MySQL 里建自增主键,常见写法就是 bigint primary key auto_increment。建表时声明好,插入时不传 id,数据库自己给下一个值。很多业务表一开始都是这么写的。
到 KingbaseES 之后,第一反应通常还是先试 auto_increment。这里没有绕开它,直接在当前环境里跑了一遍。结果是能建表,也能自动生成 1、2。不过这只能说明当前版本能识别这个兼容写法,不能把所有自增场景都压到 auto_increment 上。
先看当前连接。库是 app_db,用户是 app_user,版本是 KingbaseES V009R001C010。刚连进去时,current_schema() 返回 public,search_path 是 "$user", public。后面的对象统一放到 app_schema,所以会话里先执行:
vbnet
set search_path to app_schema, public;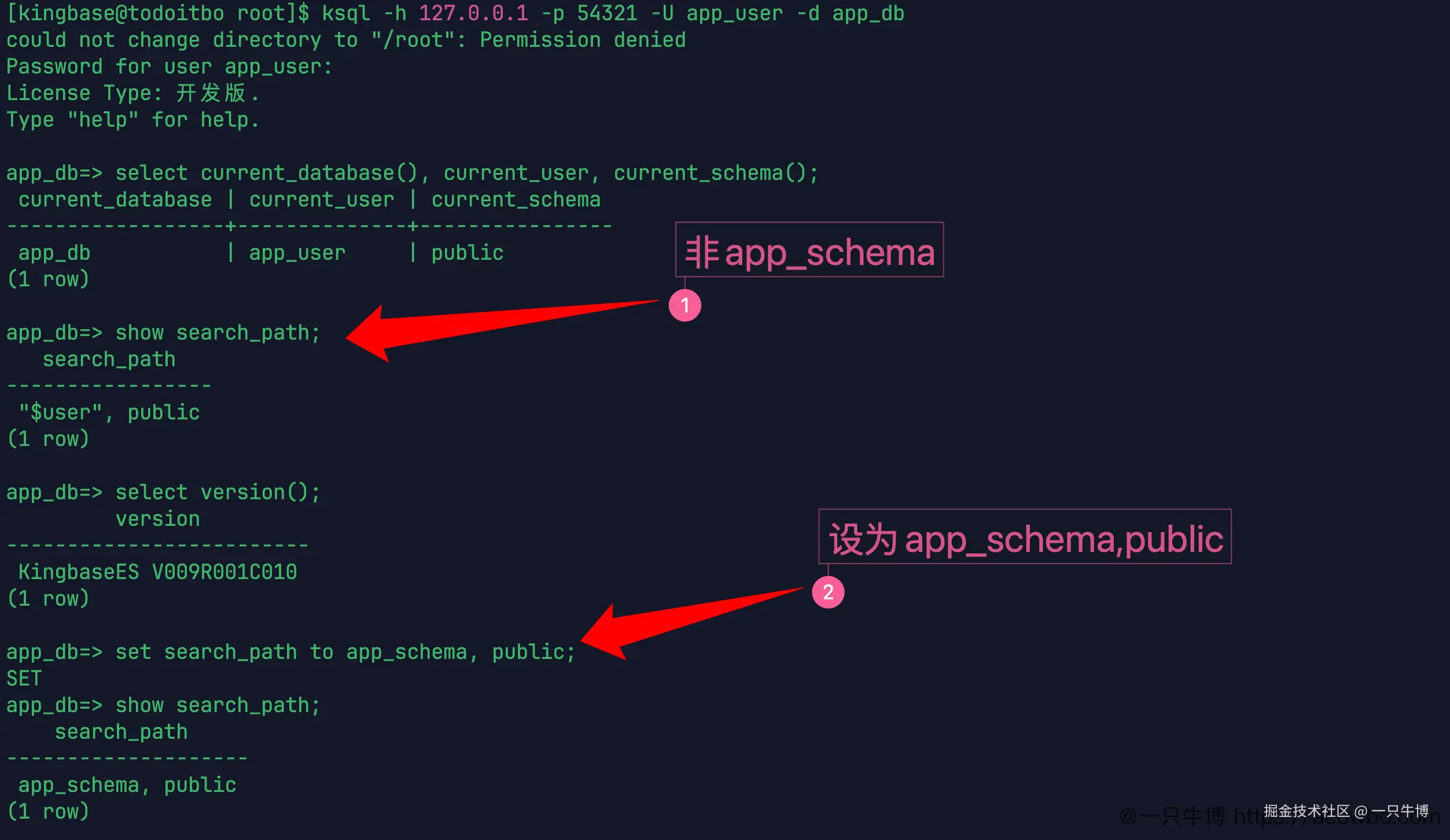
自增实验会创建表,也会创建序列。先把 schema 固定住,后面看 \d 输出时更清楚,不会一会儿在 public,一会儿在 app_schema。
auto_increment 在当前环境里能跑
先试最熟悉的 MySQL 写法:
sql
create table app_schema.t_mysql_auto_increment(
id bigint primary key auto_increment,
name varchar(50)
);建表成功,插入时不写 id:
sql
insert into app_schema.t_mysql_auto_increment(name)
values ('mysql-style-a'), ('mysql-style-b')
returning id, name;返回结果是 1 和 2。
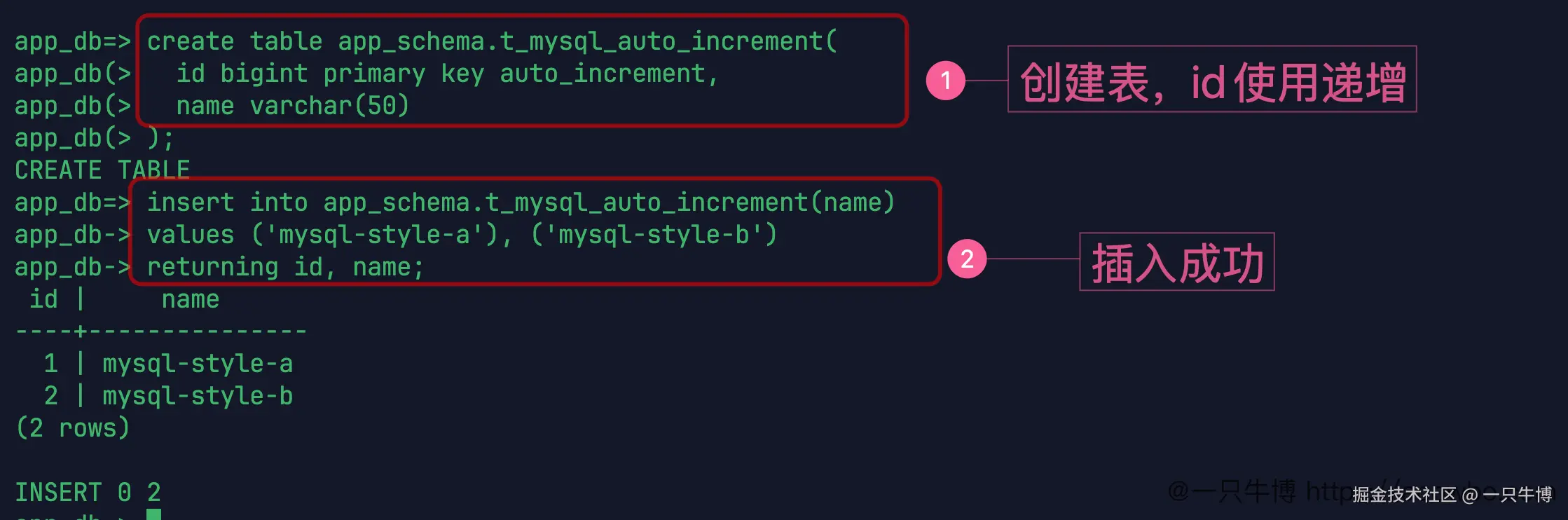
这个结果先放在前面:当前 V009R001C010 环境下,auto_increment 可以完成自增效果。简单表从 MySQL 迁过来时,这种写法不一定马上报错。
