概述
前几天,凌晨收到MySQL数据库监控告警:xxx实例的全备失败。此时,登录到备份节点上,查看了日志,看到报错信息:An optimized (without redo logging) DDL operation has been performed. All modified pages may not have been flushed to the disk yet.PXB will not be able to take a consistent backup. Retry the backup operation. 通过该报错并结合业务侧逻辑的排查分析,最后找到根本原因,同时扩展出几个很值得思考的问题,最后对这些思考的问题从原理上进行了解析。
全备报错分析
通过与业务确认,在全备期间进行了跑批,而期间创建索引的操作应该是没有执行的。而为了获得较全的会影响全备失败的根因,也对binlog进行了分析。从binlog的分析结果来看,存在的DML:update,delete,insert,而DDL有:drop,optimize。从解析binlog来看并没有发现有创建索引的语句,也就是alter table add index和create index的语句。
对MySQL进行全备的工具用的是xtrabackup,通过报错关键字搜索在percona blog中找到了一个帖子,里面的内容正是与该报错一样的案例。帖子案例主要讲的是MySQL5.7进行全备时导致全备文件损坏或者说全备可能出现不一致的情况,而根本的原因是某些DDL语句跳过了写redo,该原因指的是MySQL新增的功能:排序索引构建。
结合解析binlog的内容来看,与上面的帖子case是没对上的,也就是没有创建索引的操作记录。这里就有点想不解了。不过再对帖子的case重新看了一边,发现了一个核心关键点,也就是如果出现了排序索引构建,那么全备期间就会有可能出现失败的情况!!!所以再结合binlog解析的内容进行分析。由于解析binlog未发现与创建索引的语句,先排除了创建索引的情况,那么除了创建索引之外,还有没有其他的场景也会触发排序索引构建呢?还有一个DDL的操作引起了注意,也就是optimize,optimize table的作用来整理表空间碎片,释放出所占的磁盘容量。想到了跑批如果delete+optimize的话,这就说得通了。那optimize会不会造成排序索引构建呢?为什么会呢?
事不宜迟,测试环境进行了测试验证。
测试环境进行验证
环境信息:
全备工具:xtrabackup version 8.0.25-17 based on MySQL server 8.0.25 Linux (x86_64) (revision id: d27028b)
MySQL server:8.0.25 MySQL Community Server - GPL
操作系统:CentOS Linux release 7.8.2003 (Core)
验证步骤:
(1)利用sysbench创建一张测试表
安装sysbench,安装文档见链接。
准备数据脚本:
shell
sysbench ./oltp_read_write.lua --threads=10 --mysql-user=ashan--mysql-password='yourpassword' --mysql-host=192.168.8.127 --mysql-port=3306 --mysql-db=sbtest --report-interval=5 --table-size=2000000 --tables=1 prepare (2)执行循环的drop,create,insert,delete,optimize操作,脚本如下:
shell
[root@localhost backup]# cat run_createtable_insert_delete_optimize.sh
#!/bin/bash
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db1.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db1.sb1 as select id,c from sbtest.sbtest1 where id < 50000;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "delete from db1.sb1;optimize table db1.sb1;"
sleep 1
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db2.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db2.sb1 as select id,c from sbtest.sbtest1 where id < 50000;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "delete from db2.sb1;optimize table db2.sb1;"循环执行脚本:
shell
while true;do sh run_createtable_insert_delete_optimize.sh ;done打印的输出如下图: 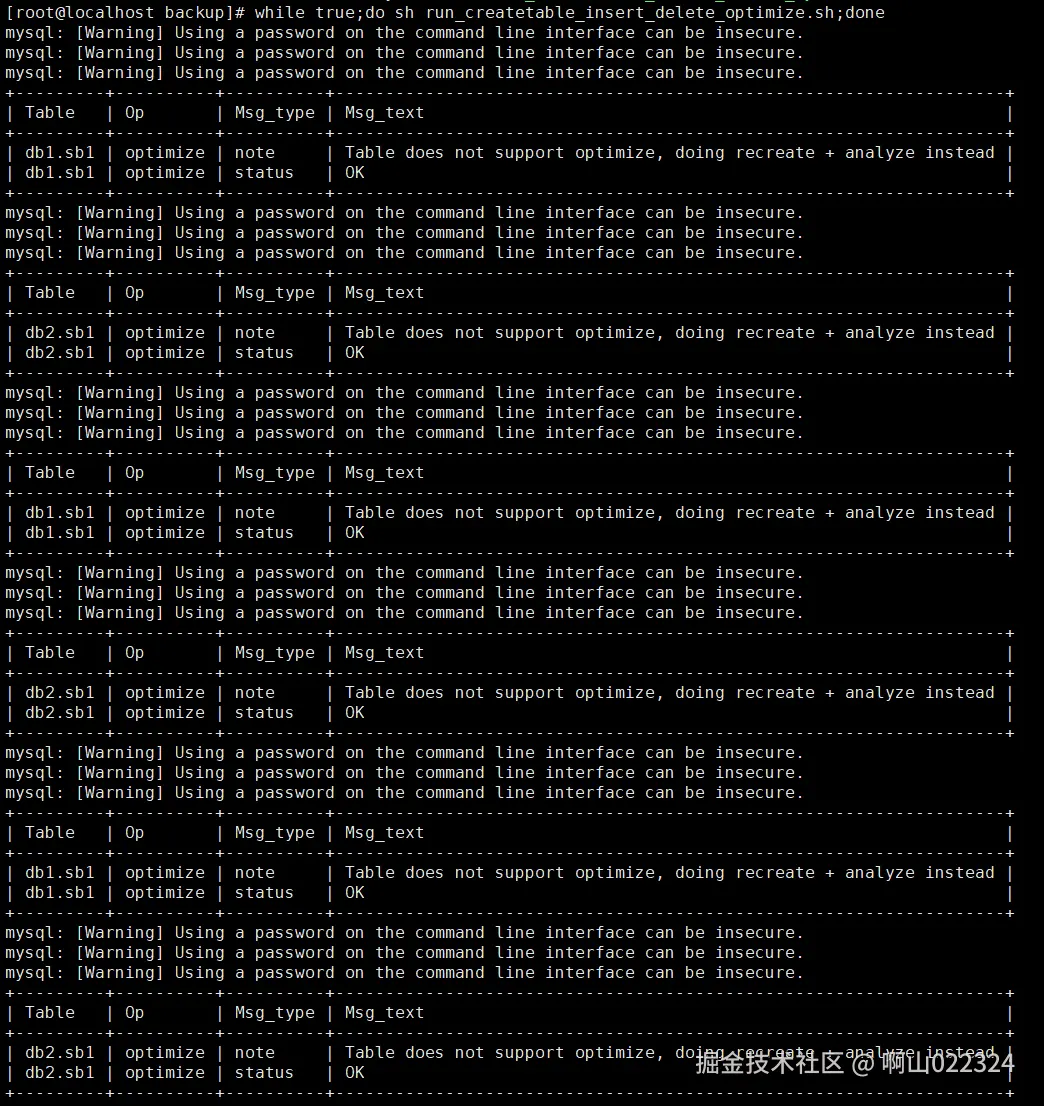
(3)循环的执行物理全备脚本,全备脚本如下:
shell
[root@localhost bin]# cat x.sh
./xtrabackup --defaults-file=/etc/my.cnf --user=root --password='yourpassword' --target-dir=/backup/full_20250528 --backup --host=127.0.0.1 --port=3306 --galera-info --parallel 2 --check-privileges --no-version-check --no-backup-locks --lock-ddl;echo $?
sleep 1
rm -rf /backup/full_20250528
echo "======================================================================================================================================================================================="注意: 全备的脚本x.sh放在与xtrabackup二进制文件同目录中
