一、环境和目标
1.1 环境
基于如下环境部署大模型(宿主机需要安装驱动,否则docker容器中的驱动无法运行)
bash
Ubuntu 22.04(驱动580)
HGX H200 ×8
Docker
vLLM
New Api
OpenWebUI
Qwen3-0.6B1.2 目标
基于docker通过vLLM部署Qwen3-0.6B大模型
基于docker部署开源token平台New Api
基于docker部署的 AI Web界面OpenWebUI
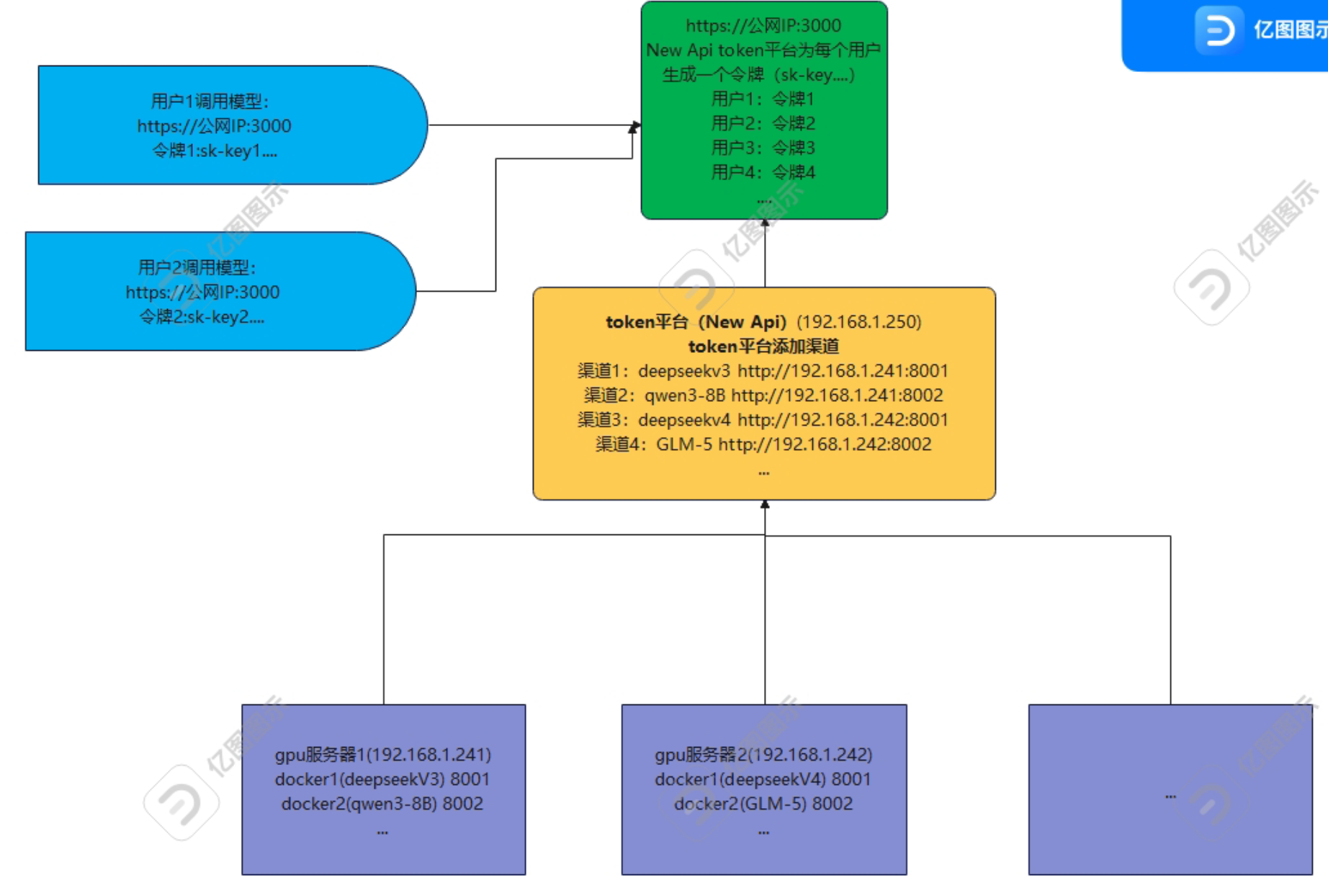
二、部署docker容器
2.1创建项目目录
bash
mkdir -p ~/ai-newapi
cd ~/ai-newapi2.2 创建 docker-compose.yml
vim docker-compose.yml
bash
services:
vllm:
image: vllm/vllm-openai:latest
container_name: vllm
restart: always
runtime: nvidia
ipc: host
ports:
- "8000:8000"
volumes:
- ~/.cache/huggingface:/root/.cache/huggingface
environment:
- HF_HUB_OFFLINE=1
command: >
Qwen/Qwen3-0.6B
--served-model-name qwen3
--host 0.0.0.0
--port 8000
--tensor-parallel-size 1
--gpu-memory-utilization 0.85
--max-model-len 4096
--max-num-seqs 64
new-api:
image: calciumion/new-api:latest
container_name: new-api
restart: always
ports:
- "3000:3000"
volumes:
- ./new-api-data:/data
openwebui:
image: ghcr.io/open-webui/open-webui:main
container_name: openwebui
restart: always
ports:
- "3001:8080"
