- 【Day1-2】15分钟部署&运行 Gemma4 大模型,撰写学习笔记任务详情 - Datawhale AI学习中心 - Datawhale AI学习中心
- https://ailc.datawhale.cn/hall/group/100000144/task/100000036
- 完成任务"【Day1-2】15分钟部署&运行 Gemma4 大模型,撰写学习笔记",获得积分与勋章。包含学习、考试、实践等形式,即学即做。拆解微技能,上手微任务,向AI实战人才迈进。
- 2026-06-11 17:31
一、如何运行部署Gemma4 大模型
第一步:确认云环境和模型目录
-
点击右侧的 Terminal 图标新建一个 终端
-
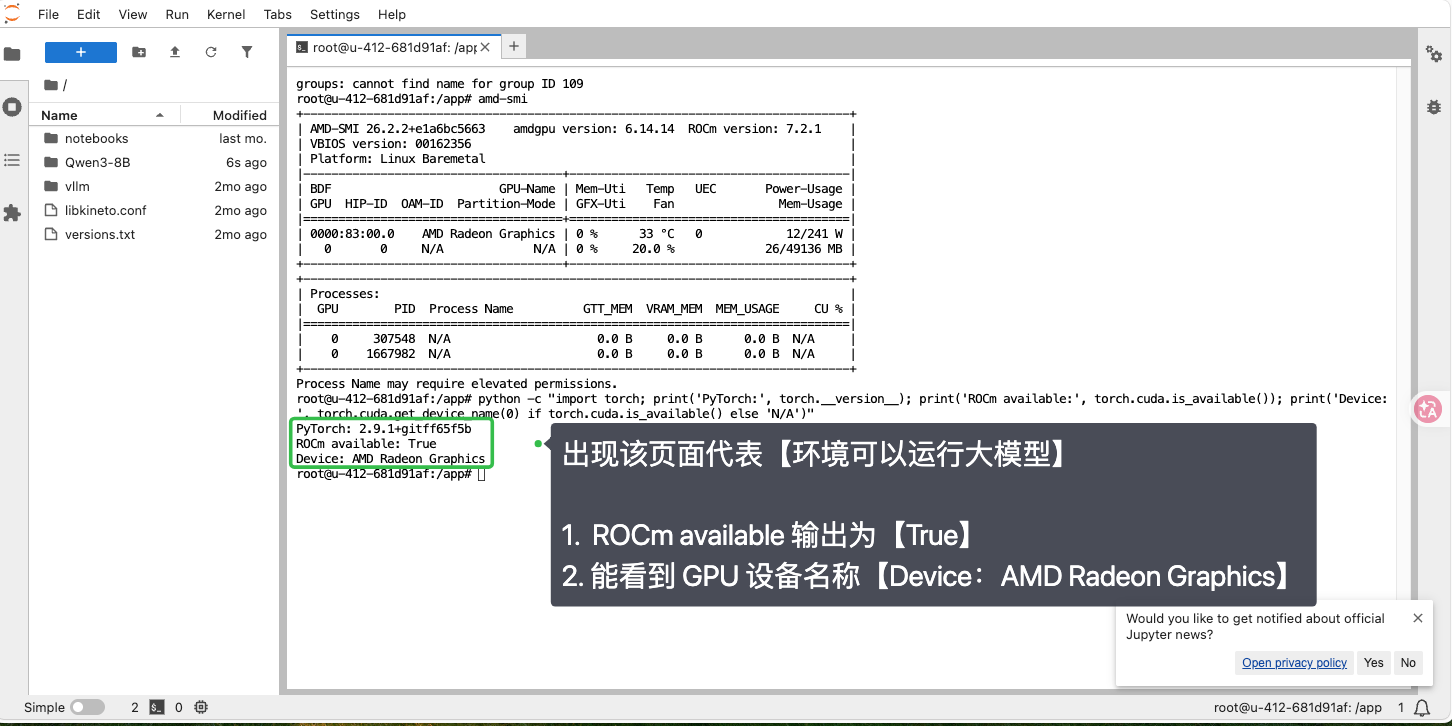
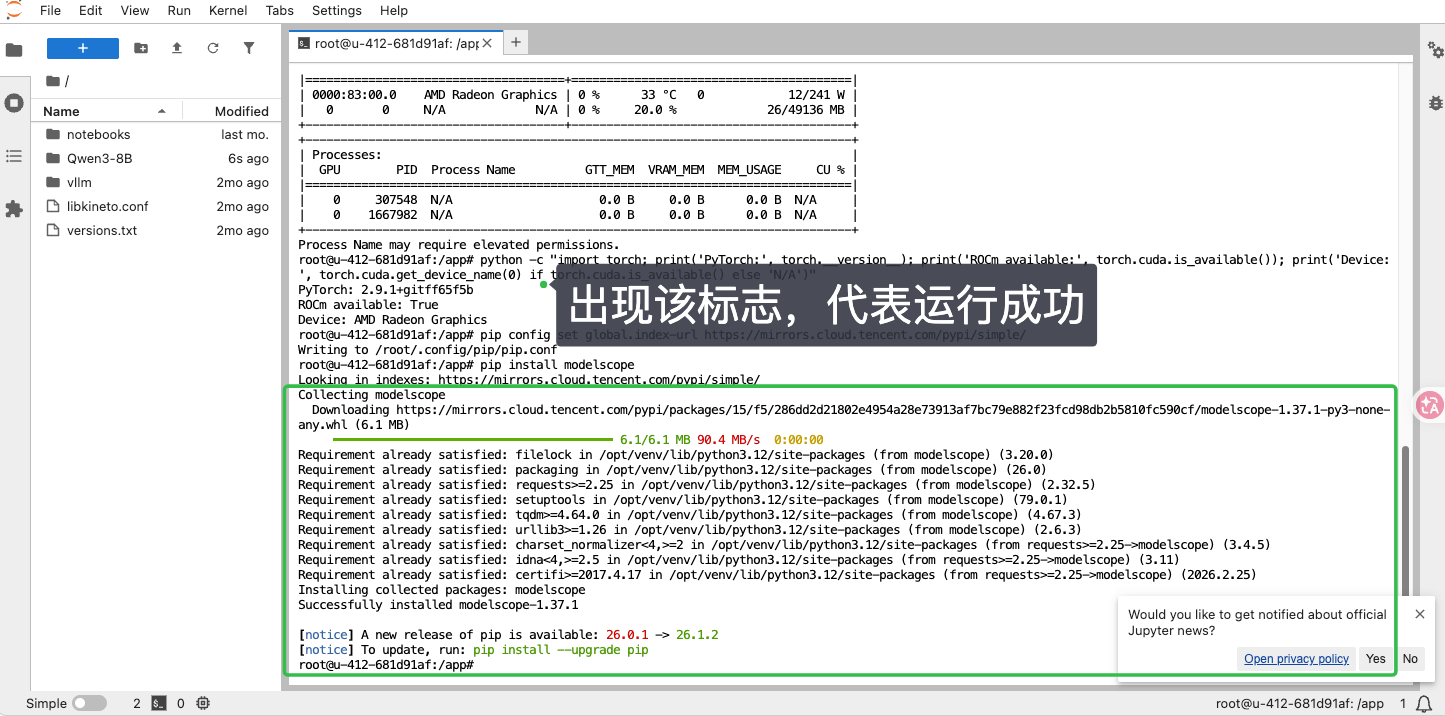
复制 指令 ,粘贴运行指令,检查当前 GPU 是否可用
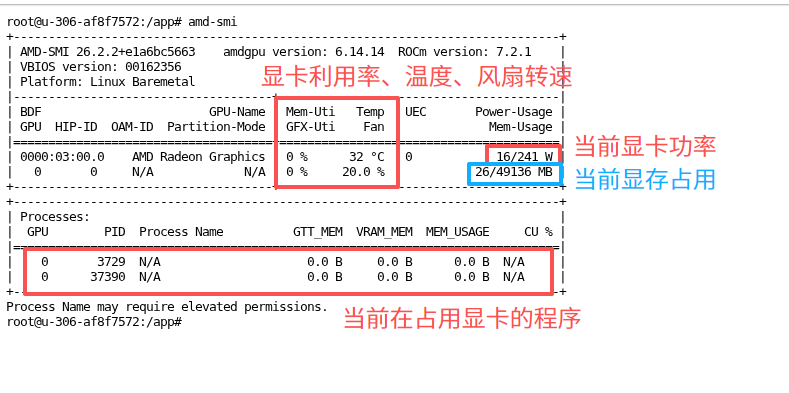
amd-smi
能看到这个内容就说明 GPU 可用
-
复制 Python 命令 ,粘贴命令运行,确认 PyTorch 能识别 AMD GPU
python -c "import torch; print('PyTorch:', torch.version); print('ROCm available:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')"
这是一个在终端(命令行)中直接执行的 Python 单行命令,用于快速检查 PyTorch 的安装环境,特别是 ROCm(AMD GPU 的机器学习框架)或 CUDA 的可用性。
命令形式解析
bash
python -c "import torch; ..."
