一、前言
我们在上一期中提到过fixture的参数化,当时我们说这个参数化我们会很少用,因为后面会介绍其他的方法就是数据驱动测试,不过我们本期介绍的方法是以参数化为基础的,我们的数据驱动测试是对参数化测试的基础上加了数据文件,那么接下来我们就开始进行本期的正题。
二、YAML文件
我们说有数据文件的叫做数据驱动测试,所以我们就来介绍一下数据文件怎么使用。
数据文件我们使用的是YAML文件来作为我们的数据驱动测试的文件。
1、为什么选择YAML
我们的文件类型有很多种,比如JSON、excel等等,我们为什么要选择YAML文件呢?
我们的YAML是一种数据格式文件,他和JSON一样,也是一种数据格式文件,而且我们的YAML是兼容JSON的。
YAML是文件,该文件的后缀格式是.yml或者.ymal
2、YAML在自动化测试中的用途
2.1 做全局配置
我们在自动化测试中会使用YAML文件作为全局配置文件:
- 设置环境变量
- 设置数据库连接信息
- 设置账号信息
- 设置日志格式
- 设置测试数据
2.2 用于编写测试用例
在YAML文件中编写的测试用例包含:
- 用例名称
- 用例步骤
- 用例的数据
- 用例的断言
3、YAML的语法规则
- 区分大小写
- 使用缩进表示层级(使用空格表示缩进)
- 使用#表示行注释
- 字符串有三种表示方式:
- 单引号
- 双引号
- 不使用引号(注意:想不使用引号,那么前提条件就是得没有特殊符号,得没有歧义才能使用这个)
4、YAML的数据类型
YMAL只有数据,没有什么循环呀等等,所以我们的数据分成如下三种类型:
4.1 标量(字面量)
标量是最基本的数据类型(可以直接写进去):
- 数字:
- 整数
- 浮点数
- 字符串
- 布尔值
- 空值
- 日期时间
例如:
首先新建一个文件data.yml
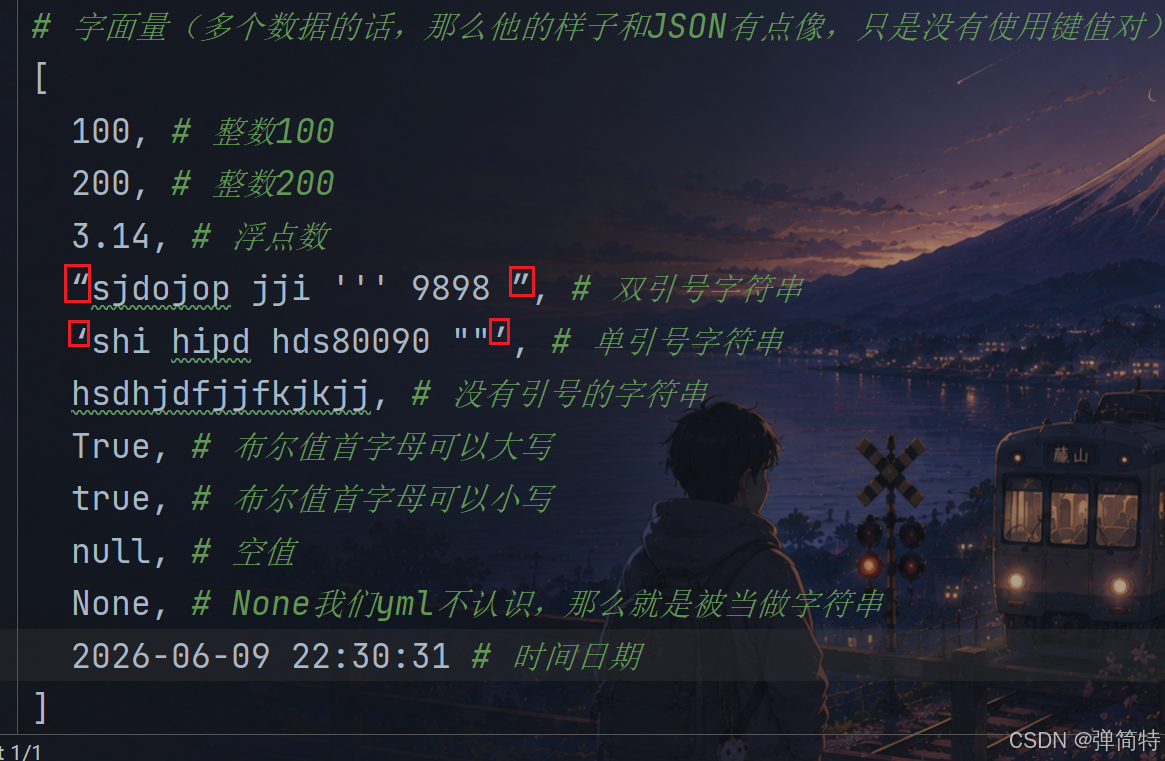
py
# 字面量
[
100, # 整数100
200, # 整数200
3.14, # 浮点数
"sjdojop jji ''' 9898 ", # 双引号字符串
'shi hipd hds80090 ""', # 单引号字符串
hsdhjdfjjfkjkjj, # 没有引号的字符串
True, # 布尔值首字母可以大写
true, # 布尔值首字母可以小写
null, # 空值
None, # None我们yml不认识,那么就是被当做字符串
2026-06-09 22:30:31 # 时间日期
]
4.2 数组(列表)
数组支持两种不同的写法,而且是可以混用的
1)JSON兼容写法
py
[ 1, 2, 3, 4, [ 2, 2, 3, 3 ], 8, 5, [ 4, [3, 4], 6, 7 ], 10 ]2)yaml自己的写法
就记住一句话,所有的同级横杆-构成列表(上述的中括号)
py
- 1
- 2
- 3
- 4
- - 2
- 2
- 3
- 3
- 8
- 5
- - 4
- - 3
- 4
- 6
- 7
- 10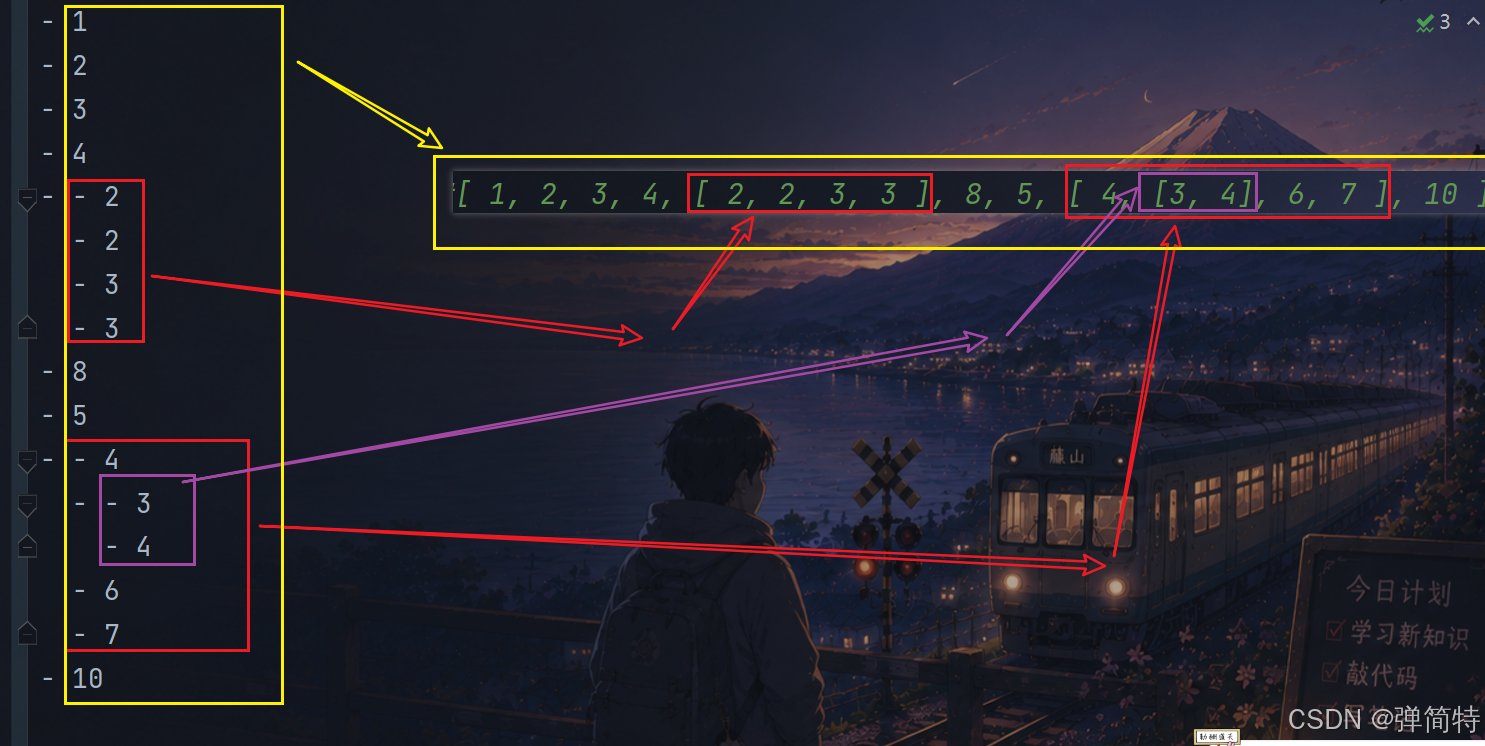
这样做的好处是什么呢?我们可以针对性的对每一个数据进行注释👇
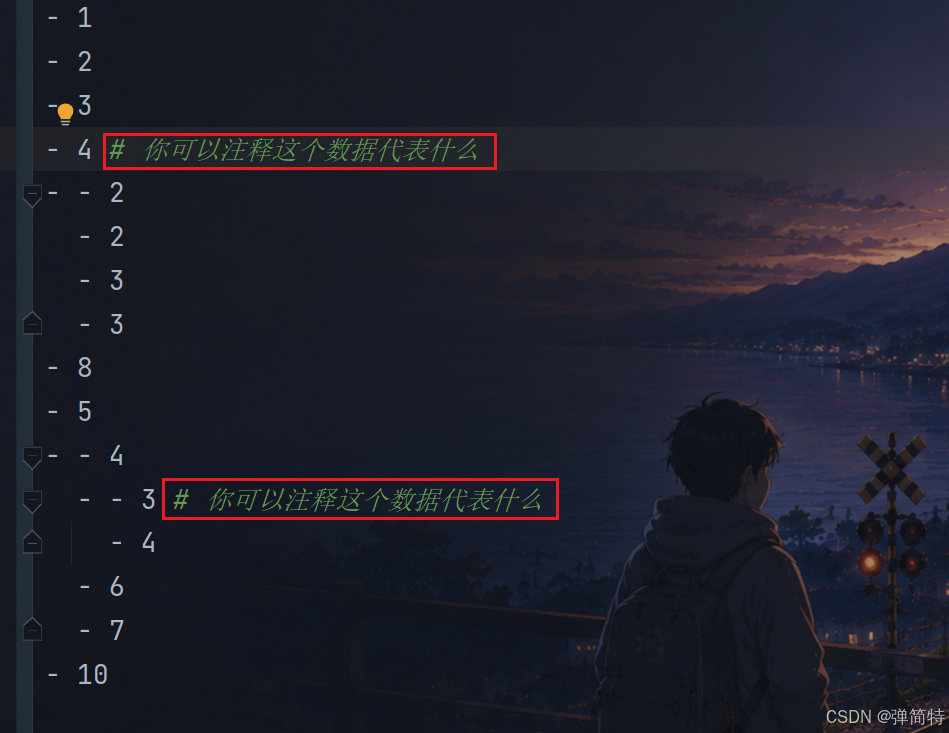
2)二者可以混合着使用:
yml
# 混着使用
- 1
- 2
- 3
- 4
- - 2
- 2
- 3
- 3
- 8
- 5
- [ 4, [3, 4], 6, 7 ]
- 104.3 对象(字典)
对象就是字典,也就是键值对。
我们的对象支持两种不同的写法:而且可以混着使用
1)JSON兼容写法
py
{"data01":100,"data02":200,"data03":{"a":10,"b":20}}2)YAML自己的写法(这个和学习springboot中yml一样的)
yaml
data01: 100
data02: 200
data03:
a: 10
b: 203)可以混合使用
yml
data01: 100
data02: 200
data03: {"a":10,"b":20}4.4 数据类型转换
我们的YAML会自动的去识别数据类型,但是你有没有想过,他自己去识别数据类型,会不会识别出错呢?比你写一个数字,他给你识别成了数字,但是你自己想写的是字符串呀,此时怎么办呢?
