企业自主 IDE 浪潮下的技术拆解:多轮对话、Agent 协作、知识库、LLM-UI、沙箱与 OPS 自动化
一、背景:为什么软件企业纷纷加码自主 AI-IDE
过去两年,Cursor、Windsurf、Trae、Claude Code、GitHub Copilot Workspace 的连续登场,让"AI-IDE"从一个 demo 词汇变成了一个赛道。但你若仔细看,软件企业(尤其是有自主低代码 / 中台 / 行业方案沉淀的企业)几乎都在投入资源做"自己的 IDE",而不是简单地接一个插件。原因有三个:
1.1 必要性:通用 AI-IDE 无法吃透企业语义
Cursor、Copilot 这类工具的强项在"通用代码生成",但对企业内部沉淀的组件库、注解体系、领域 DSL、流程模型、权限矩阵几乎一无所知。一个企业级的页面,从来不是几个 React 组件拼起来的,而是:
- 四分离模型(properties / styles / events / behaviors)
- 注解驱动的元数据(@A2uiSkill / @NlpDescription / @NlpIntent)
- 聚合根 + DAO + Service + VO 的全链路
- 流程引擎 + 表单引擎 + 权限引擎的耦合
这些"企业语义"不是公网知识,通用模型不会知道,但它们恰恰是企业每天 80% 的生产力来源。
1.2 危机:不做就被通用工具吃掉中台
真正的危机不是"AI 替代程序员",而是"通用 AI-IDE 替代企业中台"。 当 Cursor 能直接生成可运行的 React + Node 全栈,再叠加自动部署,企业辛苦沉淀的低代码平台、设计器、组件库就会成为"上一代的资产",被新一代开发者绕过。
所以越是有沉淀的软件企业,越要把自己的组件库、模板库、流程库、调试能力升级成"AI 原生 IDE",让通用模型"借道"自己的语义体系,才能守住护城河。
1.3 可行性:模型能力到了临界点
2025 年的几个关键变化让自主 AI-IDE 真正变得可行:
- Function Calling 稳定可靠:DeepSeek/GPT-4.1/Claude 3.7 对工具调用的准确率突破 90%,多轮工具循环成为可能;
- Reasoning 模型普及:o1、DeepSeek-R1、Qwen-Thinking 把"深度思考过程"显式输出,IDE 第一次可以把"AI 在想什么"展示给用户;
- 长上下文 + 显式压缩:200k 上下文 + 智能摘要让"整页 / 整项目"喂进 LLM 成为现实;
- 开源 SDK 成熟:Spring AI、LangChain4j、各家厂商 SDK 都把流式 / Tool / Reasoning 标准化。
下面我们以 OODER Studio 的实际实现为线索,拆解做一款 AI-IDE 真正要解决的五大难点。
二、总体架构:Studio 已经做到了哪一步
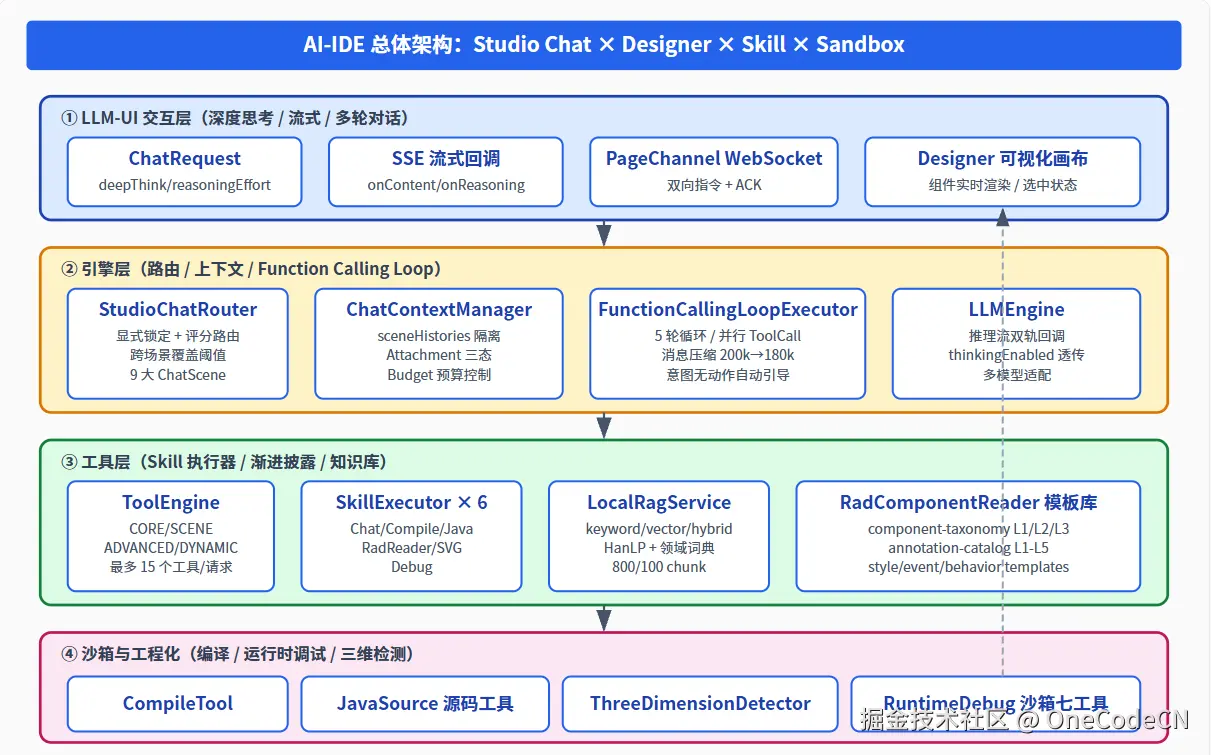
整个 Studio Chat 模块可以拆成四层,每一层对应一个核心难点:
| 层级 | 关键组件 | 对应难点 |
|---|---|---|
| ① LLM-UI 交互层 | ChatRequest / SSE 流式 / PageChannel WebSocket / Designer 画布 | 难点 3 |
| ② 引擎层 | StudioChatRouter / ChatContextManager / FunctionCallingLoopExecutor / LLMEngine | 难点 1 |
| ③ 工具/技能层 | ToolEngine / 6 类 SkillExecutor / LocalRagService / RadComponentReader 模板库 | 难点 2 |
| ④ 沙箱与工程化 | CompileTool / JavaSourceSkillExecutor / ThreeDimensionDetector / RuntimeDebugSkillExecutor | 难点 4、5 |
三、难点 1:多轮对话、多 Agent 协作与底层协议
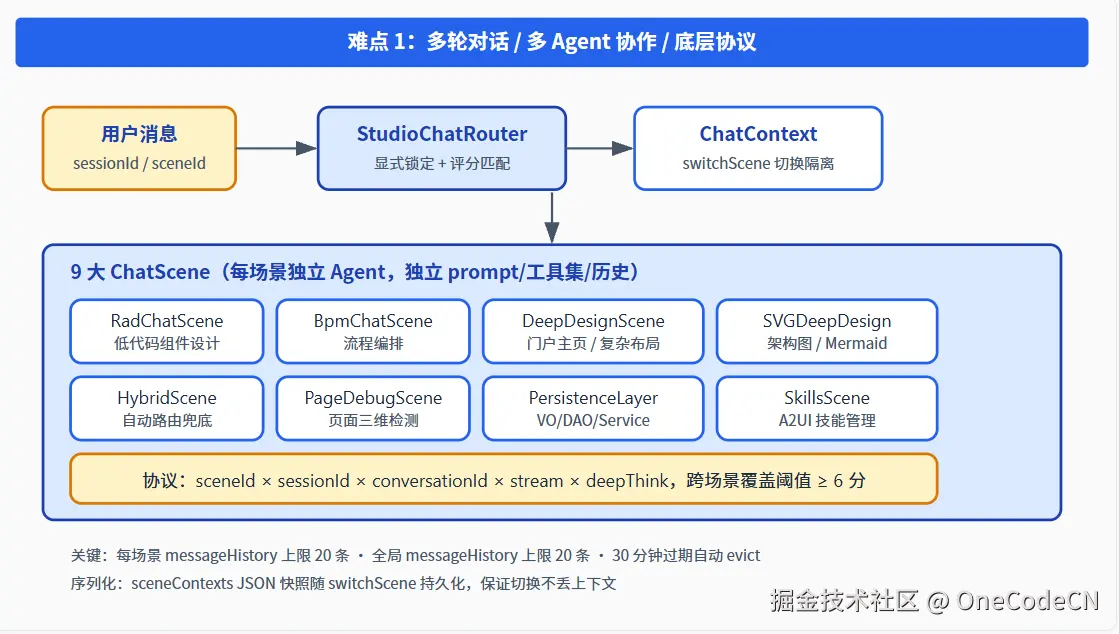
3.1 协议层:sessionId × sceneId × conversationId 的三维标识
翻开 ChatRequest.java 就能看到一款 AI-IDE 在协议层"必须想清楚"的字段:
javascript
public class ChatRequest {
private String sessionId; // 会话级
private String sceneId; // Agent / 场景维度
private String conversationId; // 对话维度(持久化)
private String content;
private Map<String, Object> context;
