嵌入式语音应用相关基础说明 ...... 矜辰所致前言
博主之前也没有太深入了解过嵌入式语音有关的应用,之前做的语音项目都直接使用的成品语音模块,最近遇到了需要低成本的解决方案,所以还得来了解一下嵌入式语音开发的一些基本内容,毕竟理论了解是我们在后期做语音应用时候的根本 。
所以本文我们主要就是来了解一下嵌入式语音方案相关的基础知识 。
我是矜辰所致,全网同名,尽量用心写好每一系列文章,不浮夸,不将就,认真对待学知识的我们,矜辰所致,金石为开!
目录
- 前言
- [一、 嵌入式语音相关基础说明](#一、 嵌入式语音相关基础说明)
-
- [1.1 嵌入式语音采样率](#1.1 嵌入式语音采样率)
- [1.2 位深/声道](#1.2 位深/声道)
- [1.3 语音码率](#1.3 语音码率)
- [二、 实现相关](#二、 实现相关)
-
- [2.1 语音采样(收音)](#2.1 语音采样(收音))
- [2.2 语音编解码](#2.2 语音编解码)
- [2.3 语音传输](#2.3 语音传输)
- [2.4 语音播放](#2.4 语音播放)
- [三、 FFmpeg 工具的使用](#三、 FFmpeg 工具的使用)
-
- [3.1 什么是 FFmpeg](#3.1 什么是 FFmpeg)
- [3.2 FFmpeg 下载安装](#3.2 FFmpeg 下载安装)
- [3.3 FFmpeg 常用命令](#3.3 FFmpeg 常用命令)
- [3.4 语音开发应用相关命令](#3.4 语音开发应用相关命令)
-
- [3.4.1 生成 PCM](#3.4.1 生成 PCM)
- [3.4.2 压缩](#3.4.2 压缩)
- [3.4.3 把 PCM 转成 WAV](#3.4.3 把 PCM 转成 WAV)
- [3.4.4 查看音频文件](#3.4.4 查看音频文件)
- [3.4.5 小结](#3.4.5 小结)
- 结语
一、 嵌入式语音相关基础说明
本文主要针对通用单片机方案,不包含高端专业的语音芯片
1.1 嵌入式语音采样率
在嵌入式语音方案中,常用的采样率基本就两种 8KHz 和 16 KHz 。
这可不是随便挑的,而是基于 人声物理特性、奈奎斯特定理、行业标准和硬件成本 决定的。
人声频率范围:
人耳能听 20Hz~20KHz ,正常成年人说话时产生的声波信号主要集中在300Hz到 3400Hz 之间,其中清晰传递语音信息的关键频段为300Hz-3000Hz。低于300Hz 的声音影响音色饱满度,高于 3400Hz 的成分对语音清晰度贡献较小,但是高于 3400Hz ~ 8KHz 的频率包括摩擦音、唇齿音细节,会使得音质更加自然。
所以语音只要保留到 4KHz,采样率 8KHz,语音就可懂,这也是 传统通话标准 (G.711 标准)使用的采样率。
语音保留到 8KHz,采样率 16KHz ,就更加自然,这是 现在 主流 AI 语音的标准采样率。
为什么采样率要是语音频率的 2 倍:
通信界有一条铁律---奈奎斯特采样定理 :采样率 ≥ 2 × 信号最高频率
采样率 ≥ 2 × 声音最高频率的 2 倍,才能保证声音传到单片机后不失真、不发生重叠。
为什么其他频率不可以:
首先对于单片机本身,单片机的外设,时钟源基本都是晶振分频,8K ,16K 可以通过从常规晶振整数分频得到,误差小,非常规频段无法精确分频得到,这样采样和播放时候的音质都会收到影响。
其次是整个语音算法、协议、生态完全不兼容,所以其他频段并无太大意义。
在单片机应用中,采样率决定了单片机的硬件定时器触发频率,8K 采样率定时器 1 秒中断 8000 次,16K 采样率定时器 1 秒中断 16000 次。
除了 采样率,还有一个位深,单声道双声道,码率等概念,下面也需要了解一下。
1.2 位深/声道
位深 = 每个采样点用多少位(bit)来存储幅度值,一般就是 8bit 和 16bit 。
8bit : 256 个音量等级,档位少,声音容易有 "阶梯感"、发闷;
16bit : 65536个音量等级,过渡平滑,人声细节保留完整。
当然,16 位深的数据量相比 8 位直接翻倍。
单声道 / 双声道:
对于语音来说,单声道完全够用,双声道几乎不提升效果,只会徒增数据量(也是翻倍)、带宽、功耗;只有音乐 / 立体音效场景,双声道才有意义。
1.3 语音码率
上面我们说的 8K 和 16K ,是 "采样率 " ! 不是码率!