应对这样的一个场景,我们就给他做一个类型的转换。
语法: !!类型 值
- !!int 转为整数 【常用】
- !!str 转为字符串 【常用】
- !!float转为浮点数
- !!bool转为布尔值
- !!null转为空值
- !!seq转为数组
- !!map转为对象(字典)
例如 :
yml
# 数据类型转换
data01: !!str 100 # 变为字符串
data02: !!int '100' # 变为整数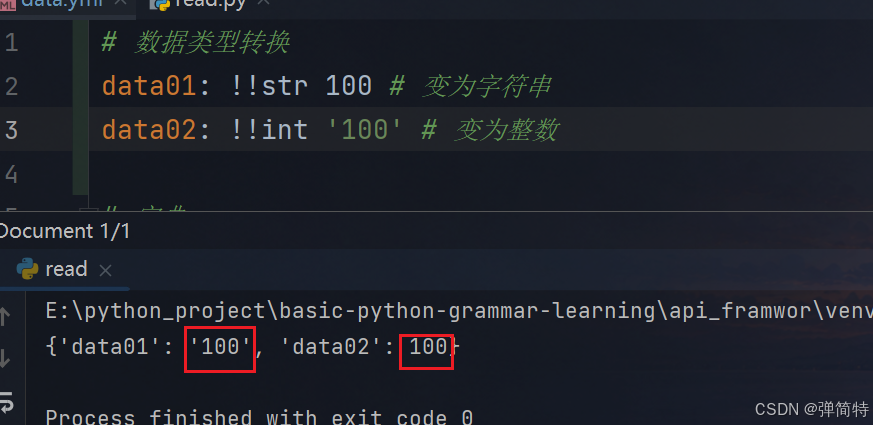
4.5 数据内容引用
有这样的一个场景,我们有data1如下所示:
yml
data1:
username: "root"
password: 123
a: 100
b: 200
url: 'xxxxx.xxx.xxx'那么现在我们又有一个data2,他的内容和data1一模一样,那么我们是直接将他赋值下来么?显然不是的,会有很多代码冗余
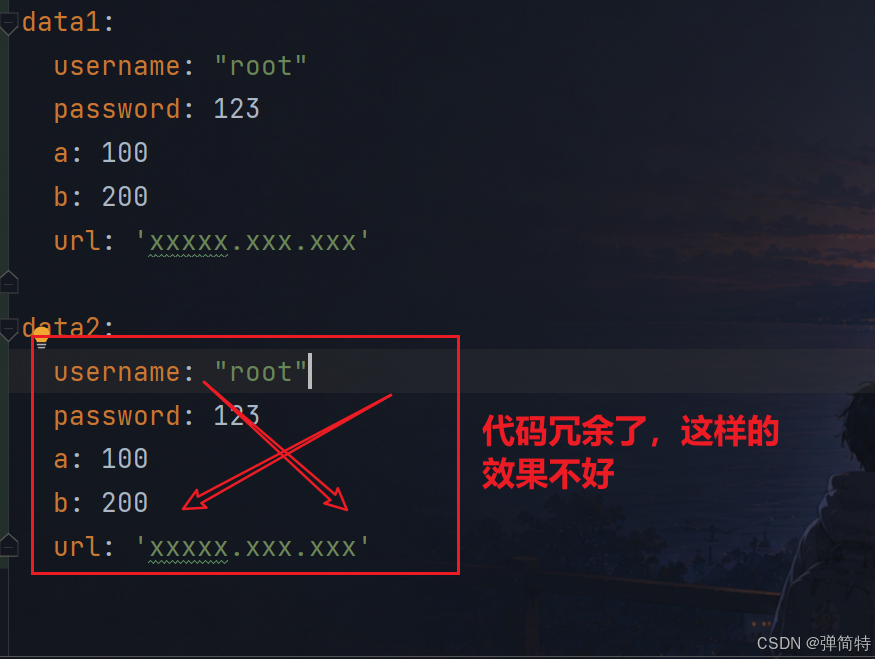
那么我们怎么做才能将data1的内容引用到data2呢?我们的思路就是将data1的内容搞到一个变量中,然后引用过去不就OK了吗?
所以我们会做以下的步骤来完成这个引用的过程:
1)建立锚点(也就是建立可复用的内容) :类似于创建一个变量名
yml
data1: &tan # 建立锚点(好比就是创建一个变量)
username: "root"
password: 123
a: 100
b: 200
url: 'xxxxx.xxx.xxx'2)建立引用(复用锚点的内容):类似于C语言中的指针那一块的东西
yml
data2:
*tan # 建立引用,好比就是找到我们刚才创建的那个变量3)内容解包:如果需要在你所引用的内容上新增新的东西,那么就先对我们的引用的东西进行解包,语法:<<: *变量,什么意思呢?看图

例如:
yml
data2:
<<: *tan # 建立引用,好比就是找到我们刚才创建的那个变量
key01: "新增的内容"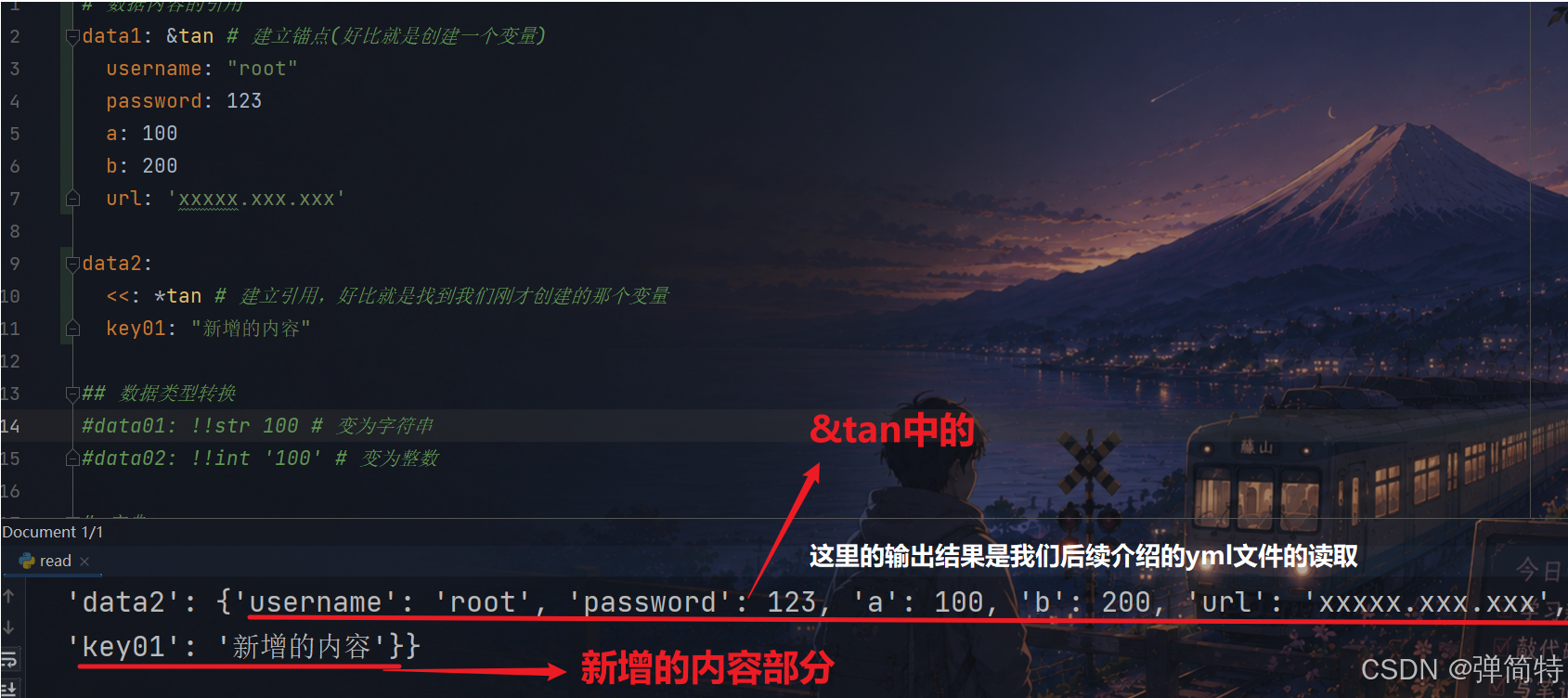
5、YAML文件读写
5.1 YAML文件内容读写的脚本实现
比如YAML中文件的内容:
py
# 字面量
[
100, # 整数100
200, # 整数200
3.14, # 浮点数
"sjdojop jji ''' 9898 ", # 双引号字符串
'shi hipd hds80090 ""', # 单引号字符串
hsdhjdfjjfkjkjj, # 没有引号的字符串
True, # 布尔值首字母可以大写
true, # 布尔值首字母可以小写
null, # 空值
None, # None我们yml不认识,那么就是被当做字符串
2026-06-09 22:30:31 # 时间日期