private String contextAttachments; // 附件状态
private boolean stream;
private boolean enableTools;
private List<String> specificTools;
private Boolean deepThink; // 深度思考开关
private String reasoningEffort; // low / medium / high
}看似简单的几个字段,背后是一整套设计哲学:
- sessionId:实际工作的"会话",跨多次请求复用上下文;
- sceneId:决定路由到哪个 Agent(Rad / Bpm / DeepDesign / PageDebug ...);
- conversationId:用于持久化检索的"对话";
- deepThink / reasoningEffort:原生支持 reasoning 模型的可控深度。
3.2 上下文容器:ChatContext 不是一个 List,而是一个状态机
很多 AI-IDE 把上下文做成一个 List<Message> 就完事,但真正用起来你会发现这远远不够。Studio 的 ChatContext.java 至少做了五件事:
- 双层历史 :
messageHistory(全局 20 条上限) +sceneHistories(每场景独立 20 条),switchScene会自动持久化旧场景历史并加载新场景历史; - 场景快照 :
sceneContexts以 JSON 形式保存每个场景的临时状态,切回来时无缝恢复; - 附件三态机 :
AttachmentStateManager把每个附件管在FULL → SUMMARY_ONLY → UNLOADED三态之间游走,超过 3 个 full 附件就按 idle 时长卸载; - 预算控制 :通过
ChatContextAdapter感知ContextBudget,超预算自动切换ATTACHMENTS_BUDGET_MODE,让 LLM 用read_component_content工具按需拉取,而不是一次性塞爆 prompt; - 生命周期审计 :
ChatContextManager通过ContextEventBus发出 LIFECYCLE 事件,可被监控、计费、合规体系订阅。
3.3 多 Agent:9 大 ChatScene 不是 prompt 切换,是工具集 + 历史 + 路由的整体隔离
Studio 没有走"一个 Agent 做万事"的路线,而是用 ChatScene SPI 把不同的工作场景拆成 9 个独立 Agent,每个都有自己的 prompt / 工具集 / 历史 / 评分函数:
| 场景 | 定位 | 工具集特征 |
|---|---|---|
| RadChatScene | 低代码组件设计(主战场) | 工具最庞大,含 Reader 全套 |
| BpmChatScene | 流程编排 | 桥接 DesignerFunctionRegistry |
| DeepDesignChatScene | 门户主页 / 复杂布局 | 双阶段:构建 + 四分离检测 |
| SVGDeepDesignChatScene | 架构图 / Mermaid | 正则解析 SVG / Mermaid |
| HybridChatScene | 自动路由兜底 | 无固定工具集 |
| PageDebugChatScene | 页面三维检测 | DesignObserve + RuntimeDebug |
| PersistenceLayerChatScene | VO/DAO/Service 生成 | 源码工具 + 模板 |
| SkillsChatScene | A2UI 技能管理 | 知识库工具 |
3.4 路由:显式锁定 + 评分匹配 + 跨场景覆盖阈值
StudioChatRouter.java 的路由逻辑是一个非常工程化的折衷:
- 若请求带 sceneId → 显式锁定;
- 若锁定的是 RAD 场景,但候选场景评分高出 6 分以上 → 触发跨场景覆盖(避免 UI 设计场景把"我想改一下流程"的请求吃掉);
- 无锁定 → 调用所有 ChatScene 的
matchScore,取最高分; - 全部未匹配 → 回退 HybridChatScene。
设计启示 :多 Agent 协作不是"AutoGPT 式的链式调度",企业 IDE 更需要"显式 + 评分 + 阈值"的可解释路由,否则用户根本搞不清楚为什么自己的话被路由到了某个 Agent。
四、难点 2:知识库积累训练、模板库 / 组件库增强归纳
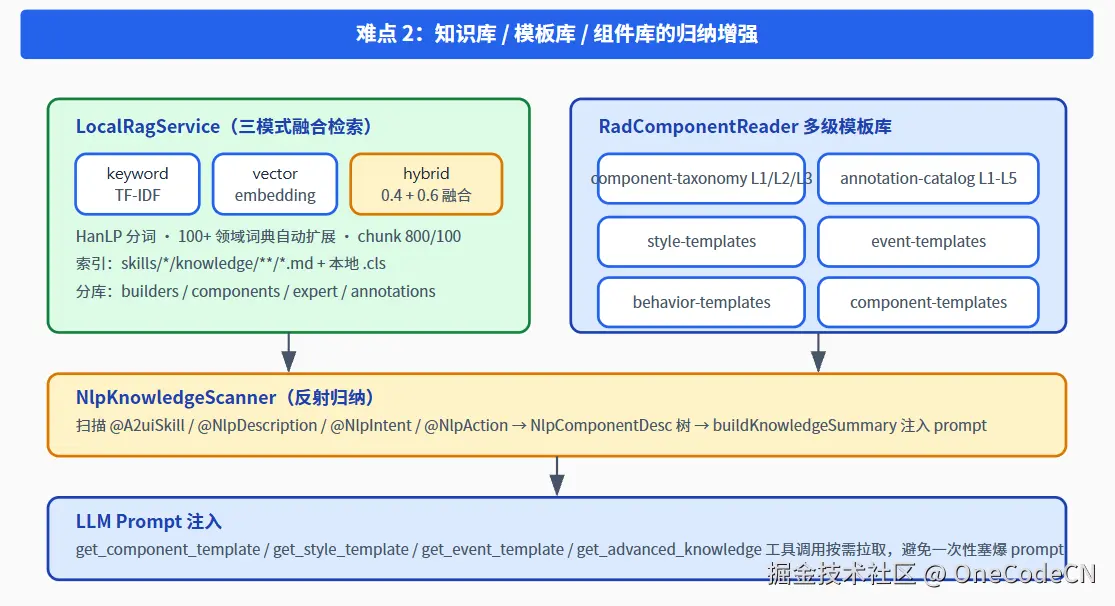
4.1 三模式 RAG:keyword × vector × hybrid
LocalRagService.java 同时支持三种检索模式:
- keyword:HanLP 分词 + 100+ 领域词典 + TF-IDF + queryCoverage 评分,特点是_对术语精确_;