码率(也叫比特率),是指音频在播放或传输时,一秒钟要消耗/产生多少个"比特(bit)"的数据。
它的单位是 bps(Bits Per Second,比特/秒) 或 Kbps(千比特/秒)。
简单来说:码率 = 这一秒钟声音占用的网络流量/存储空间有多大。
在未压缩的原始 PCM 状态下,码率是由你前面总结的"三要素"共同乘出来的。
码率(bps)= 采样率 ✖ 位深 ✖ 声道数
注意,这是相对原始 PCM 来说的,如果是有压缩,那么码率就不是这么对应的。
比如,以前的固定电话标准(8KHz 语音)
参数:采样率 8kHz、位深 8bit、单声道
码率=8000×8×1=64000 bps=64 Kbps
这就是 PSTN 电话、G.711 经典 64Kbps 的由来。
现在的主流 AI 语音标准
参数:采样率 16kHz、位深 16bit、单声道
码率=16000×16×1=256000 bps=256 Kbps
在单片机应用中,码率决定了 Flash 空间够不够用,如果使用无线传输比如蓝牙,也要看蓝牙带宽够不够用。所以,原始的 PCM 相对比较大,语音应用中,可以使用编码压缩的方式减少码率,以获得更小的资源需求 。
二、 实现相关
2.1 语音采样(收音)
连续的声音能够采集播放的原理就像:高速连拍照片,连起来就是视频。快速播放一串按时间排列的电压数字。
收音流程 :麦克风 → 模拟 → 数字 PCM,使用 咪头采集原始的声音通过 ADC 采集电压值,把人声变成PCM(脉冲编码调制,原始的数字音频编码方式。)。
比如 每 1/16000 秒(16K采样率 )采样一次电压,把电压通过 ADC 转成数字,这些数字排成一串就是 PCM 数据,PCM 就是原始声音数字版,没有压缩。采样得到的PCM 会很大。
比如上面我们16K 采样用 12bit ADC,那么1S 理论数据如下:
16,000 × 12 bit = 192,000 bit = 24,000 Byte = 23.4375 KB 。
在很多应用上, 12bit 的数据应该会对齐到 16bit 放置,一是为了 CPU 访问速度,二是正好变成标准的 16位深的 PCM ,所以实际上的数据大小会变成:
16,000 × 16 bit = 256,000 bit = 32,000 Byte = 31.25 KB 。
至于 MIC 采集 ,有机会的话我们再来单独说明,但是这里先记录一下:
MIC 采集电路的输出静态电压是主要是由 MIC 的 供电电压 和偏置电阻 决定的,MIC 内部就是一个 可变电容 + 内置 JFET(场效应管).
