一、引言
Hudi 1.x 提供5 种查询类型,本质上是对同一份数据的不同视图(View),为不同数据消费场景提供匹配的语义和性能特征。

二、Snapshot Query
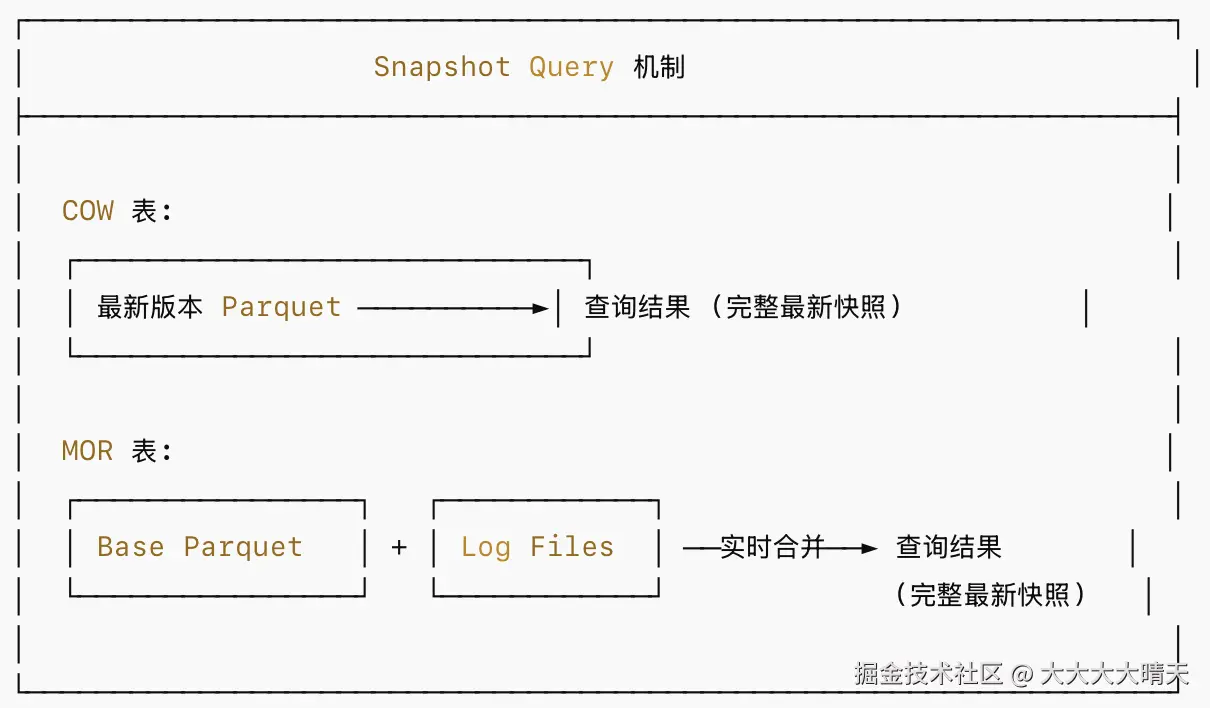
Snapshot Query(快照查询):返回表在最新提交时刻的 完整数据状态。
- 对 COW 表:直接读取最新版本的 Parquet 文件(性能等同于原生 Parquet 查询)
- 对 MOR 表:读取 Base File 并实时合并(on-the-fly merge)所有未压缩的 Log File
适用场景:
- 需要看到最新数据状态的 BI 报表
- 数据一致性要求高的分析场景
- 实时数据探查与 Ad-hoc 查询
三、Read Optimized Query
Read Optimized Query(读优化查询):仅读取已经合并(compacted)的 Base File,不合并 Log File。
- 对 COW 表:等同于 Snapshot Query(因为 COW 表没有 Log File)
- 对 MOR 表:只看到最近一次 compaction 时刻的数据,不包含后续的增量更新

适用场景:
- 对查询性能要求极高、可容忍一定数据延迟的场景
- MOR 表上的大规模 OLAP 查询
- 报表类场景中不需要秒级新鲜度的分析
四、Incremental Query
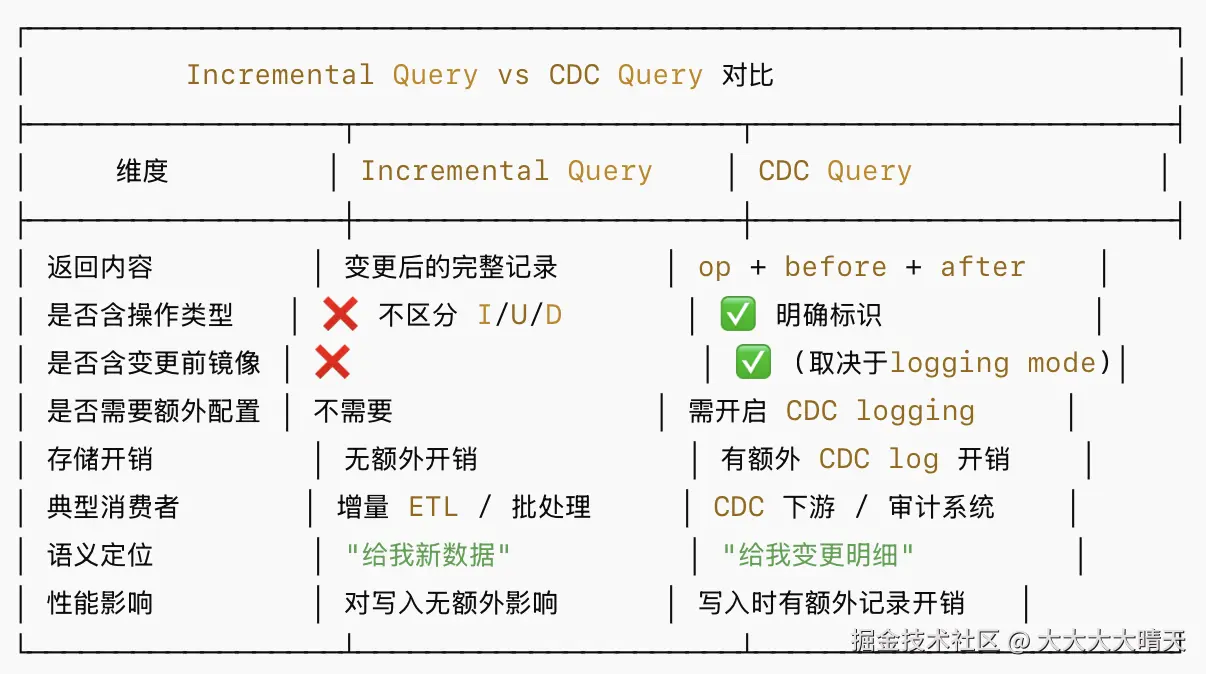
Incremental Query(增量查询):仅返回在给定时间范围内发生变更的记录。利用 Hudi Timeline 机制,精确识别哪些 commit 在查询区间内,只读取相关文件中的变更数据。

适用场景:
- ETL 管道中的增量数据同步
- 构建增量物化视图
- 避免全量扫描的增量报表更新
- 增量数据导出到下游系统
五、Time Travel Query
Time Travel Query(时间旅行查询):允许用户查询表在历史某个时刻的完整快照状态,而非只能看最新版本。Hudi 利用 Timeline 上的 commit 信息和文件版本管理来重建历史状态。

适用场景:
- 数据审计与合规回溯
- 误操作后的数据恢复参考
- 调试数据管道中的问题(对比不同时间点的数据状态)
- 可重复的机器学习特征快照
- 监管合规场景下的历史状态取证
