对于计算机而言,内存是临时的"工作空间",断电数据清空;而磁盘是永久的"数据仓库",我们的系统、文件、照片、代码,所有持久化数据全都存储在磁盘中。
日常使用磁盘、分区、格式化,易搞不懂磁盘底层是如何存储数据、如何定位数据、操作系统如何管理数据。今天这篇博客,从零到一拆解磁盘核心原理,从物理结构到逻辑寻址,再到操作系统文件管理、inode机制,来理解磁盘。
一、磁盘是什么?
磁盘是计算机核心的外部持久化存储设备 ,主要用于长期保存数据,不受断电影响,是所有数据落地的最终载体。其中机械磁盘是计算机中唯一的机械设备,属于外设硬件,对比内存速度较慢,但具备容量大、价格低廉的核心特点,是服务器、PC设备长期存储数据的核心硬件。
日常我们所说的磁盘主要分为两类:
-
HDD机械硬盘:依靠物理机械结构读写数据,容量大、成本低、寿命长,读写速度相对较慢,本文讲解的物理结构、寻址机制均基于机械硬盘(磁盘经典原理)。
-
SSD固态硬盘:基于闪存芯片存储,无机械结构,读写速度极快,是目前主流硬盘,但底层逻辑仍兼容传统磁盘的寻址与文件管理机制。
简单来说:磁盘就是计算机的"超大永久储物柜",所有需要长期保留的数据,都规整存放在这个柜子里,而我们接下来要搞懂的,就是这个柜子的构造、数据存放规则、以及系统如何精准找到每一份数据。
二、磁盘的物理结构
机械硬盘的所有数据读写,都依赖精密的物理机械结构,核心组成部分非常固定,弄懂这些结构,就能理解后续所有存储概念:
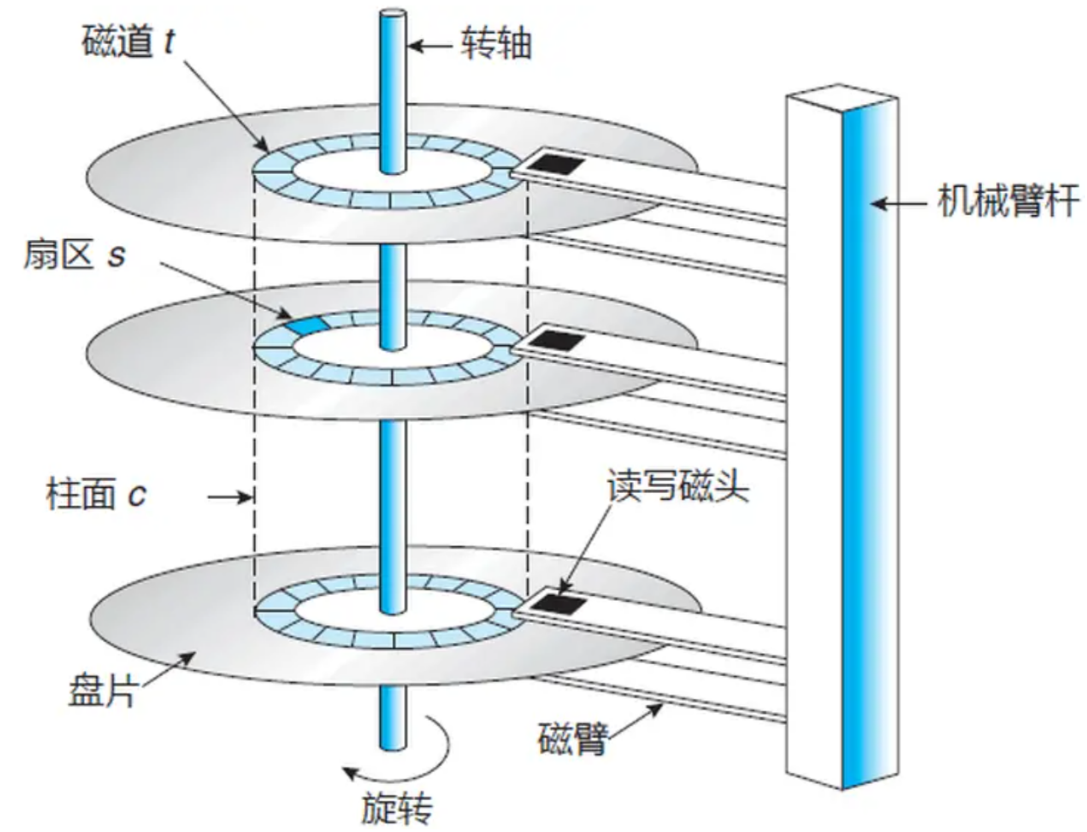
1. 盘片(Platter)
磁盘内部包含一张或多张圆形金属盘片,盘片数量也称为圆盘(platter)数 ,直接决定磁盘基础容量。盘片表面涂有磁性涂层,数据以磁性信号的形式存储在盘片表面,且每一张盘片的正反两面都可以独立存储数据。
2. 磁头(Head)
每一个盘面对应一个独立磁头,磁头不接触盘片,工作时悬浮在盘片上方。磁头的唯一作用就是读取和写入盘片上的磁性数据,磁头数量和可存储数据的盘面数量完全一致。常规情况下,每个盘片一般有上下两个盘面,分别对应1个磁头,单张盘片共2个磁头。
3. 主轴与电机
主轴固定所有盘片,工作时带动盘片高速旋转(常见转速5400转、7200转),盘片旋转+磁头静止,形成相对运动,完成数据读写。
4. 磁臂
用于固定所有磁头,可左右摆动,带动磁头移动到盘片的不同半径位置,实现不同区域的数据访问。
总结:磁盘物理工作流程------电机带动盘片旋转,磁臂带动磁头平移,磁头在对应盘面位置完成数据读写 。这里有一个极其关键的核心细节:传动臂上的所有磁头是共进退的,只能整体移动,无法单独移动某一个磁头,这个特性是后续磁盘优先按柱面读写、优化读写效率的核心原理。