但如果到这里就停,后面还是会卡。表能建,只是第一步。后面还要看表结构里到底多了什么,默认值怎么写,序列对象是否能单独操作。否则换成迁移工具生成的 DDL、换成历史数据导入、换成手动修复主键时,还是不知道该查哪里。
所以 auto_increment 这里先当作兼容写法记下来:能用,但还要继续看 KingbaseES 自己常见的写法。
这里也不建议马上把所有表都改成 auto_increment。如果项目已经有一大批 MySQL DDL,先验证兼容写法可以省时间;如果是新建 KingbaseES 表,还是要看看后面几种写法。尤其是脚本需要多人维护时,字段类型、默认值、序列名这些信息越明确,后面排查越省事。
迁移场景里还有一个实际问题:DDL 不一定全靠人手写。ORM、数据库迁移工具、旧系统导出的建表语句,都可能生成不一样的自增写法。只验证 create table 能不能执行还不够,最好再插入几条数据,看返回的主键值,再用 \d 看列默认值。这样后面发现主键值不对时,至少知道该从表结构还是序列对象查起。
serial 是最短的自增写法
接着用 serial 建一张表:
sql
create table app_schema.t_serial_demo(
id serial primary key,
name varchar(50) not null
);插入三行数据,不写 id:
sql
insert into app_schema.t_serial_demo(name)
values ('serial-a'), ('serial-b'), ('serial-c')
returning id, name;结果返回 1、2、3。
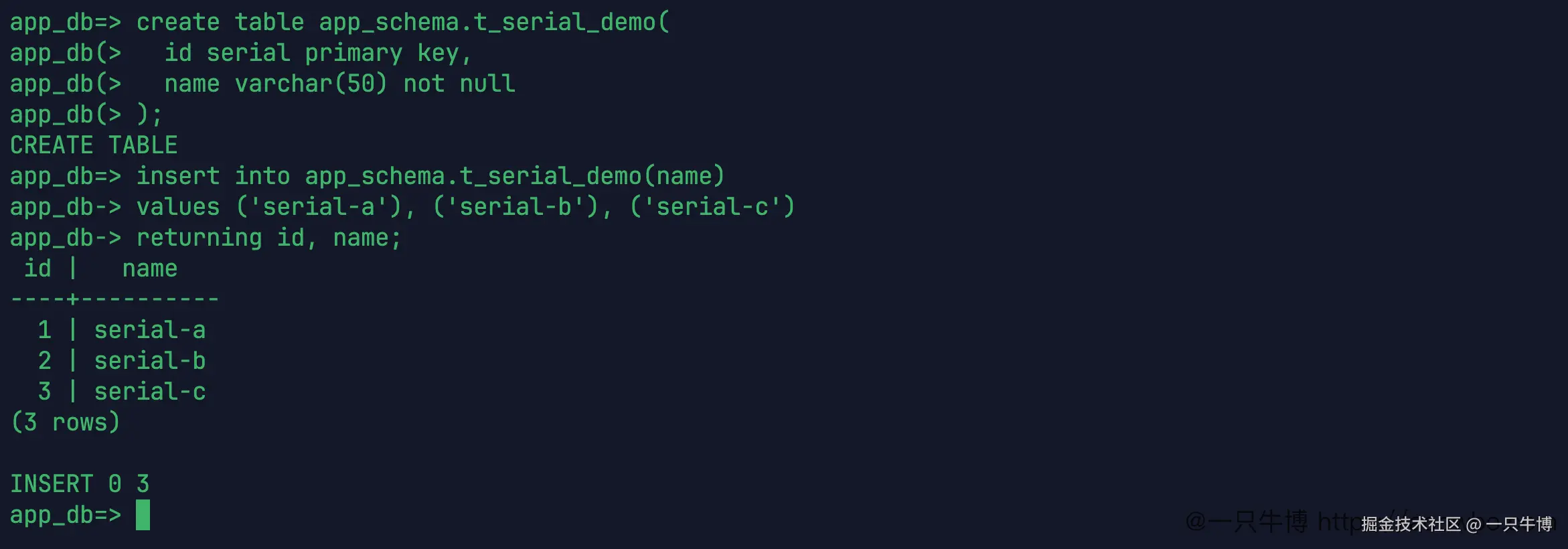
从插入结果看,serial 和前面的 auto_increment 没什么区别,都是不传 id 也能返回递增值。差别在表结构里。继续看 \d 输出,id 的类型是 integer,默认值是:
php