- vector :通过
SceneEmbeddingService + VectorStore,特点是_对意图泛化_; - hybrid :以
0.4 keyword + 0.6 vector加权融合,是默认推荐模式。
启动时自动索引 classpath:skills/*/knowledge/**/*.md 与本地 .cls 文件,按 chunk=800 / overlap=100 切分,并按 kbId(builders / components / expert / annotations)分库。领域词典支持外部 domain-dictionary.txt 自动加载------意味着每个技能包发布时都可以"随插随用"地扩展 IDE 的语言能力。
4.2 模板归纳:从"组件文档"到"L1/L2/L3 + L1-L5"的分级模板
RadComponentReaderExecutor.java 通过 PathMatchingResourcePatternResolver 加载了一整套"模板字典":
| 资源 | 作用 |
|---|---|
| component-taxonomy | 组件 L1/L2/L3 三级分类 |
| annotation-catalog | 注解 L1-L5 五级目录 |
| component-defaults | 默认值字典 |
| component-roles | 组件角色(Form / List / Chart / Nav ...) |
| style-templates | 样式模板(按场景预设) |
| event-templates | 事件模板 |
| behavior-templates | 行为模板 |
| component-templates | 整组件模板 |
这套体系不会一次性塞到 prompt 里,而是通过 get_component_template / get_style_template / get_event_template / get_advanced_knowledge 等工具,让 LLM 按需拉取 ------这才是企业级知识库的正确打开方式:知识库不是 prompt,而是工具的弹药库。
4.3 注解驱动归纳:NlpKnowledgeScanner 把代码本身变成知识
NlpKnowledgeScanner.java 通过 A2uiSkillRegistrySPI 发现所有 @A2uiSkill,反射读取 @NlpDescription / @NlpIntent / @NlpAction,生成 NlpComponentDesc 树,再通过 buildKnowledgeSummary 注入到 RAD 场景的 system prompt。
这是 AI-IDE 最高效的"知识沉淀机制"------开发者写代码时顺手打的注解,自动就成为 LLM 的工作记忆。不需要单独维护一份文档,不需要训练专属模型。
五、难点 3:LLM-UI 深度思考展现 + 多轮任务交互
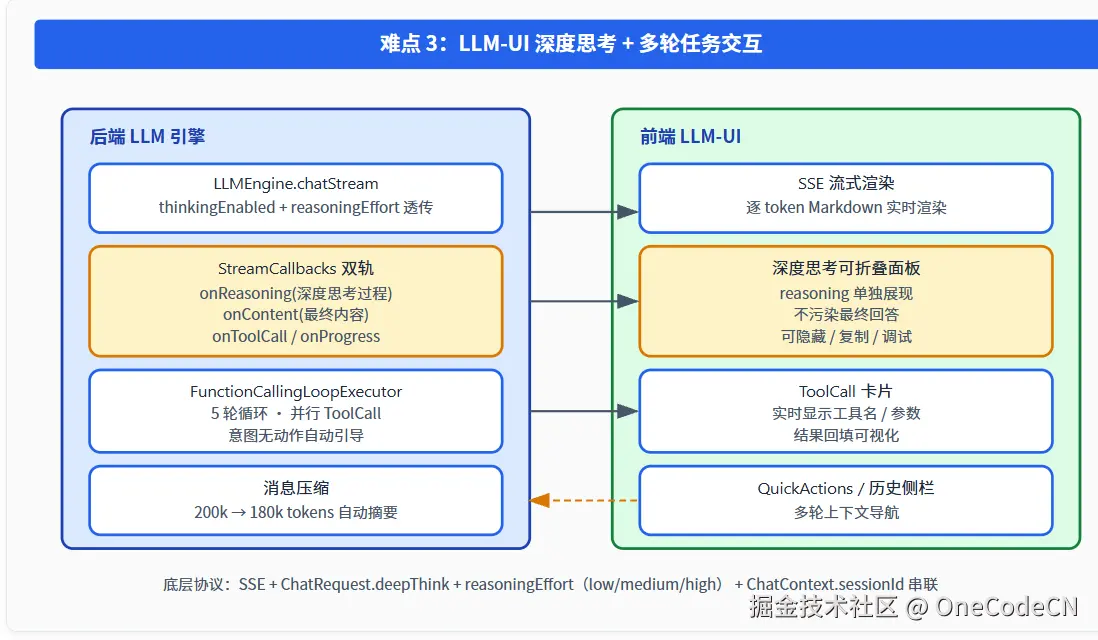
5.1 双轨流式:reasoning 与 content 分离的回调通道
很多产品只用一条 SSE 流,把 reasoning 与 content 混在一起,最后展示效果很糟。Studio 在 LLMEngine.java 中暴露了至少四种回调:
javascript
StreamCallbacks
├── onContent(token) // 最终回答
├── onReasoning(token) // 深度思考过程
├── onToolCall(toolCall) // 工具调用
└── onProgress(stage) // 阶段进度前端可以把 reasoning 渲染成"可折叠的灰色思考面板",把 content 渲染成最终 Markdown,工具调用渲染成卡片,进度渲染成 step bar------这才是 LLM-UI 应有的"深度思考可视化"。
5.2 Function Calling Loop:5 轮 / 并行 / 自动引导
FunctionCallingLoopExecutor.java 是整个 Studio 的"大脑驱动器",它的工程细节非常值得借鉴:
| 能力 | 实现 |
|---|---|
| 循环上限 | 默认 5 轮(可配置) |
| 超时控制 | 单工具 30s / LLM 调用 120s / 总 180s |
| 并行执行 | 同一轮多个 ToolCall 用 CompletableFuture + 共享线程池 fc-tool-exec-N |
| 消息压缩 | 估算超 200k token → 保留首尾 → 中间按 role 摘要到 180k |
| 降级解析 | structured → text(XML/JSON/简单文本) 三种 tool_call 写法兼容 |
| 意图无动作引导 | LLM 说"读取"但没调工具 → 自动注入引导消息 |