]我们去读取YAML文件中的数据的话,其实操作也很简单,因为很多的操作我们不需要自己写,人家已经给我们写好了, 我们就直接导入pyyaml来使用即可,但是使用之前,得先安装和这个pyyaml库,只有安装这个库,我们才能读取里面的数据内容,并且将里面的数据转为我们Python的数据类型。
bash
pip install pyyaml如何去读取呢?👇
我们先使用open函数打开这个yml文件,考虑到文件中有中文,那么在打开的时候,一定要指定字符集编码为utf-8,然后将这个打开的文件句柄存到我们的变量中

接下来,我们直接将这个文件句柄传入到yaml的safe_load() 安全加载方法中,就可以得到我们的数据
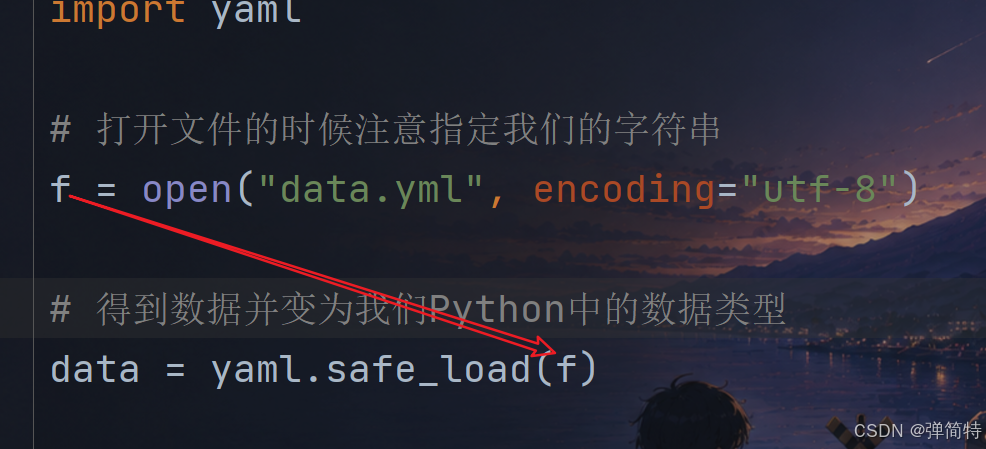
结果:

代码:
py
import yaml
# 打开文件的时候注意指定我们的字符串
f = open("data.yml", encoding="utf-8")
# 得到数据并变为我们Python中的数据类型
data = yaml.safe_load(f)
# 将数据打印
print(data)5.2 封装YAML文件读写的代码
我们上述直接写的是一个流水线脚本,那么你这里用了,到时候其他地方要使用的时候,就又得重新写,那么一般我们要实现复用,都是使用封装来实现,所以我们也会对YAML文件读取进行封装:
我们首先创建一个目录,这个目录就存我们的常用工具类:
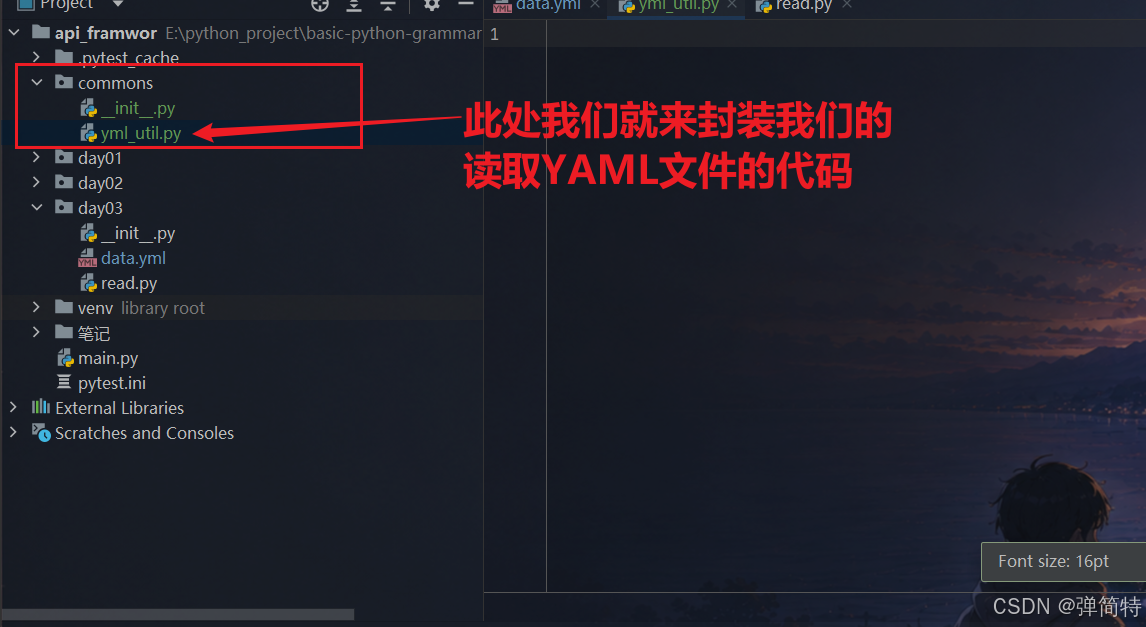
代码:
py
import yaml
# yml文件工具类
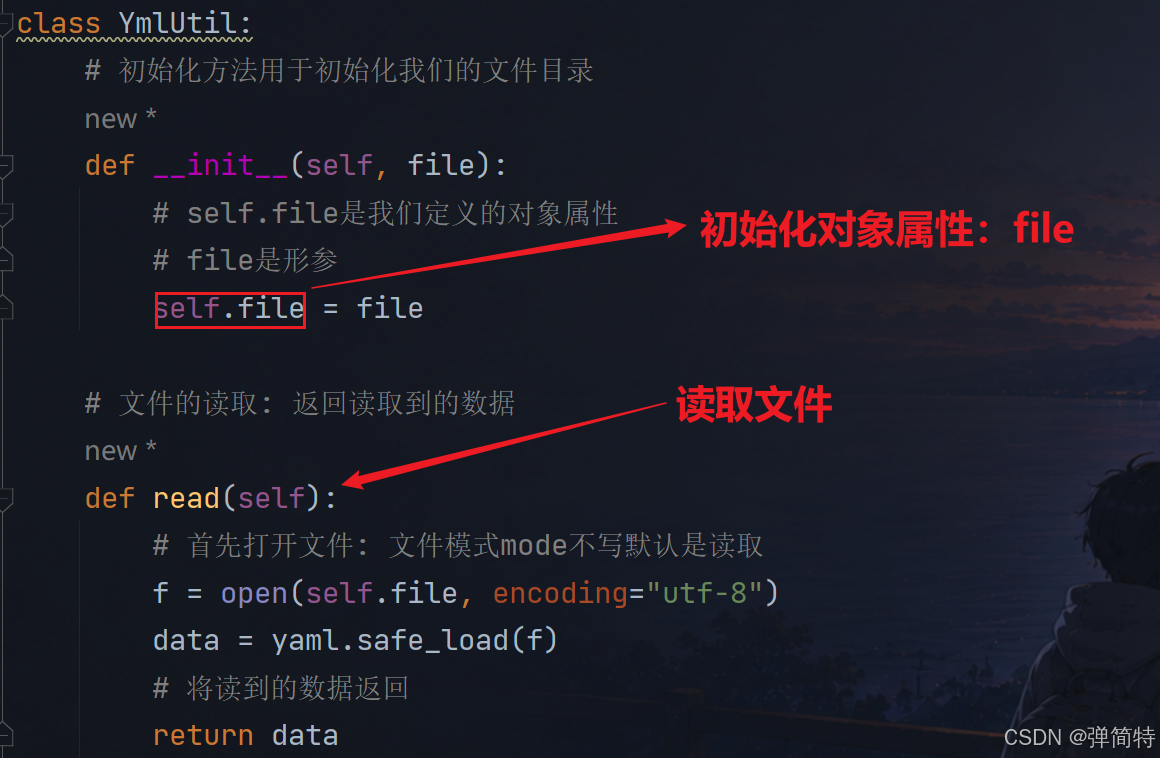
class YmlUtil:
# 初始化方法用于初始化我们的文件目录
def __init__(self, file):
# self.file是我们定义的对象属性
# file是形参
self.file = file
# 文件的读取: 返回读取到的数据
def read(self):
# 首先打开文件: 文件模式mode不写默认是读取
f = open(self.file, encoding="utf-8")
data = yaml.safe_load(f)
# 将读到的数据返回
return data
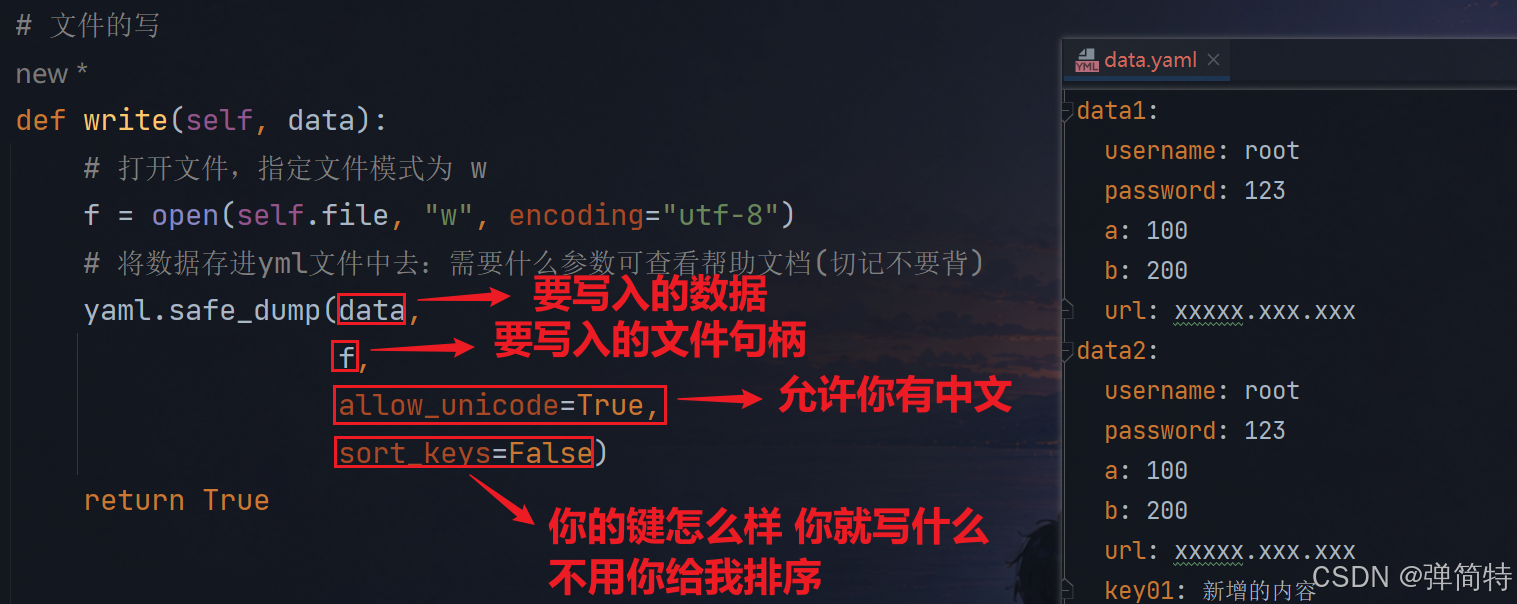
# 文件的写
def write(self, data):
# 打开文件,指定文件模式为 w
f = open(self.file, "w", encoding="utf-8")
# 将数据存进yml文件中去:需要什么参数可查看帮助文档(切记不要背)
yaml.safe_dump(data,
f,
allow_unicode=True,
sort_keys=False)
return True解释 :
示例:
py
# 导入我们的工具类
from commons.yml_util import YmlUtil
