
📋 目录
一、单库事务
1.1 @Transactional 核心原理
Spring 事务的本质是 AOP 代理 + ThreadLocal 绑定 Connection:
java
// 你以为的执行流程
@Service
public class OrderService {
@Transactional
public void createOrder(Order order) {
orderMapper.insert(order); // 1. 插入订单
inventoryService.deduct(order); // 2. 扣库存
couponService.use(order.getCouponId()); // 3. 核销优惠券
}
}核心机制:
| 组件 | 作用 |
|---|---|
DataSourceTransactionManager |
管理事务生命周期(begin/commit/rollback) |
TransactionSynchronizationManager |
用 ThreadLocal<Map<DataSource, Connection>> 绑定连接 |
@Transactional |
AOP 切面,拦截注解方法,织入事务逻辑 |
执行流程为什么需要代理 :如果同一个类内部调用
this.createOrder(),不会触发代理,事务不生效。详见 [1.4 自调用失效](#1.4 自调用失效)。
1.2 隔离级别
sql
-- MySQL 默认: REPEATABLE READ
-- 查看当前隔离级别
SELECT @@transaction_isolation;| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 实现方式 | 推荐场景 |
|---|---|---|---|---|---|
| READ UNCOMMITTED | Y | Y | Y | 无锁 | 几乎不用 |
| READ COMMITTED | N | Y | Y | MVCC 快照读 | PostgreSQL 默认,OLTP 高并发 |
| REPEATABLE READ | N | N | N(间隙锁) | MVCC + 间隙锁 | MySQL 默认,推荐 |
| SERIALIZABLE | N | N | N | 全表锁 | 金融对账、一致性要求极高 |
选择指南:
java
// 大多数场景:用默认 REPEATABLE READ
@Transactional
public void normalBusiness() { ... }
// 报表/统计场景:承受不可重复读换取并发性能
@Transactional(isolation = Isolation.READ_COMMITTED)
public List<StatVO> generateReport() { ... }
// 资金对账:串行化
@Transactional(isolation = Isolation.SERIALIZABLE)
public void reconcile() { ... }实践建议:先不改隔离级别。性能瓶颈先优化 SQL 和索引,隔离级别降级是最后手段。90% 的并发问题可以用乐观锁(version 字段)解决。
1.3 传播行为
7 种传播行为的决策树:
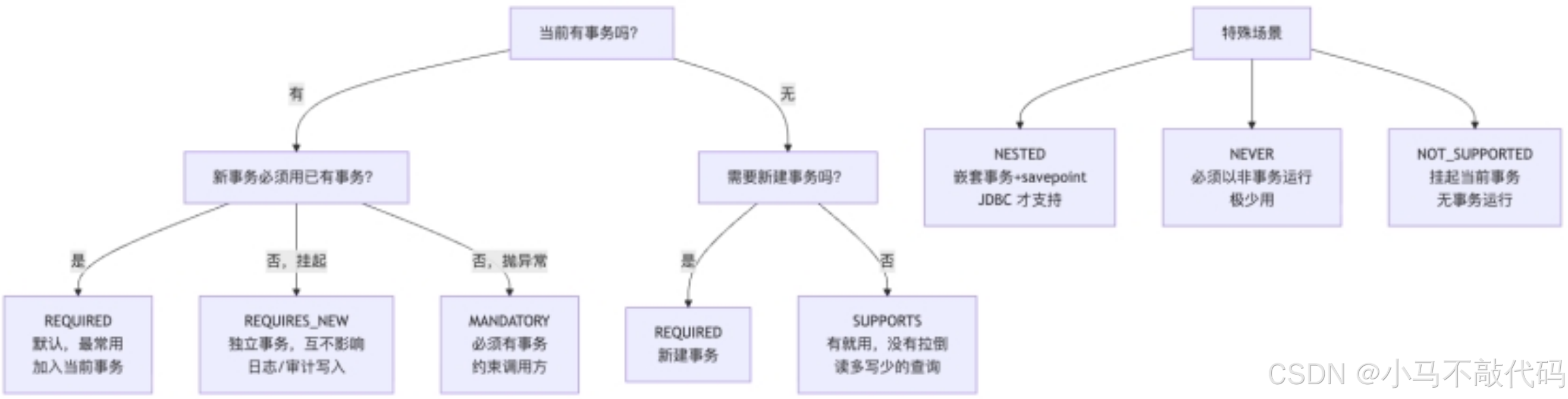
典型组合用法:
java
@Service
public class OrderService {
// 核心业务:默认 REQUIRED
@Transactional(rollbackFor = Exception.class)
public void createOrder(CreateOrderCmd cmd) {
orderRepo.save(cmd.toOrder()); // require 事务
inventoryRepo.deduct(cmd.getItems()); // require 事务
// 若此处抛异常,以上全部回滚
}
// 独立事务:审计日志不受业务回滚影响
@Transactional(propagation = Propagation.REQUIRES_NEW, rollbackFor = Exception.class)
public void writeAuditLog(String action, String detail) {
auditLogRepo.save(new AuditLog(action, detail));
}
}组合调用陷阱:
java
@Transactional // 外层 REQUIRED
public void createOrder(CreateOrderCmd cmd) {
orderRepo.save(order); // 加入外层事务
try {
writeAuditLog("CREATE", "..."); // REQUIRES_NEW → 内层已提交!
