现有的 PIC 方案(位置无关 KV 缓存复用)实际加速效果并不明显,RedKnot 在注意力头粒度上复用和重算缓存,配合分层稀疏 FFN 和 SegPagedAttention,在答案质量不降的前提下,把首 token 延迟最高压到原来的约 1/3.5
一、位置无关缓存复用
长上下文推理里,KV 缓存是绕不开的系统瓶颈:上下文越长,缓存吃掉的显存越多,首 token 延迟(TTFT)也涨得越凶。一条很自然的优化路是 KV 缓存复用 ------ 在 RAG、长文档问答、智能体这类场景里,同一批文档块会反复出现在不同请求的 prompt 里,如果能把它们的 KV 提前算好存起来,遇到时直接取用,就省掉了重算
但这里有个关键问题,因果语言模型的特点让传统前缀缓存只有在新旧请求完全相同时才能复用,门槛很高。而现实中同一段文档每次出现的位置、前面拼接的内容都不一样。对此,研究者们提出了位置无关缓存复用(PIC):把每个文档块单独算一次 KV(不带任何前缀)存下来,之后不管它出现在什么位置都拿来复用
不过,单独算出来的 KV 没见过当前前缀,复用时必然带着误差。好在这个误差是稀疏的 ------ 换一个前缀,文档块里绝大多数 token 的 KV 几乎不变,只有一小撮会明显偏移。