前言
在前面的 Agent 记忆体系里,我们已经把短期记忆和长期记忆的边界拆开了:Redis 更适合承载最近几轮消息、会话摘要、临时状态;PostgreSQL 或向量数据库更适合承载永久消息、历史记录和语义检索。
但当你真的开始做长期记忆时,会发现"把历史消息向量化之后搜回来"只是第一步,远远不够。
举个很常见的例子。用户在不同时间说过这些信息:
- "我叫小明,住在杭州。"
- "我对海鲜过敏。"
- "这次先帮我写 Q1 季度总结。"
- "你以后回答技术问题时尽量带代码示例。"
如果只做简单向量检索,系统可能能搜到"海鲜过敏"这种语义相近的信息,但面对姓名、城市、项目名、工具名、临时任务目标时,纯语义召回就容易出现漏召回或错召回。长期记忆不是简单的聊天记录归档,它要解决的是:什么值得记、记到哪一层、下次如何准确找回来。
这也是 Mem0 这类长期记忆库的价值。它把长期记忆拆成更工程化的模型:
- 分层记忆:区分用户记忆、会话记忆、Agent 记忆。
- 三路召回:结合语义检索、关键词检索、知识图谱检索。
- 统一 API :通过
add、search、getAll、update、history等接口管理记忆生命周期。
