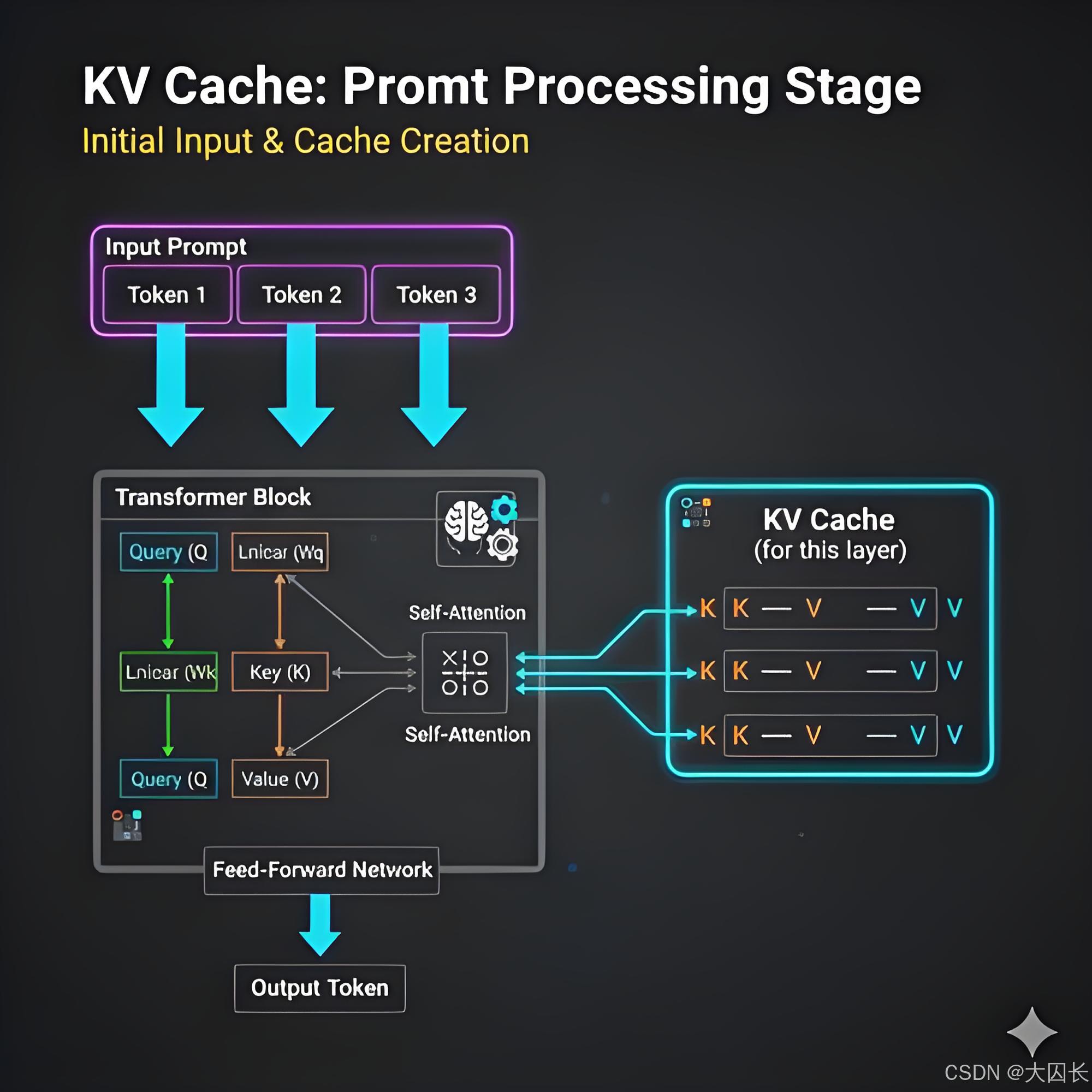
一、技术本质:它到底复用了什么?
