从前端工程向 AI 应用工程师转型快一年了,最近突然想写一点自己的感受和一些想法。这里就来跟大家聊一下,既然模型会越来越强,我们这些所谓的 AI 应用工程师做的事情,还有存在的必要吗
核心探讨:AI 应用工程的本质矛盾

随着基础模型能力的不断跃升,很多 AI 应用开发者都会产生一个真实的焦虑:我们这么努力地优化 Agent 工程,是不是不如模型侧的一次升级? 比如在代码编写和分析场景中,模型之所以能知道如何使用工具读写代码,本质是因为训练数据中包含了大量代码和工具使用的 RLHF(基于人类反馈的强化学习)。如果给模型一些相对冷门的工具,它甚至不会去使用。
这种现象说明,很多 Agent 工程的努力,本质上是在对冲模型的不足。模型变强,这部分工程价值似乎就会被压缩。
然而,这个问题的答案并非非此即彼,而是需要理解两者在价值链上所处的位置。
模型提供概率,工程提供确定性
第一,模型升级的速度不均匀,工程填补的是"当下的缺口"。今天某个模型在长上下文推理上有缺陷,明天另一个模型补上了,但又在工具调用稳定性上出现了新问题。工程层永远在填补"此时此刻"的缺口,这个需求不会消失,只是内容在变。
第二,模型解决的是通用能力,工程解决的是特定场景的可靠性。一个模型能"大概率"写出正确代码,和一个系统能"在生产环境稳定地"完成代码审查任务,是两件事。后者需要错误重试、上下文管理、工具编排、结果验证等。模型提供概率,工程提供确定性。
第三,真正的壁垒在于"冷门"工具和私有数据。如果一个工具已经在模型训练数据里,它的使用门槛极低,竞争激烈,利润薄。真正有壁垒的业务场景,往往是那些"冷门"的、私有的、领域专属的工具和数据。让模型学会用这些工具,才是应用层工程师的核心竞争力。
第四,模型升级本身也需要应用层来"接住"。模型是基础设施,应用工程是把基础设施变成用户价值的桥梁。
结论是:做靠近业务和数据的工程,而不是靠近模型 trick(技巧)的工程。 前者随着模型变强会变得更强,后者会被蚕食。
为什么 Agent 层不会消失?
如果模型未来会越来越强,还要 Agent 这一层干嘛呢?
Agent 这一层不会消失,但它的形态会发生根本性的变化。很多人认为 Agent 的价值来自于弥补模型的不足,但这只是 Agent 价值中最脆弱的一部分。Agent 层真正不可替代的价值体现在以下几个方面:
-
模型是无状态的,世界是有状态的 模型本身没有记忆、没有身份、没有持久化的上下文。但真实的业务场景需要跨会话的用户记忆、任务的中断与恢复、多步骤的状态追踪。这些是运行时基础设施问题,不是智能问题。