2.2 语音编解码
编码就是将收音过程采集到的 PCM 按照规定的标准进行压缩。
解码就是把压缩的数据还原成PCM。
因为原始的 PCM 数据会很大,在一些应用中要尽可能的压缩。在接收端再进行解码操作。
通过上文的学习,我们可以从理论上分析压缩的好处,压缩算法改变的是什么 :
原始 16kHz 的声音原始码率(256 Kbps)太高,蓝牙传输容易卡顿,
可以使用 ADPCM 压缩算法:
压缩后,采样率依然是 16kHz(声音的音质、高频细节完全没有变,单片机定时器依然是一秒中断 16000 次)。
但是,位深从 16bit 变成了 4bit。
重新计算压缩后的码率:16,000 × 4 ×1 = 64,000 bps = 64 Kbps。
结果:码率从 256 Kbps 掉到了 64 Kbps,蓝牙传输数据量缩减到 1/4,但音质没有发生断崖式下跌。
单片机方案常用编码方式有:SBC、OPUS、ADPCM、CVSD
| 编解码 | 主要使用场景 | 典型工作码率 | 音质 | 核心特点 | 软件实现难易 |
|---|---|---|---|---|---|
| Opus | 高清语音、游戏低延迟语音 | 16~64 kbps | 最高 | 高清语音、超低延迟、自适应码率 | 难,算法复杂,内存和算力开销大 |
| SBC | 蓝牙 A2DP 音乐 / mSBC 语音 | 127~328 kbps (音乐) ~64 kbps(语音 mSBC) | 较高,音乐最低要求 | 蓝牙音乐标准,所有蓝牙音箱/耳机必支持 | 中等,有开源库,纯 C 可移植 |
| ADPCM | 低码率语音、对讲、BLE 语音 | 32~64 kbps(4:1 压缩后) | 一般,语音可听清 | 差分量化,极省 Flash 和 CPU | 容易,算法简单,内存占用低 |
| Speex | VoIP、网络对讲、嵌入式语音通信 | 8~32 kbps | 中等,语音可懂 | 专为语音优化,支持降噪/回声消除 | 中等,有开源库,纯 C 可移植,内存占用较小 |
| CVSD | 老式蓝牙 HFP 通话 | 64 kbps | 较差,语音可懂但粗糙 | 传统蓝牙通话,老旧设备标配 | 容易 |
2.3 语音传输
语音传输,比如使用 BLE 无线传输,一个核心的点就是蓝牙的传输速率。
对于目前市面上的稍微正规一点厂商的蓝牙芯片来说,一般都能做到 100Kb/s ,完全能够满足一般语音数据收发要求,比如博主测试过的 沁恒微的 CH585 ,最大可以达到 140 kB/s 。
比如我们上面算出来, 即便是 16K/16bit/单声道无压缩的 PCM 每秒的实际大小位 31.25 KB/s , 在蓝牙信号正常的情况下,实时传输也是不会卡顿的(具体应用实现当然还需要注意实现方式等一些细节问题)。
2.4 语音播放
这里介绍实际应用中常见的几种语音播放方案:
- PWM 模拟音频方案 (低成本、省芯片)