nextval('t_serial_demo_id_seq'::regclass)这条默认值比插入结果更重要。插入结果只能说明数字变大了,默认值能说明数字从哪里来。t_serial_demo_id_seq 是数据库创建出来的序列对象,id 列每次需要默认值时都会调用它。
这个细节在导入数据时会用上。比如先导入一批带 id 的旧数据,表里最大 id 已经到了 5000,但序列还停在很小的值,下一次插入就可能撞主键。处理这类问题时,方向不是改 id 列类型,而是把对应序列调到正确位置。
所以看 serial 时,不要只记住"它能自增"。更该记住的是它生成了一个 integer 字段,并且把字段默认值指到了一个序列。这个判断来自表结构,不是猜的。
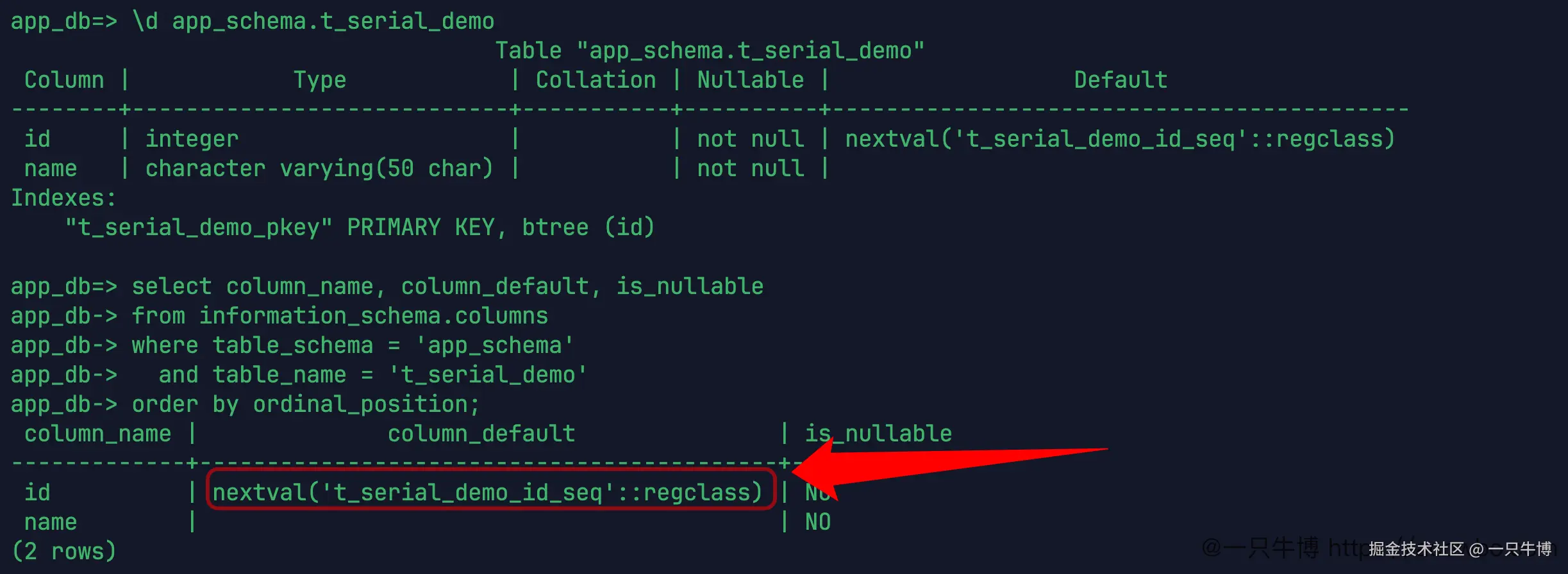
这里已经不是单纯的"列属性"了。serial 建表后,列类型落成了 integer,默认值落成了 nextval(...)。插入数据时没有传 id,数据库就执行这个默认值,从对应的序列里取下一个数。
以后遇到自增值不对,不能只盯着表字段看。表结构里的 nextval('t_serial_demo_id_seq'::regclass) 已经把线索给出来了,序列名就在这里。
serial 对应 integer。如果原来的 MySQL 表用的是 bigint auto_increment,下一步就该看 bigserial。
bigserial 更接近 bigint auto_increment
bigserial 的写法和 serial 一样短:
sql
create table app_schema.t_bigserial_demo(
id bigserial primary key,
name varchar(50) not null
);插入两行后,返回 1、2。继续看结构,id 是 bigint,默认值是:
php
nextval('t_bigserial_demo_id_seq'::regclass)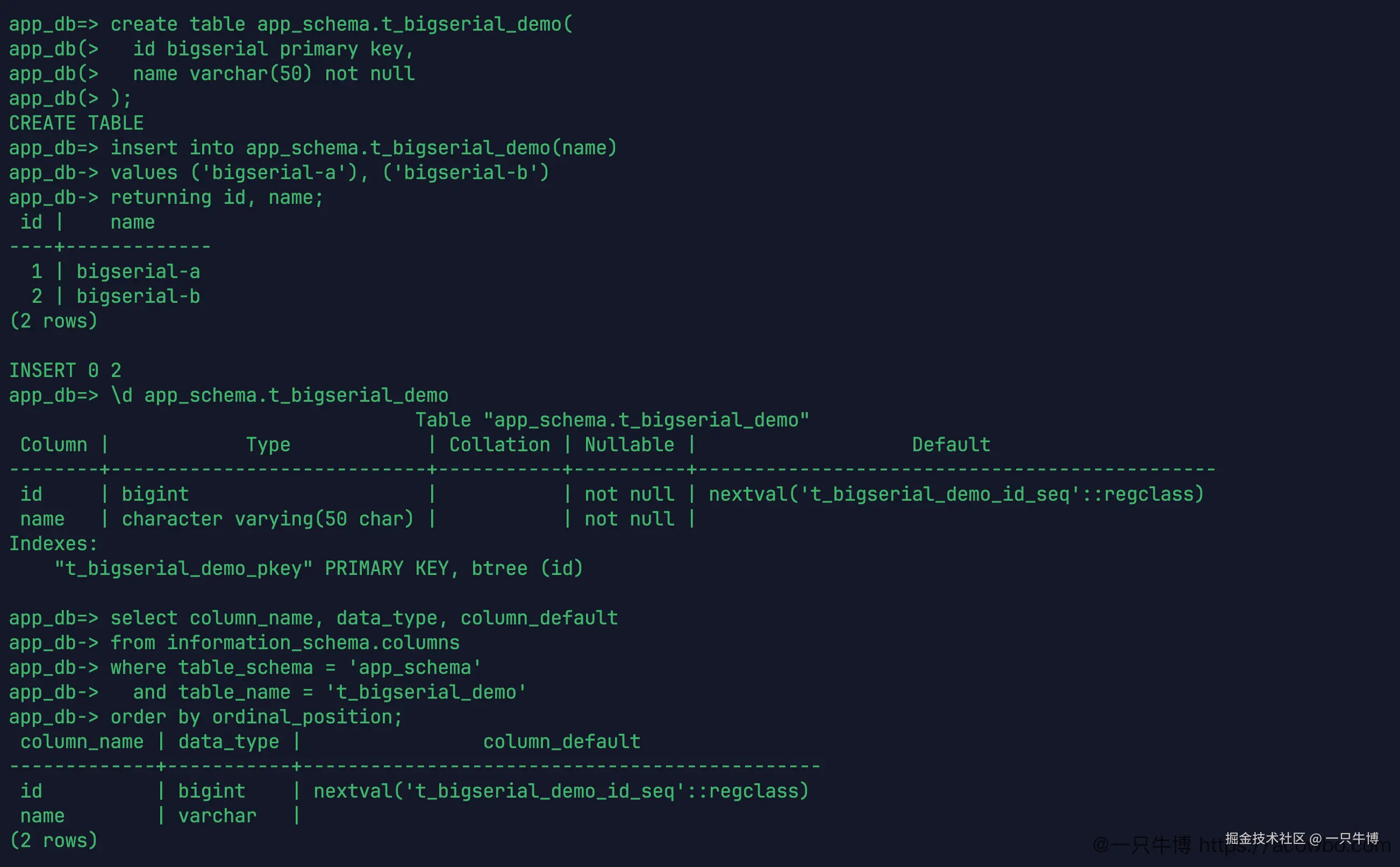
