认识微服务
微服务是一种软件架构风格,它是以专注于单一职责的很多小型项目为基础,组合出复杂的大型应用。
单体架构
将业务的所有功能集中在一个项目中开发,打成一个包部署
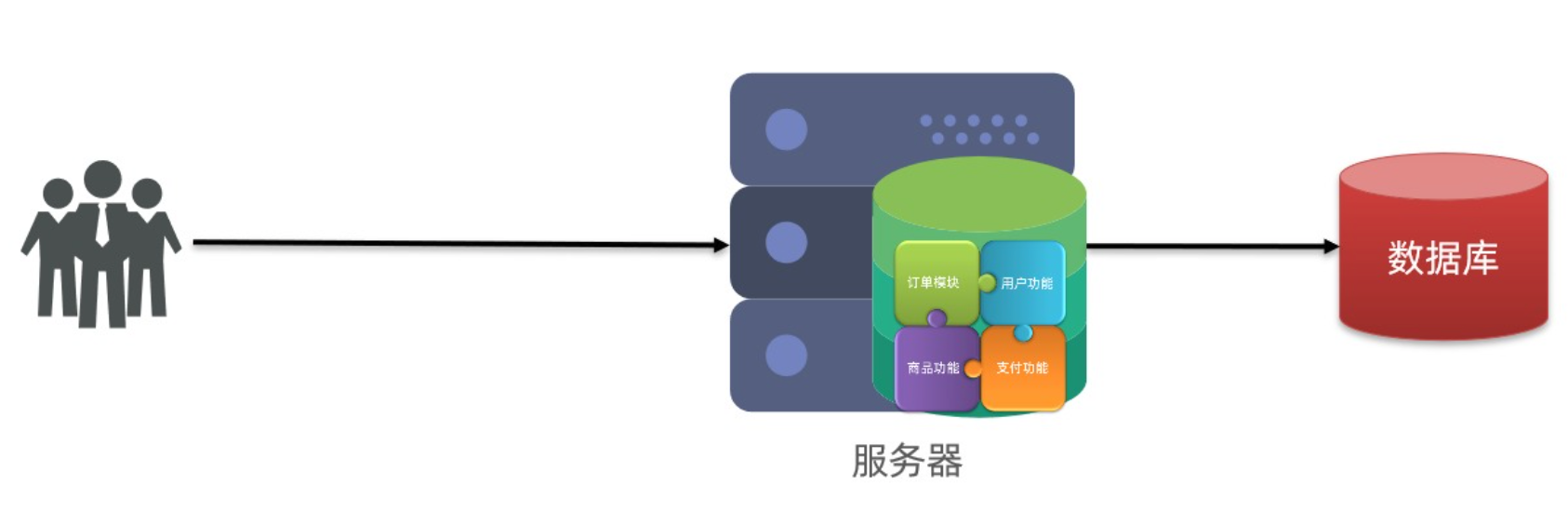
优点
- 架构简单
- 部署成本低
缺点 - 耦合度高(维护困难、升级困难)
分布式架构
根据业务功能对系统做拆分,每个业务功能模块作为独立项目开发,称为一个服务
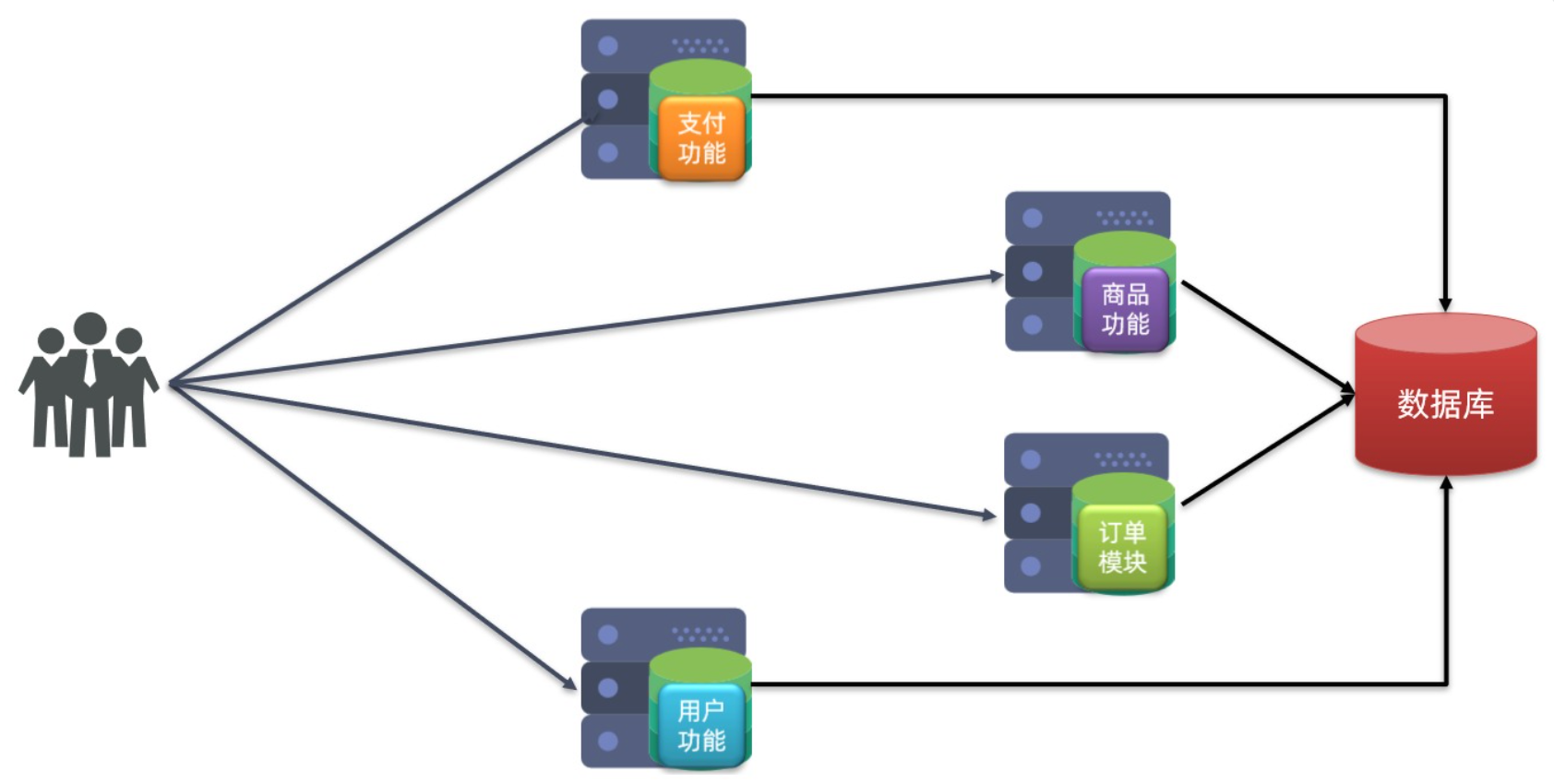
优点
- 降低服务耦合
- 有利于服务升级和拓展
缺点 - 服务调用关系错综复杂
分布式架构虽然降低了服务耦合,但是服务拆分时也有很多问题需要思考,服务拆分的细粒度如何界定?服务之间如何调用?服务的调用关系如何管理?人们需要指定一套行之有效的标准来约束分布式架构
微服务
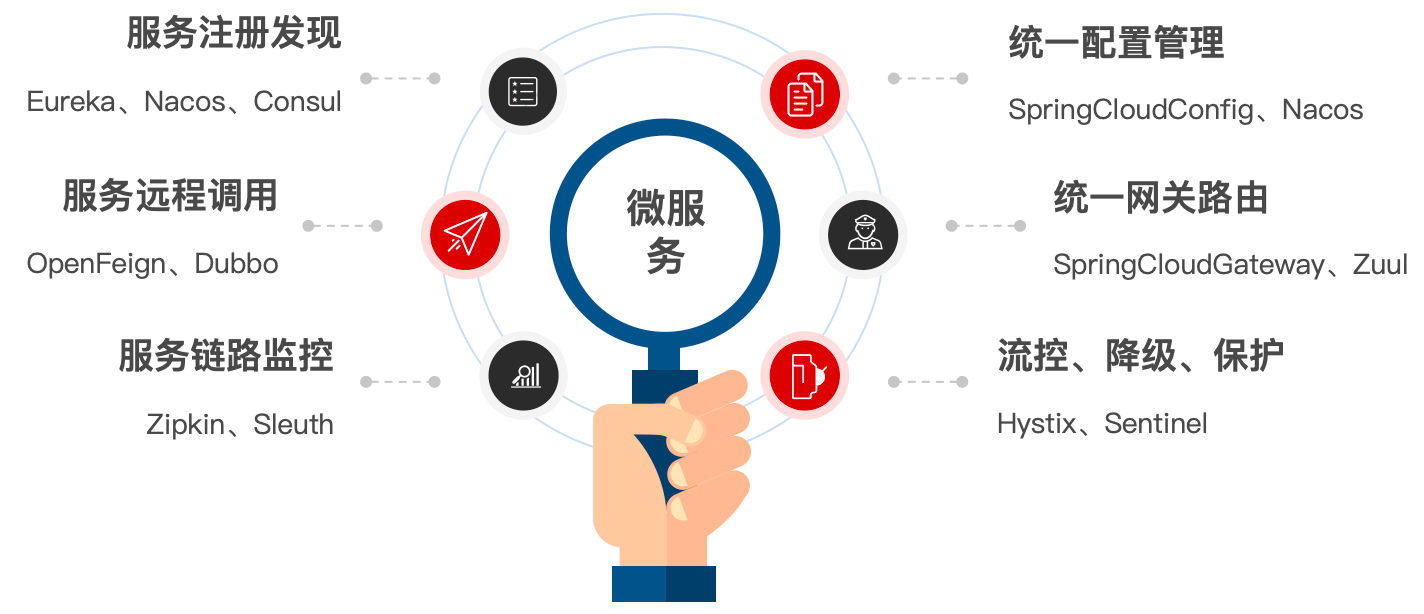
微服务是一种经过良好架构设计的分布式架构方案,微服务架构特征:
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,避免重复业务开发
- 面向服务:微服务对外暴露业务接口(让别人来访问)
- 自治:团队独立、技术独立(可以用不同的技术实现)、数据独立(可以用不同的数据库)、部署独立
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
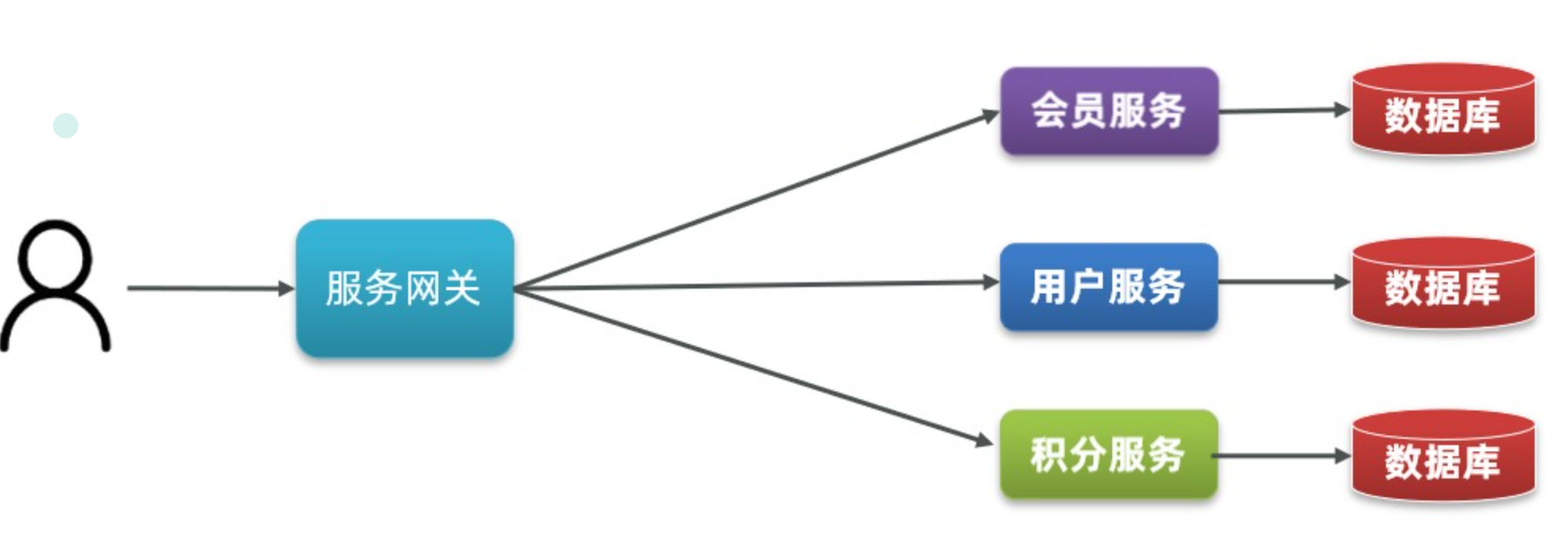
微服务这种方案需要技术框架来落地,全球的互联网公司都在积极尝试自己的微服务落地技术。在国内最知名的就是 SpringCloud 和阿里巴巴的 Dubbo。
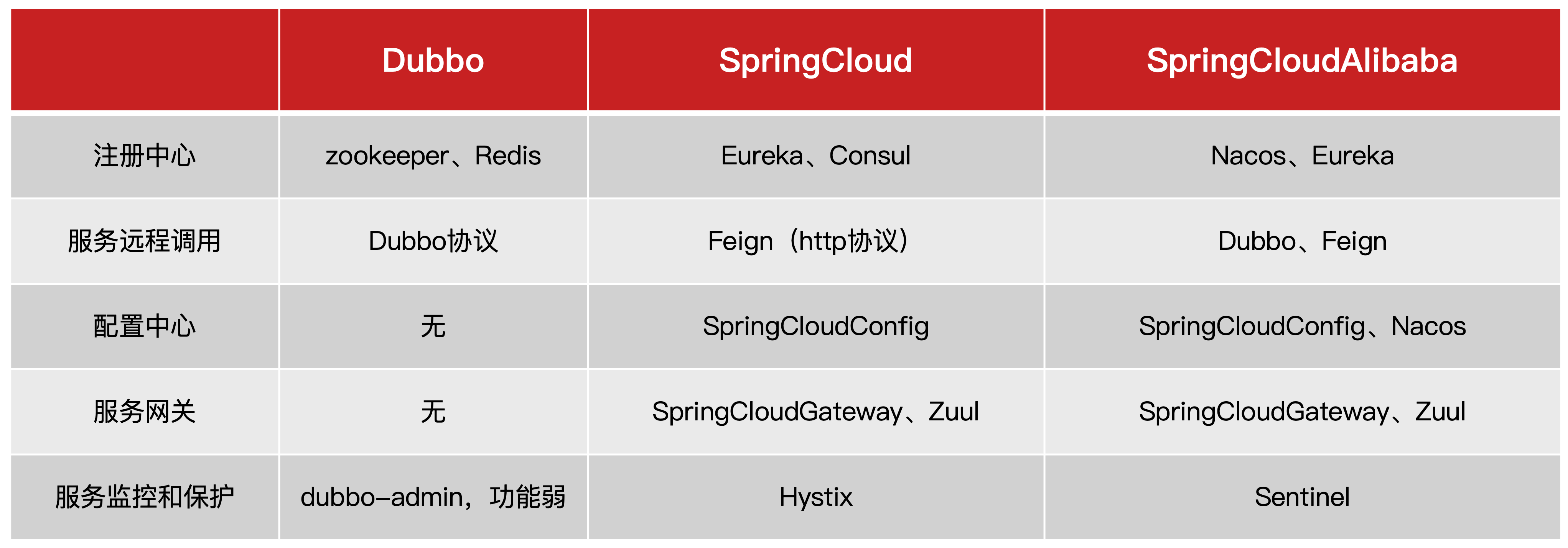
SpringCloud
SpringCloud是目前国内使用最广泛的微服务框架。官网地址:https://spring.io/projects/spring-cloud。
SpringCloud集成了各种微服务功能组件,并基于 SpringBoot 实现了这些组件的自动装配,从而提供了良好的开箱即用体验
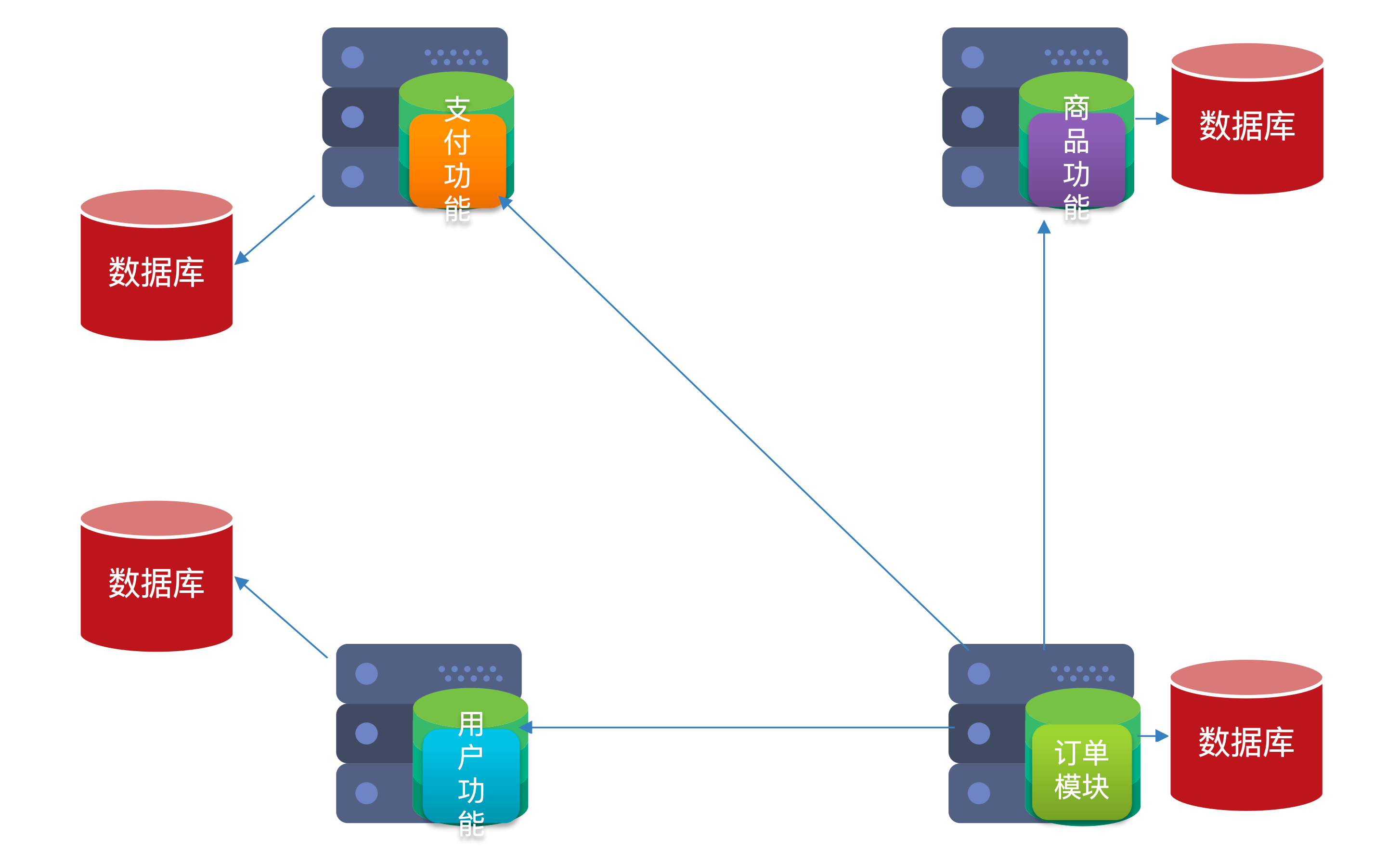
服务拆分及远程调用
服务拆分原则
- 单一职责:不同微服务,不要重复开发相同业务(比如订单模块里面不应该包含查询用户信息、修改商品信息的语句)
- 数据独立:不要访问其它微服务的数据库(每个模块都是自己的数据库,访问不到别的数据库,从根源上杜绝了订单模块能查询用户信息的能力)
- 面向服务:将自己的业务暴露为接口,供其它微服务调用
服务拆分示例
cloud-demo:父工程,管理依赖
- order-service:订单微服务,负责订单相关业务
- user-service:用户微服务,负责用户相关业务
需求
- 订单微服务和用户微服务必须有各自的数据库,相互独立
- 订单服务和用户服务都对外暴露
Restful的接口 - 订单服务如果需要查询用户信息,只能调用用户服务的
Restful接口,不能查询用户数据库
{% tabs 服务拆分示例实体类 , 1 %}
java
@Data
public class Order {
private Long id;
private Long price;
private String name;
private Integer num;
private Long userId;
private User user;
}
java
@Data
public class User {
private Long id;
private String username;
private String address;
}{% endtabs %}
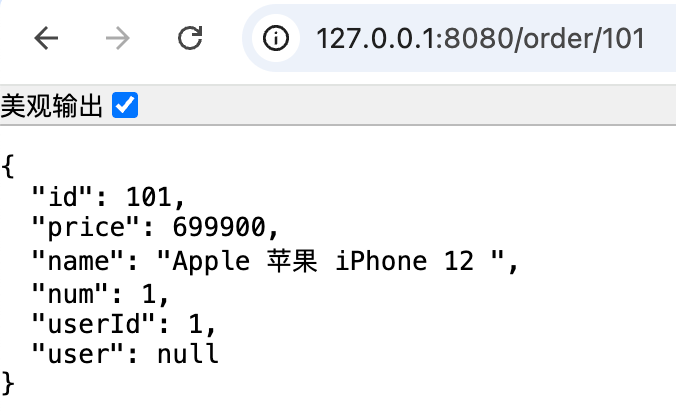
启动两个服务后,我们访问 http://localhost:8080/order/101 ,是可以查询到数据的,但是此时 user 是 null
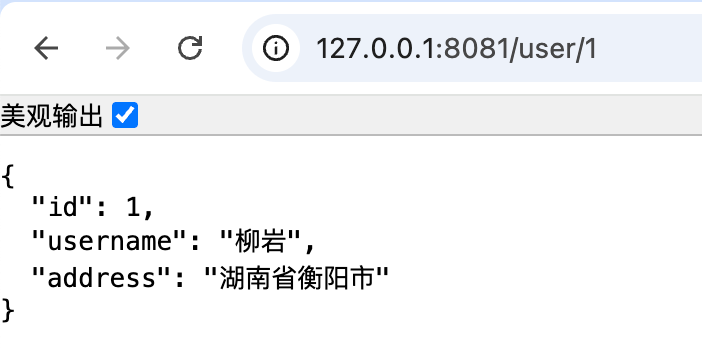
在 user-service 下面,通过 Get /user/{id} 方式可以根据 id 查询用户
实现远程调用
