老板:我要看上周华东区销售TOP10
我:好的(内心:又要写join,又要写group by)
现在:老板自己对着对话框说一句,SQL自动生成,数据直接出
产品经理临时要个数据,运营同学天天喊"帮我导一下",开发排期永远不够------这是很多后端都经历过的日常。写SQL本身不累,累的是各种千奇百怪的需求,换来换去的字段,还有写完还要担心慢查询。
去年我在一个项目中尝试了Text2SQL(也叫NL2SQL),就是让大模型把自然语言直接转成可执行的SQL。跑通之后,我们搭了一个"数据问答助手",业务人员自己输入问题,系统自动生成SQL并返回结果。一开始我也担心准确性,但用下来发现:70%的常见查询完全不用人动手了。
今天聊聊我们是怎么用Java+大模型把Text2SQL落到项目里的,顺便分享几个踩过的坑。
📌 需求场景:每天被"帮我查一下"支配的恐惧
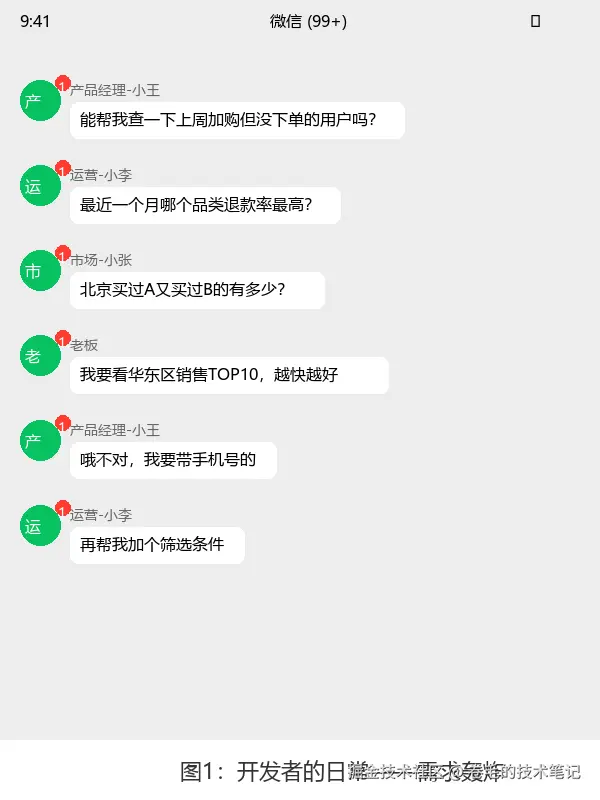
先说一下背景。我们做的是一个电商后台,每天都有运营、市场、产品的人来找开发要数据:
- "帮我拉一下上周加购但没下单的用户"
- "最近一个月哪个品类的退款率最高?"
- "北京地区购买过A商品又买过B商品的人有多少?"
每次接到这种需求,流程大概是:打开数据库客户端→理清表关系→写SQL→导出Excel→发过去。对方一看,"哦不对,我要的是带手机号的",再改一遍。一天下来,半条命没了。
后来我们就想:能不能让业务人员自己用大白话问,系统自动把SQL生成出来,甚至直接返回表格?