本期我们围绕 Mem0 + Node.js + Redis + LangChain 来做一篇实战教程。重点不是把 API 过一遍,而是建立一个长期记忆的心智模型:Redis 负责这轮聊天的短期上下文,Mem0 负责值得长期保留的事实和任务记忆。
读完这篇文章后,大家可以掌握:
- 为什么长期记忆不能只靠普通向量检索。
- Mem0 的三种记忆 scope 分别解决什么问题。
- 如何用
mem0ai快速完成记忆写入、搜索、更新和历史追踪。 - 如何把 Redis 短期记忆和 Mem0 长期记忆组合到一个 Agent 调用链路里。
一、Mem0 长期记忆:为 Agent 的"记得住"和"找得准"做减法
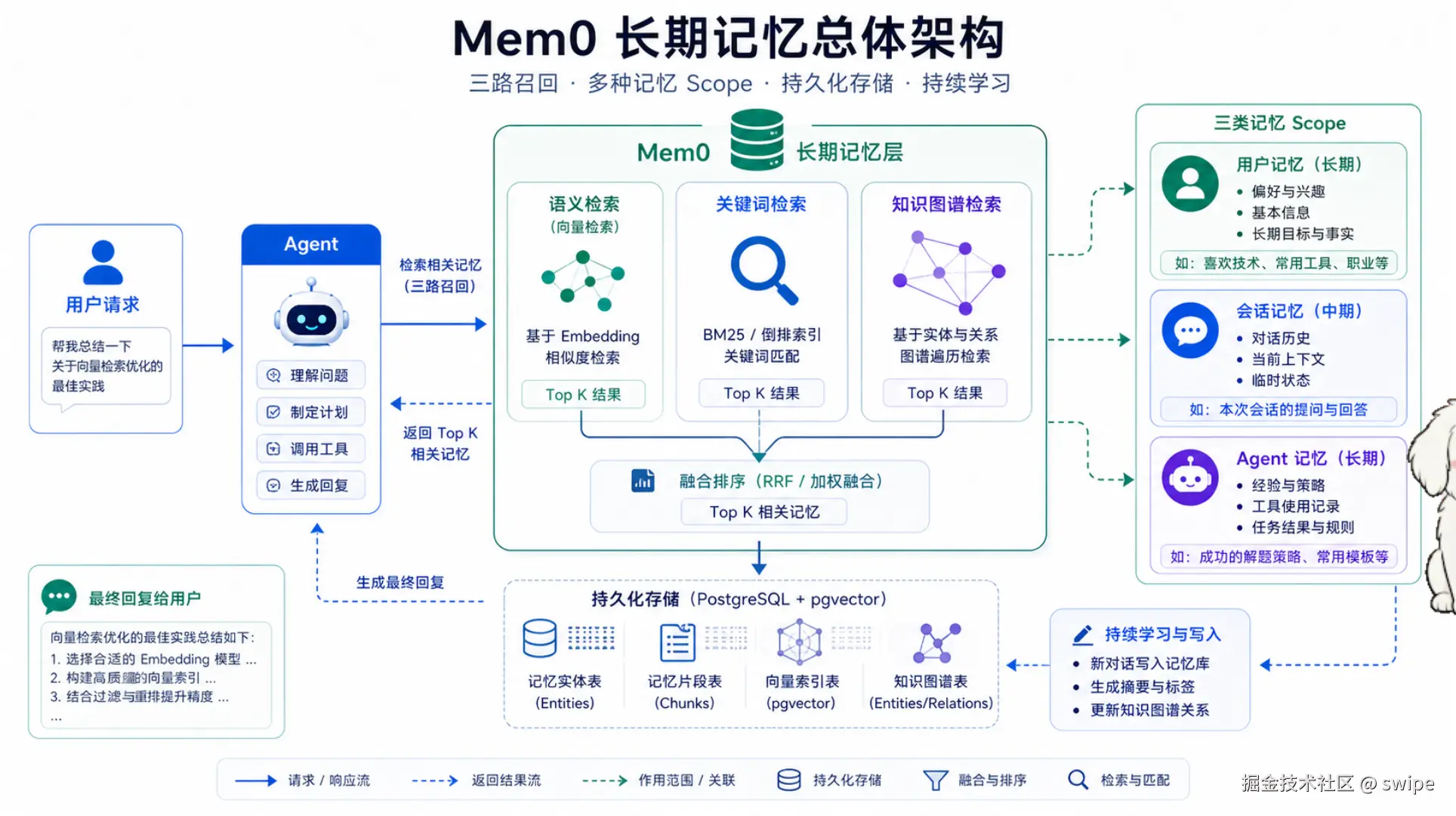
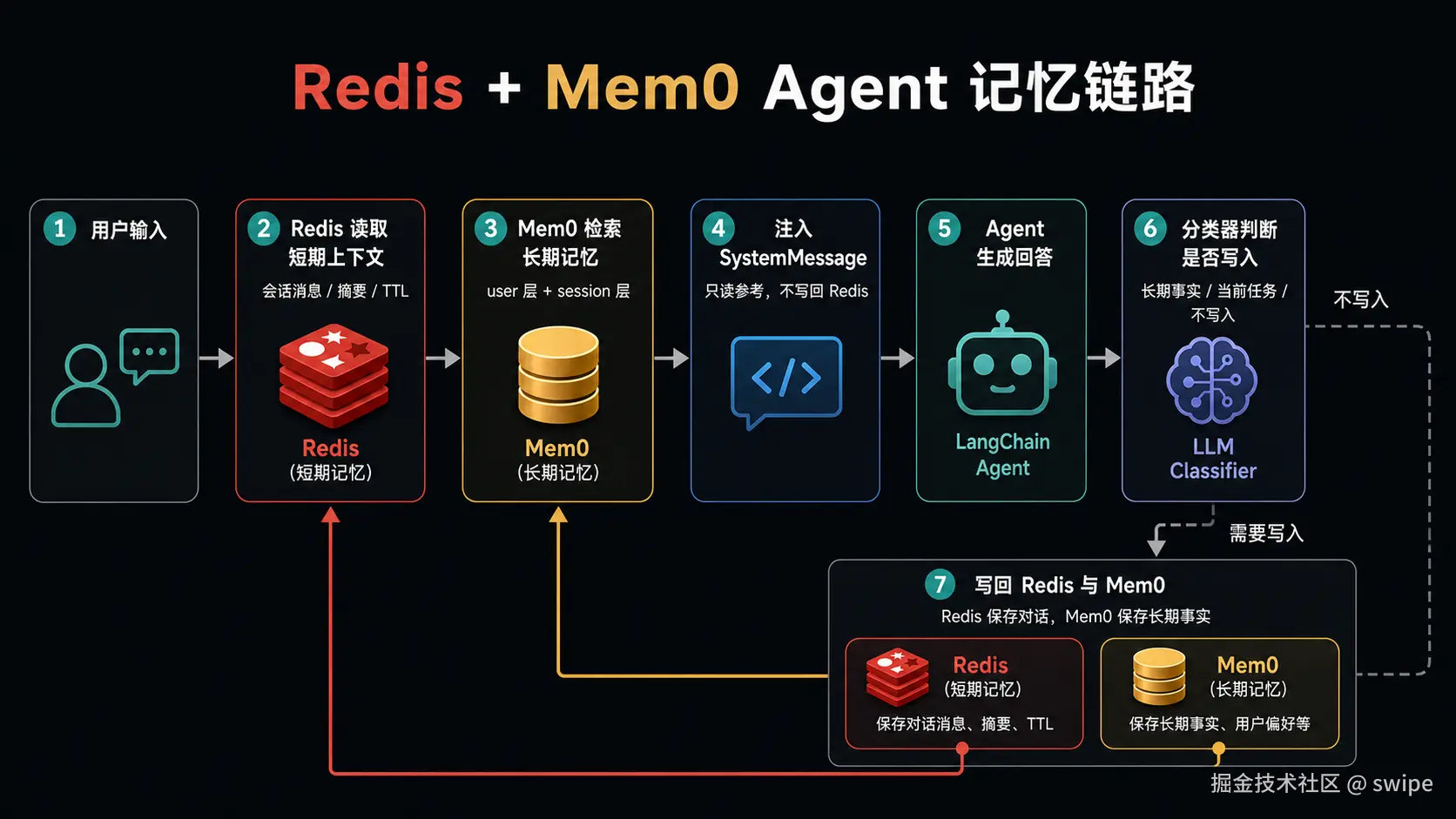 图 1:Mem0 把长期记忆抽象成分层记忆与多路召回,Agent 只需要面向统一 API 使用记忆能力。
图 1:Mem0 把长期记忆抽象成分层记忆与多路召回,Agent 只需要面向统一 API 使用记忆能力。
1.1 为什么需要 Mem0?