} catch (Exception e) {
// 即使这里 catch 了,审计日志已经写入了,不会回滚
}
// 这里抛异常 → 订单回滚,但审计日志保留 ✓ (符合预期)
}1.4 自调用失效
问题 :同一个类的方法 A 调用方法 B,B 上的 @Transactional 不生效。
java
@Service
public class UserService {
public void register(User user) {
// 这是 this.methodB(),不经过 AOP 代理!
// saveUser 的 @Transactional 被忽略
this.saveUser(user);
}
@Transactional
public void saveUser(User user) {
userMapper.insert(user);
}
}原理:
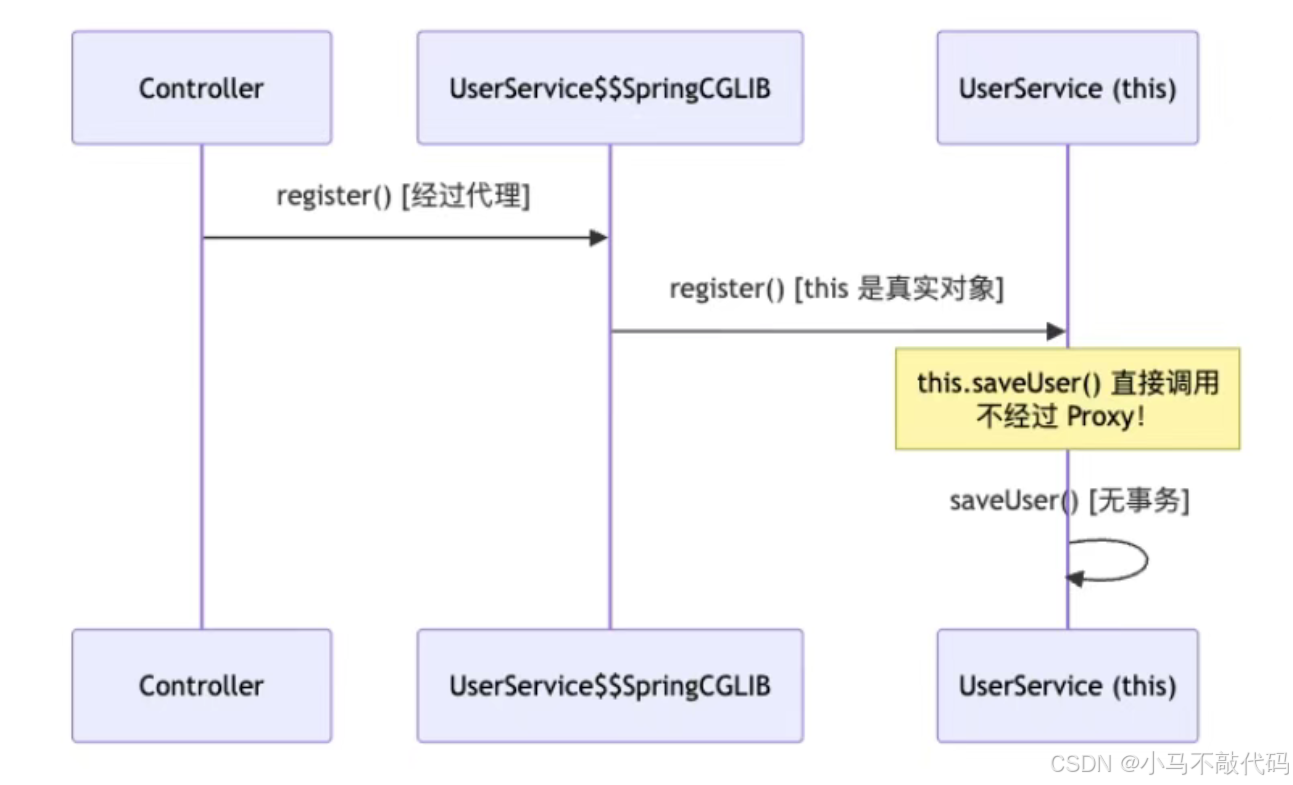
三种解决方案:
| 方案 | 代码 | 优点 | 缺点 |
|---|---|---|---|
| 1. 自注入 | @Autowired private UserService self; |
改动最小 | 循环依赖告警 |
| 2. 抽新 Service | 拆成 UserService + UserTxService |
职责清晰 | 多一个类 |
| 3. AopContext | ((UserService)AopContext.currentProxy()).saveUser() |
不拆类 | 丑陋、暴露代理模式 |
推荐方案 2(拆分 Service):
java
@Service
public class UserRegisterService {
private final UserTxService userTxService;
@Transactional(rollbackFor = Exception.class)
public void register(User user) {
// 跨 Service 调用,经过代理,事务生效
userTxService.saveUser(user);
sendWelcomeEmail(user); // 非事务方法
}
}
@Service
public class UserTxService {
@Transactional(rollbackFor = Exception.class)
public void saveUser(User user) {
userMapper.insert(user);
}
}1.5 事务超时与回滚策略
java
// ❌ 坏实践:不设超时,慢 SQL 占着连接不释放
@Transactional
public void batchProcess() { ... }
// ✅ 好实践:按场景设置超时
@Transactional(timeout = 30) // 30 秒
public void batchImport(List<Record> records) {
// 批量导入,预估最长 30 秒
}
@Transactional(timeout = 5) // 5 秒
public void orderPayment(Long orderId) {
// 支付操作,必须快速完成
}回滚策略:
java
// ❌ 默认只对 RuntimeException 和 Error 回滚
// checked exception(如 IOException)不会触发回滚!