这就是Text2SQL要做的事。
🧠 Text2SQL到底是什么?一句话讲清楚
Text2SQL = 把"人话"翻译成"数据库话"。
比如你输入:
"查询2025年订单金额超过1000元的用户姓名和手机号"
系统自动生成:
sql
SELECT user_name, phone FROM orders
WHERE order_amount > 1000 AND year(create_time)=2025;当然,实际业务中表名、字段名都是你们自己的,所以需要先让AI"学会"你的数据库结构------告诉它有哪些表、哪些字段、字段是什么意思。

🛠️ 我们选择的实现方案:Spring Boot + 通义千问 + 本地元数据
市面上有几种做法:
- 调用现成的NL2SQL API(比如阿里云DataWorks的数据分析助手),适合不想折腾的团队,但要花钱。
- 自己封装大模型API,用Prompt控制,灵活性高,成本可控。
- 本地跑开源模型(如Chat2DB-API、SQLCoder),适合数据不能出内网的环境。
我们选了方案二:Spring Boot + 阿里云DashScope(通义千问) 。因为公司大部分业务已经在阿里云上,接入方便,而且中文理解能力不错。
核心思路就是:把数据库Schema(表结构、字段注释、外键关系)提前告诉模型,然后每次用户提问时,把问题+Schema一起发给模型,让它生成SQL,后端再把SQL扔到数据库执行。
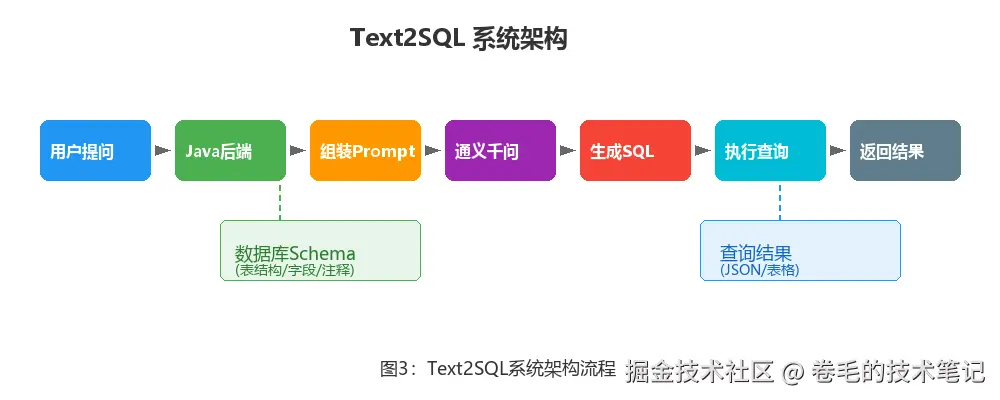
🔧 实战步骤:从零搭一个Text2SQL助手
第一步:准备数据库元数据
我们建了一个配置表,存放业务人员最常查询的表和字段说明。不一定把整个数据库几百张表都丢给AI,只挑核心的几张就够了。
sql
CREATE TABLE `data_dict` (
`table_name` varchar(64) COMMENT '表名',
`column_name` varchar(64) COMMENT '字段名',
`column_comment` varchar(255) COMMENT '字段业务说明',
`example_value` varchar(255) COMMENT '示例值'
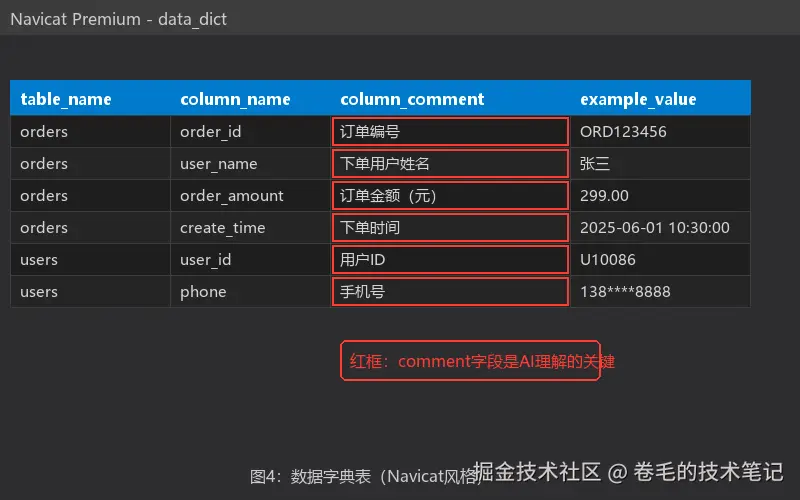
);比如订单表:
| table_name | column_name | column_comment | example_value |
|---|---|---|---|
| orders | order_id | 订单编号 | ORD123456 |
| orders | user_name | 下单用户姓名 | 张三 |
| orders | order_amount | 订单金额(元) | 299.00 |
把这些数据拼成一段文本,就是AI的"字典"。
第二步:写一个Prompt模板
我们在代码里维护了一个固定的Prompt,每次把用户问题和Schema塞进去:
java
String systemPrompt = """
你是一个专业的SQL生成助手。
数据库类型:MySQL 8.0
表结构如下:
{schema}
要求:
1. 只生成SELECT语句,禁止生成INSERT、UPDATE、DELETE
2. 不要使用存储过程和游标
3. 如果无法生成有效SQL,返回 "无法解析"
4. 只输出SQL语句,不要输出额外解释
""";用户提问时会拼成:
text
用户问题:查询上周订单金额超过1000的用户
表结构:...