bigserial 和 serial 的差别主要在类型:一个是 bigint,一个是 integer。两者的默认值都走 nextval(...)。如果原表是 bigint auto_increment,bigserial 更贴近原来的字段范围。
它的好处是短,缺点也是短。序列名由数据库按规则生成,起始值、步长、缓存这些设置都没有在建表语句里展开。实验里生成的序列名是 t_bigserial_demo_id_seq,小表够用;建表脚本如果要统一命名和参数,就得把 sequence 单独写出来。
这里先记住一条就够:bigserial 不是把自增逻辑藏没了,只是替你把 sequence 创建好了。
实际写表时,bigserial 的可读性还算不错,至少一眼能看出这是一个 bigint 自增主键。问题出在后续管理:序列对象什么时候创建、名字叫什么、缓存是多少,建表语句本身没有全部展开。小项目不一定在意这些,迁移脚本和初始化脚本会更在意。
如果只是日常开发建表,bigserial 已经够直白。需要换成显式 sequence 的,通常是那些要进版本库、要反复执行、要在多套环境里跑的脚本。脚本一旦进了发布流程,少写几行 SQL 的收益就没那么大了,能看懂、能回滚、能定位对象更重要。
显式 sequence 把自增拆开了
显式写 sequence 会比 bigserial 多几行,但可读性更强。先创建序列:
sql
create sequence app_schema.t_seq_demo_id_seq
start with 100
increment by 1
minvalue 100
no maxvalue
cache 1;再建表,让 id 默认调用这个序列:
sql
create table app_schema.t_seq_demo(
id bigint primary key default nextval('app_schema.t_seq_demo_id_seq'),
name varchar(50) not null
);插入三行数据,返回 100、101、102。currval 查到的当前序列值也是 102,继续插入一行,得到 103。

这时自增主键被拆成两段:
sql
sequence:负责产生数字
