Architecture: Single Controller + Multiple ActorGroups
It wraps a group of Ray actors that form a single distributed model:
actor_model = RayActorGroup(
args.actor_num_nodes, # e.g., 1
args.actor_num_gpus_per_node, # e.g., 8
PolicyModelActor, # the @ray.remote class
pg=pg, # optional placement group
num_gpus_per_actor=0.2 if pg else 1, # fractional GPU for colocation
duplicate_actors=args.ring_attn_size * args.ds_tensor_parallel_size,
)What happens inside RayActorGroup.init (launcher.py:228):
- Create a placement group (if no shared one provided). A placement group is Ray's way of reserving GPU bundles atomically --- all-or-nothing scheduling. This prevents partial allocation where some GPUs are on node A and others on node B when you need them co-located.
- Spawn rank 0 (master actor) --- it discovers its own IP and a free port, then returns master_addr and master_port via ray.get().
- Spawn ranks 1...N (worker actors) --- they receive the master's address and connect to the same process group.
Each actor inside the group is a @ray.remote(num_gpus=1) class. The num_gpus=1 tells Ray to assign exactly 1 GPU to each actor. When num_gpus_per_actor=0.2 (hybrid engine mode), 5 actors share 1 GPU --- this is how models get colocated.
┌─────────────────────────────────────────────────────┐
│ RAY (控制平面 - 决策者) │
│ • 资源分配:决定用几个GPU、几个节点 │
│ • 任务编排:启动/停止/重启训练进程 │
│ • 容错恢复:worker挂了自动重启 │
│ • 超参搜索:并行运行多个实验 │
└─────────────────┬───────────────────────────────────┘
│ 创建并管理worker进程
▼
┌─────────────────────────────────────────────────────┐
│ DEEPSPEED (执行平面 - 加速器) │
│ • 显存优化:ZeRO分片、CPU卸载 │
│ • 通信优化:重叠计算与通信、梯度聚合 │
│ • 混合精度:自动管理FP16损失缩放 │
│ • Kernel优化:Fused Adam, CUDA算子融合 │
└─────────────────┬───────────────────────────────────┘
│ 包装模型、优化器
▼
┌─────────────────────────────────────────────────────┐
│ PYTORCH (计算平面 - 执行者) │
│ • 前向传播:计算loss │
│ • 反向传播:计算梯度 │
│ • 参数更新:优化器step │
└─────────────────────────────────────────────────────┘
用户执行: python main.py --num-gpus 2
│
▼
┌─────────────────────────────────────────────┐
│ Ray.init() - 资源发现 │
│ • 扫描可用GPU设备 │
│ • 建立分布式对象存储 │
│ • 启动GCS (Global Control Service) │
└──────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ RayDeepSpeedController.setup_workers() │
│ • 创建Placement Group (请求2个GPU) │
│ • Ray调度器分配GPU资源 │
│ • 创建2个DeepSpeedRayWorker Actor │
└──────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ DeepSpeedRayWorker.__init__ (在每个GPU上) │
│ • 设置分布式环境变量(Master地址、Rank等) │
│ • 创建PyTorch模型 │
│ • 调用 deepspeed.initialize() │
│ - 根据ZeRO配置分片模型参数 │
│ - 创建Fused Adam优化器 │
│ - 初始化梯度累加器 │
│ - 设置混合精度管理器 │
└──────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ controller.run_training() │
│ • Ray并行调用所有worker的train方法 │
│ • Ray自动处理分布式对象引用 │
└──────────────┬──────────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ 训练循环 (每个worker独立但通过NCCL通信) │
│ │
│ for batch in dataloader: │
│ loss = model(batch) # 前向 │
│ engine.backward(loss) # DeepSpeed后向 │
│ engine.step() # 参数更新 │
│ • DeepSpeed自动all-reduce梯度 │
│ • 处理ZeRO参数同步 │
│ • 更新学习率调度器 │
└──────────────────────────────────────────────┘
