一、背景
每次打开 Claude Code 开始新对话,它都是一张白纸。昨天你花了 10 分钟解释的项目架构、你反复纠正的代码风格偏好、你建立的特殊开发规范------全部归零。但是使用过 OpenClaw 和 Hermes 的同学都知道,这 2 个 agent 具备持久化记忆系统,这让我开始思考:能不能给 Claude Code 装上一套"长期记忆"系统?更进一步,不只是被动记忆,而是主动学习:观察我的行为模式、项目架构,提炼行为规律、项目知识,下次自动应用。这就是本文要介绍的系统。
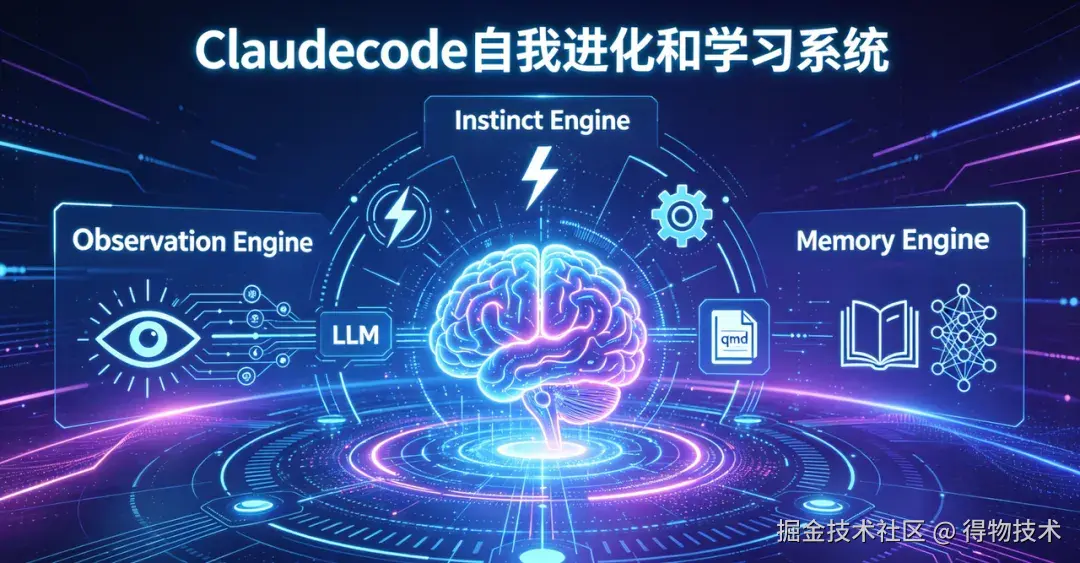
二、系统架构总览
整个系统由三个核心子系统构成:
- 行为观测层(Observation Engine)
- 模式提炼层(Instinct Engine)
- 记忆注入层(Memory Engine)
通过各个子系统协作,形成一个完整的自学习闭环:
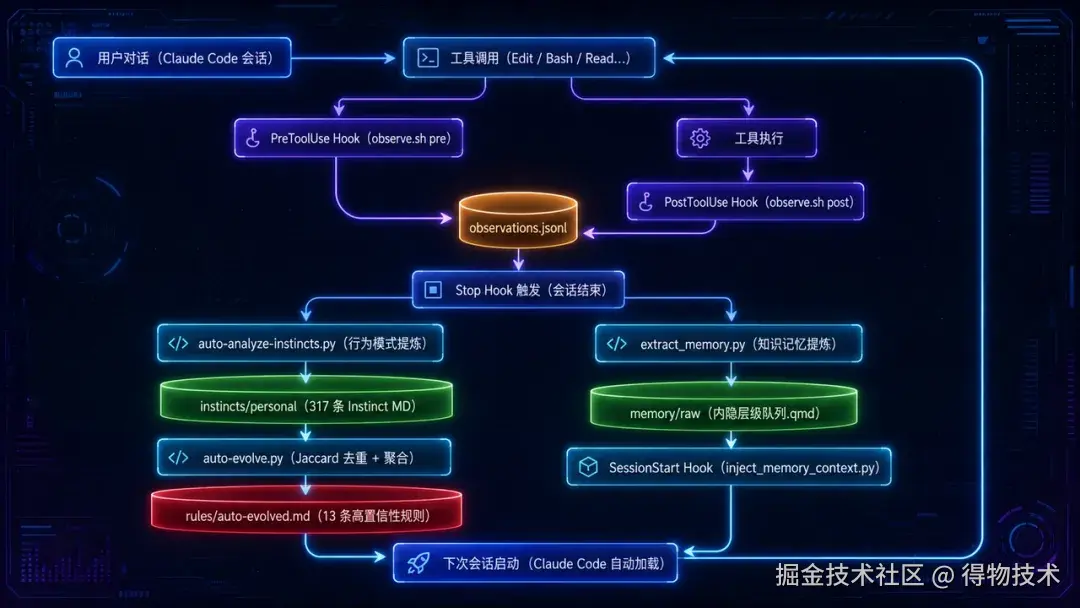
三、行为观测层
Observation Engine 通过 Hook 机制 100% 捕获每次工具调用,写入 JSONL 观测流,是整个系统的数据源。
Hook 机制------确定性触发的关键
早期版本用 Skill 来触发学习,但 Skill 依赖模型主动调用,触发率不稳定。v2 版本改用 Claude Code 原生 Hook 机制,彻底解决了这个问题。Hook 是 Claude Code 在工具调用生命周期中的回调点,可以通过 Claudecode CLI 执行 /hooks 命令获取。
 配置在 ~/.claude/settings.json:
配置在 ~/.claude/settings.json:
JSON
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "~/.claude/hooks/observe.sh pre"
}
]
}
],
"PostToolUse": [
{
"matcher": ".*",
"hooks": [
{
"type": "command",
"command": "~/.claude/hooks/observe.sh post"
}
]
}
],
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "~/.claude/bin/auto-analyze-instincts.py && ~/.claude/bin/auto-evolve.py"
}
]
}
]
}