六、CDC Query
CDC Query(变更数据捕获查询):CDC Query 不仅返回变更的记录内容,还返回变更的操作类型以及变更前后的镜像(before/after image)。这比 Incremental Query 提供了更丰富的变更语义,CDC 功能需要在表创建或写入时启用。

适用场景:
- 构建下游 CDC 流水线(替代外部 CDC 工具的部分场景)
- 数据同步到其他系统时需要区分 INSERT/UPDATE/DELETE
- 审计日志生成
- 构建 SCD(Slowly Changing Dimension)逻辑
- 实时数据一致性校验
Incremental Query 与 CDC Query 这两者容易混淆,核心区别如下:
七、选型指南
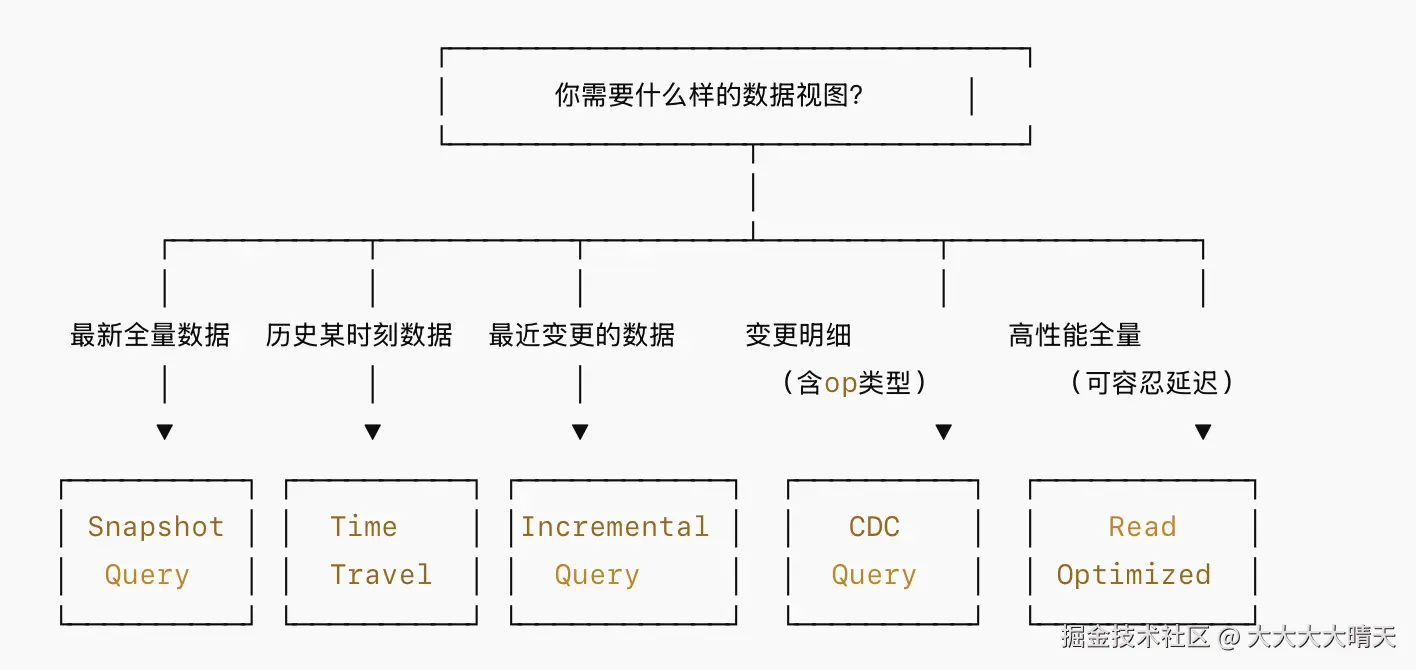
对于Hudi表数据查询的查询类型选择参考如下:
结合Hudi表类型与查询类型,搭配使用的组合矩阵如下:
bash
┌────────────────────────────────────────────────────────────────────────────────────────────────┐
│ Table Type × Query Type 完整组合矩阵 (Hudi 1.x) │
├──────────────┬────────────┬──────────────┬────────────┬─────────────┬──────────────────────────┤
│ │ Snapshot │ Read │Incremental │ Time Travel │ CDC Query │
│ │ Query │ Optimized │ Query │ Query │ │
├──────────────┼────────────┼──────────────┼────────────┼─────────────┼──────────────────────────┤
│ │ │ │ │ │ │
│ COW │ ✅ 最新快照 │ ✅ 等同 │ ✅ 增量 │ ✅ 历史快照 │ ✅ 需开启 CDC 功能 │
│ │ 性能:极好 │ Snapshot │ 变更记录 │ 任意时间点 │ 返回 op + before/after │
