消息结构,只做透传。协议越往后演进,这个好处越明显。
四、信封模式 vs 其他方案的设计决策
信封模式不是唯一的方案。在确定用信封模式之前,我对比过三种方案:
| 方案 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 信封模式 | type + bytes payload |
解耦彻底,扩展性强 | 需要两步反序列化 |
| Protobuf oneof | 联合类型,编译期检查 | 类型安全,一步解析 | 扩展要改顶层定义,gRPC 难复用 |
| 多 WebSocket 连接 | 每种消息类型一条连接 | 隔离性好 | 资源浪费严重,移动端扛不住 |
移动端 IM 最忌讳多连接------每多一条 WebSocket,心跳流量翻倍、电量消耗翻倍、NAT 映射表翻倍。信封模式用一条连接跑所有消息类型,是最经济的选择。
至于"两步反序列化"的顾虑------实际测试下来,拆信封(解析 ImProtoRequest)和拆 payload(解析 C2CSendReq)加在一起也就 1μs 出头,在 Netty 的业务线程池里执行,对延迟毫无影响。
五、字段级优化:每一字节都是抠出来的
信封模式解决的是架构层面的问题,这一节讲具体的字段优化------这才是消息体积砍掉 60% 的核心。
5.1 优化前的 C2C 消息(JSON)
回顾一下早期 JSON 协议里的字段:
| 字段 | JSON 值示例 | 占用字节 |
|---|---|---|
| clientMsgId | "550e8400-e29b-41d4-a716-446655440000" |
36 + 2(引号) = 38B |
| msgId | "1988484031183061064" |
19 + 2 = 21B |
| from | "1966479049087913984" |
19 + 2 = 21B |
| to | "1966369607918948352" |
19 + 2 = 21B |
| chatId | "100-1-1966369607918948352-1966479049087913984" |
31 + 2 = 33B |
| content | "你好" |
6 + 2 = 8B |
| format | 1 |
1B |
| time | 1729987654321 |
13B |
| 字段名合计 | "clientMsgId"等 |
~56B |
| JSON 结构符号 | {} : , "" |
~30B |
一个简单文本消息,光结构开销和 ID 字段就占了 240+ 字节,实际有效内容就 6 字节的"你好"。
5.2 优化后的 C2C 消息(Protobuf)
先看 .proto 定义:
protobuf
// C2C发送消息请求 - 上行(优化版)
message C2CSendReq {
bytes clientMsgId = 1; // UUID 16字节(优化:string 36B -> bytes 16B)
fixed64 msgId = 2; // 雪花算法(优化:string 19B -> fixed64 8B)
fixed64 from = 3; // 发送人ID(优化:string 19B -> fixed64 8B)
fixed64 to = 4; // 接收人ID(优化:string 19B -> fixed64 8B)
int32 format = 5; // 消息格式
string content = 6; // 消息内容
fixed64 time = 7; // 时间戳(优化:int64 -> fixed64)
// chatId 已删除!服务端/客户端根据 from + to 动态拼接(节省 33 字节)
optional ReplyInfo reply_info = 10; // 引用回复(可选)
}proto 文件里的注释就是我优化时写的笔记,每个字段的优化思路都标得很清楚。下面逐个拆解。
5.3 优化一:string → bytes --- clientMsgId 从 36B 压到 16B
UUID 在 Java/Dart 里默认是 36 字符的字符串格式:550e8400-e29b-41d4-a716-446655440000。8-4-4-4-12 的格式里有 4 个连字符,纯装饰品,没有任何信息量。
UUID 的本质是 128 位整数,拆成两个 long(高位 + 低位)就是 16 字节。所以我把 clientMsgId 从 string 改成了 bytes:
protobuf
bytes clientMsgId = 1; // 16字节,不再是36字符的字符串SDK 端转换(Dart):
dart
// proto_converter_util.dart
/// UUID字符串 → 16字节(用于Protobuf传输)
static Uint8List uuidStringToBytes(String uuidString) {
// 去掉连字符,解析为16字节
final hex = uuidString.replaceAll('-', '');
final bytes = Uint8List(16);
for (int i = 0; i < 16; i++) {
