公司要求开发全面用 Claude Code + Deepseek 辅助开发。刚开始大家都很兴奋,效率确实提升了不少。
但很快问题就来了------
问题一:每个人让 AI 干活的方式不一样
有人直接甩需求让它写,有人让它先出方案再写,有人边写边改。代码风格对不上,review 的时候看得头疼,改起来还不如自己写。
问题二:AI 根本不知道项目历史
每次新开一个对话,AI 就是个「失忆」状态。它不知道上周刚做了什么功能,不知道某个字段为什么这样设计,动不动就往已有逻辑上叠加冲突的代码。
问题三:需求没想清楚就开始写,返工严重
AI 写代码很快,快到你还没想清楚方向,它已经给你写了一大堆。改起来比重写还麻烦。
直到我用上了 OpenSpec,这几个问题基本都解决了。
OpenSpec 使用分享:从初始化到实战
一、什么是 OpenSpec
OpenSpec 是一套规范驱动开发(Spec-Driven Development) 的工作流工具,核心理念是 「先想,再做」------在写代码之前,先把需求想清楚、方案定下来、规范对齐好。
它通过 4 个命令覆盖了从探索到归档的完整生命周期:
/openspec-explore→ 思考、探索,不动代码/openspec-propose→ 把想法固化成提案(proposal + design + tasks)/openspec-apply→ 按任务列表实际写代码/openspec-archive→ 提案完成后归档
二、安装与初始化
2.1 安装 OpenSpec
OpenSpec 通过 npm 安装,提供三种方式,根据你的使用场景选择:
方式一:全局安装(推荐,所有项目都能用)
perl
npm install -g @fission-ai/openspec@latest
openspec --version # 验证安装成功,查看版本号安装完成后,在任何项目中都能直接使用 OpenSpec 命令。
方式二:项目级安装(只在当前项目用)
css
npm install --save-dev @fission-ai/openspec适合多个项目使用不同版本 OpenSpec 的场景。
方式三:npx 直接运行(不用安装,临时用)
kotlin
npx @fission-ai/openspec init适合偶尔使用,省去安装和卸载的麻烦。
2.2 项目初始化:openspec init
安装完成后,进入你的项目目录,执行初始化命令:
csharp
openspec init执行后会出现交互式引导,关键一步是选择你正在使用的 AI 编程工具,常用AI工具基本都能够支持:
- Claude Code
- CodeBuddy
- Cursor
- Gemini
- ......
选择完成后,按照提示重启 IDE ,初始化即完成。重启后就可以在编程工具中使用 /openspec-* 系列命令了。
💡 每个新项目第一次使用时,都需要执行一次
openspec init。
2.3 目录结构
进入项目根目录,初始化后会生成 openspec/ 目录:
python
openspec/
├── changes/ # 存放所有提案(change)
│ ├── archive/ # 已归档的提案(初始为空)
│ │ ├── 2026-05-24-gantt-show-all-users/