// ✅ 显式指定回滚
@Transactional(rollbackFor = Exception.class) // 所有异常都回滚
public void process() throws IOException { ... }
// ✅ 指定不回滚的异常
@Transactional(noRollbackFor = {BusinessException.class})
public void process() {
// 业务异常不触发回滚(如余额不足)
}团队规范 :所有
@Transactional必须显式设置rollbackFor = Exception.class,避免 checked exception 不回滚的坑。
1.6 读写分离下的事务陷阱
java
// 问题场景:读写分离 + 事务
@Transactional
public void updateAndRead(Long id) {
userMapper.updateById(user); // 写主库
User u = userMapper.selectById(id); // 期望读主库(刚写入),但路由到从库!
// → 主从延迟导致读到旧数据
}解决方式:
java
// 方案 1:事务内始终走主库(ShardingSphere hint)
@Transactional
public void updateAndRead(Long id) {
HintManager.getInstance().setWriteRouteOnly(); // 强制走主库
userMapper.updateById(user);
User u = userMapper.selectById(id); // 走主库 ✓
}
// 方案 2:写后读用 selectById + 校验(适合偶尔不一致可接受的场景)
// 方案 3:拆分事务,写完 commit 后再读二、跨库事务(分布式事务)
当业务数据分布在多个数据库实例上,单库事务不再适用。
2.1 XA/2PC --- 强一致性方案
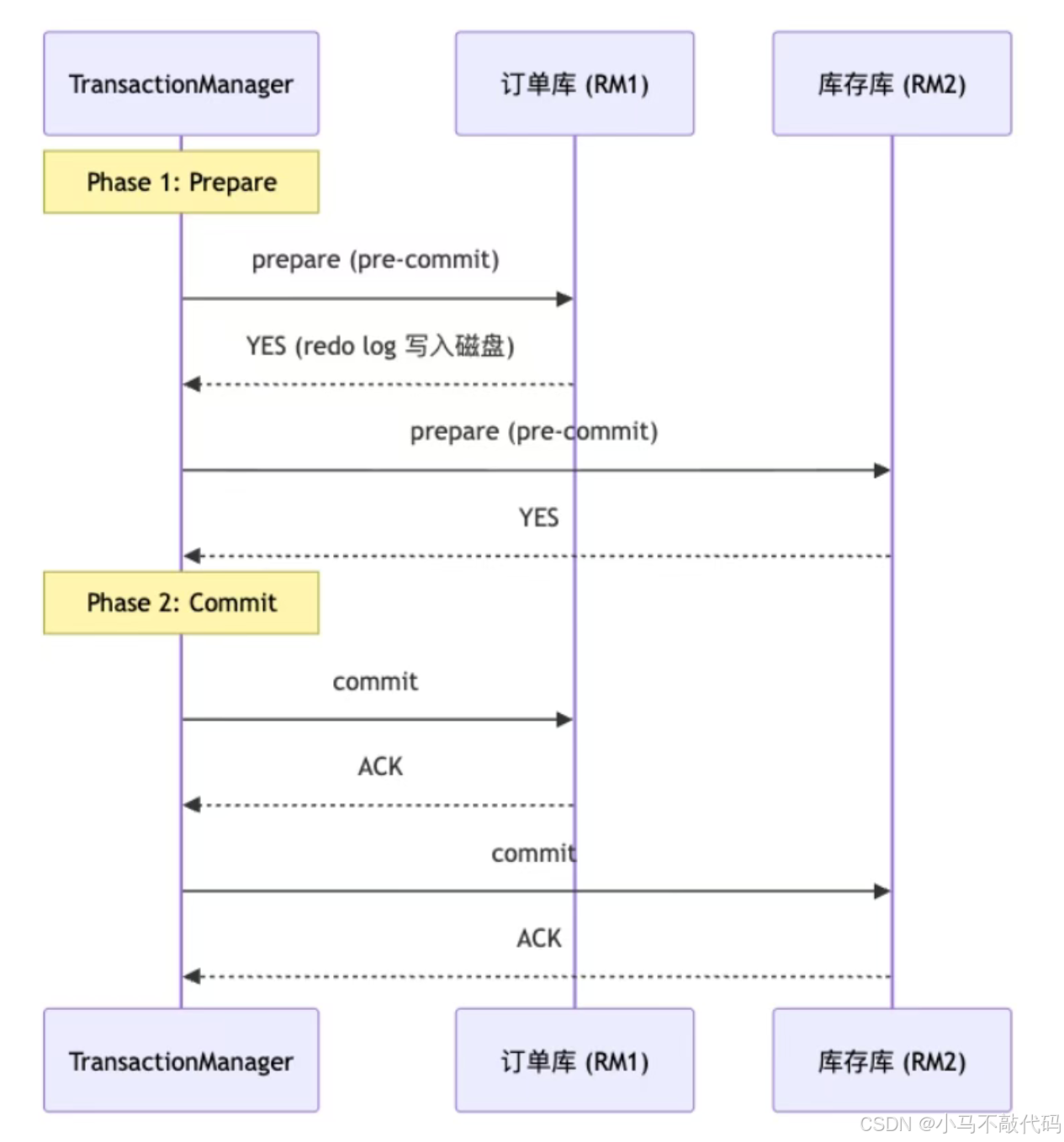
Spring Boot + Atomikos 示例:
java
@Configuration
public class AtomikosConfig {
@Bean(initMethod = "init", destroyMethod = "close")
public AtomikosDataSourceBean orderDataSource() {
AtomikosDataSourceBean ds = new AtomikosDataSourceBean();
ds.setUniqueResourceName("orderDS");
ds.setXaDataSourceClassName("com.mysql.cj.jdbc.MysqlXADataSource");
Properties p = new Properties();
p.setProperty("url", "jdbc:mysql://db1:3306/order_db");
p.setProperty("user", "root");
