今年 AI Agent 彻底爆发,从 Claude Code 到各家国产大模型,人人都在用。可你有没有过这种憋屈:同样的工具,别人产出能直接上生产的代码和架构,你得到的却是一坨连改都没法改的东西?
差距真不在工具。今天这 17 个概念,就是那条把"AI 使用者"和"AI 工程师"分开的线。看完你会发现,AI 一点都不神秘------它只是工程。
几个月前,我注意到一个有意思的现象。
两个开发者用着完全相同的 AI 工具。一个产出平平无奇,另一个却产出了强得离谱的成果------可直接上生产的代码、结构清晰的架构、整洁的文档。
差别在哪?不在工具,而在工具背后的理解。
今天很多人每天都在用 Codex、Claude Code、Cursor、Copilot,但只有一小部分人真正懂 AI 到底是怎么思考、回应、生成结果的。而真相很简单:一旦你理解了核心概念,AI 就会变得简单得多。
你不需要博士学位,只需要一步步搞懂这套系统怎么运转。下面这 17 个概念,没有学术黑话,全是能立刻改善你使用 AI 方式的实用知识。
我们开始。
第一部分 ------ AI 如何"读懂"文本
1. Token:AI 的语言
AI 模型不像人类那样读单词,它读的是 token,并且中文语言区已经有统一的称呼"词元"。
人类把句子当作完整的意思来读,AI 却是一片一片地读------逐词,有时甚至是词的一部分。所以你写下一句话时,模型看到的根本不是句子,而是一串 token。
一个 token 可以是:一个完整单词、单词的一部分、标点,或数字。
例如 "I love JavaScript",可能被切成这样:
bash
"I"" love"" Java""Script"而 "Building AI applications is fun" 可能被这样拆开:
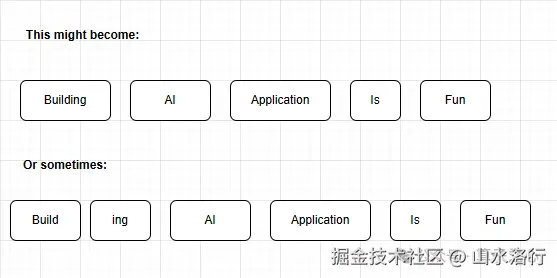
Token 切分示例
为什么这事关重大?因为 AI 里的一切都按 token 计量------输入输出的长度、上下文窗口、记忆,还有你的钱包:API 说"每 1,000 token 多少钱",算的就是你发出和收到的文本量。
不信你自己试,用 OpenAI Tokenizer 或 Tiktokenizer 粘一句话进去,看 AI 怎么把它大卸八块。
💡 看懂 token,你才能写出更短、更准、更省钱的提示词。
2. Embedding(嵌入):AI 如何理解含义
分词之后,文本会被转成数字 ,这些数字就叫 embedding(嵌入),它用数学的方式表示含义。
想象一张巨大的地图:含义相近的词彼此靠近,含义相反的词彼此远离。
•
King(国王)→ Queen(王后)
•
Doctor(医生)→ Nurse(护士)
•
Apple(苹果)→ Banana(香蕉)
•
Apple(苹果公司)→ Microsoft(微软,公司语境下)
AI 并不像人类那样"理解"含义,它理解的是向量之间的距离。 正因如此,"How to learn JavaScript" 和 "Best way to study JS" 这两句不同的话,会在向量空间里挨得很近。
下面是一个用 sentence-transformers 写的最小示例:
bash
import torch
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# 把文档文本作为输入
corpus = [
"Put your input text",
]
corpus_embeddings = embedder.encode_document(corpus, convert_to_tensor=True)
# 查询句子:
queries = [
"Put your queries here",
]
# 用余弦相似度,为每个查询从语料中取出最相似的句子
top_k = min(2, len(corpus))