│ ├── async-export-task/ # 进行中的提案
│ │ ├── specs/ # 当前提案的规格说明
│ │ ├── .openspec.yaml # 提案的基本信息
│ │ ├── design.md # 设计:如何做?前后端各做什么?有什么风险?
│ │ ├── proposal.md # 方案:为什么做?具体需求是什么?可能影响的地方
│ │ └── task.md # 任务:转化为每一个可执行的最小化任务
│ └── specs/ # 规格文档
└── config.yaml # 项目全局配置2.4 接入开发规范:config.yaml
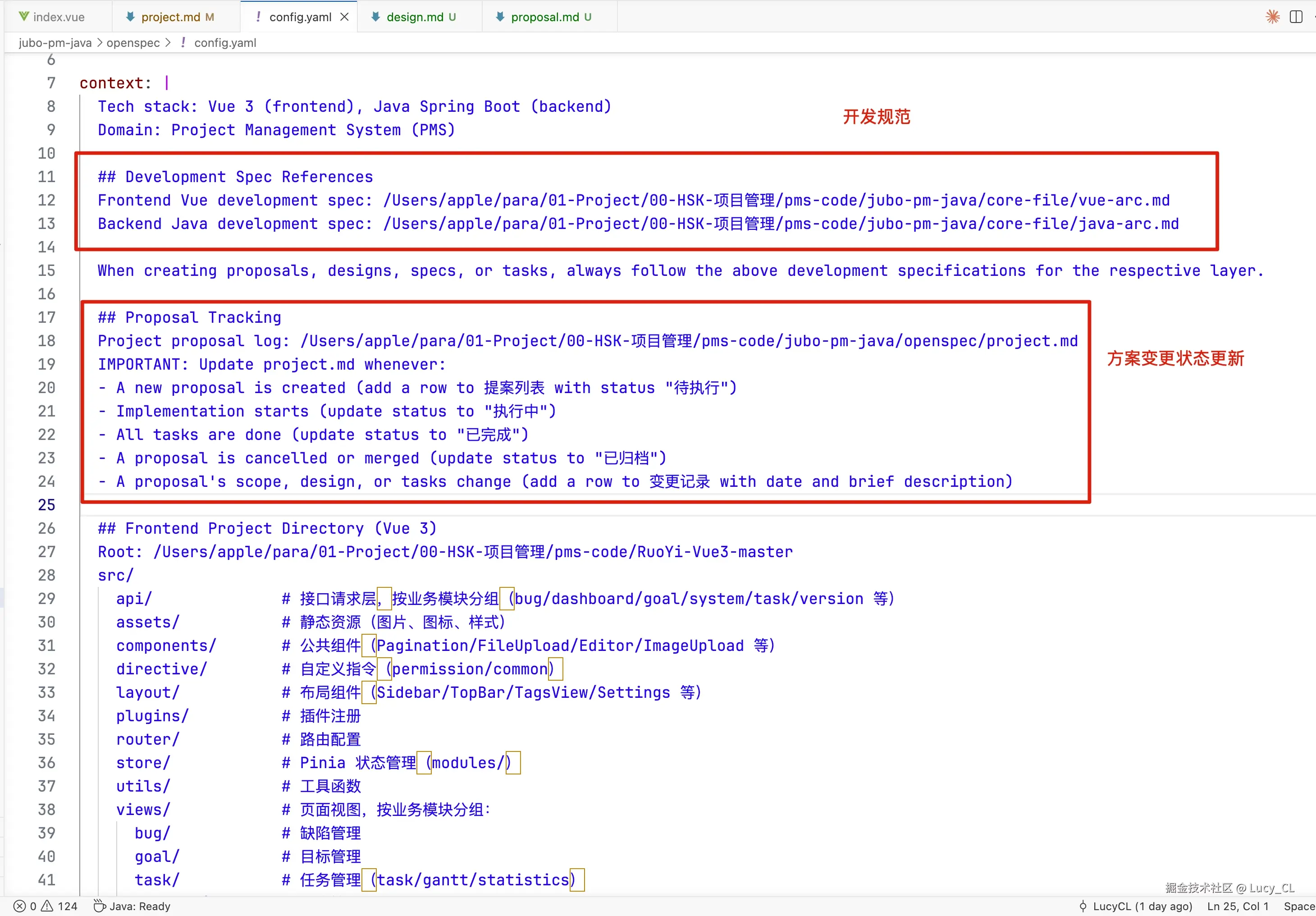
这一步是整套方案的灵魂,也是解决「AI 不遵守团队规范」问题的关键。
在 config.yaml 的 context 字段中声明开发规范文档路径,AI 在执行 propose 或 apply 时会自动读取并遵循这些规范:
注:开发规范也可以让AI通读你现在的代码结构,生成对应的代码规范,保持开发风格统一。
makefile
# openspec/config.yaml
context:
前端规范: "core-file/vue-arc.md" # 前端 Vue 开发规范
后端规范: "core-file/java-arc.md" # 后端 Java 开发规范
project: "./project.md" # 项目提案记录配置完成后,每次执行 /openspec-propose 或 /openspec-apply,AI 都会自动读取这两份规范文档,生成的方案和代码始终符合项目既定标准。

2.5 初始化提案记录:project.md
project.md 是一个轻量的提案追踪文件,解决的正是「AI 失忆」的问题。
它记录当前项目做过哪些设计提案、每个提案的状态:
| 目录 | 日期 | 状态 | 简要说明 |
|---|---|---|---|
| 任务甘特图视图 | 2025-xx-xx | 已完成 | 为任务模块增加甘特图展示 |
| 工时热力图 | 2025-xx-xx | 进行中 | ... |
变更记录表(可选):
| 日期 | 提案名称 | 变更内容 |
|---|---|---|
| 2025-xx-xx | 任务甘特图视图 | 新增移动端适配需求 |
在 config.yaml 中声明 project.md 路径后,AI 每次操作提案时都会自动同步这个文件。
project.md文件以及config.yaml中的说明,都可以让AI给你创建和补充需要说明的内容。
三、四个命令的完整工作流
bash
/openspec-explore → /openspec-propose → /openspec-apply → /openspec-archive
思考与探索 固化提案 编码实现 归档清理
不动代码 propose + tasks + specs 按任务列表写 标记完成
Phase 1:/openspec-explore ------ 想清楚了再动手
这是整个工作流中最关键的环节,也是和「直接让 AI 写代码」最大的区别。
当你有一个模糊的需求想法但不确定具体方案时,先用 explore:
bash
