前几天随手敲了一段最简单的定时器代码,本以为是再基础不过的知识点,闭着眼都能猜对输出结果。结果代码一跑,控制台的打印顺序直接推翻了我的固有认知,当场懵了。
我第一反应是:代码从上到下逐行执行,顺序肯定是 start → 222 → end。可实际运行后才发现,根本不是这么回事,也借着这个契机,重新把 JS 同步、异步、事件循环和 Promise 完整梳理了一遍。
先看这段入门级演示代码:
javascript
// 同步代码 sync
console.log('start');
// 异步代码 async
setTimeout(() => {
console.log('222');
}, 1000);
console.log('end');实际输出顺序:
plaintext
start
end
// 等待1秒后
222看到结果的时候我第一时间反问自己:为什么定时器里的内容会最后执行?想要搞懂答案,就得先吃透 JS 的执行模型。
先搞懂底层:进程、线程与单线程设计
先聊两个基础概念,我当时也是在这里绕了一会。可以用一个很形象的比喻帮自己记:进程 = 公司董事长 ,负责分配内存、资源这些全局事务;线程 = 执行具体工作的经理,真正跑代码、处理任务。
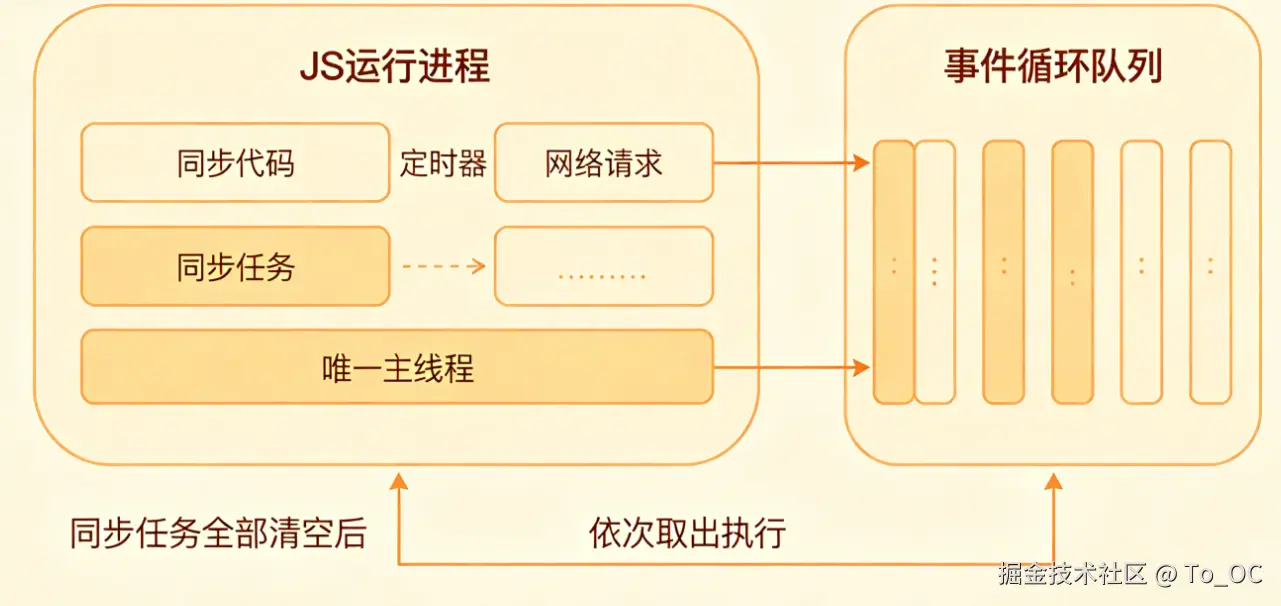
示意图说明:左侧为 JS 运行所在进程,内部只启动唯一主线程;主线程优先执行所有同步代码,遇到定时器、网络请求等异步任务,统一推入右侧事件循环队列;等主线程同步任务全部清空后,再依次取出队列中的异步任务执行。
像 Java、C++ 这类语言支持多线程,可以同时开启多个 "经理" 并行干活,效率高但逻辑复杂。而 JS 从设计之初就定为单线程------ 整个进程里只有一个主线程在干活。
这么设计的核心原因是 JS 主打前端页面交互,单线程能完美规避多线程资源抢占、DOM 冲突等复杂问题,保证页面逻辑简单稳定。
但问题来了:如果遇到定时器、网络请求这类耗时任务 ,单线程原地等待的话,页面会直接卡死。JS 给出的解决方案就是 事件循环(Event Loop) :
- 主线程优先全速执行所有同步代码;
- 碰到异步耗时任务,不会阻塞主线程,而是把它丢进事件循环队列;
- 等主线程手上所有同步工作全部做完、进入空闲状态,再从队列里取出异步任务执行。
再看一段纯同步代码,就能直观感受到单线程的执行逻辑,代码顺序和输出顺序完全一致:
javascript
// 纯同步代码,单线程按顺序逐行执行
let a = 1;
let b = 2;
let c = 3;
console.log(a + b + c); // 直接输出 6到这里,基础的同步异步规则就理清了。但新的问题接踵而至:如果异步任务之间存在依赖关系该怎么办?
举个实际场景:先请求接口获取所有用户列表,再根据每个用户 ID 逐个请求用户详情。如果只用原生定时器嵌套,代码会一层套一层,变成大家口中的回调地狱,后期维护简直是灾难。
也正是为了解决异步流程难以管控的痛点,ES6 正式推出了 Promise。
上手 Promise:踩过认知误区才懂底层设计
Promise 是 ES6 专门用来标准化异步任务的方案,我最开始只会调用 then 和 catch,对内部执行逻辑一知半解,踩了不少坑。先从基础用法入手,看完整示例:
javascript
// promise es6 用于异步任务控制的最佳时机
const p = new Promise((resolve, reject)=>{
// 耗时性任务
setTimeout(()=>{
// resolve(666); // 异步成功分支
reject('网络错误');// 异步任务失败,走拒绝分支
},1000);
});
// 查看Promise实例的原型,佐证它是构造函数实例
console.log(p.__proto__);
// 链式调用处理结果
p
.then((data)=>{
console.log(data);
console.log('end');
})