修改 order-service 中的根据 id 查询订单业务,要求在查询订单的同时,根据订单中包含的 userId 查询出用户信息,一并返回
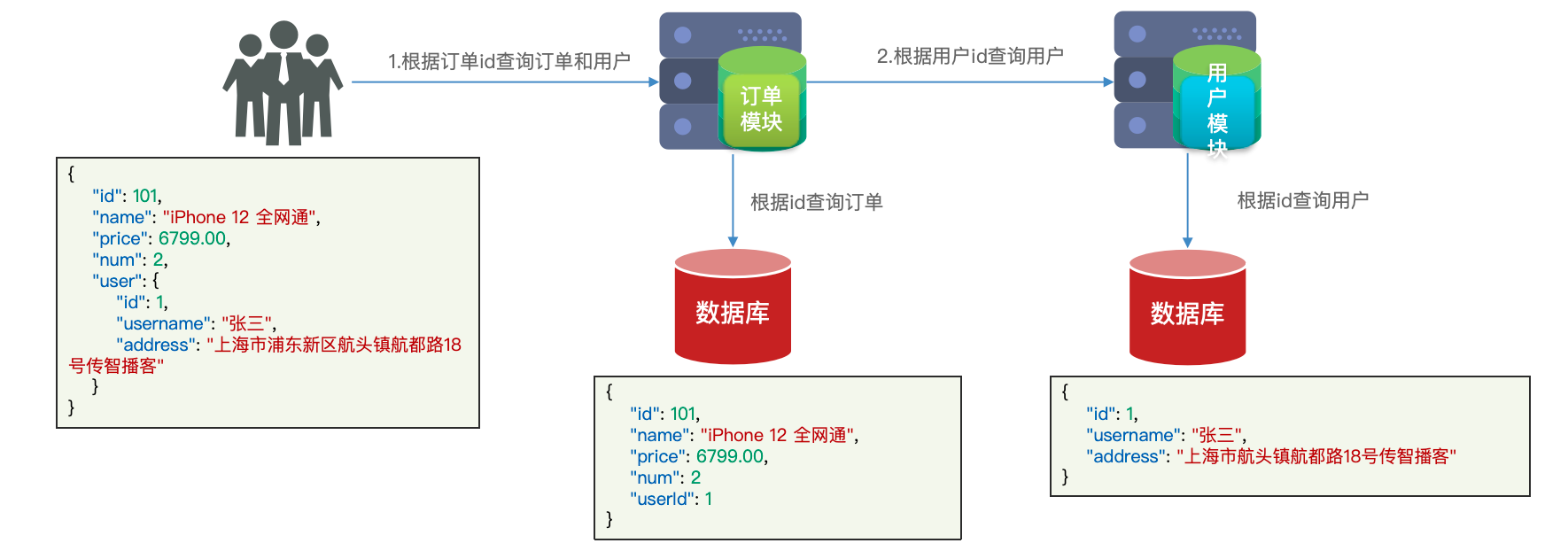
我们原来查询用户信息是通过 http 请求的方式,如果在 order-service 中也向 user-service 发送一个 http 请求用户的信息,就能获取我们需要的信息了。
步骤如下
- 注册一个
RestTemplate的实例到Spring容器 - 修改 order-service 服务中的
OrderService类中的queryOrderById方法,根据 Order 对象中的 userId 查询 User - 将查询到的 User 填充到 Order 对象,一并返回
注册 RestTemplate
注册 RestTemplate 实例到容器
java
@MapperScan("cn.itcast.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
// 实例
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}这里就直接放在启动类里面了,正常应该放在配置类里面
实现远程调用
通过 RestTemplate 进行远程调用获取用户信息
java
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate;
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2. 远程查询User
// 2.1 url地址,这里的url是写死的,后面会改进
String url = "http://localhost:8081/user/" + order.getUserId();
// 2.2 发起调用 --> 传入 url 和返回值类型
User user = restTemplate.getForObject(url, User.class); // 这个User类也是在 order-service 里面定义的
// 3. 存入order
order.setUser(user);
// 4.返回
return order;
}
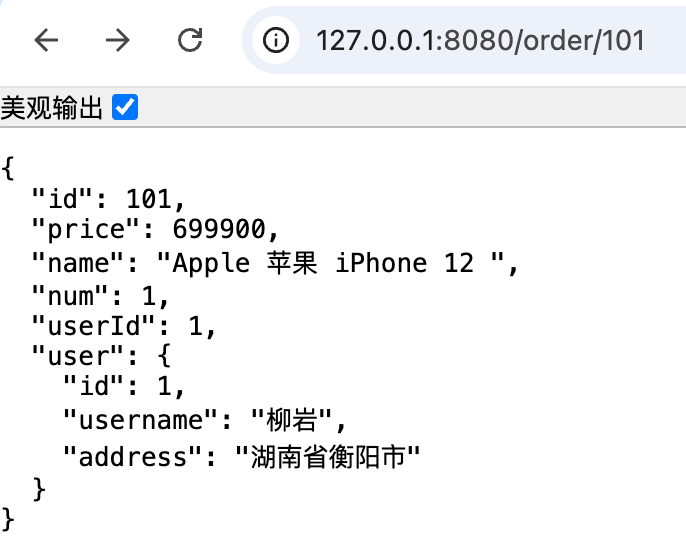
}再次访问就可以看到了
提供者与消费者

在服务调用关系中,会有两个不同的角色
- 服务提供者:一次业务中,被其他微服务调用的服务(提供接口给其他微服务)
- 服务消费者:一次业务中,调用其他微服务的服务(调用其他微服务提供的接口)
但是,服务提供者与服务消费者的角色并不是绝对的,而是相对于业务而言
如果服务A调用了服务B,而服务B又调用的服务C,那么服务B的角色是什么?
- 对于A调用B的业务而言:A是服务消费者,B是服务提供者
- 对于B调用C的业务而言:B是服务消费者,C是服务提供者
因此服务B既可以是服务提供者,也可以是服务消费者
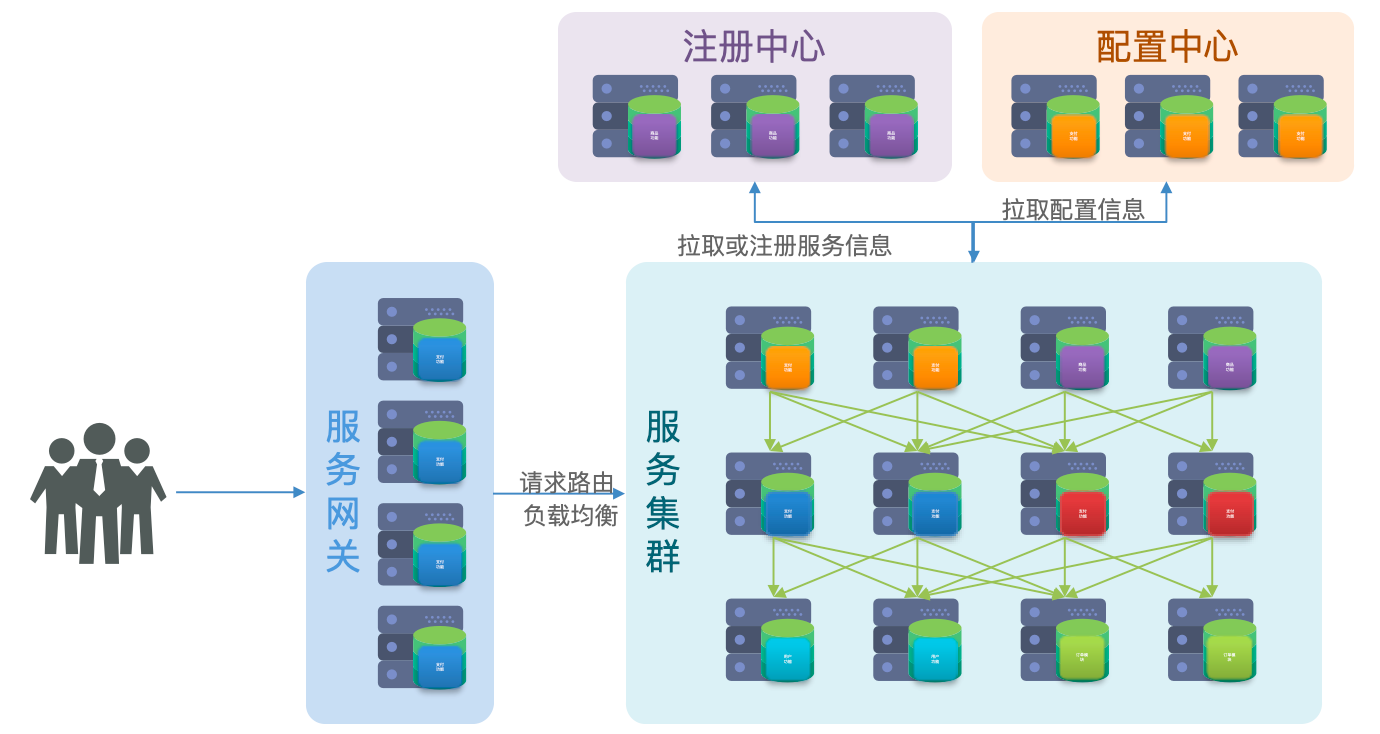
Eureka 注册中心
远程调用的问题
假如我们的服务提供者 user-service 提供了三个实例,占用的分别是 8081、8082、8083 端口,那原来把 URL 硬编码在代码里就不合适了。
那我们来思考几个问题
- 问题一:order-service 在发起远程调用的时候,该如何得知 user-service 实例的 ip 地址和端口?
- 问题二:有多个 user-service 实例地址,order-service 调用时,该如何选择?
- 问题三:order-service 如何得知某个 user-service 实例是否健康,是不是已经宕机?
eureka 原理
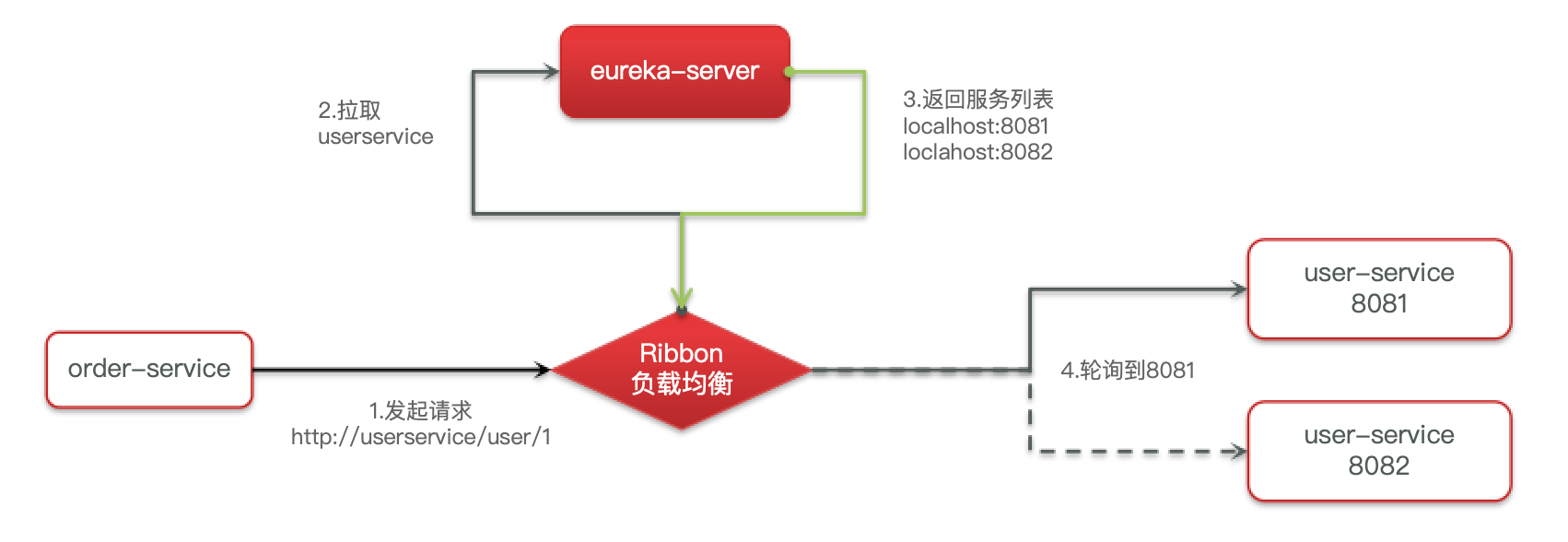
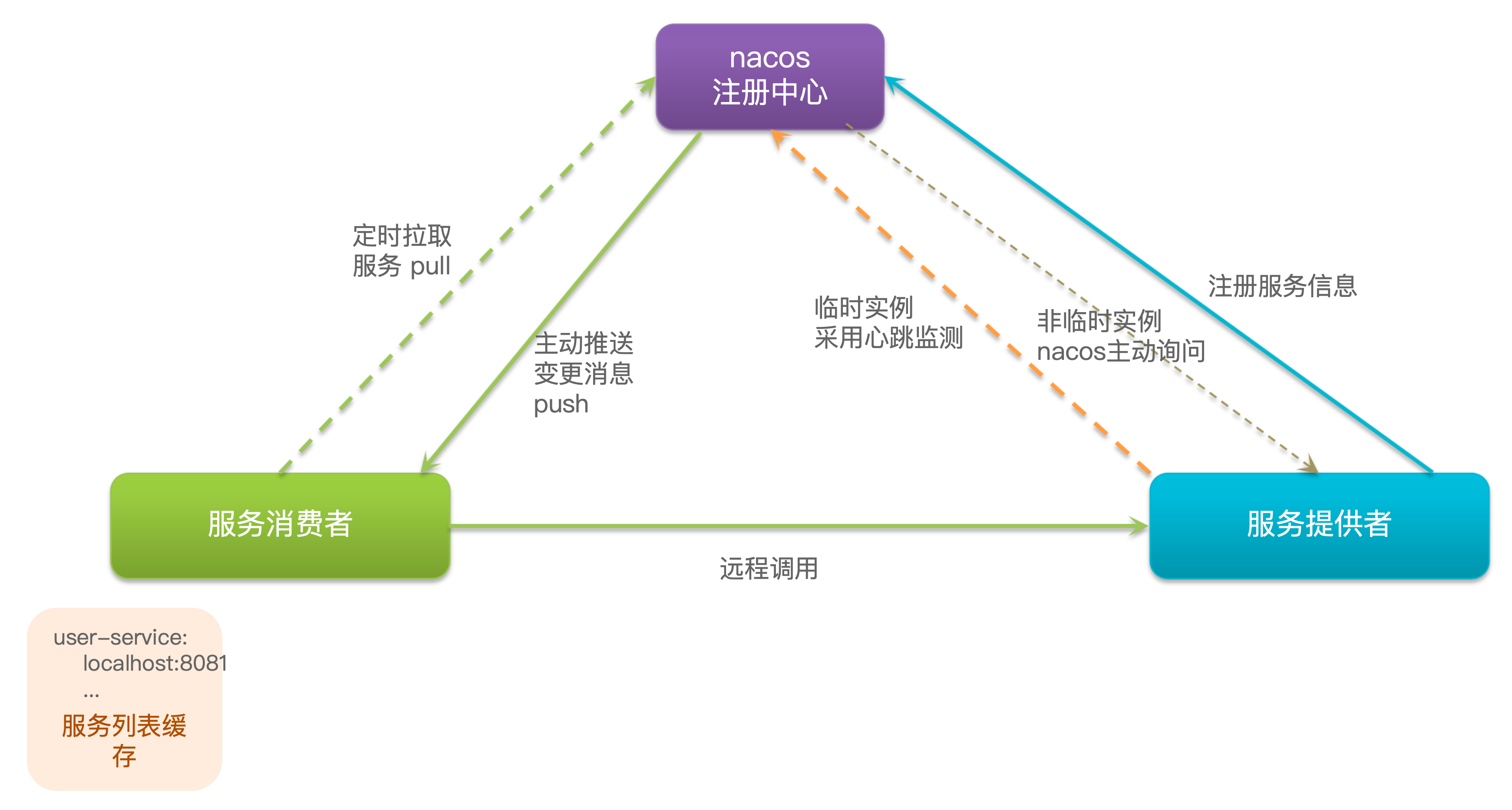
这些问题都需要利用SpringCloud中的注册中心来解决,其中最广为人知的注册中心就是Eureka,其结构如下
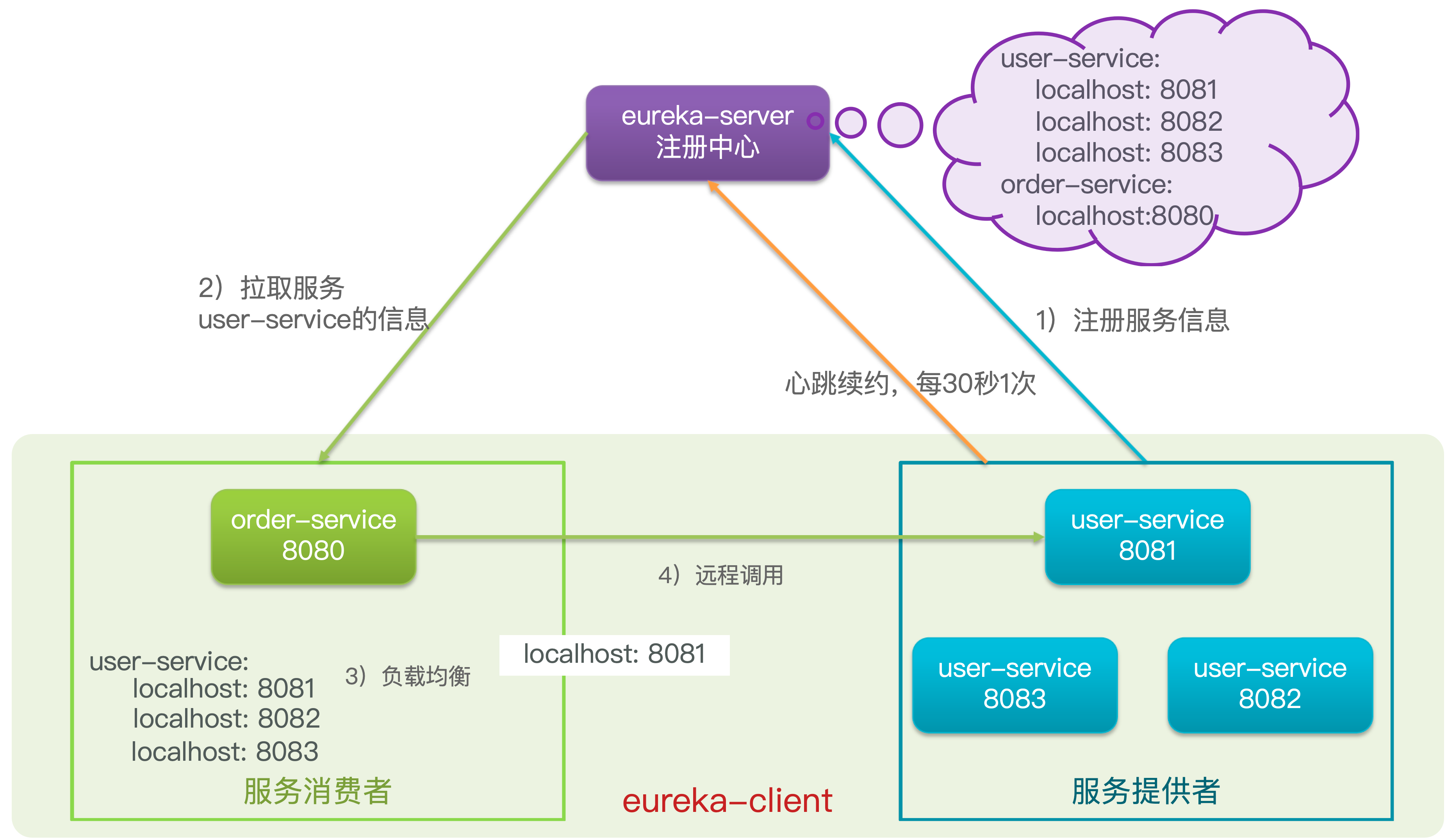
项目启动时,eureka-client 会向 eureka-server 注册中心进行注册。
那么现在来回答之前的各个问题
问题一:order-service 如何得知 user-service 实例地址?