原理:利用单片机内部的定时器产生高频 PWM 波。通过快速改变 PWM 的占空比(Duty Cycle)来模拟电压的高低变化。
驱动方式也分为两种:
低成本:单路 PWM + ( RC滤波) + 功放(小攻放/三极管)。
缺点:音质较差。
进阶版:双 PWM(互补输出) + H桥芯片(如数字功放 IC)。这种方式属于 Class-D(D类)功放原型。它利用 H桥直接驱动喇叭,效率极高、省电、推力大,在智能门锁、警报器里非常普及。
缺点:占用两个 IO ,高频噪声大,需要用电感/电容做低通滤波(LC滤波),否则喇叭容易发热、有杂音。 - 外接 I2S DAC 功放芯片方案
通过 I2S 总线把标准的 S16LE 裸数字直接扔给专门的音频芯片。单片机只需要把内存里的 PCM 数据搬运到 I2S 寄存器解码、放大、驱动全由外接芯片搞定。
优点:
音质极好:芯片内部集成了高精度的硬件 DAC 和 D类功放,自带完美的滤波电路,声音非常干净、清脆。
缺点:多了一颗芯片的成本。 - 单片机自带内部 DAC 方案 (部分MCU支持)
有些单片机内部自带硬件数模转换器(DAC)。它能直接输出真正的模拟电压信号,接一个普通的模拟功放就能放音。
三、 FFmpeg 工具的使用
介绍一款语音应用需要用到的工具 。
3.1 什么是 FFmpeg
FFmpeg (Fast Forward Mpeg)是一套免费开源的、跨平台的音视频处理 命令行工具 。
它能读、写、转换、剪辑、录制、直播几乎任何格式的音频和视频,是专门用于音频和视频的编码、解码、转码等操作的开源软件。
3.2 FFmpeg 下载安装
FFmpeg 官网下载地址如下:
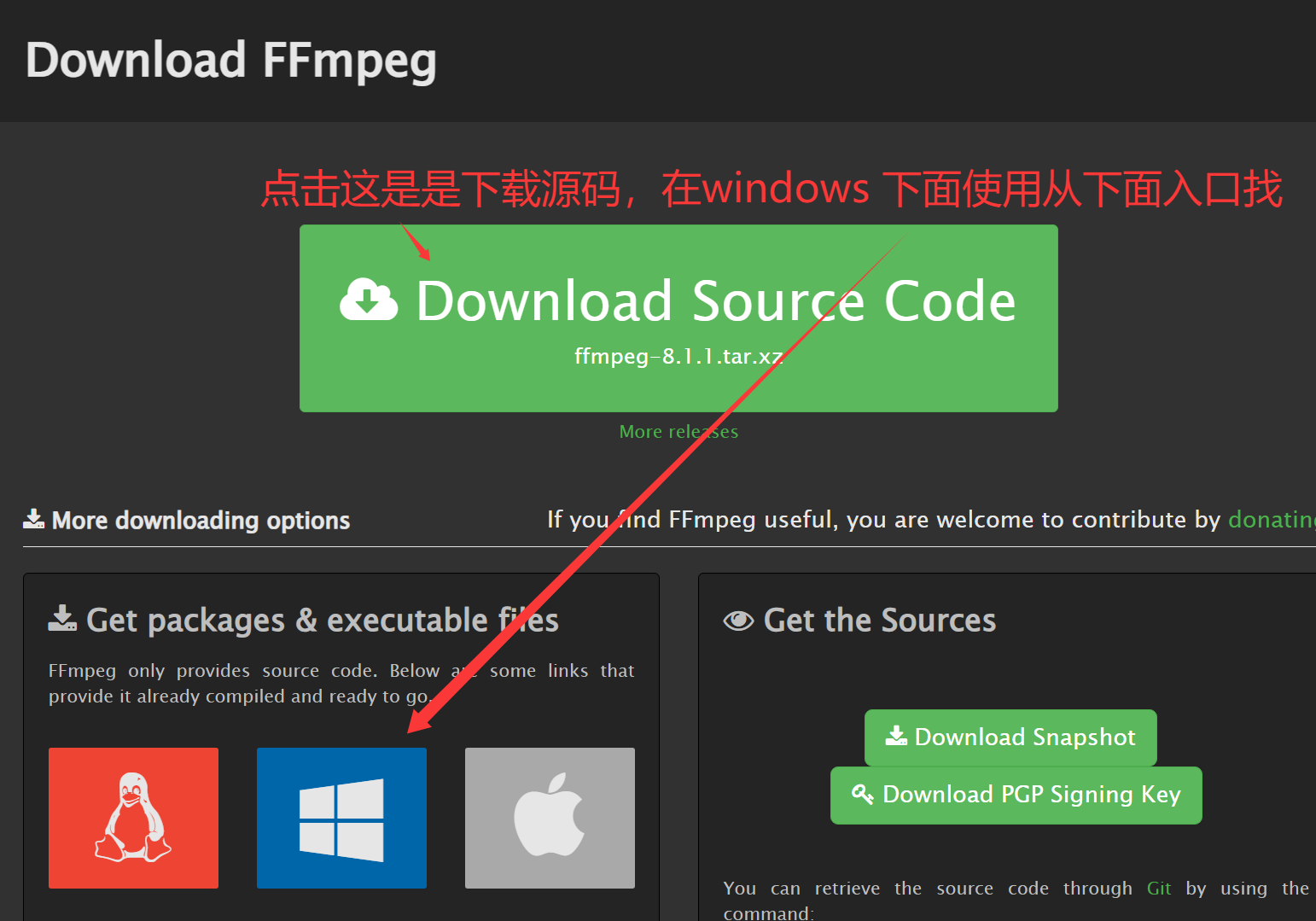
上面最显眼的那个下载是源码,给底层开发人员用的。在 Windows 下面使用通过下面 Windows 图标那里选择下载,选择 Windows builds by BtbN :

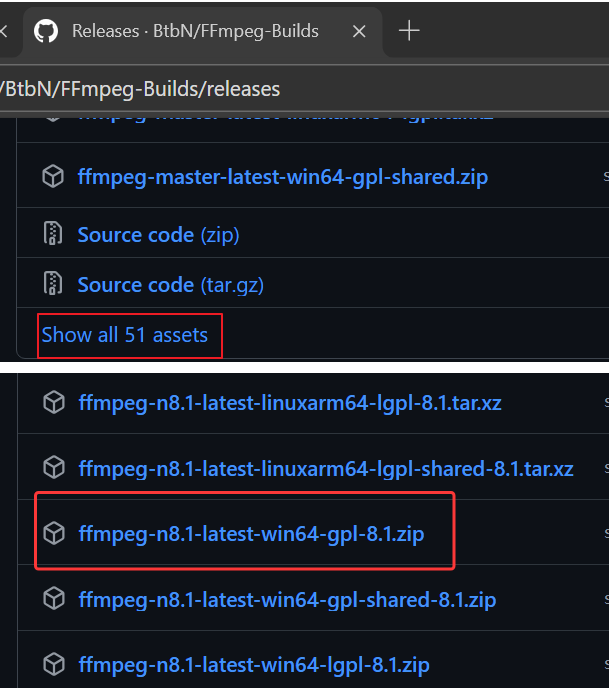
这是去 FFmpeg builds 的 github 页面,我们按照下图方式选择最新的 win64 版本,点击即可下载:
下载好以后解压出来:
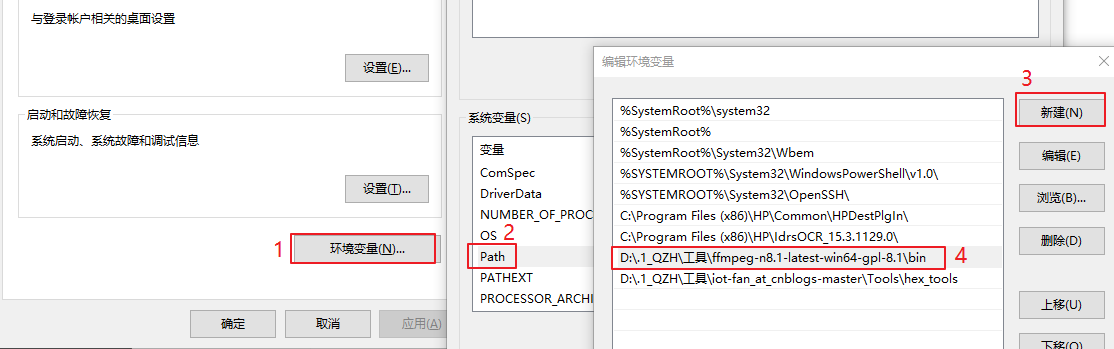
接下来就是添加环境变量,这个和我们很多工具链一样,bin 下面就是可以使用命令行的工具,我们需要把 bin 的路径添加到系统环境变量(现在找的系统找环境变量,可以直接打开 win 输入环境变量搜索,就可以直接找出来):
添加完环境变量,我们可以在 CMD 命令提示符里面输入 ffmpeg ,如果命令有效,表示我们安装成功,如下图:
3.3 FFmpeg 常用命令
现在有 AI ,一般需要用到什么命令,可以现场找 AI 问即可,这里就简单的列举几个常用命令了,具体的实际应用需要的时候临时问就行了。
文件信息查看(ffprobe):
bash