ds.setXaProperties(p);
ds.setPoolSize(10);
return ds;
}
@Bean
public JtaTransactionManager jtaTransactionManager() {
UserTransactionManager utm = new UserTransactionManager();
UserTransaction ut = new UserTransactionImp();
return new JtaTransactionManager(ut, utm);
}
}
@Service
public class CrossDBService {
@Transactional // JTA 事务,自动协调两个 XA 数据源
public void placeOrder(Order order, List<OrderItem> items) {
orderMapper.insert(order); // DS1
inventoryMapper.deduct(items); // DS2
}
}| 场景 | 评价 |
|---|---|
| 一致性 | ⭐⭐⭐⭐⭐ 强一致,ACID 保证 |
| 性能 | ⭐⭐ 两阶段锁、同步阻塞 |
| 可用性 | ⭐⭐ 协调者单点(需 HA 部署) |
| 适用 | 金融核心、资金交易,数据量小 |
核心缺陷:2PC 的"同步阻塞"问题 --- 如果协调者在 Phase 2 执行中宕机,参与者拿不到 commit/rollback 指令,锁一直持有,数据库连接挂起直到超时。
2.2 Seata AT 模式 --- 零侵入方案
AT 模式是 Seata 的默认模式,对业务代码零侵入:
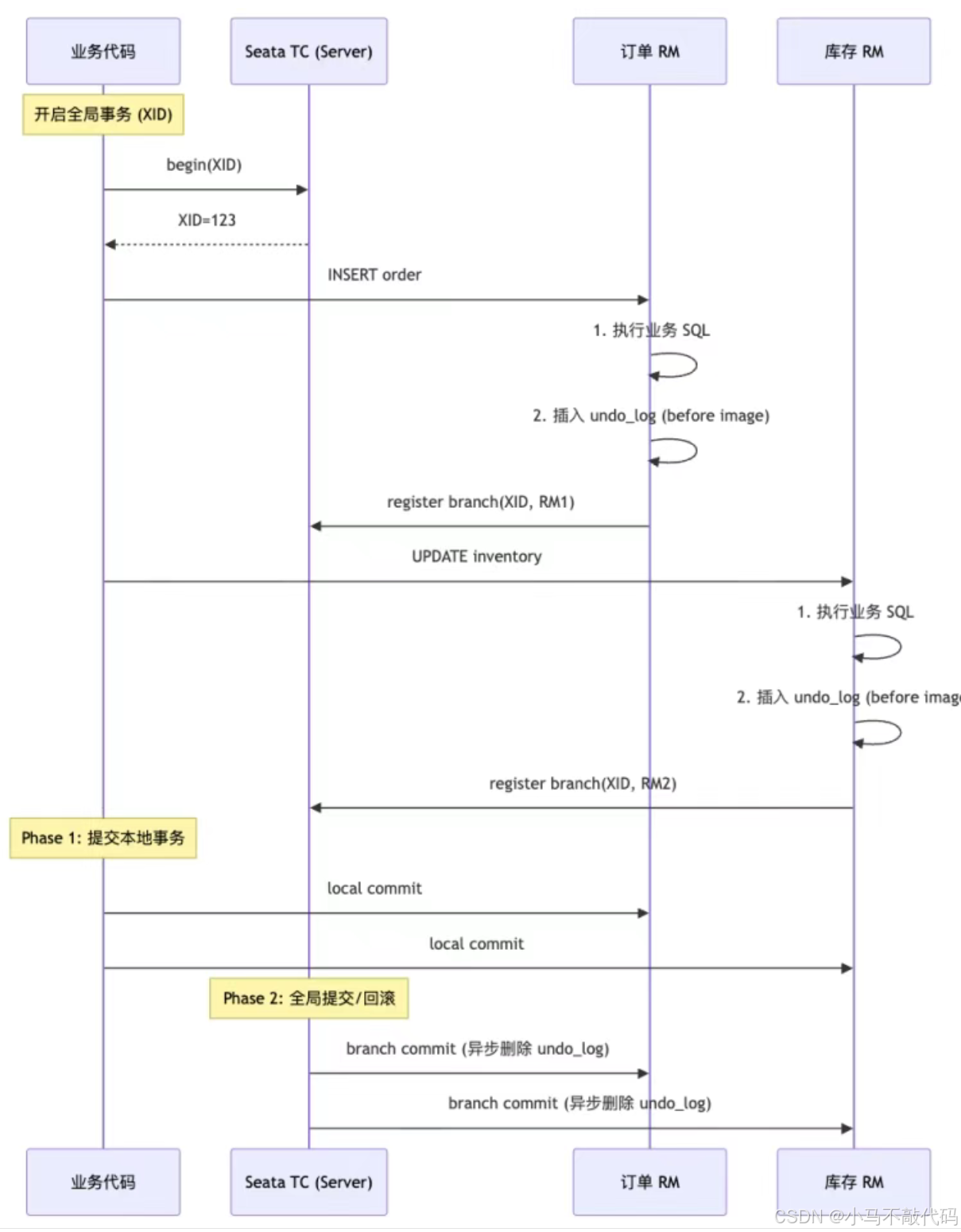
undo_log 原理:
sql
-- Seata 在每个业务库自动维护此表
CREATE TABLE undo_log (
id BIGINT NOT NULL AUTO_INCREMENT,
branch_id BIGINT NOT NULL,
xid VARCHAR(100) NOT NULL,
context VARCHAR(128) NOT NULL,
rollback_info LONGBLOB NOT NULL, -- 回滚所需的前镜像数据
log_status INT NOT NULL,
log_created DATETIME NOT NULL,
log_modified DATETIME NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY ux_undo_log (xid, branch_id)
) ENGINE=InnoDB;
-- rollback_info 示例(对 UPDATE inventory SET stock=stock-1 WHERE id=100):
-- {
-- "beforeImage": { "rows": [{"id":100, "stock":50}] },
-- "afterImage": { "rows": [{"id":100, "stock":49}] },