CacheBlend 实测表明,重算其中约 10~20% 偏移最大的 token,质量就能基本追平全量预填充,相关方法包括 EPIC、ProphetKV 等走的也是 "复用 + 选择性重算" 的路线
二、为什么现有 PIC 没兑现承诺
PIC 方案的关键就在于,怎样挑选部分 token 对新前缀做交叉注意力,将误差补回来,但在实际操作中,这一步并不是想象中那么简单,主要麻烦来自四个层面:
2.1 位置编码对不上
现代 LLM 普遍用 RoPE 把位置信息以 "旋转" 的方式编进 KV。一段文档离线计算时所在的位置,和它在线复用时的实际位置不一样,直接套用旧缓存等于用了错误的旋转角度,精度自然下降
不过这个问题也好解决,因为位置是确定的,旋转角度也可以利用各种手段去纠正,再不济使用 CoPE 这种受绝对位置差异影响更轻的位置编码即可
2.2 多头并集
我们希望的是,从复用段落里挑一小部分 token 去补算前缀的注意力,那自然就得挑当前注意力分布下最重要的几个 token 发起计算。但问题是,在多头注意力的设置下,不同头关注的 token 并不相同:A 头需要补第 1、3、5 个 token,B 头需要的却是第 2、4、6 个。系统无法按头分别安排,只能取一个并集来统一决定补哪些 token。头一多,这个并集迅速膨胀到覆盖整段,最后几乎要把整段重算一遍,复用也就名存实亡