environment:
- OPENAI_API_BASE_URL=http://new-api:3000/v1
- OPENAI_API_KEY=sk-4EdMtghGH1Puw4nqLCxaFyC3AM7NJIfPSPX1H16E48wJZExf
- ENABLE_RAG_WEB_SEARCH=false
- ENABLE_RAG_HYBRID_SEARCH=false
- ENABLE_OLLAMA_API=false
- HF_HUB_OFFLINE=1
- RAG_EMBEDDING_ENGINE=openai
volumes:
- ./openwebui:/app/backend/data**更换模型:**如果想换成Qwen3-8B,就把Qwen/Qwen3-0.6B改成Qwen/Qwen3-8B
**ipc=host:**可能存在容器中共享内存不足的情况,启动容器时需要添加该参数以配置和host宿主机共享内存,否则多GPU很容易共享内存不足。
**served-model-name:**让 vLLM 接受 qwen3 作为模型名字,vLLM 默认的服务名是模型全路径,而不是 qwen3,如果不设置使用 "model": "qwen3" 请求时会返回 NotFoundError: The model 'qwen3' does not exist
**tensor-parallel-size:**控制并行计算 这个参数决定了用多少张GPU卡来并行计算,如果是单卡系统不用设置,对于8卡系统如果模型很小单卡可以跑可以设置为1,如果模型很大推荐设置--tensor-parallel-size 8
**gpu-memory-utilization:**GPU 显存利用率阈值,就是告诉加载器:这块显卡显存,最多允许用百分之多少 留给模型 + KV Cache,剩下的留空不占用。留给系统、驱动、CUDA 后台开销,不分给大模型。
**max-model-len :**模型最大上下文总长,输入问题 + 模型输出回答 + 历史对话 全部加起来的最大 Token 上限。
max-num-seqs: 参数的主要 作用是控制 vLLM 推理服务可以同时处理的并发请求数量。
2.3 启动docker容器
启动:
docker compose up -d一键获取完整项目代码bash
第一次:
会自动下载 模型。
等待:Uvicorn running on ...