table column default:负责在插入时调用 sequence序列叫什么、从多少开始、每次加多少,都在 DDL 里。比 bigserial 啰嗦,但排查时少猜一步。
这种写法在导入历史数据时更好处理。比如原表已经有数据,下一次插入不能再从 1 开始,就需要把序列调到当前最大主键之后。显式 sequence 至少把操作对象摆在明面上。
示例里 nextval 写了完整的 app_schema.t_seq_demo_id_seq。多 schema 环境里,完整名字比裸序列名更省心。
显式 sequence 还有一个好处:看 SQL 时能知道主键从哪里开始。示例里故意从 100 开始,就是为了让结果和前面的 1、2、3 区分开。插入后返回 100、101、102,说明起始值确实生效;再插一条得到 103,说明表字段默认值和序列已经接上。
nextval 会推进序列
sequence 不是只有表插入时才会动。手动调用 nextval,它也会往前走:
csharp
select nextval('app_schema.t_seq_demo_id_seq') as next_id;前面已经插到了 103,手动调用后得到 104。此时再查 currval,当前值也是 104。继续插入一条表数据,返回 105。
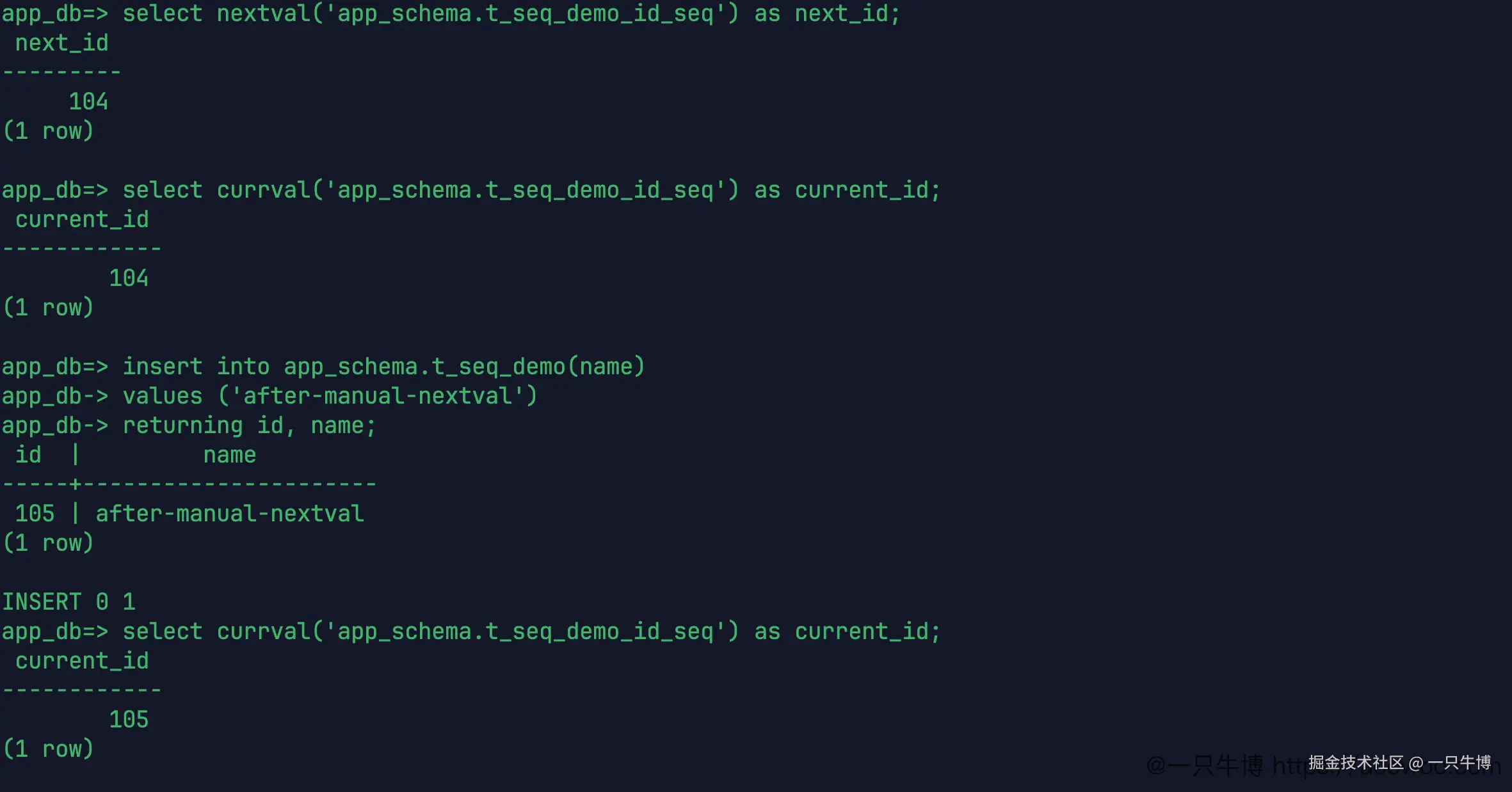
这个输出能说明一个常见现象:自增主键不保证连续。序列被取过一次,下一个值就往后走一次。手动取号会这样,回滚、缓存、批量导入也可能让数字中间空出来。
因此,自增 id 适合当内部主键,不适合拿来当必须连续的业务编号。订单号、流水号、票据号要单独设计。
看到 103 后面变成 105,不用先怀疑数据丢了。先查有没有调用过 nextval,再看事务和导入过程。
这也是自增主键和业务编号要分开的原因。内部主键只要唯一、稳定、方便关联就够了;业务编号经常还要带日期、地区、渠道、流水位数,甚至还要满足人工对账习惯。把这些要求压到自增 id 上,后面会很别扭。
在 MySQL 里也会遇到类似情况,只是平时不一定去看底层生成器。到了 KingbaseES,sequence 是明面上的对象,正好把这件事讲清楚:数字能增长,不代表它必须连续。