- 获取地址信息流程如下
- user-service 服务实例启动后,将自己的信息注册到 eureka-server(Eureka服务端),这个叫服务注册
- eureka-server 保存服务名称到服务实例地址列表的映射关系
- order-service 根据服务名称,拉取实例地址列表,这个叫服务发现或服务拉取
问题二:order-service 如何从多个 user-service 实例中选择具体的实例?
- order-service 从实例列表中利用负载均衡算法选中一个实例地址
- 向该实例地址发起远程调用
问题三:order-service 如何得知某个 user-service 实例是否依然健康,是不是已经宕机?
- user-service 会每隔一段时间(默认30秒)向 eureka-server 发起请求,报告自己的状态,成为心跳
- 当超过一定时间没有发送心跳时,eureka-server 会认为微服务实例故障,将该实例从服务列表中剔除
- order-service 拉取服务时,就能将该故障实例排除了
{% note warning %}
一个微服务,即可以是服务提供者,又可以是服务消费者,因此 eureka 将服务注册、服务发现等功能统一封装到了 eureka-client 端
{% endnote %}
动手实践
搭建 EurekaServer
首先我们注册中心服务端:eureka,这个必须是一个独立的服务器
创建 eureka-server 服务
在父工程项目下,搭建一个子模块,这里是创建一个 maven 项目
引入 eureka 依赖
SpringCloud 为 eureka 提供的 starter 依赖
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>编写启动类
给 eureka-server 服务编写一个启动类,一定要添加一个 @EnableEurekaServer 注解,开启 eureka 的注册中心功能
java
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class);
}
}编写配置文件
yaml
server:
port: 10086 # 服务端口
spring:
application:
name: eurekaserver # 微服务名字: Eureka自己也是一个微服务
eureka:
client:
service-url: # eureka 的地址信息,因为 Eureka 服务也可能做集群
defaultZone: http://127.0.0.1:10086/eureka这里为什么还要配置 eureka 的服务名称?因为 Eureka 本身也是一个微服务,也要注册自己
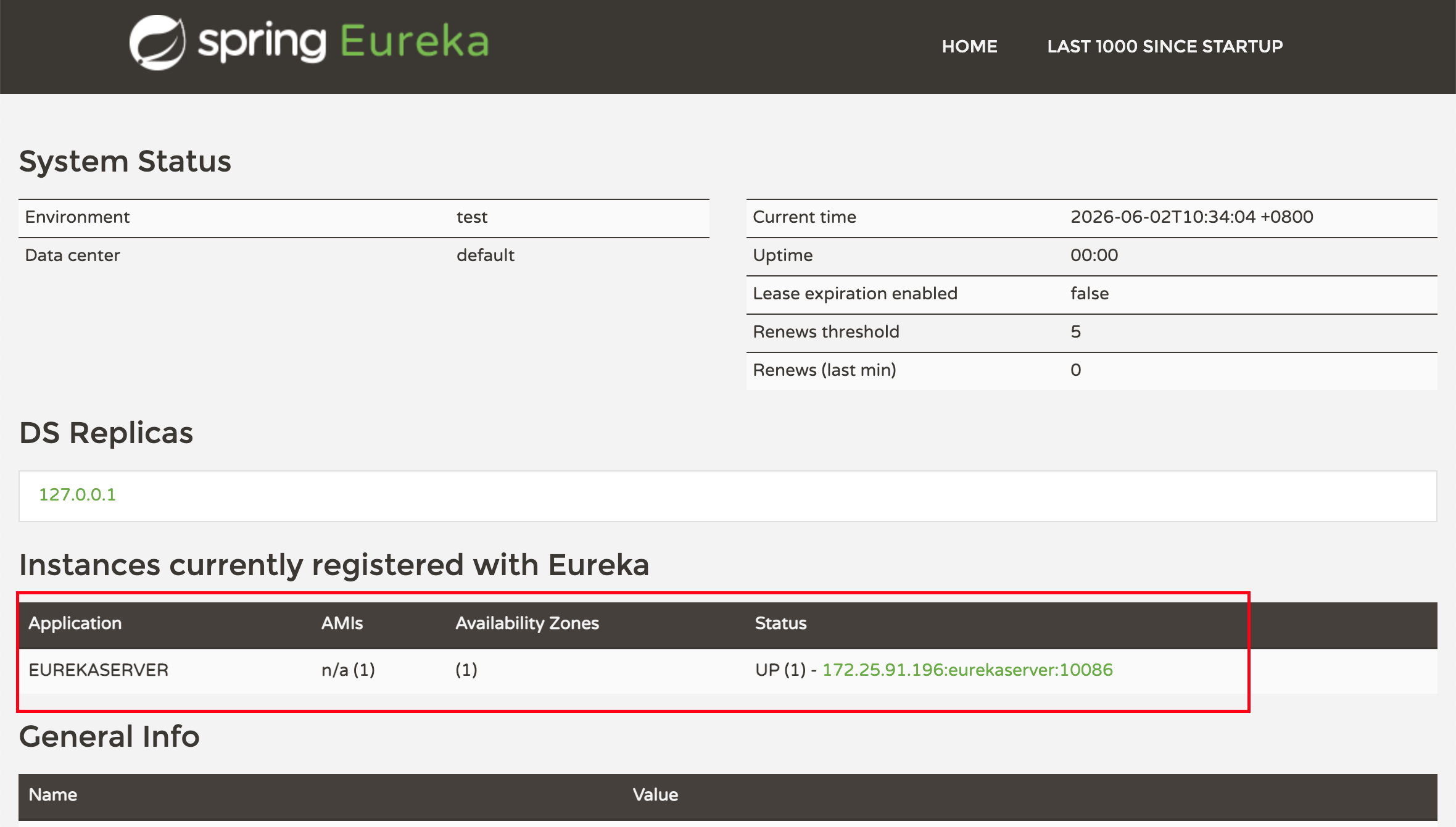
启动可以看到如下
服务注册
现在在 user-service 和 order-service 里面进行服务注册
引入依赖
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>前面是 eureka-server,注意这里是 eureka-client
编写配置
在 yaml 里面添加配置信息,和前面的 server 里面配置其实类似
yaml
spring:
application:
name: user-server
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka同理 order-server 也是,改一下 spring-application-name 就可以
启动多个 user-service 实例
为了演示一个服务有多个实例的场景,我们添加一个 SpringBoot 的启动配置,再启动一个 user-service,其操作步骤就是复制一份 user-service 的配置,name 配置为 UserApplication2,同时也要配合 VM 选项,修改端口号 -Dserver.port=8082,点击确定之后,在 IDEA 的服务选项卡中,就会出现两个 user-service 启动配置,一个端口是 8081,一个端口是 8082,然后查看 eureka-server 管理页面,发现服务确实都启动了,而且 user-service 有两个
然后重启一下 user-service 和 order-service,观察
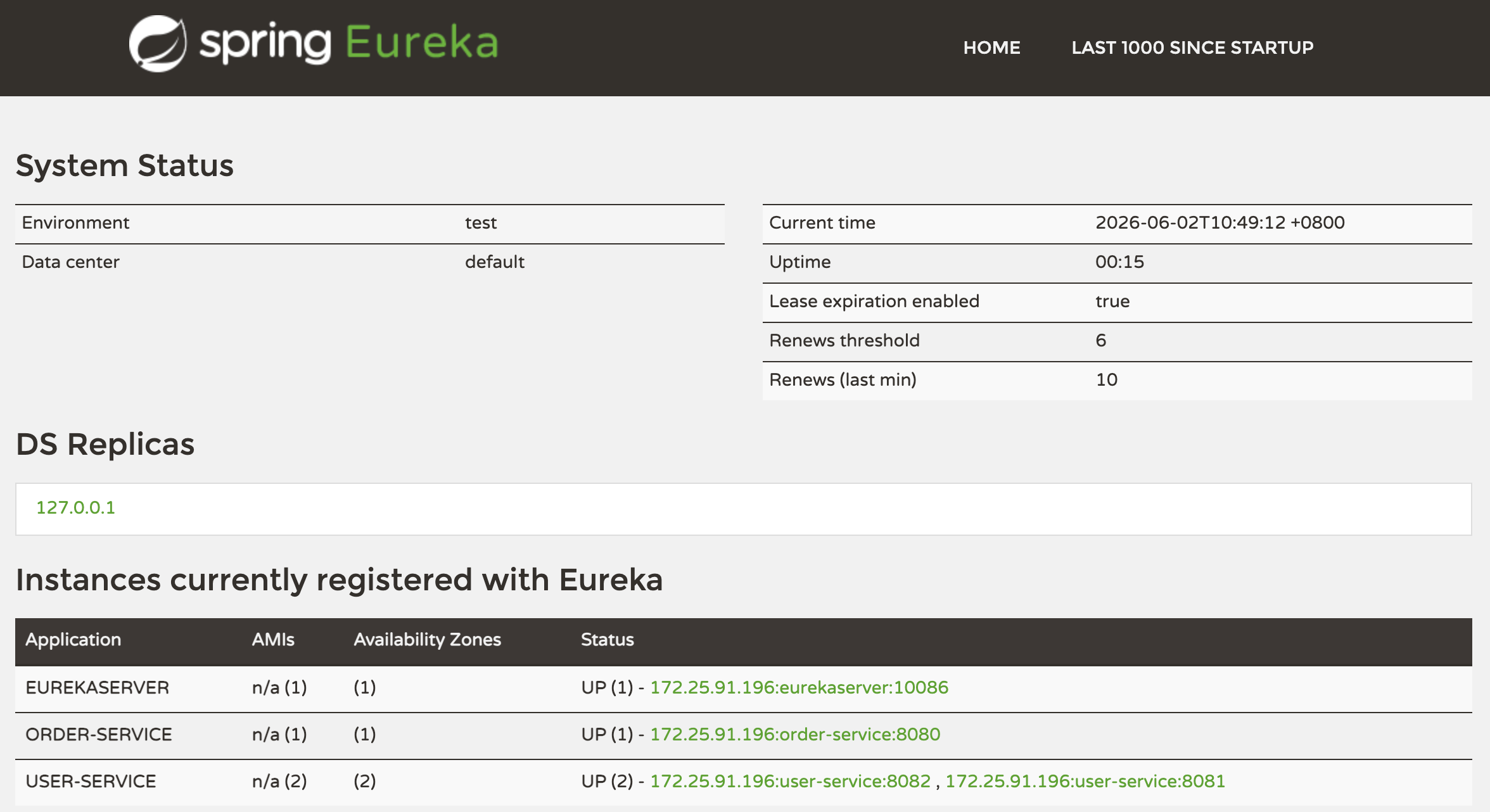
确实可以看到两个服务了
服务发现
现在我们将 order-service 的拉取逻辑修改,修改 URL,实现服务发现
引入依赖
服务发现、服务注册统一都封装在 eureka-client 依赖,因此这一步与服务注册时一致
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>在 order-service 中加入这个依赖
编写配置
服务发现也需要知道 eureka 地址,所以这一个也是和服务注册一致
yaml
spring:
application:
name: orderservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka{% note info %}
思考,既然有发现和注册,是不是可以设定自己的微服务只被发现不被注册,或者只被注册不被发现
确实可以,是通过下面这个来实现
yaml
eureka:
client:
register-with-eureka: true/false # 是否注册
fetch-registry: true/false # 是否被发现{% endnote %}
服务拉取与负载均衡
给 RestTemplate 这个 Bean 添加一个 @LoadBalanced 注解来实现负载均衡
java
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}修改 queryOrderById 方法,修改访问路径,用服务名代替IP+端口
java
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 修改为 user-service,代替 localhost:8081
String url = "http://user-service/user/" + order.getUserId();
// 2 发起调用
User user = restTemplate.getForObject(url, User.class);
// 3. 存入order
order.setUser(user);
// 4.返回
return order;
}Spring 会自动帮我们从 eureka-server 端,根据 user-service 这个服务名称,获取实例列表,然后完成负载均衡
访问 http://localhost:8080/order/101 ,是可以成功的,再访问一下 http://localhost:8080/order/102 ,其实可以发现,两个 user-service 每人被访问了一次,这就是负载均衡。
小结
- 搭建 EurekaServer
- 引入 eureka-server 依赖
- 添加
@EnableEurekaServer注解 - 在 application.yml 中配置 eureka 地址
- 服务注册
- 引入 eureka-client 依赖
- 在 application.yml 中配置 eureka 地址
- 服务发现
- 引入 eureka-client 依赖
- 在 application.yml 中配置 eureka 地址
- 在 RestTemplate 添加
@LoadBalanced注解 - 用服务提供者的服务名称远程调用
Ribbon 负载均衡
@LoadBalanced 注解是怎么实现负载均衡的呢?