# 简易查看音视频参数
ffprobe input.mp4
# json结构化输出(脚本批量解析用)
ffprobe input.mp4 -v error -show_format -show_streams -print_format json视频格式互转:
bash
# 最简转码(自动编码)
ffmpeg -i input.mkv output.mp4
ffmpeg -i input.mp4 output.avi
# 限定码率压缩视频
ffmpeg -i input.mp4 -b:v 1200k -b:a 128k output.mp4
# 只封装不重新编码(极速拷贝)
ffmpeg -i input.mov -c copy output.mp4视频裁剪、片段截取:
bash
# 从10秒开始截取20秒
# 从 00:01:30 开始,截取 10 秒
# -ss 放前面 = 快 -ss 放后面 = 准
ffmpeg -i input.mp4 -ss 00:00:10 -t 20 -c copy cut.mp4
ffmpeg -ss 00:01:30 -t 10 -i input.mp4 -c copy output.mp4
# 精准起止时间
ffmpeg -i input.mp4 -ss 00:00:05 -to 00:00:25 cut.mp4视频提取音频:
bash
# 提取mp3 -vn = Video None = 不要视频
ffmpeg -i input.mp4 -vn output.mp3
ffmpeg -i input.wav output.mp3
# 提取aac
ffmpeg -i input.mp4 -vn -c:a aac output.aac
# 提取无损wav
ffmpeg -i input.mp4 -vn -c:a pcm_s16le output.wav音频通用处理:
bash
# mp3<->wav互转
ffmpeg -i input.mp3 output.wav
# 音量放大1.8倍
ffmpeg -i in.wav -af "volume=1.8" out.wav
# 多音频拼接
ffmpeg -i a.wav -i b.wav -filter_complex amix=inputs=2 out.wav视频截图:
bash
ffmpeg -i input.mp4 -ss 00:00:05 -vframes 1 output.jpg3.4 语音开发应用相关命令
在单片机语音开发中,随着需求的变化,常用的 FFmpeg 命令主要分为 三大类:生成裸数据、高压缩比导出、以及录音验证。
先记几个参数:
bash
-ar 16000 → 采样率 16k
-ac 1 → 单声道
-f s16le → 16bit 单片机标准PCM
-ab 64k → 码率 64k
-acodec sbc → 编码格式 SBC(蓝牙语音)3.4.1 生成 PCM
bash