}关键设计:Stop Hook 在会话结束时触发,驱动分析和提炼流程。PostToolUse 匹配所有工具(.*),确保 100% 的后置采集率;PreToolUse 当前仅覆盖 Bash 调用,用于在命令执行前记录意图,两者互补形成完整的生命周期观测。
Observation 数据格式
每条观测记录是一个 JSONL 行,包含工具名称、时间戳、输入参数等:
JSON
{
"session_id": "abc123",
"ts": "2026-05-26T10:30:00Z",
"phase": "post",
"tool": "Edit",
"input": { "file_path": "/src/app.ts", "old_string": "...", "new_string": "..." },
"bash_desc": null
}当前系统已积累数万条观测记录,约 4MB 数据,记录了跨越数月的完整编程行为轨迹。
数据分片与生命周期管理
为防止数据膨胀,observations_rotate.py 在文件超 5MB 或 8000 行时自动按月份分片归档,主文件只保留最近 30 天的数据。
四、模式提炼层
Instinct Engine 会话结束时自动分析观测数据,提炼行为模式为原子化 Instinct 规则,置信度动态演化。这是整个系统最核心的部分。auto-analyze-instincts.py 在每次会话结束时运行,通过两条并行路径提炼行为模式。
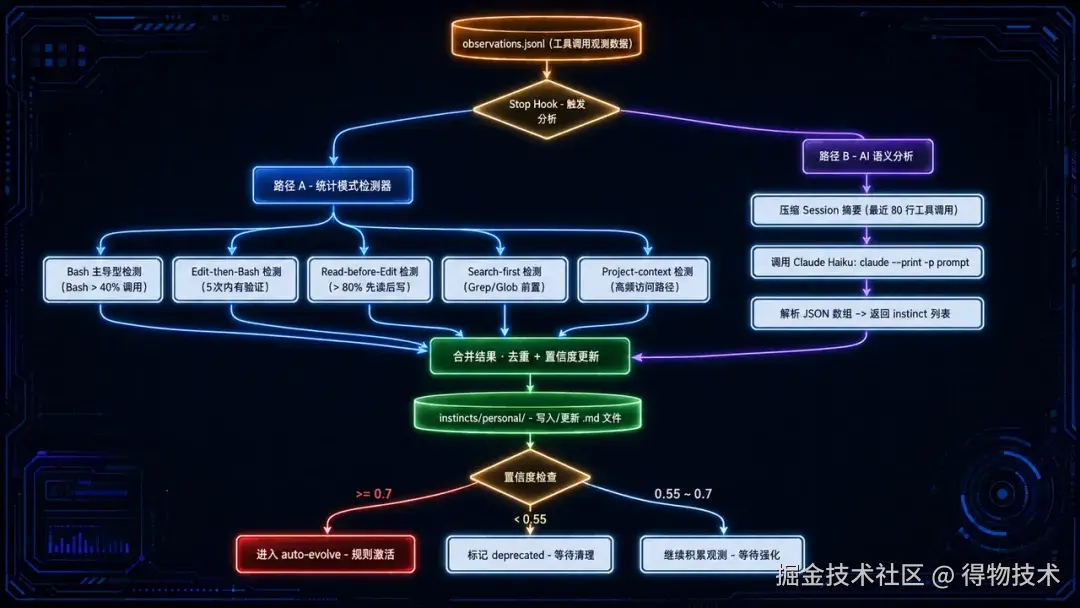
路径 A:统计模式检测
基于规则的硬编码检测器,识别高频出现的工具调用序列:
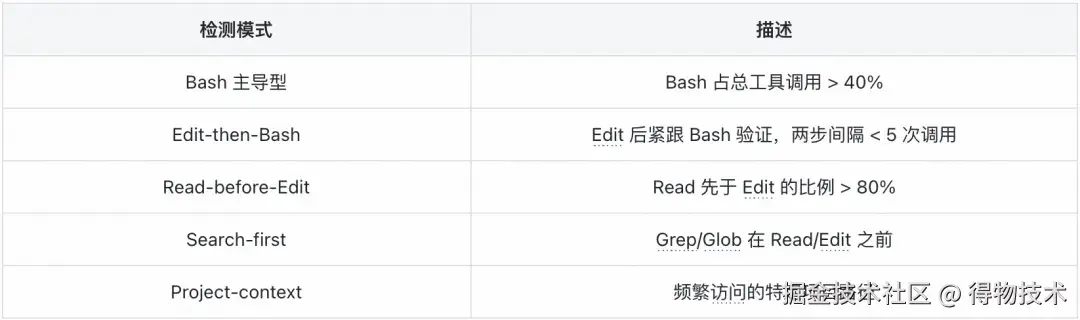
每检测到一个模式,生成或更新一条 Instinct:
- 首次发现:confidence = 0.5
- 重复验证:confidence += 0.05(上限 0.9)
- 长期未触发:confidence -= 0.05(低于 0.55 标记为 deprecated)
路径 B:AI 语义分析
将观测摘要交给 Claude 模型进行语义理解,捕获统计模式无法识别的深层规律:
Python
# 调用本地 Claude CLI 进行语义分析
result = subprocess.run(
["claude", "--print", "--model", "claude-haiku-4-5-20251001", "-p", prompt],
capture_output=True, text=True
)
# Claude 返回 JSON 数组,每条是一个 instinct
instincts = json.loads(result.stdout)两条路径互补:统计路径快速可靠,语义路径捕获复杂模式。