.catch((err)=>{
console.log(err);
console.log('error');
})
.finally(()=>{
console.log('finally');
})这段代码的执行逻辑我拆解一下,也是 Promise 的核心规则:
- 实例化
Promise时,必须传入一个执行器函数 (executor) ; - 执行器函数自带两个形参:
resolve(标记任务成功)、reject(标记任务失败); - 异步任务成功调用
resolve,结果会传递给.then();失败调用reject,错误信息传递给.catch(); .finally()属于通用收尾逻辑,不管异步成功还是失败,都会执行。
控制台打印 p.__proto__ 可以清晰看到 Promise 的原型链,能直观证明 Promise 是基于构造函数实现的。

现在前端最常用的网络请求 API fetch,底层就是基于 Promise 封装的。我当时特意写了一段 HTML 代码验证,直接把 fetch 打印到控制台,想看看它的返回值:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
console.log('start');
// fetch 的底层是 promise
console.log(fetch('https://www.baidu.com',{
method: 'POST',
}).then(()=>{
}).catch((err)=>{
console.log(err);
}))
console.log('end');
</script>
</body>
</html>
截图说明:控制台中可以看到,
fetch执行后直接返回了一个 Promise 实例对象,而非接口请求结果,彻底印证了它和 Promise 的绑定关系。
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script>
console.log('start');
// fetch 的底层是 promise
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json; charset=UTF-8',
},
body: JSON.stringify({
title: 'foo',
body: 'bar',
userId: 1,
}),
}).then((response) => {
console.log('请求成功!', response.status);
return response.json();
}).then((data) => {
console.log('响应数据:', data);
}).catch((err) => {
console.log('请求失败:', err);
})
console.log('end');
</script>
</body>
</html>
运行后能明显看到:start 和 end 先打印,fetch 返回 Promise 对象,请求的异步逻辑延后执行,完全贴合前面讲的事件循环规则。
实打实踩过的两个大坑,别再被表象迷惑
讲完基础用法,重点说说我实际开发和练习时踩的坑,这也是理解最容易出现偏差的地方。
坑 1:误以为 Promise 构造器内部代码是异步的
这是我卡得最久的一个问题,足足纠结了半小时。我写了一个模拟延时的 sleep 函数,第一反应 :函数内部嵌套了 setTimeout,那整个 Promise 里的代码都会延迟 2 秒执行。
代码如下:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Promise执行顺序</title>
</head>
<body>
<script>
function sleep(t) {
const p = new Promise((resolve, reject) => {
// 注意这一行,坑了我半小时!