原理
SpringCloud 底层其实是利用了一个名为 Ribbon 的组件,来实现负载均衡功能
流程
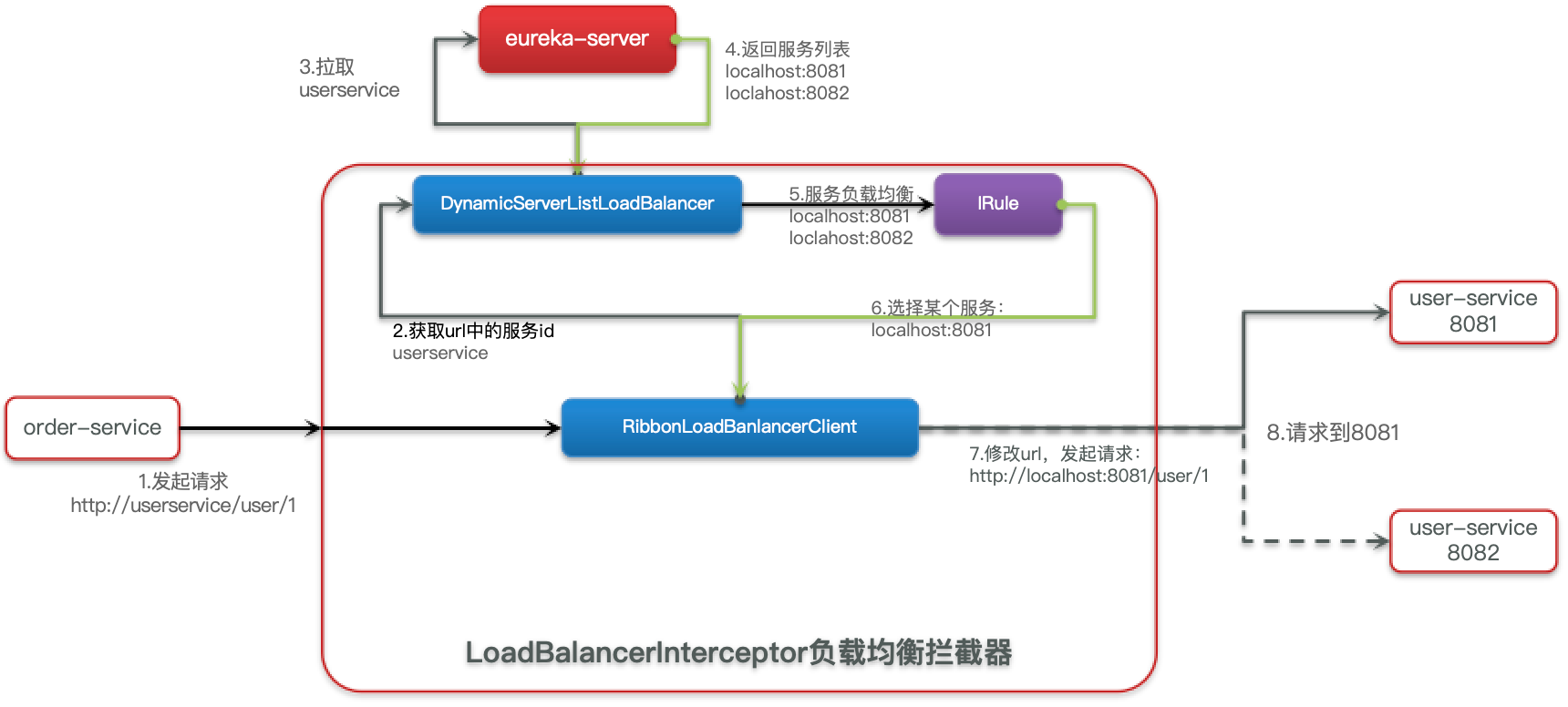
- Interceptor 拦截我们的 RestTemplate 请求:http://user-service/user/1
RibbonLoadBalancerClient会从请求 url 中获取服务名称,也就是 user-serviceDynamicServerListLoadBalancer根据 user-service 到 eureka 拉取服务列表- eureka 返回服务列表,localhost:8081、localhost:8082
- IRule 利用内置负载均衡规则,从列表中选择一个,例如 localhost:8081
RibbonLoadBalancerClient修改请求地址,用 localhost:8081 替代 user-service,得到 http://localhost:8081/user/1 发起真实请求
负载均衡策略
负载均衡策略
负载均衡的规则都定义在 IRule 接口中,IRule 有很多不同的实现类
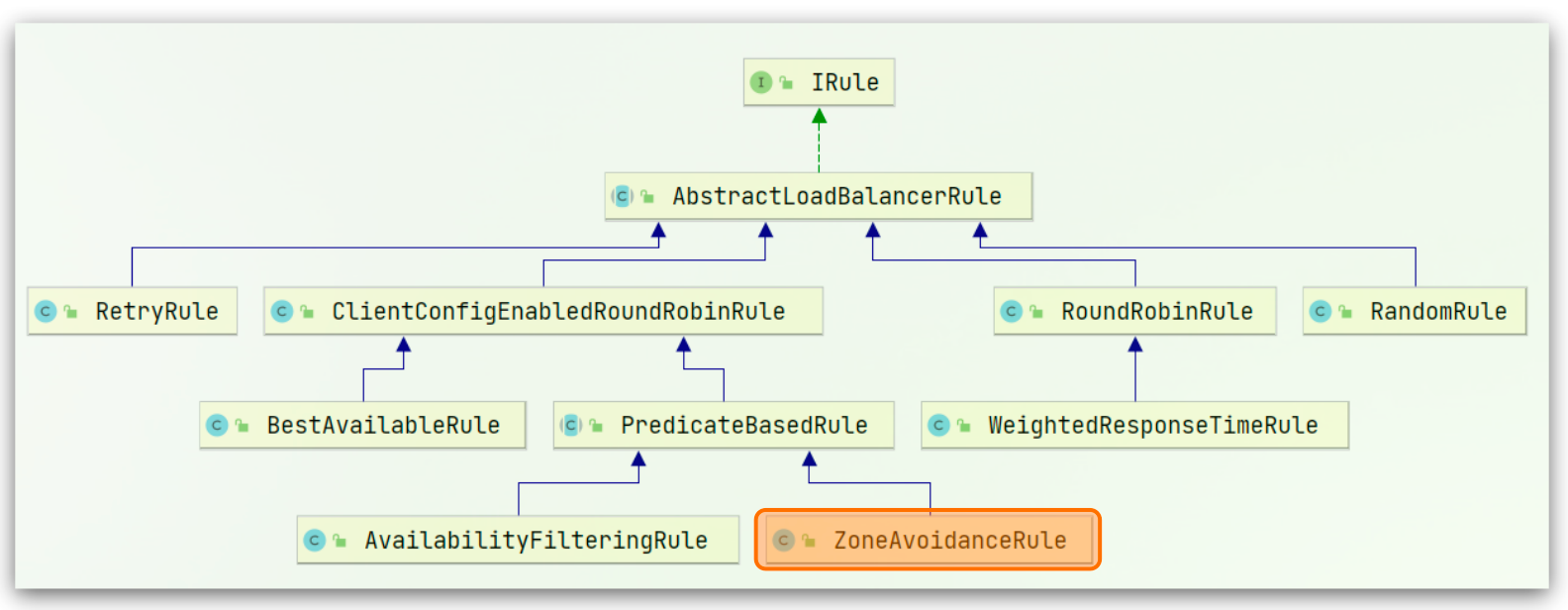
不同规则含义如下
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是 Ribbon 默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为"短路"状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了 AvailabilityFilteringRule 规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的 clientName.clientConfigNameSpace.ActiveConnectionsLimit 属性进行配置。 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用 Zone 对服务器进行分类,这个 Zone 可以理解为一个机房、一个机架等。而后再对 Zone 内的多个服务做轮询。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器。 |
| RetryRule | 重试机制的选择逻辑 |
默认的实现就是 ZoneAvoidanceRule,是一种轮询方案
自定义负载均衡策略
通过定义 IRule 实现,可以修改负载均衡规则,有两种方式
代码方式
在 order-service 中的 OrderApplication 类中,注册一个 IRule,此种方式定义的负载均衡规则,对所有微服务均有效,属于全局配置
java
@Bean
public IRule randomRule(){
return new RandomRule();
}配置灵活,但是修改后需要重新打包发布
配置文件方式
在 order-service 中的 application.yml 文件中,添加新的配置也可以修改规则,可以针对不同的微服务配置不同的负载均衡规则
yaml
user-service: ## 给某个微服务配置负载均衡规则,这里是user-service服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule ## 负载均衡规则 直观方便,无需重新打包发布,但是无法做全局配置
一般用默认的就可以了
饥饿加载
Ribbon 默认是采用懒加载,即第一次访问时,才回去创建 LoadBalanceClient,这样我们浏览器请求的时候,第一次请求时间会很长
而饥饿加载在则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载
在 order-service 的配置文件中
yaml
ribbon:
eager-load:
enabled: true ## 开启饥饿加载
clients: ## 指定对user-service这个服务进行饥饿加载,可以指定多个服务
- user-service这是对 order-service 在用 Ribbon 的时候,它去做服务拉取的时候配置是否是懒加载,所以在 order-service 配置文件里面配置,不影响别的微服务。
Nacos 注册中心
国内公司一般都推崇阿里巴巴的技术,比如注册中心,SpringCloud Alibaba 也推出了一个名为 Nacos 的注册中心
认识和安装 Nacos
Nacos 是阿里巴巴的产品,现在是 SpringCloud 中的一个组件,相比于 Eureka,功能更加丰富,在国内受欢迎程度较高
官网有下载教程
zip 方式
这里演示一下下载 zip 包的方式,目录说明:
- bin:启动脚本
- conf:配置文件
Nacos 的默认端口是 8848,如果你电脑上的其它进程占用了8848端口,请先尝试关闭该进程。
如果无法关闭占用 8848 端口的进程,也可以进入 nacos 的 conf 目录,修改配置文件 application.properties 中的 nacos.server.main.port
详细教程看这个 quickstart
需要我们在 application.properties 里面配置三个内容,一个是,base64 位的key
这个可以用 cmd 命令来帮助我们生成一个 key
cmd
openssl rand -base64 32
properties
nacos.core.auth.plugin.nacos.token.secret.key=xxxxxxx另外两个是
properties
nacos.core.auth.server.identity.key=nacos
nacos.core.auth.server.identity.value=nacos # 这里我都设置 nacos 了,这是登陆的账号密码注意,因为控制台是在 8080 端口(注意不是 nacos 服务在8080,只是登陆展示的在8080),所以我们在访问前需要保证这个端口是没被占用的

配置完成之后,进行启动,进入 bin 目录,打开终端执行以下命令即可
cmd
sh startup.sh -m standalone以单机模式启动,默认是集群模式,输入 http://locahost:8080/ 进入 Nacos 控制台页面,输入账号密码进入
这里演示的是 3.x 版本的,因为项目是 1.4.x,所以我们再介绍一种 docker 的方式
先 shutdown 一下
cmd
sh shutdown.shdocker
cmd
docker run -d \
--name nacos \
-p 8848:8848 \
-e MODE=standalone \
nacos/nacos-server:1.4.2
然后启动,访问 http://localhost:8848/nacos ,你看不同版本控制台端口访问还不一样,默认的登录账号和密码都是 nacos
老版本有默认鉴权密钥,所以这里使用很方便,学习本地没问题,但不适合公网部署。Nacos 后来的版本移除/强化了默认密钥配置,就是因为默认密钥有安全风险。官方鉴权文档里也提到 token secret key 用于鉴权,并建议自定义 Base64 密钥。
nacos-setup 一键部署
这种好像挺好,比前面两种都更方便,自动处理下载、鉴权配置、端口检测和 Java 环境验证等操作。用的时候可以看看官网,这里不演示了
服务注册
这里还是用老版本的 docker 部署的 1.4.2 来演示
Nacos 是 SpringCloudAlibaba 的组件,而 SpringCloud Alibaba 也遵循 SpringCloud 中定义的服务注册、服务发现规范。因此使用 Nacos 与使用 Eureka 对于微服务来说,并没有太大区别
主要差异在于
- 依赖不同
- 服务地址不同
引入依赖
在父工程的 pom.xml 文件中引入 SpringCloudAibaba的依赖
xml
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>注意是在 dependencyManagement 里面的 dependencies 里面,它只负责管理依赖版本,并不真正把依赖引入项目。如果子模块想使用,还是要自己引入依赖,但是版本可以不指定,会直接用父工程的版本号
然后在 user-service 和 order-service 的 pom 文件中引入 nacos-discovery 依赖
xml
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>{% note warning %}
同时删掉原来 eureka 的依赖
{% endnote %}
配置 Nacos 地址
在 user-service 和 order-service 的 application.yml 中添加 Nacos 地址
yaml
spring:
cloud:
nacos:
server-addr: localhost:8848{% note warning %}
同时也要将 eureka 的地址注释掉