# 实例化对象
yaml1 = YmlUtil("data.yml") # 读取
yaml2 = YmlUtil("data.yaml") # 写入
# 读取
data = yaml1.read()
print(data)
# 写入
yaml2.write(data)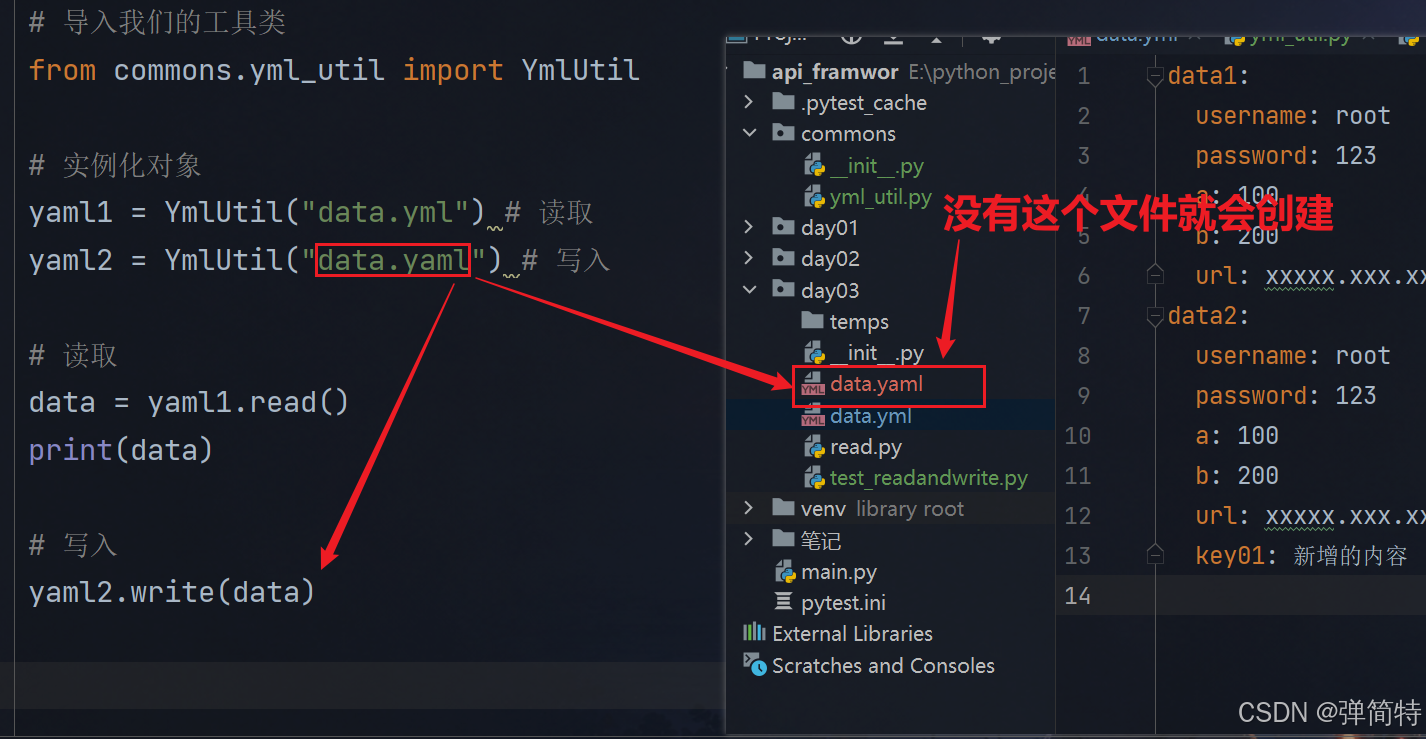
三、pytest之parametrize数据驱动测试
我们介绍上述的YAML文件的核心作用就是为了进行数据驱动测试。
1、pytest参数化测试
parametrize 译为参数化。
场景:当多个用例相似的时候,可以将其有差异的内容提取到参数中,再通过标记进行参数化的测试。
比如,我们有以下的测试用例:
py
def test_add_01():
a = 1
b = 2
c = a + b
assert c == 3
def test_add_02():
a = "1"
b = "2"
c = a + b
assert c == "12"
def test_add_03():
a = [1,]
b = [2,]
c = a + b
assert c == [1,2]分析:
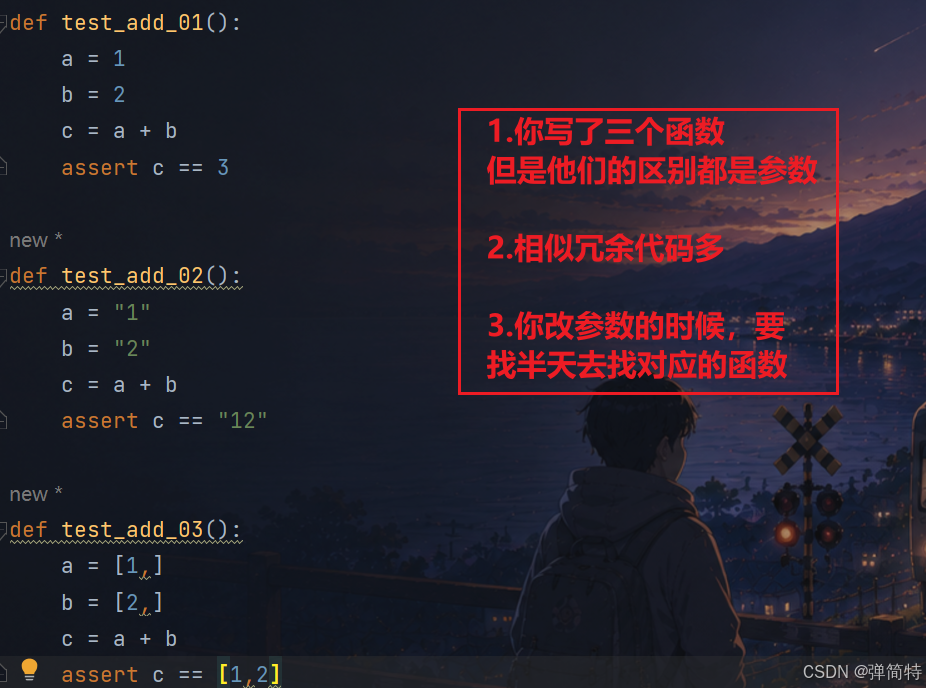
为了解决这样的一个情况,我们就使用参数化测试,使用参数化之后,我们就只需要写一个测试用例即可👇
1.1 第一种方式
使用@pytest.mark.parametrize那么意味着会为我们的用例提供一系列 的参数,然后他会根据参数进行执行。👇
语法:
py
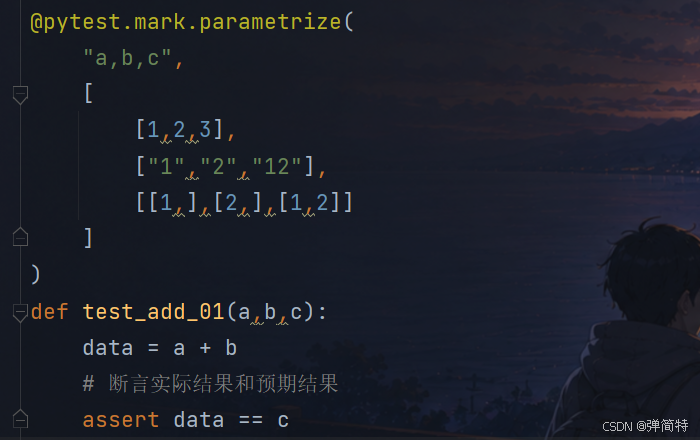
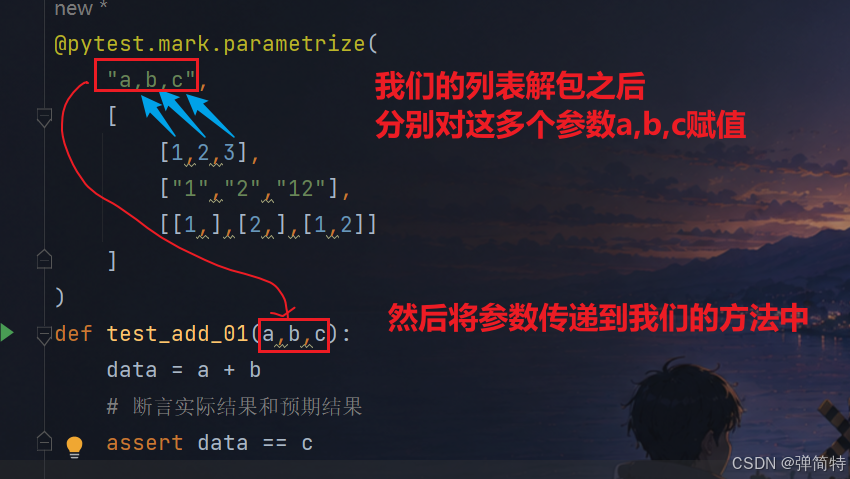
@pytest.mark.parametrize("参数名1,参数名2,...",[[参数值1,参数值2,...],[参数值1,参数值2,...],[参数值1,参数值2,...],...])示例:
py
@pytest.mark.parametrize(
"a,b,c",
[
[1,2,3],
["1","2","12"],
[[1,],[2,],[1,2]]
]
)
def test_add_01(a,b,c):
data = a + b
# 断言实际结果和预期结果
assert data == c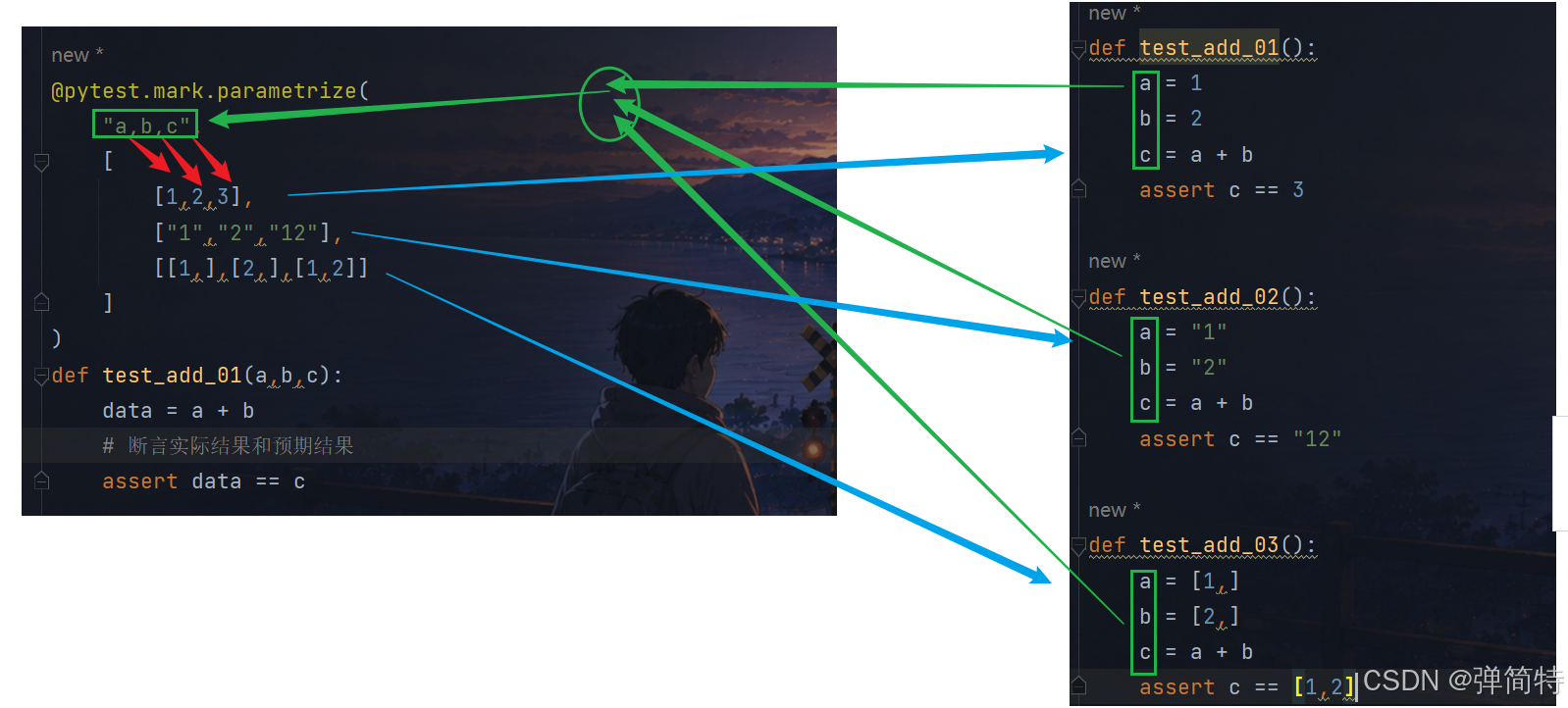
原理上说:
是将多个用例代码,合并为一份代码。
效果上看:
一份代码生成了若干用例。
参数化的好处:把多个用例合成一份代码,但是这份代码可以生成多分用例。
1.2 第二种方式
现在来看一个问题:
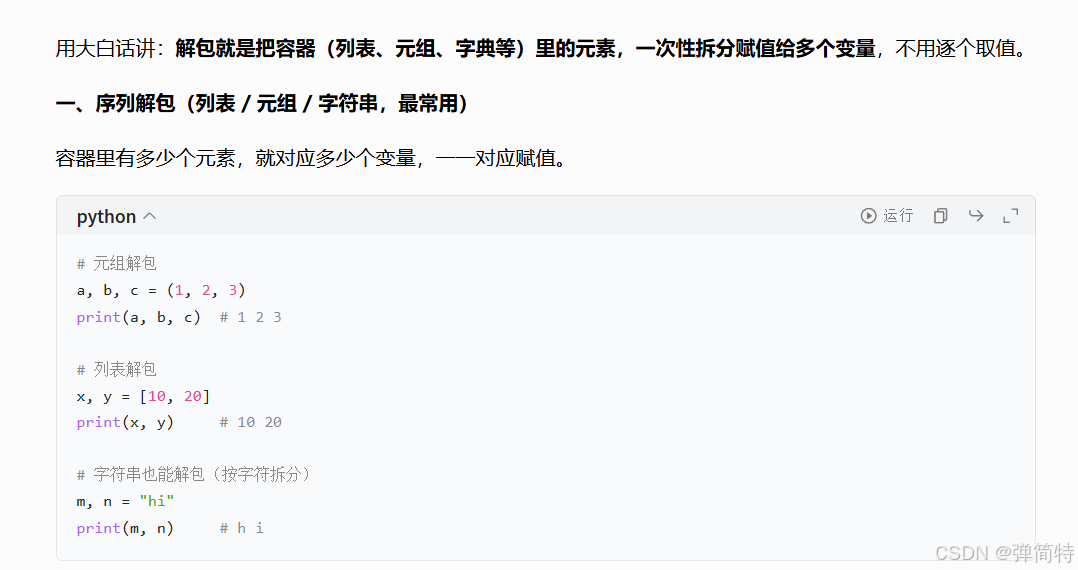
首先,我们来看一个概念:解包
那么我们有多个参数的时候👇
但是如果,我有300个,甚至更多的参数,那么你写的动吗?