for query in queries:
query_embedding = embedder.encode_query(query, convert_to_tensor=True)
similarity_scores = embedder.similarity(query_embedding, corpus_embeddings)[0]
scores, indices = torch.topk(similarity_scores, k=top_k)
print("\nQuery:", query)
print("Top most similar sentences in corpus:")
for score, idx in zip(scores, indices):
print(f"(Score: {score:.4f})", corpus[idx])语义搜索、推荐系统、"和 PDF 对话"、RAG、向量数据库------背后全靠它。
💡 Embedding 让机器读懂的是含义,而不只是关键词。
3. Attention(注意力):AI 如何理解上下文
这个概念,彻底改变了 AI。一个词的含义,取决于它的上下文:
She bought shares in Apple.(她买了苹果公司的股票。)
She ate an apple.(她吃了一个苹果。)
同一个词,意思天差地别。
注意力(Attention) 就是让模型扫视句子里每一个词、判断哪些词最重要的机制。模型不像人那样一次只读一个词,而是一次性看完整句,把彼此相关的词连起来------就像你读一句话,瞬间就知道"谁对谁做了什么",根本不用逐字破译。
正因如此,现代 AI 才能读懂长句、写代码、总结文档、翻译、答题。
想啃原始论文?就是它:"Attention Is All You Need"------这篇论文提出了 Transformer,从此永久改写了 AI。
💡 理解了"注意力",你就理解了现代 AI 智商的起点。
4. Transformer:现代 AI 的引擎
Transformer 是 GPT、Claude、Gemini、Llama、Mistral 以及几乎所有现代大模型采用的架构。
它的流程是这样的------文本变成 token,token 变成 embedding,注意力层堆出"理解",最后一层吐出下一个 token:
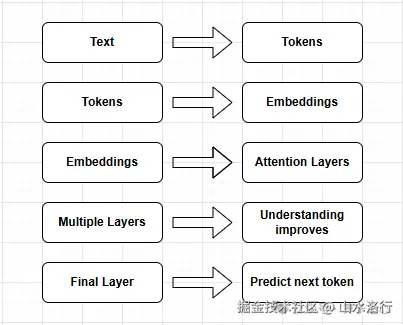
Transformer 流程
注意:Transformer 不会一次性生成一整句话,而是一个 token 一个 token 地往外蹦------
•
预测下一个 token
•
把它接上
•
再预测下一个
•
不断重复
所以你跟 AI 聊天时,它本质上就是在飞快地、一遍又一遍地猜下一个词。
Transformer 架构
想深入,图解 Transformer 和 HuggingFace 课程 是全网最好的两份资料。
5. 大语言模型(LLM)
现在把前面的全串起来。一个**大语言模型(LLM)**说白了就是:
一个在海量文本上训练、专门用来预测下一个 token 的 Transformer。
训练时,它读过书籍、网页、代码、文章、文档和对话,从中学会语言的规律。它不像数据库那样存答案,它学的是模式。 所以它能写代码、讲概念、翻译、总结、出主意、回答问题。
但有件事你必须刻进脑子里:
LLM 是模式预测机器,不是真理机器。
这就直接引出了下一个概念。
第二部分 ------ 如何掌控 AI 的输出
6. 上下文窗口:AI 的短期记忆
AI 不会记住所有东西。它只能看到上下文窗口 之内的内容------把它想成 AI 的内存条。
上下文包括:你的提示词、对话历史、你粘进去的文档,还有模型自己的回复。一旦撑满,较早的消息会被遗忘,推理开始退化,回答前后矛盾。