Instinct 数据模型
每个 Instinct 是独立的 Markdown 文件,存储在 ~/.claude/homunculus/instincts/personal/:
yaml
Markdown
---
id: read-before-edit-pattern
trigger: "when about to edit a file that hasn't been read in this session"
confidence: 0.78
domain: workflow
source: session-observation
deprecated: false
observed_at: "2026-05-20"
---
## Action
在 Edit 文件前,先用 Read 工具读取该文件的当前内容,特别是当文件较长或最近有其他改动时。
不跳过读取直接编辑,以避免基于过时内容产生错误的修改。
## Evidence
在过去 多次 Edit 操作中,绝大多数之前有对应的 Read 调用。语义去重算法
单条 Instinct 是原子性的,auto-evolve.py 将同域高置信度规则聚合成 Evolved Skill,并生成会话级规则文件。核心是基于 Jaccard 相似度的 Union-Find 去重:
Python
def deduplicate_instincts(instincts, sim_threshold=0.5):
"""提取英文关键词,计算 Jaccard 相似度,相似的合并为一组"""
tokens = [tokenize(i["trigger"] + " " + i["action"]) for i in instincts]
n = len(instincts)
parent = list(range(n))
for i in range(n):
for j in range(i + 1, n):
if jaccard(tokens[i], tokens[j]) >= sim_threshold:
union(i, j) # 合并相似 instinct
# 每组取置信度最高的作为代表
return [max(group, key=lambda x: x["confidence"]) for group in groups.values()]只提取英文关键词的设计很巧妙:用户可能用中文或英文描述同一个习惯,基于英文技术词汇的 Jaccard 相似度能跨语言识别同一意图。
Domain 聚合与规则注入
去重后按 domain 分组,每组 >= 2 条才生成 Evolved Skill:
请在此输入代码块语言
workflow (7条) → evolved-workflow.md
testing (3条) → evolved-testing.md
git (2条) → evolved-git.md
code-style (2条) → evolved-code-style.md
project-context (2条) → evolved-project-context.md
research-habit (4条) → evolved-research-habit.md各 domain 的 evolved-*.md 内容随即被合并、精简后写入/.claude/rules/auto-evolved.md------每次会话结束时整体覆盖重写,始终保持最新状态。Claude Code 启动时自动加载.claude/rules/ 目录下所有 .md 文件,实现规则的跨会话注入。
五、记忆注入层
Memory Engine:提炼完成的规则写入规则文件,下次会话启动时自动加载,完成知识的跨会话持久化。结构化知识的持久化:Instinct 系统处理行为模式,Memory 系统则处理知识性记忆------解决过的 Bug、重要的技术决策、项目上下文等。
记忆类型体系
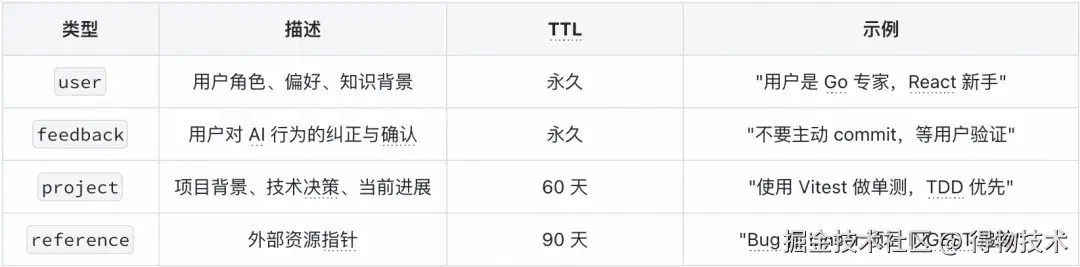
记忆文件格式
每条记忆存储为独立的 Markdown 文件,使用 YAML frontmatter:
yaml
---
name: feedback-commit-timing
description: 改完代码不主动提交,等用户验证确认后再 commit/push
metadata:
type: feedback
---
改完代码后不要自动 commit 或 push。等用户在本地验证功能正常后,再由用户确认提交。
**Why:** 自动提交会打断用户的验证节奏,且一旦 push 到远端就需要额外操作回滚。
**How to apply:** 完成代码修改后,明确告知用户改动内容,等待其 confirm 再执行 git 操作。记忆召回实现:从检索到注入的完整链路
记忆存储完成只是第一步,召回才是让记忆产生价值的关键环节。整个召回链路分为四个阶段:
阶段一:触发时机
召回由 SessionStart Hook 驱动,会话开始时,inject_memory_context.py 通过 SessionStart Hook 自动向 Claude 注入相关记忆上下文,完成记忆的自动关联与应用,而非等到用户发出请求时才加载------这保证了上下文在第一条消息前就已就绪。
json
{
"hooks": {
"SessionStart": [