│ │ 新鲜度:实时│ (COW无Log) │ 新鲜度:实时│ 受Cleaner限 │ 有额外存储开销 │
│ │ │ │ │ │ │
├──────────────┼────────────┼──────────────┼────────────┼─────────────┼──────────────────────────┤
│ │ │ │ │ │ │
│ MOR │ ✅ 最新快照 │ ✅ 仅 Base │ ✅ 增量 │ ✅ 历史快照 │ ✅ 需开启 CDC 功能 │
│ │ 需合并Log │ File │ 变更记录 │ 任意时间点 │ 返回 op + before/after │
│ │ 性能:中等 │ 性能:极好 │ 新鲜度:实时│ 受Cleaner限 │ 有额外存储开销 │
│ │ 新鲜度:实时│ 新鲜度:滞后 │ │ │ │
│ │ │ │ │ │ │
└──────────────┴────────────┴──────────────┴────────────┴─────────────┴──────────────────────────┘八、查询类型使用实践
- Snapshot Query
lua
-- Spark SQL(默认即为 Snapshot Query)
SELECT * FROM hudi_table
WHERE partition_date = '2024-01-01'
AND status = 'active';
// DataFrame API
spark.read.format("hudi")
.option("hoodie.datasource.query.type", "snapshot")
.load("s3://bucket/hudi_table")- Read Optimized Query
lua
-- Hive/Presto/Trino 中通过后缀表名访问 [⚠️ 见注1]
SELECT * FROM hudi_table_ro
WHERE partition_date = '2024-01-01';
// Spark DataFrame API
spark.read.format("hudi")
.option("hoodie.datasource.query.type", "read_optimized")
.load("s3://bucket/hudi_table")- Incremental Query
lua
// 增量查询
