AI 编码工具读文件没问题,但遇到"项目怎么分层""这个接口后面调用了谁""改一个类会影响哪些流程"时,只靠搜索文件名和关键字就不够了。GitNexus 的思路是先把项目索引成代码知识图谱,再把这份图谱提供给 CLI、Web UI 和 MCP。接入 Codex 之后,Codex 可以直接读取 GitNexus 的项目上下文、功能聚类和执行流。
这次操作基于一个多模块 Java 项目 bo-camunda-flow。过程里包含安装、Codex MCP 配置、一次目录错误、项目索引、Web UI 查看图谱,以及最后让 Codex 基于 GitNexus 做架构分析。
环境和安装
先确认本机 Node 和 npm。实际环境是 Node v22.12.0,npm 10.9.0。

GitNexus 的 CLI 会加载本地解析和图数据库相关依赖,版本过低时容易在安装或运行阶段出问题。这里保留环境信息,不是为了凑步骤,而是后面遇到安装失败、native dependency 构建失败时能快速判断是不是运行环境引起的。
全局安装 GitNexus:
bash
npm install -g gitnexus@latest
gitnexus --version安装完成后,版本返回 1.6.5。中间出现 deprecated 警告不影响使用。

如果安装时卡在可选语法包构建,可以跳过部分可选 grammar:
bash
GITNEXUS_SKIP_OPTIONAL_GRAMMARS=1 npm install -g gitnexus@latest配置到 Codex
GitNexus 最值得用的地方不是单独跑 CLI,而是接到 Codex 这类支持 MCP 的工具里。这里使用全局安装后的命令注册 MCP:
bash
codex mcp add gitnexus -- gitnexus mcp终端返回 Added global MCP server 'gitnexus'.,说明 Codex 已经能启动 GitNexus MCP 服务。

也可以用 npx 写法:
bash
codex mcp add gitnexus -- npx -y gitnexus@latest mcp两种方式都可以。全局安装后使用 gitnexus mcp,启动会更直接一些。
GitNexus 也提供了通用配置命令:
bash
gitnexus setup它会尝试自动检测本机安装的编辑器并写入 MCP 配置。手动执行 codex mcp add 的好处是更明确,只改 Codex;gitnexus setup 适合同时配置 Claude Code、Cursor、Codex 等多个工具。文章里如果只讲 Codex,保留 codex mcp add 这条命令更清楚。
gitnexus analyze 是核心命令
GitNexus 的入口命令是:
bash
gitnexus analyze这个命令会扫描当前 Git 仓库,解析代码,生成 .gitnexus 本地索引,并把仓库注册到全局 registry。后面的 Web UI 和 MCP 都依赖这个索引。
这次使用的是:
bash
gitnexus analyze --embeddings --skills --verbose三个参数的意思分别是:
| 参数 | 作用 | 是否必须 |
|---|---|---|
--embeddings |
生成语义搜索向量,后续 query/search 更适合自然语言检索,但会更慢、更吃资源 | 可选 |
--skills |
根据项目功能聚类生成 repo-specific skills,方便 AI 工具获得更具体的模块上下文 | 可选 |
--verbose |
输出更详细的分析日志,适合第一次安装、排查跳过文件或解析问题 | 可选 |
不加这些参数也可以:
bash
gitnexus analyze第一次体验只想快速看图谱,可以先跑默认命令。需要更好的语义搜索和 AI 上下文时,再加 --embeddings --skills。
这里可以按目标选择命令。只想生成基础图谱,用 gitnexus analyze;准备接给 Codex 做自然语言查询,用 gitnexus analyze --embeddings;希望 AI 工具拿到更细的模块上下文,用 --skills;第一次排错或者想看跳过了哪些文件,再加 --verbose。这些参数是增强项,不是必填项。
实际使用时可以分两轮跑。第一轮先执行 gitnexus analyze,确认项目能被正常解析、gitnexus list 能看到仓库、gitnexus status 是 up-to-date。第二轮再按需要补 --embeddings 和 --skills。这样做更稳:如果基础索引都没生成,就没必要先花时间生成向量;如果只是想让 Web UI 画出关系图,默认 analyze 已经够用;如果准备让 Codex 做自然语言问答和模块分析,再上增强参数更合适。
--verbose 不建议长期默认开启。它适合第一次接入或排查阶段,能看到更详细的解析过程;等命令稳定后,日常只保留需要的参数即可。大项目生成 embeddings 的时间会更长,最好在机器空闲时跑。
如果项目改动频繁,提交前重新执行一次 gitnexus analyze,再让 Codex 查询,会比拿旧索引分析更可靠。
多人协作项目里,也要先确认当前分支和本地改动状态。 这样结果更容易稳定复现。
一个常见报错:当前目录不是 Git 仓库
第一次直接执行 analyze 时,终端提示:
text
Not inside a git repository.
