引言:从"大航海时代"到"数字主权"
在 2023 年到 2024 年期间,开发者社区沉浸在云端 API 的便利中。只要写几行代码调用 OpenAI 或 Anthropic 的接口,便能快速构建出具备智能交互能力的应用。那是一个将所有业务数据打包送往云端的时代,云端大模型被视为解决一切技术难题的万能钥匙。
然而到了 2026 年,事情没那么简单了。随着企业级应用的深入,API 账单让许多初创团队发现,成本顶不住了。而且,各国对数据隐私与合规(如欧盟 GDPR、企业数据安全管理条例)的审查愈发严格,许多大型企业明确禁止将敏感文档上传至第三方云端服务器。此外,网络延迟波动或云端服务偶然的宕机,也会直接导致依赖云端 API 的本地工作流处于瘫痪状态。
2024 年,开发团队将数据源源不断地送往云端的大脑;而在 2026 年,开发者正在将大脑直接部署到数据身旁。本地优先 AI(Local-First AI)的开发模式,正逐步成为当下的技术主流。
核心驱动力:为什么本地优先成为必然?
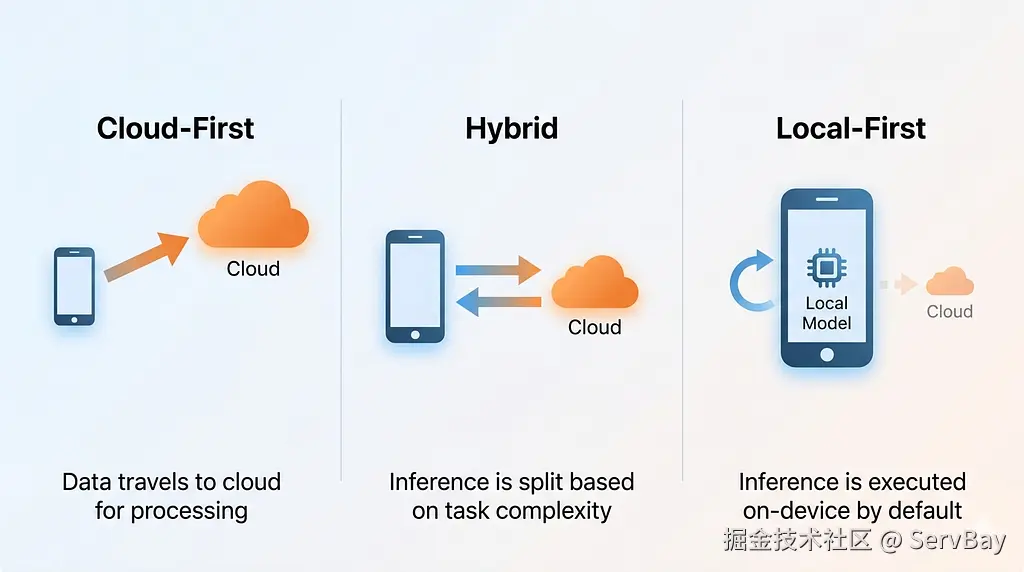
本地优先 AI 的兴起并非一时兴起,而是由底层硬件、经济效益和合规需求共同推动的必然结果。以下是支撑这一趋势的三个支柱。
一、 数据安全与合规的本地边界
当下的检索增强生成(RAG)应用和 AI 智能体(Agent)通常需要读取用户的私密文档、财务报表、甚至是核心代码库。如果将这些高度敏感的信息发送给第三方平台,会给企业带来难以估量的安全隐患。
采用本地模型(Local LLM)开展业务,数据能够始终保留在物理硬盘内。这种物理隔离的优势,使得开发团队在面对严苛的企业级安全审查时,能够拥有更强的合规底气。
二、 零边际成本与推理自由
在云端架构中,AI 智能体每一次执行自主思考和循环推理,都会消耗一定数量的 Token,从而产生真金白银的账单。随着调用频次的累积,研发成本将呈现指数级增长。

得益于 Apple 芯片统一内存技术的升级以及边缘端 GPU 的普及,在本地运行 8B 或 14B 参数级别的大模型已变得十分普及。由于硬件资产属于开发者个人或企业,本地推理的边际成本趋近于零。技术团队可以允许 AI 服务在后台进行全天候的推理与任务调度,而无需担心产生计划外的财务负担。
三、 毫秒级低延迟与离线可用性
随着 AI 应用由简单的问答框演变为能够提供实时反馈的辅助编码工具(Copilot)或交互式智能体,网络交互带来的延迟将极大地破坏使用体验。本地部署的 AI runtime 能提供低至个位数毫秒级的响应速度。
这种高即时性还带来了离线工作的可能。即使在没有网络连接的高铁或航班上,本地运行的 AI 辅助系统依然能够正常运作。
理想很丰满,但基建很骨感
尽管本地优先 AI 展现出巨大的优势,但在实际落地过程中,本地开发环境的零散和繁琐却成为开发者的掣肘。

在本地开发一个完整的、具备前端界面的 RAG 应用,就要独立配置和维护一个庞大的技术栈:
-
部署和运行本地大模型(例如配置 Ollama)。
-
安装并运行支持
pgvector扩展的 PostgreSQL 数据库,用于存储和检索高维向量数据。 -
部署基于 Python 或 Node.js 的后端服务。
-
处理繁杂的环境变量、端口占用以及跨域(CORS)问题。
-
解决部分高阶 API(如网页端调用本地麦克风、摄像头或 WebRTC 接口)对于 HTTPS 的强制性要求,这通常需要开发者在本地手动创建并信任自签名 SSL 证书。
许多开发者在尚未编写核心业务代码之前,就已经消耗了大量精力在这些繁琐的环境配置上。这种碎片化的本地环境工具,极大地限制了本地 AI 应用的开发效率。
ServBay 与一体化本地 AI 基础设施
要破解上述开发困局,本地开发环境需要完成从碎片化配置向系统级集成的跃升。开发者需要的是一个开箱即用、无需频繁借助虚拟化技术便能直接发挥硬件算力的本地工作站基座。
而 ServBay 就是一个不错的选择,它不仅仅是 Web 开发环境管理工具,更是一个一体化本地 AI 基础设施,它通过免除复杂的 Docker 虚拟机配置,大幅降低了本地开发环境的损耗。
-
免虚拟化开销, 算力直达硬件:ServBay 采用原生运行模式,不依赖笨重的 Docker 容器,从而将宝贵的 CPU、统一内存和 GPU 算力完整保留给本地大模型,确保推理速度的最大化。
-
一站式 AI 工具链集成 :ServBay 内部预置了编译好的 PostgreSQL 数据库,并默认集成了
pgvector向量检索插件。同时,它提供了开箱即用的 Python、Node.js 与 Java、Rust 运行环境,能够与本地运行的 Ollama 顺畅对接。 -
零配置本地 SSL 证书:针对 AI 语音和图像调用所需的 HTTPS 环境,ServBay 提供了快捷的域名管理和本地 SSL 自动签发功能。只需简单勾选,本地服务即可在安全的 HTTPS 环境下运行。