于是 token 级方案陷入两难:选的 token 少了,总有些头补不到位,质量受损;选的 token 多了,速度优势又没了
此外还存在一种更隐蔽的问题 ------ 级联失真。被选中重算的 token,它前面仍然用的是过期缓存,此 token 在重算时看到的上下文本身就是脏的,补出来的 KV 也无法完全回到全量预填充的真值,误差还会沿序列向后传播。这是任何 token 级 PIC 方案的内生缺陷
2.3 FFN 瓶颈
PIC 几乎只盯着注意力,却忽略了一个事实:在上下文较短时(2K~8K token),前馈网络的计算量占了 TTFT 的一大半(57%~62%),注意力反而不是大头。即便把注意力的重算优化到极致,TTFT 也降不下来,因为 FFN 的开销原封不动
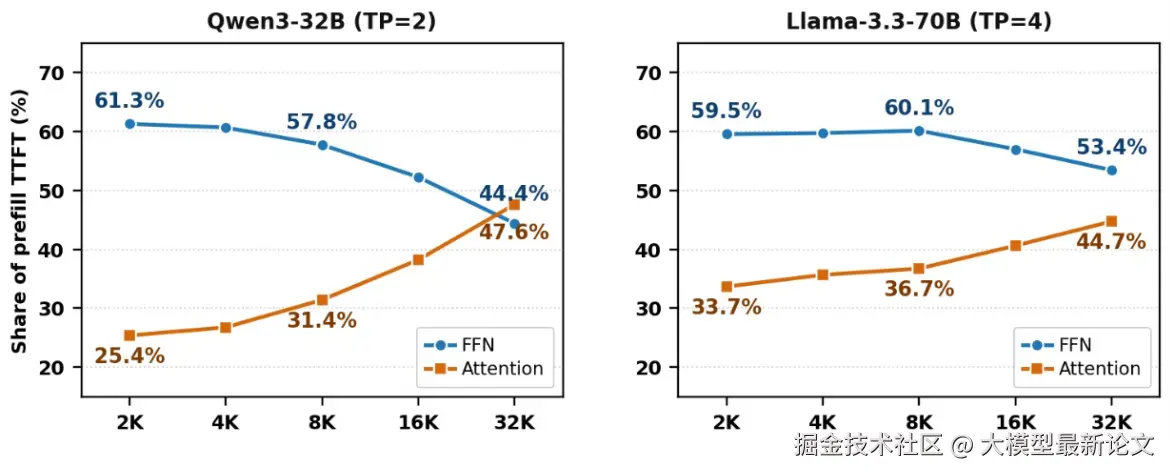
这把 PIC 的适用面卡死在了长上下文 RAG,难以推广到上下文相对短一些,却同样在意延迟的智能体等场景
2.4 FlashAttention 失效