要理解上下文缓存,得先知道大模型生成文本时的两个关键点:自回归解码 和 KV Cache。
-
自回归与重复计算
大模型每次生成一个token,都要把之前所有token(包括输入的prompt和已生成的部分)重新计算一遍注意力(Attention)。这其中大部分计算都是在重复计算已有的内容,非常浪费。
-
KV Cache
为了加速,推理引擎会把每一层Transformer里计算出的 Key 和 Value 矩阵缓存下来。这样生成新token时,只需要算新token的Query,再和历史的Key、Value做注意力运算即可,无需重算历史部分。这部分缓存就叫 KV Cache。
-
上下文缓存的本质
常规的KV Cache在请求结束后就释放了。上下文缓存,就是把一个请求中某段前缀的KV Cache持久化下来,给后续共享相同前缀的请求直接复用。
复用时,推理引擎跳过前缀部分的全部计算,直接从缓存中加载Key/Value,等于用存储换计算。效果:
- 延迟大幅降低:省去前缀的预填充时间,TTFT(首token时间)显著缩短。
- 成本降低:省去前缀token的推理计算成本,API按读取缓存的折扣价计费。
二、三种实现模式与API深度剖析
不同厂商提供了不同粒度的控制,主要分三类:
1. 显式缓存:开发者完全掌控
你需要主动创建、引用和删除缓存。优点是命中率高,行为可控,适合需要精细成本优化的场景。
① Anthropic Claude:断点缓存
通过在messages数组中插入cache_control标记来声明缓存断点。系统会缓存该断点之前的所有连续内容。
-
请求示例(伪代码)
json{ "model": "claude-sonnet-4-20250514", "system": [ { "type": "text", "text": "你是一个严谨的法律助手...很长的系统指令", "cache_control": {"type": "ephemeral"} } ], "messages": [ { "role": "user", "content": "帮我审阅这份合同..." } ] }在
system内容的最后标记了cache_control,这样整个system prompt的KV Cache就会被创建并存储。 -
成本模型(大致比例,以官方最新为准)
- 缓存写入(创建/更新):略高于标准输入价格,例如基准输入3/MTok,写入可能3.75/MTok。
- 缓存读取 (命中):极低价格,例如$0.30/MTok,节省约90%。
- 最小缓存长度:通常1024 token(低于此的片段不缓存)。
- 最大断点数:4个,可让系统匹配前缀的不同子集。
- 生命周期:默认5分钟,每次命中后刷新TTL。
② 阿里云DashScope:独立的缓存资源
将缓存作为一个独立资源管理,需要先调用CreateCache接口创建,再在对话时引用cache_id。
-
流程:
- 创建缓存 :上传文本,获得
cache_id。 - 使用缓存 :在Chat请求中传入
cache_id,并指定enable_cache=True。系统会检查前缀是否匹配,命中则自动读取。 - 删除/管理:可手动删除释放存储。
- 创建缓存 :上传文本,获得
-
成本模型(显式)
- 创建费用 :按输入单价的125% 收取(贵在需要计算并存储KV Cache)。
- 命中费用 :仅收输入单价的10%。
- 这是典型的"前期投入,后期大量节省"模式。假设输入单价1元/百万token,一个100k token的系统提示,创建花费0.125元;之后每次命中仅花0.01元,普通无缓存每次0.1元,命中10次即回本。
③ 月之暗面 Kimi:存储单独计费
Kimi的显式缓存把费用拆得更细,适应超长待机的缓存场景。
- 成本模型
- 创建费用:24元/百万token(一次性)。
- 存储费用:10元/百万token/分钟(即缓存占用时间收费)。
- 调用费用 :每次调用若命中缓存,收取0.02元/次,且可能不再收输入token费用 或极低价格。
这种方式鼓励你长时间保留"热"数据,对于频繁访问的文档非常划算。
④ 快手万擎:支持增量更新