python:调用 Python 解释器。-c:Python 的 "command" 选项,表示后面紧跟的字符串是一条 Python 代码。
执行完该代码后解释器立即退出,无需创建.py文件。"...":双引号内是完整的 Python 语句(多条语句用分号;分隔)。如何使用
- 在 Linux / macOS / Windows(命令提示符或 PowerShell) 中,直接复制整行命令,粘贴到终端并回车。
替代方法
如果想写成脚本文件,可以创建一个
check.py:python
import torch print('PyTorch:', torch.__version__) print('ROCm available:', torch.cuda.is_available()) if torch.cuda.is_available(): print('Device:', torch.cuda.get_device_name(0))然后运行
python check.py效果相同。总之,这条命令是一种简洁、无需文件的现场检测手段,非常适合在终端快速了解 PyTorch 的环境配置。
出现如下标志说明环境可以运行大模型
第二步:下载 Gemma4 模型
Gemma 4 是Google推出的一款大语言模型,后续我们学习如何微调这个LLM。
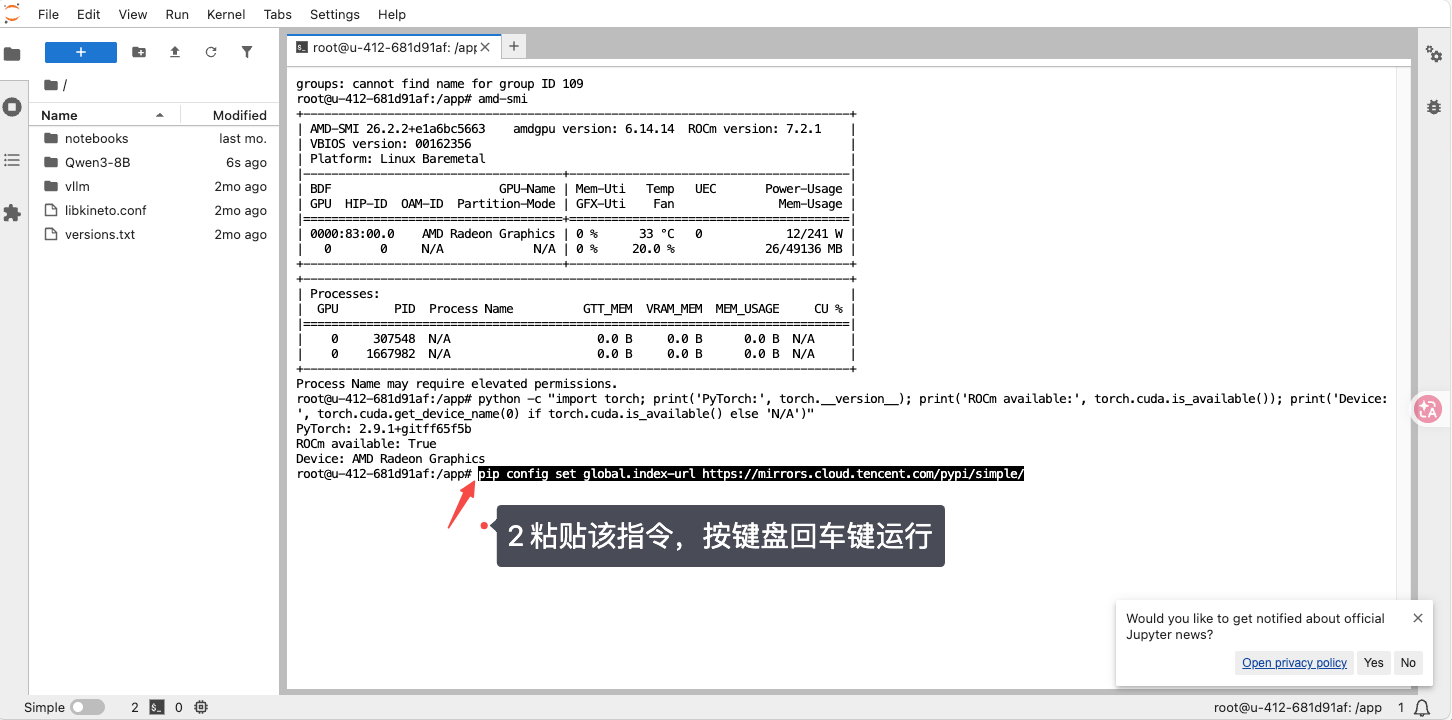
第一环节: 为了提升国内环境下的依赖下载速度,先把 pip 源切换到腾讯云镜像
-
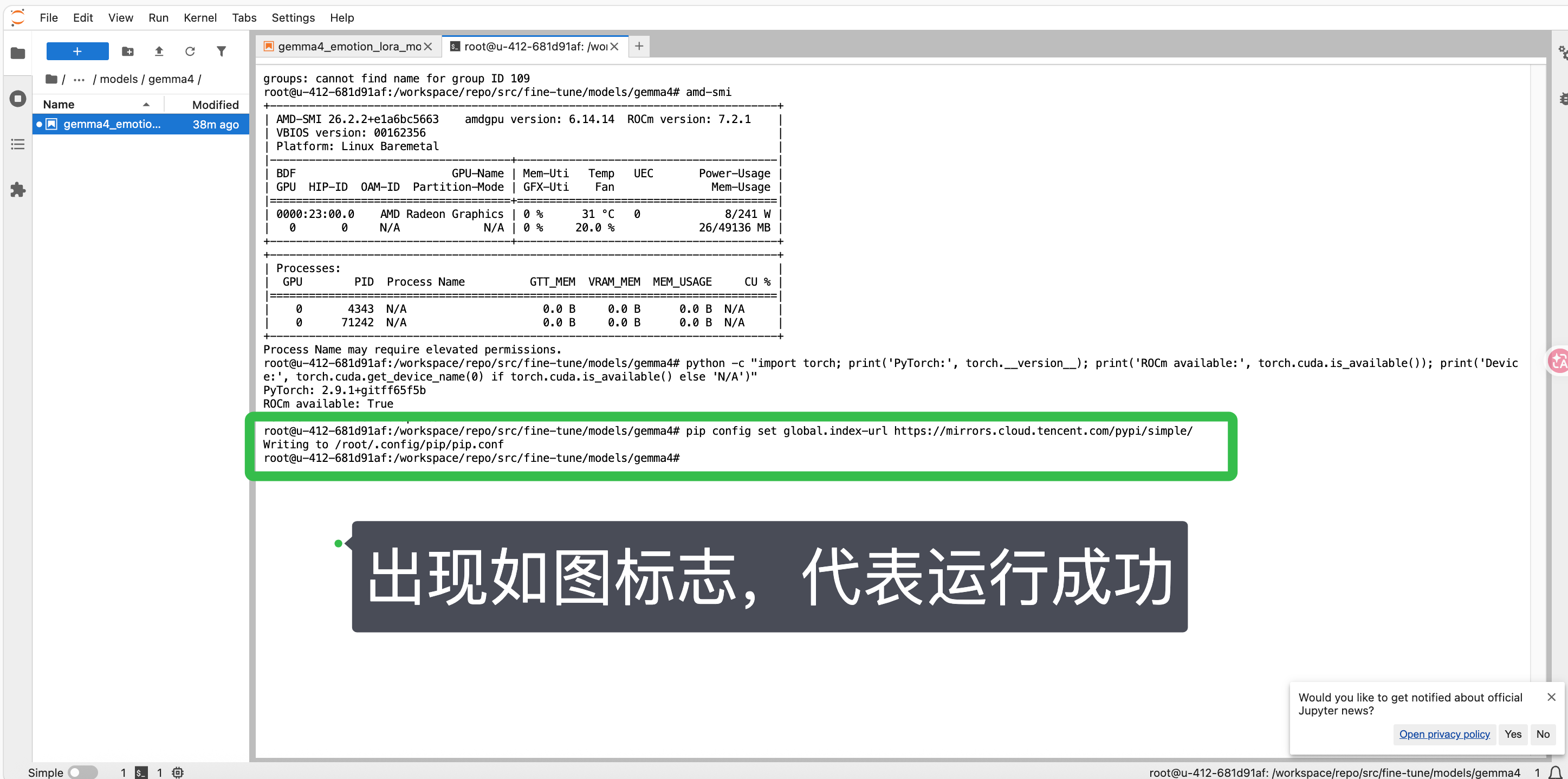
复制命令,粘贴命令运行
pip config set global.index-url https://mirrors.cloud.tencent.com/pypi/simple/
这条命令用于修改 pip 的配置 ,将默认的 Python 包索引源(PyPI)更换为腾讯云镜像源,从而在中国大陆地区获得更快的下载速度和更稳定的连接。
命令详解