{% endnote %}
重启服务
{% note info %}
这里面就不需要 eureka-server 这个服务了。
其实 nacos 也是一个 Java 程序
{% endnote %}
重启微服务后,登录 nacos 的管理页面,可以看到微服务信息
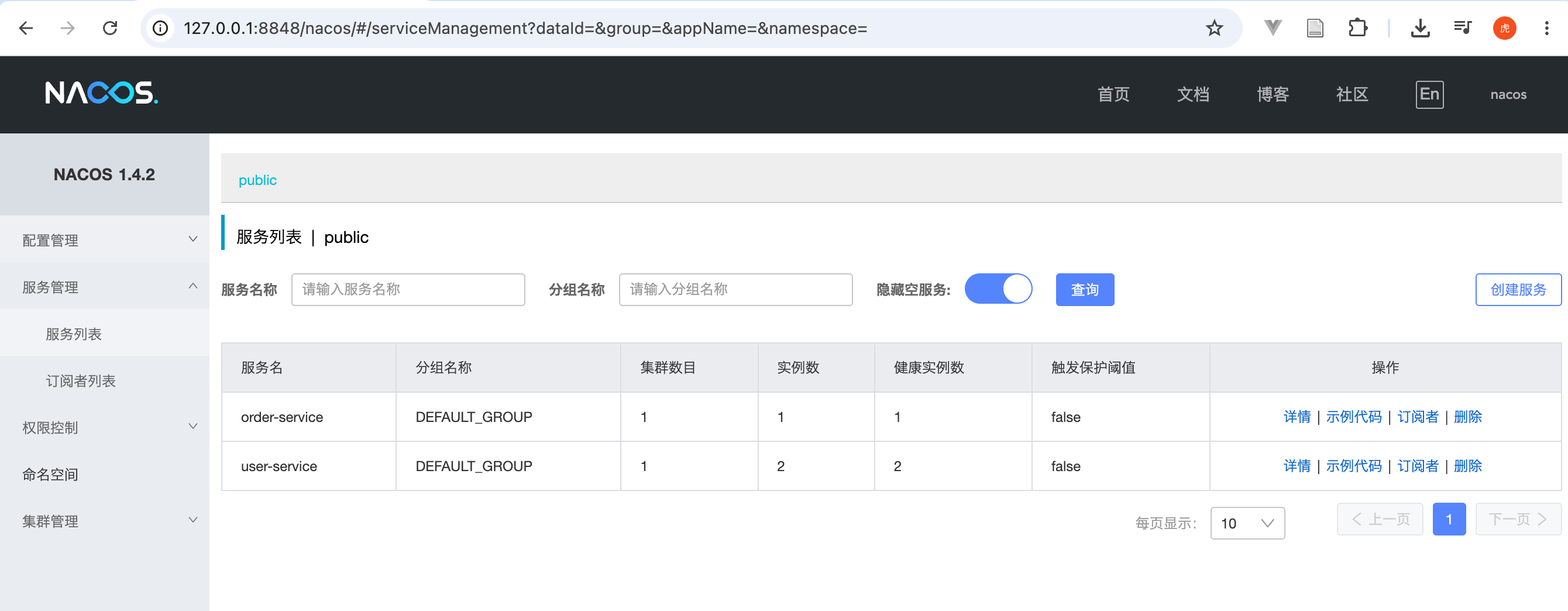
服务分级存储模式
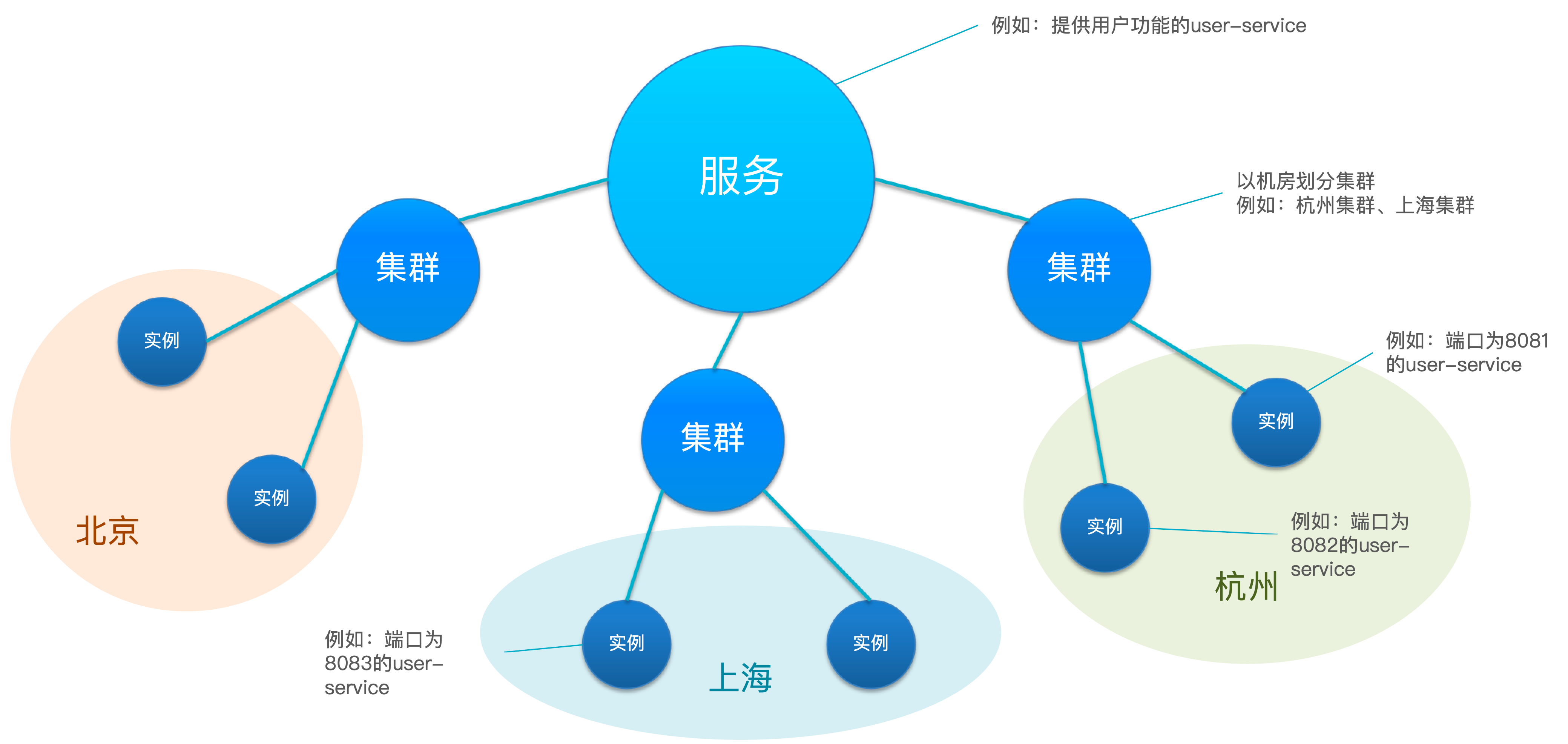
一个服务可以有多个实例,例如我们的 user-service,可以有
- 127.0.0.1:8081
- 127.0.0.1:8082
- 127.0.0.1:8083
假如这些实例分布于全国各地的不同机房,例如
- 127.0.0.1:8081,在杭州机房
- 127.0.0.1:8082,在杭州机房
- 127.0.0.1:8083,在上海机房
Nacos 就将在同一机房的实例,划分为一个集群,也就是说,user-service 是服务,一个服务可以包含多个集群,例如在杭州,上海,每个集群下可以有多个实例,形成分级模型
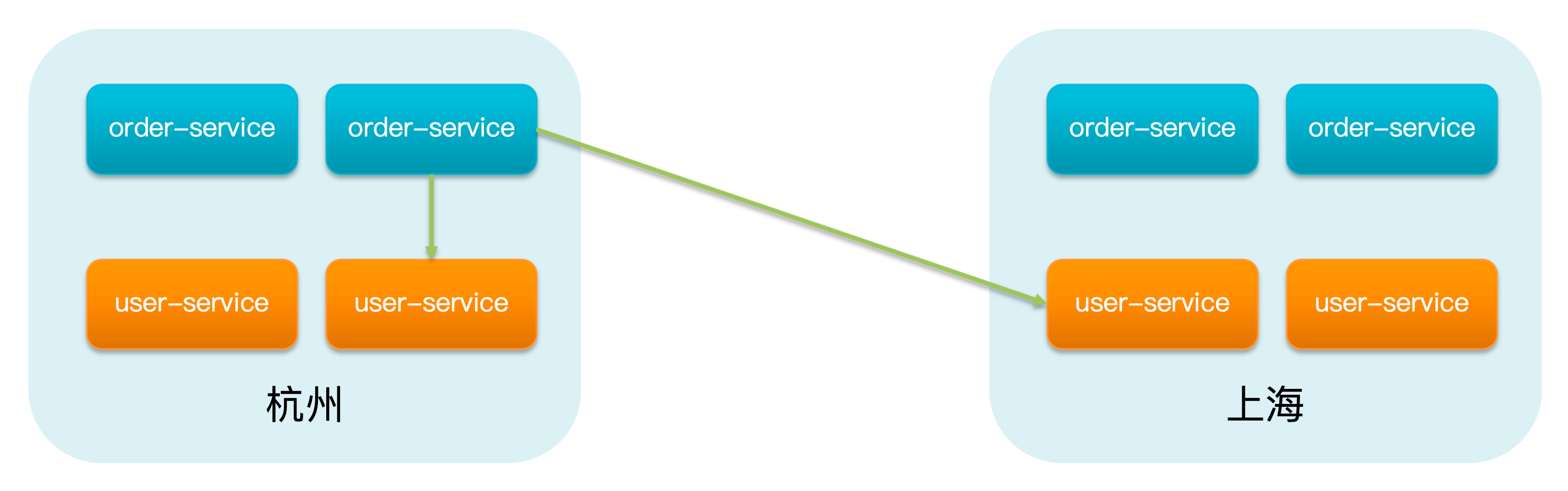
微服务相互访问时,应该尽可能访问同集群实例,因为本地访问速度更快,访问本集群内不可用时,才去访问其他集群
例如:杭州机房内的 order-service 应该有限访问同机房的 user-service,若无法访问,则去访问上海机房的 user-service
{% note success %}
Nacos服务分级存储模型
- 一级是服务,例如 user-service
- 二级是集群,例如杭州或上海
- 三级是实例,例如杭州机房的某台部署了 user-service 的服务器
{% endnote %}
配置集群
{% note info %}
默认都是在 DEFAULT 集群
{% endnote %}
修改配置文件,添加集群配置
yaml
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称,杭州重启两个 user-service 实例,之后我们再复制一个 user-service 的启动配置,端口号设为 8083,配置 Program arguments
bash
--spring.cloud.nacos.discovery.cluster-name=SH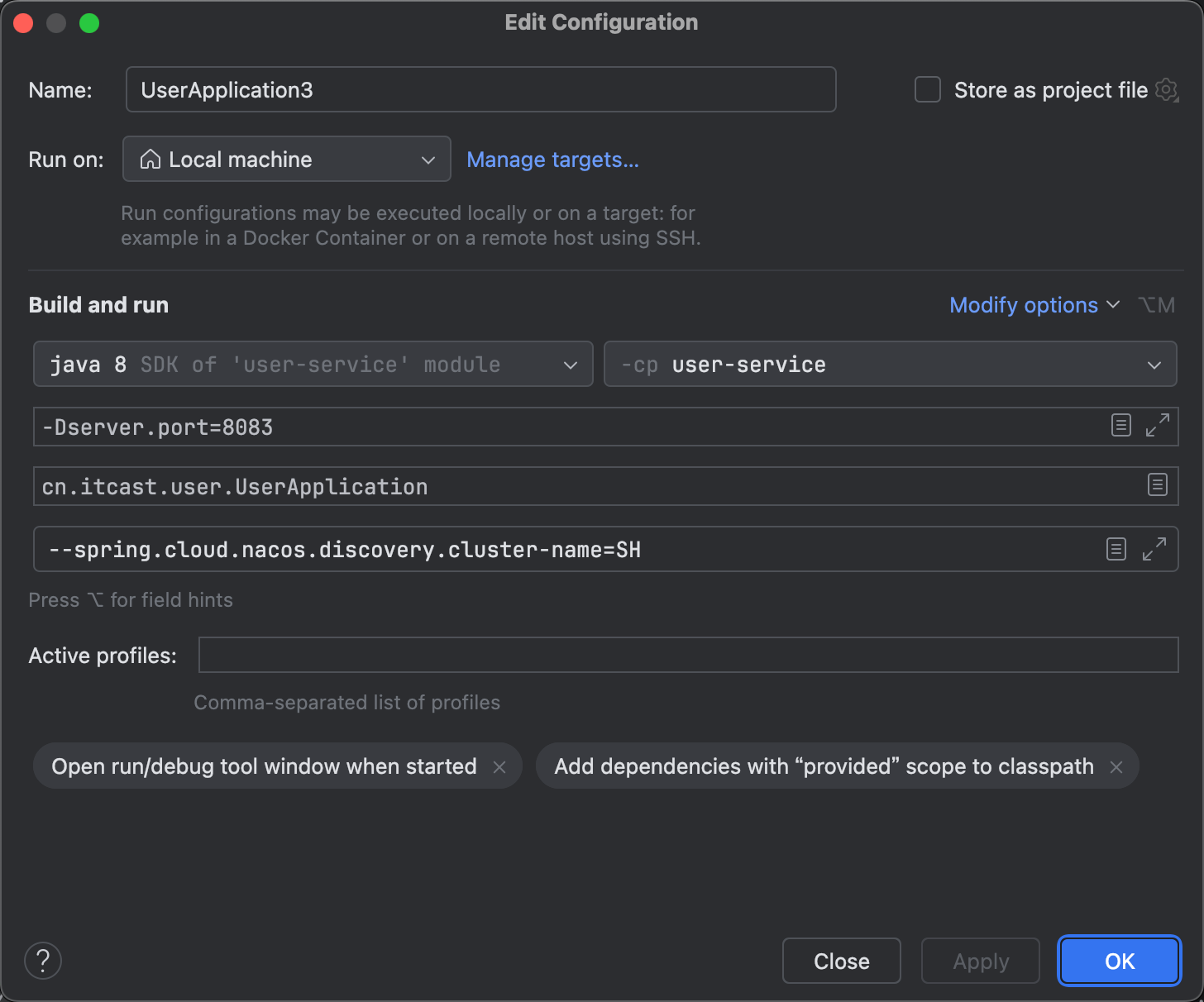
查看控制台效果
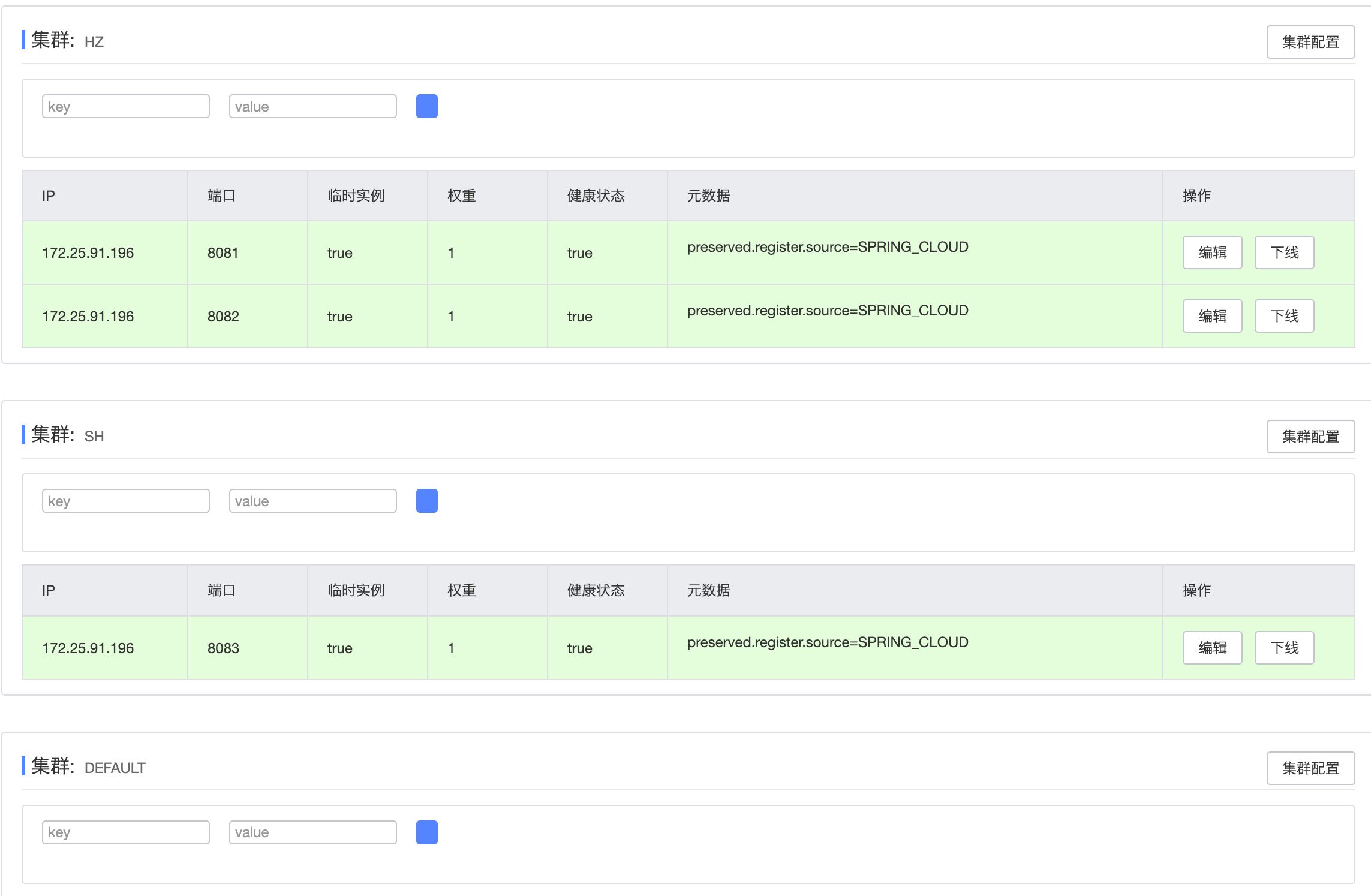
同集群优先的负载均衡
默认的 ZoneAvoidanceRule 并不能根据同集群优先来实现负载均衡
因此 Nacos 中提供了一个 NacosRule 的实现,可以优先从同集群中挑选实例
- 给 order-service 配置集群信息,修改其 application.yml 文件,将集群名称配置为 HZ
yaml
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ ## 集群名称,杭州- 修改负载均衡规则
yaml
user-service: ## 给某个微服务配置负载均衡规则,这里是user-service服务
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则之后再进行访问,集群名称为 HZ 的两个 user-service 可以看到日志输出,而集群名称为 SH 的 user-service 看不到日志输出
NacosRule 负载均衡策略
- 优先选择同一集群服务实例列表
- 本地集群找不到提供者,才去其他集群寻找,并且会报警告
- 确定了可用实例列表后,再采用随机负载均衡挑选实例,并不是轮询的负载均衡
权重配置
{% note info %}
这个是在 NacosRule 规则下才能配置权重
{% endnote %}
实际部署中肯定会出现这样的场景,服务器设备性能有差异,部分实例所在的机器性能较好,而另一些较差,那么肯定希望性能好的机器承担更多的用户请求,但默认情况下 NacosRule 是统计群内随机挑选,不会考虑机器性能的问题,因此 Nacos 提供了权重配置来控制访问频率,权重越大则访问频率越高,在 Nacos 控制台,找到 user-service 的实例列表,点击编辑,即可以修改权重,权重值范围在 0~1 之间

比如设置一个 0.1 一个 1,那么访问比例概率上基本上是 1:10
{% note info %}
若权重修改为 0,则该实例永远不会被访问。我们可以将某个服务实例的权重修改为 0,然后进行更新,然后也不会影响到用户的正常访问,因为其他服务实例还在运行,之后我们可以给更新后的该服务,设置一个很小的权重,这样就会有一小部分用户来访问该服务,测试该服务是否稳定(类似于灰度测试)
{% endnote %}
环境隔离
Nacos 提供了 namespace 来实现环境隔离功能
- nacos 中 可以有多个 namespace
- namespace 下可以由 group、service 等
- 不同的
namespace之间相互隔离,例如不同的 namespace 的服务互相不可见
创建 namespace
默认情况下,所有的 service、data、group 都是在同一个 namespace,名为 public
点击命名空间 -> 新建命名空间 -> 填写表单,可以创建一个新的 namespace
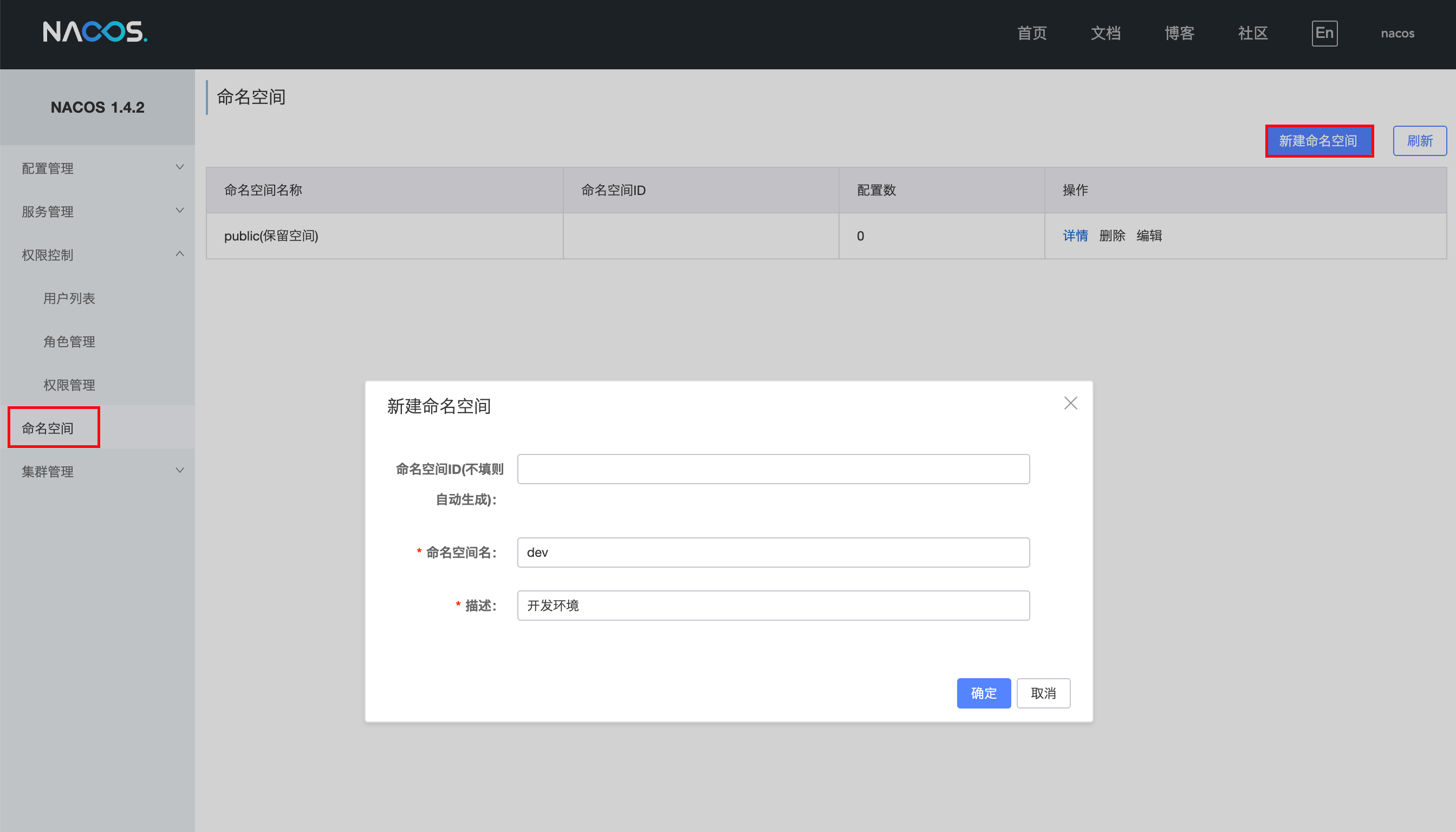
这个命名空间会生成一个 ID,这个要记住
给微服务配置 namespace
给微服务配置 namespace 只能通过修改配置来实现
例如,修改 order-service 的 application.yml 文件
yaml
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ
namespace: 89d7077f-52e5-4d87-bb7b-906815001fa5 # 命名空间,填上图中的命名空间ID重启 order-service 后,访问 Nacos 控制台,可以看到下面的结果,此时访问 order-service,因为 namespace 不同,会导致找不到 user-service,若访问http://localhost:8080/order/101 则会报错,No instances available for userservice
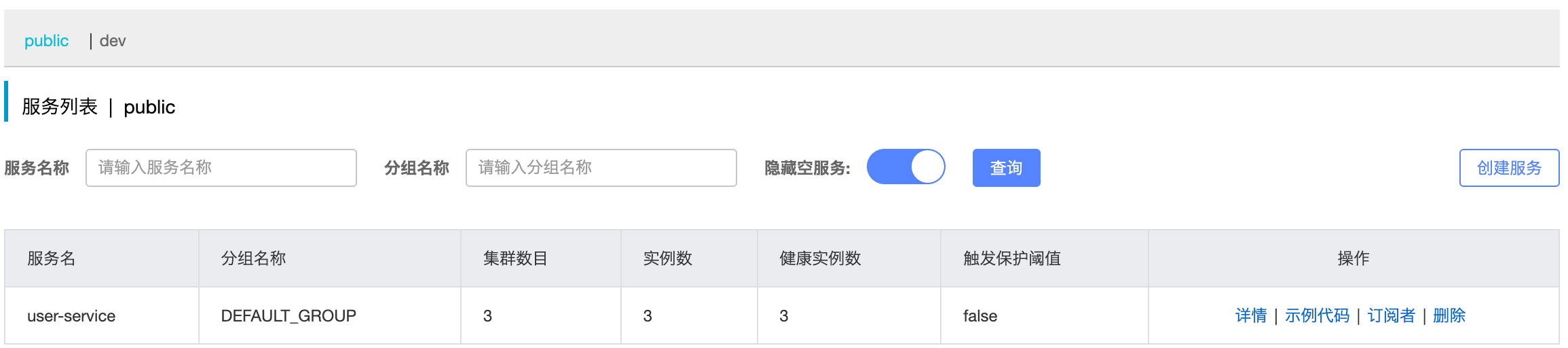
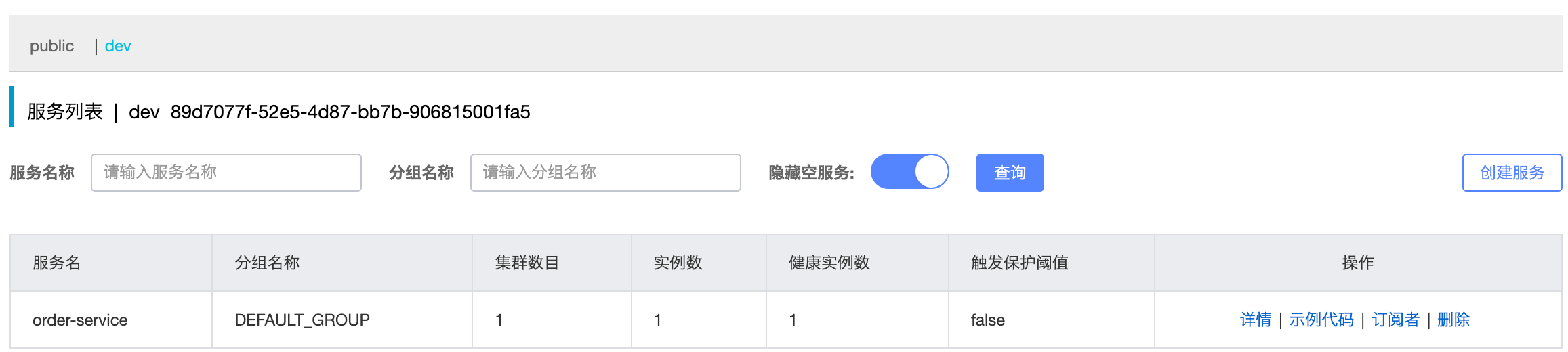
dev 下没有 user-service 服务,所以 order-servcie 找不到
Nacos 和 Eureka 的区别
Nacos 的服务实例可以分为两种类型
- 临时实例:如果实例宕机超过一定时间,会从服务列表剔除,默认为临时实例
- 非临时实例:如果实例宕机,不会从服务列表剔除,也可以叫永久实例
配置一个服务实例为永久实例
yaml
spring:
cloud:
nacos:
discovery:
ephemeral: false ## 设置为非临时实例Nacos 和 Eureka 整体结构类似,服务注册、服务拉取、心跳等待,但是也存在一些差异
Nacos 与 Eureka 的共同点
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康监测
Nacos 与 Eureka 的区别
- Nacos 支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式(但是对服务器压力比较大,不推荐)
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos 支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos 集群默认采用 AP 方式,当集群存在非临时实例时,采用 CP 模式;Eureka 采用 AP 方式
Nacos 配置管理
Nacos除了可以做注册中心,同样还可以做配置管理来使用
统一配置管理
当微服务部署的实例越来越多,达到数十、数百时,逐个修改微服务配置就会让人抓狂(还需要重启服务),而且容易出错,所以我们需要一种统一配置管理方案,可以集中管理所有实例的配置
Nacos 一方面可以将配置集中管理,另一方面可以在配置变更时,及时通知微服务,实现配置的热更新
在 Nacos 中添加配置文件
配置列表中点击加号
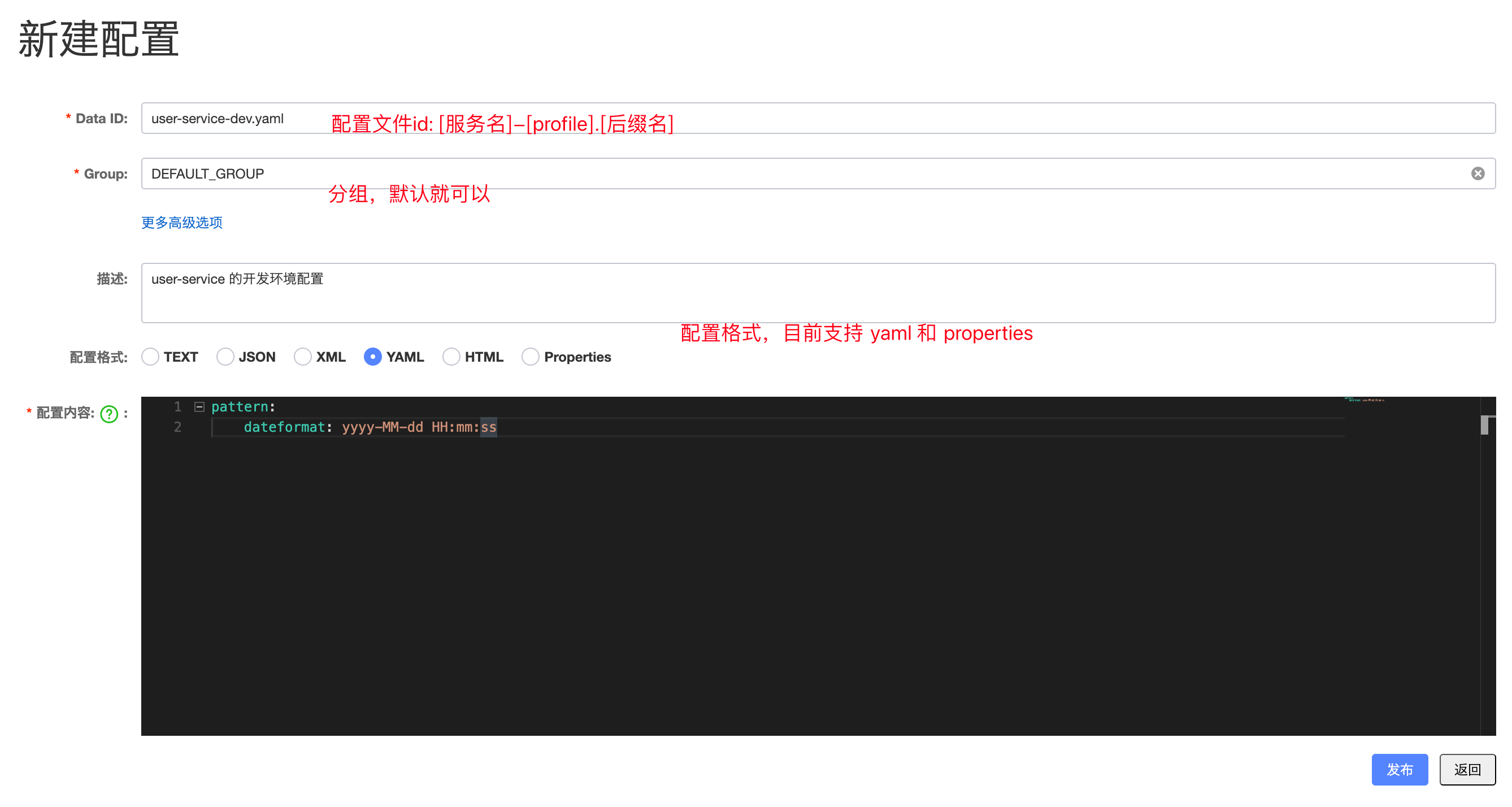
弹出的表单中,填写配置信息
{% note warning %}
只有需要热更新的配置才有放到 Nacos 管理的必要,基本不会变更的一些配置,还是保存到微服务本地比较好(例如数据库连接配置等)
{% endnote %}
微服务拉取配置

原来服务启动的时候,读取本地配置文件然后创建容器。
现在微服务要拉取 nacos 中管理的配置,并且与本地的 application.yml 配置合并,才能完成项目启动。
但如果尚未读取 application.yml,又如何得知 nacos 地址呢?