很多 Agent 项目刚开始做记忆时,会走一条很自然的路线:
- 把用户消息存起来。
- 调用 Embedding 模型生成向量。
- 写进向量数据库。
- 下次用户提问时做相似度搜索。
- 把召回结果塞进 Prompt。
这条路线可以跑通 Demo,但落到真实产品里会很快遇到几个问题。
第一个问题是召回方式单一。向量检索擅长处理语义相近的问题,比如"用户有什么饮食限制"和"用户不能吃什么"可以相互匹配。但它不一定擅长精确命中实体、专有名词、数字、任务 ID、工具名。比如用户说过"order-service 的 500 错误",后面问"之前那个 order-service 怎么处理",关键词检索往往比纯向量更直接。
第二个问题是记忆层级混乱。用户长期偏好、当前会话任务、Agent 自身角色设定,这些都叫"记忆",但生命周期完全不同。把它们混在一个 collection 里,后面过滤、清理和复用都会变复杂。
第三个问题是记忆生命周期难管理。一条记忆可能需要查看、更新、删除,也可能需要追踪历史变更。如果从零实现,这些能力很容易散落在业务代码里。
Mem0 解决的不是"帮你存几条文本"这么简单,而是把长期记忆做成一个可复用的系统组件。它把写入、检索、范围过滤、结果排序和记忆管理封装在统一接口里,让 Agent 可以专注于"怎么使用记忆",而不是"怎么维护记忆系统"。
1.2 Mem0 适用场景
Mem0 更适合下面几类场景。
-
个性化 Agent 用户的姓名、城市、职业、偏好、禁忌、常用工具栈,都需要跨会话持续生效。
-
任务型 Agent 当前任务目标、执行进度、临时决策、待办事项,需要在一个 run 或 thread 内保持连续。
-
多 Agent 系统 不同 Agent 有不同角色设定、回答风格、能力边界,应该有各自独立的 Agent 记忆。
-
长期对话产品 用户可能隔几天回来继续聊,上次的重要事实仍然需要被找回。
-
需要记忆治理的产品 记忆不只是写入,还需要查询、更新、删除和追踪历史。
1.3 Mem0 核心原理
可以把 Mem0 理解成 Agent 的"长期记忆中枢"。它不是 Redis 那种工作台,也不是单纯的向量表,而是更接近一个带索引、带范围、带治理能力的记忆系统。
一次典型流程可以拆成 5 步:
-
输入是什么 输入是一段对话消息,通常包含
user和assistant两类角色内容。 -
触发条件是什么 当对话中出现值得长期保留的事实、偏好、目标或设定时,调用 Mem0 的
add写入记忆。 -
中间处理了什么 Mem0 会把对话提取成可检索的记忆,并结合语义、关键词、图谱等能力建立索引。
-
输出结果是什么 下次调用
search时,Mem0 返回和当前问题最相关的记忆列表。 -
对整体系统产生什么影响 Agent 不再只依赖当前上下文,而是可以跨会话找回长期事实,并根据用户、会话、Agent 范围做精确过滤。
这里要注意一个边界:Mem0 是长期记忆,不是短期上下文缓存。最近几轮消息、临时摘要、Token 控制,仍然适合交给 Redis 或 LangChain 的摘要中间件处理。Mem0 更适合保存"下次还值得记住"的信息。
二、快速上手:构建第一个可运行示例
这一节先用最小示例跑通 Mem0 的核心 API。目标很明确:
- 写入一段用户对话。
- 搜索和用户相关的长期记忆。
- 列出全部记忆。
- 获取、更新、查看单条记忆历史。
- 按用户清理测试数据。
2.1 环境准备
示例使用的技术栈如下:
- Node.js
mem0aidotenvioredislangchain@langchain/openaizod
安装依赖:
bash
pnpm add mem0ai dotenv ioredis langchain @langchain/openai zod准备 .env:
env
MEM0_API_KEY=your_mem0_api_key
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxxx
MODEL_NAME=qwen-plus
REDIS_HOST=localhost
REDIS_PORT=6379
REDIS_DB=0
MEMORY_TTL_SECONDS=1800
MEMORY_KEY_PREFIX=agent:short_memory
MEM0_USER_ID=demo_user_001
MEM0_TOP_K=5其中 MEM0_API_KEY 是 Mem0 的核心配置。后面的 OpenAI 和 Redis 配置,是为了后续把 Mem0 和 Agent 调用链路组合起来。
2.2 最小代码:写入、搜索、更新、追踪历史
下面这段代码是一个完整的最小可运行示例。为了方便阅读,我把关键位置都加了中文注释。
js
import dotenv from "dotenv"
// 读取 .env 配置,便于本地调试 MEM0_API_KEY 等环境变量