请输出SQL: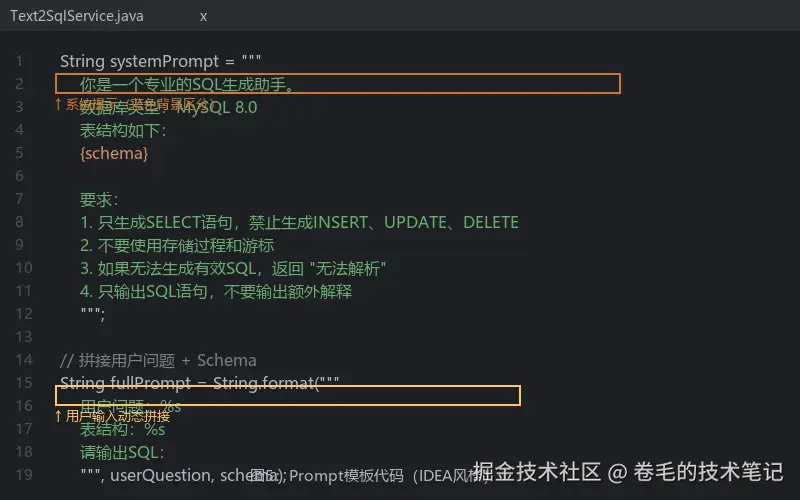
第三步:调用大模型生成SQL
用Spring AI Alibaba的ChatClient,直接拿到模型返回的SQL字符串:
java
@Service
public class Text2SqlService {
private final ChatClient chatClient;
public String generateSql(String userQuestion, String schema) {
String fullPrompt = String.format("""
用户问题:%s
表结构:%s
请输出SQL:
""", userQuestion, schema);
return chatClient.prompt()
.user(fullPrompt)
.call()
.content();
}
}第四步:执行SQL并返回结果
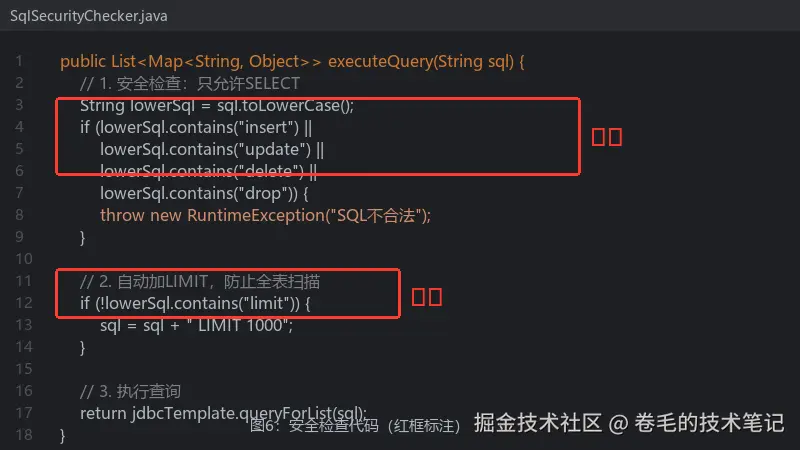
拿到SQL后,先用正则做一次安全检查(只允许SELECT),再用JdbcTemplate执行,最后把结果转成JSON返回给前端。
java
public List<Map<String, Object>> executeQuery(String sql) {
// 1. 简单校验:不能包含 DML 关键字
String lowerSql = sql.toLowerCase();
if (lowerSql.contains("insert") || lowerSql.contains("update")
|| lowerSql.contains("delete") || lowerSql.contains("drop")) {
throw new RuntimeException("SQL不合法");
}
// 2. 限制行数,防止全表扫
if (!lowerSql.contains("limit")) {
sql = sql + " LIMIT 1000";
}
// 3. 执行
return jdbcTemplate.queryForList(sql);
}
第五步:前端页面
我们做了一个简单的对话框,业务人员输入问题,后端返回SQL和数据表格。支持类似这样的对话:
Q:上周五北京地区的订单总金额
A:表格 总金额 ¥23,456
Q:按商品类别分组看一下A:表格 类别A:¥8900,类别B:¥12340
模型会根据上下文理解"分组"是指对上一次查询结果再分组,所以我们还加了会话记忆(就是之前文章写的Redis记忆)。

💣 踩过的坑:Text2SQL不是银弹
在实际用的时候,发现几个大坑,分享出来你可能也会遇到。
坑一:SQL幻觉 ------ 生成了根本不存在的字段
有一次用户问"查询会员等级",模型写了个SELECT vip_level FROM users,但实际上我们的表里字段叫user_level。这是因为模型"猜"了,而不是严格按Schema来。
解决:在Prompt里强调"字段名必须从表结构中选取,不要自己编造",并且在返回SQL前,用正则检查SQL中出现的字段是否都在Schema里。
坑二:复杂关联查询瞎 join
比如问"买了A商品又买了B商品的用户",模型可能会把订单表自关联三次,性能极差。
解决:对复杂查询,我们不是完全信任AI,而是让它先输出"思考过程"(类似CoT),然后人工规则兜底。实在复杂的,还是让开发写。
坑三:数据权限怎么控制?