循环执行全备脚本:
shell
while true;do sh x.sh ;done提示:
xtrabackup退出码,xtrabackup二进制文件在备份完成后,xtrabackup 二进制文件在备份完成后,如果没有发生错误,则会以传统的成功值 0 退出。如果在备份过程中发生错误,则退出值为 1。
在某些情况下,由于 MySQL 库中包含的命令行选项代码,退出值可能不是 0 或 1。例如,如果使用了未知的命令行选项,则退出代码将为 255。
所以在执行xtrabackup备份后使用echo $?获取上一条命令退出时返回的退出状态码。
全备日志输出: 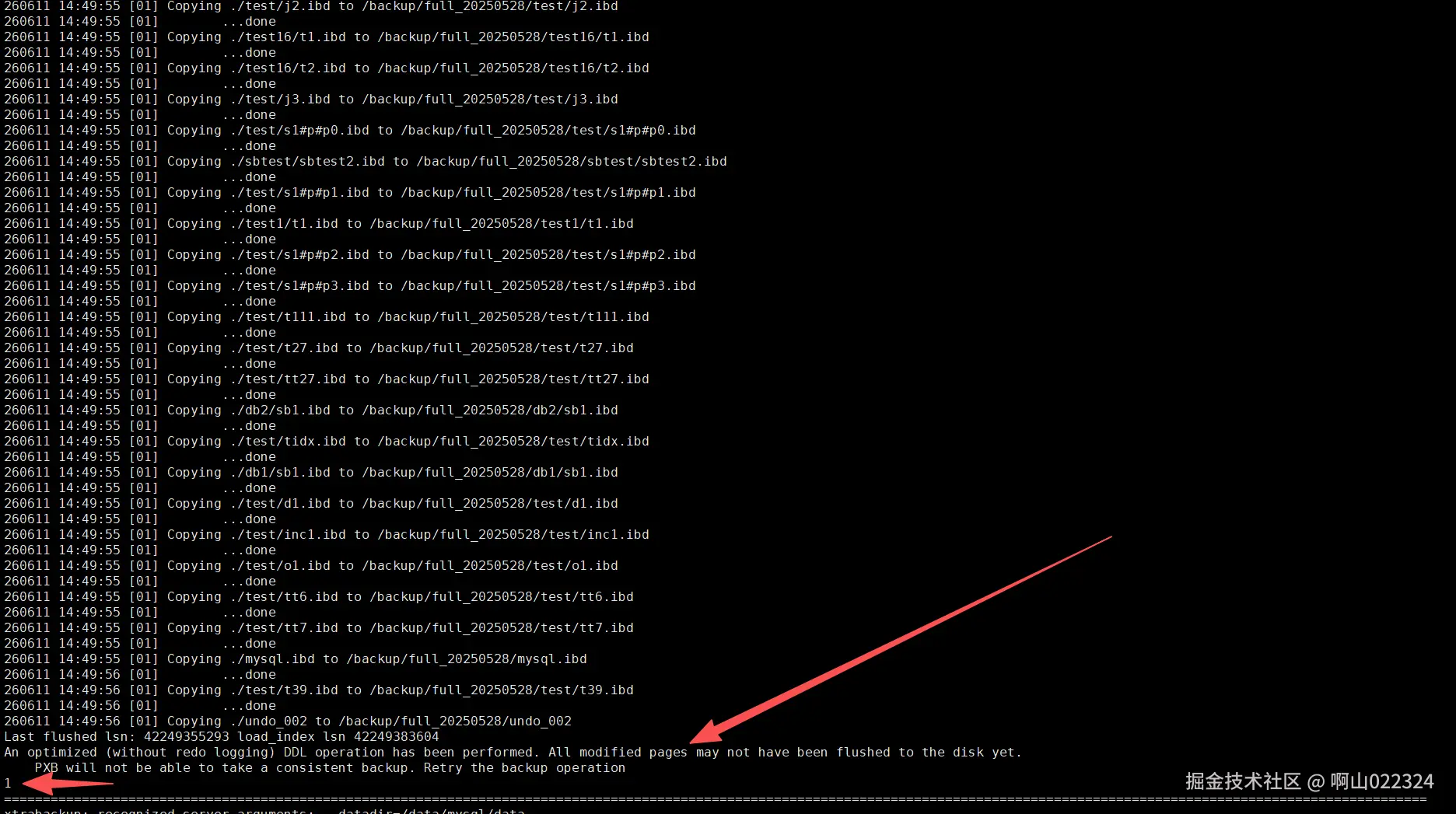
通过验证确认在全备过程中,执行optimize操作,会导致全备失败。
疑问及扩展
到这测试验证是结束了,但是当时有很多疑惑:
- 问题1:索引构建过程中为什么要禁用redo,如果不禁用redo,会出现什么问题?
- 问题2:optimize table为什么会触发批量排序索引构建?
- 问题3:如果将delete+optimize table换成了truncate table,或者换成drop table+create table+create index是否也会出现排序索引构建?
- 问题4:是否有什么解决办法,即redo被禁用了,全备还能继续不会失败?
问题1:索引构建过程中为什么要禁用redo,如果不禁用redo,会出现什么问题?
可以从MySQL官方文档中了解到排序索引构建的概念、索引构建的三个阶段、排序索引构建和重做日志记录的介绍。了解了基础的概念后,再慢慢的深入解析。
首先明确非常核心的点,禁用redo并不是整个MySQL实例关闭redo,不是整个innodb不写redo,不是所有事务都不写redo。而是:针对"正在构建的那些新索引页"的页面修改,不走常规的redo logging记录。有了这个核心的点之后,就很明确的锁定目标了,禁用redo,其实就是在索引构建过程中产生的新page的这些操作,不会记录到redo log中。
这里基于什么考虑,为什么不会记录到redo呢?因为批量排序索引构建B+Tree本身就是一中可重放操作,即是只要原数据还在,原聚簇索引还在,那么二级索引可以重新创建,并不是只有redo才能恢复的操作,而redo对它而言代价极高,收益很低。举个例子,在进行创建100G的索引中,会产生100G或更多的redo,这里写redo包含不限于:每个页修改,每次页分裂,每次页头部修改等。还会引起更严重的问题:因为redo log本质是,顺序fsync日志,而建索引本来已经是大量排序+大量page写入,再加上redo写放大,会导致redo file被疯狂刷满,出现日志检查点压力;checkpoint压力巨大,导致严重堵塞;DDL性能急剧下降(DDL时间变长),也就是写redo成为了瓶颈;DDL狂写redo时,redo是全局共享资源,业务可能出现相应写延迟,受到影响;再有崩溃恢复的时间变长,redo recovery需要replay巨量redo。redo被禁用了取而代之的是系统会执行检查点操作,以确保索引构建能够承受意外退出或故障。检查点操作会强制将所有脏页写入磁盘。在排序索引构建期间,页面清理线程会定期收到信号以刷新脏页,从而确保检查点操作能够快速完成。
问题2:optimize table为什么会触发批量排序索引构建?