identity 是另一套更标准的写法
除了 sequence 和 serial/bigserial,KingbaseES 还支持 identity 列。先看 generated by default as identity:
sql
create table app_schema.t_identity_default_demo(
id bigint generated by default as identity primary key,
name varchar(50) not null
);不写 id 插入两行,返回 1、2。再手动插入 id = 1000,也能成功。表结构里,id 的默认规则显示为 generated by default as identity。
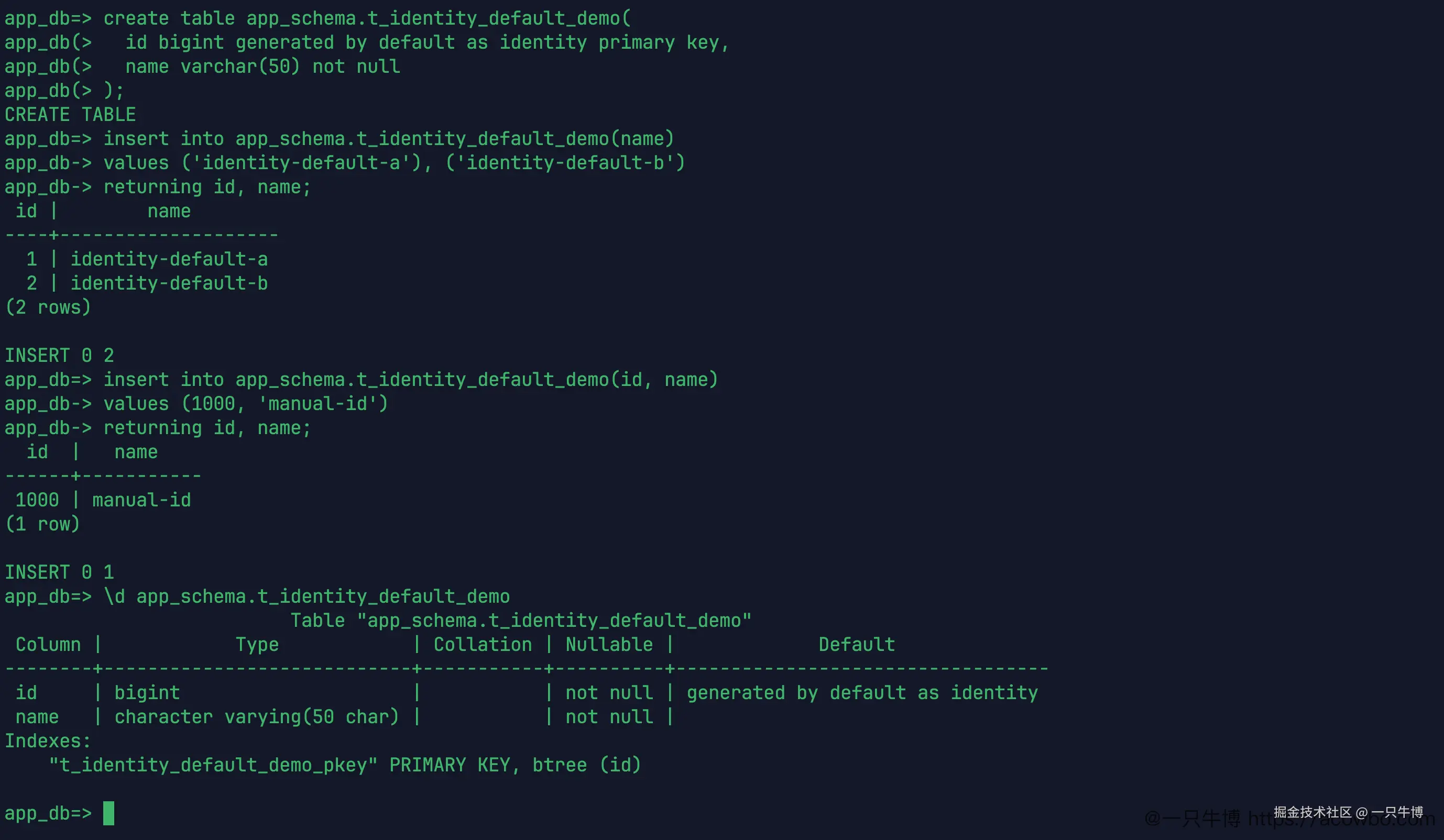
by default 的表现比较宽松:不传 id 时数据库生成,传了 id 也接受。导入历史数据时,这种行为会方便一些。
这类写法看起来不像 nextval(...) 那么直白,但表结构已经把规则写出来了:generated by default as identity。如果只关心建表语句紧凑,identity 比显式 sequence 清爽;如果要单独管理生成器,显式 sequence 更直接。
再看 generated always as identity:
sql
create table app_schema.t_identity_always_demo(
id bigint generated always as identity primary key,
name varchar(50) not null
);不写 id 插入两行,同样返回 1、2。但手动插入 id = 2000 时会报错:
sql
ERROR: cannot insert into column "id"
DETAIL: Column "id" is an identity column defined as GENERATED ALWAYS.