-- "sqlType": "UPDATE"
-- }
-- 回滚时执行:UPDATE inventory SET stock=50 WHERE id=100AT 模式写隔离:通过全局锁防止脏写:
bash
事务1: UPDATE stock SET stock=50 WHERE id=1 (本地提交,全局锁 id=1 被持有)
事务2: UPDATE stock SET stock=stock-1 WHERE id=1 → 被全局锁阻塞,等待事务1释放
事务1: 全局回滚 → undo_log 还原 stock → 释放全局锁
事务2: 获取全局锁 → 读到最新值 50 → 执行 stock=492.3 Seata TCC 模式 --- 高性能方案
TCC (Try-Confirm-Cancel) 需要业务自行实现三阶段逻辑,但性能优于 AT:
java
/**
* TCC 接口定义:每个参与方实现 try / confirm / cancel
*/
public interface InventoryTccAction {
/**
* Try: 资源预留(冻结库存)
*/
@TwoPhaseBusinessAction(name = "inventory-deduct", commitMethod = "confirm", rollbackMethod = "cancel")
boolean tryDeduct(BusinessActionContext ctx,
@BusinessActionContextParameter("skuId") Long skuId,
@BusinessActionContextParameter("count") Integer count);
/**
* Confirm: 确认扣减(冻结 → 已扣)
*/
boolean confirm(BusinessActionContext ctx);
/**
* Cancel: 取消扣减(解冻库存)
*/
boolean cancel(BusinessActionContext ctx);
}
sql
-- 库存表设计(TCC 需要业务层面的冻结字段)
CREATE TABLE inventory (
id BIGINT PRIMARY KEY,
sku_id BIGINT NOT NULL UNIQUE,
total INT NOT NULL DEFAULT 0, -- 总库存
frozen INT NOT NULL DEFAULT 0, -- 冻结库存(TCC Try)
available INT GENERATED ALWAYS AS (total - frozen) STORED, -- 可用库存
version INT NOT NULL DEFAULT 0 -- 乐观锁
);
-- Try: UPDATE inventory SET frozen = frozen + ? WHERE sku_id = ? AND available >= ?
-- Confirm: UPDATE inventory SET total = total - ?, frozen = frozen - ? WHERE sku_id = ?