Tip: pass --skip-git to index any folder without a .git directory.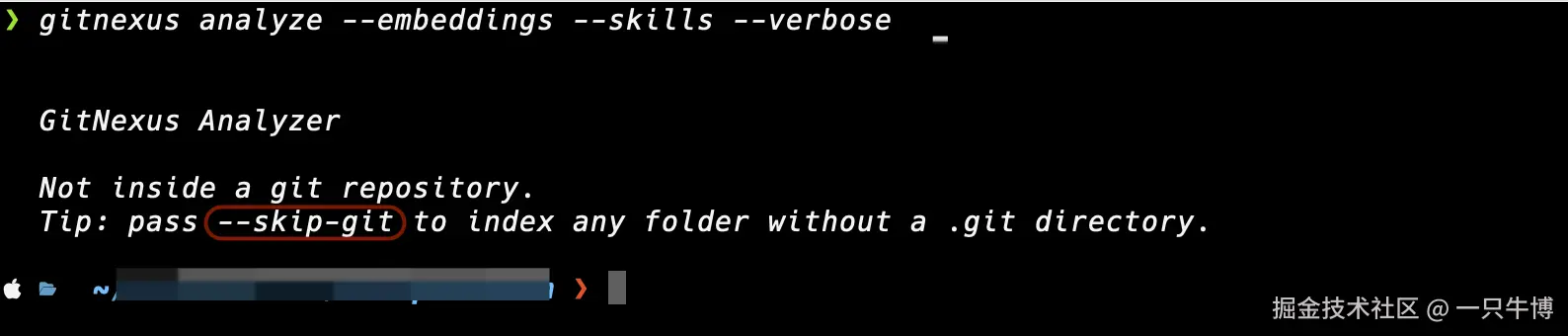
原因很简单:命令跑在了非 Git 目录里。GitNexus 默认需要在 Git 仓库里分析,因为它要记录项目路径、commit 和索引状态。
正确做法是进入项目根目录:
bash
cd /Users/xiaobo/huawei-code/bo-camunda-flow
gitnexus analyze --embeddings --skills --verbose如果确实要分析普通文件夹,可以加:
bash
gitnexus analyze --skip-git索引项目并验证状态
在 bo-camunda-flow 目录下重新执行后,GitNexus 完成索引:
text
105 files
863 symbols
1844 edges
28 clusters
32 processes这些统计分别对应文件、代码符号、关系边、功能聚类和执行流程。对于后续分析来说,edges、clusters、processes 比文件数更关键,因为它们才是调用关系和模块边界的来源。
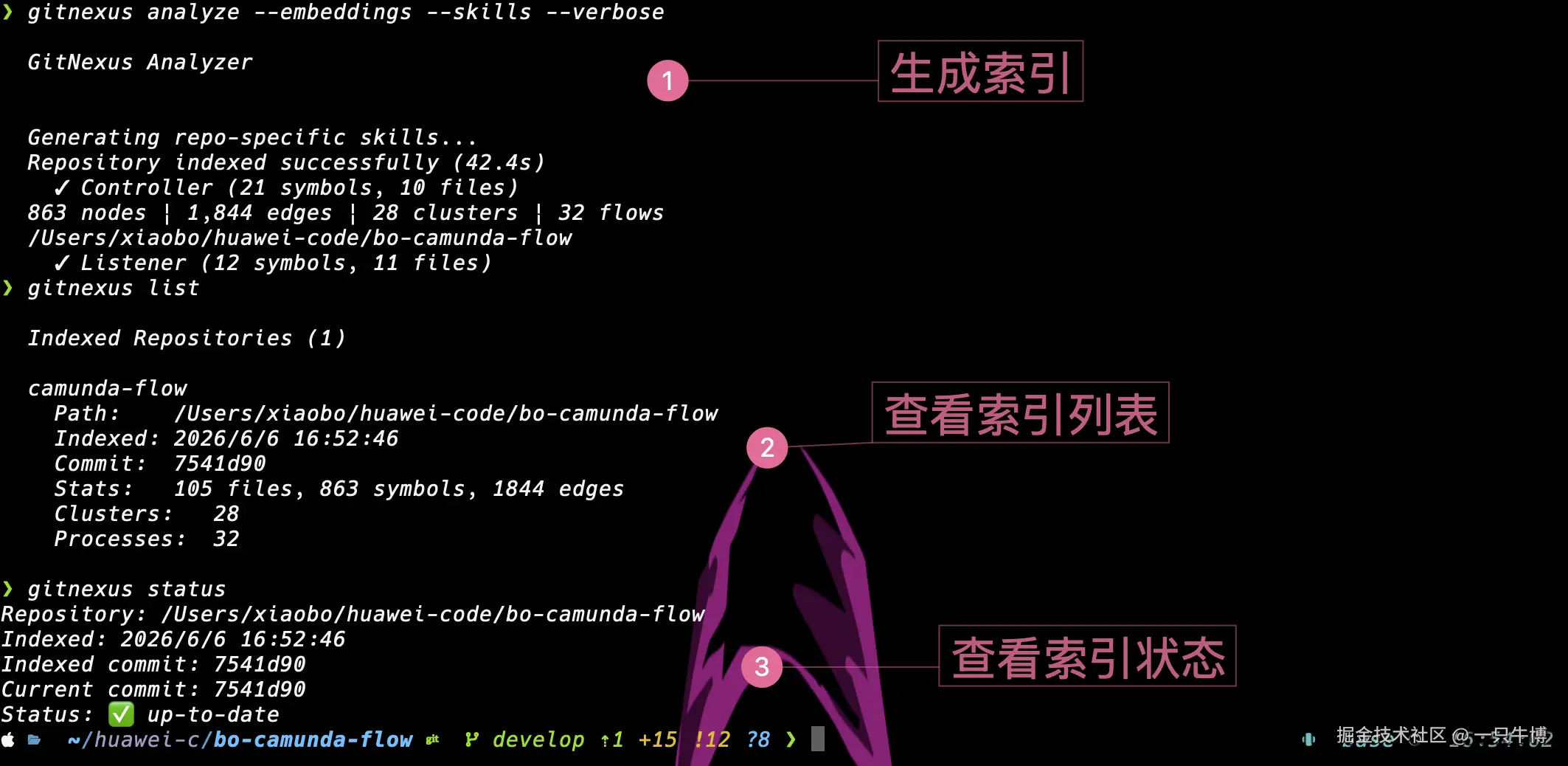
索引完成后,建议顺手检查:
bash
gitnexus list
gitnexus statusgitnexus list 可以看到已注册仓库,gitnexus status 用来确认当前 commit 和 indexed commit 是否一致。图里显示 Status: up-to-date,说明当前索引没有过期。
启动 Web UI
本地启动服务:
bash
gitnexus serve输出里能看到:
text
MCP HTTP endpoints mounted at /api/mcp
GitNexus server running on http://localhost:4747浏览器打开:
text
http://localhost:4747页面会列出已经索引的 camunda-flow,并显示 105 files、863 symbols、32 flows。
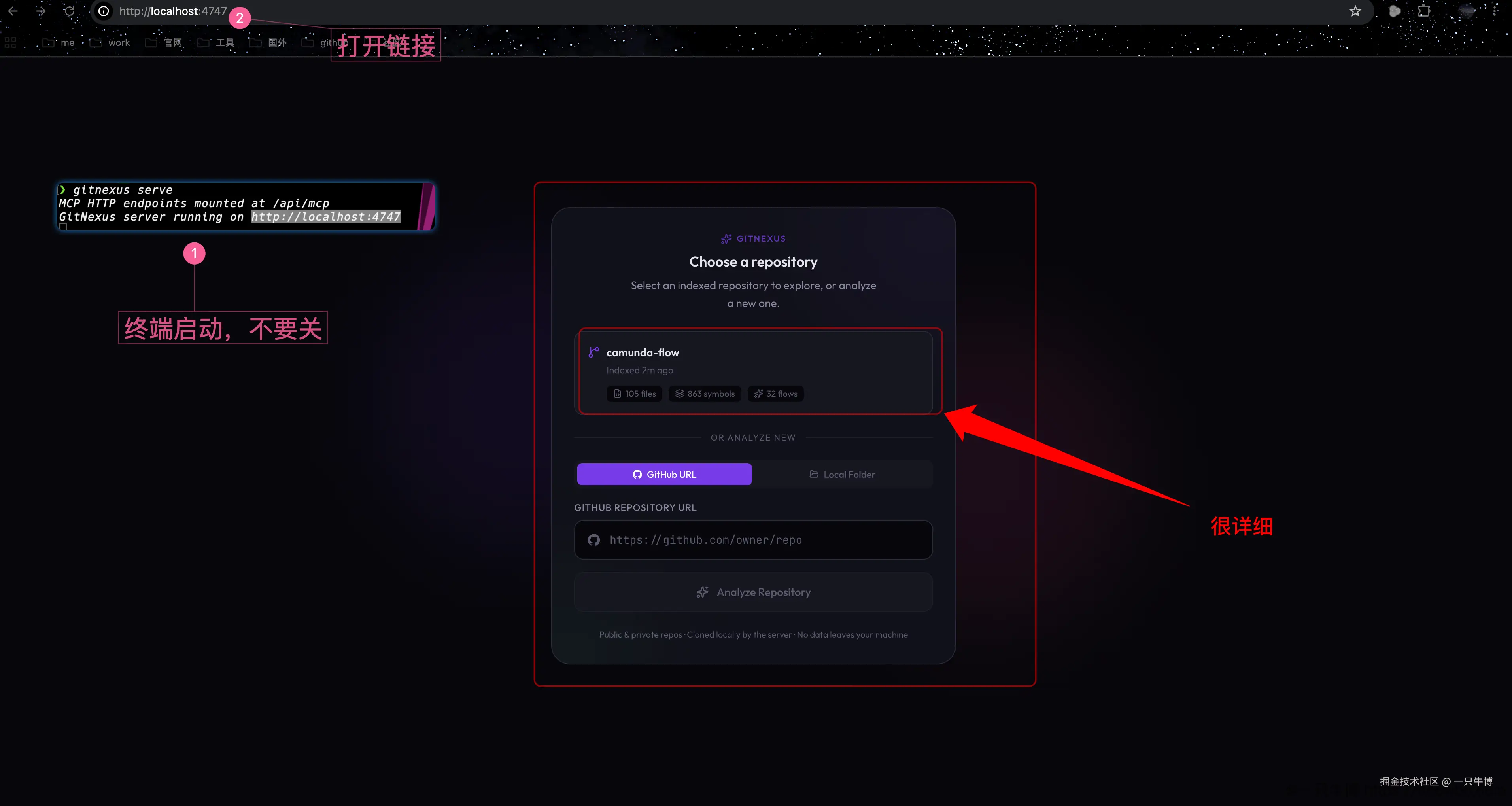
gitnexus serve 启动后,终端要保持运行。Web 页面只是前端入口,真正提供仓库列表、图谱数据和 MCP HTTP endpoint 的是这个本地服务。页面里显示的文件数、符号数和流程数来自前面生成的 .gitnexus 索引,不需要重新上传代码。
进入项目后,左侧是文件树,右侧是知识图谱。flow-common、flow-config、flow-service、flow-web 这些模块能在左侧直接看到;右侧图谱展示了 863 个节点和 1844 条边。
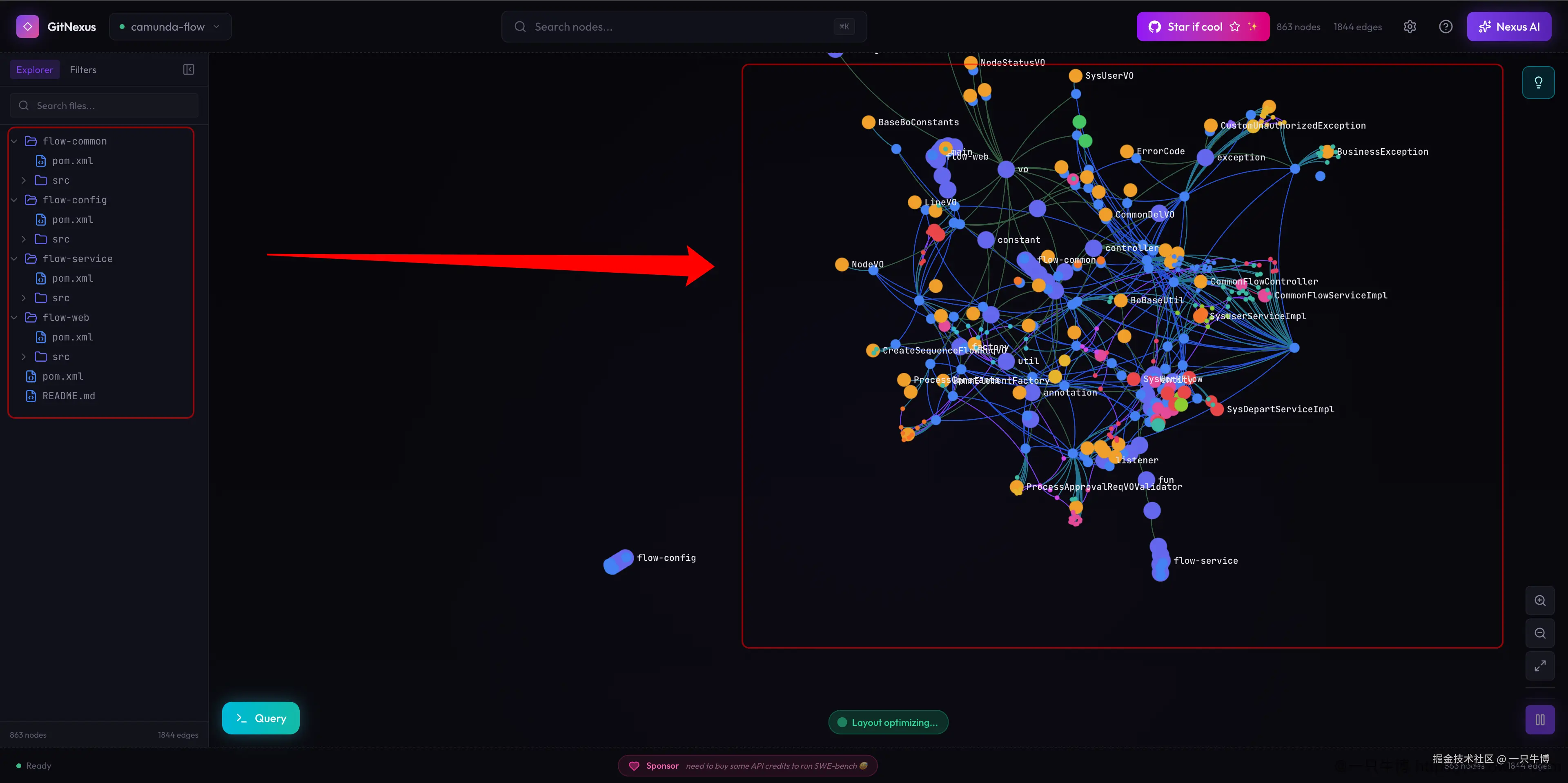
图谱的作用不是替代 IDE,而是先给出关系视角。比如 flow-service 附近关系密度更高,Controller、CommonFlowServiceImpl、SysWorkFlowServiceImpl 等节点集中在主干区域,说明业务逻辑主要围绕这些类展开。
对业务项目来说,文件树只回答"代码放在哪",图谱回答"代码之间怎么连"。这两个视角放在一起比较好用:左侧能看到 Maven 模块拆分,右侧能看到哪些类处在关系中心。初次接手项目时,可以先从高连接节点下手,再回到源码确认职责。
点击某个节点后,左侧会打开 Code Inspector,并定位到源码。这里选中的是 ProcessDetailInfoRespVO,能直接看到 Java 文件内容、注解和字段。
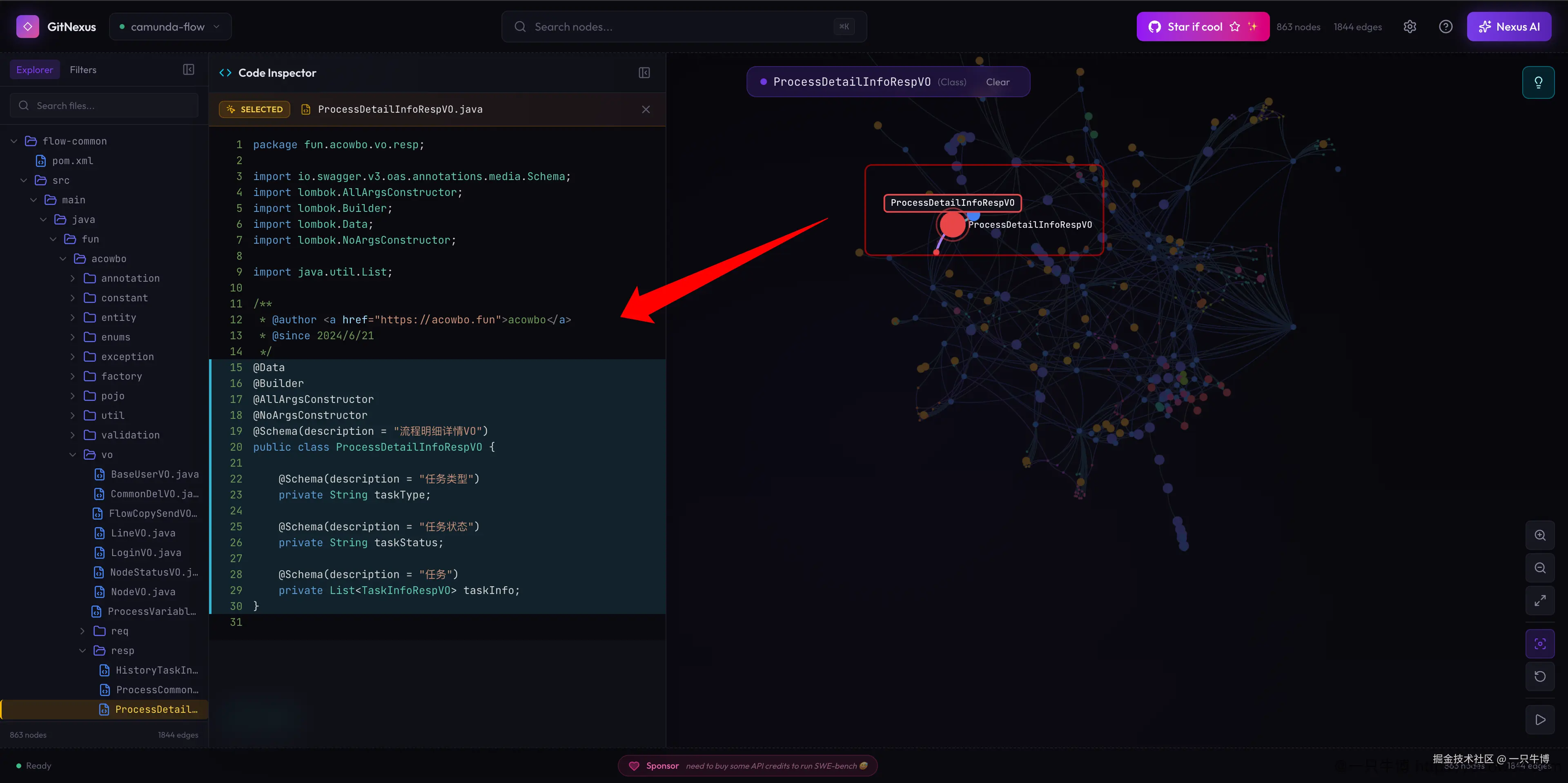
这一步比较实用:先在图上找到节点,再回源码确认。图谱负责告诉你"它和谁有关",源码负责确认"它到底做什么"。