val incrementalDF = spark.read.format("hudi")
.option("hoodie.datasource.query.type", "incremental")
.option("hoodie.datasource.read.begin.instanttime", "20240101120000")
// 可选:指定结束时间
// .option("hoodie.datasource.read.end.instanttime", "20240101130000")
.load("s3://bucket/hudi_table")- Time Travel Query
lua
-- Spark SQL 时间旅行语法
SELECT * FROM hudi_table TIMESTAMP AS OF '2024-01-01 12:00:00';
// DataFrame API
spark.read.format("hudi")
.option("as.of.instant", "20240101120000")
.load("s3://bucket/hudi_table")- CDC Query
java
// 写入侧开启 CDC
val writeOptions = Map(
"hoodie.table.cdc.enabled" -> "true",
"hoodie.table.cdc.supplemental.logging.mode" -> "data_before_after"
)
// 读取侧消费 CDC 数据
val cdcDF = spark.read.format("hudi")
.option("hoodie.datasource.query.type", "incremental")
.option("hoodie.datasource.query.incremental.format", "cdc")
.option("hoodie.datasource.read.begin.instanttime", "20240101120000")
.load("s3://bucket/hudi_table")
// 处理 CDC 记录
cdcDF.select("op", "before", "after")
.filter(col("op") === "u") // 仅处理 update
.show()