-- Cancel: UPDATE inventory SET frozen = frozen - ? WHERE sku_id = ?TCC 三大问题及解决方案:
| 问题 | 描述 | 解决 |
|---|---|---|
| 空回滚 | Try 超时未执行,TC 直接调 Cancel | Cancel 判断 Try 是否执行过(查冻结记录),若未执行则无操作返回成功 |
| 防悬挂 | Cancel 先于 Try 到达(网络乱序) | Try 执行前查是否有 Cancel 记录,有则拒绝执行 |
| 幂等 | Confirm/Cancel 被重复调用 | 状态机控制:INIT → TRIED → CONFIRMED/CANCELLED,同状态跳过 |
java
@Transactional
public boolean tryDeduct(BusinessActionContext ctx, Long skuId, Integer count) {
// 防悬挂:检查是否已被 Cancel
TccRecord record = tccRecordMapper.selectByXidAndBranchId(
ctx.getXid(), ctx.getBranchId());
if (record != null && record.getStatus() == TccStatus.CANCELLED) {
log.warn("Try 被 Cancel 抢先执行,拒绝"); // 防悬挂
return false;
}
// 幂等:检查是否已 Try 成功
if (record != null && record.getStatus() == TccStatus.TRIED) {
return true; // 幂等重放
}
// 执行资源预留
int rows = inventoryMapper.freeze(skuId, count); // UPDATE ... WHERE available >= count
if (rows == 0) return false;
// 记录状态
tccRecordMapper.insert(new TccRecord(ctx.getXid(), ctx.getBranchId(), TccStatus.TRIED));
return true;
}2.4 MQ 最终一致性
最常用的方案:本地事务 + 消息表 + 定时补偿。
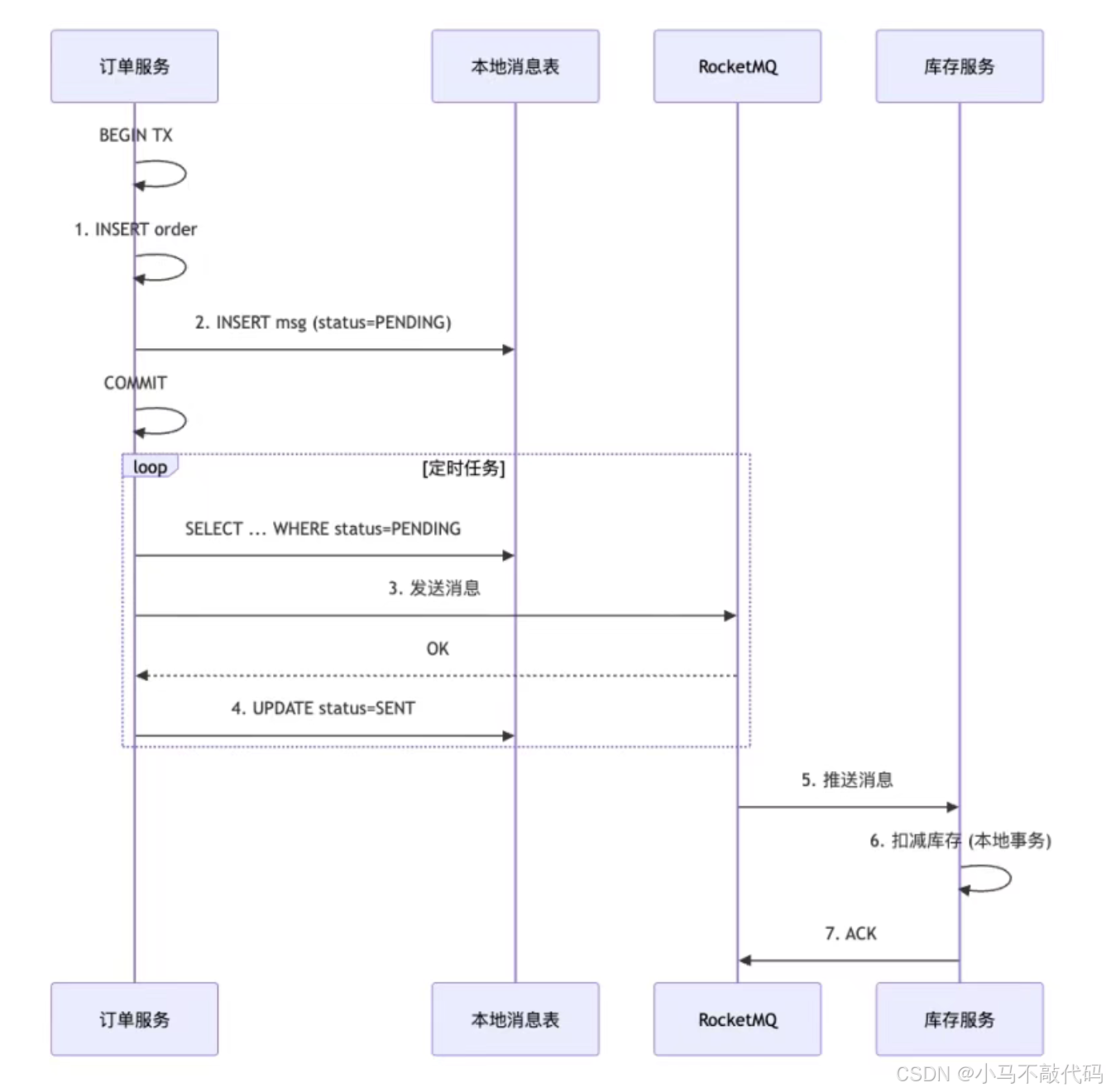
实现代码:
java
@Service
public class OrderService {
@Transactional(rollbackFor = Exception.class)
public void createOrder(CreateOrderCmd cmd) {
// 1. 业务操作 + 消息写入:同一本地事务
orderMapper.insert(cmd.toOrder());
OutboxMessage msg = OutboxMessage.builder()
.topic("ORDER_CREATED")
.body(JSON.toJSONString(cmd))
.status(MsgStatus.PENDING)
.createTime(LocalDateTime.now())
.build();
outboxMapper.insert(msg);
}
}
@Component
public class OutboxRelay {
@Scheduled(fixedDelay = 1000) // 每 1 秒轮询
public void relay() {
// 2. 扫描未发送的消息
List<OutboxMessage> messages = outboxMapper.selectPending(100);
for (OutboxMessage msg : messages) {
// 3. 发送到 MQ
SendResult result = rocketMQTemplate.syncSend(msg.getTopic(), msg.getBody());
if (result.getSendStatus() == SendStatus.SEND_OK) {
outboxMapper.updateStatus(msg.getId(), MsgStatus.SENT);
}
}
}
}消息消费端幂等:
java
@RocketMQMessageListener(topic = "ORDER_CREATED", consumerGroup = "inventory-group")
@Component
public class OrderCreatedConsumer implements RocketMQListener<String> {