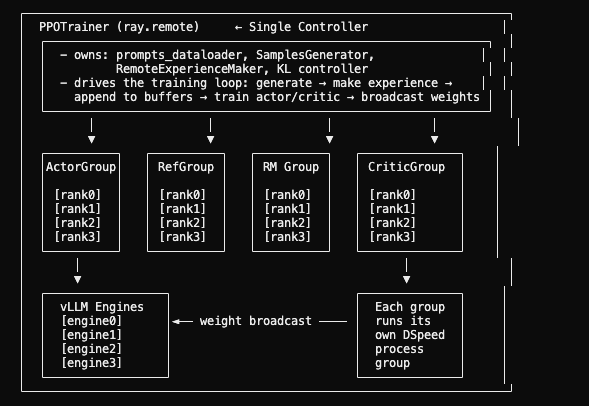
┌────────────────────────────────────────────────────────────────────────┐
│ PPOTrainer.fit() --- Single Controller Loop │
│ │
│ 1. GET PROMPTS │
│ prompts_dataloader → rand_prompts, labels │
│ │
│ 2. GENERATE SAMPLES (via vLLM) │
│ SamplesGenerator.generate_samples(rand_prompts, labels, ...) │
│ ├── vllm_engines[i].add_requests.remote(sampling_params, tokens) │
│ ├── ray.get(refs) # wait for generation to complete │
│ └── vllm_engines[i].get_responses.remote() # collect results │
│ → returns List[Experience] with sequences, action_mask │
│ │
│ 3. MAKE EXPERIENCE (add logprobs, values, rewards, KL) │
│ RemoteExperienceMaker.make_experience_batch(rollout_samples) │
│ ├── actor_model_group.async_run_method_batch("forward", ...) │
│ │ → each actor replica forward-passes to get action_log_probs │
│ ├── reference_model_group.async_run_method_batch("forward", ...) │
│ │ → each ref replica forward-passes to get base_log_probs │
│ ├── critic_model_group.async_run_method_batch("forward", ...) │
│ │ → each critic replica forward-passes to get values │
│ ├── reward_model_group.async_run_method_batch("forward", ...) │
│ │ → each RM replica forward-passes to get rewards │
│ │ (or remote_rm_url → HTTP call to external RM) │
│ ├── compute_approx_kl(action_log_probs, base_log_probs) │
│ └── compute_advantages_and_returns(...) │
│ → returns List[Experience] with full training data │
│ │
│ 4. APPEND TO REPLAY BUFFERS │
│ actor_model_group.async_run_method_batch("append", experience=..) │
│ critic_model_group.async_run_method_batch("append", experience=..)│
│ → each actor/critic replica appends to its local NaiveReplayBuffer│
│ │
│ 5. TRAIN (ppo_train) │
│ ├── critic_model_group.async_run_method("fit") │
│ │ → each CriticModelActor runs CriticPPOTrainer.ppo_train() │
│ │ → iterates replay_buffer, calls training_step() │
│ │ → backward + optimizer_step (DeepSpeed handles sync) │
│ ├── actor_model_group.async_run_method("fit", kl_ctl=value) │
│ │ → each PolicyModelActor runs ActorPPOTrainer.ppo_train() │
│ │ → iterates replay_buffer, calls training_step() │
│ │ → backward + optimizer_step (DeepSpeed handles sync) │
│ └── broadcast_to_vllm() │
│ → actor rank 0 pushes updated weights to vLLM engines │
│ │
│ 6. LOG & CHECKPOINT │
│ → wandb/tensorboard logging, save checkpoint on actor/critic │
│ │
│ → repeat from step 1 │
└────────────────────────────────────────────────────────────────────────┘The async trainer (ppo_trainer_async.py (OpenRLHF/openrlhf/trainer/ppo_trainer_async.py)) decouples generation from training using a producer-consumer queue:
GenerateSamplesActor ──→ queue ──→ PPOTrainerAsync
(producer) (consumer)
continuously generates continuously trains on
samples via vLLM dequeued experiences

-
单进程多GPU vs 多进程单GPU
- 每个Ray Actor占用一个GPU
- 通过num_gpus=1确保独占
- DeepSpeed在actor内部管理该GPU上的模型并行
-
Ray负责跨节点,DeepSpeed负责节点内
- Ray:节点发现、资源分配、容错恢复
- DeepSpeed:GPU间通信、显存优化、梯度同步
-
混合并行策略
- 数据并行:不同actor组处理不同数据块
- 模型并行:同一组内的多个actor(duplicate_actors)运行相同模型的不同部分
- Ring Attention:通过ring_attn_group实现长序列并行