结合磁盘所有物理硬件参数,我们可以得出机械磁盘标准理论容量计算公式,也是行业通用核算公式:
磁盘容量 = 磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数
为了方便大家直观看懂磁盘整体结构、理清各部件关系,下面附上磁盘物理与逻辑结构全景示意图,并对图中所有核心区域逐一解析:

三、磁盘的逻辑存储结构(核心概念)
磁盘的物理盘面是圆形的,为了方便规整存储、精准定位数据,系统将盘片表面抽象划分出三层核心逻辑结构:磁道、柱面、扇区,这也是磁盘寻址的基础。
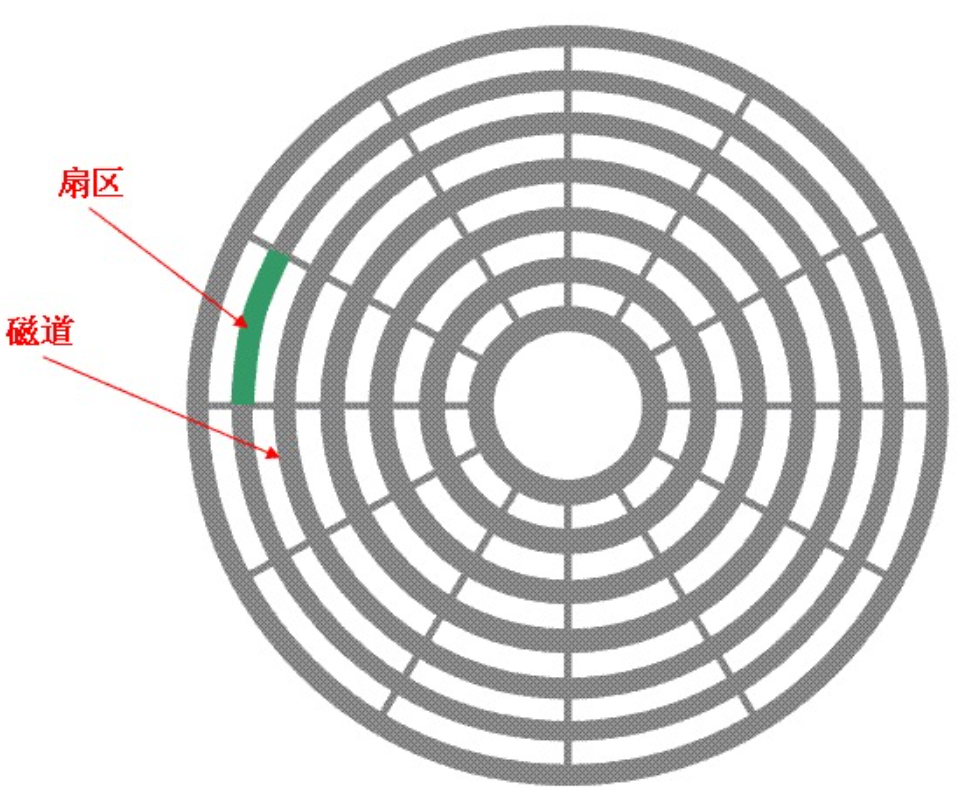
1. 磁道(Track)
盘片高速旋转时,磁头保持静止,会在盘面划出一个圆形轨迹,这个同心圆轨迹就是磁道(Track) 。一张盘面会被划分出成千上万个磁道,编号规则从盘片外圈往内圈依次递增,即0磁道、1磁道、2磁道......其中,靠近主轴的最内侧同心圆为磁头停靠区域,仅用于设备启停,不存储任何数据。
2. 柱面(Cylinder)
一块磁盘有多张盘片、多个盘面,所有盘面中,半径相同、编号一致的磁道,共同组成一个柱面 (Cylinder)。
简单理解:柱面就是垂直堆叠起来的一组磁道,在数量上,柱面个数完全等同于单盘面的磁道个数。磁盘的读写优先按照柱面进行,而非盘面,核心原因就是前文提到的「所有磁头共进退」,切换磁头无需移动磁臂,仅切换读写盘面即可,能大幅降低机械损耗、提升读写效率。
3. 扇区(Sector)
磁道是一个完整的圆环,系统将每一个磁道均匀切分成若干个小段,每一个小段就是一个扇区 。扇区是磁盘最小的物理存储单元,也是磁盘从硬件层面读出、写入信息的最小单位 ,标准单个扇区固定大小为 512 字节。系统会将每一个磁道均匀切分成若干个扇形小段,每一个小段就是一个扇区,且同一块磁盘中,每一条磁道被划分的扇区数量完全相同。
四、磁盘数据寻址:从三维CHS到一维LBA
知道了柱面、磁头、扇区的概念,核心问题来了:磁盘上成千上万个扇区,计算机如何精准定位到某一个扇区的数据?这里就诞生了磁盘两大核心寻址方式:CHS寻址、LBA寻址。
1. CHS三维寻址(物理寻址)
CHS对应三个核心参数:Cylinder(柱面)、Head(磁头)、Sector(扇区),三者可以完美抽象为一个三维数组 :磁盘[柱面号][磁头号][扇区号]。
这个三维数组,就是磁盘最原始的物理寻址模型,定位一个扇区的固定顺序完全遵循:先找柱面 → 再找磁头 → 最后找扇区。
完整定位流程:
-
定位柱面:磁臂摆动,将磁头移动到目标柱面的半径位置,确定数据所在的垂直磁道组;
-
定位磁头:激活目标盘面的磁头,确定数据所在的具体盘面;
-
定位扇区:盘片高速旋转,等待目标扇区转动到磁头下方,完成精准定位。