业务人员只能看自己部门的数据。我们是在执行SQL前,动态给WHERE条件加一层租户过滤。比如原来生成的SQL是SELECT * FROM orders,我们替换成SELECT * FROM orders WHERE dept_id = 'xxx'。
坑四:大模型调用成本
每次查询都要调一次API,一天几百次,费用也不少。我们做了两层缓存:相同的用户问题直接返回历史生成的SQL;相似问题用向量检索匹配历史。

✅ 最终效果与数据
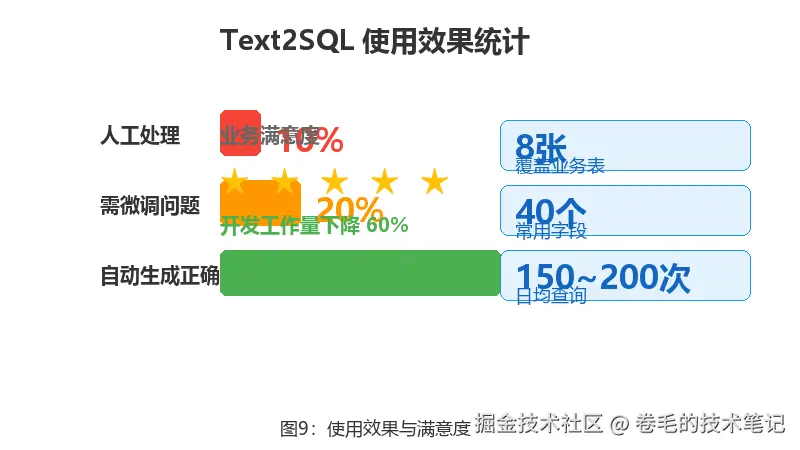
这个系统上线了小半年,实际数据是这样的:
- 覆盖了8张核心业务表 ,约40个常用字段
- 每天处理150~200次自然语言查询
- 约70% 的查询完全自动生成SQL并返回正确结果
- 20% 需要用户微调一下问题再试
- 10% 太复杂,模型无能为力,仍由人工处理
业务人员的反馈是: "小需求不用再排队等开发了,自己问就行。" 开发团队的SQL取数工作量大概降了60% 。
📌 总结:Text2SQL适不适合你?
如果你的团队经常被重复的取数需求困扰,并且数据库表结构相对规范、字段注释齐全,Text2SQL绝对值得一试。
不适用场景:库表几百张、字段命名乱七八糟没注释、查询极其复杂(比如多步计算、窗口函数嵌套)。这种场景下AI生成的SQL基本没法用。
建议循序渐进:先只开放几张最常用的表,配合严格的安全控制(只读+行数限制),跑通后再逐步扩展。
技术选型上,Java后端用Spring AI Alibaba或原生OpenAI SDK都能实现,重点在于Prompt设计和安全兜底。
最后想说的是:Text2SQL不是为了取代程序员写SQL,而是把我们从"重复取数"的低价值劳动中解放出来------把时间花在真正复杂的数据分析和系统优化上。
如果你们也在尝试类似的东西,欢迎在评论区交流踩过的坑。