💡一、什么是树?
数据结构中的"树",是对现实世界中树的抽象和简化:
- 根节点:对应现实中的树根,是一切的起点
- 边:对应现实中的树枝,连接两个节点
- 叶子节点:对应现实中的树叶,是树的末端
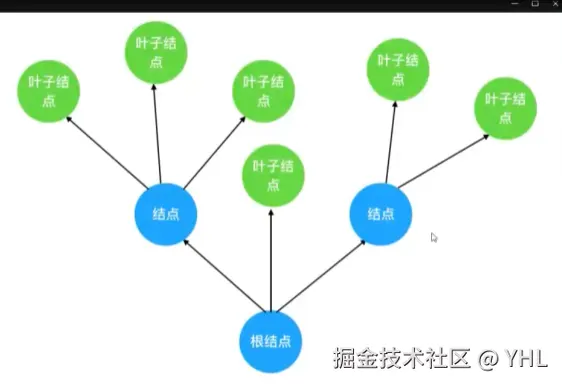
把现实中的树倒过来看,就是数据结构中树的样子:从根节点开始,每个节点延伸出一个或多个子节点,层层向下,直到叶子节点为止。
css
A ← 根节点(第 1 层)
/ \
B C ← 第 2 层
/ \ / \
D E F G ← 第 3 层(叶子节点)🧠关键概念速览
| 概念 | 说明 |
|---|---|
| 层次 | 根节点为第 1 层,其子节点为第 2 层,依此类推 |
| 高度 | 叶子节点高度为 1,每向上一层 +1 |
| 度 | 一个节点拥有的子树数量 |
| 叶子节点 | 度为 0 的节点,即没有子节点的节点 |
| 深度 | 从根节点到目标节点的路径长度 |
⚖️二、二叉树
📚定义
二叉树 是每个节点最多有两个子节点的树。它的定义天然适合用递归来描述:
一棵二叉树要么是空树,要么由根节点 、左子树 和右子树三部分组成,且左右子树本身也都是二叉树。
这里有两点值得注意:
- 左右严格区分:二叉树中左子树和右子树的位置是严格约定的,不能随意交换。左右互换后是两棵不同的二叉树。
- 度 ≤ 2 不等于二叉树:二叉树不能简单定义为"每个节点度最大为 2 的树",因为普通树不区分左右,而二叉树区分。
📚在 JavaScript 中表示二叉树
一个二叉树节点由三部分构成:数据域 + 左子节点引用 + 右子节点引用。
js
function TreeNode(val) {
this.val = val;
this.left = this.right = null; // 左右子节点初始为空
}构建一棵具体的二叉树:
js
const tree = {
val: 'A',
left: {
val: 'B',
left: { val: 'D', left: null, right: null },
right: { val: 'E', left: null, right: null }
},
right: {
val: 'C',
left: { val: 'F', left: null, right: null },
right: { val: 'G', left: null, right: null }
}
};这棵二叉树的结构如下:
css
A
/ \
B C
/ \ / \
D E F G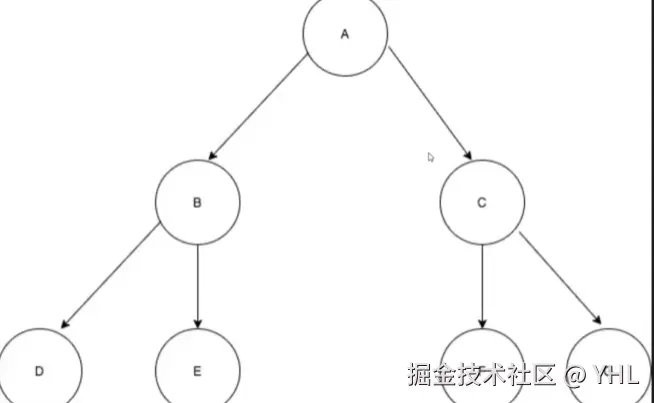
📚多叉树的表示
如果不是二叉树,而是一个节点可以有任意多个子节点的情况,可以用 children 数组来表示:
js
const tree = {
value: 'A',
children: [
{
value: 'B',
children: [
{ value: 'D', children: [] },
{ value: 'E', children: [] }
]
},
{
value: 'C',
children: [
{ value: 'F', children: [] },
{ value: 'G', children: [] }
]
}
]
};两种表示方式的选择取决于实际场景:二叉树用 left/right 语义更清晰,多叉树用 children 数组更灵活。
🎯三、二叉树的遍历
遍历是树最核心的操作。按照访问根节点的时机不同,分为四种遍历方式。递归遍历中,左右子树的访问顺序永远是先左后右,区别只在于根节点何时被访问。
✨3.1 前序遍历(根 → 左 → 右)
先访问根节点,再递归访问左子树,最后递归访问右子树。
js
function preorder(root) {
if (!root) {
return; // 退出条件:空节点
}
console.log(root.val); // 先访问根
preorder(root.left); // 再访问左子树
preorder(root.right); // 最后访问右子树
}对示例树调用 preorder(tree),输出顺序为:A → B → D → E → C → F → G。
动态演示
p1-jj.byteimg.com/tos-cn-i-t2...