只要确定一组唯一的CHS坐标,就能锁定磁盘上唯一的一个扇区,这就是CHS三维寻址方式,完全贴合磁盘物理结构。
2. LBA一维寻址(逻辑寻址)
CHS寻址有明显缺陷:不同磁盘的柱面数、磁头数、扇区数各不相同,硬件差异极大,操作系统如果直接使用三维CHS坐标管理磁盘,适配难度极高、逻辑极其复杂。
为了简化管理,系统对CHS三维结构做了一次抽象降维 :将磁盘中所有扇区,按照固定顺序(柱面优先、磁头次之、扇区最后)全部拉直,拼接成一个一维线性数组。
这个一维数组的每一个下标,就是一个LBA地址(逻辑块地址),每一个LBA下标,唯一对应一个物理扇区。
简单对比:
-
CHS:三维坐标
(C, H, S),贴合物理结构,硬件层识别; -
LBA:一维下标
0、1、2、3...,逻辑线性地址,操作系统识别。
3. CHS与LBA的转换关系
操作系统只认识简单的LBA一维地址,而磁盘硬件只认识CHS三维物理坐标,磁盘固件会自动完成两者转换,核心公式如下:
LBA = C × 单柱面总扇区数 + H × 单磁道扇区数 + (S - 1)
其中:单柱面总扇区数 = 磁盘磁头数 × 单磁道扇区数,扇区号从1开始计数,LBA从0开始计数,因此需要减1修正偏移。
也就是说:操作系统下发LBA地址 → 磁盘硬件自动转为CHS物理坐标 → 精准定位扇区读写数据,这是现代磁盘读写的核心底层流程。
五、操作系统如何管理磁盘?(分区、块组、inode详解)
磁盘硬件只负责"按地址读写扇区",但文件的存储、查找、管理,全部由操作系统的文件系统完成。我们日常的分区、格式化、存文件,都是操作系统对磁盘的逻辑管理行为。
1. 磁盘分区:划分独立管理区域
一块全新的磁盘是一整块空白空间,Linux 系统无法直接精细化管理裸磁盘,因此需要分区。分区就是将整块物理磁盘划分为多个独立的逻辑区域,Linux 中所有设备均以文件形式存在,磁盘分区对应 /dev/vda1、/dev/sda1 这类设备文件,每个分区可以单独格式化、单独挂载、互不干扰。
分区的本质:给磁盘划分逻辑边界,每个分区可以独立格式化 Linux EXT 系列文件系统,拥有一套独立完整的文件系统管理规则。
2. 磁盘块:系统最小读写单元
前面提到,扇区是磁盘硬件最小读写单元(512字节) ,但操作系统如果每次只读写512字节,效率极低。因此文件系统引入了**块(Block)**的概念。
块是操作系统文件读写的最小单位,一个块由多个连续扇区组成(常见大小1KB、2KB、4KB)。系统所有文件读写、数据占用空间统计,都以块为单位,而非扇区。
3. 分区与块组:磁盘分层管理核心(配图详解)
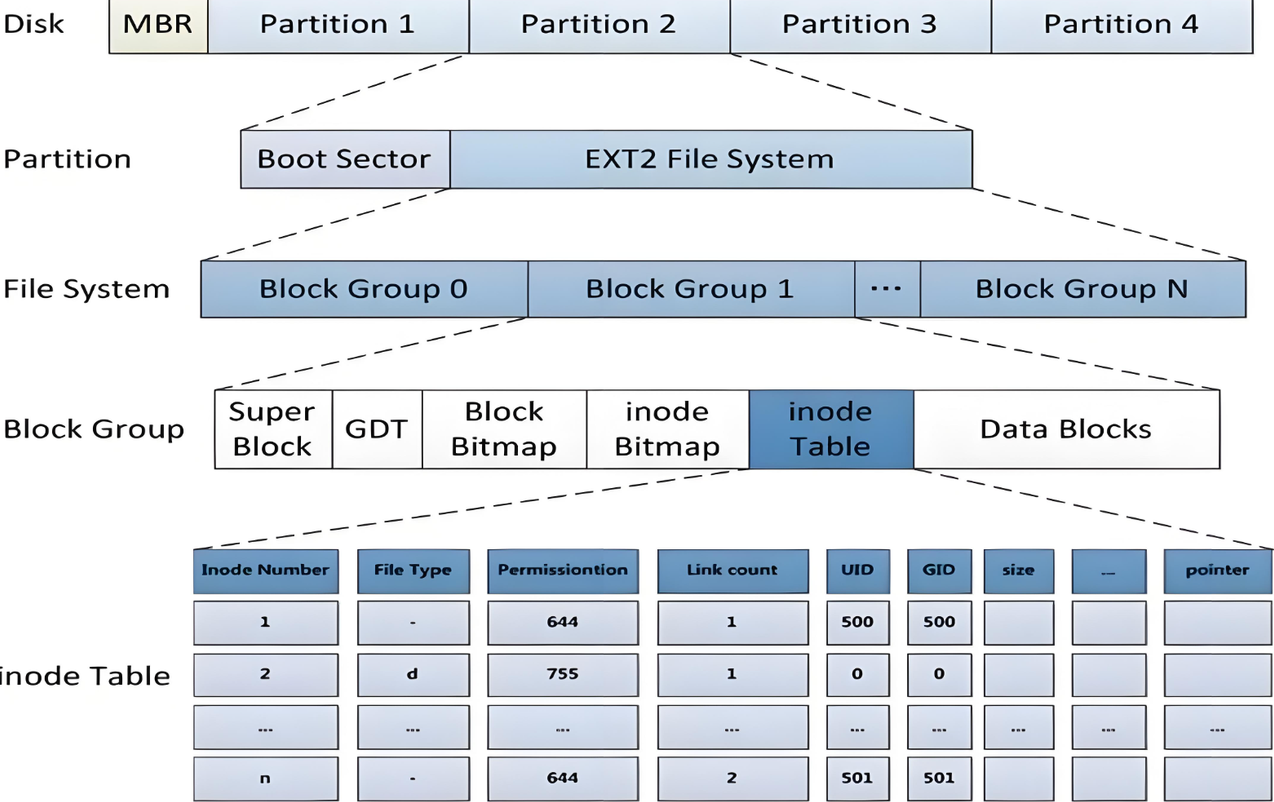