大窗口能撑起长对话、大文档、整个代码库的分析。但代价也实在:更大的上下文 = 更多内存、更高成本、更慢响应。上下文大小,永远是一场权衡。
💡 真正的高手,都在偷偷管理上下文。
7. Temperature(温度):创造力旋钮
AI 动笔前并不会真的"构思"------它是一个 token 一个 token 地预测最可能的下一个词。对每个 token,模型都会算概率,而 temperature 控制的,就是这种选择有多随机。
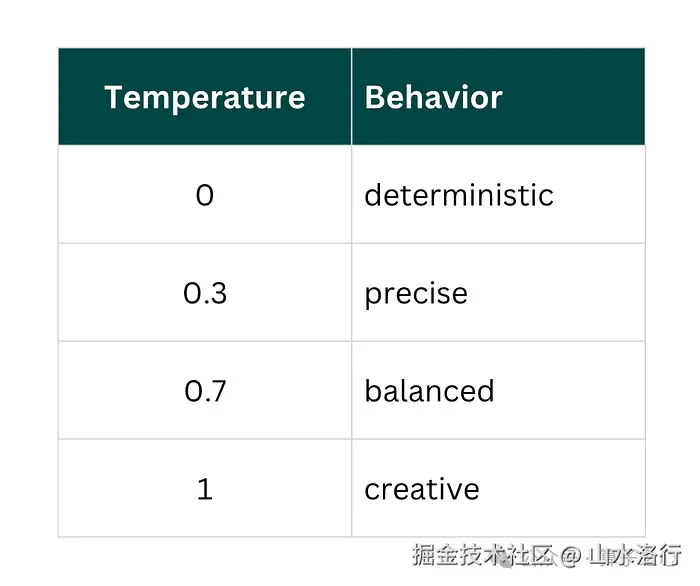
Temperature 与行为对照
常用取值给你抄作业:
•
0.2 → 写代码
•
0.4 → 技术性回答
•
0.7 → 普通写作
•
1.0 → 创意写作
低温度更准、更稳(适合代码和事实),高温度更野、更花(适合写作和脑暴)。
💡 就这一个参数,能把输出风格从"严谨理工男"调成"放飞文艺青年"。
8. 提示词工程:正确提问的本领
很多人张口就是"AI 不行"。但真相是:烂提示词,喂出烂结果。 提示词工程,就是设计出能把 AI 指挥明白的指令。
糟糕的提示词:
bash
Explain React Hooks更好的提示词:
bash
Explain React Hooks with a real-world example for frontend developers transitioning from class components.优秀的提示词:
bash
Act as a senior React engineer. Explain React Hooks with a practical example, and include best practices and common mistakes.💡 AI 输出的质量,和你提示词的质量,严格成正比。
9. 系统指令:给 AI 定人设
大多数 AI 系统都支持系统提示词(system prompt)------专门定义语气、专业程度、回复风格和约束。比如:
bash
You are a senior Node.js backend architect with 15 years of experience. Provide scalable solutions with clean architecture principles.一句话,回复质量立刻上一个台阶。
💡 系统指令,能把一个聊天机器人变成你的专属领域专家。
10. 思维链(Chain-of-Thought)
与其逼 AI 直接给答案,不如让它一步一步想。
别这么问:
bash
Solve this problem这么问:
bash
Explain your reasoning step-by-step before giving the final answer.准确性、推理力、逻辑性,全都往上走。
💡 让 AI"把过程说出来",可靠性立刻翻倍。
第三部分 ------ 认清 AI 的局限
11. 幻觉:当 AI 听着特别对、其实全错
AI 有时会给你一段措辞漂亮、口吻笃定,但事实上离谱的回答。这就是幻觉(hallucination)。
它能凭空编出不存在的论文、推荐根本没有的 API、写错代码、捏造事实和统计数字。这不是 AI 在撒谎,而是它在预测什么"听起来对",而不是核实什么"确实对"。 只要一句话看着像真的,它就敢生成出来------哪怕是错的。
所以生产环境里的 AI 系统,全都靠 RAG、验证、工具调用、人工复核和护栏兜底。
💡 AI 给的关键信息,永远要自己核一遍------尤其是它说得越笃定的时候。
12. AI 是一台概率机器
这是最最重要的一条 。AI 并不"知道"事实,它预测的是最可能的下一个 token。
它生成的一切,都基于从训练数据里学到的概率。这意味着:AI 很强大,但它不神奇。 把这点想透,你才能对 AI 抱以恰当的信任、设计更安全的系统、做出更好的产品。