**"意图无动作自动引导"是个非常实用的工程巧思。**很多模型会在文字里说"让我先读取一下这个组件",但就是不去调用 read_component_content 工具,结果一轮空转。Studio 用关键词匹配 + 引导消息,把这种"嘴上说不做"的行为强行拉回正轨。
5.3 多轮交互的协议总结
多轮对话的真正"难"在于:用户不会每轮都把上下文复述一遍,但模型每轮都需要完整上下文。Studio 用一个 sessionId 串起来:
- 用户消息 → Router 路由到场景 Agent;
- Agent 拉取 ChatContext(含场景历史 + 全局历史 + 附件摘要);
- FC-Loop 进入工具循环,每轮结果追加到 messages;
- 流式回调通过 SSE 同时输出 reasoning / content / toolCall;
- onComplete 时
wrapCallbackWithPersistence异步落库; - 下一轮请求带同一个 sessionId 进来 → 历史无缝续上。
六、难点 4:工程能力可视化(让 LLM 能"看见"也能"改"前端)
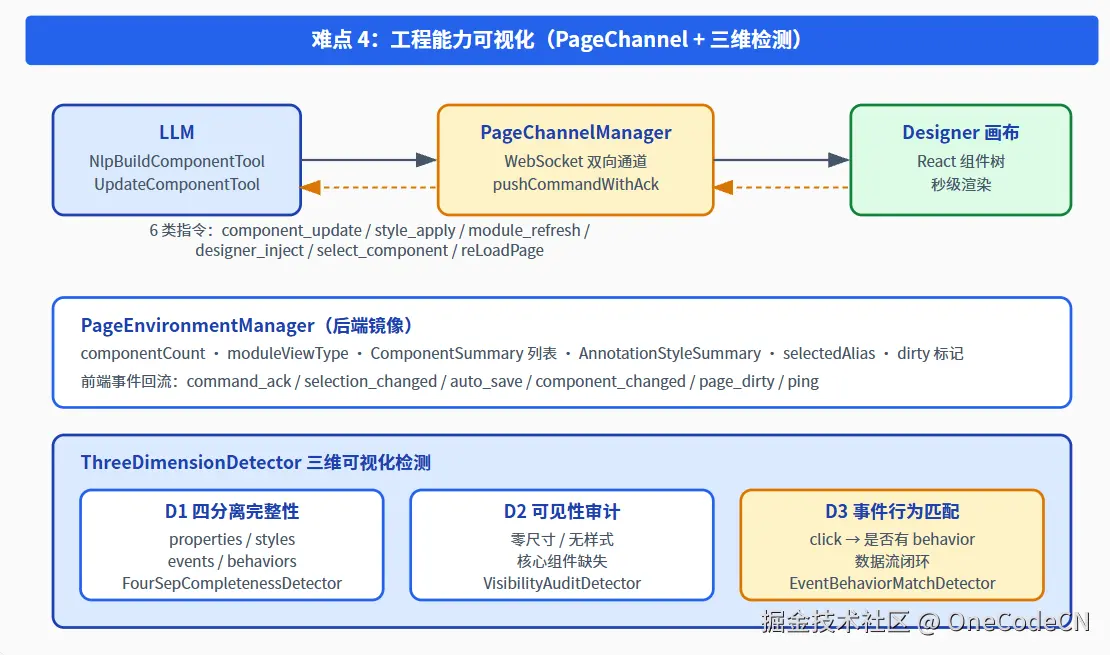
6.1 PageChannel:双向 WebSocket 而不是单向 HTTP
大多数 AI-IDE 只能"生成代码 → 用户复制粘贴 ",Studio 通过 PageChannel 把"LLM 一句话 → 前端组件秒级生效"做成了闭环:
- 每个打开的页面 = 一条 WebSocket(pageId + className + projectName 标识);
- 后端通过
PageChannelManager.pushCommand推送 6 类指令:component_update / style_apply / module_refresh / designer_inject / select_component / reLoadPage; pushCommandWithAck用 CompletableFuture + 10s 超时等待前端 ACK,保证可靠下发;- 前端回传 6 类事件:
command_ack / selection_changed / auto_save / component_changed / page_dirty / ping,让后端实时感知 Designer 状态。
6.2 PageEnvironmentManager:后端镜像让 LLM "看见"前端
很多 IDE 让 LLM 改前端时是"瞎子",Studio 通过 PageEnvironmentManager 在后端维护了一份前端镜像:
javascript
PageEnvironment {
componentCount,
moduleViewType,
componentSummaries: [{alias, role, dimensions, styles}, ...],
annotationStyleSummary,
selectedAlias,
dirty
}LLM 调用 list_page_components / get_component_info 时,秒拿到结构化数据;调用 update_component / apply_component_style 时,PageTool 自动检测页面活性(页面是否打开、通道是否活跃),然后推 PageCommand。
6.3 三维检测:让"做得好不好"也可视化
ThreeDimensionDetector 把"页面质量"拆成三维度评分:
| 维度 | 检测内容 | 关键类 |
|---|---|---|
| D1 四分离完整性 | properties / styles / events / behaviors 是否各司其职 | FourSepCompletenessDetector |
| D2 可见性审计 | 零尺寸 / 无样式 / 核心组件缺失 | VisibilityAuditDetector |
| D3 事件行为匹配 | click 是否绑定 behavior、数据流是否闭环 | EventBehaviorMatchDetector |
结果输出为 ThreeDimensionDetectionReport,含 overallScore / criticalIssues / componentResult,可作为 REST 返回也可作为 LLM 工具结果继续推理修复,从"生成"延伸到"评估"再延伸到"自我修复"。
七、难点 5:沙箱与 OPS 自动化(生成---编译---部署---验证闭环)
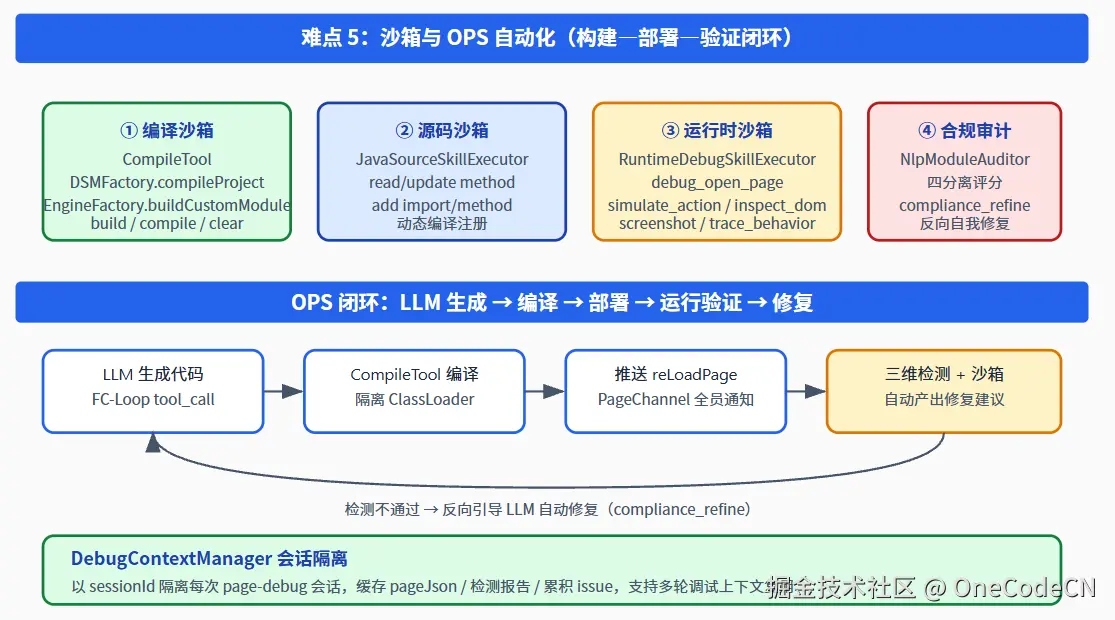
7.1 四类沙箱缺一不可
| 层级 | 沙箱 | 解决什么 |
|---|---|---|
| ① 编译沙箱 | CompileTool | 调用 DSMFactory.compileProject + EngineFactory.buildCustomModule,提供 build/compile/clear 三模式 |