我们结合上方配图,直观看懂 Linux 操作系统对磁盘的分层管理逻辑。整块物理磁盘经过分区后,会被切分为多个独立分区。但单个分区容量依然很大,为了避免寻址低效、实现精细化管理,Linux EXT2/EXT3/EXT4 文件系统 会将每一个分区,均匀拆分为若干个大小一致的块组(Block Group) ,这张示意图清晰展示了 Linux 磁盘完整层级关系:物理磁盘 → 磁盘分区 → 多个均等块组 → 块组内部结构。
这种拆分方式的核心优势:每个块组独立管理自己的元数据和数据内容,读写数据时只需检索当前块组信息,无需遍历整个分区,极大提升磁盘读写、文件检索效率。所有块组的结构完全统一,保证磁盘管理的规整性。
根据配图结构,每一个块组内部固定包含5大核心模块,分为「元数据区域(管理信息)」和「数据区域(真实文件内容)」,各司其职、缺一不可,下面结合图示逐一精准讲解:
-
超级块(Super Block) :属于分区全局元数据,是 Linux EXT 文件系统中整个分区的"总档案手册"。配图中为块组最核心的管理区域,它不针对单个块组,而是记录整个分区 的核心参数:分区总容量、块大小、inode总数、空闲inode数量、空闲数据块数量、块组总数、挂载时间、读写校验时间等 EXT 文件系统核心信息。Linux 系统挂载分区、检测磁盘状态、执行 fsck 磁盘修复时,优先读取超级块。 核心答疑:超级块是全局分区数据,为什么不只存一份,而是在多个块组中都做备份? 1. 核心目的:容错容灾,防止分区彻底损坏 超级块是 Linux EXT 文件系统的核心命脉,如果仅保存唯一一份,一旦该扇区/数据块出现物理坏道、数据损坏,整个分区的文件系统结构信息会彻底丢失,Linux 系统无法识别、挂载分区,所有数据全部报废。多副本备份是 Linux EXT 系列文件系统经典的容错设计。 2. 所有副本数据完全一致,统一管理全局 所有块组内的超级块副本,记录的都是**整个分区的全局信息**,而非当前块组信息,所有副本实时同步、数据完全一致,不存在多份数据冲突的问题。 3. 保障故障可修复、可恢复 Linux 系统正常挂载默认读取第一个块组的主超级块;当主超级块损坏时,系统可自动读取其他块组的备份超级块,通过
e2fsck工具修复文件系统,最大限度保留分区结构与用户数据。 简单总结:单份超级块风险极高,Linux EXT 文件系统通过多副本冗余,牺牲少量磁盘空间,换取文件系统高可用性与故障自愈能力。 -
GDT 块组描述符表(Group Descriptor Table) :是 Linux EXT 文件系统专属的核心结构,GDT 是整个分区所有块组的统一信息记录表,是衔接超级块与每个块组的核心桥梁。分区被划分为多少个块组,GDT 中就对应存储多少个块组描述符,每个描述符专门记录**单个块组**的专属元数据,相当于每个块组的"精准索引名片"。核心存储内容包含:当前块组的块位图起始块号、inode位图起始块号、inode表起始块地址、当前块组空闲数据块数量、空闲inode数量、目录文件数量等核心参数。和超级块一致,GDT 也具备多副本备份机制,保障 Linux 文件系统不会因局部区块损坏而失效,让内核可以快速定位任意块组的管理区域与空闲资源。