最后一个问题出在工程落地。即便算法层面已经标记出哪些 KV 不用参与计算,在 GPU 显存里这些 KV 仍然和其他数据挤在同一块稠密张量里,靠一张注意力掩码告诉核函数哪些位置要跳过
而 FlashAttention 之所以快,正是因为它把注意力分块逐块处理、从不在显存里展开完整矩阵,但这要求所有位置都参与计算。一旦传入掩码,系统就退回慢得多的通用实现,带来 4.9~7.6 倍的惩罚。算法省下的计算量,全被更慢的核函数吃了回去
三、RedKnot 解决方案
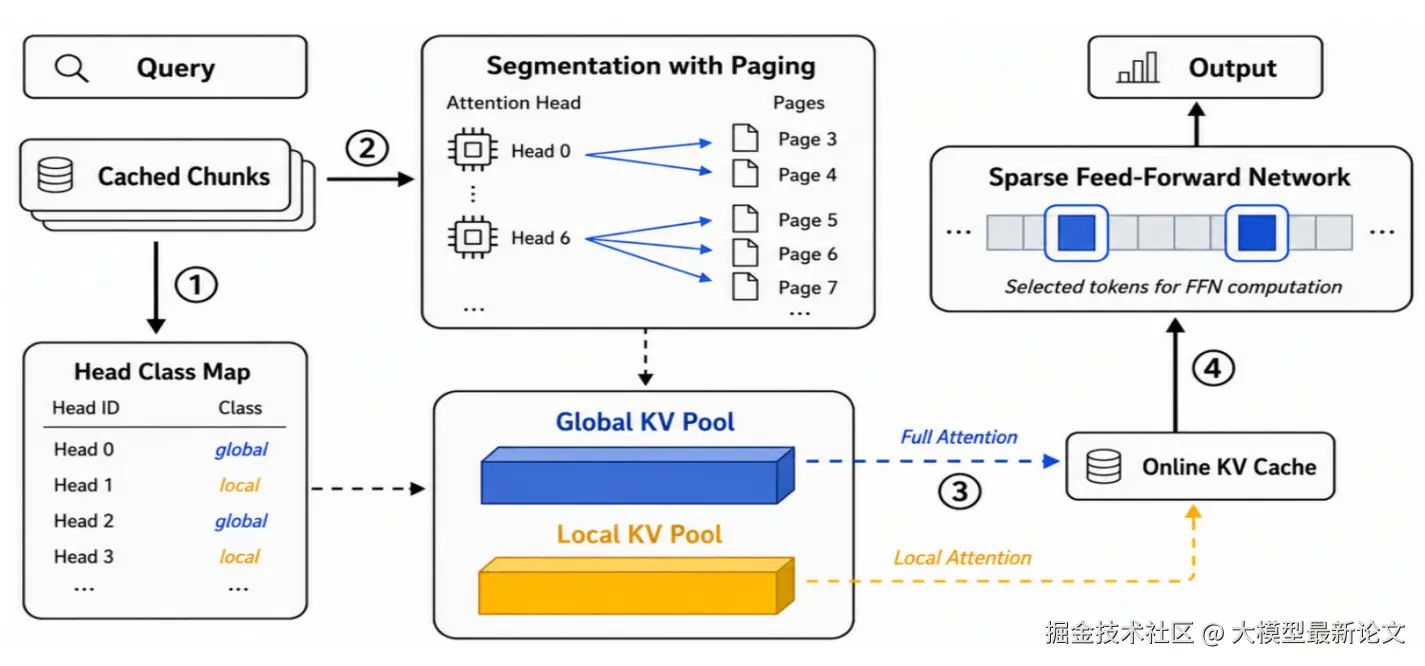
RedKnot 的思路是,让省算力的粒度对齐推理的运算结构。注意力和 FFN 本是两种不同的运算,省的粒度也不同 ------ 注意力是分头、跨 token 的,就只重算少数前缀敏感的全局头;FFN 是逐 token 独立的,就只对少数重要 token 做完整计算。现有方案的根本失误,正是把两者都捆死在 token 这一个粒度上
3.1 对齐位置编码
RedKnot 利用 RoPE 自身的旋转结构,对缓存里的 Key 向量做一次 "反向旋转 + 正向旋转",把它从离线位置的旋转角度纠正到在线实际位置。这一步是纯数学操作,开销极小,却能把位置偏移带来的误差彻底消掉