所以我们提供了下面的方法:你别解包一个一个的赋值了,你直接给我整个列表,然后我手动解包
py
@pytest.mark.parametrize(
"tan",
[
[1,2,3],
["1","2","12"],
[[1,],[2,],[1,2]]
]
)
def test_add_01(tan):
# 手动解包
a, b, c = tan
data = a + b
# 断言实际结果和预期结果
assert data == c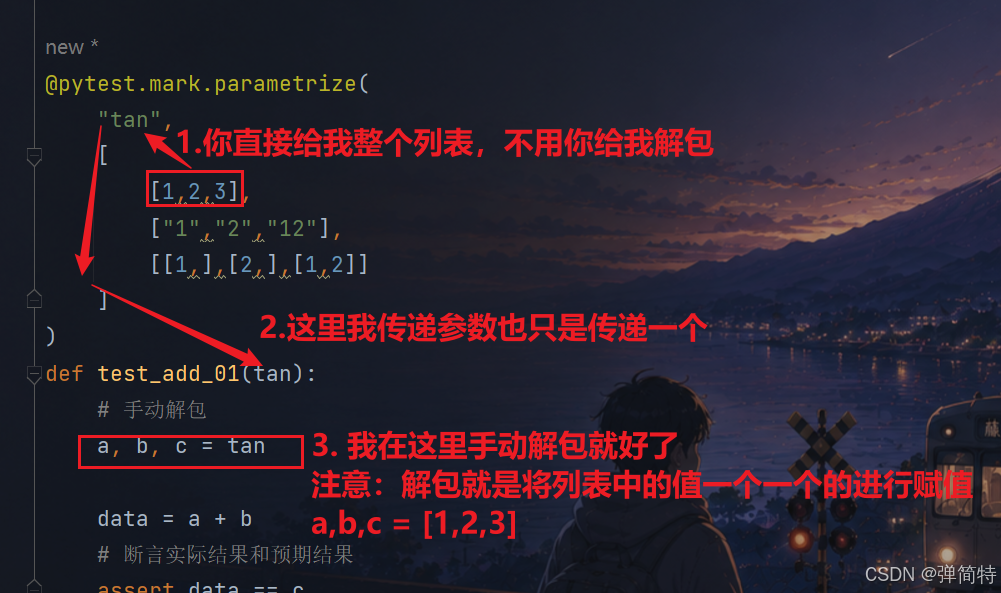
结果也是正确的:
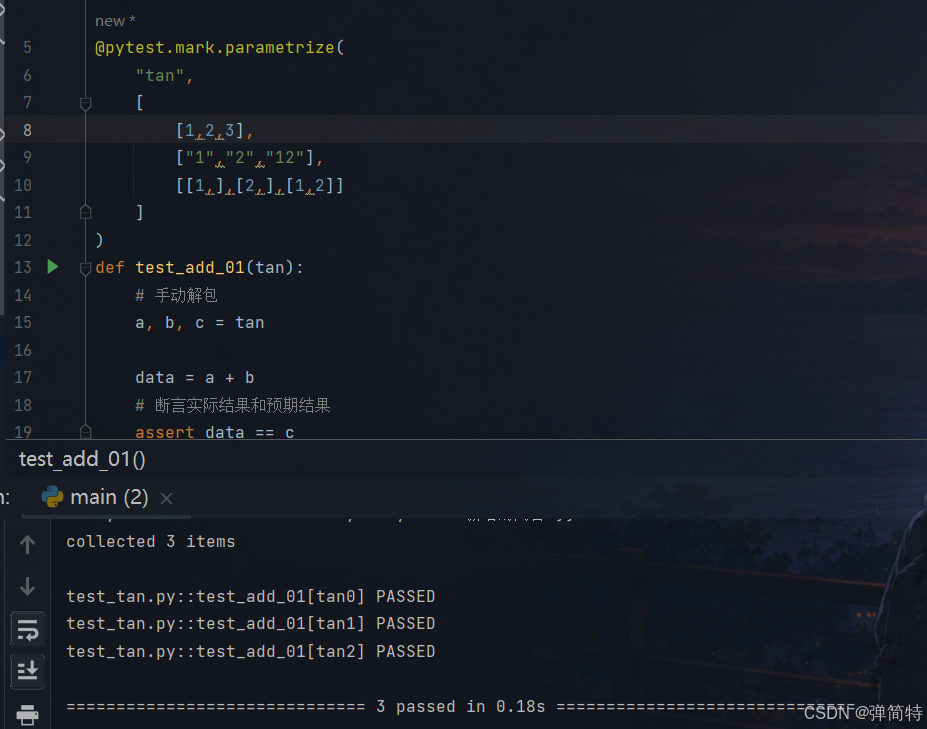
当然,如果不想手动解包,那么我们就自己读取值:
py
@pytest.mark.parametrize(
"tan",
[
[1,2,3],
["1","2","12"],
[[1,],[2,],[1,2]]
]
)
def test_add_01(tan):
# 自己读取值
a = tan[0]
b = tan[1]
c = tan[2]
data = a + b
# 断言实际结果和预期结果
assert data == c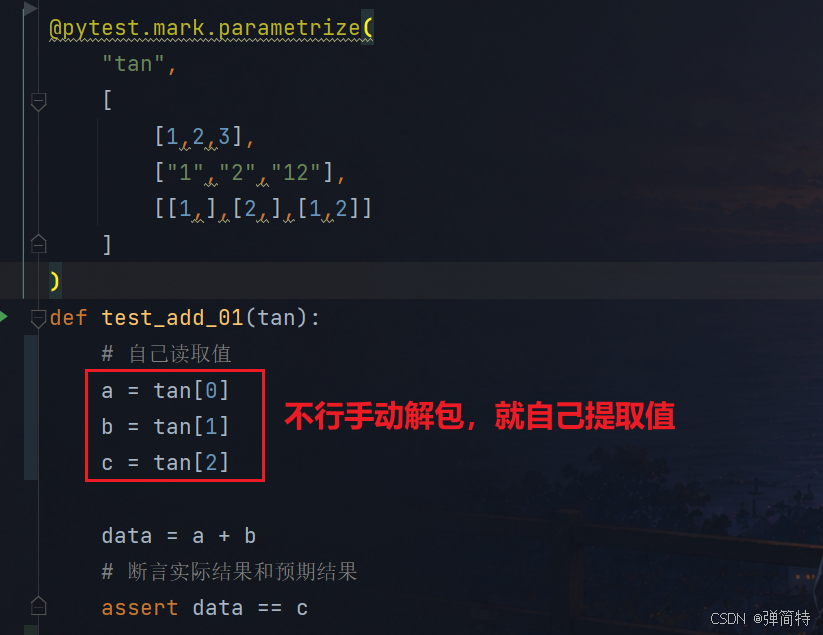
那么参数化测试我们上述介绍完第一种方式和第二种方式:
- 第一种方式:自动解包,用于参数少的时候
- 第二种方式:手动解包,参数多的时候
2、参数化测试的用例名
我们这部分介绍什么呢?
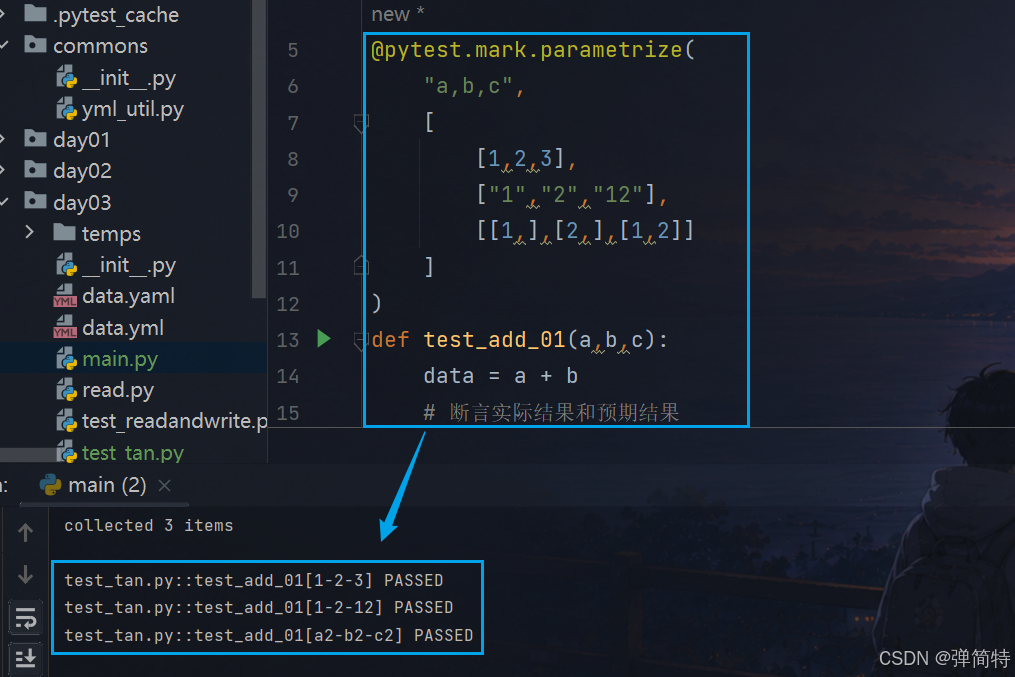
你看咱们的执行结果:
1)第一种情况:自动解包,那么用例名就是参数值,如下
py
test_tan.py::test_add_01[1-2-3] PASSED
test_tan.py::test_add_01[1-2-12] PASSED
test_tan.py::test_add_01[a2-b2-c2] PASSED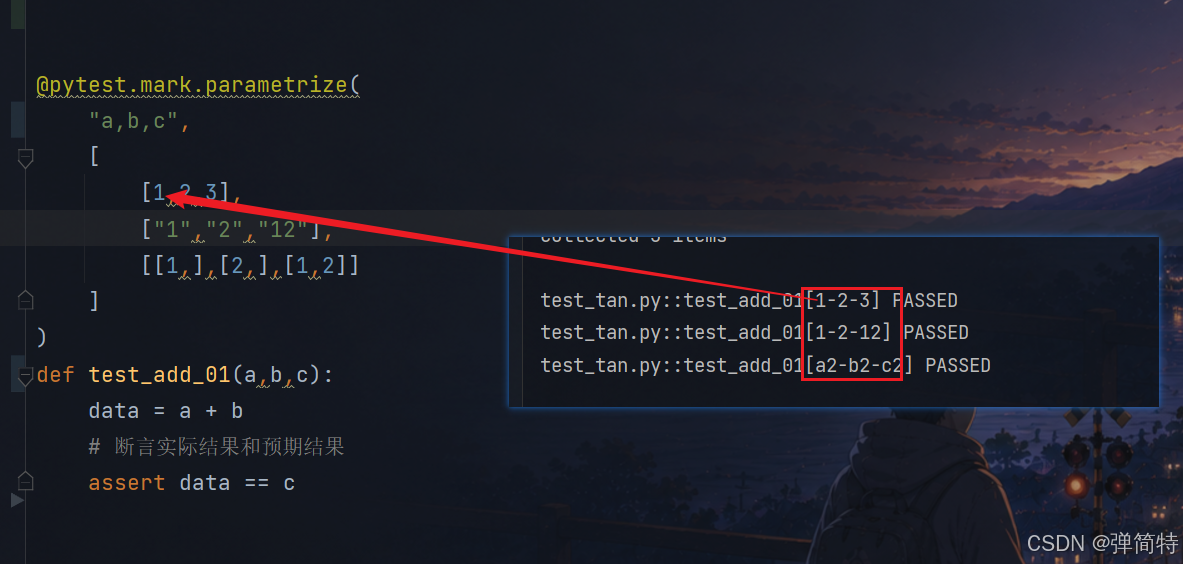
2)第二种情况:如果是手动解包(不是自动解包)那么用例名为:参数名+数字,如下
py
test_tan.py::test_add_01[tan0] PASSED
test_tan.py::test_add_01[tan1] PASSED
test_tan.py::test_add_01[tan2] PASSED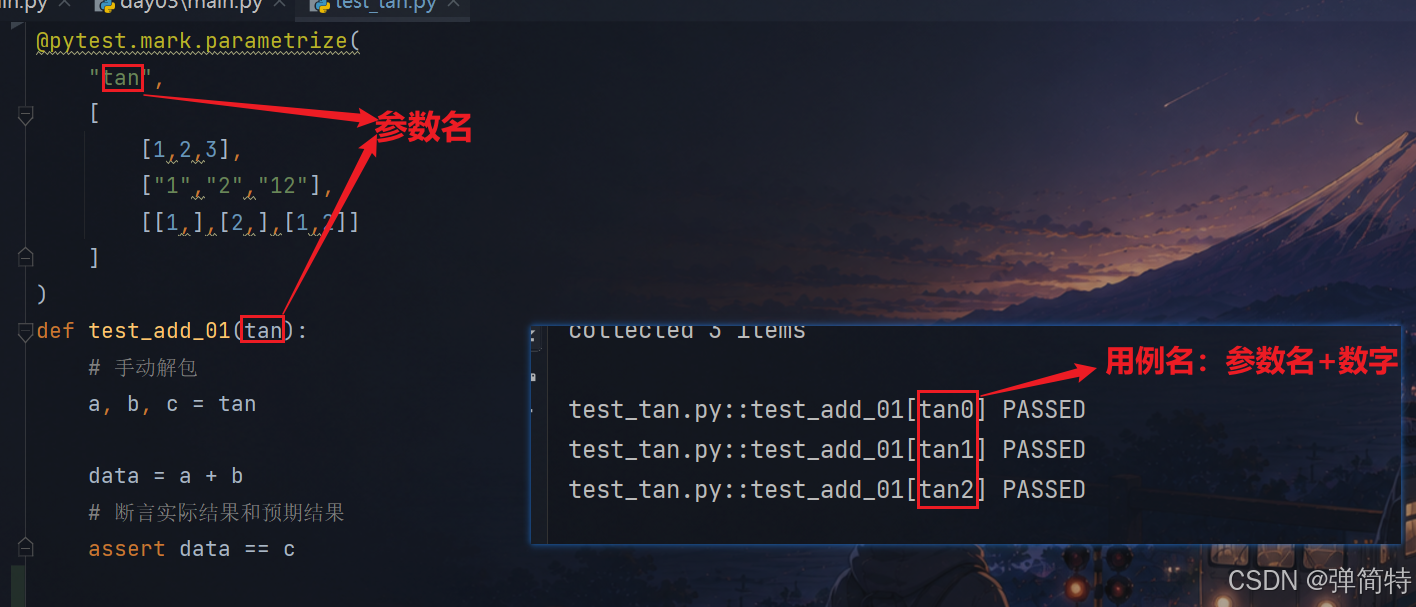
2)如果用例有中文
py
@pytest.mark.parametrize(
"a,b,c",
[
[1,2,3],
["1","2","12"],
["你","好","你好"],
[[1,],[2,],[1,2]]
]
)
def test_add_01(a,b,c):
data = a + b
# 断言实际结果和预期结果
assert data == c