2.4 查看镜像和容器
bash
root@pc:~/ai-newapi# docker images
i Info → U In Use
IMAGE ID DISK USAGE CONTENT SIZE EXTRA
calciumion/new-api:latest 5a4ca9705f13 264MB 65.6MB U
ghcr.io/open-webui/open-webui:main 7f1b0a1a50cf 6.73GB 1.72GB U
vllm/vllm-openai:latest 70a098d90dba 31.8GB 8.23GB U
root@pc:~/ai-newapi# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
39b7a1c3e0f6 vllm/vllm-openai:latest "vllm serve Qwen/Qwe..." 23 hours ago Up 10 hours 0.0.0.0:8000->8000/tcp, [::]:8000->8000/tcp vllm
b3b581aebed3 ghcr.io/open-webui/open-webui:main "bash start.sh" 23 hours ago Up 10 hours (healthy) 0.0.0.0:3001->8080/tcp, [::]:3001->8080/tcp openwebui
876f403c69fa calciumion/new-api:latest "/new-api" 23 hours ago Up 10 hours 0.0.0.0:3000->3000/tcp, [::]:3000->3000/tcp new-api
root@pc:~/ai-newapi#2.5 查看 vLLM 日志
bash
docker logs -f vllm可以看到vLLM 已经正确识别了模型标识 Qwen/Qwen3-0.6B,但是在尝试联网下载配置文件时,容器内无法访问 Hugging Face 服务器 (Network is unreachable)。
第一步:在宿主机上把模型下载好
你可以直接在宿主机上使用 huggingface-cli 下载 Qwen3-0.6B 模型(若未安装,先 pip install huggingface_hub):
bash
apt install -y python3-pip
root@pc:~/ai-platform# pip3 install -U huggingface_hub
Collecting huggingface_hub
Downloading huggingface_hub-1.14.0-py3-none-any.whl (661 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 661.5/661.5 KB 2.1 MB/s eta 0:00:00