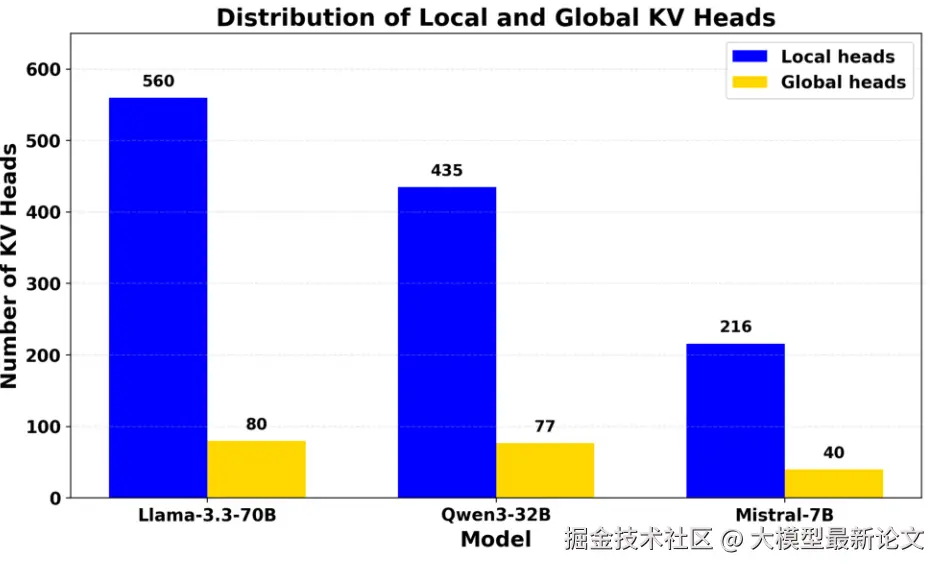
3.2 注意力头分类
这是 RedKnot 最关键的观察。作者分析了大量注意力头后发现,它们的行为可以分成两类:
- 本地头(local head):注意力天然集中在附近一个小窗口里,外加开头几个锚点 token,根本不看远处内容。前缀换了对它们几乎没影响,缓存可以直接复用
- 全局头(global head):要纵览整个上下文做长距离信息检索,前缀一变,注意力分布显著变化,必须全量重算
在 Mistral-7B、Qwen3-32B、Llama-3.3-70B 三个模型上,本地头占到了 84%~88% ,全局头只有 12%~16%。更重要的是,一个头属于全局还是本地,是由它所在的层和头编号决定的模型固有属性
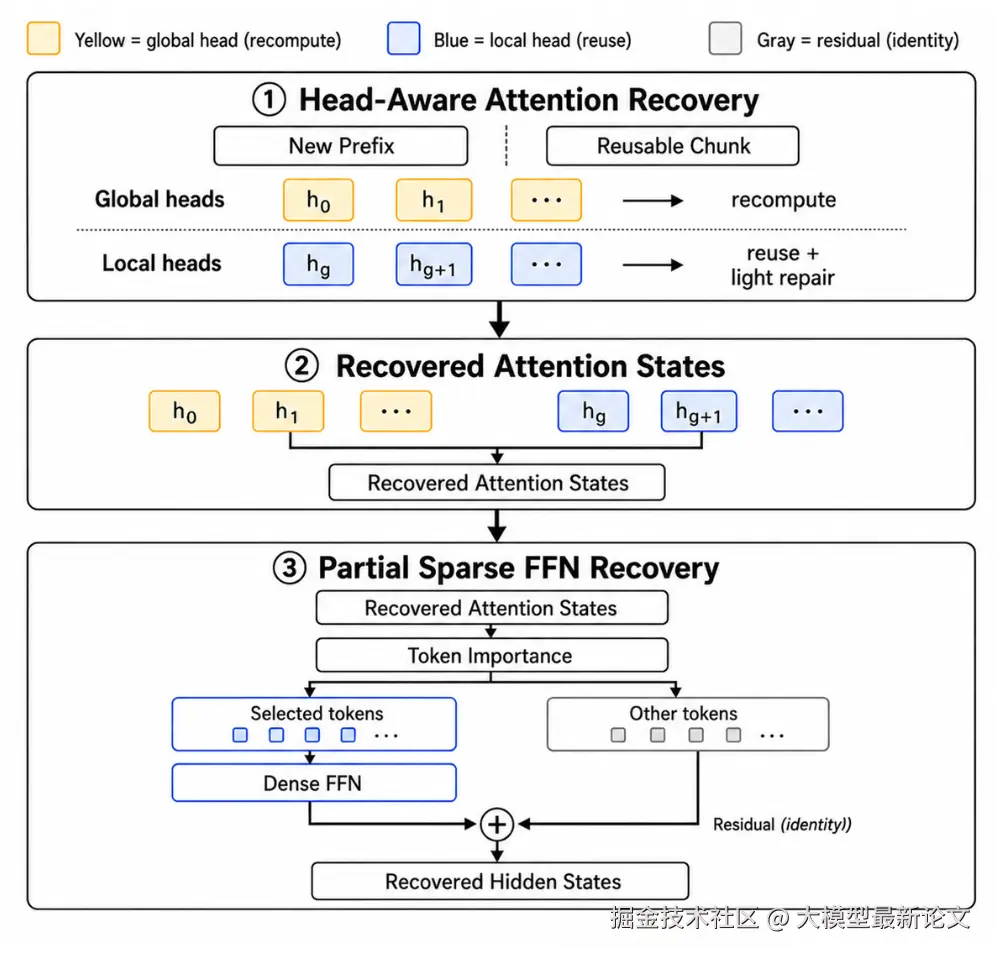
3.3 弹性稀疏
光按头省还不够,不同层对误差的敏感程度不一样。RedKnot 据此设计了分层的弹性稀疏恢复:
- 浅层保守:浅层的隐藏状态对误差很敏感,小扰动会被后续层层层放大。所以浅层只做局部窗口的注意力修复,FFN 全量执行,先把精度的根基稳住