HINT: Use OVERRIDING SYSTEM VALUE to override.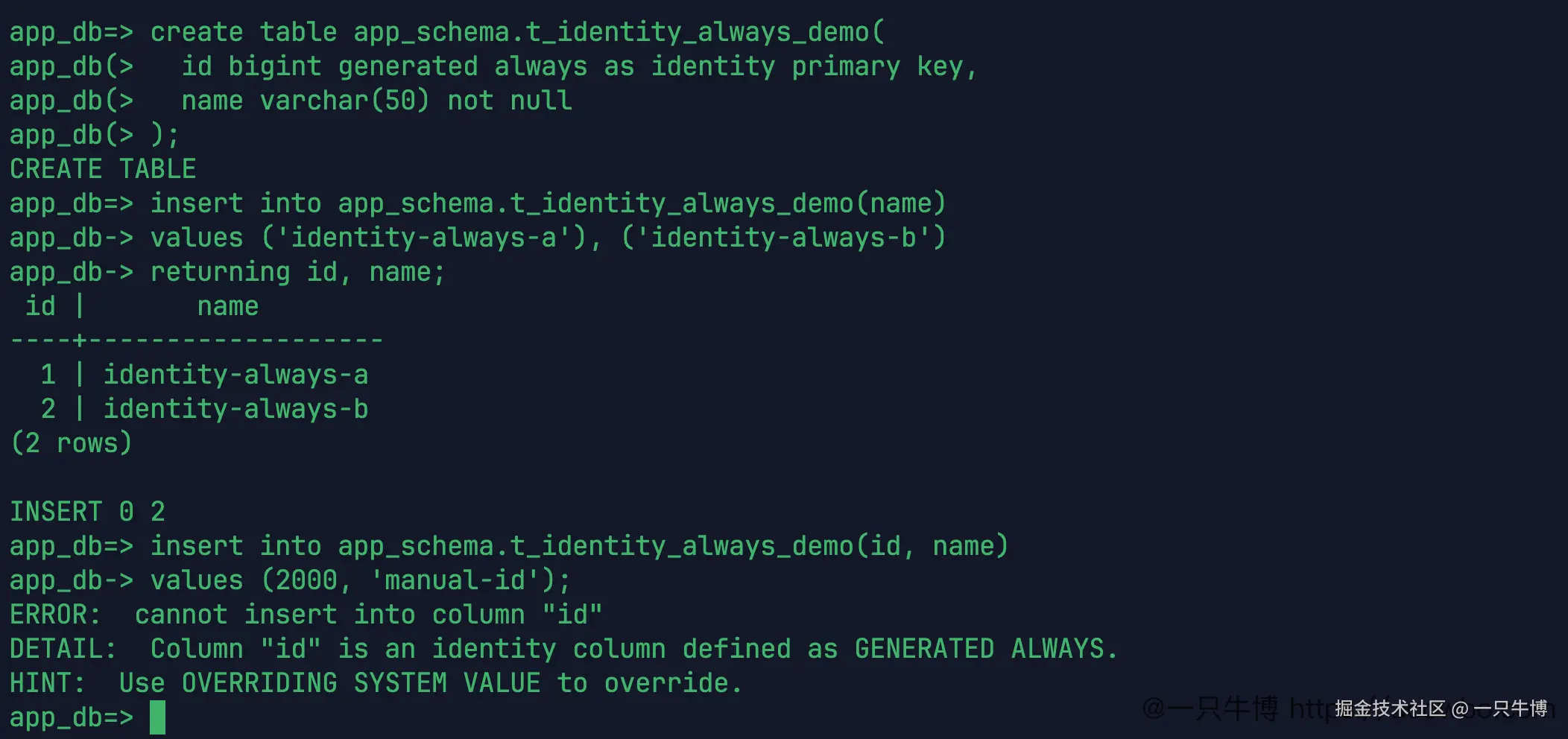
两种 identity 的差别可以直接按插入行为记:
csharp
generated by default:默认自动生成,允许手动给值
generated always:默认自动生成,手动给值会被拦住always 更硬,手动插入要额外写覆盖语法;by default 更松,迁移数据时少一道限制。选哪个,要看是否允许外部 SQL 显式写主键。
identity 把自增规则写在列定义里,显式 sequence 把生成器单独拿出来。两种写法都能用,差别主要在管理方式。
从这组实验看,identity 两种模式都能跑。by default 适合需要保留历史主键的导入场景,always 适合不希望普通插入语句随便指定主键的表。哪种更合适,不看名字,看插入规则能不能接受。
如果表会经常做数据修复、临时补数、历史导入,by default 少一些限制;如果表的主键必须完全交给数据库生成,always 更符合这种约束。报错里的 OVERRIDING SYSTEM VALUE 也说明了,严格模式下不是完全不能覆盖,而是要显式声明覆盖行为。
更像业务表的写法
如果只是写一个练习表,bigserial 很省事:
bash
id bigserial primary key建表脚本需要长期维护时,可以直接写 sequence。下面这个表只放几个常见字段:自增主键、业务编号、金额、创建时间。
sql
create sequence app_schema.t_order_demo_id_seq
start with 1
increment by 1
cache 20;
create table app_schema.t_order_demo(
id bigint primary key default nextval('app_schema.t_order_demo_id_seq'),
order_no varchar(64) not null,
amount numeric(12, 2) not null,
created_at timestamp not null default current_timestamp
);插入两条数据后,id 是 1、2,order_no 是业务编号,created_at 自动取当前时间。结构里也能看到 id 的默认值来自 t_order_demo_id_seq。