bashpip config set global.index-url https://mirrors.cloud.tencent.com/pypi/simple/
pip config set:pip 提供的配置修改子命令,用于写入配置项。global.index-url:配置项路径,global表示全局生效(对所有用户),index-url是 PyPI 索引的 URL 地址。https://mirrors.cloud.tencent.com/pypi/simple/:腾讯云提供的 PyPI 镜像源地址。
作用效果
执行后,pip 在安装、搜索、列出包时,会优先从腾讯云镜像源拉取数据 ,而不是默认的
https://pypi.org/simple。这样可以:
- 大幅提升
pip install的速度(尤其在国内)。- 避免因国际网络波动导致的超时或连接失败。
如何使用
- 在命令行(终端 / CMD / PowerShell) 中直接粘贴并回车。
- 确保 pip 版本较新(旧版本可能不支持
config子命令,可升级:pip install --upgrade pip)。- 执行后无输出即为成功,或显示
Writing to ...表示配置已写入文件。
验证配置是否生效
bashpip config list会输出类似:
global.index-url='https://mirrors.cloud.tencent.com/pypi/simple/'也可以直接安装一个包观察速度:
bashpip install numpy
如何恢复默认源
若想恢复为官方 PyPI 源:
bashpip config unset global.index-url或手动将值改为
https://pypi.org/simple。
其他说明
作用范围 :