| ② 源码沙箱 | JavaSourceSkillExecutor | read/update/add method、add import,动态编译注册 |
| ③ 运行时沙箱 | RuntimeDebugSkillExecutor | open_page / simulate_action / inspect_dom / screenshot / trace_behavior 七工具,把 LLM 当 QA 用 |
| ④ 合规审计沙箱 | NlpModuleAuditor | 四分离评分 + compliance_refine 反向自我修复 |
7.2 OPS 闭环:让 LLM 自己"开发---自测---修复"
整个闭环长这样:
- LLM 生成:在 FC-Loop 中通过工具调用产出代码 / 组件 / 样式;
- 编译沙箱:CompileTool 在隔离 ClassLoader 中编译;
- 自动推送 :编译完成自动通过 PageChannelManager 向所有活跃页面推
reLoadPage; - 三维检测 + 运行时沙箱:自动产出修复建议;
- 反向修复 :检测不通过 →
compliance_refine工具回灌 LLM,进入下一轮 FC-Loop。
这其实就是企业级 AI-IDE 的"灵魂"------不是生成代码就完事,而是构建"生成 → 编译 → 部署 → 检测 → 修复"的全自动闭环。只有闭环跑通,AI-IDE 才不只是"快速打字员",而是"自主程序员"。
7.3 DebugContextManager:让多轮调试也有"记忆"
每次 page-debug 会话由 DebugContextManager 以 sessionId 隔离,缓存 pageJson / 最近检测报告 / 累积 issue。这意味着 LLM 在第 5 轮修复某个 bug 时,仍然记得第 1 轮就发现的 12 个问题。调试上下文不丢,多轮自治才成立。
八、LLM-Chat UI/UE 详细设计
前面我们从协议、架构、工程化角度讲了"为什么难",这一节用一张完整的线框原型图把"AI-IDE 的对话界面到底长什么样"具象化。它不是一个简单的 ChatGPT 风格输入框,而是 **"场景导航 + 多轮对话 + 深度思考可视化 + 工具调用卡片 + 实时画布预览 + 三维检测看板"**六合一的工程化界面。
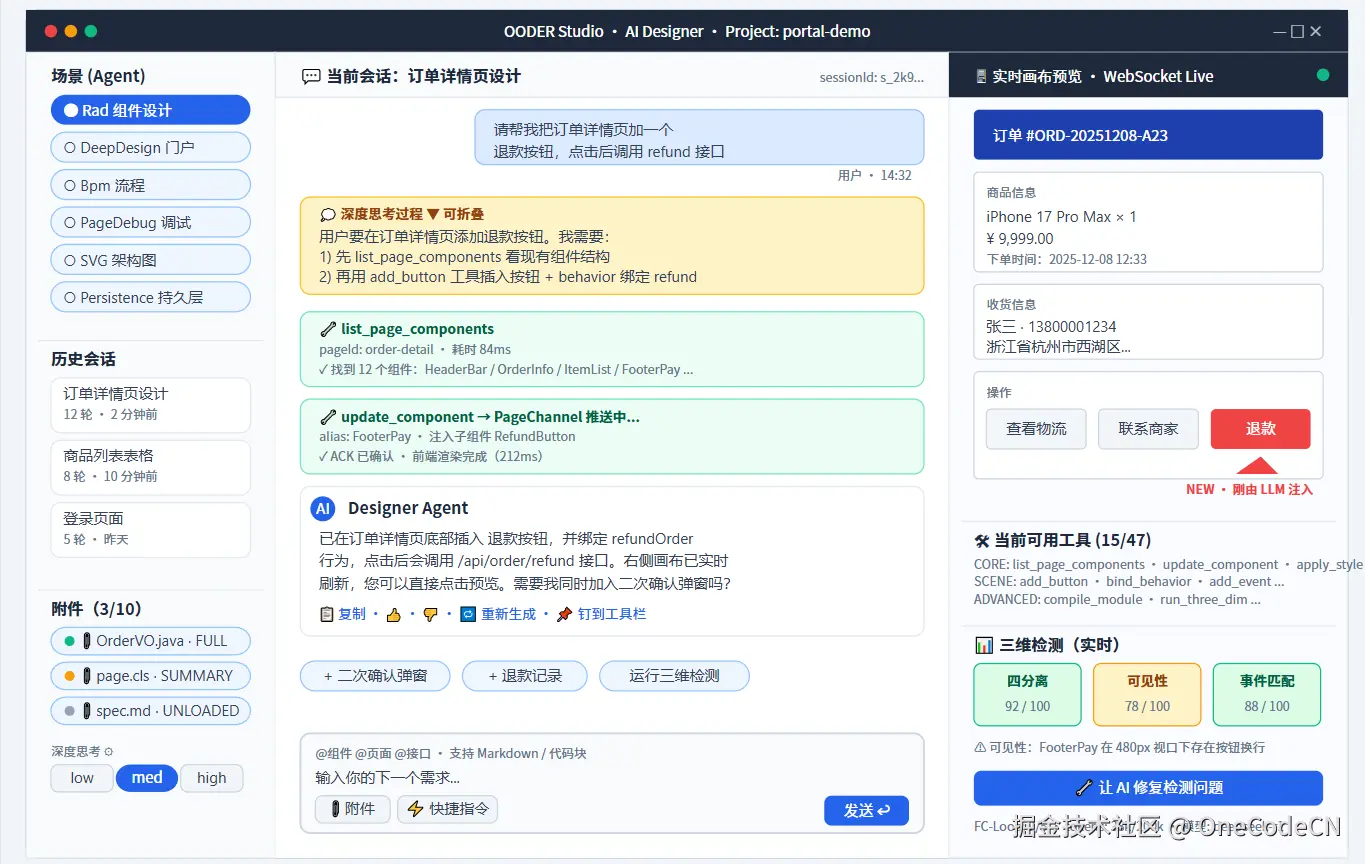
8.1 三栏布局:导航 / 对话 / 画布
| 区域 | 核心控件 | 对应能力 |
|---|---|---|
| 左栏 - 场景导航 | 9 大 ChatScene Chip · 历史会话 · 附件三态指示器 · 深度思考 low/med/high | 多 Agent 显式切换、上下文可视化、reasoningEffort 控制 |
| 中栏 - 对话流 | 用户消息气泡 · 💭 思考折叠面板 · 🔧 ToolCall 卡片 · AI 最终回答 · Quick Actions | 双轨流式渲染、FC-Loop 全过程可见 |
| 右栏 - 实时画布 | WebSocket Live 预览 · 当前可用工具列表 · 三维检测评分 · 修复按钮 | PageChannel 双向通道、工具渐进披露、检测闭环 |
8.2 关键交互点设计
- 💭 思考过程默认折叠:避免污染最终答案,但用户可一键展开看 AI 的推理链;reasoning token 与 content token 走不同回调通道(onReasoning vs onContent)。
- 🔧 工具调用渲染为卡片:每次 ToolCall 显示工具名、参数摘要、耗时、结果首行;点击可展开看完整 JSON。这让 LLM 的"做什么"完全透明。
- 📎 附件状态指示器:绿点 FULL / 黄点 SUMMARY / 灰点 UNLOADED,对应 AttachmentStateManager 的三态机;用户可手动锁定关键附件不被卸载。
- ⚡ Quick Actions:每轮回答尾部由 LLM 主动建议的下一步动作 chip,点击直接发送,降低多轮交互成本。
- 🖥 实时画布 ACK 反馈:右上角小绿点 = WebSocket 健康,每次组件注入完成会触发卡片轻微高亮 + "NEW" 标记,让用户一眼看到 AI 改了什么。
- 📊 三维检测看板 :实时显示四分离 / 可见性 / 事件匹配三个评分,低于阈值的项变黄,并提示"让 AI 修复检测问题"------把质量评估也变成对话动作。
- 状态条:底部显示 FC-Loop 当前轮次(2/5)、token 占用(38k/200k)、使用模型,让"AI 在做什么、还能做多久"始终可观测。
UX 设计哲学 :AI-IDE 不是"问答工具",而是"多模态工程驾驶舱 "。屏幕的每一像素都在回答用户三个问题:① AI 在想什么?② AI 在做什么?③ AI 做出的东西好不好?