-
模型是单点的,业务是分布式的 真实的业务流程涉及调用内部 API、读写数据库、与第三方系统交互等。模型只能"思考",Agent 层负责"执行"。执行层的编排、权限控制、错误处理、幂等性保障,永远需要工程来承载。
-
模型是概率的,生产是确定性的 模型给出的是"大概率正确的输出",但生产系统要求的是"可预期、可审计、可回滚的行为"。Agent 层扮演的角色是把概率性的智能包装成确定性的服务。
-
模型是通用的,价值是垂直的 通用模型不知道公司的审批流程、代码库规范或客户画像。把这些领域知识注入到模型的执行过程中,这个"注入"的过程本身就是 Agent 工程。
这就像云计算越来越强大,但我们依然需要应用开发工程师。模型是新的基础设施,Agent 是新的应用层。 基础设施的进化不会消灭应用层,只会重新定义应用层的工作内容。未来的 Agent 工程,低层的工作(如 prompt 调优)会被模型吸收,而高层的工作(如任务定义、业务集成)会变得更重要。
Harness 工程:为智能构建落地环境
在探讨如何让 Agent 在确定性环境中可靠工作时,Harness 工程(治理/驾驭工程)的概念应运而生。Harness 工程的核心哲学是:不是让模型更聪明,而是把环境设计得更聪明,让模型的智能有地方可靠落地。
它主要由三大核心支柱构成: 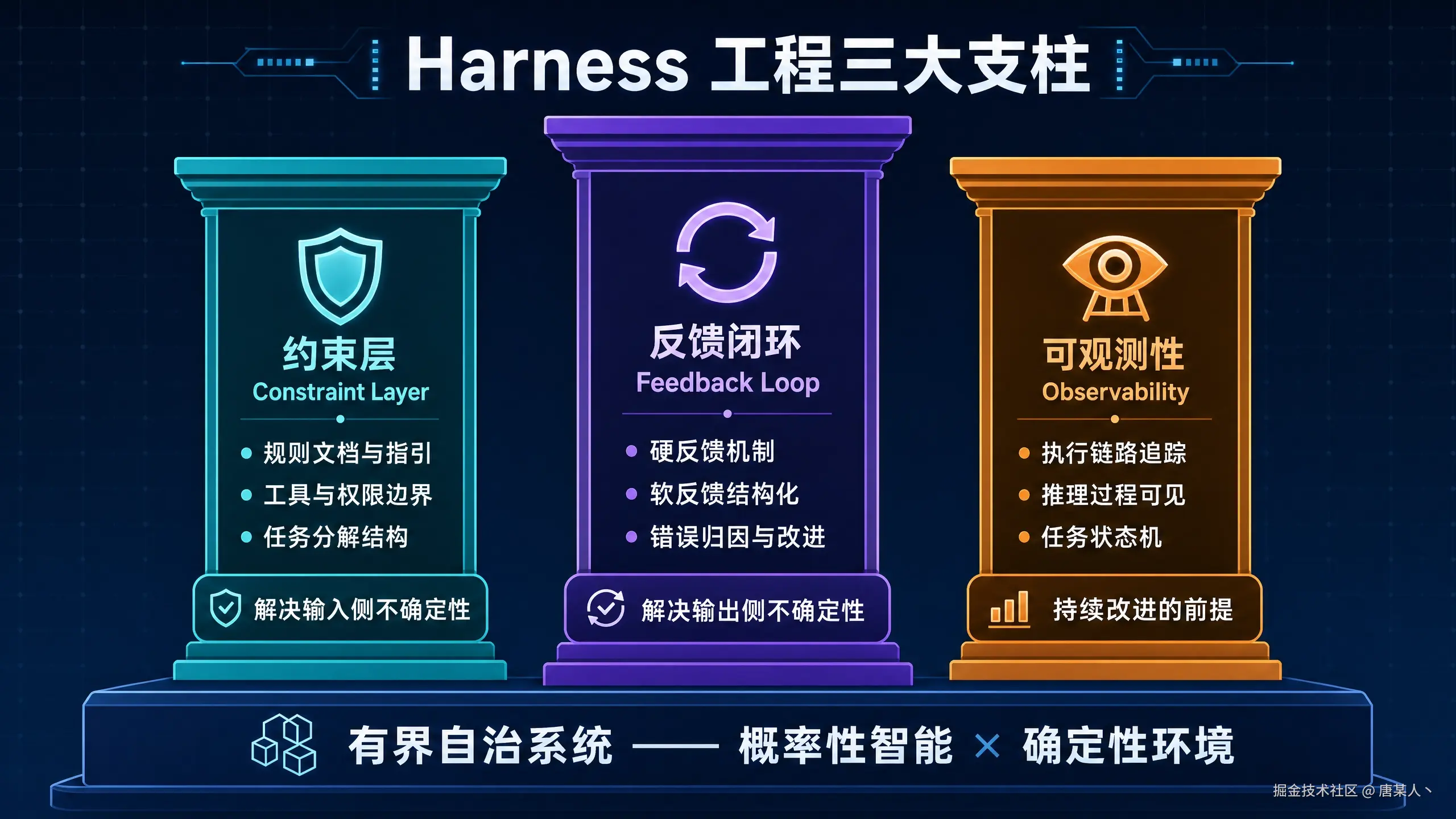
1. 约束层(Constraint Layer)
为 Agent 的执行划定明确的边界,解决"输入侧"的不确定性。
- 规则文档与指引:明确任务目标、执行规范、禁止行为,让模型在有界空间内自主决策。
- 工具与权限边界:限制 Agent 只能访问被授权的工具和数据,防止能力溢出导致副作用。
- 任务分解结构:将复杂任务拆解为有明确输入输出定义的子任务,缩小每一步的决策空间。
2. 反馈闭环(Feedback Loop)
为 Agent 的执行提供持续的校正信号,解决"输出侧"的不确定性。
- 硬反馈机制:测试用例、类型检测、格式校验等,对错分明,直接驱动模型自我修正。
- 软反馈结构化:将业务逻辑校验、风格一致性等模糊标准转化为可量化的评估信号。
- 错误归因与改进信息:反馈不只是"错了",而是"为什么错、如何改",这决定了模型自我迭代的效率上限。
3. 可观测性(Observability)
为整个执行过程提供透明度,是前两个支柱能够持续改进的前提。
- 执行链路追踪:记录每一步工具调用的入参、出参和耗时。