dotenv.config({ override: true })
import { MemoryClient } from "mem0ai"
// 这里用固定用户 ID 演示用户级长期记忆
const USER_ID = "demo-user"
function log(title, data) {
console.log(`\n=== ${title} ===`)
console.log(typeof data === "string" ? data : JSON.stringify(data, null, 2))
}
async function main() {
if (!process.env.MEM0_API_KEY) {
throw new Error("缺少 MEM0_API_KEY")
}
// 初始化 Mem0 客户端,后续所有记忆操作都通过 client 完成
const client = new MemoryClient({
apiKey: process.env.MEM0_API_KEY,
})
// 一段真实对话。Mem0 会从对话中提取值得保存的长期事实
const conversation = [
{ role: "user", content: "我是素食主义者,而且对坚果过敏。" },
{ role: "assistant", content: "好的,我会记住你的饮食偏好。" },
{ role: "user", content: "我住在北京,平时喜欢跑步。" },
{ role: "assistant", content: "已记录:北京、爱好跑步。" },
]
// add:把对话写入用户级长期记忆
const added = await client.add(conversation, { userId: USER_ID })
log("添加记忆", added)
// search:按问题搜索长期记忆,filters 用来限定只查当前用户
const searchResult = await client.search("用户的饮食限制是什么?中文回答", {
filters: { user_id: USER_ID },
topK: 5,
})
log("搜索记忆", searchResult)
// getAll:列出该用户下的全部记忆,适合调试和管理后台展示
const allMemories = await client.getAll({
filters: { user_id: USER_ID },
pageSize: 10,
})
log("列出全部记忆", allMemories)
// 取一条记忆做 get / update / history 演示
const firstMemory = allMemories.results?.[0] ?? searchResult.results?.[0]
if (firstMemory?.id) {
// get:按记忆 ID 获取完整信息
const memory = await client.get(firstMemory.id)
log("获取单条记忆", memory)
// update:更新记忆内容,适合修正错误或补充说明
const updated = await client.update(firstMemory.id, {
text: `${memory.memory ?? firstMemory.memory}(已通过示例脚本更新)`,
})
log("更新记忆", updated)
// history:查看这条记忆的变更历史
const history = await client.history(firstMemory.id)
log("记忆变更历史", history)
}
// cleanup:测试结束时可清理该用户的全部记忆
if (process.argv.includes("--cleanup")) {
const deleted = await client.deleteAll({ userId: USER_ID })
log("清理测试数据", deleted)
}
}
main().catch(error => {
console.error("\n执行失败:", error.message ?? error)
if (error.suggestion) {
console.error("建议:", error.suggestion)
}
process.exit(1)
})2.3 代码执行流程
这段代码的执行流程可以理解成一条记忆生命周期链路:
new MemoryClient()创建 Mem0 客户端。client.add()把对话写入长期记忆。client.search()用自然语言问题检索相关记忆。client.getAll()查询当前用户的全部记忆。client.get()获取单条记忆详情。client.update()修正或补充记忆。client.history()查看记忆变更历史。client.deleteAll()清理测试数据。