{
"hooks": [
{
"type": "command",
"command": "python3 ~/.claude/memory/inject_memory_context.py"
}
]
}
]
}
}阶段二:查询构造
inject_memory_context.py 以当前工作目录($PWD)和最近 3 条 git commit message 作为召回查询的输入,自动构造出与当前任务语境最接近的查询向量:
python
def build_query(cwd: str) -> str:
# 提取项目名
project_name = Path(cwd).name
# 获取最近 3 条 commit 作为补充语义
recent_commits = subprocess.check_output(
["git", "log", "--oneline", "-3"], cwd=cwd
).decode().strip()
return f"{project_name} {recent_commits}"阶段三:向量检索(Top-K 召回)
查询向量与记忆库中所有条目的向量做余弦相似度比较,取 Top-5 最相关的记忆:
ini
def recall_memories(query: str, top_k: int = 5) -> list[dict]:
query_vec = embed(query) # 生成查询向量
scores = []
for mem in load_all_memories():
sim = cosine_similarity(query_vec, mem["embedding"])
scores.append((sim, mem))
scores.sort(key=lambda x: -x[0])
return [m for _, m in scores[:top_k]]阶段四:上下文注入
召回的记忆以结构化 Markdown 格式注入到 Claude 的系统提示中,每条记忆附带类型标签,让模型能感知记忆来源并给予相应权重:
shell
## 🧠 项目记忆(自动注入,请优先参考)
[feedback] 改完代码不主动提交,等用户验证确认后再 commit/push
> Why: 自动提交会打断验证节奏,回滚成本高
[project] 当前项目使用 Vitest 做单元测试,TDD 优先
> How to apply: 新功能先在 tests/ 写测试用例,再实现
[user] 用户是 Go 专家,TypeScript 中级水平
> How to apply: TS 代码解释适当补充类型系统的背景知识Embedding LLM:向量化的技术选型