global对所有用户有效。若只想对当前用户生效,可用user代替global;若只对某个虚拟环境生效,可在激活环境后使用site。镜像源安全性 :腾讯云等国内大厂镜像会定期同步官方 PyPI,包内容是原样的,可放心使用。但不要随意使用来源不明的镜像。
可能需要的额外配置 :某些镜像源需要添加
--trusted-host,但现代 pip 通常已支持 HTTPS 且默认信任,一般无需额外操作。若遇到证书问题,可以执行:
bashpip config set global.trusted-host mirrors.cloud.tencent.com
总结
这条命令是 pip 换源 的标准写法,特别适合中国大陆开发者使用国内镜像加速 Python 包的安装。通过
pip config set修改配置比每次手动加-i参数更方便持久。
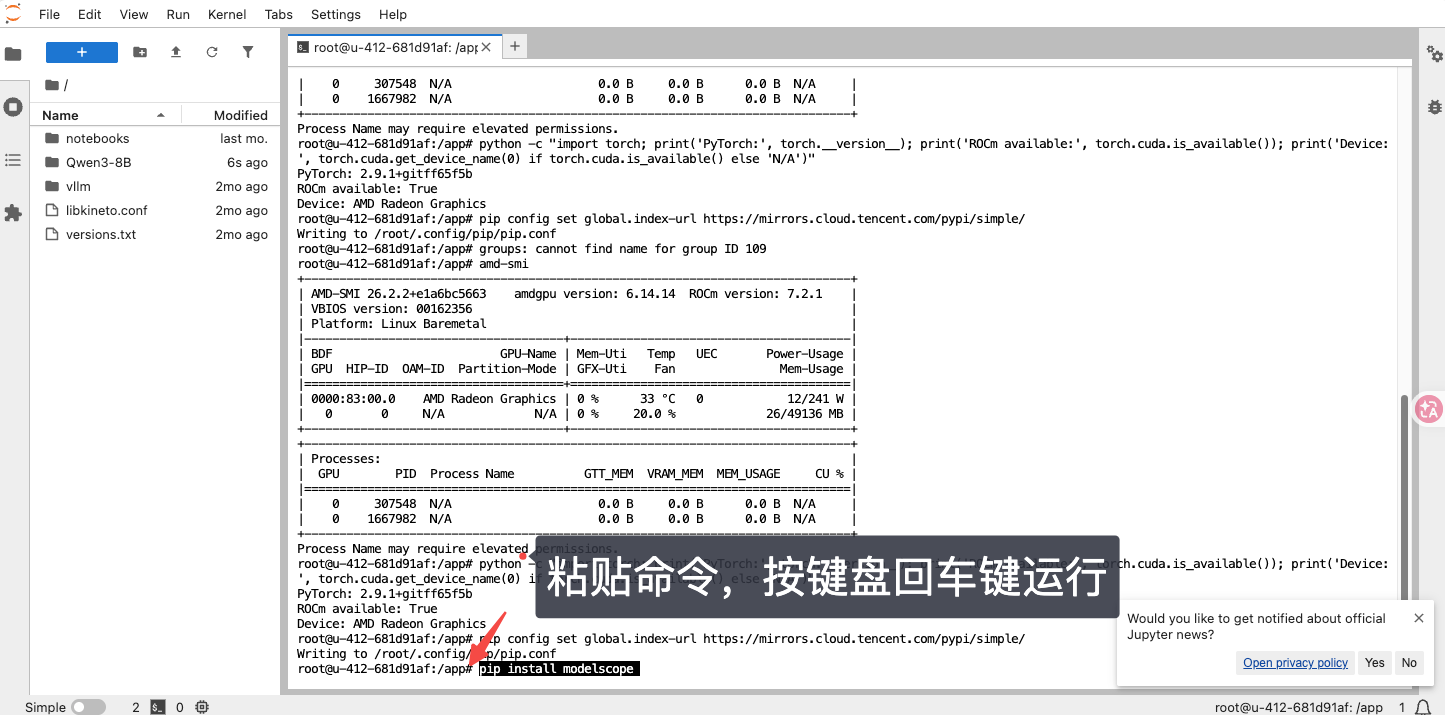
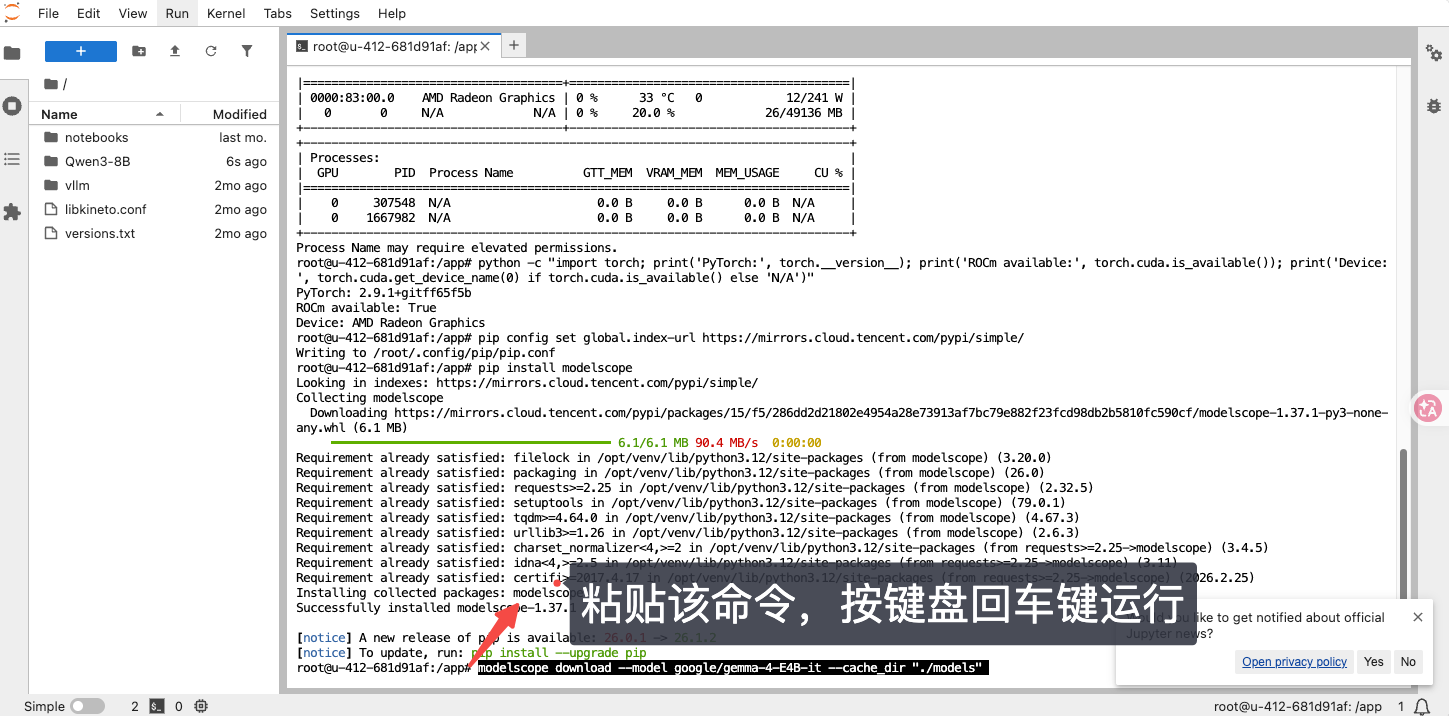
第二环节: 安装 魔搭 ModelScope
什么是 ModelScope? 它是由阿里达摩院主导的国内开源模型社区,是国内的"AI 模型应用商店"。而其服务器在国内,因此能帮我们高速、稳定地把大模型拉到本地。
-
复制命令,粘贴命令运行
pip install modelscope
简单来说,ModelScope就是一个国内的、功能更强大的"Hugging Face" ,它不只是一个存储模型的地方。对于你在服务器上做微调实验,安装它主要是为了解决两大痛点:获取数据 和拿到模型。
🤔 ModelScope 到底是个什么平台?
ModelScope(魔搭社区)是阿里巴巴在2022年推出的 "模型即服务"(MaaS) 平台,目标是为开发者提供从找模型、用模型到部署模型的一站式服务。
为了方便理解,你可以把它看作是功能更全面的"Hugging Face + Transformers 库" 。它既是一个在线社区,也是一个强大的Python工具库。
🤝 为什么说它是"中国的 Hugging Face"?