因此spring引入了一种新的配置文件:bootstrap.yaml 文件,会在 application.yml 之前被读取,流程如下:
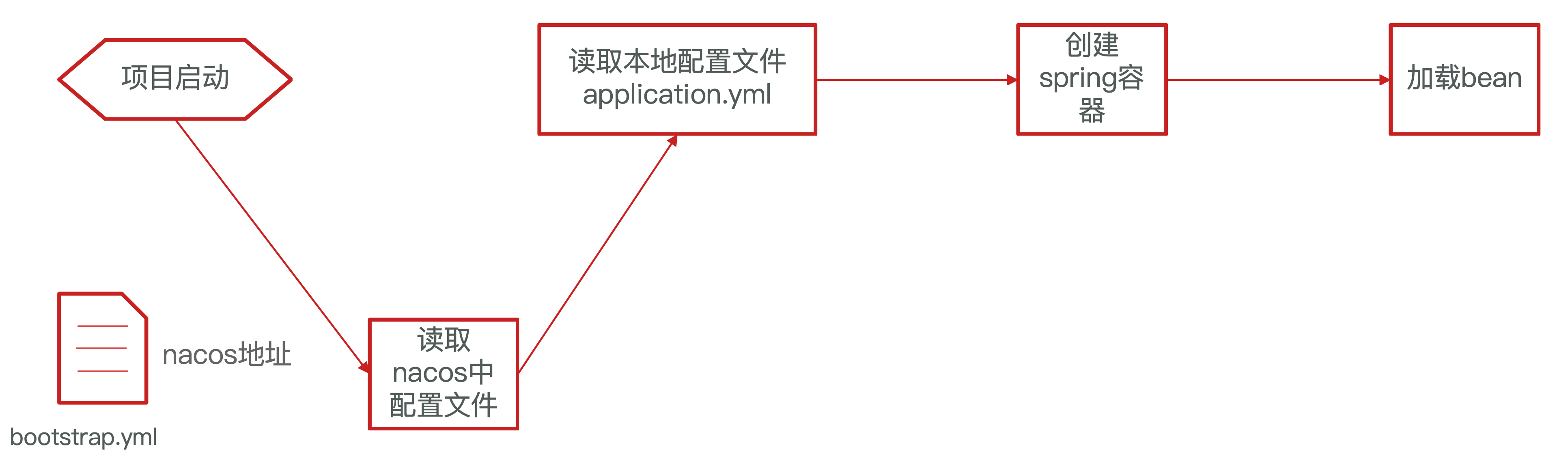
- 项目启动
- 加载 bootstrap.yml 文件,获取 Nacos 地址,配置文件 id
- 根据配置文件 id,读取 Nacos 中的配置文件
- 读取本地配置文件 application.yml,与 Nacos 拉取到的配置合并
- 创建 Spring 容器
- 加载 bean
引入 nacos-config 依赖
首先,在 user-service 服务中,引入 nacos-config 的客户端依赖:
xml
<!--nacos配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>添加 bootstrap.yaml
然后,在 user-service 中添加一个 bootstrap.yaml 文件,内容如下:
yaml
spring:
application:
name: user-service # 服务名称
profiles:
active: dev #开发环境,这里是dev
cloud:
nacos:
server-addr: localhost:8848 # Nacos地址
config:
file-extension: yaml # 文件后缀名这里会根据 spring.cloud.nacos.server-addr 获取 nacos 地址,再根据
${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension} 作为文件id,来读取配置。
本例中,就是去读取 user-service-dev.yaml。
{% note warning %}
既然 bootstrap.yaml 里面配置了去哪个 nacos,读那个配置文件,以及知道了自己的服务名称,那么在 application.yaml 中可以把这部分删掉了
{% endnote %}
读取nacos配置
在 user-service 中的 UserController 中添加业务逻辑,读取 pattern.dateformat 配置:
java
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Value("${pattern.dateformat}")
private String dateformat;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));
}
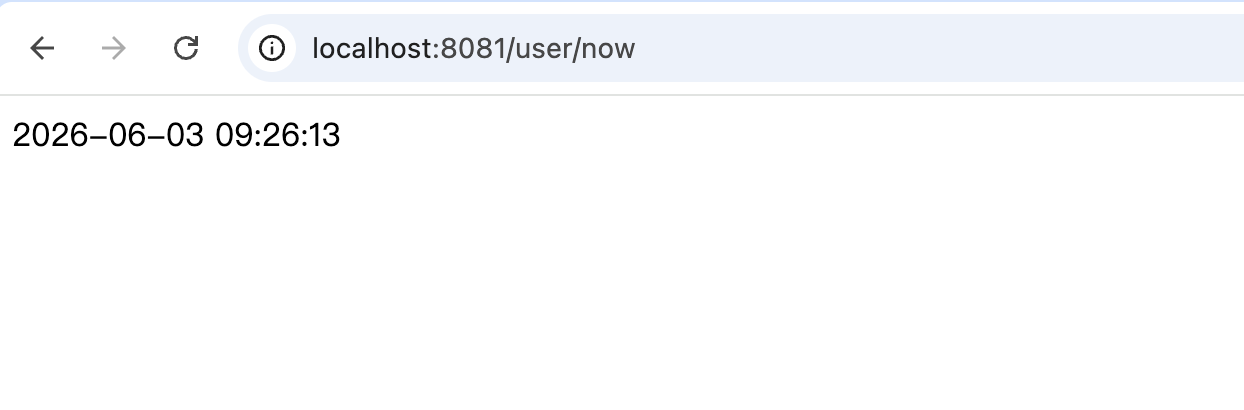
}在页面访问,可以看到效果:
配置热更新
我们最终的目的,是修改nacos中的配置后,微服务中无需重启即可让配置生效,也就是配置热更新。
要实现配置热更新,可以使用两种方式:
方式一
在 @Value 注入的变量所在类上添加注解 @RefreshScope
java
@RestController
@RequestMapping("/user")
@RefreshScope
public class UserController {
@Autowired
private UserService userService;
@Value("${pattern.dateformat}")
private String dateformat;
}方式二
使用 @ConfigurationProperties 注解代替 @Value 注解。
{% note info %}
@ConfigurationProperties 是 Spring 的注解,不是 Nacos 新搞的注解,而 @RefreshScope 注解所在包如下
java
package org.springframework.cloud.context.config.annotation;{% endnote %}
在 user-service 服务中,添加一个类,读取 patterrn.dateformat 属性
java
package cn.itcast.user.config;
@Component
@Data
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat;
}在 UserController 中使用这个类代替 @Value
java
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Autowired
private PatternProperties patternProperties;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat()));
}
}也能同样实现热更新(项目启动后,我在 Nacos 修改配置文件,可以做到不用重启项目就能热更新配置属性)
配置共享
有的时候,无论是生产环境还是开发环境,都是使用的相同的配置,如果这种配置发生变动,就会修改多个配置文件,很麻烦,怎么解决?
其实微服务启动时,会去 nacos 读取多个配置文件,例如:
-
[spring.application.name]-[spring.profiles.active].yaml,例如:user-service-dev.yaml -
[spring.application.name].yaml,例如:user-service.yaml
而 [spring.application.name].yaml 不包含环境信息,一定会被加载,因此可以被多个环境共享。
下面我们通过案例来测试配置共享
添加一个环境共享配置
我们在 nacos 中添加一个 userservice.yaml 文件:
yaml
pattern:
envSharedValue: 多环境共享属性值在 user-service 中读取共享配置
在 user-service 服务中,修改 PatternProperties 类,读取新添加的属性
java
@Component
@Data
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat;
private String envSharedValue;
}在 user-service 服务中,修改 UserController,添加一个方法
java
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private PatternProperties patternProperties;
@GetMapping("/prop")
public PatternProperties prop(){
return patternProperties;
}
}运行两个UserApplication,使用不同的profile
修改 UserApplication2 这个启动项,改变其profile值:
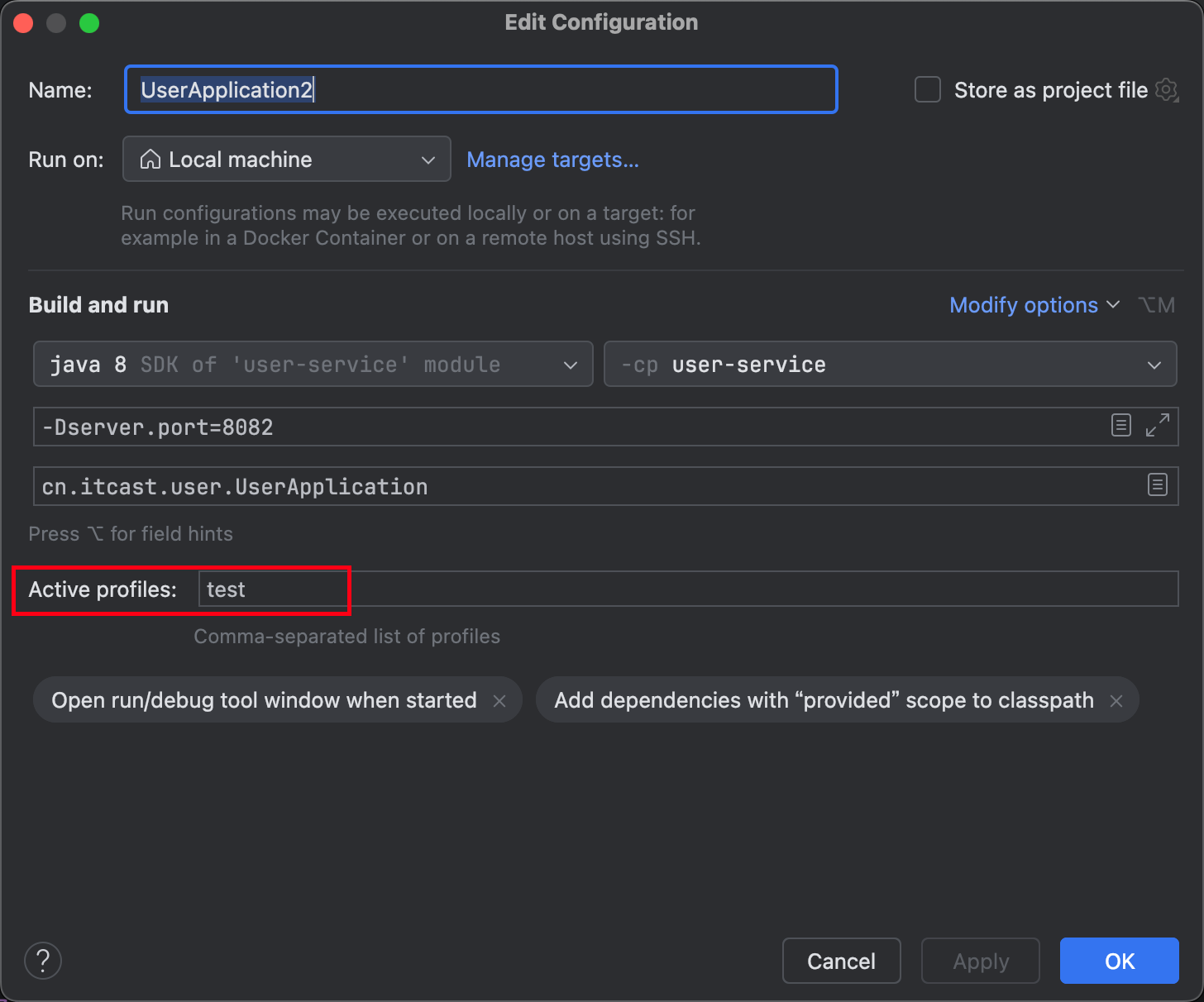
这样,UserApplication(8081)使用的 profile 是 dev,UserApplication2(8082) 使用的 profile 是 test。
启动 UserApplication 和 UserApplication2,访问 http://localhost:8081/user/prop 访问 http://localhost:8082/user/prop 可以看出来,不管是 dev,还是 test 环境,都读取到了 envSharedValue 这个属性的值。
json
// UserApplication
{
"dateformat": "yyyy/MM/dd HH:mm:ss",
"envSharedValue": "多环境共享属性值",
}
// UserApplication2
{
"dateformat": null,
"envSharedValue": "多环境共享属性值",
}配置共享的优先级
当 nacos、服务本地同时出现相同属性时,优先级有高低之分:

- user-service-dev.yaml > user-service.yaml > application.yaml
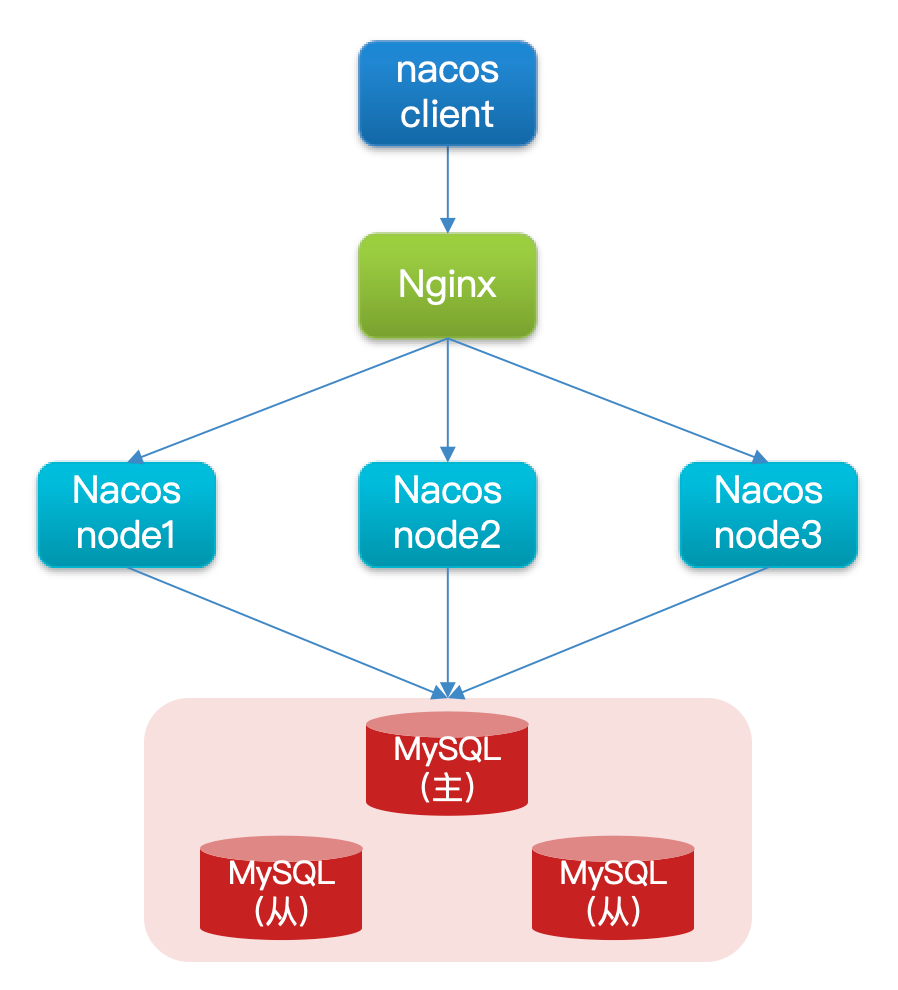
搭建Nacos集群
集群架构图
Nacos 生产环境下一定要部署为集群状态
{% note info %}
原来 Nacos 的一些数据信息是存在内置数据库 Derby 中,生产中是不可用的,你想在分布式下实现数据一致,得找一个外部数据库来用,用它来持久化配置和管理数据。
{% endnote %}
三个nacos节点的地址:
| 节点 | ip | port |
|---|---|---|
| nacos1 | 192.168.150.1 | 8845 |
| nacos2 | 192.168.150.1 | 8846 |
| nacos3 | 192.168.150.1 | 8847 |
搭建集群
搭建数据库
初始化数据库表结构
sql
CREATE TABLE `config_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) DEFAULT NULL,
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
`c_desc` varchar(256) DEFAULT NULL,
`c_use` varchar(64) DEFAULT NULL,
`effect` varchar(64) DEFAULT NULL,
`type` varchar(64) DEFAULT NULL,
`c_schema` text,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_aggr */
/******************************************/
CREATE TABLE `config_info_aggr` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) NOT NULL COMMENT 'group_id',
`datum_id` varchar(255) NOT NULL COMMENT 'datum_id',
`content` longtext NOT NULL COMMENT '内容',
`gmt_modified` datetime NOT NULL COMMENT '修改时间',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='增加租户字段';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_beta */
/******************************************/
CREATE TABLE `config_info_beta` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`beta_ips` varchar(1024) DEFAULT NULL COMMENT 'betaIps',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_beta';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_tag */
/******************************************/
CREATE TABLE `config_info_tag` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`tag_id` varchar(128) NOT NULL COMMENT 'tag_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_tag';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_tags_relation */
/******************************************/
CREATE TABLE `config_tags_relation` (
`id` bigint(20) NOT NULL COMMENT 'id',
`tag_name` varchar(128) NOT NULL COMMENT 'tag_name',
`tag_type` varchar(64) DEFAULT NULL COMMENT 'tag_type',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`nid` bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`nid`),
UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_tag_relation';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = group_capacity */
/******************************************/
CREATE TABLE `group_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`group_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_group_id` (`group_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='集群、各Group容量信息表';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = his_config_info */
/******************************************/
CREATE TABLE `his_config_info` (
`id` bigint(64) unsigned NOT NULL,
`nid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`data_id` varchar(255) NOT NULL,
`group_id` varchar(128) NOT NULL,
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL,
`md5` varchar(32) DEFAULT NULL,
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`src_user` text,
`src_ip` varchar(50) DEFAULT NULL,
`op_type` char(10) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`nid`),
KEY `idx_gmt_create` (`gmt_create`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_did` (`data_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='多租户改造';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = tenant_capacity */
/******************************************/