运行后你通常会看到几类输出:
- 添加记忆的结果。
- 搜索命中的记忆列表。
- 记忆 ID、内容、创建时间等元信息。
- 更新后的记忆和历史记录。
需要注意的是,记忆写入可能存在异步处理过程。如果你刚 add 完马上 search,偶尔可能搜索不到刚写入的内容。工程里更稳妥的做法,是把写入和搜索分开,或者在 UI 上给出"记忆处理中"的状态。
三、核心配置 / 关键流程详解
3.1 三种记忆 scope:这个人、这次对话、这个助手
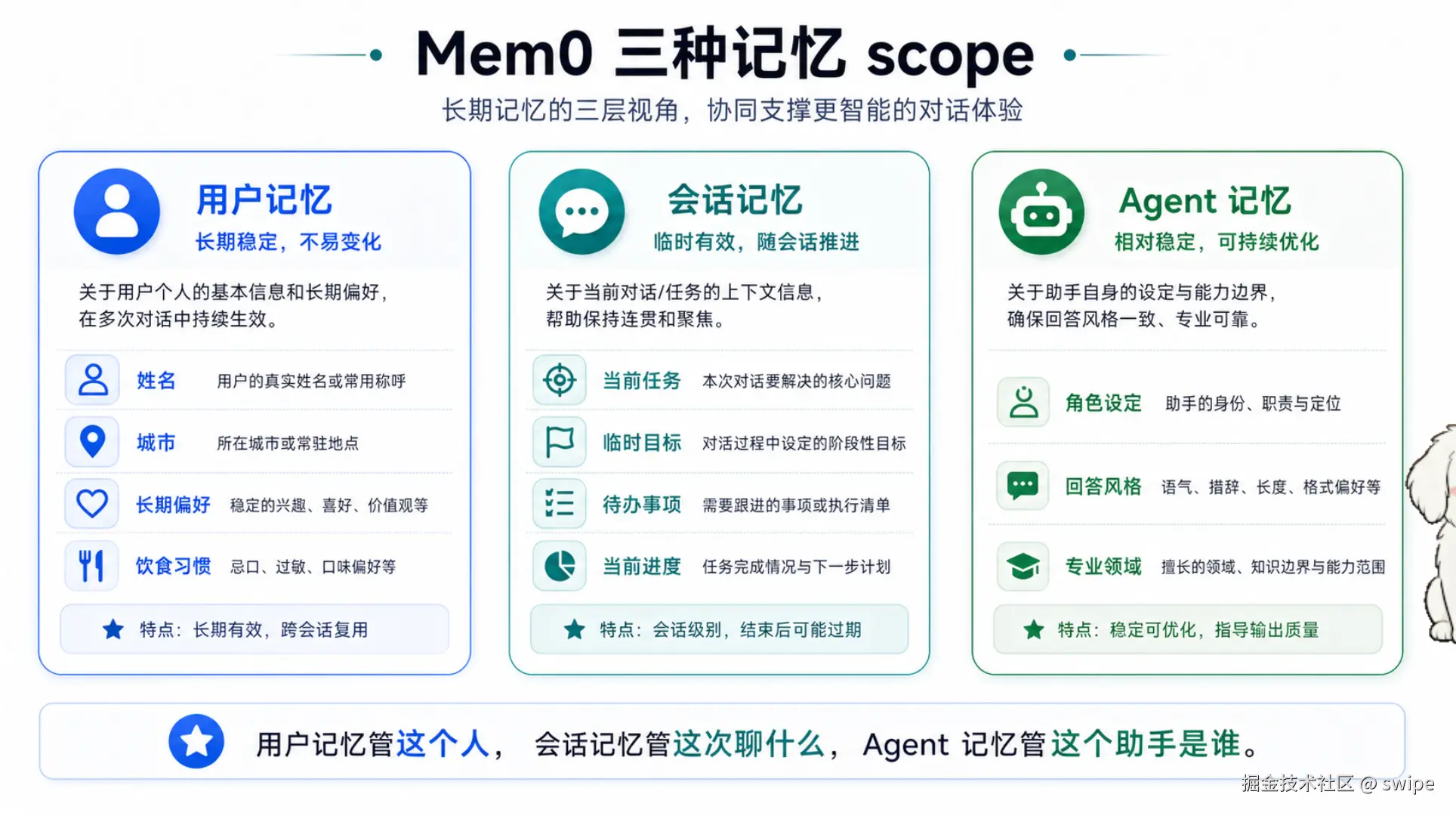
图 2:用户记忆、会话记忆、Agent 记忆分别对应不同生命周期和作用范围。
Mem0 最重要的概念之一,是记忆 scope。
用户记忆(User Memory)
它绑定 userId,用于保存跟着用户长期存在的信息,比如姓名、城市、长期偏好、饮食禁忌、常用技术栈。用户换一个会话、换一个 Agent,只要仍然是同一个 userId,这些信息都可以继续被召回。
适合保存:
- 用户姓名、城市、职业。
- 长期兴趣和偏好。
- 饮食禁忌、语言偏好。
- 稳定的工作习惯和工具栈。
容易踩坑的地方是,把一次性任务误写进用户记忆。比如"这次先帮我写季度总结",这句话不应该成为用户长期画像。
会话记忆(Session Memory)
它通常绑定 userId + runId,用于保存当前这次对话或当前任务的上下文。比如"本轮先写 Q1 总结""当前排查 payment-api 超时""下一步看 P99 日志",这些都属于当前会话有效的信息。
适合保存:
- 当前任务目标。
- 本轮对话进度。
- 临时待办事项。
- 当前上下文里的阶段性决策。
会话记忆的边界是"这次聊什么"。它不应该污染用户长期画像。
Agent 记忆(Agent Memory)
它绑定 agentId,用于保存某个 Agent 自己的角色、语气、回答方式和专业领域。比如"你是旅行规划助手""回答时多给备选方案""偏向工程化解释",这些更像 Agent 的长期行为设定。
适合保存:
- 角色定位。
- 回答风格。
- 专业领域。
- 工具使用偏好。
简单总结就是:用户记忆管这个人,会话记忆管这次聊什么,Agent 记忆管这个助手是谁。
3.2 三种 scope 的写入与搜索
下面是一个完整的 scope 示例。代码把 add 和 search 分开,是因为实际写入可能有异步处理过程。
js
import dotenv from "dotenv"
// 读取环境变量,包含 MEM0_API_KEY
dotenv.config({ override: true })
import { MemoryClient } from "mem0ai"
const USER_ID = "mem0_test_user"
const RUN_ID = "mem0_test_session"
const AGENT_ID = "mem0_test_agent"
function log(title, data) {
console.log(`\n=== ${title} ===`)
console.log(typeof data === "string" ? data : JSON.stringify(data, null, 2))
}
async function addUserMemory(client) {
// 用户记忆:跨会话长期稳定的信息
const messages = [
{ role: "user", content: "我叫小明,住在杭州,平时喜欢骑行和摄影。" },
{ role: "assistant", content: "好的,已记住你的姓名、城市和爱好。" },
]
const added = await client.add(messages, { userId: USER_ID })
log("用户记忆 add", added)
}
async function searchUserMemory(client) {
// 只按 user_id 过滤,表示搜索这个用户的长期画像
const searched = await client.search("用户住在哪里,有什么爱好", {
filters: { user_id: USER_ID },
topK: 5,
})
log("用户记忆 search", searched.results?.map(m => m.memory) ?? [])
}
async function addSessionMemory(client) {
// 会话记忆:只属于当前 run/thread 的临时任务上下文
const messages = [
{
role: "user",
content: "这次聊天先帮我把季度总结的大纲列出来,重点写 Q1 的项目复盘。",