九、AIServer 拆分部署架构(Harness 融入 OPS 自动化)
当前 e:\github\a2ui\aiserver\ 是一个 Spring Boot 单体,AiServerApplication 一锅端,@ComponentScan 同时覆盖 net.ooder.aiserver / bpm / vfs / event 四个域。对于一个 PoC 是 OK 的,但要走向生产级 AI-IDE 平台,必须拆分成多个面向独立扩展维度的子服务。
9.1 拆分后的 5 个核心子服务

| 子服务 | 来源包/模块 | 独立扩展维度 |
|---|---|---|
| 📁 vfs-service | net.ooder.vfs.* + vfs-web-app/ + 8 种 Dialect 适配 | 存储 IOPS / 容量 / 多介质(本地、S3、SMB、集群盘) |
| 🌐 cluster-service | net.ooder.event.ClusterEventBusImpl + bpm.ClusterService + Org/ContextIsolation | 节点数 / 多租户隔离 / 跨节点事件路由 |
| ⚙ workflow-service | net.ooder.bpm.engine.*(百余类)+ BPMServerApplication + esdbpm 插件 | 并发流程实例数 / Agent 编排吞吐 |
| 🧩 skillcenter-service | bpm.SkillDefController + skills-framework/* + 4 类 Discoverer | Skill 数量 / 远端仓库 / 多 Agent 同步 |
| 🛡 harness-ops | ouc.engine.llm.harness.* + NlpModuleAuditor + AggRootBuildAuditor | Pipeline 阶段并行度 / 审计规则数 / 修复迭代 |
9.2 为什么单独把 harness-ops 拆出来?
因为 Harness 是整个 AI-IDE 的"工程治理大脑",它不属于任何单一业务域,而是横切所有域的"质量门 + 自动化流水线"。把它独立成服务有三个好处:
- 独立演进 Pipeline 规则:四分离评分阈值、AggRoot 校验规则、StageContract 实现可以独立发布;
- 独立扩展计算资源:Pipeline 6 阶段可并行执行,CPU/内存可独立伸缩;
- 独立审计与回放:所有 LLM 决策的 TransparencyReport 都汇聚到 harness-ops,便于审计、合规、问题回放。
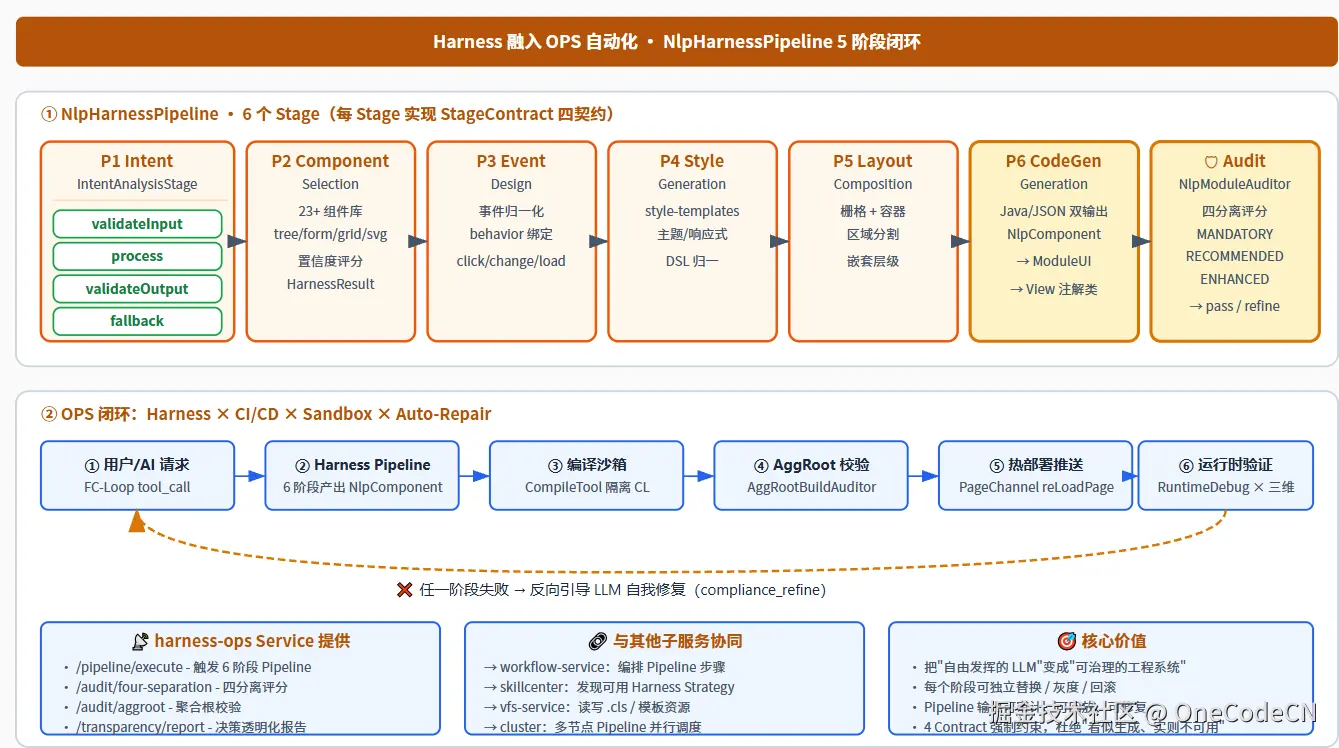
9.3 Harness × OPS 闭环的 6 步流水线
| # | 步骤 | 组件 | 失败后果 |
|---|---|---|---|
| ① | 用户/AI 请求 | FC-Loop ToolCall | --- |
| ② | Harness Pipeline 6 阶段 | NlpHarnessPipeline + 6 Stage × 4 Contract | fallback() 兜底,HarnessResult 标 requiresReview |
| ③ | 编译沙箱 | CompileTool + 隔离 ClassLoader | 错误注入 LLM → compliance_refine |
| ④ | AggRoot 校验 | AggRootBuildAuditor | 缺失字段 / 关联错误 → 触发重生成 |
| ⑤ | 热部署推送 | PageChannel reLoadPage | ACK 超时 → 降级为下次刷新生效 |
| ⑥ | 运行时验证 | RuntimeDebug × ThreeDimensionDetector | 评分不达标 → 反向回灌 LLM 修复 |
关键洞见:通用 AI 工具的 OPS 通常只到第 ③ 步(编译通过就算成功),但企业级 AI-IDE 必须做到第 ⑥ 步------因为_"编译通过 ≠ 业务可用"_。Harness 的 6 阶段 Pipeline + AggRoot 审计正是用来填补这个鸿沟。
十、Agent SDK 与 Skills 机制设计
如果说 Studio Chat 是 "应用层",那 agent-sdk + skills-framework 就是 "OS 层"------它们定义了"如何让任何 LLM 调用任何工具、加载任何技能、热更新任何配置"的底层契约。
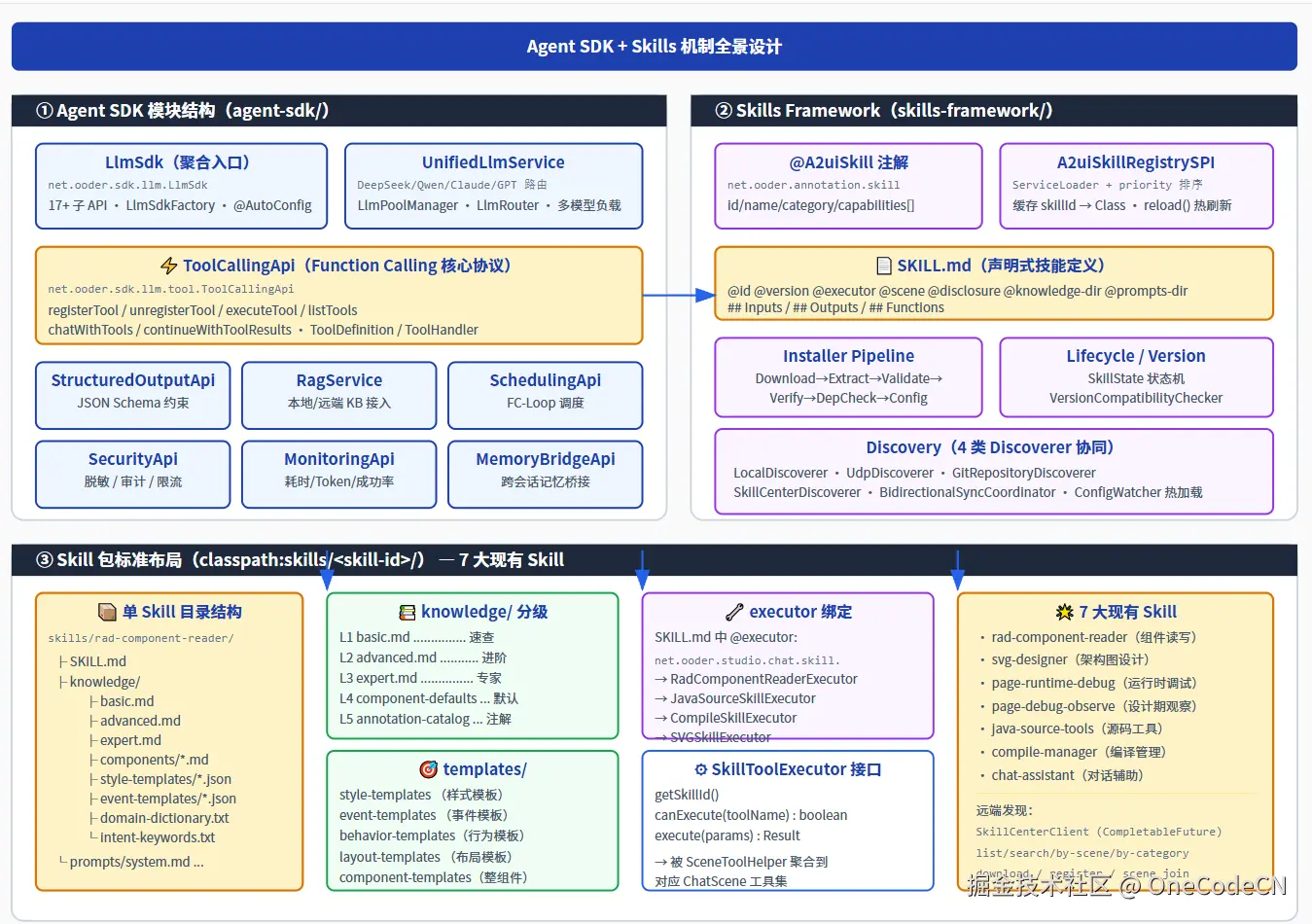
10.1 Agent SDK:17+ 子 API 的统一接入门面
e:\github\a2ui\agent-sdk\ 下分为 7 个子模块:
| 子模块 | 定位 |
|---|---|
| llm-sdk | 统一 LLM 客户端,聚合 17+ API(ToolCalling / StructuredOutput / RAG / Memory / Scheduling / Security / Monitoring ...) |
| agent-sdk-core | Agent 运行时核心(含 SkillCenterClientImpl) |
| agent-sdk-cli / cli-starter | 命令行接入 |
| agent-sdk-spring-boot-starter | Spring Boot 自动装配 |
| skills-framework | Skill 安装/版本/发现/同步全套设施 |
| skill-spi | SPI 接口契约 |
核心入口 net.ooder.sdk.llm.LlmSdk 把以下能力聚合在一个 facade 后面,避免业务代码直接依赖具体厂商 SDK:
javascript
LlmSdk
├── ToolCallingApi // Function Calling 注册/执行/闭环
├── StructuredOutputApi // JSON Schema 约束输出
├── RagService // 本地/远端知识库
├── UnifiedLlmService // DeepSeek/Qwen/Claude/GPT 多模型路由
├── LlmPoolManager // 资源池 / 限流
├── MemoryBridgeApi // 跨会话记忆
├── SchedulingApi // FC-Loop 调度
├── SecurityApi // 脱敏 / 审计 / 限流
├── MonitoringApi // 耗时 / Token / 成功率
└── CapabilityRequestApi // 能力发现10.2 ToolCallingApi:本地 ToolEngine 与 SDK 双向同步
ooder-pro 的 ToolEngine 维护一份本地 ChatTool 注册表(含 4 级渐进披露 CORE/SCENE/ADVANCED/DYNAMIC),但 LLM 真正调用时走的是 SDK。同步机制如下:
- 业务代码用