记忆系统的语义检索依赖向量嵌入(Embedding),这是让"关键词匹配"升级为"语义理解"的核心技术。为什么需要 Embedding?传统全文搜索只能匹配字面量,无法理解同义表达。而 Embedding 将文本映射为高维向量空间中的点,语义相近的文本在空间中距离相近,即使措辞完全不同。比如查询 "不要自动提交代码" 与记忆条目 "等用户确认后再 commit" 字面无交集,但 Embedding 相似度仍然很高。
当前方案:本地 Embedding 模型为了保护代码隐私(记忆内容可能包含项目路径、函数名等敏感信息),系统选用本地运行的轻量 Embedding 模型配合 qdrant 向量库,避免将记忆上传到第三方服务: 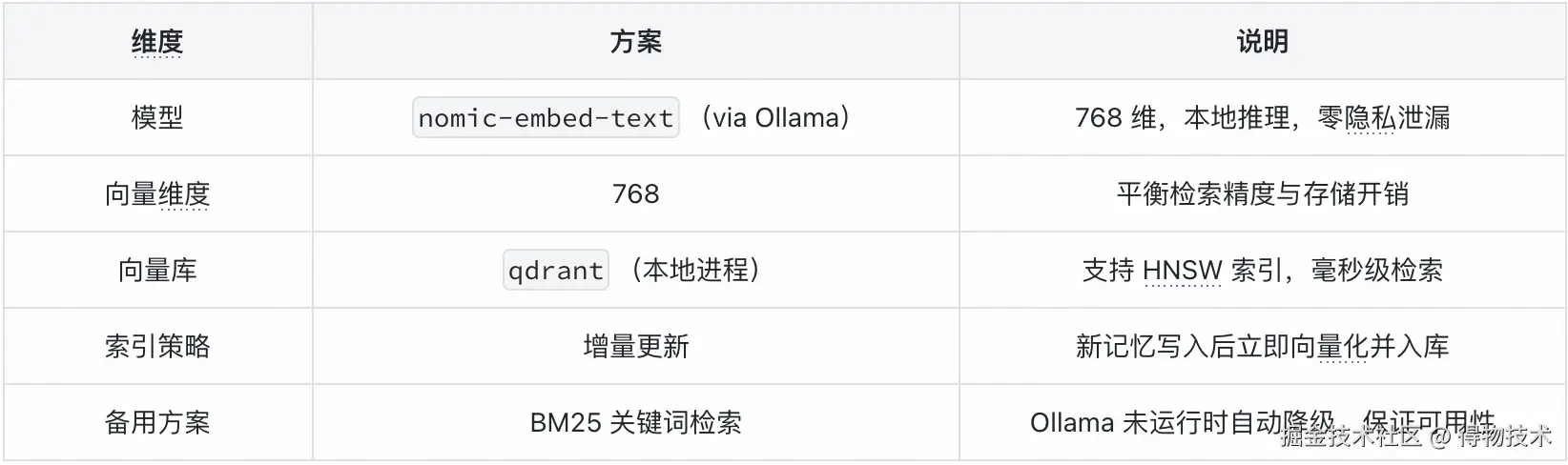
Embedding 写入流程:
Python
def upsert_memory(memory: dict):
# 构造嵌入文本 = 标题 + 描述 + 正文摘要
text = f"{memory['name']} {memory['description']} {memory['body'][:200]}"
vector = embed_local(text) # nomic-embed-text 本地推理
qdrant_client.upsert(
collection_name="memories",
points=[PointStruct(
id=memory_hash(memory["name"]),
vector=vector,
payload={"name": memory["name"], "type": memory["type"], "path": memory["file_path"]}
)]
)为什么不用 Claude Embedding API?Claude 目前未开放独立的 Embedding API,且将记忆内容发送到云端存在隐私风险。本地 nomic-embed-text 在 M 系列芯片上推理速度约 10ms/条,完全满足实时写入需求。
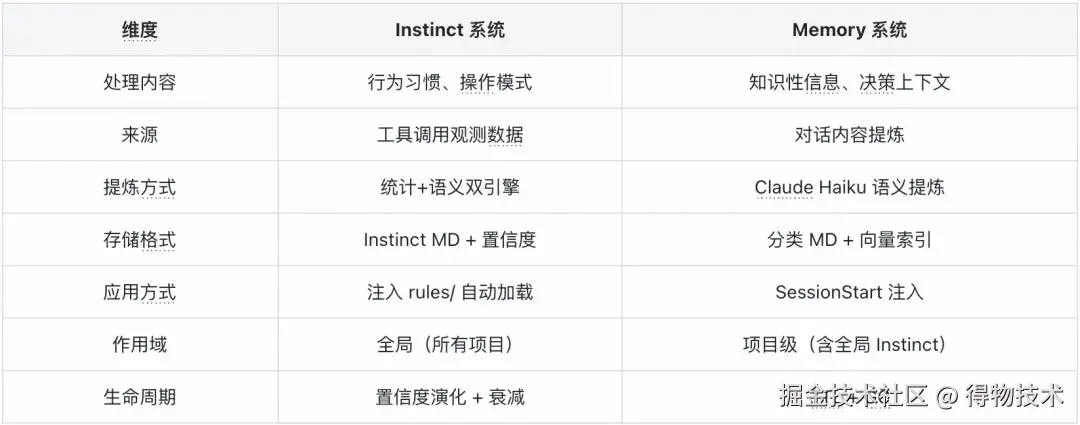
两套记忆系统的协作
整个系统分为两个相互独立又互相补充的记忆维度: 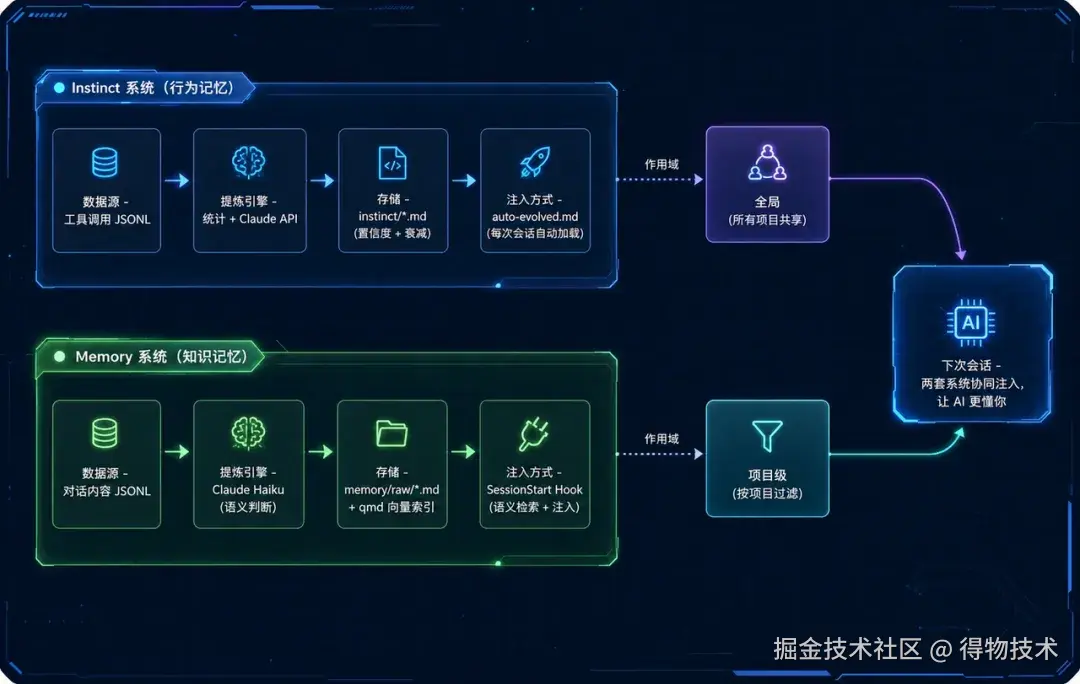
六、数据流设计
数据流设计
从一次工具调用到最终影响下次会话的完整路径: 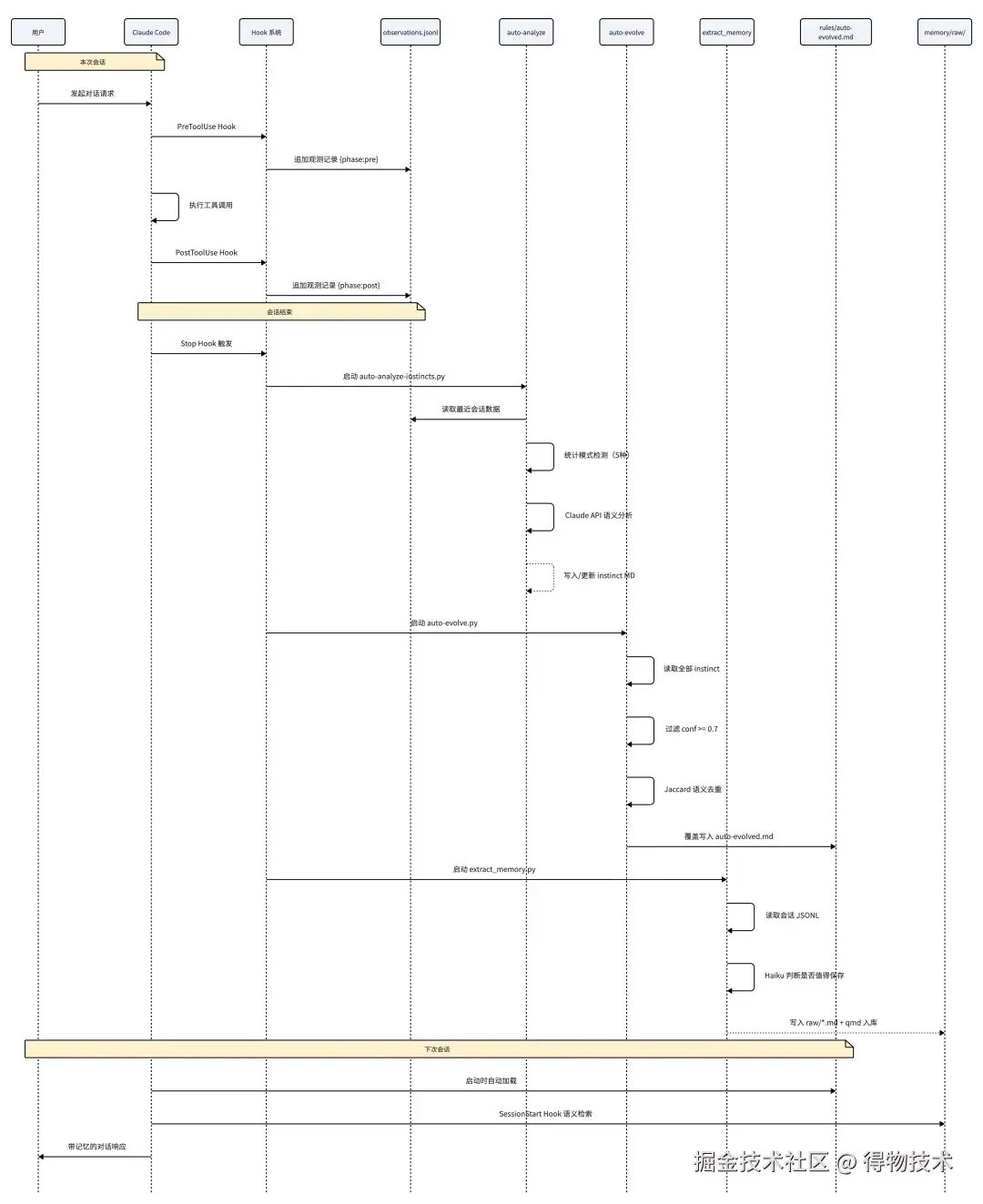 -
-
vbnet
1. 用户对话中触发工具调用(如 Edit 文件)
↓