console.log('同步');
setTimeout(() => {
resolve();
}, t)
})
return p;
}
sleep(2000)
.then(() => {
console.log('2s 后执行');
})
</script>
</body>
</html>
截图说明:页面刚加载完成,就立刻打印出「同步」,等待 2 秒后才打印「2s 后执行」。
看到结果我瞬间反应过来自己错在哪了:Promise 的执行器函数,本身是同步代码! 创建 Promise 实例的瞬间,执行器就会被主线程立即执行,只有执行器内部的 setTimeout 这类异步逻辑,才会被丢进事件循环排队。
所以 console.log('同步') 页面一加载就输出,resolve 要等待 2 秒触发,进而执行 then 里的逻辑。这是 90% 新手都会混淆的知识点。
坑 2:认为 finally 只有异步成功才会执行
我之前想当然地觉得,finally 是 "成功之后的收尾",如果异步任务报错走了 catch,finally 就不会运行。
测试之后才纠正这个错误认知:无论 Promise 状态是成功(fulfilled)还是失败(rejected),finally 都会执行。
它的定位就是通用收尾操作,比如关闭加载动画、释放资源、清空临时状态,非常适合做这类和业务结果无关的逻辑。
不要在 finally 中返回业务数据,它的返回值无法被后续链式调用接收,仅用来做收尾工作。
顺着这些坑再回头看 Promise 的设计思路,翻看了部分规范和 V8 底层实现后也明白:它的核心思想就是解耦 。把「耗时的异步操作」和「结果处理逻辑」拆分开,执行器负责干活,then/catch/finally 负责处理结果,彻底告别了回调地狱。
最后梳理总结与实际使用提醒
一路从基础定时器、事件循环,再到 Promise 踩坑调试,整套逻辑串下来,我提炼出三个最核心的要点,也是日常编码必须记牢的:
- JS 单线程是底层根基,同步代码永远优先执行,所有异步任务都会进入事件循环排队;
- Promise 执行器函数属于同步逻辑,只有内部嵌套的异步代码才会延后执行,不要把整个 Promise 当成异步代码;
then处理成功、catch捕获异常、finally统一收尾,三者分工明确,构成完整的异步流程。
另外客观说一句,Promise 并非万能。如果遇到大批量异步任务串行、复杂分支嵌套,纯链式调用依旧会显得臃肿;同时原生 Promise 也不支持主动取消正在进行的异步请求。实际开发中,我们一般会搭配 async/await、Promise.all、Promise.race 等语法和方法配合使用,才能应对各类复杂业务场景。
把这些底层逻辑和坑点都摸透之后,再写异步代码就踏实多了。如果你平时写 JS 异步逻辑时,也遇到过莫名其妙的执行顺序问题,或是踩过其他有意思的坑,不妨留个言聊聊,我也想看看大家遇到的奇葩场景。