CREATE TABLE `tenant_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tenant_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Tenant ID',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='租户容量信息表';
CREATE TABLE `tenant_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`kp` varchar(128) NOT NULL COMMENT 'kp',
`tenant_id` varchar(128) default '' COMMENT 'tenant_id',
`tenant_name` varchar(128) default '' COMMENT 'tenant_name',
`tenant_desc` varchar(256) DEFAULT NULL COMMENT 'tenant_desc',
`create_source` varchar(32) DEFAULT NULL COMMENT 'create_source',
`gmt_create` bigint(20) NOT NULL COMMENT '创建时间',
`gmt_modified` bigint(20) NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='tenant_info';
CREATE TABLE `users` (
`username` varchar(50) NOT NULL PRIMARY KEY,
`password` varchar(500) NOT NULL,
`enabled` boolean NOT NULL
);
CREATE TABLE `roles` (
`username` varchar(50) NOT NULL,
`role` varchar(50) NOT NULL,
UNIQUE INDEX `idx_user_role` (`username` ASC, `role` ASC) USING BTREE
);
CREATE TABLE `permissions` (
`role` varchar(50) NOT NULL,
`resource` varchar(255) NOT NULL,
`action` varchar(8) NOT NULL,
UNIQUE INDEX `uk_role_permission` (`role`,`resource`,`action`) USING BTREE
);
INSERT INTO users (username, password, enabled) VALUES ('nacos', '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu', TRUE);
INSERT INTO roles (username, role) VALUES ('nacos', 'ROLE_ADMIN');配置 Nacos
我们进入 Nacos 的 conf 目录,修改配置文件 cluster.conf.example,重命名为 cluster.conf,然后添加内容,如果后面启动报错了,就把这里的 127.0.0.1 换成本机真实IP
bash
127.0.0.1:8845
127.0.0.1:8846
127.0.0.1:8847
替换掉上面这三个
然后修改 application.properties 文件,添加数据库配置
properties
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root
db.password.0=root启动 Nacos 集群
将 nacos 文件夹复制 3 份,分别命名为:nacos1、nacos2、nacos3
然后分别修改这三个文件夹中的 application.properties
nacos1
properties
server.port=8845nacos2
properties
server.port=8846nacos3
properties
server.port=8847{% note info %}
理解一下这个流程,正常来说,我们先配数据库,就是存放那些配置信息、服务信息,让 Nacos 集群都从这个里面读写来保证数据一致,这个表结构是官网给我,他们定义的规则。之后,我们配置 Nacos 的集群,正常来说是三台服务器下,每个 Nacos 都配置上其他服务器 Nacos 的IP+端口(第一步做的),还有读取的数据库信息,也就是上面我们做的。
这里为了模拟,我们是三个不同的端口各启动一个 Nacos 模拟集群
{% endnote %}
Nginx 反向代理
修改 conf/nginx.conf 文件,将下面的配置粘贴到 http 块中
nginx
upstream nacos-cluster {
server 127.0.0.1:8845;
server 127.0.0.1:8846;
server 127.0.0.1:8847;
}
server {
listen 80;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}启动 nginx,然后在浏览器访问 http://localhost/nacos 即可(因为 http 请求访问的就是80端口,不写端口号默认 80)
同时将 bootstrap.yml 中的 Nacos 地址修改为localhost:80,user-service 和 order-service 中都改
yaml
spring:
cloud:
nacos:
server-addr: localhost:80 ## Nacos地址重启服务,在 Nacos 中可以看到管理的服务
{% note warning %}
这是通过 Nginx 反向代理实现对 Nacos 的访问,并且实现了负载均衡,可以不用 80 端口的哈,换个端口也一样
{% endnote %}
Feign 远程调用
先来看我们以前利用 RestTemplate 发起远程调用的代码
java
String url = "http://user-service/user/" + order.getUserId();
User user = restTemplate.getForObject(url, User.class);存在下面的问题:
- 代码可读性差,编程体验不统一(里面参杂着 URL,和业务不相关)
- 参数复杂 URL 难以维护
我们可以利用 Feign 来解决上面提到的问题,Feign 是一个声明式的 http 客户端,官方地址:https://github.com/OpenFeign/feign
其作用就是帮助我们优雅的实现 http 请求的发送,解决上面提到的问题。
Feign 替代 RestTemplate
引入依赖
我们在 order-service 服务的 pom 文件中引入 feign 的依赖:
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>添加注解
在 order-service 的启动类上添加 @EnableFeignClients 注解,开启 Feign 的功能
编写 Feign的客户端
在 order-service 中新建一个接口,内容如下
java
package com.itcast.order.client
@FeignClient("userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id); // 方法名无所谓
}这个客户端主要是基于 SpringMVC 的注解来声明远程调用的信息,比如:
- 服务名称:userservice
- 请求方式:GET
- 请求路径:/user/{id}
- 请求参数:Long id
- 返回值类型:User
这样,Feign 就可以帮助我们发送 http 请求,无需自己使用 RestTemplate 来发送了。
测试
修改 order-service 中的 OrderService 类中的 queryOrderById 方法,使用 Feign 客户端代替 RestTemplate
diff
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
- @Autowired
- private RestTemplate restTemplate;
+ @Autowired
+ private UserClient userClient;
public Order queryOrderById(Long orderId) {
Order order = orderMapper.findById(orderId);
- String url = "http://user-service/user/" + order.getUserId();
- User user = restTemplate.getForObject(url, User.class);
+ User user = userClient.findById(order.getUserId());
order.setUser(user);
return order;
}
}{% note danger no-icon %}
原来 RestTemplate 怎么做负载均衡的?Fegin 怎么做?
原来 RestTemplate 可以通过 IRule + @Bean 配置负载规则,或者通过配置文件编写的方式,但是开启负载均衡还需要一个 @LoadBalanced 注解。但是 Fegin 不需要,它不需要开启,只要在启动类加上了 @EnableFeignClients,就有服务发现+负载均衡,底层还是 Ribbon,负载规则配置可以使用原来同样的方式
{% endnote %}
自定义配置
Feign可以支持很多的自定义配置,如下表所示:
| 类型 | 作用 | 说明 |
|---|---|---|
| feign.Logger.Level | 修改日志级别 | 包含四种不同的级别:NONE、BASIC、HEADERS、FULL |
| feign.codec.Decoder | 响应结果的解析器 | http远程调用的结果做解析,例如解析 json 字符串为 java 对象 |
| feign.codec.Encoder | 请求参数编码 | 将请求参数编码,便于通过 http 请求发送 |
| feign.Contract | 支持的注解格式 | 默认是 SpringMVC 的注解 |
| feign.Retryer | 失败重试机制 | 请求失败的重试机制,默认是没有,不过会使用 Ribbon 的重试,相当于有了 |
一般情况下,默认值就能满足我们使用,如果要自定义时,只需要创建自定义的 @Bean 覆盖默认 Bean 即可。
下面以日志为例来演示如何自定义配置。
配置文件方式
基于配置文件修改feign的日志级别可以针对单个服务:
yaml
feign:
client:
config:
userservice: # 针对某个微服务的配置
loggerLevel: FULL # 日志级别 也可以针对所有服务:
yaml
feign:
client:
config:
default: # 这里用 default 就是全局配置,如果是写服务名称,则是针对某个微服务的配置
loggerLevel: FULL # 日志级别 而日志的级别分为四种:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在 BASIC 的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Java 代码方式
也可以基于 Java 代码来修改日志级别,先声明一个类,然后声明一个 Logger.Level 的对象:
java
public class DefaultFeignConfiguration { // 上面没有注解,没有后续操作是不会生效的
@Bean
public Logger.Level feignLogLevel(){ // feign.Logger 下的 Level
return Logger.Level.BASIC; // 日志级别为BASIC
}
}如果要全局生效 ,将其放到启动类的 @EnableFeignClients 这个注解中:
java
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class) 如果是局部生效 ,则把它放到对应的 @FeignClient 这个注解中:
java
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class) Feign 使用优化
Feign 底层发起 http 请求,依赖于其它的框架。其底层客户端实现包括:
- URLConnection:默认实现,不支持连接池
- Apache HttpClient :支持连接池
- OKHttp:支持连接池
因此提高 Feign 的性能主要手段就是使用连接池代替默认的 URLConnection。
这里我们用 Apache 的 HttpClient 来演示。
引入依赖
在 order-service 的 pom 文件中引入 Apache 的 HttpClient 依赖:
xml
<!--httpClient的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>配置连接池
在 order-service 的 application.yml 中添加配置:
yaml
feign:
client:
config:
default: # default全局的配置
loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息
httpclient:
enabled: true # 开启feign对HttpClient的支持
max-connections: 200 # 最大的连接数
max-connections-per-route: 50 # 每个路径的最大连接数{% note success %}
Feign 性能优化总结
- 日志级别尽量用 basic 或 none
- 使用 HttpClient 或 OKHttp 代替 URLConnection
- 引入 feign-httpClient 依赖
- 配置文件开启 httpClient 功能,设置连接池参数
{% endnote %}
最佳实践
仔细观察可以发现,Feign 的客户端与服务提供者的 controller 代码非常相似
{% tabs 最佳实践代码相似 , 1 %}
java
@FeignClient("userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
java
@RequestMapping("/user")
public class UserController {
@GetMapping("/{id}")
public User queryById(@PathVariable("id") Long id) { // 方法名无所谓
return userService.queryById(id);
}
}{% endtabs %}
有没有一种办法简化这种重复的代码编写呢?
继承方式
一样的代码可以通过继承来共享:
- 定义一个API接口,利用定义方法,并基于 SpringMVC 注解做声明
java
public interface UserAPI{
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}- Feign 客户端和 Controller 都集成改接口
{% tabs 最佳实践继承方式 , 1 %}
java
@FeignClient(value = "user-service")
public interface UserClient extends UserAPI{}
java
@RestController
public class UserController implents UserAPI{