bytes[i] = int.parse(hex.substring(i * 2, i * 2 + 2), radix: 16);
}
return bytes;
}
/// 16字节 → UUID字符串(接收时还原)
static String bytesToUuidString(List<int> bytes) {
return '${_hex(bytes.sublist(0, 4))}-${_hex(bytes.sublist(4, 6))}-'
'${_hex(bytes.sublist(6, 8))}-${_hex(bytes.sublist(8, 10))}-'
'${_hex(bytes.sublist(10, 16))}';
}服务端转换(Java):
java
// ProtoConverterUtil.java
// UUID字符串 → 16字节 ByteString
public static ByteString uuidStringToBytes(String uuidStr) {
UUID uuid = UUID.fromString(uuidStr);
ByteBuffer bb = ByteBuffer.wrap(new byte[16]);
bb.putLong(uuid.getMostSignificantBits());
bb.putLong(uuid.getLeastSignificantBits());
return ByteString.copyFrom(bb.array());
}
// 16字节 ByteString → UUID字符串
public static String bytesToUuidString(ByteString bytes) {
ByteBuffer bb = ByteBuffer.wrap(bytes.toByteArray());
long mostSigBits = bb.getLong();
long leastSigBits = bb.getLong();
return new UUID(mostSigBits, leastSigBits).toString();
}节省:36B → 16B,一条消息省 20 字节。
5.4 优化二:string → fixed64 --- msgId/from/to 从 19B 压到 8B
雪花算法生成的 ID 是 19 位数字字符串,比如 1988484031183061064。但它的本质是一个 64 位整数,完全可以用 fixed64(固定 8 字节)来传输:
protobuf
fixed64 msgId = 2; // 8字节,不再是19字符的字符串
fixed64 from = 3; // 同上
fixed64 to = 4; // 同上为什么用 fixed64 而不是 int64?这涉及 Protobuf 的 varint 编码原理。
int64 用 varint 编码------每个字节只用 7 位存数据,最高位是"继续标志"。数值越小,编码越短。但雪花 ID 是 19 位十进制数(约 2^60),varint 编码需要 9-10 个字节 。而 fixed64 是固定 8 字节,永远不变。
来算一笔账:
bash
雪花 ID: 1988484031183061064
int64 (varint): 需要 9 个字节 (61位有效数据, ceil(61/7)=9)
fixed64: 需要 8 个字节 (固定)
每个 ID 省 1 字节,一条 C2C 消息有 4 个 ID (msgId + from + to + time):
4 × 1 = 4 字节额外节省而且 fixed64 还有两个额外优势:
- 解析更快:固定长度不需要循环读取 varint 的"继续位",直接读 8 字节
- 长度可预测:对内存分配和缓存友好,不会因为数值变化导致消息长度波动
一句话:小数字用 varint,大数字用 fixed。雪花 ID 是大数字,所以用 fixed64。
服务端转换:
java
// ProtoConverterUtil.java
public static long snowflakeStringToLong(String snowflakeIdStr) {
return Long.parseLong(snowflakeIdStr);
}
public static String longToSnowflakeString(long snowflakeId) {
return String.valueOf(snowflakeId);
}简单到不需要解释------就是字符串和数值的互转。
节省:每个 ID 从 19B → 8B,一条 C2C 消息里至少有 3 个 ID(msgId + from + to),省 33 字节。
5.5 优化三:chatId 直接砍掉------不传了
这是最有意思的一个优化。chatId 是会话 ID,格式 100-1-1966369607918948352-1966479049087913984,31 字节。
早期 JSON 协议里,每条消息都要带上 chatId,因为后端路由需要它。但仔细想想------chatId 是可以从 from 和 to 动态计算出来的!