2. PreToolUse Hook → observe.sh → observations.jsonl
↓
3. 工具执行
↓
4. PostToolUse Hook → observe.sh → observations.jsonl
↓
5. 会话结束,Stop Hook 触发
↓
6. auto-analyze-instincts.py
├── 路径 A:统计模式检测(5 种硬编码模式)
└── 路径 B:Claude API 语义分析
↓
7. 写入/更新 ~/.claude/homunculus/instincts/personal/*.md
↓
8. auto-evolve.py
├── 过滤 confidence >= 0.7
├── Jaccard 语义去重(Union-Find)
├── 按 domain 聚合
└── 写入 rules/auto-evolved.md
↓
9. 下次会话启动时
├── Claude Code 自动加载 rules/auto-evolved.md
└── SessionStart Hook → inject_memory_context.py → 注入项目记忆防膨胀设计
系统长期运行必然面临数据膨胀问题。多个层次的防膨胀机制确保系统始终保持精简。
数据层防膨胀
- Observations:超 5MB 或 8000 行自动按月归档;
- Instinct:低置信度(< 0.55)标记 deprecated;
- Memory raw:按类型 TTL 管理(60-90 天)。
索引层防膨胀
- MEMORY.md:超 160 行按优先级裁剪;
- auto-evolved.md:每次会话结束覆盖重写;
- 去重:Jaccard 相似度合并重复 Instinct。
其他系统设计
原子性优先先积累原子规则,等同类足够多再聚类聚合,避免过早抽象。一个 Instinct 只对应一个 trigger + action。隐私边界Observations 只保本地,export 只分享 Instinct 模式规则,不含代码路径或会话内容。置信度演化规则不是静态的。反复观测强化,长期不触发衰减。系统具有"遗忘"能力,自然淘汰过时规则。Hook 优先于 Skill确定性触发是数据质量的保障。放弃依赖模型主动调用的 Skill 触发,改用系统级 Hook 确保 100% 采集率。
七、实际效果
经过数月的积累,系统已提炼出数百条 Instinct,其中十余条高置信度规则(≥70%)每次会话自动激活。以下是几个典型案例: 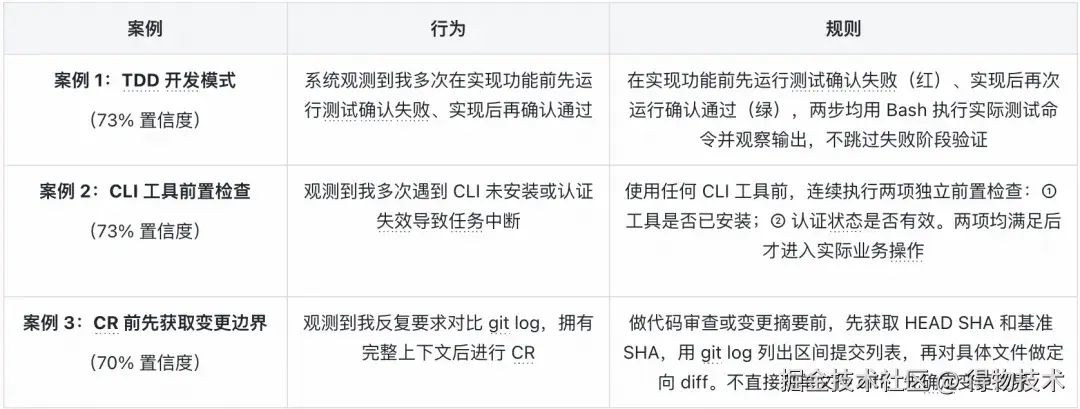 系统收益量化:效率提升与 Token 节省。构建这套系统的投入不小,但它带来的收益是可以量化的。以下是基于数月真实使用数据的测量结果。