public User findById(@PathVariable("id") Long id){ // PathVariable 还要再次声明
// ...实现业务逻辑
}
}{% endtabs %}
优点
- 简单
- 实现了代码共享
缺点
- 服务提供方、服务消费方紧耦合
- 参数列表中的注解映射并不会继承,因此 Controller 中必须再次声明方法、参数列表、注解

抽取方式
将 Feign 的 Client 抽取为独立模块,并且把接口有关的 POJO、默认的 Feign 配置都放到这个模块中,提供给所有消费者使用。
例如,将 UserClient、User、Feign 的默认配置都抽取到一个 feign-api 包中,所有微服务引用该依赖包,即可直接使用。
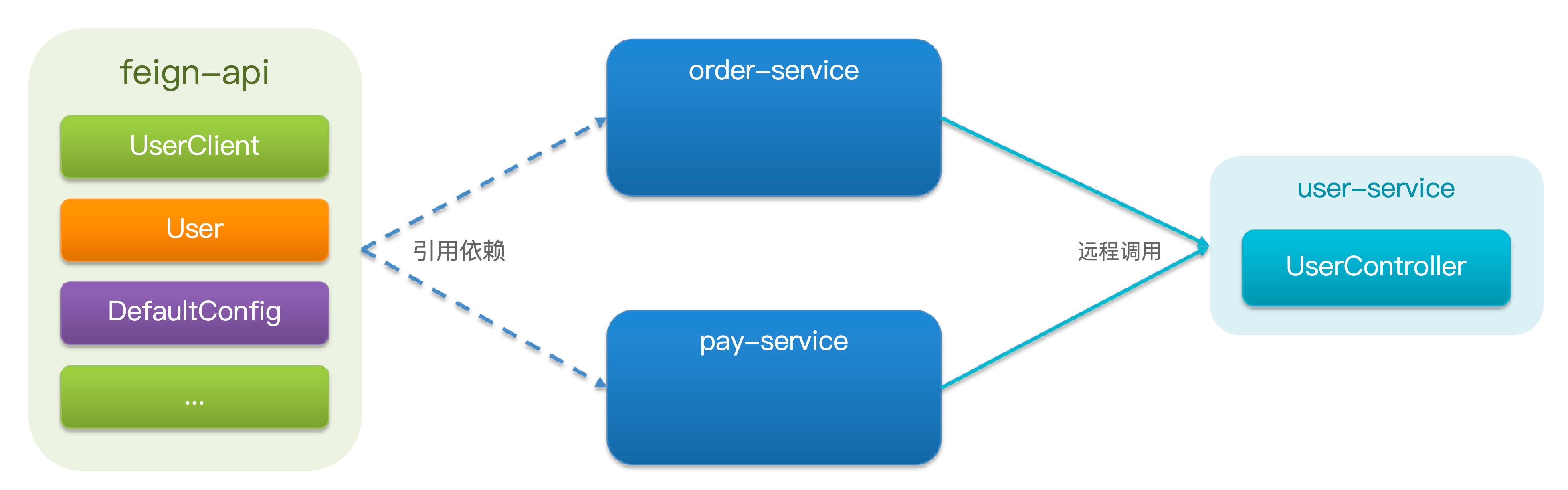
缺点就是我可能只用 UserClient 中的一两个方法,但是还是把所有的都引入了。
实现基于抽取的最佳实践
抽取
首先创建一个 module,命名为 feign-api,在 feign-api 中然后引入 feign 的 starter 依赖
xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>然后,order-service 中编写的 UserClient、User、DefaultFeignConfiguration 都复制到 feign-api 项目中
,项目结构
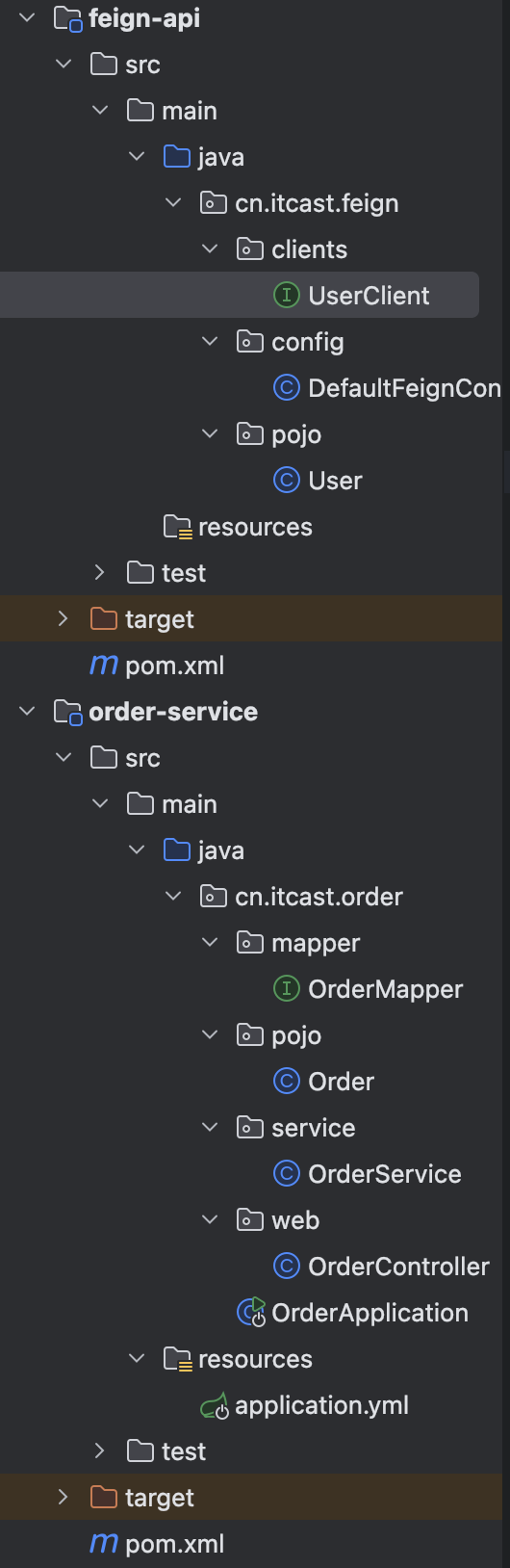
{% note info %}
也挺好,order-service 里面基本不参杂关于任何 feign 的代码了(启动类还是要开启扫描的)
{% endnote %}
在 order-servic e中使用 feign-api
首先,删除 order-service 中的 UserClient、User、DefaultFeignConfiguration 等类或接口。
在 order-service 的 pom 文件中中引入 feign-api 的依赖
xml
<dependency>
<groupId>cn.itcast.demo</groupId>
<artifactId>feign-api</artifactId>
<version>1.0</version>
</dependency>修改 order-service 中的所有与上述三个组件有关的导包部分,改成导入 feign-api 中的包
解决扫描包问题
因为 order-service 的 OrderApplication 默认扫描包是自己的类包,扫不到 feign-api 包下的 @EnableFeignClients 注解,所以没办法加入 Spring 容器
-
方式一:指定 Feign 应该扫描的包
java@EnableFeignClients(basePackages = "cn.itcast.feign.clients")这种就是全局的,把这个下面所有的
@EnableFeignClients注解的类都加入容器 -
方式二:指定需要加载的Client接口
java@EnableFeignClients(clients = {UserClient.class})只加载需要的
Gateway 网关
SpringCloudGateway 是 SpringCloud 的一个全新项目,该项目是基于 Spring 5.0,SpringBoot2.0 和 ProjectReactor 等响应式办成和事件流技术开发的网关,它旨在为微服务框架提供一种简单有效的统一的API路由管理方式
为什么需要网关
Gateway网关是服务的守门神,是所有微服务的统一入口
网关的核心功能特性
- 请求路由
- 权限控制
- 限流
架构图如下
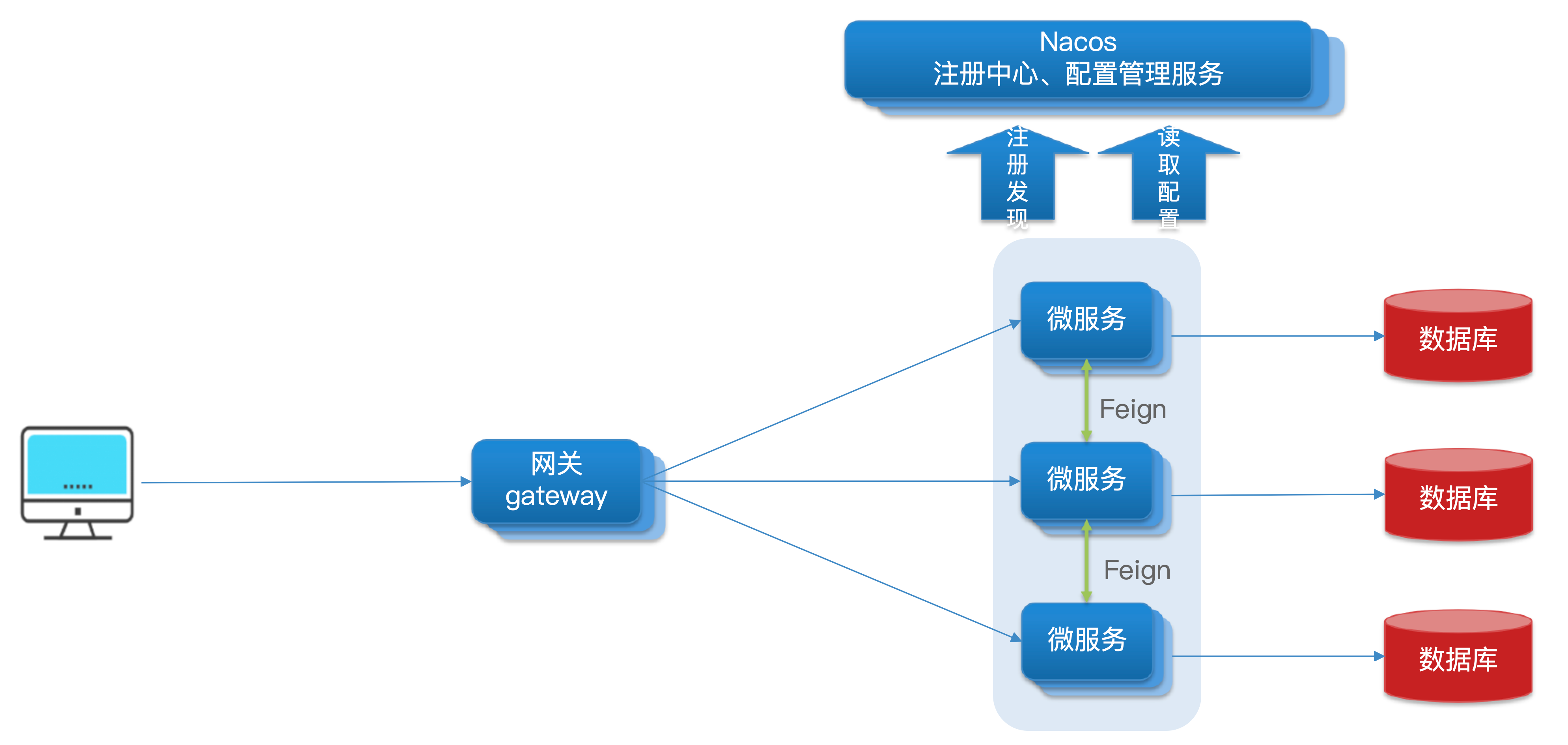
路由和负载均衡:一切请求都必须先经过 gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫路由。当然路由的目标服务有多个时,还需要做负载均衡(这里的负载均衡和 Nacos 的不同,Nacos 的是微服务之间相互调用时的负载均衡,但是这里是比如用户客户端发起 /user/** 请求时的负载均衡)
权限控制:网关作为微服务的入口,需要校验用户是否有请求资格,如果没有则拦截
限流:当请求量过高时,在网关中按照微服务能够接受的速度来放行请求,避免服务压力过大
在 SpringCloud 中网关的实现包括两种
- gateway
- zuul
Zuul 是基于 Servlet 的实现,属于阻塞式编程。而 SpringCloudGateway 则是基于 Spring5 中提供的 WebFlux,属于响应式编程的实现,具备更好的性能
搭建网关服务
创建一个 gateway 服务(他也是一个微服务),引入网关依赖
xml
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>添加启动类
java
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}编写基础配置和路由规则
yaml
server:
port: 10010 # 网关端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址(也可以用的 nginx 反向代理,这里写 localhost:80,然后向 nacos 集群发请求)
gateway:
routes:
- id: user-service ## 路由id,自定义,只需要唯一即可,这里就用服务名
uri: lb://user-service ## 路由的目标地址,lb表示负载均衡,后面跟服务名称
## uri: http://localhost:8081 ## 路由的目标地址,http就是固定地址
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** ## 这个是按照路径匹配,只要是以/user开头的,就符合规则
- id: order-service ## 按照上面的写法,再配置一下order-service
uri: lb://order-service
predicates:
- Path=/order/**路由配置包括
- 路由id:路由的唯一表示
- 路由目标(uri):路由的目标地址,http代表固定地址,lb(LoadBalance) 代表根据服务名称负载均衡
- 路由断言(predicates):判断路由的规则
- 路由过滤器(filters):对请求或相应做处理
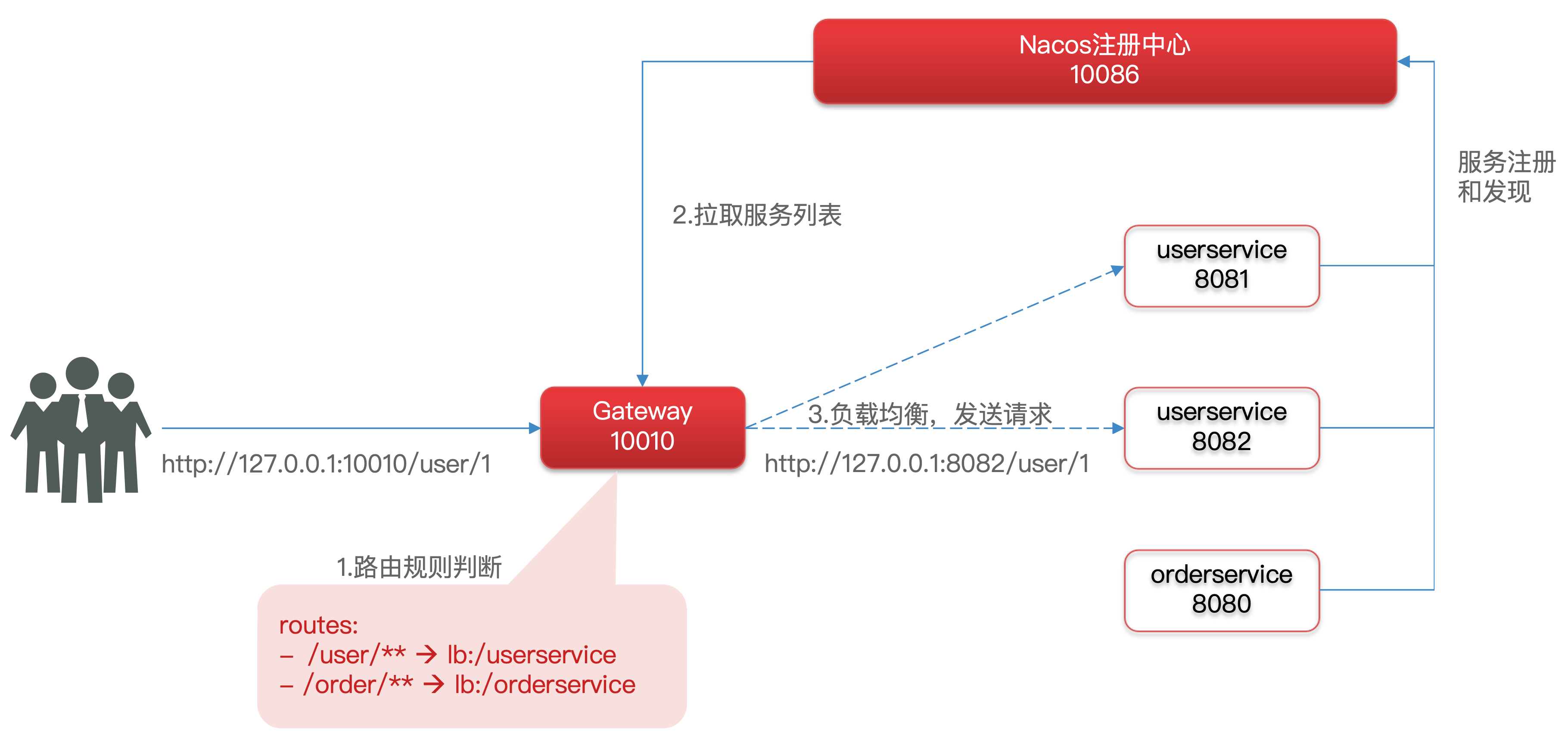
最后启动网关测试,访问 http://localhost:10010/user/1 ,能访问到!注意这是网关拦截转发的

下面详细学一下路由断言和路由过滤器的详细知识
路由断言工厂
Route Predicate Factory
我们在配置文件中写的断言规则只是字符串,这些字符串会被 Predicate Factory 读取并处理,转变为路由判断的条件
例如 Path=/user/** 是按照路径匹配,这个规则是由 org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory 类来处理的,像这样的断言工厂,在 SpringCloudGatewway 还有十几个
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00America/Denver |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00Asia/Shanghai |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00America/Denver, 2037-01-21T17:42:47.789-07:00America/Denver |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 |
要用的时候可以去官网查查看
{% note warning %}
注意多种断言可以 And 或者 Or,用的时候再查
{% endnote %}
路由过滤器
GatewayFilter
GatewayFilter 是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理
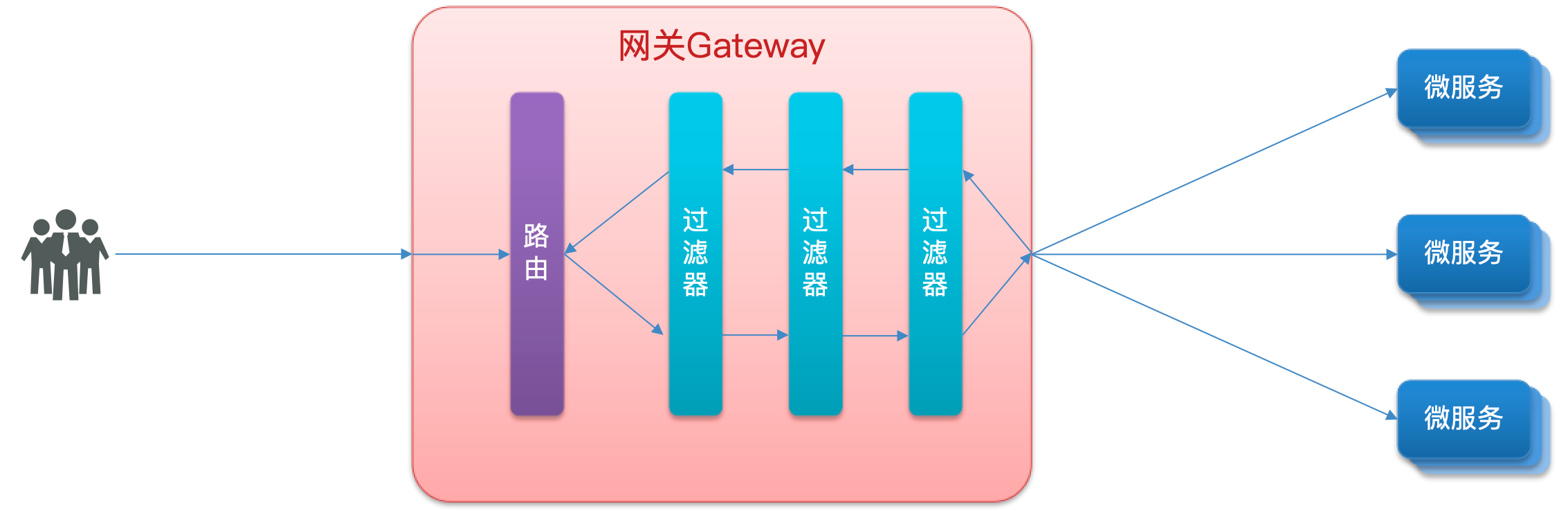
Spring提供了31种不同的路由过滤器工厂。例如:
| 名称 | 说明 |
|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
请求头过滤器
下面我们以 AddRequestHeader 为例来讲解。
需求:给所有进入 userservice 的请求添加一个请求头:Truth=itcast is freaking awesome!
只需要修改 gateway 服务的 application.yml 文件,添加路由过滤即可:
yaml
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
filters: # 过滤器
- AddRequestHeader=Truth, Itcast is freaking awesome! # 添加请求头当前过滤器写在 userservice 路由下,因此仅仅对访问 userservice 的请求有效。
默认过滤器
如果要对所有的路由都生效,则可以将过滤器工厂写到 default 下。格式如下:
yaml
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
default-filters: # 默认过滤项
- AddRequestHeader=Truth, Itcast is freaking awesome! 全局过滤器
GlobalFilter
上一节学习的过滤器,网关提供了31种,但每一种过滤器的作用都是固定的。如果我们希望拦截请求,做自己的业务逻辑则没办法实现。
全局过滤器作用
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与 GatewayFilter 的作用一样。区别在于 GatewayFilter通 过配置定义,处理逻辑是固定的;而 GlobalFilter 的逻辑需要自己写代码实现。
定义方式是实现 GlobalFilter 接口。
java
public interface GlobalFilter {
/**
* 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理
*
* @param exchange 请求上下文,里面可以获取Request、Response等信息
* @param chain 用来把请求委托给下一个过滤器
* @return {@code Mono<Void>} 返回标示当前过滤器业务结束
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}在 filter 中编写自定义逻辑,可以实现下列功能:
- 登录状态判断
- 权限校验
- 请求限流等
自定义全局过滤器
需求:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件
- 参数中是否有 authorization
- authorization 参数值是否为 admin
如果同时满足则放行,否则拦截
在 gateway 模块下新建 cn.itcast.gateway.filter 包,然后在其中编写 AuthorizationFilter 类,实现 GlobalFilter 接口,重写其中的 filter 方法
java
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求参数
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.获取authorization参数
String auth = params.getFirst("authorization");
// 3.校验
if ("admin".equals(auth)) {
// 放行
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
// 4.2.结束处理
return exchange.getResponse().setComplete();
}
}@Order(-1) 设置顺序,因为如果有多个全局过滤器,他们之间需要一个执行顺序排序。除了用这个注解也可以实现一个接口 Ordered,重写里面的 getOrder() 方法返回排序大小。
过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和 DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
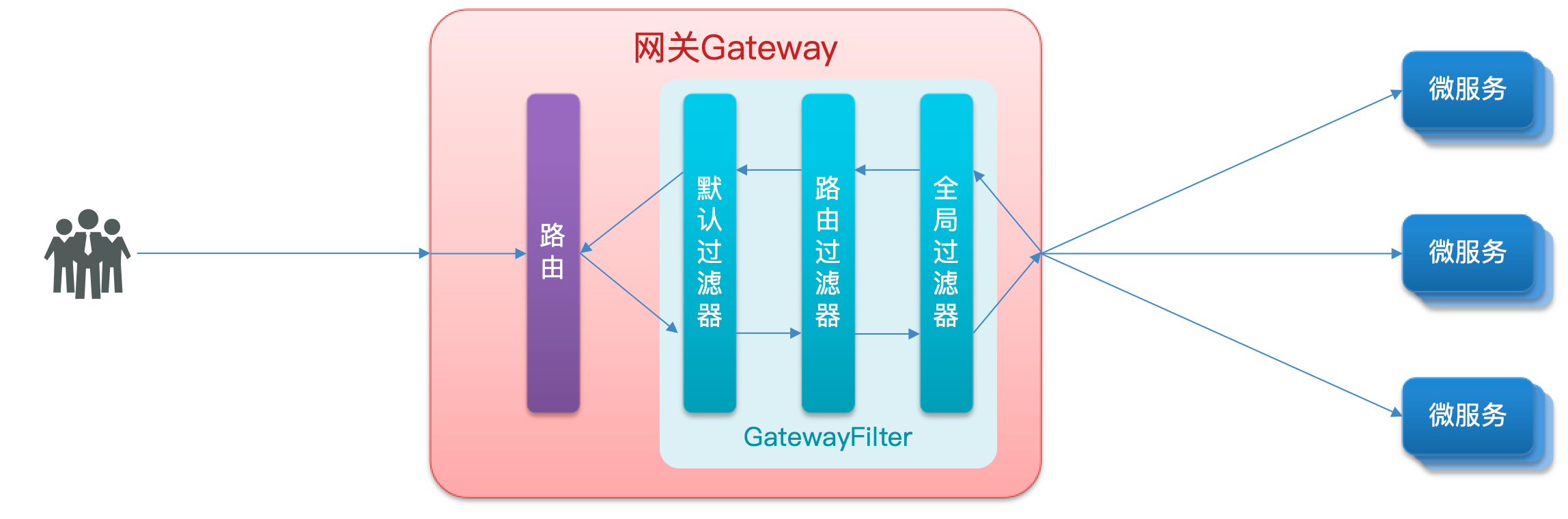
排序的规则是什么呢?
- 每一个过滤器都必须指定一个 int 类型的 order 值,order值越小,优先级越高,执行顺序越靠前。
- GlobalFilter 通过实现 Ordered 接口,或者添加
@Order注解来指定 order 值,由我们自己指定 - 路由过滤器和 defaultFilter 的 order 由 Spring 指定,默认是按照声明顺序从
1递增。
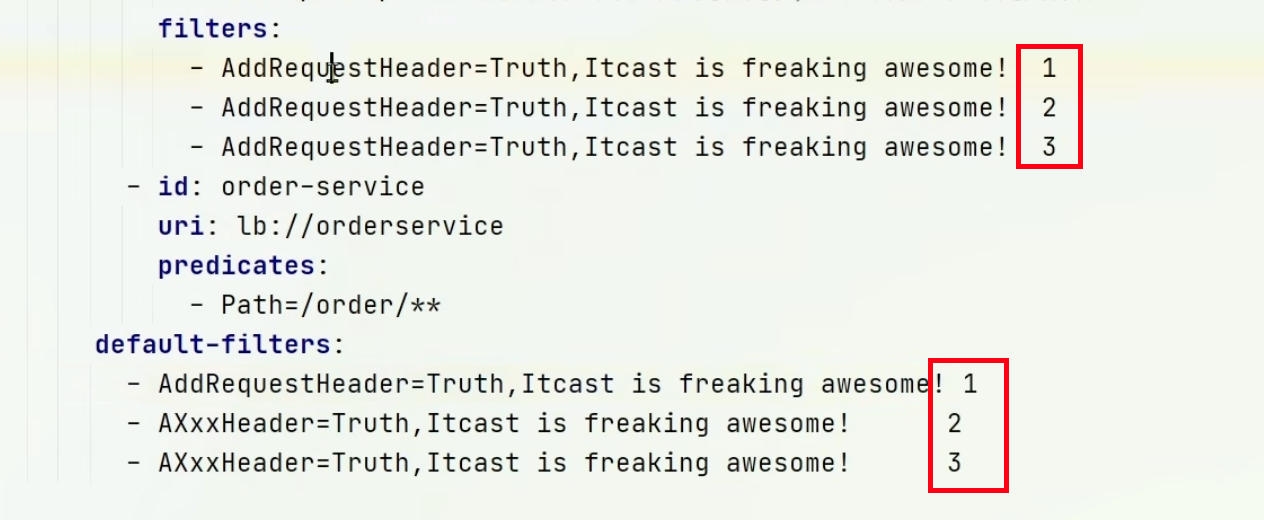
- 当过滤器的 order 值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter 的顺序执行。
详细内容,可以查看源码:
org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator#getFilters() 方法是先加载 defaultFilters,然后再加载某个 route 的 filters,然后合并。
org.springframework.cloud.gateway.handler.FilteringWebHandler#handle() 方法会加载全局过滤器,与前面的过滤器合并后根据 order 排序,组织过滤器链
跨域问题
什么是跨域问题
跨域:域名不一致就是跨域,主要包括:
- 域名不同: www.taobao.com 和 www.taobao.org 和 www.jd.com 和 miaosha.jd.com
{% note info %}
www.taobao.com 和 www.taobao.org 一级域名不同
www.taobao.org 和 www.jd.com 二级域名不同
www.jd.com 和 miaosha.jd.com 三级域名不同
{% endnote %} - 域名相同,端口不同:localhost:8080 和 localhost:8081 也是跨域问题
跨域问题:浏览器禁止 请求的发起者与服务端发生跨域 ajax 请求,请求被浏览器拦截的问题
解决方案:CORS,详细可以查看 https://www.ruanyifeng.com/blog/2016/04/cors.html
解决跨域问题
在 gateway 服务的 application.yml 文件中,添加下面的配置:
yaml
spring:
cloud:
gateway:
# 。。。
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期add-to-simple-url-handler-mapping: true 是网关中特有的,因为 Ajax 采用的 CORS 方案,浏览器会有一次询问,也就是 options 请求,问一下让不让跨域,然后如果允许才会真正发起请求,默认会被拦截的,所以要放行。另外,如果每次请求都有 options 请求,那就要发送两次请求,性能上有损耗,所以 maxAge 是这次跨域检查的有效期,第一次知道允许跨域后,这个时间段内就不再询问了,直接发起请求。