ToolEngine.register(chatTool, level)注册; - ToolEngine 内部调用
syncToSdk(tool)把ChatTool转成ToolDefinition注册到ToolCallingApi; - FC-Loop 拉起
chatWithTools()时,SDK 已持有完整ToolDefinition; - LLM 返回
ToolCall→ SDK 回调ToolHandler→ 路由回 ToolEngine 本地执行 →continueWithToolResults进入下一轮。
10.3 Skills 机制:声明式 SKILL.md + 反射注解 + SPI 发现
整个 Skills 体系由三层契约支撑:
第一层:注解契约
@A2uiSkill(net.ooder.annotation.skill.A2uiSkill)是所有技能的 Java 注解:
javascript
@A2uiSkill(
id = "treegrid",
name = "树形表格",
description = "支持层级展开的数据表格",
version = "1.0.0",
category = "data",
capabilities = {"hierarchy", "sortable", "editable"},
moduleViewType = ModuleViewType.GRID,
componentType = ComponentType.TREEGRID,
priority = 100
)
public class TreeGridSkill extends AbstractA2uiSkill { ... }第二层:SPI 发现
A2uiSkillRegistrySPI 通过 ServiceLoader<A2uiSkillRegistry> 按 priority 排序加载所有 registry,缓存 skillId → className / Class / category / moduleViewType / componentType,并提供 reload() 热刷新------意味着新增技能只需把 Jar 丢进 classpath 即可生效。
第三层:SKILL.md 声明式资源包
每个技能在 classpath:skills// 下有标准布局:
javascript
skills/rad-component-reader/
├── SKILL.md # 声明式元数据 + Inputs/Outputs/Functions
├── knowledge/
│ ├── basic.md / advanced.md / expert.md # L1/L2/L3 分级知识
│ ├── components/*.md # 单组件详细文档
│ ├── style-templates/*.json # 样式模板
│ ├── event-templates/*.json # 事件模板
│ ├── behavior-templates/*.json # 行为模板
│ ├── component-templates/*.json # 整组件模板
│ ├── domain-dictionary.txt # 领域词典自动扩展
│ └── intent-keywords.txt # 意图关键词
└── prompts/
├── system.md # 系统 prompt
├── rad.md / deep-design.md / bpm.md # 场景 prompt
└── intent-recognition.md # 意图识别 promptSKILL.md 头部声明 @executor 指向 Java 执行器:
javascript
---
@id: rad-component-reader
@version: 1.2.0
@executor: net.ooder.studio.chat.skill.RadComponentReaderExecutor
@scene: rad, deep-design
@disclosure: CORE
@knowledge-dir: knowledge/
@prompts-dir: prompts/
---
## Inputs
- componentType: string
- pageId: string
## Outputs
- componentInfo: ComponentInfoVO
## Functions
- get_component_template
- get_style_template
- apply_component_style
- ...10.4 Skills Framework:工业级技能生命周期
agent-sdk/skills-framework/ 提供了完整的"技能 OS":
| 能力 | 实现 |
|---|---|
| 安装流水线 | Installer Pipeline:Download → Extract → Validate → Verify → DependencyCheck → Config,配 RollbackManager |
| 生命周期 | SkillLifecycleImpl + SkillState 状态机 |
| 版本兼容 | VersionCompatibilityCheckerImpl 自动判定升降级 |
| 4 类发现 | LocalDiscoverer · UdpDiscoverer · GitRepositoryDiscovererAdapter · SkillCenterDiscoverer |
| 热加载 | ConfigWatcher 监听配置文件变更 |
| 多 Agent 同步 | BidirectionalSyncCoordinator 双向同步技能 |
| 声明式执行 | SkillMdParser + SkillExecutionEngine 解析并按段执行 SKILL.md |
10.5 远端 SkillCenter:跨集群分发协议
SkillCenterClient 把 Skill 仓库做成了"npm-like"的中心化服务:
list()/get(id)/search(keyword)findByScene(sceneId)/findByCategory/findByTagsdownload(id, version)/versions(id)register/unregistersceneJoin/sceneLeave
全部异步 CompletableFuture,使得"新技能上架 → 所有 Studio 节点秒级感知 → 拉取 → 安装 → 进入工具列表"成为一条流水线。这也是 skillcenter 必须独立成服务的根本原因。
设计精髓 :Agent SDK 用 17+ 子 API 把 LLM 能力切片,Skills Framework 用 SKILL.md + SPI + Discoverer 把工具能力切片。两者通过 ToolCallingApi 接合,让 IDE 既能"接任何模型",也能"装任何能力"------这才是 AI-IDE 的"OS 层"。
十一、总结:做一款 AI-IDE 到底有多难?