本地 RAG 开发实战:以 Python、pgvector 与 Ollama 为例
在 ServBay 构建的本地环境中,开发一个简单的本地知识库检索(RAG)原型不再需要繁琐的配置。以下是一个使用原生 Python 连接本地 PostgreSQL(pgvector)和 Ollama 的标准实现代码。
python
import psycopg2
import requests
# 1. 连接到 ServBay 本地集成的 PostgreSQL 数据库
try:
conn = psycopg2.connect(
dbname="local_rag_db",
user="servbay_root",
password="", # 请根据 ServBay 实际配置填写
host="127.0.0.1",
port=5432
)
cur = conn.cursor()
print("本地数据库连接成功")
except Exception as e:
print(f"数据库连接失败: {e}")
# 注意:运行前请确保在数据库中执行了以下 SQL 语句:
# CREATE EXTENSION IF NOT EXISTS vector;
# CREATE TABLE IF NOT EXISTS documents (id serial PRIMARY KEY, content text, embedding vector(384));
# 2. 获取查询文本的本地向量表示(以 Ollama 运行的 nomic-embed-text 模型为例)
query_text = "如何在 ServBay 中配置本地 SSL 证书?"
try:
embed_response = requests.post(
"http://127.0.0.1:11434/api/embeddings",
json={"model": "nomic-embed-text", "prompt": query_text}
)
query_vector = embed_response.json().get("embedding")
except Exception as e:
print(f"获取 Embedding 失败: {e}")
query_vector = None
if query_vector:
# 3. 将向量转化为 pgvector 兼容的字符串格式,并进行余弦相似度检索
vector_str = "[" + ",".join(map(str, query_vector)) + "]"
try:
cur.execute(
"SELECT content FROM documents ORDER BY embedding <=> %s LIMIT 1;",
(vector_str,)
)
db_result = cur.fetchone()
context = db_result[0] if db_result else "未找到相关本地上下文。"
except Exception as e:
context = "数据库检索异常。"
print(f"检索失败: {e}")
# 4. 拼接上下文,提交给本地大模型(如 Llama 3)生成回答
prompt = f"请根据以下已知内容回答问题。\n\n已知内容:\n{context}\n\n问题:{query_text}\n\n回答:"
try:
gen_response = requests.post(
"http://127.0.0.1:11434/api/generate",
json={"model": "llama3", "prompt": prompt, "stream": False}
)
answer = gen_response.json().get("response")
print("\n=== AI 本地回答 ===")
print(answer)
except Exception as e:
print(f"本地大模型推理失败: {e}")
# 清理数据库连接资源
cur.close()
conn.close()在这套工作流中,数据从读取、向量化、存储到最终的大模型推理,全程在开发者的个人物理设备上完成。配合 ServBay 提供的本地域名与 SSL 支持,整个系统的安全性与私密性得到了底层技术架构的保障。
结语
本地优先 AI 的兴起代表着算力和数据主权的理性回归。它将人工智能的构建能力重新交付到了每一位开发者的本地物理设备上,使得 AI 不再是少数云端巨头垄断的特权,而是成为任何人在离线状态下都能自由调用的本地算力资产。
在这个技术演进的节点上,选择高效的工具能够帮助开发人员在时代浪潮中更进一步。通过使用 ServBay,开发者可以在极短的时间内搭建起一个原生、高性能且安全的本地 AI 开发工作站,从而将更多的时间投入到产品核心业务逻辑与算法的打磨中。