ffmpeg -i 输入文件 -ar 16000 -ac 1 -f s16le 输出.pcm任意音频 生成 16K/16-bit/单声道 标准 PCM
bash
// 不仅仅是.mp3 支持,其他的格式都支持 .flac .aac .mp4
ffmpeg -i 111.mp3 -f s16le -ar 16000 -ac 1 output.pcm-i 111.mp3:输入你原始的文件。
这里不仅仅是 mp3 支持,基本上电脑能播放的格式,都可以支持直接转成规定格式的 pcm,无论是 .wav、.ogg、.flac、.aac,还是视频格式 .mp4、.avi、.mkv 。- -f s16le:16bit 位深,小端,单片机标准格式。
强制输出格式为 s16le(有符号 16 位小端格式)。这可以让 FFmpeg 剥离掉所有文件头(如 WAV 头),只留下纯电压数字数字流。单片机读取后可以直接赋值给 int16_t 数组。 - -ar 16000:设置采样率为 16kHz 。
- -ac 1:设置声道数为单声道。
- output.pcm:输出文件名。
任意音频 转成 8k 电话音质 PCM
bash
ffmpeg -i input.mp3 -ar 8000 -ac 1 -f s16le output_8k.pcm3.4.2 压缩
比如 sbc:
bash
ffmpeg -i 输入文件 -acodec sbc -ab 64k -ar 16000 -ac 1 输出.sbc
bash
# SBC
ffmpeg -i 111.mp3 -acodec sbc -ab 64k -ar 16000 -ac 1 111s.sbc
# ADPCM 它能把 16 位的数据变成 4 位(4-bit)。
ffmpeg -i 111.mp3 -acodec adpcm_ima_wav -ar 16000 -ac 1 output_adpcm.wav
# opus
ffmpeg -i 111.mp3 -acodec libopus -b:a 16k -ar 16000 -ac 1 output.opus-b:a 16k:把声音码率(比特率)压到 16 Kbps(每秒只需要 2 KB 的流量)。
Opus 的压缩率是很强的,2 KB/s 的声音听起来依然非常清晰。但是,单片机想要解压它需要跑非常复杂的数学公式(浮点运算/高内存占用)
3.4.3 把 PCM 转成 WAV
调测单片机录音功能时需要用到,当我们使用 麦克风(咪头)和 ADC 录制用户说话时候,单片机录下来并存在 Flash 里的数据是 没有格式信息的裸数据(PCM),把这个文件拉到电脑上,电脑是打不开的。我们可以用 FFmpeg 转成标准 WAV 来听听录音质量。
bash
ffmpeg -f s16le -ar 16000 -ac 1 -i mcu_record.pcm out.wav- 这里要注意参数顺序,
-f s16le -ar 16000 -ac 1这三个参数被提到了 输入文件 -i 的前面!