把上面五个难点 + 三个补充视角凝聚一下,做一款真正可用、可演进的企业级 AI-IDE,至少需要打通这十一个工程支点:
| # | 工程支点 | Studio / Agent-SDK / Harness 中的对应 |
|---|---|---|
| 1 | 协议清晰 | ChatRequest 的 sessionId × sceneId × deepThink × reasoningEffort |
| 2 | 上下文状态机 | ChatContext 双层历史 + 附件三态 + 预算控制 |
| 3 | 多 Agent 显式路由 | 9 大 ChatScene + StudioChatRouter 评分 + 跨场景覆盖阈值 |
| 4 | 知识库工具化 | LocalRagService 三模式 + RadComponentReader 多级模板 |
| 5 | 注解归纳 | NlpKnowledgeScanner 把代码注解转成 LLM 工作记忆 |
| 6 | LLM-UI 双轨流 | onReasoning / onContent / onToolCall / onProgress |
| 7 | 前后端双向通道 | PageChannel WebSocket + PageEnvironmentManager 镜像 |
| 8 | 沙箱 OPS 闭环 | 编译 / 源码 / 运行时 / 合规 四类沙箱 + 反向自我修复 |
| 9 | 多模态工程驾驶舱 UX | 三栏布局:场景导航 + 对话流 + 实时画布;思考折叠 / 工具卡片 / 检测看板 |
| 10 | 服务化拆分 + Harness 独立 | vfs / cluster / workflow / skillcenter / harness-ops 五服务架构 |
| 11 | Agent SDK + Skills OS 层 | LlmSdk 17+ API + @A2uiSkill + SKILL.md + SkillCenterClient |
**难,不在某一项技术。**难在"八件事必须同时做对,且彼此一致"。任一缺口都会让 AI-IDE 退回到"花哨 Demo"。
从 OODER Studio 的现有实现看,这条路已经走通了一半以上------剩下的工作主要在更细致的模型适配、更智能的预算控制、更深的工程闭环 。这也是为什么越是软件企业,越要做自己的 AI-IDE:因为"通用 AI-IDE + 通用 SDK"装不下企业自己的语义体系,而企业的真正护城河,恰恰就在这套体系里。
附:本文涉及的关键代码路径速查
| 模块 | 绝对路径 |
|---|---|
| ChatRequest 协议 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\model\ChatRequest.java |
| ChatContext 上下文 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\context\ChatContext.java |
| ChatContextManager | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\context\ChatContextManager.java |
| AttachmentStateManager | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\context\AttachmentStateManager.java |
| StudioChatRouter 路由 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\router\StudioChatRouter.java |
| ChatScene SPI 与 9 大场景 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\scene\ |
| FunctionCallingLoopExecutor | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\engine\FunctionCallingLoopExecutor.java |
| LLMEngine 双轨回调 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\engine\LLMEngine.java |
| ToolEngine 渐进披露 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\engine\ToolEngine.java |
| NlpKnowledgeScanner 注解归纳 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\engine\NlpKnowledgeScanner.java |
| LocalRagService 三模式检索 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\rag\LocalRagService.java |
| RadComponentReader 模板库 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\skill\RadComponentReaderExecutor.java |
| PageChannel 双向通道 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\page\ |
| CompileTool 编译沙箱 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\knowledge\tool\CompileTool.java |
| JavaSourceSkillExecutor 源码沙箱 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\skill\JavaSourceSkillExecutor.java |
| RuntimeDebugSkillExecutor 运行时沙箱 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\debug\skill\RuntimeDebugSkillExecutor.java |
| ThreeDimensionDetector 三维检测 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\debug\detection\ |
| NlpModuleAuditor 合规审计 | e:\github\a2ui\ooder-pro\src\main\java\net\ooder\studio\chat\scene\impl\NlpModuleAuditor.java |
| Agent SDK 入口 LlmSdk | e:\github\a2ui\agent-sdk\llm-sdk\src\main\java\net\ooder\sdk\llm\LlmSdk.java |
| ToolCallingApi | e:\github\a2ui\agent-sdk\llm-sdk\src\main\java\net\ooder\sdk\llm\tool\ToolCallingApi.java |
| Skills Framework | e:\github\a2ui\agent-sdk\skills-framework\ |
| SkillCenterClient | e:\github\a2ui\agent-sdk\skills-framework\src\main\java\net\ooder\skills\api\SkillCenterClient.java |
| @A2uiSkill 注解 | e:\github\a2ui\ooder-common\ooder-annotation\src\main\java\net\ooder\annotation\skill\A2uiSkill.java |
| A2uiSkillRegistrySPI | e:\github\a2ui\ooder-common\ooder-annotation\src\main\java\net\ooder\annotation\spi\A2uiSkillRegistrySPI.java |
| 7 大 classpath Skills | e:\github\a2ui\ooder-pro\src\main\resources\skills\ |
| Harness Pipeline 核心 | e:\github\a2ui\ouc\ouc-core\src\main\java\net\ooder\engine\llm\harness\NlpHarnessPipeline.java |
| AIServer 主入口 | e:\github\a2ui\aiserver\src\main\java\net\ooder\aiserver\AiServerApplication.java |
| AIServer SkillDef Controller | e:\github\a2ui\aiserver\src\main\java\net\ooder\bpm\controller\SkillDefController.java |
| VFS 独立样例 | e:\github\a2ui\vfs-web-app\src\main\java\net\ooder\vfswebapp\VfsWebApplication.java |
© OODER Studio · A2UI · AI-IDE 技术拆解系列
本文基于 OODER Studio 真实代码实现总结,所有路径均可在源码中验证。