},
{
role: "assistant",
content: "明白,我们先围绕 Q1 项目复盘整理季度总结大纲。",
},
]
const added = await client.add(messages, { userId: USER_ID, runId: RUN_ID })
log("会话记忆 add", added)
}
async function searchSessionMemory(client) {
// 同时按 user_id 和 run_id 过滤,避免串到其他会话
const searched = await client.search("这次对话要先做什么", {
filters: { AND: [{ user_id: USER_ID }, { run_id: RUN_ID }] },
topK: 5,
})
log("会话记忆 search", searched.results?.map(m => m.memory) ?? [])
}
async function addAgentMemory(client) {
// Agent 记忆:描述这个助手的角色和回答方式
const messages = [
{
role: "user",
content: "你现在是旅行规划助手,回答时多给具体建议和备选方案。",
},
{
role: "assistant",
content: "好的,我会以旅行规划助手的身份,提供具体建议和备选方案。",
},
]
const added = await client.add(messages, { agentId: AGENT_ID })
log("Agent 记忆 add", added)
}
async function searchAgentMemory(client) {
// 按 agent_id 过滤,搜索这个 Agent 自身的行为设定
const searched = await client.search("这个 Agent 的角色和回答方式", {
filters: { agent_id: AGENT_ID },
topK: 5,
})
log("Agent 记忆 search", searched.results?.map(m => m.memory) ?? [])
}
async function main() {
if (!process.env.MEM0_API_KEY) {
console.error("缺少 MEM0_API_KEY")
process.exit(1)
}
const client = new MemoryClient({
apiKey: process.env.MEM0_API_KEY,
})
const action = process.argv[2] ?? "add"
if (action === "add") {
await addUserMemory(client)
await addSessionMemory(client)
await addAgentMemory(client)
console.log("\nadd 已提交,稍后再运行 search 更稳定")
return
}
if (action === "search") {
await searchUserMemory(client)
await searchSessionMemory(client)
await searchAgentMemory(client)
return
}
if (process.argv.includes("--cleanup")) {
await client.deleteAll({ userId: USER_ID })
await client.deleteAll({ userId: USER_ID, runId: RUN_ID })
await client.deleteAll({ agentId: AGENT_ID })
log("清理完成", { USER_ID, RUN_ID, AGENT_ID })
}
}
main().catch(error => {
console.error("\n执行失败:", error.message ?? error)
if (error.suggestion) console.error("建议:", error.suggestion)
process.exit(1)
})这一段最重要的不是代码量,而是过滤条件:
filters: { user_id: USER_ID }:查用户长期记忆。filters: { AND: [{ user_id }, { run_id }] }:查当前会话记忆。filters: { agent_id: AGENT_ID }:查 Agent 记忆。
记忆系统是否好用,很多时候不取决于写入量,而取决于你有没有把作用范围切清楚。
3.3 三路召回:为什么不只做向量检索?