对比这两个平台,就能看出ModelScope对国内开发者的特殊价值:
特性 Hugging Face ModelScope (魔搭) 核心定位 全球最大的开源模型社区 中文友好的一站式模型平台 网络速度(国内) 海外为主,国内下载体验不佳,速度慢 本土CDN加速,下载速度快且稳定 中文生态 依赖社区贡献 官方维护大量中文SOTA模型,中文文档覆盖率高 主要模型 模型数量巨大(50万+),涵盖全球所有语言 模型质量高(1000+),中文模型丰富(如通义千问、ChatGLM等) 💡 你的理解,还可以再加一层
对开发者而言,ModelScope更像是一个低门槛、高效率的AI开发工作台。它通过SDK把模型仓库和开发工具无缝整合在一起,让你在写代码时就能搞定模型下载和微调,省去了去各个网站手动找配置的麻烦,使得整个开发流程变得非常简单。
ModelScope的低门槛和高效率体现在,它将一个复杂的AI应用开发过程,浓缩成了像操作一个集成工具箱一样简单的体验。
它不是一个普通的网站,而是一个"模型即服务 "(MaaS)平台,其核心设计理念是以模型为中心的一站式开发和体验。它就像一个大型建材市场,让你能一站式找到所有东西:
🏪 丰富的模型仓库:它提供了超过2000个涵盖自然语言处理、计算机视觉等几乎所有主流AI方向的预训练模型。这些模型就像是盖房子所需的"预制板",质量高且已就位,省去了你从头烧制砖块的时间。
🛠️ 无缝衔接的开发者工具链:通过SDK将模型下载、微调、评估和部署等所有工具无缝整合在一起。
- 模型加载 :只需要一行代码(如
from modelscope.pipelines import pipeline),就能完成模型的加载和推理。- 模型微调 :也只需要大概十行代码,就能使用LoRA(低秩适应)这样的微调技术,去适应你的数据。
- 模型部署:模型可以一键部署为RESTful API服务,方便地被其他应用程序调用。
因为国内访问海外平台速度不稳定,ModelScope的低门槛和高效率 通常意味着下载大模型的速度能提升10倍以上 。传统方式需要处理十几个环节的流程,通过ModelScope可能被压缩到5个主要步骤,整体效率能提升40%以上。
✨ ModelScope 的核心优势
它的价值主要体现在这几点:
- 🐌 告别"龟速"下载 :这是它最直接的好处。通过国内的CDN加速,下载大模型的速度能提升10倍以上。一个70亿参数的模型,用ModelScope下载可能只要几分钟,而在Hugging Face上可能需要几个小时,甚至还会失败。这让你做微调实验的效率大大提升。
- 🇨🇳 专为中文开发者打造:它拥有强大的中文大模型生态,对中文的支持非常好。像阿里的通义千问(Qwen)、智谱AI的ChatGLM这些热门的中文模型,都能在这里找到官方优化过的版本,而且有中文文档和技术支持。
- 🚀 强大的微调"利器" :安装
modelscope库后,你可以获得强大的微调工具,比如 ms-swift 。这个框架支持 600+ 个纯文本大模型 和 400+ 个多模态大模型,让你能进行预训练、微调、对齐等全流程的开发。让你可以在服务器上执行类似下面的代码来轻松微调模型:
pythonfrom modelscope.trainers import Trainer from modelscope.msdatasets import MsDataset dataset = MsDataset.load('your_dataset') trainer = Trainer(model='your_model', train_dataset=dataset) trainer.train()总的来说,在微调实验中安装ModelScope,不是为了替代任何已有的东西,而是为了利用它的一站式服务 和国内网络优势 ,让你的实验进行得更高效、更顺畅。
-
复制命令,粘贴命令运行,下载 Gemma4 模型到当前目录
modelscope download --model google/gemma-4-E4B-it --cache_dir "./models"
运行命令后,需等待8分钟,然后查看下载完成结果(成功下载后的提示比较隐蔽)
这条命令用于从 ModelScope 平台下载预训练模型到本地,是针对大模型(如 Gemma)进行本地微调或推理前的必要准备步骤。
命令分解
bashmodelscope download --model google/gemma-4-E4B-it --cache_dir "./models"
modelscope downloadModelScope 官方命令行工具的子命令,专门负责下载模型文件(支持断点续传、增量更新)。
--model google/gemma-4-E4B-it指定要下载的模型 ID,格式为"组织名/模型名"。这里
google/gemma-4-E4B-it是谷歌在 ModelScope 上托管的 Gemma 系列的一个版本(具体是 4B 参数量的指令微调版)。注意:实际是否存在这个准确的模型 ID 需要确认。
--cache_dir "./models"指定缓存根目录 为当前目录下的
models文件夹。ModelScope 会将模型文件保存在./models/google/gemma-4-E4B-it/内(自动追加模型 ID 作为子目录)。实际文件保存位置
执行后,你会在当前路径下看到:
./models/google/gemma-4-E4B-it/ ├── config.json ├── pytorch_model.bin ├── tokenizer.json └── ...⚠️ 如果你期望模型直接放在
./models文件夹内(不额外嵌套模型名的子目录),请改用--local_dir参数:
bashmodelscope download --model google/gemma-4-E4B-it --local_dir "./models"更通用的用法示例
1. 下载其他模型
bashmodelscope download --model Qwen/Qwen2-7B-Instruct --cache_dir ./my_models2. 下载特定版本(revision)
bashmodelscope download --model ZhipuAI/chatglm3-6b --revision v1.0.0 --cache_dir ./cache3. 只下载部分文件(--include)
bashmodelscope download --model AI-ModelScope/stable-diffusion-v2-1 \ --include "*.safetensors" "*.json" \ --cache_dir ./models4. 排除某些文件(--exclude)
bashmodelscope download --model google/gemma-7b \ --exclude "*.bin" \ --cache_dir ./models如何安装 modelscope 命令行工具?