规则很简单:
- 把两个用户 ID 比大小,小的在前大的在后
- 拼接格式:
{bizType}-{chatType}-{smallUserId}-{bigUserId}
java
// ChatIdUtils.java
public static String buildC2CChatId(Integer bizType, Long fromUserId, Long toUserId) {
Long smallUserId, bigUserId;
if (fromUserId < toUserId) {
smallUserId = fromUserId;
bigUserId = toUserId;
} else {
smallUserId = toUserId;
bigUserId = fromUserId;
}
return String.format("%d-%s-%d-%d", bizType, "1", smallUserId, bigUserId);
}SDK 端同样的逻辑:
dart
// chat_id_utils.dart
static String generateC2CChatId(String userId1, String userId2) {
int userId1Int = int.parse(userId1);
int userId2Int = int.parse(userId2);
String smallUserId = userId1Int < userId2Int ? userId1 : userId2;
String bigUserId = userId1Int < userId2Int ? userId2 : userId1;
return '$bizTypeIM-$chatTypeC2C-$smallUserId-$bigUserId';
}关键点:小 ID 在前。不管 A 给 B 发还是 B 给 A 发,算出来的 chatId 一定一样。这样客户端和服务端各算各的,不需要在网络上传。
proto 文件里的注释写得很直接:
protobuf
// chatId 已删除!服务端/客户端根据 from + to 动态拼接(节省 31+2=33 字节)31+2 是因为 Protobuf 里 string 字段还需要额外 1-2 字节存长度。
节省:一条消息省 33 字节,而且服务端不需要做 chatId 的合法性校验了------因为是根据 from/to 算出来的,天然一致。
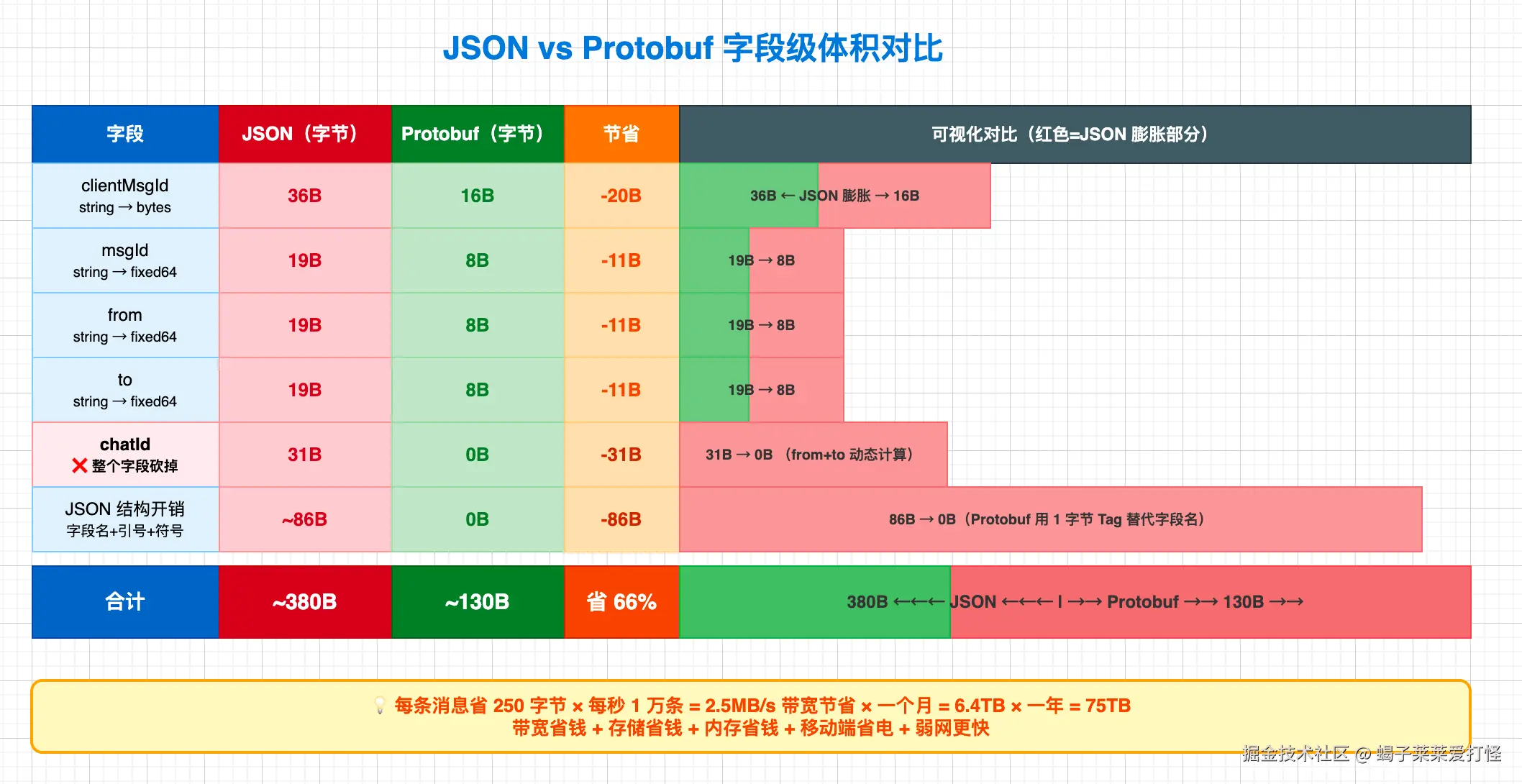
5.6 优化汇总
把上面三项优化放在一起算一笔账:
| 优化项 | 原始(JSON) | 优化后(Protobuf) | 节省 |
|---|---|---|---|
| clientMsgId: string → bytes | 36B | 16B | 20B |
| msgId: string → fixed64 | 19B | 8B | 11B |
| from: string → fixed64 | 19B | 8B | 11B |
| to: string → fixed64 | 19B | 8B | 11B |
| chatId: 整个字段砍掉 | 31B | 0B | 31B |
| time: string → fixed64 | 13B | 8B | 5B |
| JSON 结构开销(字段名+符号) | ~86B | 0B | 86B |
| 合计 | ~380B | ~130B | ~250B(66%) |
这就是为什么标题说"消息体积砍掉 60%"。一条消息省 250 字节,每秒 1 万条消息就是 2.5MB/s 的带宽节省,一个月下来就是 6.5TB。

六、所有消息类型的一览
到目前为止只讲了 C2C 发送消息(C2CSendReq),但协议设计要覆盖整个 IM 系统的消息交互。完整的 .proto 文件定义了 25+ 个 message 类型:
6.1 单聊消息
| 消息类型 | 用途 | 关键字段 |
|---|---|---|
C2CSendReq |
发送消息(上行) | clientMsgId, msgId, from, to, content |
C2CMsgPush |
推送消息(下行) | 同上,time 为服务端时间 |
C2CAckReq |
消息确认(上行/下行) | clientMsgId, msgId, status |
C2CWithdrawReq |
撤回消息(上行) | msgId, from, to |