optimize table实际上等价于recreate + analyze操作,可以从测试环境进行验证的章节可以看到。官网也介绍了,对于 InnoDB 表,OPTIMIZE TABLE 映射到 ALTER TABLE ... FORCE,它会重建表以更新索引统计信息并释放聚集索引中未使用的空间。也就是说optimize table映射为 ALTER TABLE FORCE语句,而该操作与ALTER TABLE tbl_name ENGINE=INNODB一样,都是用于对 InnoDB 表进行碎片整理。重建表也就是旧数据和索引需要搬迁,然后进行bulk load,那么这个过程就是排序索引构建。
这里需要特别注意的时,在测试验证中,我使用delete语句是删除全表数据,而不是删除部分数据,这时候触发了全备报错,说明了xtrabackup在进行全备时检测是否发生不写redo的DDL,而不会去判断这个DDL最终构建了多少个数据页,也就是说一旦检测到innodb的DDL进入了批量排序索引构建流程,就会报错。
如果感兴趣的话,可以在测试验证章节中将delete from db1.sb1;修改为delete from db1.sb1 limit 45000; 试着跑一下,看看结果是否也会触发全备不一致的情况。结果是会触发全备不一致的情况,上文测试直接删除全表数据,是因为直接测试临界点,也就是最终无数据页的时候,看能否触发全备不一致的情况。而删除部分数据,基本都比删除完全表数据,剩下的数据页多的,那么就会有更多的数据页进行排序索引构建。
特别注意:delete删除数据时,需要分批进行删除,不要直接删除全表数据,数据量较大时,可以把删除全表数据当是一个大事务,都尽量删除数据时带上索引条件列,按分批小事务进行删除。
optimize的内容扩展:
OPTIMIZE TABLE 对常规 InnoDB 表和分区 InnoDB 表使用在线 DDL,从而减少并发 DML 操作的停机时间。OPTIMIZE TABLE 触发的表重建操作会就地完成。仅在操作的准备阶段和提交阶段短暂获取独占表锁。在准备阶段,会更新元数据并创建一个中间表。在提交阶段,会提交表元数据更改。整个optimize table的操作下来,其实就是将表的页面重新排序整理了一遍,使表中所有b+tree更加紧凑,碎片化更少。
其实还可以测试下在无数据的情况,optimize table是否也会造成排序索引构建。
测试脚本:
shell
[root@localhost backup]# cat run_createtable_optimize.sh
#!/bin/bash
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db1.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db1.sb1 as select id,c from sbtest.sbtest1 where 1=0;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "optimize table db1.sb1;"
sleep 1
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db2.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db2.sb1 as select id,c from sbtest.sbtest1 where 1=0;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "optimize table db2.sb1;"循环执行如上脚本:
shell
while true;do sh run_createtable_optimize.sh ;done再循环执行全备脚本:
shell
while true;do sh x.sh ;done测试结果:全备失败,会出现全备不一致的报错。
| 用例场景 | 是否单独创建索引 | 是否有数据 | 是否导致全备失败 |
| drop table+create table as select +delete+optimize table | 否 | 是 | 是 |
| drop table+create table+optimize table | 否 | 否 | 是 |
总结:综上,无论表中是否有数据,在执行全备过程中,如果执行了optimize table语句,就会造成全备失败。
问题3:如果将delete+optimize table换成了truncate table,或者换成drop table+create table+create index是否也会出现排序索引构建?