第四部分 ------ 构建真实的 AI 应用
13. RAG(检索增强生成)
这是当今 AI 最重要的架构之一,也是做真实应用时绕不开的核心思路。AI 不再只靠训练时记住的东西,而是先检索 相关文档,再用这些文档来生成答案。
流程很简单:
bash
用户提问
↓
把问题转成 embedding
↓
检索向量数据库
↓
取回相关文档
↓
把文档 + 问题一起交给 LLM
↓
生成答案因为回答前用上了真实数据,AI 的答案更准、更新、更靠谱,幻觉也大幅下降。"和 PDF 对话"、企业知识库机器人、客服机器人、内部搜索,背后几乎全是它。想入门,从 LangChain 文档 和 LlamaIndex 开始。
💡 RAG,是绝大多数真实 AI 应用的地基。
14. 向量数据库
处理 embedding 时,你得把它们存进向量数据库。主流的有 Pinecone、Weaviate、Chroma、Qdrant。
它们能在数百万条向量里做闪电般的相似度搜索------"找出和这个问题最像的文档"------而这正是 RAG、AI 搜索、推荐系统的命根子。
💡 没有向量数据库,RAG 就只是个 PPT 概念。
15. 微调(Fine-Tuning):教 AI 新技能
微调,就是在特定数据集上训练模型------医疗 AI、法律 AI、编程助手、企业知识机器人,都靠它。
但现代 AI 系统往往更偏爱 RAG 而非微调 ,因为 RAG 更便宜、更快、更好维护。记住这条选择题的答案:要改模型的"行为和风格",用微调;要给它"新鲜知识",用 RAG。
16. AI 智能体(Agent):会"动手"的 AI
普通 AI 的流程是:你问 → 它答 。而**智能体(Agent)**的流程是:你问 → 它规划 → 调用工具 → 执行 → 检查 → 重复 → 干完。
智能体不只会答题。它能调 API、写代码、跑代码、搜网络、读文件、改数据库、发邮件,乃至把一整套工作流自动化。
bash
User: Find the best flight
Agent:
→ search flights
→ compare prices
→ return options它在一个循环里干活:理解目标 → 规划步骤 → 执行一步 → 检查结果 → 重复。
常见框架:LangChain、AutoGen、CrewAI、Semantic Kernel、LangGraph。智能体很强,但要做到可靠极难------而它,正是今年整个 AI 行业押注的方向。
💡 智能体,把 AI 从一个助手,升级成一个自主系统。
17. 多模态、延迟与成本
最后是用 AI 落地时,绕不开的两个现实。
多模态 AI。 现代模型能同时吃文本、图像、音频、视频。它已经在驱动图像分析、语音助手、文档理解、AI 视频生成,未来还会撑起机器人、自动驾驶、医学影像和设计工具。
延迟与成本。 AI 系统很烧钱,所以高手会死磕 token 用量、API 调用、缓存和模型选择。一个朴素但极有效的策略:
bash
简单任务 → 小模型
复杂推理 → 大模型💡 聪明的 AI 工程师,做的是"成本高效"的流水线,而不只是"能跑起来"的流水线。
一条建议的学习顺序
从零开始的话,这条路径非常好用:
1
Token
2
Embedding
3
Transformer
4
LLM 基础
5
提示词工程
6
RAG
7
向量数据库
8
微调
9
智能体
10
AI 系统架构
沿着这条路走,AI 会突然变得好懂很多。
写在最后
今天大多数开发者只是在用 AI ,真正懂它如何运转 的人寥寥无几。一旦你把 token、embedding、注意力、RAG、智能体这些吃透,AI 就不再像魔法,而开始像工程------那一刻,正是你从"使用者"变成"工程师"的起点。
下一个十年里最好的开发者,不会只是写代码。
他们会设计AI Agent智能体系统。
这 17 个概念,你已经卡在第几个了?评论区告诉我,最想让我把哪一个单独拆开讲透。