-
块位图(Block Bitmap) :当前块组的数据块状态记录表。仅负责管理当前块组内的数据块,用二进制位标记每一个数据块的状态:0代表空闲可写入数据,1代表已占用。系统新建文件、分配存储空间时,会优先检索块位图,快速找到空闲数据块。
-
inode位图(Inode Bitmap) :当前块组的inode状态记录表。和块位图逻辑一致,专门标记当前块组内inode的使用状态:0代表inode空闲,可分配给新文件;1代表inode已被占用。每创建一个新文件,系统就会通过inode位图分配一个空闲inode。
-
inode表(Inode Table) :当前块组的文件索引仓库。集中存放本块组内所有文件、目录对应的inode结构体,每个inode大小固定(默认128字节)。这里只存储文件元数据(属性、权限、数据块指针),不存储文件真实内容,是系统快速检索文件的核心索引区域。
-
数据块(Data Block):磁盘的真实数据存储区域,也是分区占用空间最大的区域。所有用户的文件内容、目录数据、日志数据,全部存储在这里。数据块是操作系统最小读写单位,由多个连续物理扇区组成,真正落地所有持久化数据。
4. 核心概念:inode(文件索引节点)
很多人听过inode,但始终不懂其作用,这里通俗讲透:inode是文件的唯一身份标识,是文件的"属性信息卡片"。
每一个文件(普通文件、目录、链接文件),都对应一个唯一的inode,inode不存储文件内容,只存储文件的所有元数据,核心包含:
-
文件大小、创建时间、修改时间、访问时间;
-
文件权限(读、写、执行)、所属用户、所属组;
-
最重要:文件数据块的指针(记录文件内容存放在哪些磁盘块中)。
结合配图的分层结构,我们可以梳理出磁盘分层读写完整链路,彻底打通前文的寻址知识:
-
用户访问文件名;
-
系统通过文件名找到对应的inode编号;
-
读取inode中的数据块指针,定位到文件对应的磁盘块;
-
通过磁盘块对应的LBA地址,转换为CHS物理坐标;
-
磁盘硬件读写对应扇区,读取文件内容返回给用户。
简单总结:文件名给用户看,inode给系统用,数据块存真实内容。
cpp
/*
* Structure of an inode on the disk
*/
struct ext2_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
union {