先看truncate table操作,该操作类似drop table+create table的操作,当然这是一个原子操作,不然全部成功,不然全部失败,truncate语句是属于DDL语句。当对innodb表执行了truncate table语句后,该InnoDB 表会删除现有的表空间并创建一个新的表空间,具体介绍见官网描述。这里重建表空间的操作可以理解为drop table+create table,是会写入redo log的,并没有触发排序索引构建。
那么对于drop table+create table select+create index操作:
将该组合测试分为如下5个测试用例:
(1)drop table+create table as select+create index
根据问题进行测试验证。
测试脚本:
shell
[root@localhost backup]# cat run_createtable_createidx.sh
#!/bin/bash
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db1.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db1.sb1 as select id,c from sbtest.sbtest1 where id < 50000;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create unique index ix on db1.sb1 (id);"
sleep 1
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db2.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db2.sb1 as select id,c from sbtest.sbtest1 where id < 50000;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create unique index ix on db2.sb1 (id);"循环执行如上脚本:
shell
while true;do sh run_createtable_createidx.sh ;done再循环执行全备脚本:
shell
while true;do sh x.sh ;done测试结果:全备失败,会出现全备不一致的报错。
(2)drop table+create table
该测试是为了验证没有create index后是否会触发全备不一致的情况。
测试脚本:
shell
[root@localhost backup]# cat run_createtable_droptable.sh
#!/bin/bash
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db1.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db1.sb1(id int key,c varchar(23));"
sleep 1
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db2.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db2.sb1(id int key,c varchar(23));"循环执行如上脚本:
shell
while true;do sh run_createtable_droptable.sh ;done再循环执行全备脚本:
shell
while true;do sh x.sh ;done测试结果:全备成功,不会出现全备不一致的报错。
(3)create table+drop table
该测试是为了再充分验证没有create index后是否会触发全备不一致的情况。
测试脚本:
shell
[root@localhost backup]# cat run_createtable_droptable.sh
#!/bin/bash
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db1.sb1 like sbtest.sbtest1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db1.sb1;"
sleep 1
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db2.sb1 like sbtest.sbtest1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db2.sb1;"循环执行如上脚本:
shell
while true;do sh run_createtable_droptable.sh ;done再循环执行全备脚本:
shell
while true;do sh x.sh ;done测试结果:全备成功,不会出现全备不一致的报错。
(4)已有表结构,有数据,进行drop index+create index
该测试是为了验证表中有数据时,创建索引是否会触发全备不一致的情况,其实在percona blog中的case已经验证了,但这里测试也是为了再次复现和印证该问题。
先插入数据:
shell
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db1.sb1 as select id,c from sbtest.sbtest1 where id < 50000;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db2.sb1 as select id,c from sbtest.sbtest1 where id < 50000;"测试脚本:
shell
[root@localhost backup]# cat run_dropidx_createidx.sh
#!/bin/bash
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "alter table db1.sb1 drop index ix";
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create unique index ix on db1.sb1 (id);"
sleep 1
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "alter table db2.sb1 drop index ix";
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create unique index ix on db2.sb1 (id);"循环执行如上脚本:
shell
while true;do sh run_dropidx_createidx.sh ;done再循环执行全备脚本:
shell
while true;do sh x.sh ;done测试结果:全备失败,会出现全备不一致的报错。
(5)已有表结构,无数据,创建索引,进行create index
该测试是为了验证表中无数据时,创建索引是否会触发全备不一致的情况。
测试脚本:
shell
[root@localhost backup]# cat run_createtable_nodata_createidx.sh
#!/bin/bash
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db1.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db1.sb1 as select id,c from sbtest.sbtest1 where 1=0;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create unique index ix on db1.sb1 (id);"
sleep 1
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "drop table if exists db2.sb1;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create table db2.sb1 as select id,c from sbtest.sbtest1 where 1=0;"
mysql -uroot -P3306 -hlocalhost -pyourpassword -e "create unique index ix on db2.sb1 (id);"循环执行如上脚本:
shell
while true;do sh run_createtable_nodata_createidx.sh ;done再循环执行全备脚本:
shell
while true;do sh x.sh ;done测试结果:全备失败,会出现全备不一致的报错。
以上的测试内容通过统计:
| 测试用例(按测试顺序) | 用例场景 | 是否单独创建索引 | 是否有数据 | 是否导致全备失败 |
| 1 | drop table+create table as select+create index | 是 | 是 | 是 |
| 2 | drop table+create table | 否 | 否 | 否 |
| 3 | create table+drop table | 否 | 否 | 否 |
| 4 | drop index+create index | 是 | 有 | 是 |
| 5 | create index | 是 | 否 | 是 |
从以上测试的统计结果可以得出:
-
全备期间,一旦执行create index,无论是否有数据,都可能会导致全备失败。
-
全备期间,执行drop table或create table,不会导致全备失败。
问题4:是否有什么解决办法,即redo被禁用了,全备不会中止?