这是在告诉 FFmpeg 这是单片机裸数据格式:"这个 mcu_record.pcm 没有任何文件头,它是用单片机按照有符号16位、16kHz、单声道录出来的。你必须强行用这个规格去读取它 " 。 -i mcu_record.pcm:单片机录的音output.wav:电脑可播放。
3.4.4 查看音频文件
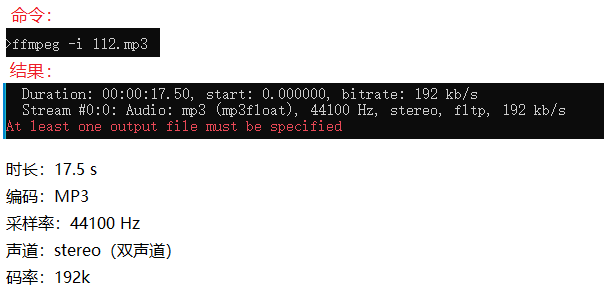
查看采样率 ,位深,声道,码率,编码格式:
bash
ffmpeg -i 111.mp3示例:
3.4.5 小结
FFmpeg 官方文档现在主推新写法,比如我们上面的一条语句:
bash
ffmpeg -i 111.mp3 -acodec sbc -ab 64k -ar 16000 -ac 1 111s.sbc新写法会写成如下:
bash
ffmpeg -i 111.mp3 -c:a sbc -b:a 64k -ar 16000 -ac 1 out.sbc在语音方面,新老写法改变的地方就 2 个:
- 指定音频编码器
老写法:-acodec sbc
新写法:-c:a sbc
-acodec变成了-c:a - 设置音频码率
老写法:-ab 64k
老写法:-b:a 64k
-ab变成了-b:a
总结来说语音开发记住这 5 个写法就够了:
-c:a编码器(sbc /opus/adpcm /pcm)
告诉 FFmpeg 用什么算法来压缩或处理声音-b:a码率(32k / 64k)
告诉 FFmpeg 一秒钟的数据量要限制在多大,只有在用压缩编码器时才需要它,原始 PCM 裸数据不需要它-ar采样率(16K / 8K)
告诉 FFmpeg 一秒钟截取多少个声音电压点,它直接决定了单片机定时器中断的频率-ac声道(1 = 单声道)
基本上嵌入式语音写 1 就行了-f指定输出格式(s16le = 16bit PCM)
告诉 FFmpeg 直接剥离所有文件头,输出纯采样数据,直接 bin2hex 烧录芯片
结语
本文我们了解了一些关于语音开发的基础知识,了解了语音采集播放实际应用的大概流程方案,以及介绍了一款很有用的音视频工具 FFmpeg 及其在语音开发时候的常用命令,希望对大家有所帮助!
后期如果有一些实际的应用案例,博主也会来给大家记录分享。
好了,本文就到这里。谢谢大家!