struct {
__le32 l_i_reserved1;
} linux1;
struct {
__le32 h_i_translator;
} hurd1;
struct {
__le32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl; /* File ACL */
__le32 i_dir_acl; /* Directory ACL */
__le32 i_faddr; /* Fragment address */
union {
struct {
__u8 l_i_frag; /* Fragment number */
__u8 l_i_fsize; /* Fragment size */
__u16 i_pad1;
__le16 l_i_uid_high; /* these 2 fields */
__le16 l_i_gid_high; /* were reserved2[0] */
__u32 l_i_reserved2;
} linux2;
struct {
__u8 h_i_frag; /* Fragment number */
__u8 h_i_fsize; /* Fragment size */
__le16 h_i_mode_high;
__le16 h_i_uid_high;
__le16 h_i_gid_high;
__le32 h_i_author;
} hurd2;
struct {
__u8 m_i_frag; /* Fragment number */
__u8 m_i_fsize; /* Fragment size */
__u16 m_pad1;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
};
/*
#define EXT2
* Constants relative to the data blocks
*/
_NDIR_BLOCKS 12
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1)
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1)
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
备注:EXT2_N_BLOCKS = 155、Linux 文件属性与文件数据的关联机制(核心重点)
在 Linux EXT 系列文件系统中,所有文件严格遵循属性与内容分离存储的核心设计,这是 Linux 磁盘文件管理的底层基石。很多人分不清「文件名、文件属性、文件数据」三者关系,下面基于 Linux 机制完整梳理关联逻辑,打通所有底层链路。