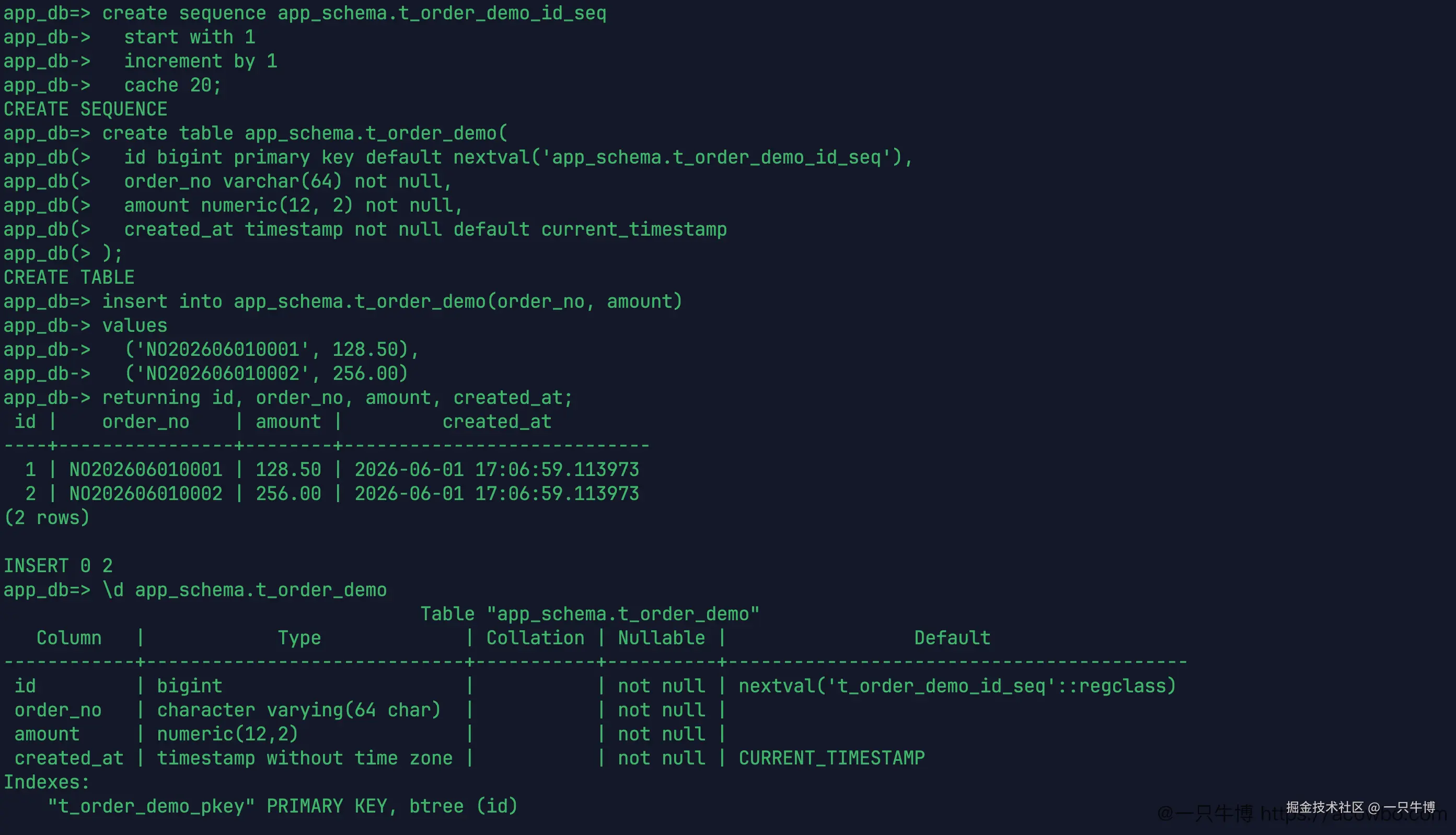
这里的 id 由 t_order_demo_id_seq 生成,order_no 仍然单独保存业务编号。两者不要混用。cache 20 也写在序列定义里,后面想改缓存时知道该改哪个对象。
临时表、验证表,用 bigserial 少写几行很正常。迁移 MySQL 旧表时,如果 auto_increment 在目标环境里能跑,也没必要为了改写而改写。到了需要长期留存的建表脚本,显式 sequence 或 identity 至少能让生成规则留在 DDL 里。
created_at 这里也给了默认值。插入订单数据时只传 order_no 和 amount,返回结果里同时有 id 和 created_at。主键来自 t_order_demo_id_seq,创建时间来自 current_timestamp,两个默认值都在这次插入里生效了。
写表结构时怎么选
把上面的实验压成几条:
sql
auto_increment 当前版本能跑,迁移 MySQL 表时先验证
serial integer + sequence,适合小实验
bigserial bigint + sequence,更接近 bigint auto_increment
sequence + default nextval 名字、起始值、缓存都能自己控制
identity 写在列定义里的自增规则,分 by default 和 always如果只是从 MySQL 迁一批简单表,auto_increment 能跑当然省事;如果开始写新的 KingbaseES 建表脚本,bigserial 和显式 sequence 都应该会用。bigserial 快,显式 sequence 清楚,identity 则适合想把生成规则放进列定义的场景。
这几个写法不用急着分出高低。当前这套实验里,auto_increment、serial、bigserial、显式 sequence、identity 都能完成"不传 id 自动生成值"。区别不在第一条插入语句,而在表结构、导入历史数据、手动覆盖主键、后续排查时暴露出来。
后面真遇到主键问题,先看两处:表结构里的 default,以及它引用的 sequence 或 identity 规则。能查到这一步,自增主键就不再只是一个建表关键字了。