/openspec-explore 我想给任务模块加一个消息通知功能,但不确定推送方案怎么选它会做什么:
- 分析现有代码结构
- 画出不同方案的对比图
- 帮你梳理各方案的优劣
- 不修改任何代码文件
当你觉得思路成熟了,告诉它「好了,帮我生成提案」,它才会调用 propose 创建正式文档。
Phase 2:/openspec-propose ------ 方案固化
将 explore 阶段的想法转化为正式提案文档,包含:
- Proposal:方案描述和技术决策
- Design:说明如何实现方案
- Tasks:拆解后的具体任务清单
- Specs:涉及的接口/数据结构等技术规格
我们需要做的就是审核方案内容是否正确,基本确认无误后再执行。
💡 两个实用技巧:
- 第一次审核如果存在问题也没关系,执行完成后检查如有需要修改的,让它同步更新文档和修改代码即可。
- 当拆分的任务较多时,可能一次执行上下文过长执行不完。可以重新开一个窗口再次执行
/openspec-apply,因为 task.md 会标记已完成的任务,后续只会继续未完成的部分。
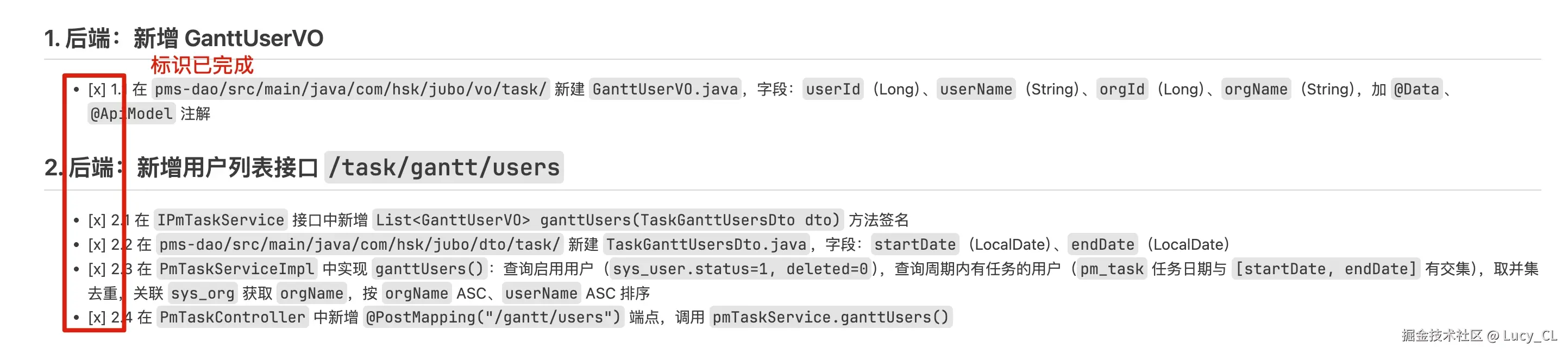
Phase 3:/openspec-apply ------ 按计划编码
根据 proposal 中的任务列表逐项实现代码。此时 AI 会:
- 读取 config.yaml 中声明的开发规范
- 参考 project.md 了解已有提案避免冲突
- 按任务顺序逐一编写代码
Phase 4:/openspec-archive ------ 收尾归档
提案全部任务完成后执行归档:
- 标记提案状态为已完成
- 同步更新 project.md 记录
- 清理临时文件,保持工作区整洁
四、实战注意事项
4.1 规范先行,编码在后
不要跳过 config.yaml 的 context 配置。把开发规范接进去看似多了一步,但它能避免后续大量返工。这是保证 AI 生成代码质量最简单有效的方式。
4.2 project.md 是团队的「共享记忆」
即使只有一个人开发,project.md 也很有价值:
- 快速回顾「这个功能之前做过吗?」
- 避免重复提案
- 方便新人了解项目演进历史
保持它的简洁性------一张表格就够,不需要复杂格式。
4.3 充分利用 explore,别急着写代码
OpenSpec 最大的价值不在自动生成代码,而在 explore 阶段的强制思考。很多 bug 和返工本质上是因为「没想清楚就开始写了」。给 explore 阶段足够的时间,让它帮你画对比图、分析现有代码、理清思路,这笔时间投入会在后面省回来。
4.4 变更要留痕
当提案在执行过程中发生范围变更或任务调整时,及时在 project.md 的变更记录表中追加一行。复盘时能清楚理解「为什么最终做出来的和最初想的不一样」。
总结
用了 OpenSpec 之后,团队 AI 开发最明显的变化是:
- AI 不再乱跑了:每次操作都有规范约束,代码风格统一了
- 不再重复踩坑:project.md 让 AI 有了「项目记忆」
- 返工少了很多:explore 阶段把方向想清楚再动手,比「写了再改」省时间
如果你的团队也在用 AI 辅助开发,遇到类似的问题,可以试试这套工作流。
有问题欢迎评论区交流 👇