@Override
public void onMessage(String message) {
CreateOrderCmd cmd = JSON.parseObject(message, CreateOrderCmd.class);
String msgId = RocketMQUtil.getMsgId(message);
// 幂等:去重表判断
DedupRecord exists = dedupMapper.selectByMsgId(msgId);
if (exists != null) return; // 已消费,跳过
@Transactional(rollbackFor = Exception.class)
void process() {
inventoryMapper.deduct(cmd.getItems()); // 业务操作
dedupMapper.insert(new DedupRecord(msgId)); // 去重记录
}
}
}2.5 方案对比矩阵
| 维度 | XA/2PC | Seata AT | Seata TCC | 本地消息表 + MQ |
|---|---|---|---|---|
| 一致性 | 强一致 | 最终一致(读已提交) | 最终一致 | 最终一致(最长延迟 = 轮询间隔) |
| 性能 | ⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 代码侵入 | 无 | 无 | 高(需实现 TCC 3 方法) | 中(需维护消息表) |
| 运维成本 | 高(XA 驱动、超时配置) | 中(需部署 TC Server) | 中(需部署 TC Server) | 低(无需协调者) |
| 适用场景 | 金融对账、资金划拨 | 通用分布式事务 | 高并发扣减、库存 | 异步解耦、事件驱动 |
四、常见问题与反模式
4.1 @Transactional 失效场景速查
| # | 场景 | 原因 | 解决 |
|---|---|---|---|
| 1 | 同 Service 自调用 | 不走代理 | 拆分 Service / 自注入 |
| 2 | 非 public 方法 | CGLIB 无法代理 private/protected | 改为 public |
| 3 | 异常被 catch 吃掉 | Spring 感知不到异常 | catch 里手动 TransactionAspectSupport.currentTransactionStatus().setRollbackOnly() |
| 4 | checked exception 不回滚 | 默认只回滚 RuntimeException | 加 rollbackFor = Exception.class |
| 5 | final 方法/类 | CGLIB 无法代理 final | 去掉 final |
| 6 | 多线程场景 | ThreadLocal 不跨线程 | 每个线程独立 @Transactional |
java
// 反模式 3 示例:异常被吃掉
@Transactional
public void process() {
try {
orderMapper.insert(order);
riskyOperation(); // 抛 RuntimeException
} catch (Exception e) {
log.error("处理失败", e);
// ❌ 异常被捕获,Spring 不知道,事务提交了!
}
}
// 正确做法
@Transactional(rollbackFor = Exception.class)
public void process() {
try {
orderMapper.insert(order);
riskyOperation();
} catch (Exception e) {
log.error("处理失败", e);
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
throw new BusinessException("处理失败", e); // 或重新抛出
}
}4.2 长事务与大事务
java
// ❌ 反模式:RPC/HTTP 调用放在事务里
@Transactional
public void createOrder(CreateOrderCmd cmd) {
orderMapper.insert(order); // SQL: 10ms
inventoryMapper.deduct(items); // SQL: 50ms
String result = httpClient.callExternal(cmd); // HTTP: 2000ms ← 锁一直持有!