让 Codex 调 GitNexus 分析项目
配置 MCP 后,Codex 可以直接调用 GitNexus 工具。实际分析时,先让 Codex 分析项目架构,它调用了:
text
gitnexus.query
gitnexus.read_mcp_resource读取的资源包括:
text
gitnexus://repo/camunda-flow/context
gitnexus://repo/camunda-flow/clusters
gitnexus://repo/camunda-flow/processescontext 给项目概览,clusters 给功能聚类,processes 给执行流程。相比直接让 Codex 扫目录,这种方式更快建立项目地图。
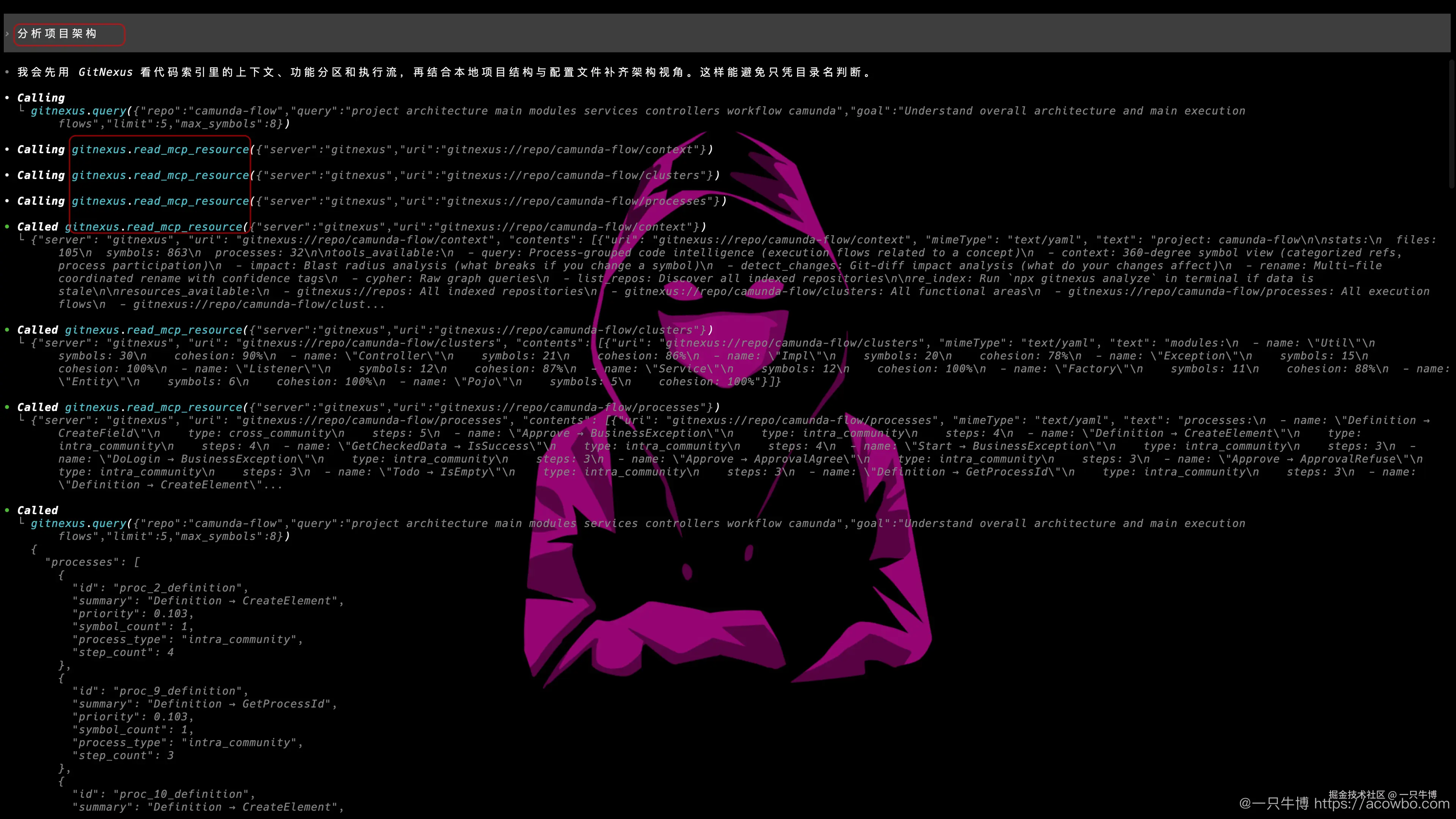
这一步相当于让 Codex 先读"索引摘要",而不是从零开始搜索。query 适合按概念找执行流,read_mcp_resource 适合读取固定资源,例如项目概览、功能区、流程列表和图 schema。对一个陌生项目来说,先拿这些信息再展开源码分析,方向会更准。
继续分析时,Codex 又结合本地文件和 GitNexus 上下文确认项目结构。它先看 pom.xml 和 Java 文件,再围绕关键类调用 gitnexus.context,例如 CommonFlowServiceImpl、CommonFlowController、SysWorkFlowServiceImpl。
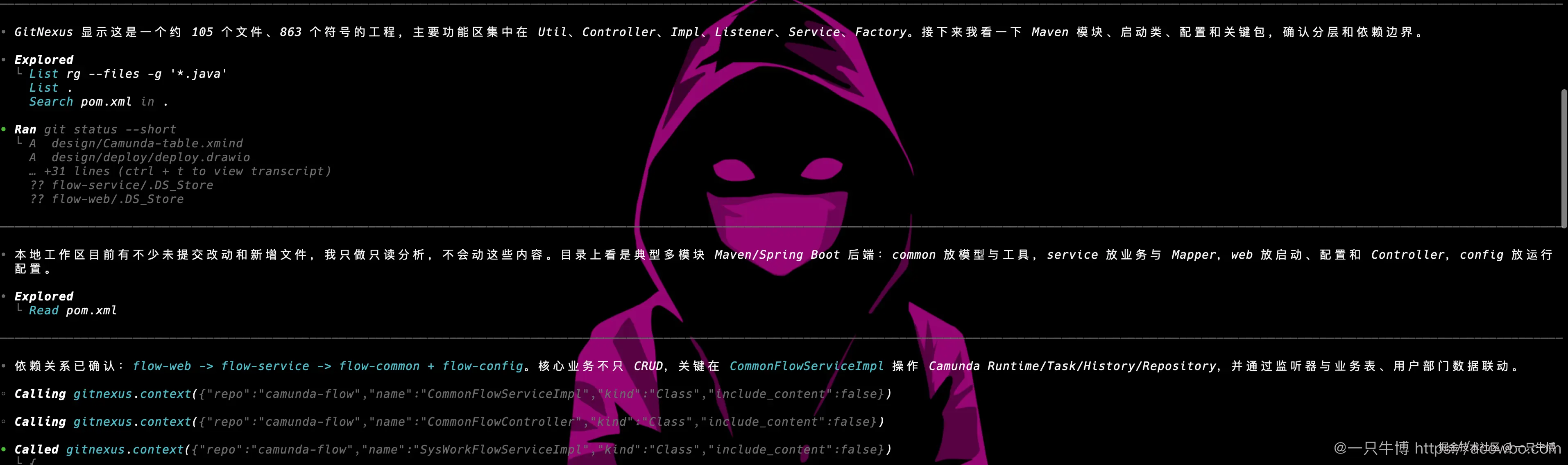
这里可以看出 GitNexus 和普通 grep 的区别。grep 能找到包含关键字的文件,但不会主动告诉你这些类处在什么流程里。context 会围绕一个符号返回调用方、被调用方、流程参与情况和相关关系,适合继续追 Controller 到 Service、Service 到 Camunda Runtime 的路径。