- 深层激进:深层的语义表征已经收敛稳定,可以开启激进策略。注意力只重算全局头,同时启用稀疏 FFN,即根据注意力分数估算每个 token 的重要性,重要的 token 走完整 FFN,不重要的直接走残差通路跳过
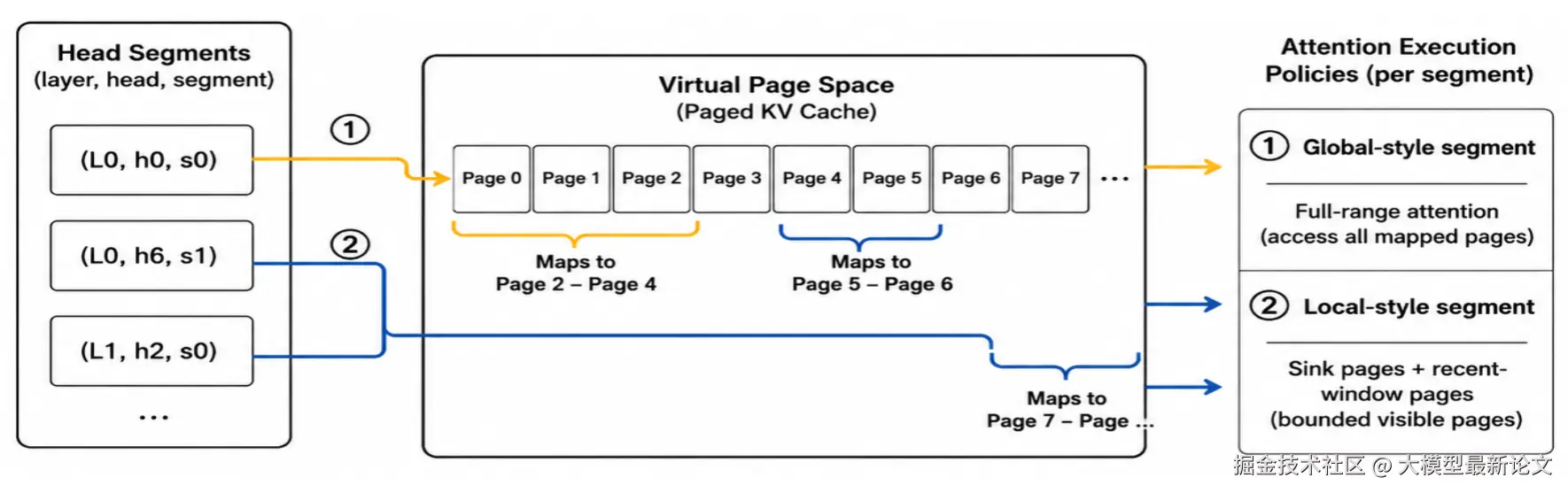
3.4 SegPagedAttention
传统 PagedAttention 按 token 块管理 KV,同一个块里所有头的数据混在一起,哪怕只需要某个头的一小段 KV,也得把整块加载进来
RedKnot 引入 SegPagedAttention,让每个注意力头单独拥有一串只装自己 KV 的页,不再和别的头挤在同一页里。每个头段都配一张自己的页表,本质就是登记 "这个头到底要读哪些页":
- 全局头:页表覆盖整个上下文,计算时整段读入、做完整注意力
- 本地头:页表只登记开头几个锚点 token + 最近窗口所在的那几页,远处 token 的页根本不收录
这和掩码方案有本质区别:掩码方案里那些 KV 数据还在、只是计算时跳过;而 SegPagedAttention 里它们根本不在这个头的页表中。于是核函数每次拿到的就是一段连续、无空洞的 KV 序列,可以直接走 FlashAttention
四、实验效果