除了create,还提供prefix和append模式。可以对一个已存在的缓存追加新内容,无需重新创建整个前缀。这在多轮对话中很有用:每轮对话结束后,把新的assistant回复和user新问题append到缓存,下次请求只需缓存最新一段增量,历史部分全被复用。
2. 隐式缓存:零操作,自动生效
服务商在后台自动检测高频前缀并复用,对开发者完全透明。典型如阿里云的隐式缓存,无需任何代码改动。
- 命中机制:系统会对所有请求的prompt做哈希,相同哈希的前缀自动共用KV Cache。
- 成本 :命中的那部分token,按照输入单价的20% 左右收费(阿里云),相当于自动打8折。
- 优点:零心智负担,自然获得优化。
- 缺点:命中率不可控,依赖实际请求重合度,对于高度定制、低频的场景效果有限。
3. 磁盘缓存(DeepSeek风格):更极致的经济性
传统KV Cache存放在昂贵的GPU显存(HBM)中,容量有限。DeepSeek则实现了将KV Cache卸载到NVMe SSD硬盘上,配合智能调度,可以缓存更大的上下文、更长时间,而硬件成本极低。
- 对用户依然透明:无需操作,系统自动将对话历史、系统提示等缓存到分布式硬盘缓存池。
- 性能权衡:从硬盘读取KV Cache的延迟远低于重新计算整个前缀,虽然比从显存读取略慢,但换来的是近乎无限的缓存容量和极低的摊销成本。
- 意义:使千万级别Token的长文档缓存成为可能,进一步拉低了大批量知识库问答的成本底线。
三、成本节省测算:一个实际例子
假设你有一个法律问答服务,系统提示词(包含角色、规则、知识)长 10万token ,每天有 1000次 不同用户提问(每次提问20token),模型输入价格为 1元/百万token。
场景A:不使用缓存
每次请求输入 = 100k系统提示 + 20用户问题 = 100,020 token
每日输入总token ≈ 1亿token
每日输入成本 = 100元
场景B:使用阿里云显式缓存
- 首次创建缓存:10万token × 1元/百万token × 125% = 0.125元(一次性)
- 后续999次请求,前缀命中,系统提示部分按10%计价:每次命中费用 = 100k token × 1元/百万token × 10% = 0.01元
- 用户问题部分(20token)按标准价:0.00002元 × 999 ≈ 0.02元
- 总成本 ≈ 0.125 + 9.99 + 0.02 ≈ 10.14元
成本从100元直降到10.14元,降幅近90%。 请求量越大、前缀越长,效果越显著。
四、最佳实践与常见陷阱
✅ 最佳实践
- 固化长前缀:把固定的、共享的长内容(系统prompt、知识库、角色设定、示例)放在请求的最前面,并设置缓存断点。之后动态的用户问题紧跟在后面。
- 合理分割断点 (Anthropic风格):对独立模块设置多个缓存断点,比如
<系统指令>、<法律条文A>、<法律条文B>,让系统可以按不同组合复用。 - 多轮对话使用append:如果支持增量缓存(快手万擎),每轮对话结束后显式将新内容追加到缓存,而不是每次发送全量历史。
- 设置缓存TTL与主动管理:留意缓存有效期,对高频场景可定期"续命"或重新创建。
- 监控命中率:大部分平台提供命中率指标,低于预期时检查是否引入了动态前缀(如时间戳、随机数)导致无法匹配。
❌ 常见陷阱
- 在缓存前缀前插入动态内容:例如先写一个用户ID,再写系统提示,导致每个请求前缀都不同,缓存彻底失效。
- 缓存过短片段:通常小于1000 token的内容不会触发缓存(厂商限制),白费功夫。
- 忽视存储成本:Kimi等按时长收费的模式下,保留超长却低频访问的缓存可能产生持续的存储费用,不如每次重新计算。
- 盲目缓存:如果前缀很短(几十token),节省有限,还要付出创建和管理开销,得不偿失。
五、总结
上下文缓存是一种用极少存储成本置换巨大推理计算开销的技术,本质是KV Cache的跨请求持久化。根据不同厂商的实现,你可以选择:
- 零侵入的隐式缓存,直接享受折扣;
- 高可控的显式缓存,通过精细管理将重复前缀的推理成本降至1-2折;
- 海量扩展的磁盘缓存,支撑百万级Token场景。
在设计AI应用时,固化并缓存共享前缀已是标配,能立竿见影地压降延迟和成本。