最后得出的结论是:这是一个多模块 Maven 的 Spring Boot + Camunda 7 工作流后端。模块关系大致是:
text
flow-web
-> flow-service
-> flow-common
-> flow-configflow-web 负责应用入口、REST Controller 和 Web 配置;flow-service 负责业务实现;flow-common 放模型、VO、枚举、异常和 BPMN 生成工具;flow-config 放 MyBatis、Camunda、Sa-Token、日志和应用配置。

这类结论不是单靠目录名猜出来的。GitNexus 提供了功能聚类和执行流,Codex 再结合本地源码确认关键路径。比如流程部署链路被整理为:
text
POST /sys/flow/deploy
-> SysWorkFlowController.definition
-> SysWorkFlowServiceImpl.processDeploy
-> Bpmn.createEmptyModel
-> BpmnElementFactory / BpmnModelUtil
-> CamundaProcessUtil
-> repositoryService.createDeployment().deploy()流程启动链路被整理为:
text
POST /flow/start
-> CommonFlowController.start
-> CommonFlowServiceImpl.processStart
-> runtimeService.startProcessInstanceById审批链路被整理为:
text
POST /flow/approve
-> CommonFlowServiceImpl.processApproval
-> taskService.complete / delegateTask
-> runtimeService.createProcessInstanceModification这就是 GitNexus 接入 Codex 后最直接的好处:不是只回答"某个类在哪里",而是能把类、模块、接口和业务流程串起来。
常用命令整理
安装和配置:
bash
npm install -g gitnexus@latest
gitnexus --version
codex mcp add gitnexus -- gitnexus mcp索引项目:
bash
gitnexus analyze
gitnexus analyze --embeddings
gitnexus analyze --skills
gitnexus analyze --embeddings --skills --verbose
gitnexus analyze --force
gitnexus analyze --skip-git索引状态:
bash
gitnexus list
gitnexus status启动服务和 MCP:
bash
gitnexus serve
gitnexus mcp直接查询图谱:
bash
gitnexus query "authentication flow"
gitnexus context CommonFlowServiceImpl
gitnexus impact CommonFlowServiceImpl --direction upstream
gitnexus detect-changes
gitnexus cypher "MATCH (n) RETURN count(n) AS count"这几个命令可以对应不同场景:
| 命令 | 适合场景 |
|---|---|
query |
按自然语言或关键词找相关执行流程 |
context |
看一个类、方法、函数的上下游关系 |
impact |
改动前看影响面,尤其是公共 Service、工具类、接口 DTO |
detect-changes |
已经有本地改动时,分析当前 diff 影响了哪些符号和流程 |
cypher |