作者在 Mistral-7B、Qwen3-32B、Llama-3.3-70B 三个模型、六个 QA 数据集(TriviaQA、MultiFieldQA、HotpotQA 等)上做了评估,上下文长度从 8K 到 128K。对照组是两个有代表性的 token 级 PIC 方案 CacheBlend 和 ProphetKV,以及稠密全量 prefill 基线
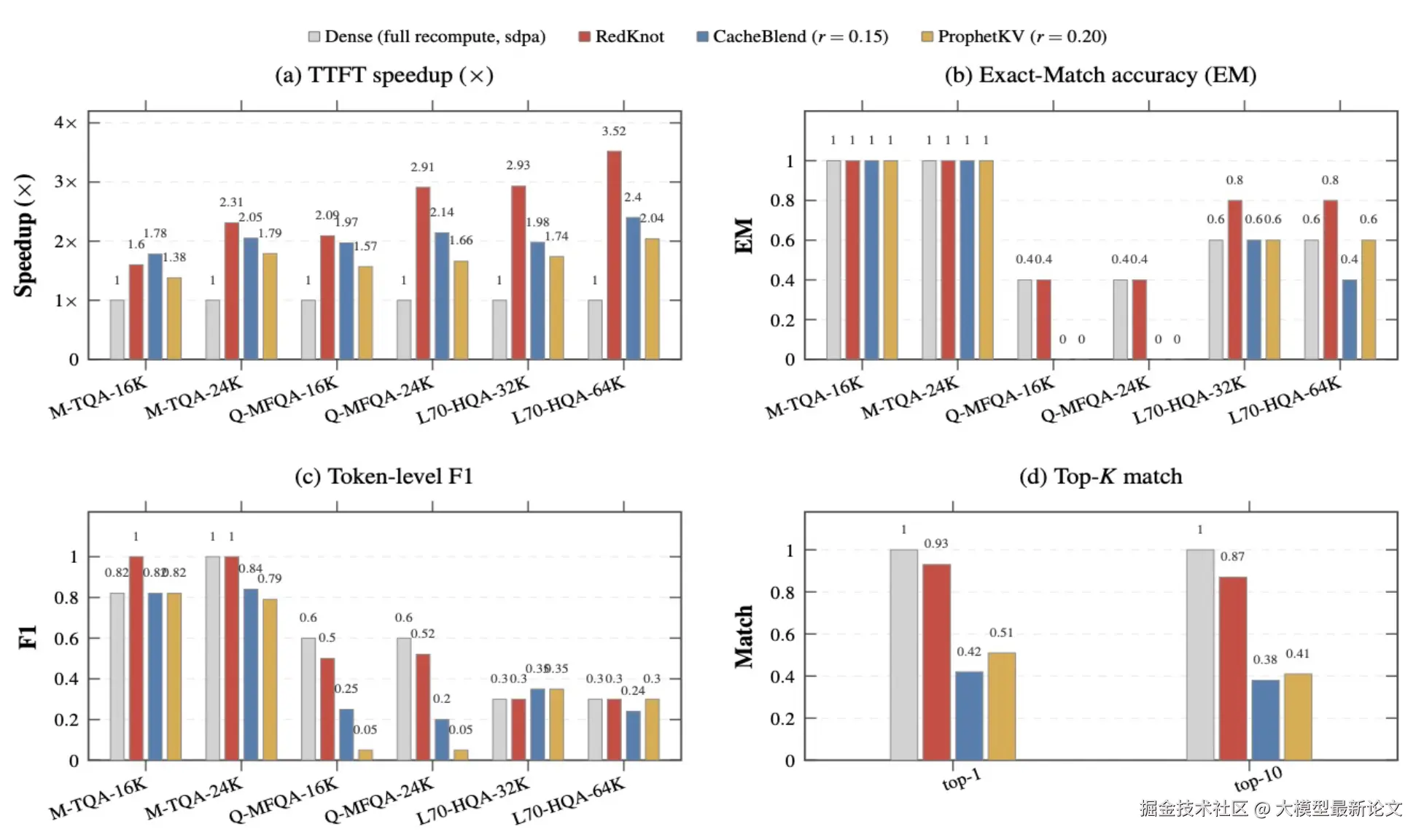
质量不降反升。 RedKnot 的 F1 和精确匹配(EM)全面持平甚至超过稠密基线,明显优于两个 token 级方案。例如在 Qwen3-32B 的 MultiFieldQA 上,RedKnot 保住了和稠密一致的 EM,token 级方案却几乎跌到零。原因正是头级别恢复让每个前缀敏感的全局头都被完整重算了,主导的注意力行为被更忠实地还原,而 token 级方案怎么调都修不到位
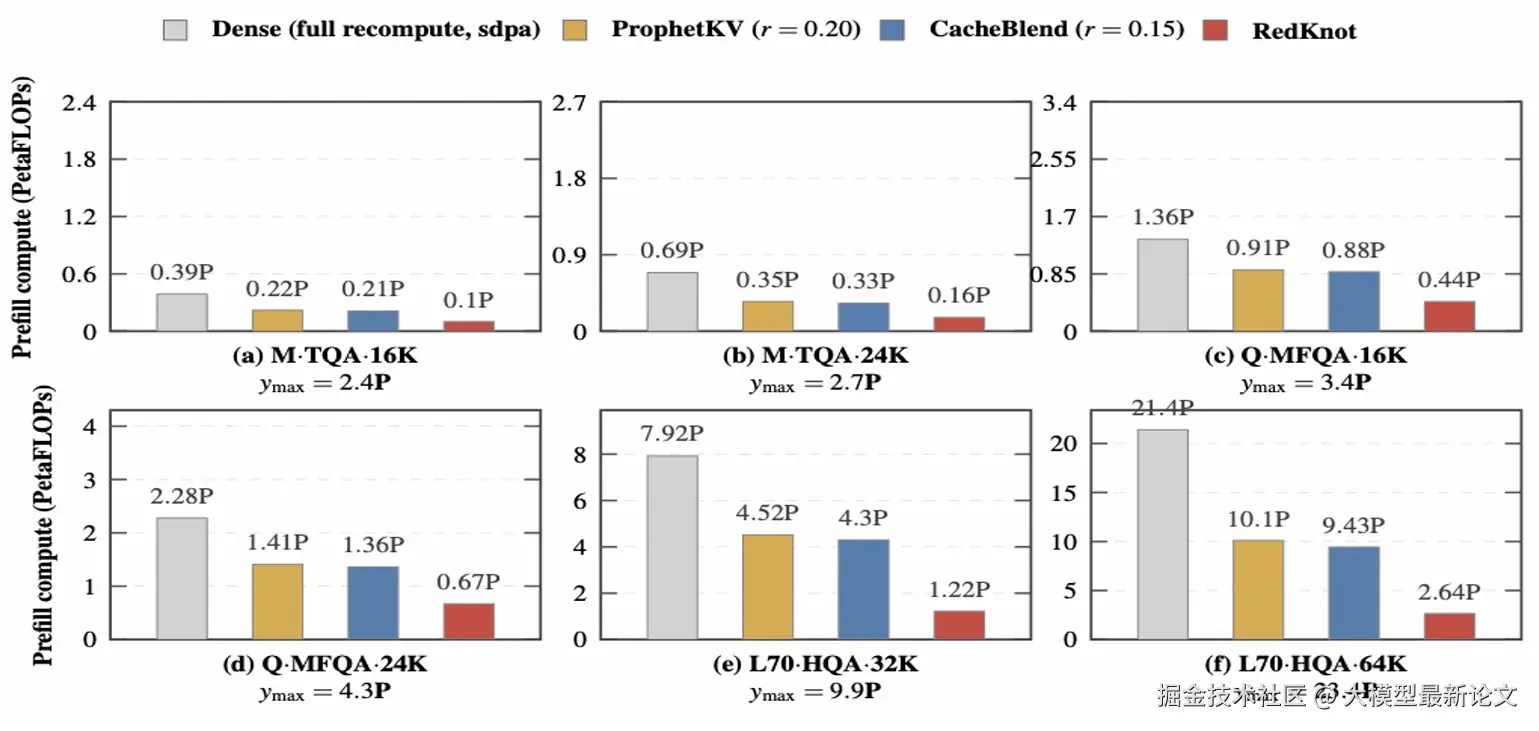
速度与算力双降。 TTFT 最高实现 3.54 倍加速;预填充的计算量(FLOPs)相比稠密全量重算减少了 67%~79.5%,这是因为它不仅省了注意力侧的重算,还通过稀疏 FFN 啃下了此前没人碰的 FFN 瓶颈。