# 结果:
test_tan.py::test_add_01[1-2-3] PASSED
test_tan.py::test_add_01[1-2-12] PASSED
test_tan.py::test_add_01[\u4f60-\u597d-\u4f60\u597d] PASSED
test_tan.py::test_add_01[a3-b3-c3] PASSED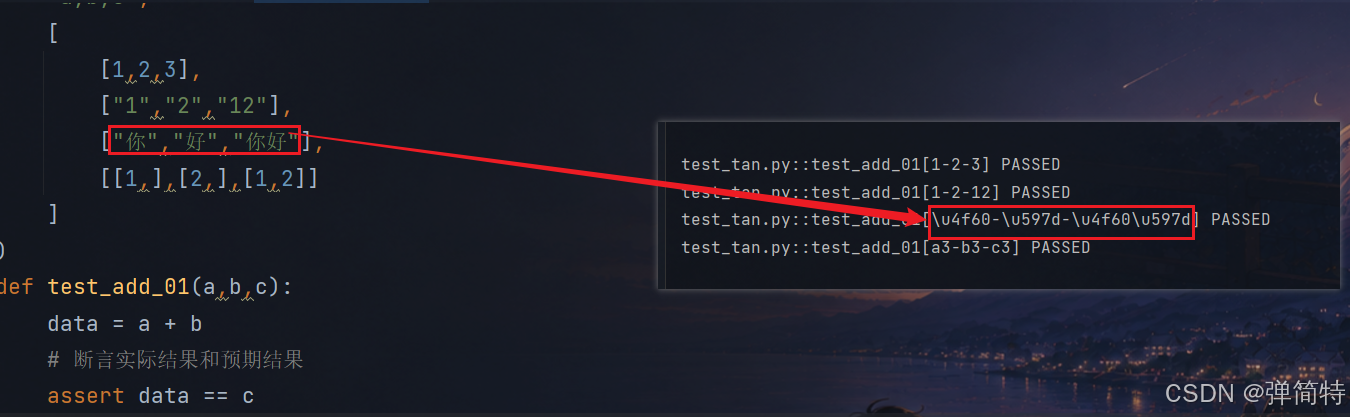
如何解决中文显示问题?我们只需要做一个配置
在我们的pytest.ini配置文件中(这个文件是我们的之前博客中提到的,他是对pytest的执行做配置的) 我们在这个配置文件中加一行配置:
py
[pytest] # 如果有这个就不用管
disable_test_id_escaping_and_forfeit_all_rights_to_community_support=true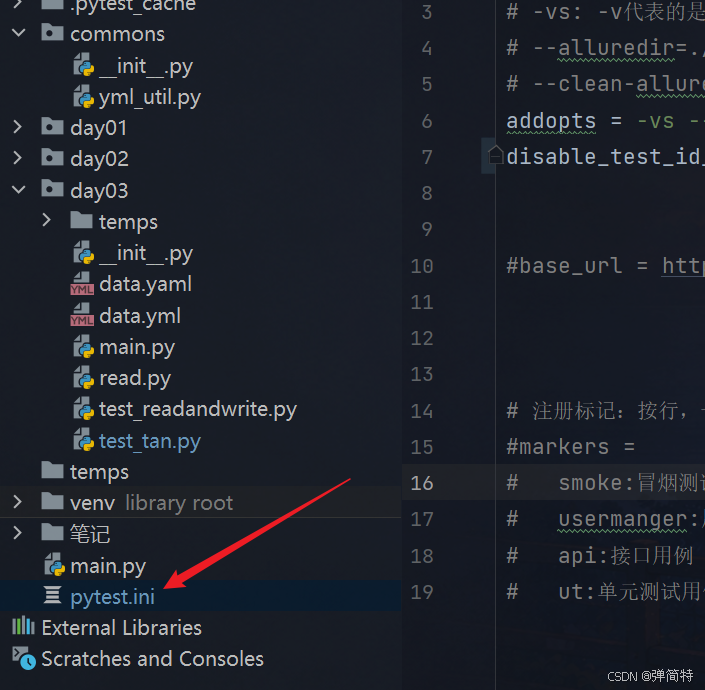
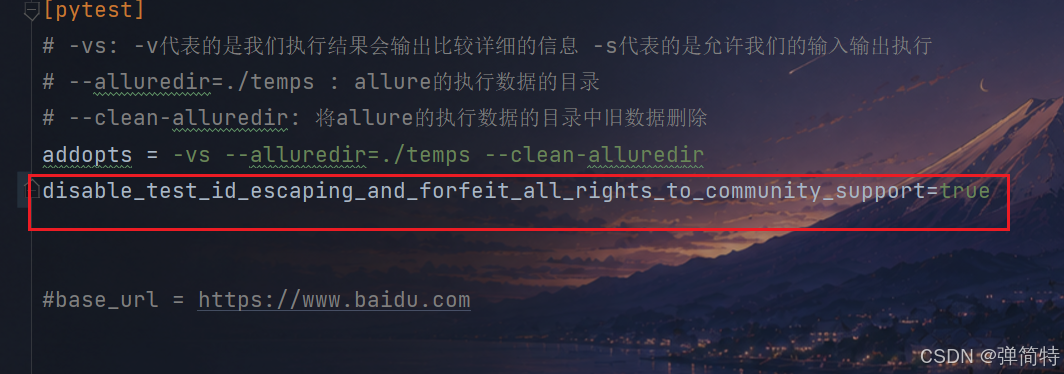
配置完毕之后结果:
py
test_tan.py::test_add_01[1-2-3] PASSED
test_tan.py::test_add_01[1-2-12] PASSED
test_tan.py::test_add_01[你-好-你好] PASSED
test_tan.py::test_add_01[a3-b3-c3] PASSED4)我们自动指定用例名
用法:在之前的基础上,给@pytest.mark.parametrize()多加一个参数ids
例如:
py
@pytest.mark.parametrize(
"a,b,c",
[
[1,2,3],
["1","2","12"],
["你","好","你好"],
[[1,],[2,],[1,2]]
],
ids=[
"数字相加",
"数字字符串相加",
"汉字相加",
"列表相加"
]
)
def test_add_01(a,b,c):
data = a + b
# 断言实际结果和预期结果
assert data == c
# 结果:
test_tan.py::test_add_01[数字相加] PASSED
test_tan.py::test_add_01[数字字符串相加] PASSED
test_tan.py::test_add_01[汉字相加] PASSED
test_tan.py::test_add_01[列表相加] PASSED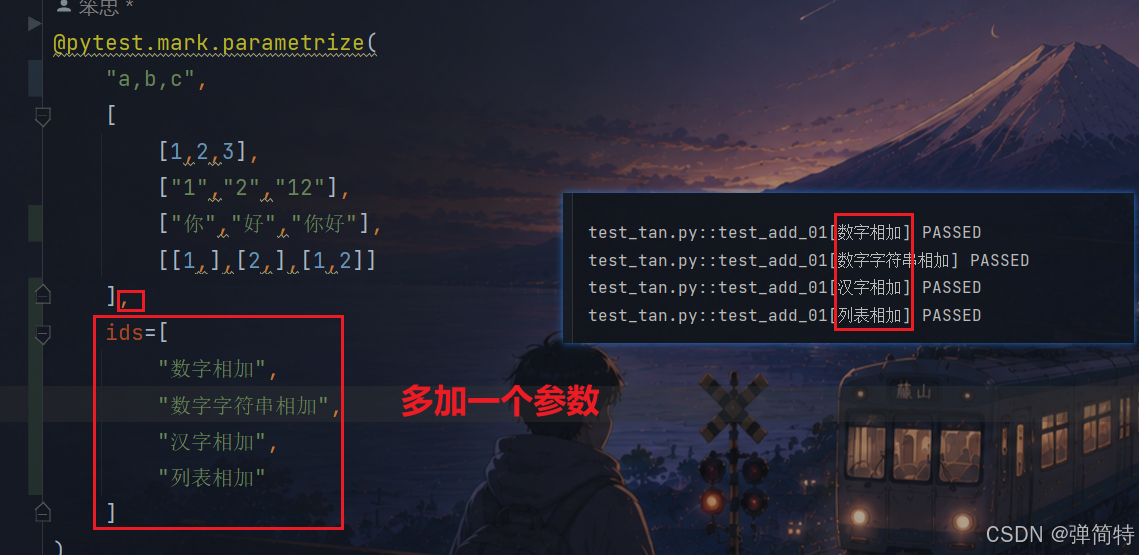
3、数据驱动测试
上述我们介绍了参数化测试之后,那么我们就可以来完成数据驱动测试了,数据驱动测试是在参数化基础上多了数据文件,即:
数据驱动测试=参数化测试+数据文件
那么我们看具体例子:
首先我们新建一个data目录
然后我们在这个目录中新建一个YAML文件add_plus.yaml
然后我们在里面去写内容,写什么呢?我们会写参数或者我们的ids用例名进入,OK,那么请看如下操作:
1)我们将我们的参数拿进去
yml
[
[1,2,3],
["1","2","12"],
["你","好","你好"],
[[1,],[2,],[1,2]]
]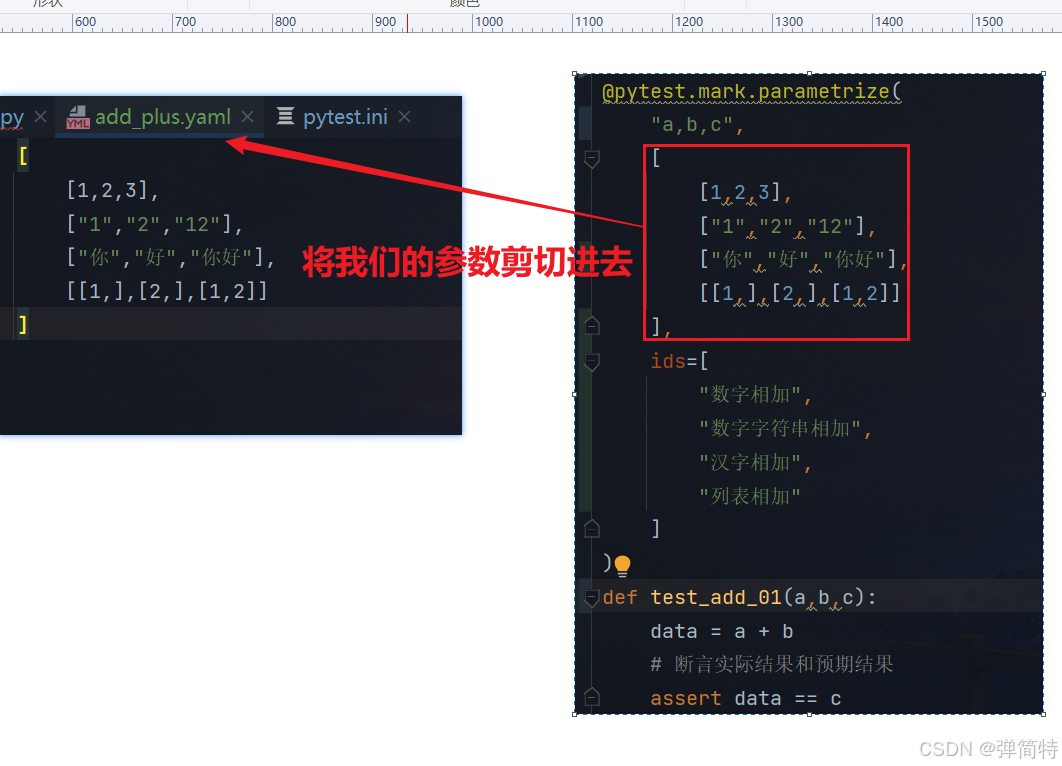
剪切之后,我们此处的参数就爆红了
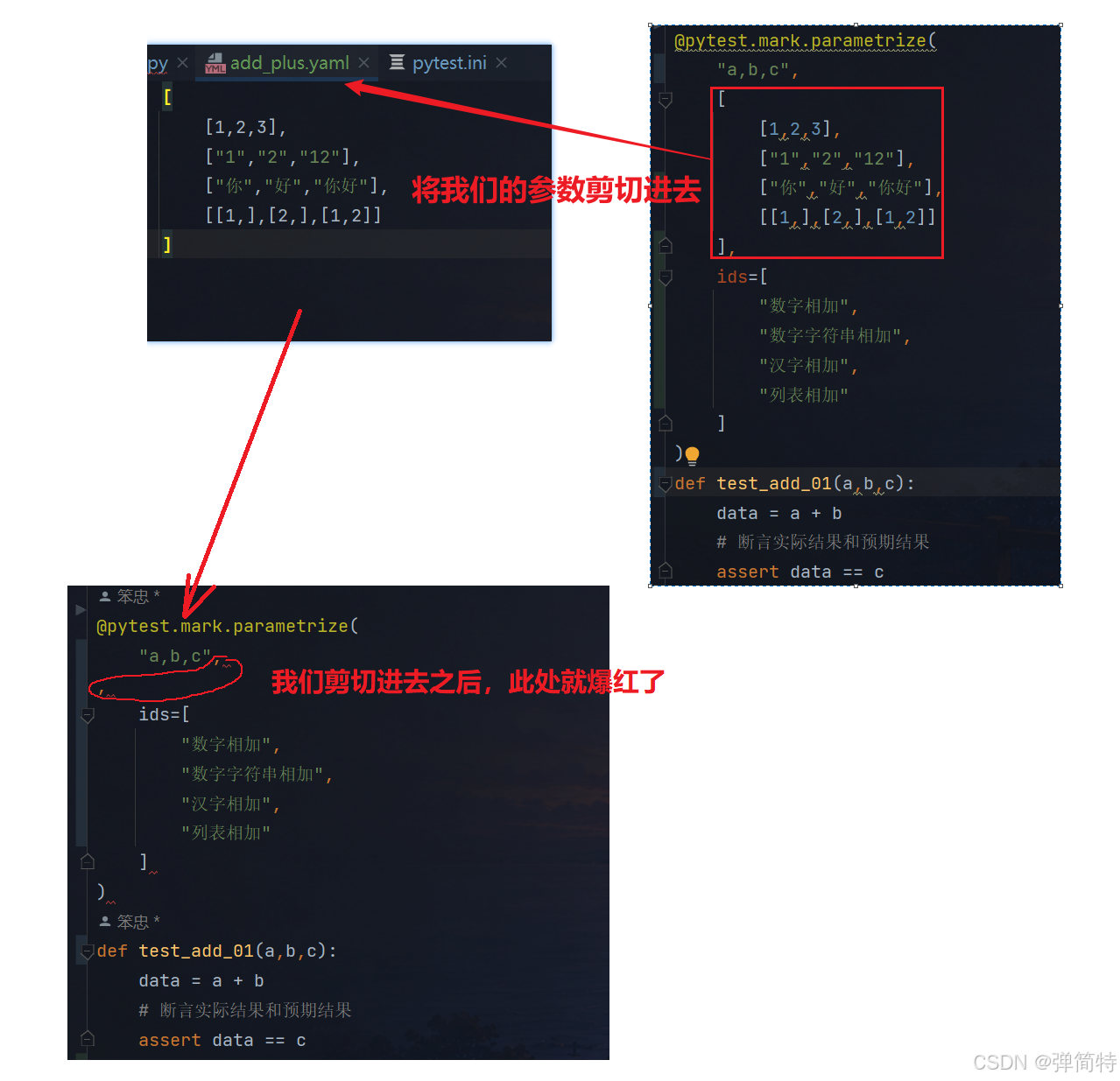
那么,接下来我们就使用我们之前封装的读取YAML文件的工具类,来读取参数,然后放在爆红处:
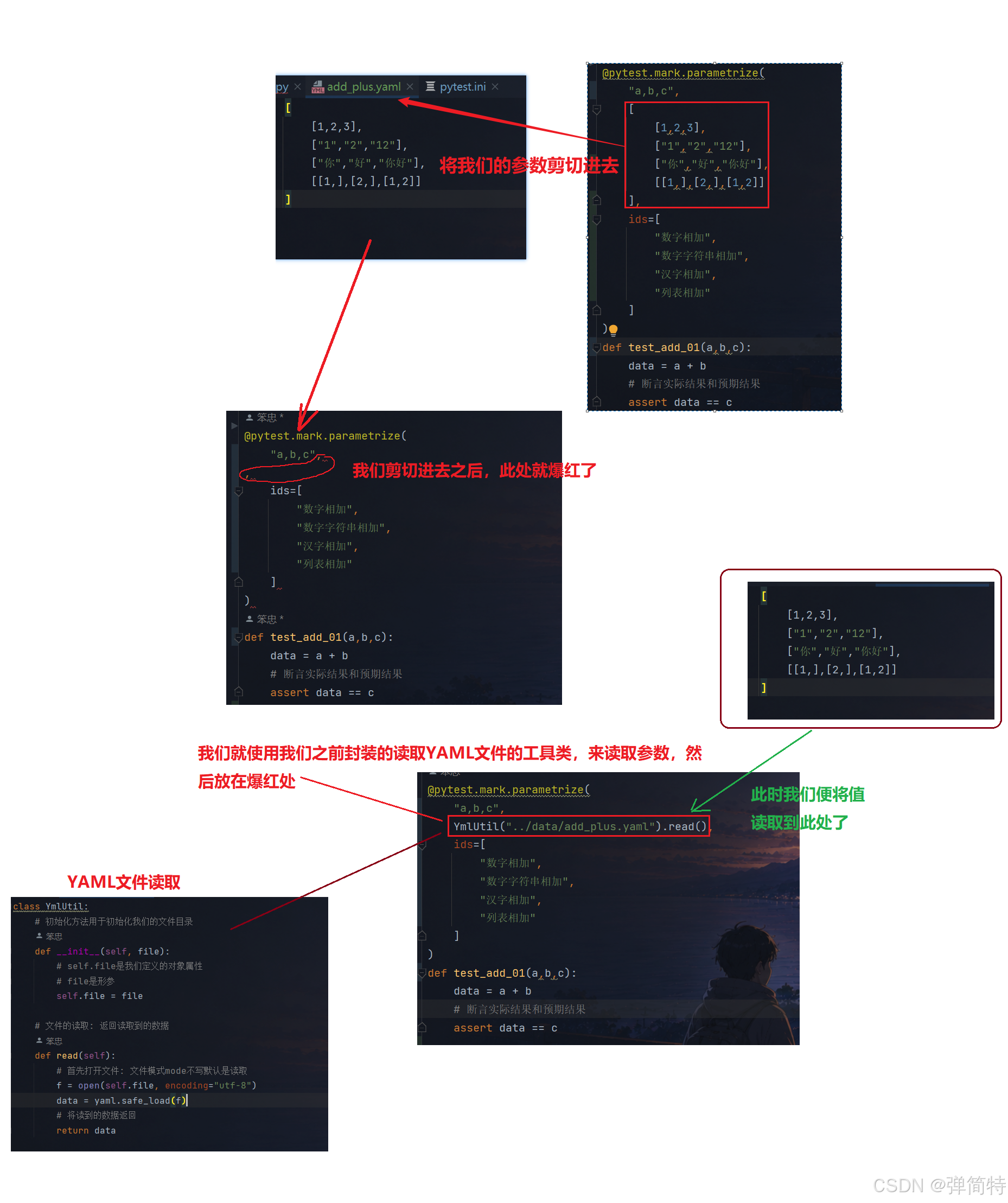
代码 :
py
# 测试用例
import pytest
from commons.yml_util import YmlUtil
@pytest.mark.parametrize(
"a,b,c",
YmlUtil("../data/add_plus.yaml").read(),
ids=[
"数字相加",
"数字字符串相加",
"汉字相加",
"列表相加"
]
)
def test_add_01(a,b,c):
data = a + b
# 断言实际结果和预期结果
assert data == c
py
# 数据驱动文件
[
[1,2,3],
["1","2","12"],
["你","好","你好"],
[[1,],[2,],[1,2]]
]
py
# YAML文件读取封装
import yaml
# yml文件工具类
class YmlUtil:
# 初始化方法用于初始化我们的文件目录
def __init__(self, file):
# self.file是我们定义的对象属性
# file是形参
self.file = file
# 文件的读取: 返回读取到的数据
def read(self):
# 首先打开文件: 文件模式mode不写默认是读取
f = open(self.file, encoding="utf-8")
data = yaml.safe_load(f)
# 将读到的数据返回
return data
# 文件的写
def write(self, data):
# 打开文件,指定文件模式为 w
f = open(self.file, "w", encoding="utf-8")
# 将数据存进yml文件中去:需要什么参数可查看帮助文档(切记不要背)
yaml.safe_dump(data,
f,
allow_unicode=True,
sort_keys=False)
return True结果和解释 :
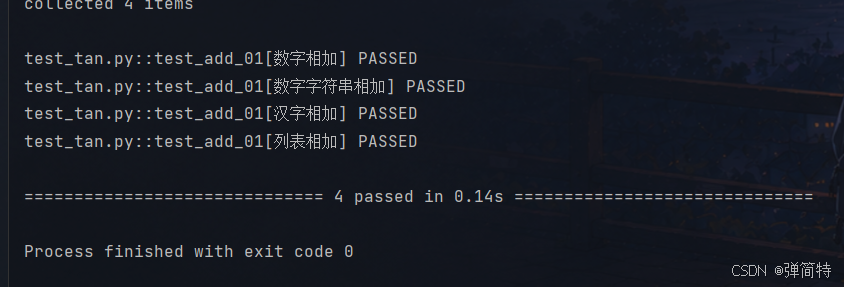
那么接下里我们有一个问题:
我们为什么要这么做呢?