是有的,通过分析全备的命令xtrabackup中,配置了--no-backup-locks,该参数控制在备份阶段是否应使用备份锁而不是 FLUSH TABLES WITH READ LOCK。如果服务器不支持备份锁,则此选项无效。此选项默认启用,使用 --no-backup-locks 禁用。即如果指定了--no-backup-locks 参数全备是使用FLUSH TABLES WITH READ LOCK全局锁来获取一致性点位的。而默认配置--backup-locks(不指定也是该配置)这个锁会比全局读锁更轻量,与 FLUSH TABLES WITH READ LOCK 不同,LOCK TABLES FOR BACKUP 不会刷新表,也就是说,存储引擎不会被强制关闭表,表也不会从表缓存中移除。因此,LOCK TABLES FOR BACKUP 只会等待冲突语句完成(例如,DDL 语句和对非事务表的更新)。例如,它从不等待 SELECT 语句或对 InnoDB 或 MyRocks 表的 UPDATE 语句完成,更多内容具体见官网介绍。
通过验证测试,用以上的测试用例,在全备不指定--no-backup-locks,全备都成功了,但还是会发出warning级别的告警,告警内容如下:An optimized(without redo logging) DDL operation has been performed. All modified pages may not have been flushed to the disk yet.This offline backup may not be consistent. xtrabackup其实将全备可能不一致的情况以warning级别的日志打印出来,说明已经不用担心全备期间,触发排序索引构建导致redo禁用了,mysql会强制刷盘来推进checkpoint来解决该问题。
指定与否--no-backup-locks参数的备份日志结果:
指定: 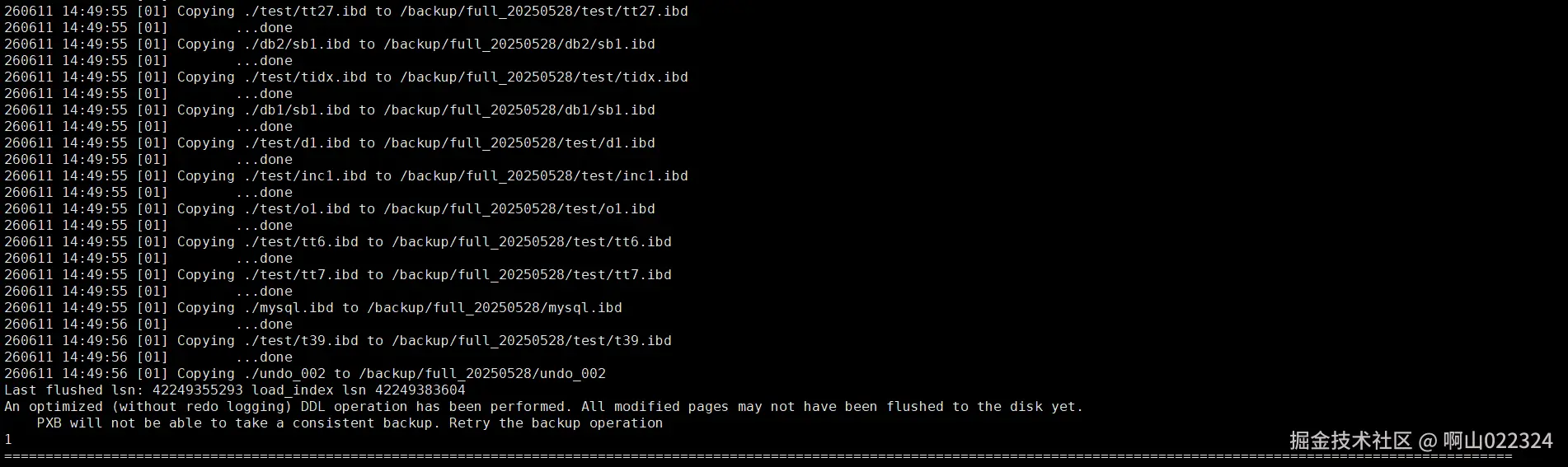
不指定: 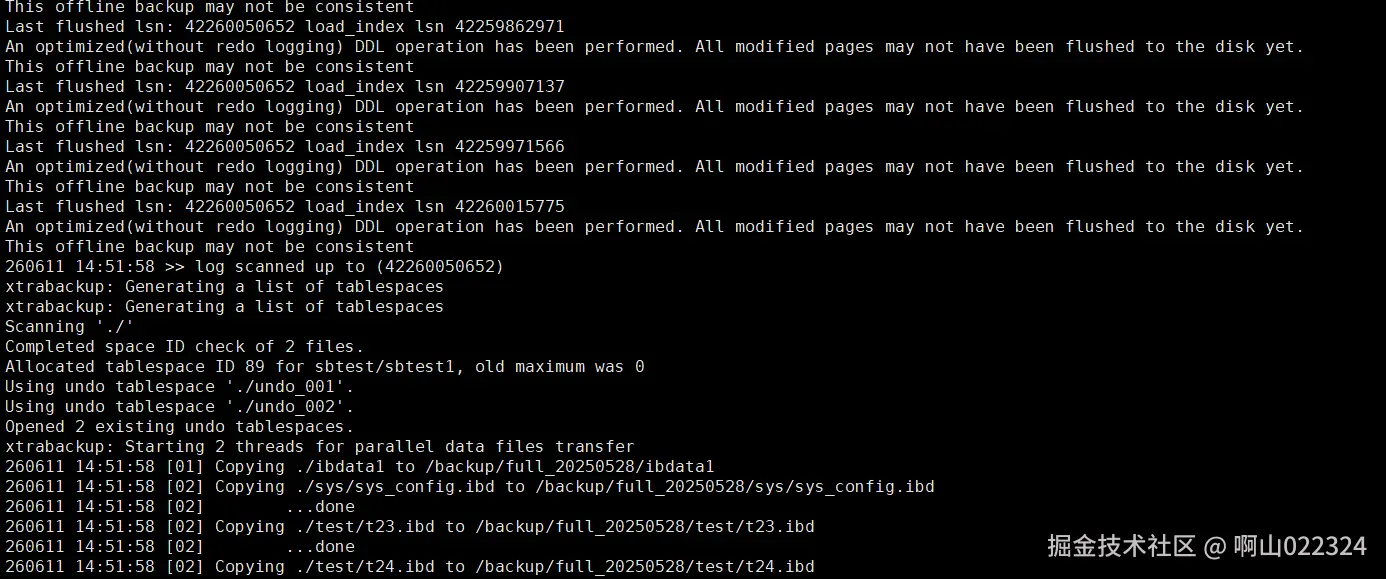
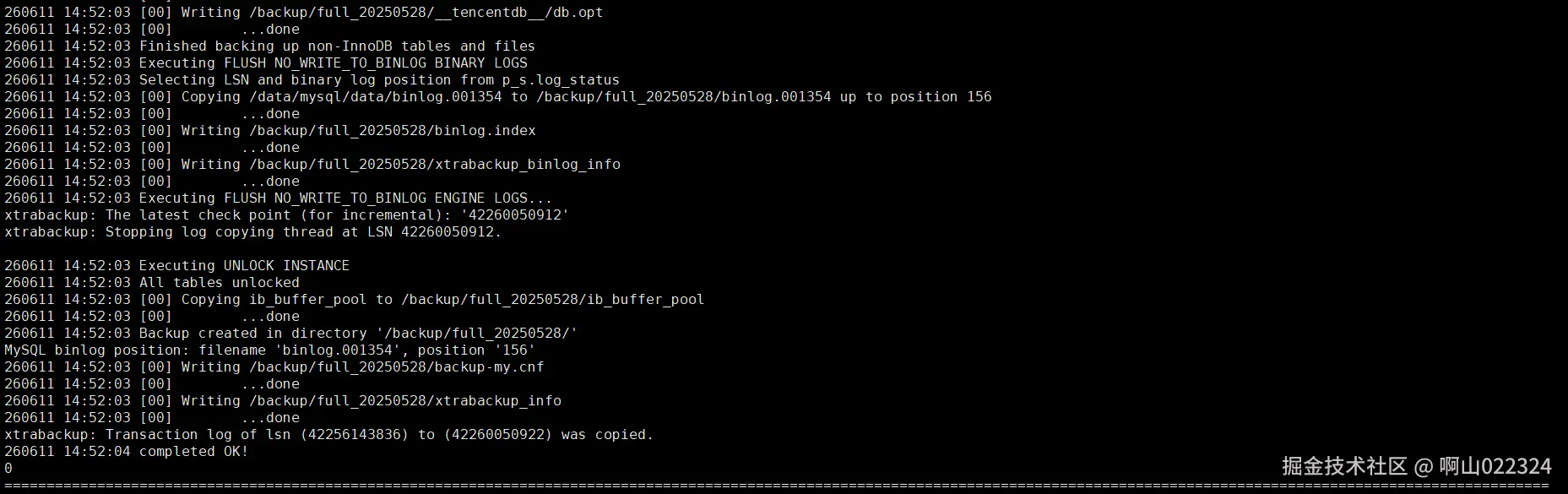
指定的结果与测试验证的结果一致,会直接备份失败。
不指定--no-backup-locks参数,会提示备份可能不一致,但仍然进行下去,并完成全备。
通过xtarbackup官网的Release notes得知:8.0.28的版本及以后,错误日志采用标准化的结构。统一的日志头使跟踪操作进度或查看日志以诊断问题变得更加容易。