Mem0 的长期记忆价值,还体现在多路召回上。
语义检索
语义检索依赖 Embedding 和向量相似度,擅长处理模糊表达和同义表达。比如"用户不能吃什么"和"用户有什么饮食限制"虽然文字不同,但语义接近。
关键词检索
关键词检索更适合精确实体、专有名词、参数、项目名。比如 order-service、Q1、payment-api,这类信息如果只靠语义检索,可能不如关键词召回稳定。
知识图谱检索
知识图谱检索强调实体之间的关系。比如"用户住在杭州""喜欢骑行""经常做旅行规划",这些信息之间能形成关联,后续就可以通过实体关系做更复杂的推理召回。
三路召回不是为了堆概念,而是为了降低单一路径的偏差。语义检索解决"意思相近",关键词检索解决"精确命中",知识图谱检索解决"关系关联"。这三类能力融合后,长期记忆的召回稳定性会更接近真实产品需要。
3.4 Redis + Mem0:短期记忆和长期记忆如何协作?
Mem0 负责长期记忆,但 Agent 每轮对话仍然需要短期上下文。一个更完整的工程模型是:
- Redis 保存最近几轮消息和摘要,响应快,带 TTL。
- Mem0 保存值得长期保留的信息,可跨会话召回。
- Agent 调用前先读 Redis,再查 Mem0,把长期记忆作为 SystemMessage 注入。
- Agent 回复后,短期消息写回 Redis,长期事实按分类结果写入 Mem0。
下面这段是整合版核心代码,保留了最关键的类和流程,并加入中文注释。
js
import Redis from "ioredis"
import { z } from "zod"
import { MemoryClient } from "mem0ai"
import { ChatOpenAI } from "@langchain/openai"
import {
SystemMessage,
HumanMessage,
mapChatMessagesToStoredMessages,
mapStoredMessagesToChatMessages,
} from "@langchain/core/messages"
// 用结构化输出约束模型分类结果,避免返回不可解析的自然语言
const memorySchema = z.object({
write_user: z.boolean().describe("是否写入用户层长期记忆"),
write_session: z.boolean().describe("是否写入当前会话层记忆"),
reason: z.string().describe("分类理由,一句话"),
})
// Redis 只保存短期消息,负责当前会话运行态
class RedisMessageStore {
constructor({ redis, keyPrefix, ttlSeconds }) {
this.redis = redis
this.keyPrefix = keyPrefix
this.ttlSeconds = ttlSeconds
}
messagesKey(sessionId) {
return `${this.keyPrefix}:${sessionId}:messages`
}
async loadMessages(sessionId) {
const raw = await this.redis.get(this.messagesKey(sessionId))
if (!raw) return []
return mapStoredMessagesToChatMessages(JSON.parse(raw))
}
async saveMessages(sessionId, messages) {
const payload = JSON.stringify(mapChatMessagesToStoredMessages(messages))
await this.redis.set(
this.messagesKey(sessionId),
payload,
"EX",
this.ttlSeconds
)
}
}
// Mem0 负责长期记忆:搜索、构造提示词、按层写入
class Mem0MemoryStore {
constructor({ client, userId, sessionId, topK, classifier }) {
this.client = client
this.userId = userId
this.sessionId = sessionId
this.topK = topK
this.classifier = classifier
}
async search(query) {
// 并行搜索用户层和当前会话层,减少等待时间
const [userRes, sessionRes] = await Promise.all([
this.client.search(query, {
filters: { user_id: this.userId },
topK: this.topK,
}),
this.client.search(query, {
filters: {
AND: [{ user_id: this.userId }, { run_id: this.sessionId }],
},
topK: this.topK,
}),
])
return {
user: userRes.results ?? [],
session: sessionRes.results ?? [],
}
}
buildSystemMessage({ user, session }) {
const blocks = []
if (user.length) {
blocks.push(`【用户长期记忆】\n${user.map(m => `- ${m.memory}`).join("\n")}`)
}
if (session.length) {
blocks.push(`【当前会话记忆】\n${session.map(m => `- ${m.memory}`).join("\n")}`)
}
if (!blocks.length) return null
// 把召回记忆注入为 SystemMessage,让 Agent 回答时显式参考
return new SystemMessage(
`${blocks.join("\n\n")}\n\n请结合以上记忆回答,勿编造。`
)
}
async classifyAndPersist(userText, assistantText) {
const turn = [
{ role: "user", content: userText },
{ role: "assistant", content: assistantText },
]
// 用模型判断这轮对话是否值得写入 user / session 层
const { write_user, write_session, reason } = await this.classifier.invoke([
new SystemMessage("判断本轮对话是否有新事实需要写入长期记忆。"),