ServerAckPush |
服务端ACK推送(下行) | clientMsgId, msgId, receiveTime |
ClientAckPush |
客户端ACK推送(下行) | clientMsgId, msgId, status |
上下行命名约定:XxxReq 表示上行(客户端→服务端),XxxPush 表示下行(服务端→客户端)。一眼就知道消息的流向。
6.2 群聊消息
| 消息类型 | 用途 |
|---|---|
GroupSendReq |
发送群消息(上行) |
GroupMsgPush |
推送群消息(下行) |
GroupAckReq |
群消息确认(上行) |
GroupWithdrawReq |
群消息撤回(上行) |
群消息多了 groupId、fromNickname、fromAvatar(群聊显示用)、atUserIds(@成员列表)等字段。
6.3 音视频通话信令
| 消息类型 | 用途 |
|---|---|
CallOfferReq |
发起通话(上行) |
CallPush |
推送通话邀请(下行) |
CallAnswerReq |
接听通话 |
CallRejectReq |
拒接通话 |
CallEndReq |
结束通话 |
通话信令直接复用 WebSocket 长连接,不需要单独的信令服务器。roomName 字段传 LiveKit 的房间名,接听后双方加入同一个房间就完事了。
6.4 其他消息
| 消息类型 | 用途 |
|---|---|
FriendRequestPush |
好友请求推送 |
FriendResponsePush |
好友响应推送 |
ReadReceiptReq/Push |
已读回执 |
TypingStatusReq/Push |
输入状态 |
ReplyInfo |
引用回复信息 |
22 个 MsgType,25+ 个 message 类型,1 个信封协议 。所有消息统一走 ImProtoRequest / ImProtoResponse 二进制帧传输,协议扩展只需要:加一个枚举值 + 定义一个 message + 写一个策略实现类。
6.5 业界 IM 协议方案对比
Protobuf 不是唯一选择。来看看主流 IM 系统用什么协议:
| 系统 | 序列化协议 | 传输协议 | 备注 |
|---|---|---|---|
| Protobuf | Noise Protocol + 自定义帧 | 端到端加密,Protobuf 做 payload 编码 | |
| Signal | Protobuf | WebSocket + Noise | 开源方案,Protobuf 定义全部消息结构 |
| 微信 | 自定义二进制协议 | 长连接 + MMTLS | 不用 Protobuf,自己设计了更极致的压缩方案 |
| Telegram | TL (Type Language) | 自定义二进制 | 自研序列化方案,类似 Protobuf 思路 |
| Discord | Protobuf | WebSocket + gRPC | 和我的架构最接近 |
| 钉钉 | Protobuf | WebSocket | 阿里系 IM 标配 |
几个规律:
- 没有一家大规模 IM 用 JSON 做长连接协议------微信、WhatsApp、Telegram、Signal,全部是二进制协议
- Protobuf 是主流选择------WhatsApp、Signal、Discord、钉钉都用 Protobuf
- 微信和 Telegram 自研协议------它们体量大到 Protobuf 的开销都不满意,自己设计了更极致的方案。但它们的思路和 Protobuf 本质一样:TLV 编码 + 二进制传输
- 信封模式是通用范式------WhatsApp 的消息也是"信封 + 密文 payload"结构,Signal 也是
我的系统选择 Protobuf 不是跟风,而是 IM 领域的工程共识:JSON 适合 HTTP API,二进制协议适合长连接高频场景。微信不用 Protobuf 不是因为 Protobuf 不好,而是因为微信的体量需要更极致的优化。对于 99% 的 IM 系统来说,Protobuf 就是最佳选择。
七、SDK 端的消息收发实现
协议设计得再好,SDK 端不好用也白搭。来看看 Flutter SDK 里是怎么使用这套协议的。
7.1 发送消息
所有发送方法都遵循同一个模式------构建具体消息 → 装信封 → 序列化 → 发送。以文本消息为例:
dart
// xzll_im_client.dart
// 构建具体消息
final sendReq = C2CSendReq(
clientMsgId: ProtoConverterUtil.uuidStringToBytes(effectiveClientMsgId),
msgId: Int64.ZERO, // msgId 由服务端生成,客户端传 0
from: ProtoConverterUtil.snowflakeStringToInt64(_currentUserId),
to: ProtoConverterUtil.snowflakeStringToInt64(toUserId),
format: 1,
content: content,
time: Int64(effectiveTimestamp.millisecondsSinceEpoch),
);
// 装信封
final protoRequest = ImProtoRequest(
type: MsgType.C2C_SEND,
payload: sendReq.writeToBuffer(),
);
// 序列化并发送
_channel?.sink.add(protoRequest.writeToBuffer());注意几点:
clientMsgId由 SDK 生成 UUID,转成 16 字节 bytes 传输msgId传Int64.ZERO,由服务端的雪花算法生成from和to是雪花 ID 字符串,转成Int64(对应 proto 的fixed64)
SDK 里 15 个发送方法------群聊、ACK、撤回、已读、通话信令------全部是同样的模式,区别只在于 MsgType 和具体 message 类型。
7.2 接收消息
SDK 的 _onMessage 是消息接收的核心分发器:
dart
void _onMessage(dynamic message) {
if (message is! Uint8List && message is! List<int>) return;
// 1. 拆信封
final protoResponse = ImProtoResponse.fromBuffer(bytes);
// 2. 按 type 分发
switch (protoResponse.type) {
case MsgType.C2C_MSG_PUSH:
_handlePushMsg(protoResponse); // 收到新消息
case MsgType.C2C_SEND:
_handleAckMessage(protoResponse); // 发送ACK
case MsgType.C2C_WITHDRAW:
_handleWithdrawMessage(protoResponse);
case MsgType.GROUP_MSG_PUSH:
_handleGroupPushMsg(protoResponse);
case MsgType.CALL_PUSH:
_handleCallSignaling(protoResponse);
// ... 其他类型
}
}收到推送消息后,解析具体 payload 并还原业务数据:
dart
void _handlePushMsg(ImProtoResponse protoResponse) {
// 解析具体消息
final pushMsg = C2CMsgPush.fromBuffer(protoResponse.payload);
// 还原业务字段
final clientMsgId = ProtoConverterUtil.bytesToUuidString(pushMsg.clientMsgId);
final msgId = ProtoConverterUtil.int64ToSnowflakeString(pushMsg.msgId);
final fromUserId = ProtoConverterUtil.int64ToSnowflakeString(pushMsg.from);
final toUserId = ProtoConverterUtil.int64ToSnowflakeString(pushMsg.to);
// 动态计算 chatId(不传,本地算)
final chatId = ChatIdUtils.generateC2CChatId(fromUserId, toUserId);
// 构建业务对象,通知 UI
// ...