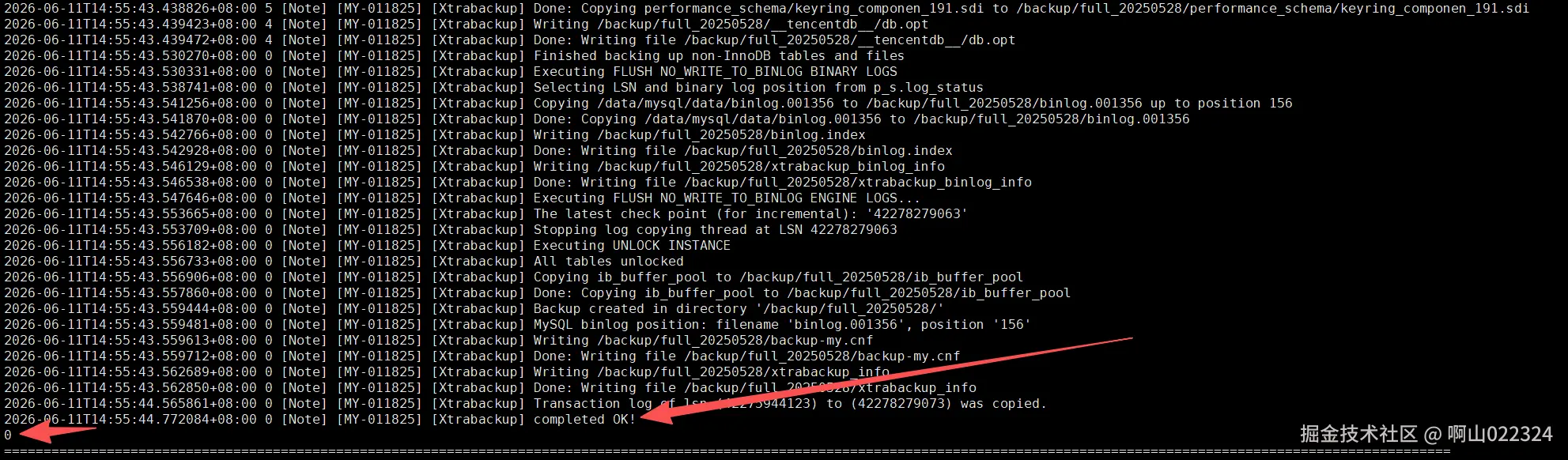
使用8.0.28xtrabackup进行全备,测试结果如下:
全备失败的日志显示: 
全备成功的日志显示: 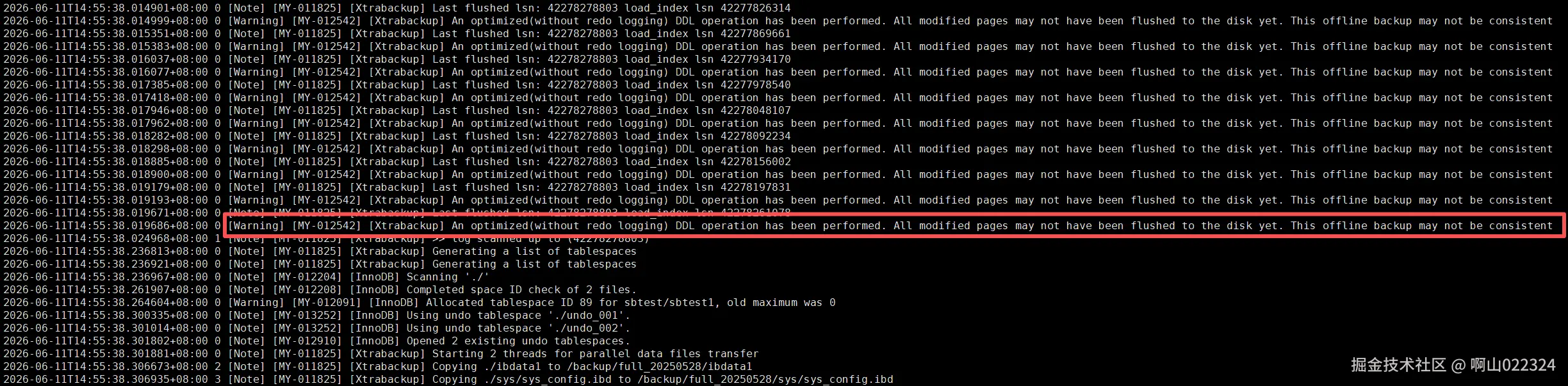
总结
通过以上的测试验证得出,造成全备失败的根因是全备期间进行了optimize table语句,而其中的原理就是触发了排序索引构建,也正因为全备指定了--no-backup-locks参数,使用FTWRL获取一致性位点,由于备份到optimize table所涉及的数据页的时候,xtrabackup发现redo被禁用了,无法进行一致性备份,最终导致全备失败。
调整及建议,使用xtrabackup进行全备时,尽量不要指定--no-backup-locks参数,xtrabackup已经有更轻量化的备份锁来替代FTWRL;可以使用8.0.28及以上的版本,日志输出更清晰,更容易排查问题。如果有DDL变更,可以申请与全备时间窗口错开,以免导致全备失败。
其实这里备份失败是定位并解决了,但是整个备份恢复还没有形成闭环,也就是备份成功后,用该备份进行恢复,恢复的实例是否符合预期,待更新,嘻嘻:)