直接查底层图数据库,适合做更精确的结构查询 |
调试和改动分析怎么用
GitNexus 自己的定位并不只是"画图"。分析它的项目实现后,可以看到它围绕 MCP 暴露了一批面向 AI Agent 的工具:query 用来按概念找流程,context 用来查看单个符号的上下游,impact 用来分析变更影响,detect_changes 用来把当前 Git diff 映射到受影响符号和流程,cypher 则保留了底层图查询能力。这些工具组合起来,比较适合 debugging 和重构前检查。
比如线上某个流程启动接口异常,普通排查通常是先搜接口路径,再进 Controller,再进 Service,然后手动追 RuntimeService、RepositoryService、TaskService 等调用。接入 GitNexus 后,可以先问:
bash
gitnexus query "start workflow process"找到相关流程后,再看核心类:
bash
gitnexus context CommonFlowServiceImpl如果准备修改 CommonFlowServiceImpl,再跑:
bash
gitnexus impact CommonFlowServiceImpl --direction upstream这样能先知道哪些 Controller、流程节点或其他服务依赖它。代码已经改完但还没提交时,用:
bash
gitnexus detect-changes它会根据当前 Git diff 反查受影响的符号和流程。这个能力比单纯看 git diff 更接近实际开发场景,因为很多问题不是"改了哪一行",而是"这行被哪些入口和流程使用"。
在 Codex 里,这套流程可以直接通过 MCP 完成。先让 Codex 用 query 找问题相关流程,再用 context 深挖关键类,最后用 impact 或 detect_changes 做改动前后的风险判断。GitNexus 的好处不是替代调试器,而是把排查入口提前收窄,让人不用从整个项目目录里盲找。