1. 核心分离规则
文件整体由两部分组成:文件属性(元数据) + 文件内容(真实数据),二者分开存储在磁盘不同区域:
-
文件属性 :全部存储在inode 表 的 inode 结构体中,包含文件大小、权限、属主、时间戳、数据块指针等;注意:inode 内部不保存文件名。
-
文件数据 :真实的文件内容(文本、代码、图片数据等),全部存储在分区的 Data Block 数据块 中。
2. inode:属性与数据的绑定桥梁
每一个 inode 内部都有一个核心数组 i_block[],专门存放数据块指针。系统通过 inode 实现双向绑定:
-
读取文件属性:直接读取当前文件 inode 的元数据信息;
-
读取文件内容:通过 inode 中的数据块指针,精准找到磁盘上对应的 Data Block,读取真实数据。
也就是说:inode 一手持有文件所有属性,一手指向文件所有数据块,实现了「属性」和「数据」的强绑定。
3. 文件名与 inode 的关联(目录文件的作用)
既然 inode 不存文件名,操作系统如何通过文件名找到文件?答案依靠目录文件:
目录本质也是一个文件,拥有自己的 inode 和数据块。目录文件的数据块中,专门存储「文件名 + 对应 inode 号」的映射表。
这就是三者的完整关系:
-
用户操作:通过文件名访问文件;
-
系统解析:读取目录文件,通过文件名查到对应的 inode 号;
-
获取属性:通过 inode 号找到 inode 表,读取文件所有属性;
-
获取数据:通过 inode 内的块指针,找到数据块,读取文件真实内容。
4. 完整关联闭环总结
文件名(目录维护)→ inode 号 → inode 属性信息 + 数据块指针 → 磁盘数据块(真实文件内容)。
这也是 Linux 系统中硬链接、文件删除的底层核心逻辑:多个文件名可以对应同一个 inode(硬链接),删除文件名仅删除目录映射关系,不删除 inode 和磁盘数据,因此文件数据依然保留,这是 Linux 文件系统的经典特性。
六、全文总结
-
磁盘是计算机持久化存储硬件,负责长期保存数据,是所有文件的最终载体;
-
磁盘物理结构由盘片、磁头、磁臂、电机组成,依靠机械运动完成数据读写;
-
磁盘逻辑结构分为磁道、柱面、扇区,扇区是磁盘最小物理存储单元;
-
CHS是三维物理寻址(柱面、磁头、扇区),贴合磁盘硬件结构,精准定位扇区;LBA是一维逻辑寻址,是系统简化管理的抽象模型,两者可相互转换;
-
Linux 系统通过分区拆分磁盘,通过 EXT4 块组精细化管理分区,以块为单位完成系统读写;
-
inode 是 Linux 文件的唯一索引标识,存储文件权限、属性与数据块指针,是 Linux 管理所有文件的核心依托。