}7.3 ProtoConverterUtil ------ 类型转换桥梁
SDK 和服务端各有一套 ProtoConverterUtil,负责业务层的 String 类型和 Protobuf 二进制类型之间的转换:
| 转换 | 业务层类型 | Proto 类型 | 方法 |
|---|---|---|---|
| UUID | String (36B) | bytes (16B) | uuidStringToBytes / bytesToUuidString |
| 雪花 ID | String (19B) | fixed64 (8B) | snowflakeStringToInt64 / int64ToSnowflakeString |
| 内容 | String | bytes (UTF-8) | contentStringToBytes / bytesToContentString |
这套转换工具是业务代码和 Protobuf 协议之间的桥梁。业务层继续用 String,到了传输层才转成二进制。各层职责清晰,互不污染。
八、Proto 文件的管理和三端同步
Protobuf 的 .proto 文件是整个协议的"源头"。我的项目里有两个 .proto 文件:
- 服务端 :
im-common/src/main/proto/message_service.proto - 客户端 :
xzll-im-flutter-client/protos/im_message.proto
两个文件内容几乎完全一致(服务端多一两个群聊字段),但必须手动保持同步。这是我在开发过程中踩过的一个大坑。
8.0 向后兼容:Protobuf 的隐藏超能力
在讲踩坑之前,先说一个 Protobuf 相比 JSON 的根本优势------天生向后兼容。
Protobuf 的编码是按字段编号来的,不是按字段名来的。这意味着:
- 新增字段:老客户端不认识新字段编号,直接跳过(unknown fields 机制)。服务端升级、客户端不升级,不会出问题。
- 删除字段:只要不重用编号,老服务端不认识新客户端多出来的字段,同样直接跳过。
- 字段类型升级 :
int32 → int64、string → bytes,在兼容的 wire type 范围内可以平滑升级。
这就是为什么 Protobuf 的铁律是"编号不能改、不能复用"------编号是协议兼容性的根基。只要编号不变,你可以随意增删字段、调整字段名称(名称根本不参与编码),老客户端和新服务端永远能正常通信。
JSON 没有这个能力。JSON 的兼容性完全靠字段名,加一个字段名、改一个字段名、改一个字段类型,都可能导致老客户端解析异常。你需要额外的版本号、迁移逻辑、兜底处理------这些在 Protobuf 里全部由编码层自动解决了。
这也是为什么 gRPC 选了 Protobuf 作为默认序列化方案。 Google 内部数万个微服务,每天都在做协议演进,如果没有这种天然的向后兼容,根本无法管理。
8.1 踩坑:字段编号改了,直接炸了
Protobuf 有一个铁律:字段编号一旦发布,永远不能改。
bash
// ❌ 错误做法:重新排列编号
message C2CSendReq {
bytes clientMsgId = 1;
fixed64 from = 2; // 原来是 msgId=2,现在换成了 from
fixed64 msgId = 3; // from 变成了 3
}
// ✅ 正确做法:新字段用新编号,老字段永远不动
message C2CSendReq {
bytes clientMsgId = 1;
fixed64 msgId = 2;
fixed64 from = 3;
fixed64 to = 4;
// 新加的字段用 10、11、12...