Collecting fsspec>=2023.5.0
Downloading fsspec-2026.4.0-py3-none-any.whl (203 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 203.4/203.4 KB 9.0 MB/s eta 0:00:00
root@pc:~/ai-platform# echo 'export HF_ENDPOINT=https://hf-mirror.com' >> ~/.bashrc
root@pc:~/ai-platform# source ~/.bashrc
root@pc:~/ai-platform# hf download Qwen/Qwen3-0.6B
Fetching 10 files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [02:21<00:00, 14.16s/it]
Download complete: : 1.52GB [02:21, 11.7MB/s] ✓ Downloaded███████████████████████▋ | 7/10 [02:21<01:07, 22.49s/it]
path: /root/.cache/huggingface/hub/models--Qwen--Qwen3-0.6B/snapshots/c1899de289a04d12100db370d81485cdf75e47ca
Download complete: : 1.52GB [02:21, 10.7MB/s]
root@pc:~/ai-platform#这样模型文件就会自动保存到 ~/.cache/huggingface/hub/models--Qwen--Qwen3-0.6B/ 中,与你的挂载路径一致。
第二步:修改 vllm 服务配置,启用离线模式并移除网络依赖
将 vllm 服务的 environment 部分增加 HF_HUB_OFFLINE: 1,同时你可以删除无用的 HUGGING_FACE_HUB_TOKEN(除非你有其他作用)。以列表格式写 command 会更清晰,避免解析错误(但保留你当前的位置参数方式也没问题)。
三、测试 vLLM的OpenAI API接口
3.1 查看模型
bash
root@pc:~/ai-newapi# curl http://192.168.5.101:8000/v1/models
{"object":"list","data":[{"id":"qwen3","object":"model","created":1781082221,"owned_by":"vllm","root":"Qwen/Qwen3-0.6B","parent":null,"max_model_len":4096,"permission":[{"id":"modelperm-a4dfca7502c79856","object":"model_permission","created":1781082221,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}