在 Llama-3.3-70B、64K 上下文这种极端场景里,预填充算力甚至从 21.4 PFLOPs 压到了 2.64 PFLOPs
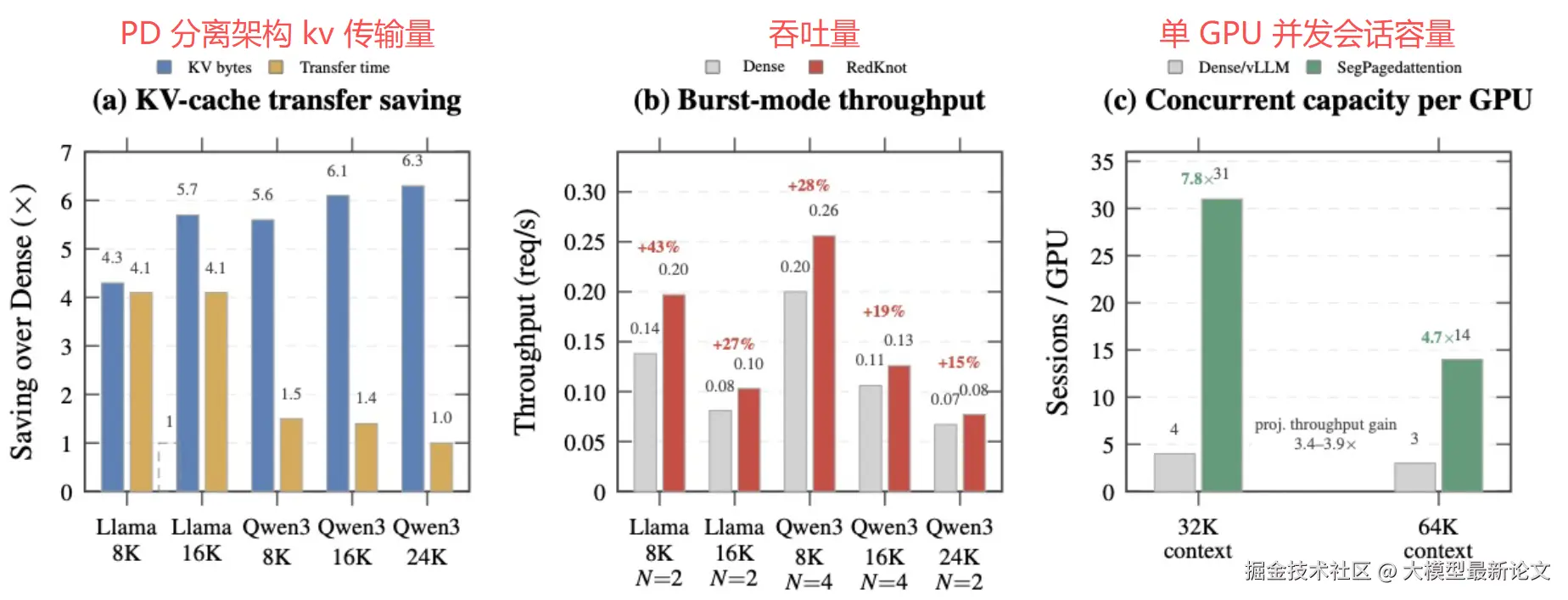
部署收益可观。 传统方案每个会话都要占完整显存的 KV,并发能力有限;SegPagedAttention 让本地头只存窗口大小的 KV,同一块 GPU 上的并发会话数提升了 4.7~7.8 倍 。在预填充与解码分离部署中,跨节点的 KV 传输量也降低了 4.3~6.3 倍。
五、总结
RedKnot 的核心贡献,是把 KV 缓存从一个按 token 统一管理的被动数据块,变成了按注意力头拆分的、模型感知的运行时基础设施。位置校正、头级别恢复、分层稀疏 FFN、SegPagedAttention 四者协同,让 PIC 路线第一次在不牺牲质量的前提下,同时降低了延迟、计算量和内存占用
它给长上下文服务提供了一个有价值的视角:复用的收益能不能落地,取决于复用与重算的粒度是否对齐了模型推理的内在结构。当粒度从 token 下放到头与重要 token 时,原本互相打架的 "省算力" 和 "保质量" 就不再是一对矛盾