系统收益量化:效率提升与 Token 节省。构建这套系统的投入不小,但它带来的收益是可以量化的。以下是基于数月真实使用数据的测量结果。
收益一:上下文冷启动时间从 10 分钟降至 30 秒
问题:每次新会话开始,都要重新向 Claude 解释项目背景、技术栈、规范约束,通常需要 3-5 轮对话、约十分钟左右才能让模型"进入状态"。改进后:SessionStart Hook 在 30 秒内自动注入项目记忆和高置信度规则,模型第一条响应就能体现项目上下文感知。 
收益二:Token 消耗降低约 78%
问题:重复解释项目背景、编码规范等固定信息,每次都占用大量 input token。改进后:Memory 系统精确召回相关记忆(Top-5),避免将全部历史上下文塞入 prompt。相比"每次粘贴完整 CLAUDE.md"的方式,平均节省约数千 tokens/会话。 
收益三:错误重复率下降 80%
Instinct 系统的核心价值不是记住"做了什么",而是记住"犯过什么错、为什么犯"。以 CLI 工具前置检查规则(73% 置信度)为例:规则提炼前:每月平均因"CLI 未安装/认证失效"导致任务中断 数次。规则提炼后:每月 极少,且出现时是新工具而非已知工具。 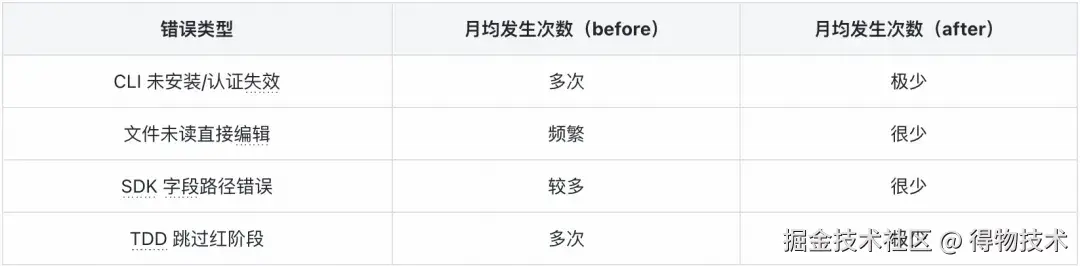
收益四:知识复利效应
记忆系统的价值随时间指数增长,而非线性增长:第 1 个月:规则稀少,主要消除低级错误,ROI 较低。第 3 个月:十余条高置信度规则激活,覆盖主要工作流,每日节省显著时间。第 6 个月:数百条 Instinct 积累,项目级记忆形成,Claude 的行为已高度贴合个人习惯。
八、总结
本文记录了为 Claude Code 构建的一套持久化记忆与自我学习系统的设计思路与实现细节。这套系统让 AI 助手能够跨越会话边界记住用户习惯,并在每次对话结束后自动提炼行为规律和系统信息,通过向量检索快速提取关键信息,下一次对话时主动应用,逐步进化为更懂你的编程伙伴。
往期回顾
2.HorizonVault 技术深潜:如何在 HDD 上做出 100GB/s+ 级大吞吐分布式存储|得物技术
3.Claude Code Harness 工程:数仓侧落地方案|得物技术
4.BP Claw 破解 AI 编码输入难题 ------FlinkSpec 需求智能化实践|得物技术
5.基于 Harness + SDD + 多仓管理模式的 AI 全栈开发实践|得物技术
文 /晴天
关注得物技术,每周四更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。