维护命令:
bash
gitnexus clean
gitnexus clean --all --force
gitnexus wiki多仓库或多服务场景还可以用 group 命令:
bash
gitnexus group create <name>
gitnexus group add <group> <groupPath> <registryName>
gitnexus group sync <name>
gitnexus group query <name> "<query>"
gitnexus group status <name>GitNexus 适合做什么
从这次使用看,GitNexus 的好处主要在四个地方。
第一,项目接手更快。query、context、clusters、processes 能先给出模块和流程视角,不用从目录开始盲翻。
第二,调试更有方向。遇到 bug 时,可以先用 query 找相关流程,再用 context 看某个类的调用方和被调用方,最后回源码确认逻辑。GitNexus 自己也把 debugging 作为典型使用场景,因为它擅长沿调用链追踪问题。
第三,改代码前能看影响面。impact <symbol> --direction upstream 可以看哪些调用方、模块或流程可能受影响,比只靠 IDE 的引用搜索更贴近"业务流程会不会断"。
第四,Codex 的项目分析不再只靠 grep。MCP 让 Codex 直接读 GitNexus 的图谱资源,回答架构、流程、模块职责时更容易落到真实文件和真实调用关系上。
它不是运行时监控,也不能保证覆盖反射、动态调用和所有框架魔法。更合理的用法是:用 GitNexus 快速建立结构判断,再回源码验证关键路径。对于 bo-camunda-flow 这种多模块 Spring Boot + Camunda 项目,这个组合已经足够把架构梳理、流程追踪和改动影响分析做得更快。