这条命令依赖于 ModelScope 的 Python 包。如果系统提示
modelscope: command not found,请先安装:
bashpip install modelscope安装后即可在终端直接使用
modelscope download命令。常见问题解决
问题现象 可能原因 解决方法 下载极慢或超时 网络到 ModelScope 不稳定 无需代理(国内源本身已优化),但可尝试 --use-cache或改用 Python SDK提示 Model not found模型 ID 错误 去 modelscope.cn 搜索准确的模型 ID 磁盘空间不足 大模型通常 10~100GB 使用 df -h检查,或换到更大的分区中断后如何续传 默认支持断点续传 再次执行相同命令即可,已下载的文件会跳过 Python SDK 等价写法(可选)
如果你更喜欢写脚本:
pythonfrom modelscope import snapshot_download model_dir = snapshot_download('google/gemma-4-E4B-it', cache_dir='./models') print(f'模型缓存于: {model_dir}')总结
- 这条命令的核心作用:从 ModelScope 模型库下载指定模型到本地缓存目录。
- 典型使用场景:准备微调或推理所需的基础模型文件。
- 最常用参数 :
--model(模型ID)、--cache_dir/--local_dir(存放位置)、--revision(版本)。- 小贴士 :记住
--local_dir是直接下载到指定文件夹(不嵌套),--cache_dir会自动添加模型名子目录。如果你能提供你实际想要下载的模型名称(例如
Qwen/Qwen2-7B-Instruct),我可以给出精确可运行的命令。
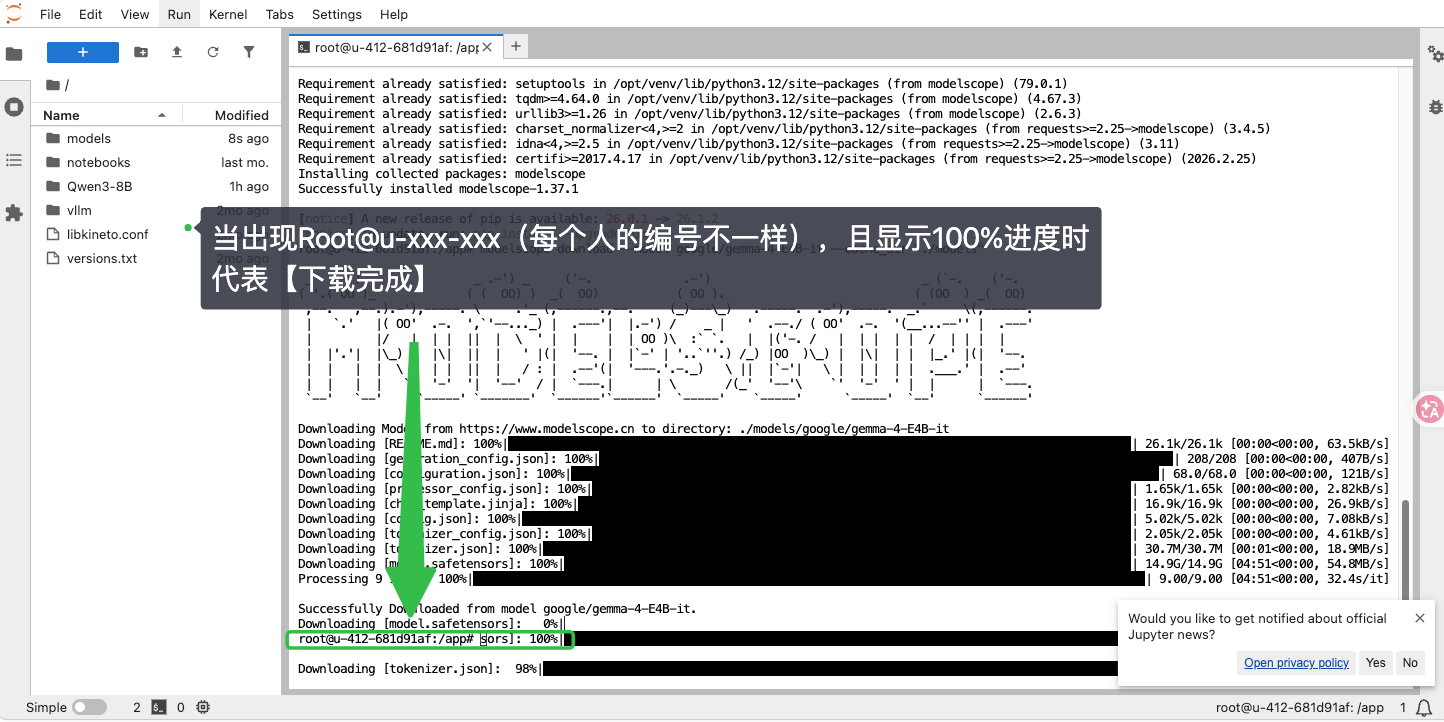
⚠️ 重要提醒:进度条卡住别急着停!
过程中你可能会遇到这种情况:有的进度条停在那儿不动、或显示没到 100%,看起来像卡住了------这通常是正常的,不代表下载失败,耐心等待即可。
如果迟迟没有进度更新,想判断是否真的下载完成,也可以找找有没有这一行提示,如果出现可进行下一步
Successfully Downloaded from model google/gemma-4-E4B-it(可能出现的位置相对隐蔽)
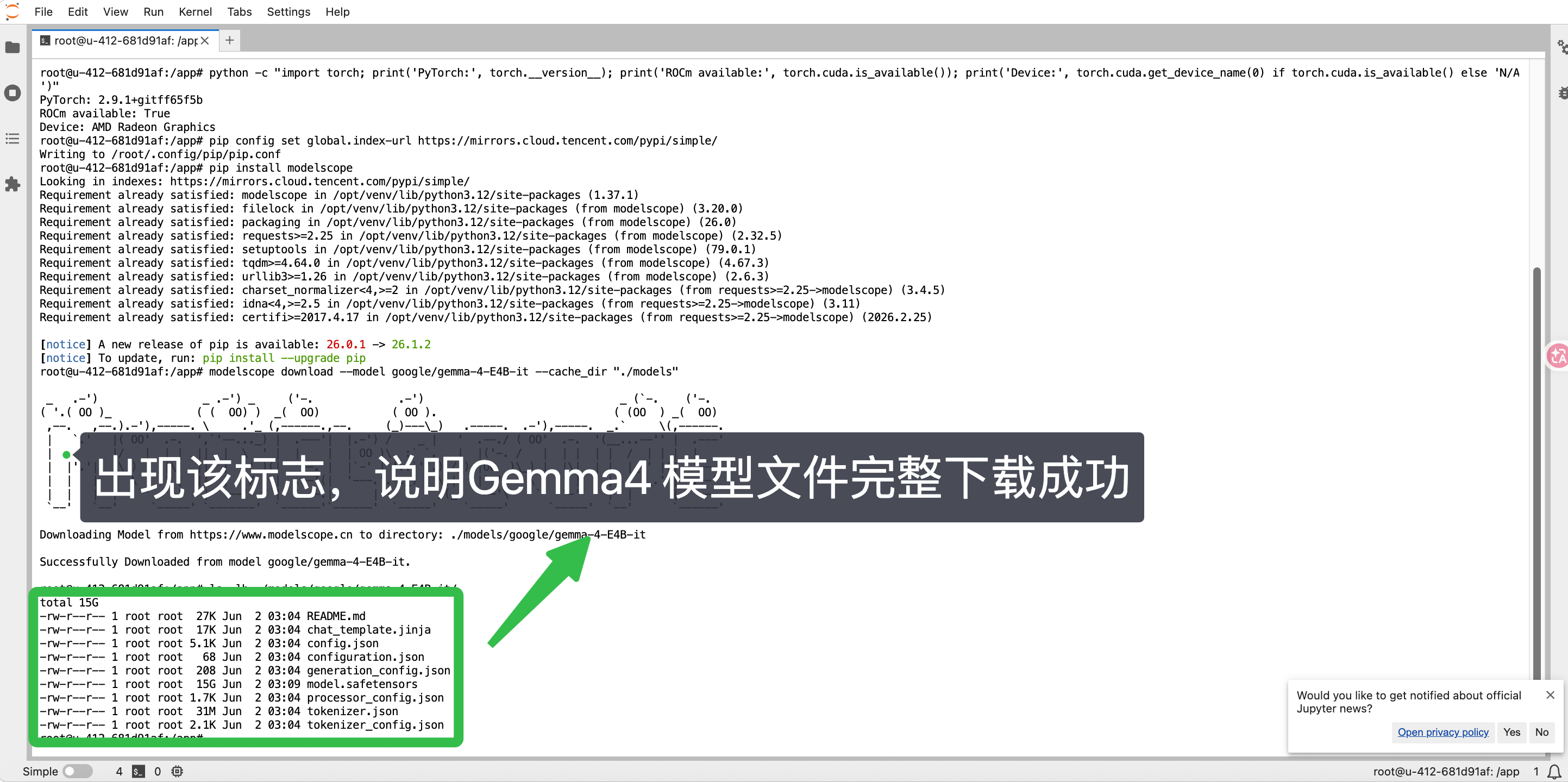