root@pc:~/ai-newapi#
root@pc:~/ai-newapi#3.2 聊天测试
bash
root@pc:~/ai-newapi# curl http://192.168.5.101:8000/v1/chat/completions -H "Content-Type: application/json" -d '{ "model":"qwen3", "messages":[{"role":"user","content":"你好"}]}'
{"id":"chatcmpl-b7dc941faf17ec21","object":"chat.completion","created":1781082389,"model":"qwen3","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\n嗯,用户发来的是"你好"。首先,我需要确认用户是否在测试我的反应,或者只是普通问候。作为AI助手,我应该保持友好和专业的态度,同时也要注意用户的意图。用户可能只是想打招呼,或者想进行某种互动,比如询问问题、提供帮助等。\n\n接下来,我需要考虑如何回应。用户可能希望得到一个自然的回复,而不是机械式的回应。因此,我应该使用一些友好的问候,比如"你好!"或者"您好!",然后根据用户的后续输入来调整回应。同时,也要保持开放式的提问,让用户有更多互动空间。\n\n另外,要注意用户可能的深层需求。用户可能希望了解我的功能,或者想进行一些具体的帮助。因此,在回应时,应该提供足够的信息,但不要过于冗长,保持简洁明了。同时,要避免使用过于复杂的术语,确保用户容易理解。\n\n最后,确保回应符合中文的表达习惯,使用自然的口语化表达,避免生硬或机械的回复。这样用户会觉得更亲切,也能更好地与我互动。\n</think>\n\n你好!有什么可以帮助你的吗?😊","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null},"logprobs":null,"finish_reason":"stop","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":9,"total_tokens":245,"completion_tokens":236,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
root@pc:~/ai-newapi#
root@pc:~/ai-newapi#四、配置 New-API