optional ReplyInfo reply_info = 10;
}你会注意到我的 C2CSendReq 里字段编号是 1-7,然后直接跳到了 10。中间 8、9 是曾经用过的编号,后来删了字段但编号不用了------宁可空着也不能复用。
有一次我在调整编号的时候,服务端先部署了新版,客户端还是老版。结果客户端发的 msgId 被服务端解析成了 from,消息全部发错人了。测试环境排查了半天才发现是字段编号改了,回滚服务端才恢复。
从那以后我定了一个规矩:
.proto文件变更必须同时改服务端和客户端两个文件- 字段编号永远不复用、不重排
- 新字段用新编号,老字段标记
deprecated但不删编号 - 先部署服务端,再升级客户端(服务端向下兼容)
8.2 optional vs singular 的区别
Proto3 里所有字段默认是 singular(可省略,但不能区分"未设置"和"默认值")。optional 关键字在 Proto3 里会生成一个 hasXxx() 方法,可以明确判断字段是否被设置。
我的协议里只有 reply_info(引用回复)、at_all(@所有人)等少数字段用了 optional,因为需要区分"没有引用回复"和"引用回复为空"。
大部分字段用默认的 singular 就够了------msgId 是 0 就是没生成,content 是空字符串就是没内容,不需要额外的 hasXxx() 判断。
九、从 JSON 迁移到 Protobuf 的实战经验
最后分享下迁移过程中的几个关键决策和踩坑。
9.1 迁移不是重写,是替换
迁移的思路很简单:
| JSON 协议 | Protobuf 协议 |
|---|---|
TextWebSocketFrame |
BinaryWebSocketFrame |
JSONUtil.toJsonStr() |
protobuf.toByteArray() |
JSON.parseObject() |
protobuf.parseFrom() |
WebSocket 层面只改了帧类型(Text → Binary),Netty Pipeline 里其他 Handler(心跳、认证、限流)完全不用动。
9.2 渐进式迁移(没用上)
我的系统在迁移时直接一刀切了------服务端上线后老版本客户端直接连不上(收到 TextWebSocketFrame 就断连),强制升级。如果你的系统不能强制升级,可以用双协议并行方案:服务端根据 WebSocket 子协议协商结果决定用 JSON 还是 Protobuf,但这会增加维护成本,不推荐长期使用。
9.3 编译命令备忘
Java 端(Maven 自动编译):
xml
<!-- pom.xml 里配置了 protobuf-maven-plugin -->
<!-- protoc 3.25.3 + gRPC 1.62.2 -->
mvn -pl im-common compile生成的 Java 类在 target/generated-sources/protobuf/java/ 下。
Flutter 端(手动编译):
bash
protoc --dart_out=lib/protos/generated --proto_path=protos protos/im_message.proto生成的 Dart 类在 lib/protos/generated/ 下。
十、总结
这篇讲了 IM 系统协议设计的五个层次:
- 原理层:Protobuf 的 TLV 编码、varint/fixed64 选择、wire type 机制------理解底层才能做对优化决策
- 架构层 :信封模式(
ImProtoRequest/ImProtoResponse)+ 策略模式分发 + gRPC 双协议复用,一套协议管住 22 种消息类型 - 字段层 :
string → bytes/fixed64、chatId 动态计算不传输,每条消息省 66% 体积 - 理论层:业界 IM 协议方案对比、向后兼容原理、oneof vs 信封模式的取舍
- 工程层:三端同步、字段编号铁律、optional 的正确使用、从 JSON 迁移的实战路径
整个 .proto 文件 376 行,定义了 IM 系统的全部协议。比起 JSON 时代几百行的消息常量类和手动序列化代码,Protobuf 的 .proto 文件本身就是最好的文档------能编译、能校验、能生成代码,永远不会和实际实现不一致。
系列下一篇会讲 消息 ID 设计------一个 UUID 搞不定的事,我用两个 ID 解决了:clientMsgId(UUID)管去重 + msgId(雪花算法)管排序。两个 ID 各管各的,谁也不抢谁的活。
本文是「XZLL-IM干货系列」第 02 篇,整个系列共 35 篇,从协议设计到消息投递、从存储方案到生产踩坑,全部基于真实项目源码。项目源码已闭源,但技术不闭源。
我是 蝎子莱莱爱打怪,一个从 0 到 1 搭建分布式 IM 系统的后端开发。
XZLL-IM 干货系列共 35 篇,从协议设计到消息投递、从存储方案到性能调优,全部基于真实项目源码,不是 PPT 架构,是踩出来的实战经验。
欢迎点赞、收藏、关注。