- 复制命令,粘贴命令运行,确认 Gemma4 模型模型文件完整下载成功
其中15G大的 model.safetensors 是模型权重
ls -lh ./models/google/gemma-4-E4B-it/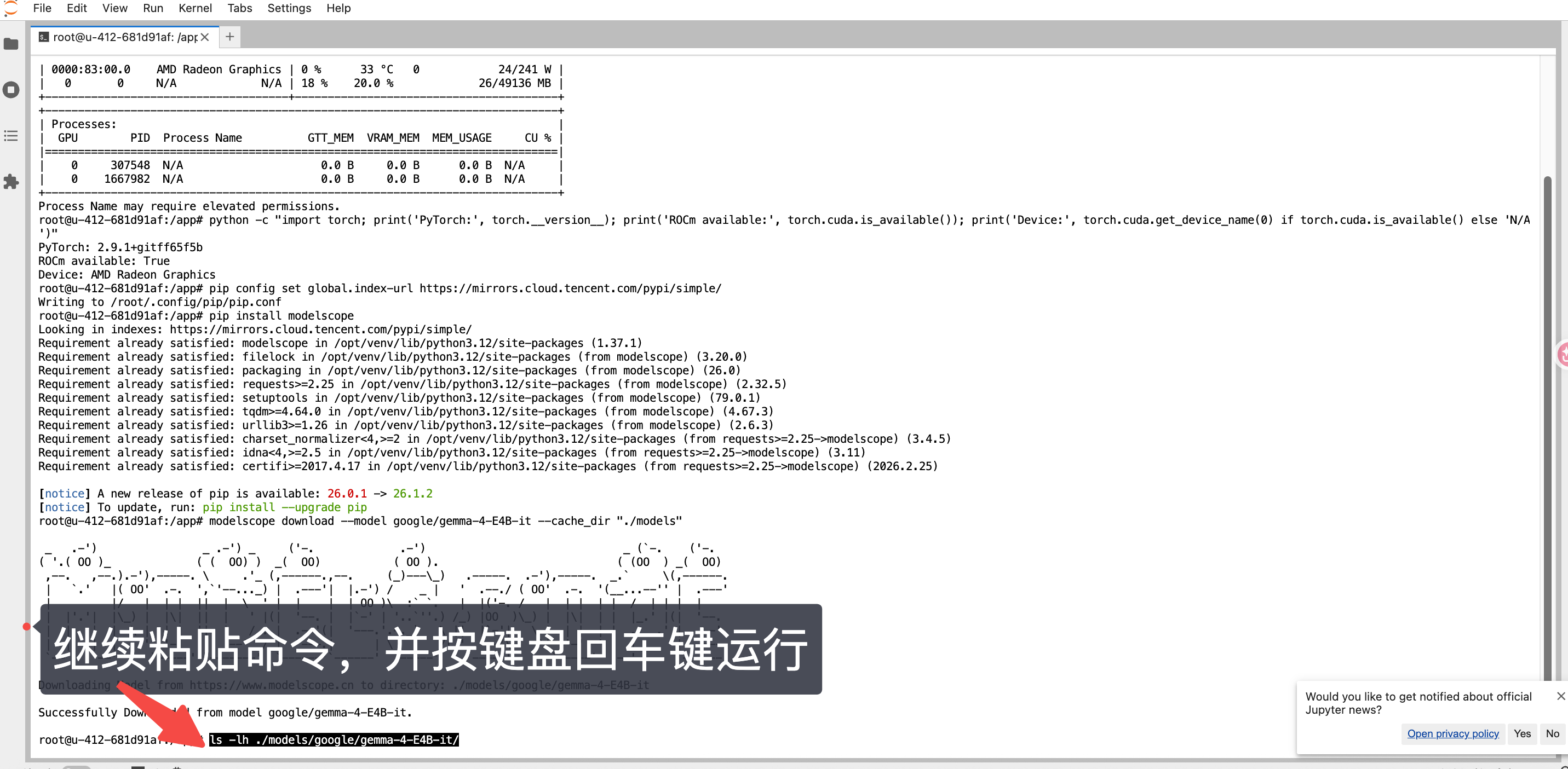
第三步:启动 vLLM 服务
vLLM 是一个本地高效推理大模型的项目,这里我们使用vLLM来测试刚才下载的模型能否正常使用。
在使用 vLLM 前,需更新云环境中的 vLLM 版本才能运行 Gemma4 模型。 操作步骤如下:
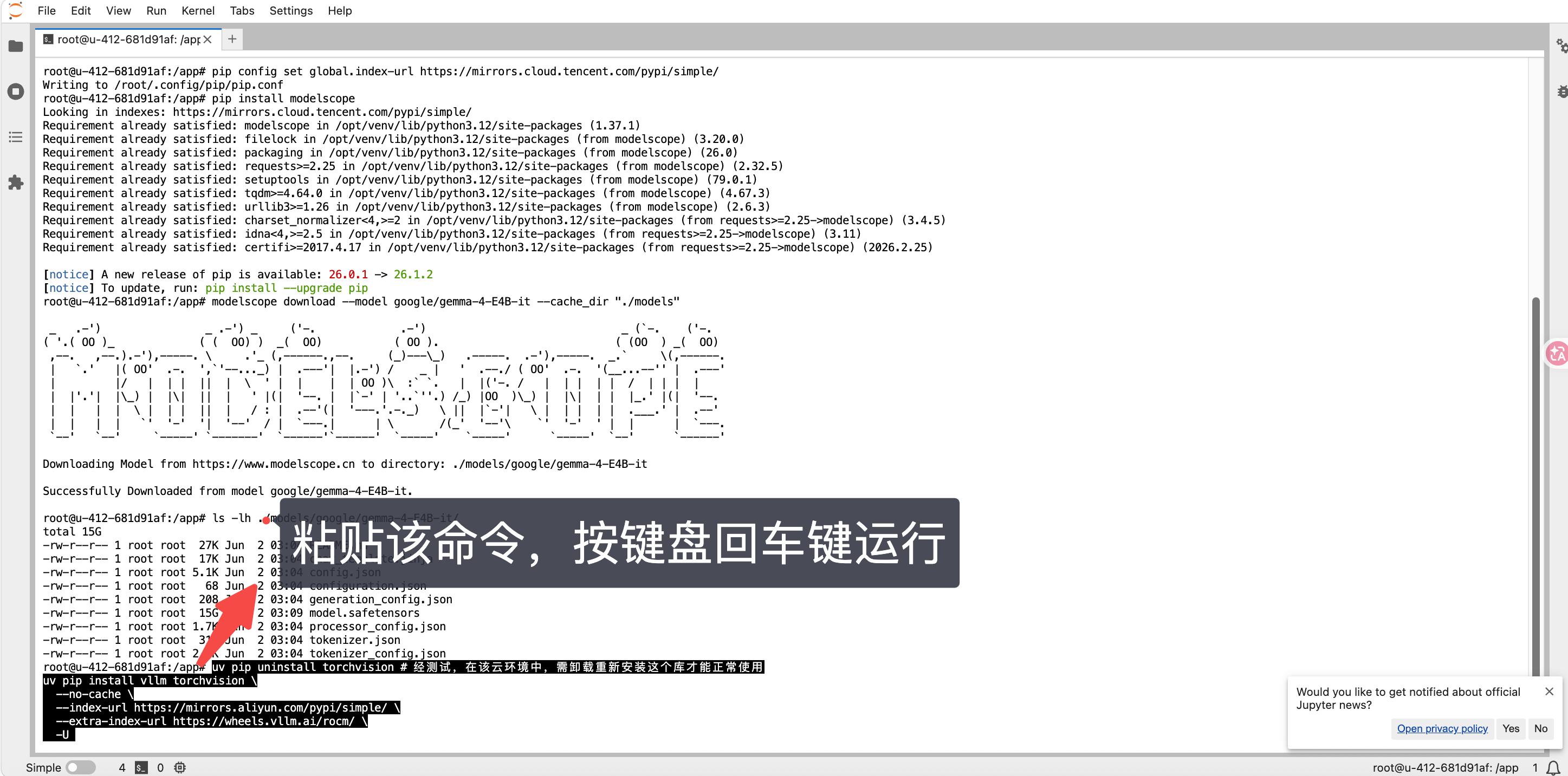
-
复制命令,粘贴命令运行
uv pip uninstall torchvision # 经测试,在该云环境中,需卸载重新安装这个库才能正常使用
uv pip install vllm torchvision
--no-cache
--index-url https://mirrors.aliyun.com/pypi/simple/
--extra-index-url https://wheels.vllm.ai/rocm/
-U
这是一个针对云环境中使用 ROCm(AMD GPU)运行 vLLM 推理框架 的依赖修复与安装命令。它解决了一个常见问题:预装的
torchvision与当前 PyTorch 或 ROCm 环境不兼容,导致 vLLM 无法正常使用。
命令整体目的
- 卸载 当前有问题的
torchvision。- 重新安装 兼容的
torchvision,同时安装vllm(一个高性能大模型推理库)。- 使用阿里云镜像 加速下载,并添加 vLLM 官方 ROCm wheel 仓库以获得 ROCm 版本的 vLLM。
- 升级所有相关包到最新版本(
-U)。
逐条命令解析
1.
uv pip uninstall torchvision
uv:一个极快的 Python 包管理器(用 Rust 写,替代 pip 的部分功能,类似pip但更快)。如果你的环境中没有uv,可以用pip代替。作用 :卸载当前已安装的
torchvision。原因:注释里说明"在该云环境中,需卸载重新安装这个库才能正常使用"。常见原因是:
- 预装的
torchvision编译时链接的 PyTorch 版本与当前实际使用的 PyTorch 不匹配(比如 ROCm 版 PyTorch 要求特定版本的 torchvision)。- 文件损坏或版本冲突(如 torchvision 与 vLLM 的依赖要求冲突)。