- 推理过程可见:保留模型的决策依据,区分"模型理解错了"、"工具出错了"还是"规则冲突了"。
- 任务状态机:维护任务在每个阶段的状态,支持中断恢复、失败重试和人工介入。
三者构成一个完整的有界自治系统:约束层压缩了问题空间,反馈闭环驱动了自我修正,可观测性保障了整个系统可以被持续优化。
业界实践:Claude Code vs. Codex CLI
目前,业界在 Harness 工程上已经有一些代表性的实践,其中 Claude Code 和 Codex CLI 尤为典型,它们在设计侧重点上有着明显的差异。

Claude Code:系统化与团队共享
Claude Code 是目前在 Harness 工程上做得最系统、最彻底的产品之一。
- 约束层 :通过项目根目录的
CLAUDE.md文件作为项目级规则文档,定义代码风格、禁止操作等。规则是版本化的、可审查的、团队共享的。 - 反馈闭环:让 Agent 直接在真实的开发环境里执行(运行测试、执行 lint)。真实工具链的输出作为硬反馈信号,模型拿到的错误信息和开发者完全一样。
- 可观测性:对话流即日志,每一步操作和工具调用都在对话流里可见,用户可以随时介入。
Codex CLI:物理隔离与分级授权
Codex CLI 的整体设计更轻量,侧重于安全边界。
- 约束层:通过网络隔离和文件系统沙盒,在受限环境里执行代码,防止不可逆的副作用。这是一种"物理约束"。
- 审批模式 :提供
suggest、auto-edit、full-auto三种执行模式,引入人工节点,让用户根据信任程度决定 Agent 的自治边界。 - 反馈闭环:相对薄弱,更多依赖模型自身的判断。
总结
Claude Code 在 Harness 工程上目前是业界最成熟的实践,它把约束层从一次性的 prompt 变成了可维护的工程资产(CLAUDE.md)。而 Codex CLI 的价值在于对"安全边界"的重视,解决 Agent 在生产环境里"做坏事"的风险。
两者互补地回答了 Harness 工程的两个核心问题:如何让 Agent 做得更好(Claude Code) ,以及如何防止 Agent 做错事(Codex CLI)。
结语
Agent 工程师的价值不在于和模型竞争智能,而在于为模型的智能构建可以可靠发挥作用的运行环境。模型越强,一个设计良好的 Harness 能释放的价值就越大。对于 AI 应用开发者而言,未来的方向是定义什么任务值得完成,以及如何把完成结果嵌入真实业务流,而不是停留在模型调用层的技巧上。