✨3.2 中序遍历(左 → 根 → 右)
先递归访问左子树,再访问根节点,最后递归访问右子树。
js
function inorder(root) {
if (!root) {
return; // 退出条件:空节点
}
inorder(root.left); // 先访问左子树
console.log(root.val); // 再访问根
inorder(root.right); // 最后访问右子树
}输出顺序为:D → B → E → A → F → C → G。
二叉搜索树的中序遍历结果是有序的,这是中序遍历的一个重要特性。
✨3.3 后序遍历(左 → 右 → 根)
先递归访问左子树,再递归访问右子树,最后访问根节点。
js
function postorder(root) {
if (!root) {
return; // 退出条件:空节点
}
postorder(root.left); // 先访问左子树
postorder(root.right); // 再访问右子树
console.log(root.val); // 最后访问根
}输出顺序为:D → E → B → F → G → C → A。
后序遍历的一个典型应用场景是删除树:先删除子节点,最后删除父节点,避免"删了父节点找不到子节点"的问题。
✨3.4 层序遍历(广度优先)
层序遍历不使用递归,而是借助队列实现逐层访问。
js
function levelorder(root) {
const queue = []; // 辅助队列
const result = []; // 存放遍历结果
if (!root) {
return result;
}
queue.push(root); // 根节点入队
while (queue.length > 0) {
const node = queue.shift(); // 队首出队
result.push(node.val); // 访问当前节点
if (node.left) {
queue.push(node.left); // 左子节点入队
}
if (node.right) {
queue.push(node.right); // 右子节点入队
}
}
return result;
}输出顺序为:A → B → C → D → E → F → G(逐层从左到右)。
✅四种遍历对比
| 遍历方式 | 访问顺序 | 实现方式 | 示例输出 |
|---|---|---|---|
| 前序 | 根 → 左 → 右 | 递归 | A B D E C F G |
| 中序 | 左 → 根 → 右 | 递归 | D B E A F C G |
| 后序 | 左 → 右 → 根 | 递归 | D E B F G C A |
| 层序 | 逐层从左到右 | 队列迭代 | A B C D E F G |
📌四、递归思想 ------ 从爬楼梯理解树状结构
树和递归是天然绑定的一对概念。递归的核心三要素:
- 自顶向下思考:把大问题拆成小问题
- 找到递归公式:每次解决的问题模式相同
- 明确退出条件:递归不能无限进行
爬楼梯问题
假设你正在爬楼梯,每次可以爬 1 阶或 2 阶。爬到第
n阶有多少种不同的方法?
这个问题从顶向下看,呈现出典型的树状结构:
scss
f(10)
/ \
f(9) f(8)
/ \ / \
f(8) f(7) f(7) f(6)
... ... ... ...
最终:
f(1) = 1 种
f(2) = 2 种- 递归公式 :
f(n) = f(n-1) + f(n-2) - 退出条件 :
n ≤ 2时,f(1) = 1,f(2) = 2
js
function climbStairs(n) {
if (n <= 2) {
return n; // 退出条件
}
let a = climbStairs(n - 1); // 最后一步走 1 阶
let b = climbStairs(n - 2); // 最后一步走 2 阶
return a + b; // 递归公式
}
console.log(climbStairs(10)); // 89
// ⚠️ 注意:这种朴素递归当 n 较大时(如 n=100)会卡死
// 原因:大量重复计算,时间复杂度 O(2ⁿ),函数调用栈也可能爆栈⚡递归的隐患
- 爆栈:每次递归调用都会在调用栈中压入一个新的函数帧。递归过深时,栈内存会被耗尽。
- 重复计算 :从上图可以看到,
f(8)被计算了两次,f(7)被计算了三次......随 n 增大,重复量呈指数级增长。
实际工程中,可以用记忆化搜索 (缓存已计算的结果)或动态规划(自底向上迭代)来优化,这里不展开。
🧩五、总结
整篇文章的核心脉络可以归纳为一条线:
现实中的树 → 数据结构的树 → 二叉树 → JS 中的表示 → 遍历(递归 / 迭代) → 递归思维(爬楼梯)- 树是递归定义的,天然适合用递归思维去理解和操作
- 二叉树的四种遍历(前序、中序、后序、层序)是树操作的基础,三种深度优先遍历的区别仅在于"访问根节点的时机"
- 递归三要素(自顶向下、递归公式、退出条件)不仅是树的解题框架,也是所有递归问题的通用心法
- 递归代码简洁优雅,但要警惕重复计算 和爆栈的风险