答:我们将参数提取到文件中,好处后续我们该参数的时候,不用修改代码,直接去修改文件就行了,提高了我们的维护性。
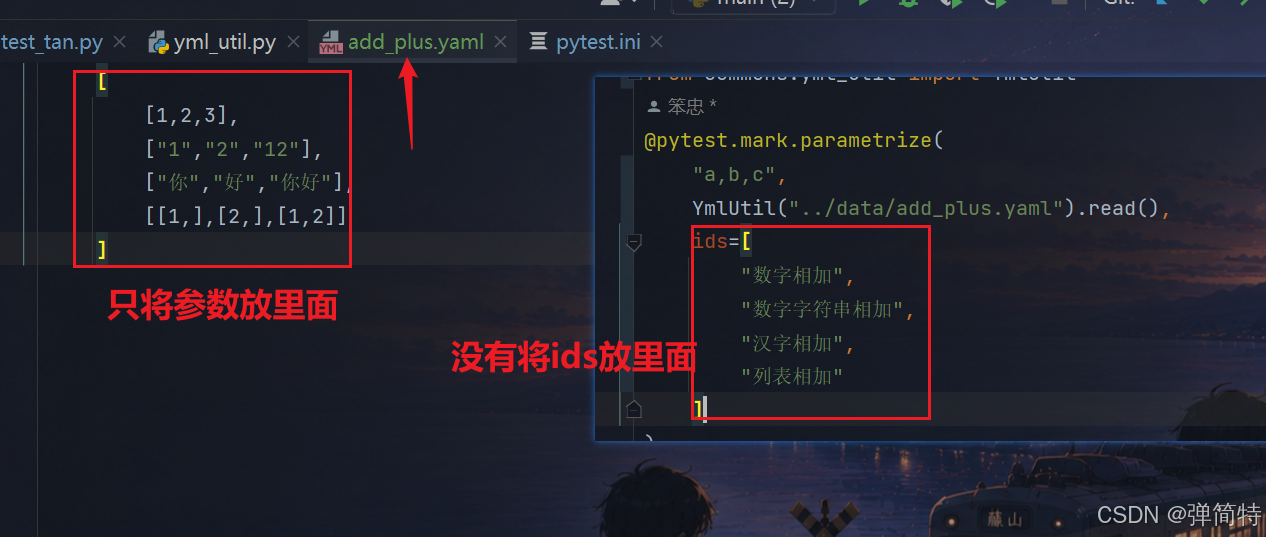
注意,我们测试数据是提前生成好的,不是你随机去动态生成的YAML文件中只有数据
那么我们YAML中也有局限性,比如我们只将参数放里面,但是ids没有放里面,那么当我增加用例的时候就会报错:
你看
如果你去YAML中增加了一个用例:
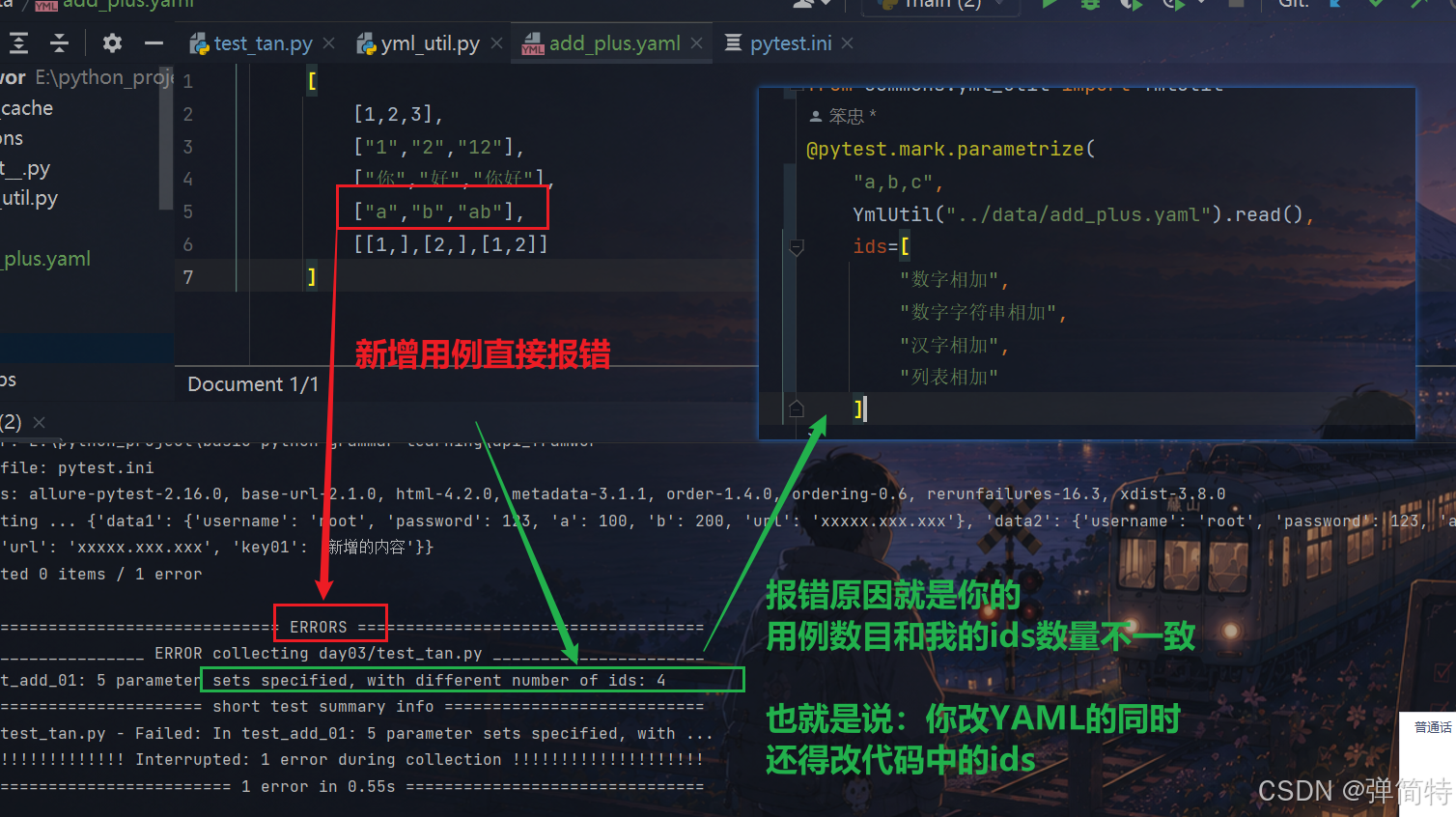
如图,我们改YAML的同时还得修改代码中的ids,那么这样并不是很友好,所以怎么办?
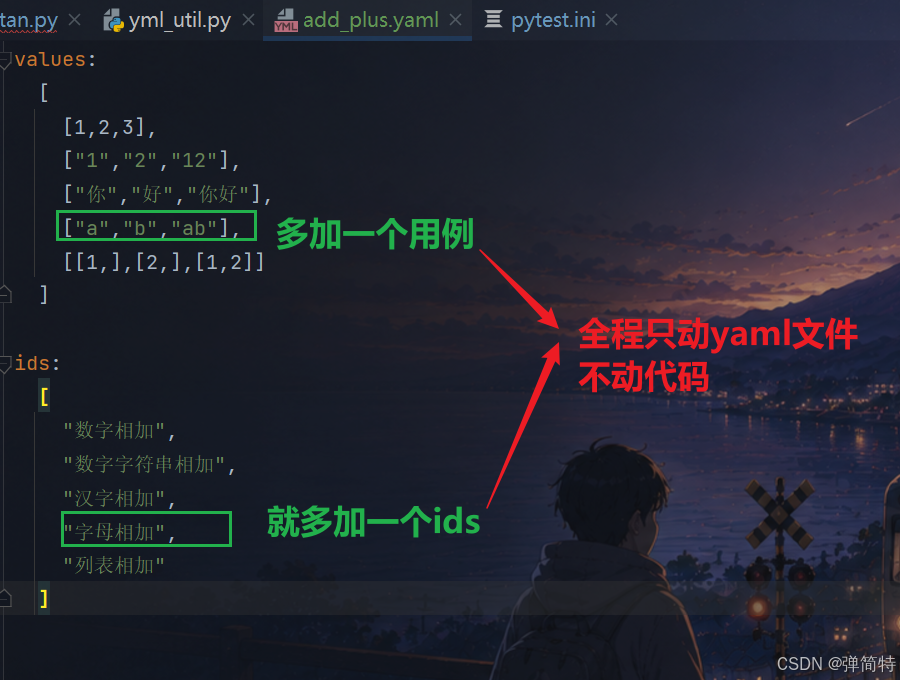
我们就连同ids也放进YAML中去就行了:
不过我们yaml中有多个对象,我们使用的是字典形式,得给他起一个key
yml
values:
[
[1,2,3],
["1","2","12"],
["你","好","你好"],
["a","b","ab"],
[[1,],[2,],[1,2]]
]
ids:
[
"数字相加",
"数字字符串相加",
"汉字相加",
"字母相加",
"列表相加"
]
那么,我们在代码中读取配置文件的方式:注意多写就会了
py
import pytest
from commons.yml_util import YmlUtil
@pytest.mark.parametrize(
"a,b,c",
YmlUtil("../data/add_plus.yaml").read()["values"],
ids=YmlUtil("../data/add_plus.yaml").read()["ids"]
)
def test_add_01(a,b,c):
data = a + b
# 断言实际结果和预期结果
assert data == c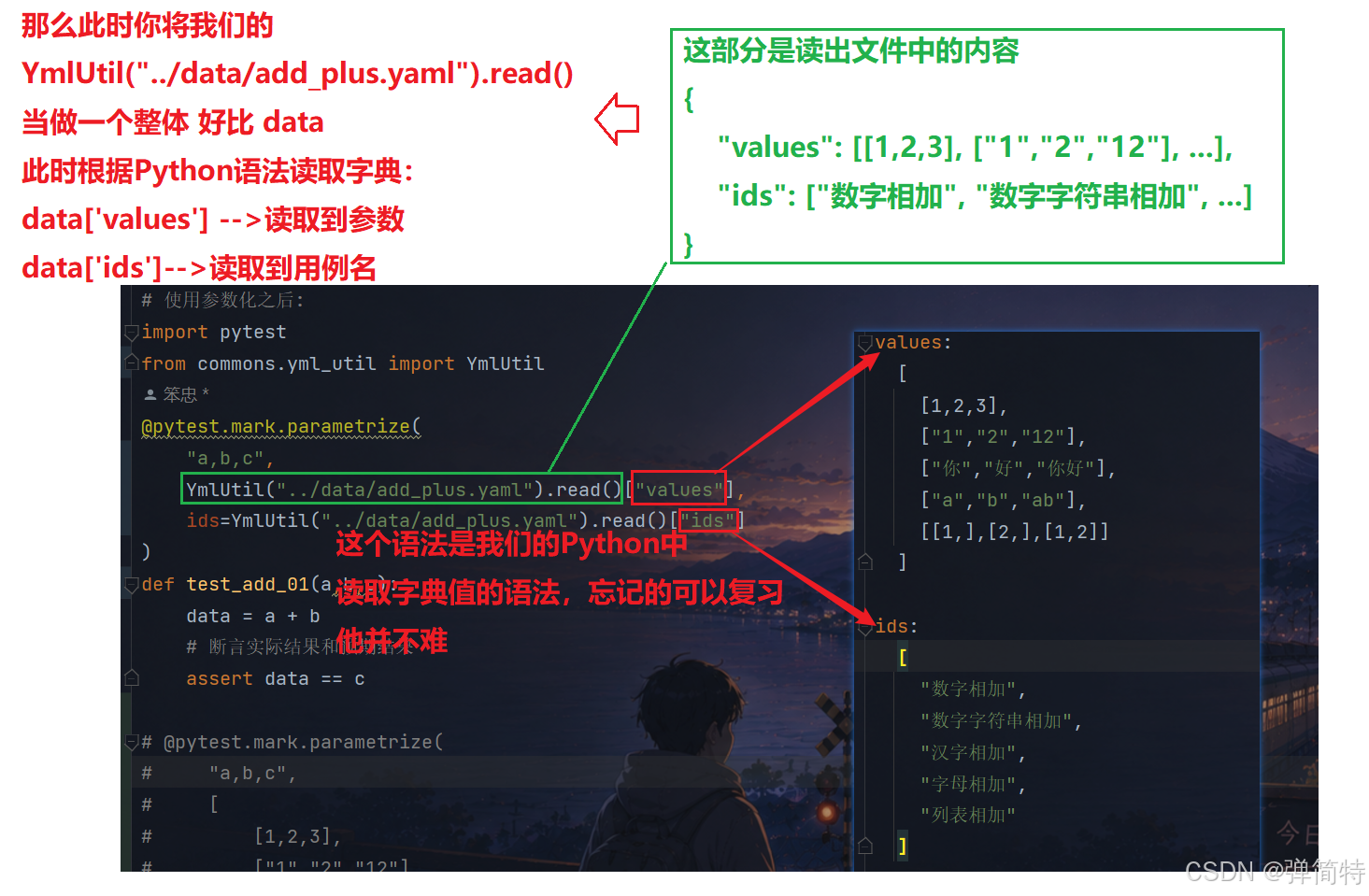
结果:
py
test_tan.py::test_add_01[数字相加] PASSED
test_tan.py::test_add_01[数字字符串相加] PASSED
test_tan.py::test_add_01[汉字相加] PASSED
test_tan.py::test_add_01[字母相加] PASSED
test_tan.py::test_add_01[列表相加] PASSEDOK,那么老铁,我们本期到这里就结束了,同时到这里我们pytest这个框架也学习的差不多了,下一期开始我们就将正式进入接口自动化测试了,本篇对你有用,记得点赞关注,我们下期见。