new HumanMessage(`用户:${userText}\n助手:${assistantText}`),
])
const written = []
if (write_user) {
await this.client.add(turn, { userId: this.userId })
written.push("user")
}
if (write_session) {
await this.client.add(turn, {
userId: this.userId,
runId: this.sessionId,
})
written.push("session")
}
return { written, reason }
}
}
async function invokeWithMemory(agent, redisStore, mem0Store, sessionId, userText) {
// 读取 Redis 短期历史
const history = await redisStore.loadMessages(sessionId)
// 从 Mem0 召回长期记忆
const mem = await mem0Store.search(userText)
const memoryMsg = mem0Store.buildSystemMessage(mem)
// 本轮调用:长期记忆 + 短期历史 + 当前用户消息
const invokeMessages = [
...(memoryMsg ? [memoryMsg] : []),
...history,
new HumanMessage(userText),
]
const result = await agent.invoke({ messages: invokeMessages })
const assistantText = String(result.messages.at(-1)?.content ?? "")
// 短期记忆写回 Redis
await redisStore.saveMessages(sessionId, result.messages)
// 长期事实按分类结果写入 Mem0
const persistResult = await mem0Store.classifyAndPersist(userText, assistantText)
return { assistantText, persistResult }
}
// 初始化 Redis、Mem0、模型和分类器
const redis = new Redis({ host: "localhost", port: 6379, db: 0 })
const mem0 = new MemoryClient({ apiKey: process.env.MEM0_API_KEY })
const model = new ChatOpenAI({
model: process.env.MODEL_NAME,
apiKey: process.env.OPENAI_API_KEY,
configuration: { baseURL: process.env.OPENAI_BASE_URL },
temperature: 0,
})
const classifier = model.withStructuredOutput(memorySchema)这段代码体现了一个比较稳定的工程分工:
- Redis 保存短期消息,解决"这轮对话怎么接上"。
- Mem0 搜索长期记忆,解决"过去重要事实怎么找回"。
- 分类器判断是否写长期记忆,解决"什么值得留下"。
SystemMessage注入召回结果,解决"Agent 怎么用这些记忆"。
3.5 容易踩坑的地方
不要把所有消息都写进 Mem0
寒暄、确认、普通回复、临时草稿,不一定都值得长期保存。写入越多,后续召回噪声越大。
不要把 session 记忆写成 user 记忆
"这次帮我写 Q1 总结"是当前任务,不是用户长期画像。如果写进用户记忆,用户下次做别的事也可能被错误影响。
不要在 Redis 里保存 Mem0 注入的 SystemMessage
长期记忆每轮都会重新召回,应该临时注入,不应该被写回短期历史。否则 Redis 里的上下文会越来越脏。
不要期待 add 后立刻 100% 可搜索
记忆写入可能需要处理时间。实际产品中可以把搜索放到下一轮,或在界面上区分"已提交"和"已可检索"。
不要忽略清理能力
测试脚本一定要准备 deleteAll 或管理接口,否则测试用户会积累大量脏记忆,后面排查召回问题会很痛苦。
四、运行效果与扩展思考
当这套流程跑起来后,系统会呈现出一个清晰的记忆闭环。
第一轮用户说:
text
我叫小明,住在杭州,平时喜欢骑行和摄影。分类器会判断这是长期稳定信息,适合写入 user 层。下次用户换一个会话再问"你还记得我住哪吗",Mem0 可以通过 user_id 召回这条记忆。
如果用户说:
text
这次我们先写 Q1 季度总结,大纲分三块:项目复盘、数据指标、下季度计划。这就是典型 session 层信息。它对当前会话很重要,但不应该变成用户长期画像。
再比如用户说:
text
你现在是旅行规划助手,回答时多给具体建议和备选方案。这更像 Agent 记忆,应该围绕 agentId 维度保存。
在真实项目里,可以进一步扩展这些能力:
- 增加一层"是否值得写入"的规则引擎,先过滤明显无价值内容。
- 给不同类型记忆设置不同保留策略。
- 在用户侧提供"查看我的记忆"和"删除某条记忆"的入口。
- 把 Mem0 召回结果和 RAG 文档召回结果一起排序。
- 结合审计日志追踪记忆被谁写入、何时更新、为何删除。
长期记忆系统最难的不是写入,而是治理。你需要让系统知道:什么是事实,什么是临时任务,什么是助手设定,什么只是一次普通聊天。
五、总结
本文围绕 Mem0 做了一次完整的长期记忆实践:从为什么需要长期记忆,到如何快速写入和搜索,再到三种 scope、三路召回,以及 Redis + Mem0 的组合架构。
核心结论可以压缩成 4 句话:
- Redis 负责短期记忆,解决当前会话的低延迟上下文。
- Mem0 负责长期记忆,解决跨会话、跨任务、跨 Agent 的事实召回。
- 用户记忆、会话记忆、Agent 记忆必须分层,否则后续会互相污染。
- 语义检索、关键词检索、知识图谱检索互相补位,比单一路径更适合真实长期记忆场景。
实际开发中,如果只是做 Demo,可以先用 Mem0 的 add / search 快速跑通;如果要做产品,就应该尽早设计记忆分层、过滤条件、写入策略、删除入口和审计能力。
下一步可以继续深入两个方向:
- 如何把 Mem0 的长期记忆接入完整 Agent 工作流,让每次工具调用也能参与记忆分类。
- 如何自部署长期记忆系统,把向量库、关键词索引、知识图谱和业务数据库统一纳入自己的数据治理体系。
Agent 要变得真正可用,不是只靠模型"聪明",还要让它在正确的范围里记住正确的东西。Mem0 的价值,就在于把这件事从一堆零散工程逻辑,收敛成一套清晰的长期记忆接口。