couponMapper.use(cmd.getCouponId()); // SQL: 10ms
}
// → 事务持有 2 秒+,锁竞争、连接池耗尽
// ✅ 重构:RPC 调用移出事务
@Transactional
public void createOrder(CreateOrderCmd cmd) {
orderMapper.insert(order);
inventoryMapper.deduct(items);
couponMapper.use(cmd.getCouponId());
} // commit → 释放锁和连接
public void createOrderWithNotify(CreateOrderCmd cmd) {
createOrder(cmd); // 事务方法
httpClient.callExternal(cmd); // 非事务
}长事务监测:
sql
-- MySQL: 查找运行时间 > 5 秒的事务
SELECT
trx_id,
trx_started,
TIMESTAMPDIFF(SECOND, trx_started, NOW()) AS duration_sec,
trx_mysql_thread_id,
trx_query
FROM information_schema.innodb_trx
WHERE TIMESTAMPDIFF(SECOND, trx_started, NOW()) > 5
ORDER BY trx_started;4.3 死锁排查
sql
-- Step 1: 查看死锁日志
SHOW ENGINE INNODB STATUS\G
-- 搜索 "LATEST DETECTED DEADLOCK" 段落
-- Step 2: 查看当前锁等待
SELECT
r.trx_id AS waiting_trx,
r.trx_mysql_thread_id AS waiting_thread,
r.trx_query AS waiting_query,
b.trx_id AS blocking_trx,
b.trx_mysql_thread_id AS blocking_thread,
b.trx_query AS blocking_query
FROM information_schema.innodb_lock_waits w
JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id
JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id;死锁预防原则:
- 固定加锁顺序 --- 始终按 table_a → table_b 的顺序更新,不要出现 table_b → table_a
- 缩小事务 --- 事务越小,持锁时间越短
- 合理使用索引 --- 无索引导致全表扫描会引起更多行锁
- 拆分大事务 --- 一次更新大量行改为分批更新
java
// ❌ 死锁风险:两个事务加锁顺序不确定
// Tx1: UPDATE order SET ... WHERE id=1; UPDATE item SET ... WHERE order_id=1;
// Tx2: UPDATE item SET ... WHERE order_id=1; UPDATE order SET ... WHERE id=1;
// ✅ 对齐加锁顺序
// Tx1: UPDATE order SET ... WHERE id=1; UPDATE item SET ... WHERE order_id=1;
// Tx2: UPDATE order SET ... WHERE id=1; UPDATE item SET ... WHERE order_id=1;4.4 事务与分布式锁
java
// ❌ 反模式:锁先行,事务后发
public void deduct(Long skuId, int count) {
RLock lock = redisson.getLock("stock:" + skuId);
lock.lock();
try {
// 事务内加锁 → 锁释放时机在 commit 之前!
// 其他线程在 commit 完成前就拿到了锁,读到旧数据
doDeduct(skuId, count); // @Transactional
} finally {
lock.unlock(); // ← 锁释放了,但事务可能还没 commit!
}
}
// ✅ 正确顺序:事务先 commit,再释放锁
// 方案 A:锁在事务外
public void deduct(Long skuId, int count) {
doDeduct(skuId, count); // @Transactional → commit 完成
// 事务提交后才释放锁,保证其他线程读到最新数据
}
// 方案 B:用乐观锁替代分布式锁(推荐)
@Transactional
public void deduct(Long skuId, int count) {
int rows = inventoryMapper.deductWithVersion(skuId, count, currentVersion);
if (rows == 0) throw new OptimisticLockException("并发冲突,请重试");
}
// deductWithVersion: UPDATE inventory SET stock=stock-?, version=version+1
// WHERE sku_id=? AND version=? AND stock>=?五、决策速查表
bash
你的场景是?
│
├── 单库单服务
│ ├── 简单 CRUD → @Transactional(rollbackFor=Exception.class)
│ ├── 需独立事务(日志/审计) → REQUIRES_NEW
│ └── 读多写少 → @Transactional(readOnly=true)
│
├── 一个服务 + 多个数据库
│ ├── 强一致、低并发 → XA/2PC (Atomikos)
│ ├── 不想改代码 → Seata AT
│ ├── 高性能、能改造 → Seata TCC
│ └── 异步解耦即可 → 本地消息表 + MQ
│
├── 多个微服务
│ ├── 异步、最终一致可接受 → 本地消息表 + RocketMQ
│ ├── 同步、需跨服务协调 → Seata Saga 状态机
│ └── 严格资金一致 → 先看能不能合并到一个服务,不行再上 Seata TCC
│
└── 不知道该用啥
└── 先问:能不能通过业务设计避免分布式事务?
能 → 合并服务 / 聚合根 / 本地事务
不能 → 从上到下选:消息表 → Seata AT → Seata TCC → XA附录:技术栈版本建议
| 组件 | 推荐版本 | 说明 |
|---|---|---|
| Spring Boot | 3.2+ | Jakarta EE 迁移完成 |
| Seata Server | 1.8+ | 支持 Raft 模式高可用 |
| Seata Client | 1.8+ | 与 Server 保持一致 |
| RocketMQ | 5.1+ | 事务消息 + Pop 消费模式 |
| MySQL | 8.0+ | InnoDB 引擎,必须 |
| Redisson | 3.27+ | 分布式锁 |
最后一条建议:分布式事务没有银弹。每次遇到跨库/跨服务的场景,先问自己:"能不能通过调整业务边界来避免分布式事务?" 能避免就不要硬上。实在避免不了,从最简单的方案(本地消息表)开始,不要一上来就引入 Seata。