访问(我的服务器ip地址是192.168.5.101):
bash
http://192.168.5.101:3000第一次会进入初始化页面。
4.1 创建管理员账号
随便创建一个即可
4.2添加渠道
进入:
渠道管理
→ 新建渠道类型选择:
OpenAI名称:
bash
#随便填一个,比如
qwen3test密钥(API Key):
bash
# 随便填一个,比如
sk-test因为 vLLM 默认不校验。
API地址:
bash
http://vllm:8000
# 如果vllm和new api不是在同一个compose里,就要改成
http://192.168.5.101:8000模型:
填--served-model-name参数指定的模型名
qwen3分组:
选择默认default即可
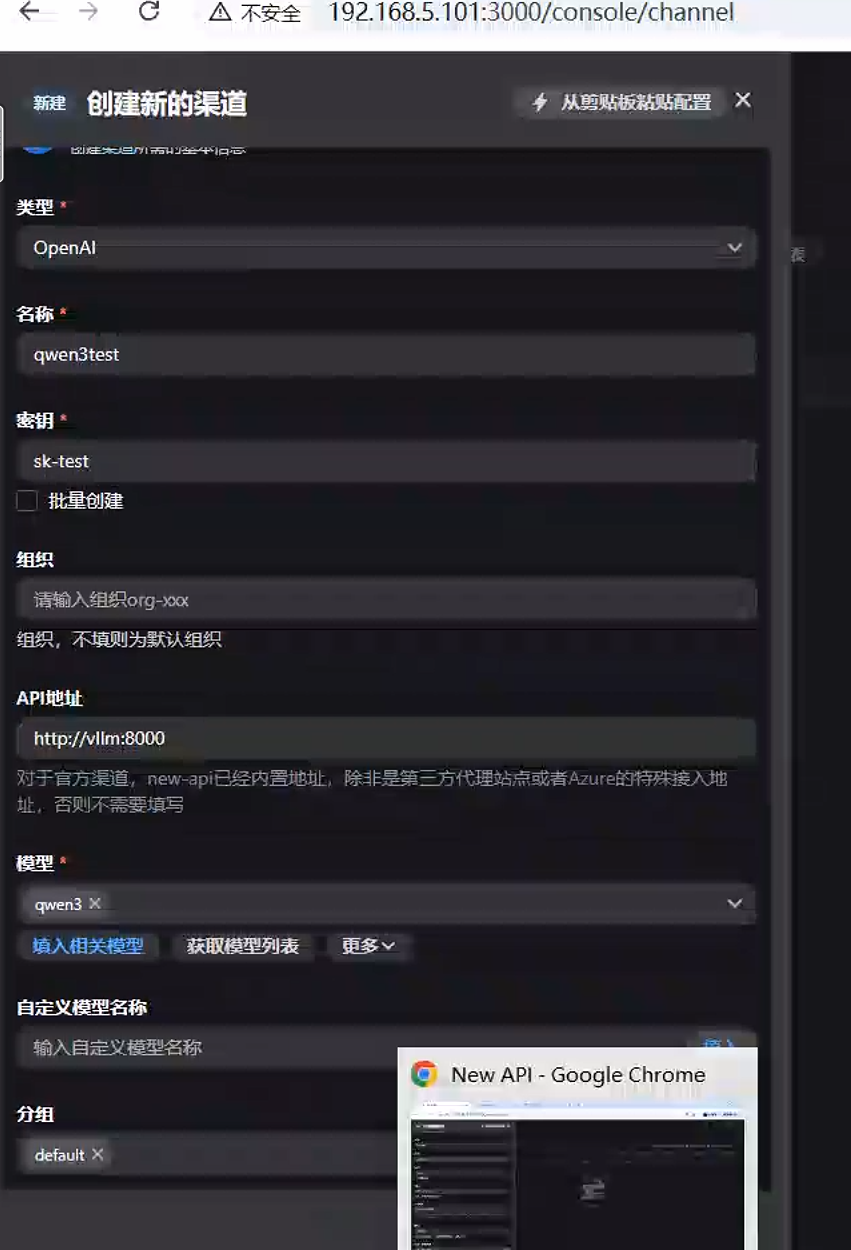
4.3 测试渠道
New-API 后台通常会有:
测试渠道点击测试。
如果成功:
说明:
New-API
↓
vLLM已经打通。
4.4 创建令牌
进入:
令牌管理创建:
测试用户得到:
sk-xxxxxxxx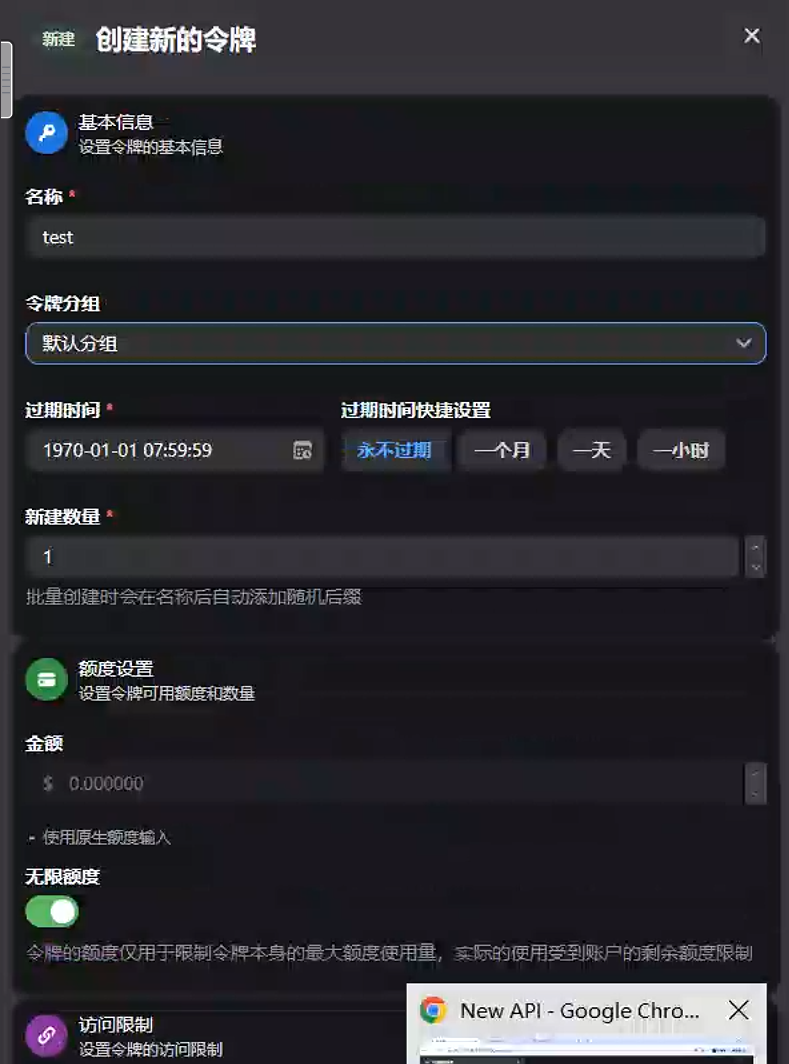
4.5 测试 token平台的API
例如:
bash
curl http://192.168.5.101:3000/v1/models \
-H "Authorization: Bearer 令牌key"应该返回:
{
"data":[
{
"id":"qwen3"
}
]
}测试聊天
bash
curl http://你的IP:3000/v1/chat/completions \
-H "Authorization: Bearer 令牌key" \
-H "Content-Type: application/json" \
-d '{
"model":"qwen3",
"messages":[
{
"role":"user",
"content":"你好"
}
]
}'五、配置 OpenWebUI
如果只是通过curl 发送信息调用模型太过麻烦,这里部署OpenWebUI调用New Api平台的URL和令牌访问大模型。
5.1创建OpenWebUI账户
随便创建一个即可
5.2 添加大模型
如果 OpenWebUI 没自动识别:
进入:
bash
管理员设置
→ 外部连接
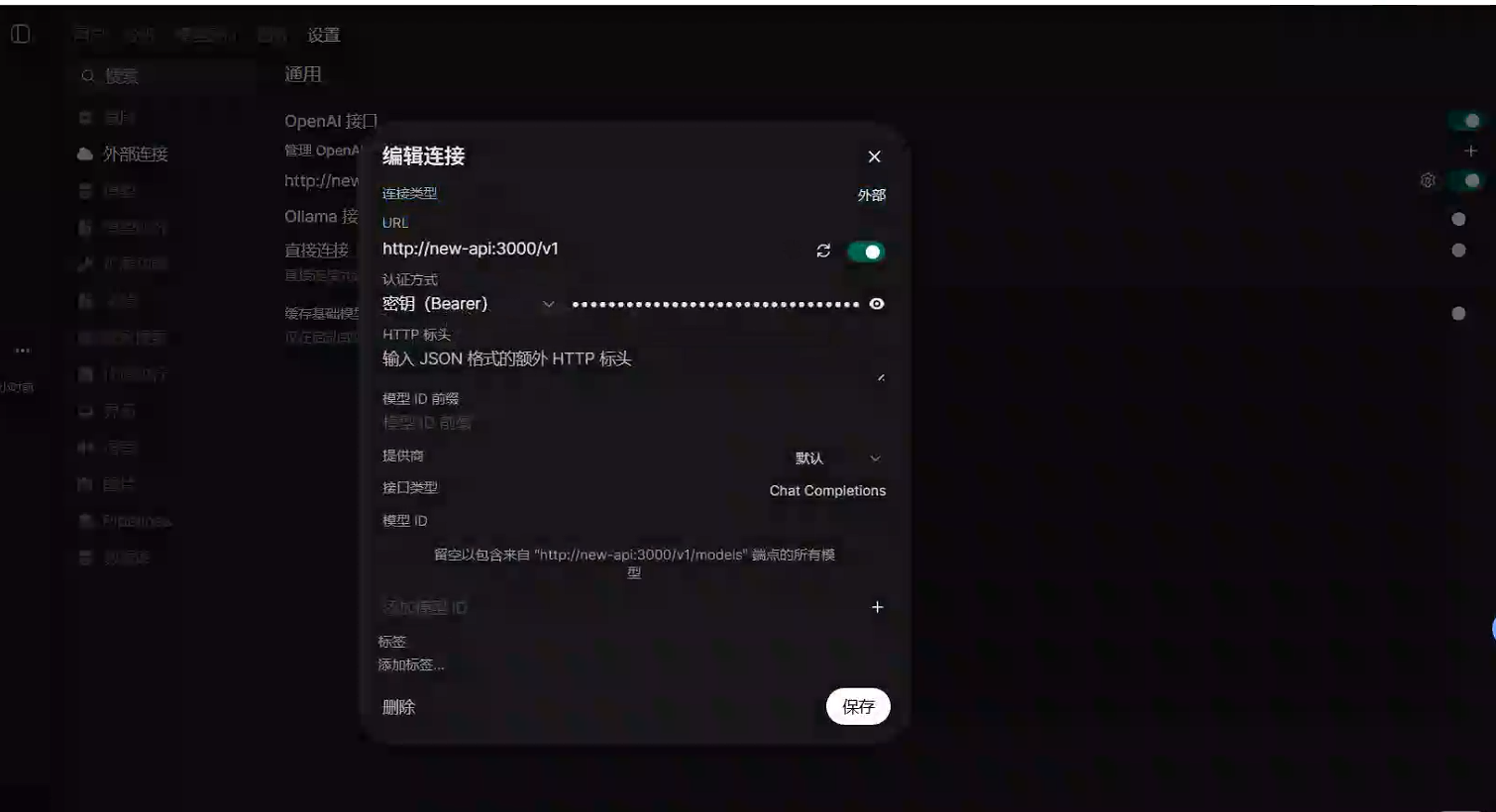
→ OpenAI API填写:
API URL:
http://new-api:3000/v1API Key:
sk-xxxxxxxx保存。
刷新页面。
手动配置URL和令牌(这里的密钥就是令牌),如果OpenWebUI和New Api不在一个compose组,URL中的new-api就需要改成ip地址
5.3 测试大模型
5.4 查看New Api面板