2.
uv pip install vllm torchvision安装两个包:
vllm:适用于大语言模型的高吞吐量推理引擎,支持 PagedAttention、连续批处理等优化。在 ROCm 环境中需要专门的 wheel。torchvision:PyTorch 的计算机视觉库。重装是为了确保它和当前的 PyTorch(ROCm 版)完全兼容。3.
--no-cache
- 禁止使用 pip 的本地缓存。强制重新从索引服务器下载包,避免使用可能损坏或过旧的缓存文件。在遇到版本冲突或损坏时很有用。
4.
--index-url https://mirrors.aliyun.com/pypi/simple/
- 设置主索引源为阿里云 PyPI 镜像。国内服务器使用阿里云镜像可以大幅提升下载速度和稳定性,避免国外源的超时问题。
5.
--extra-index-url https://wheels.vllm.ai/rocm/
- 添加额外的索引源 ,专门用于查找 vLLM 针对 ROCm(AMD GPU)编译的 wheel 包。
- 普通的 PyPI 源可能只提供 CUDA 版本的 vLLM,而通过这个 extra-index,pip 会优先或额外搜索该 URL 来找到
vllm的 ROCm 兼容版本。6.
-U(即--upgrade)
- 升级所有要安装的包到最新版本。因为之前可能已安装旧版,加上
-U可以确保获得与当前环境最兼容的新版本。
为什么在这个云环境中要这样处理?
问题 原因 解决方案 torchvision不兼容预装镜像可能安装了 CUDA 版的 torchvision,但当前 PyTorch 是 ROCm 版;或者版本号不匹配。 卸载后重新安装,让 pip 根据当前 PyTorch 版本自动拉取兼容的 torchvision。 vLLM 默认只支持 CUDA vLLM 官方 PyPI 包通常是为 NVIDIA GPU 构建的,在 AMD GPU(ROCm)上会报错。 添加 --extra-index-url指向 vLLM 为 ROCm 预编译的 wheel 仓库。国内网络慢 直接访问 PyPI 或 vLLM 官方源速度慢、易超时。 使用阿里云镜像作为主源( --index-url),同时 extra-index 也走国内可访问的地址(vLLM 的 wheel 仓库也在国内加速)。缓存干扰 之前失败的安装可能留下损坏的 wheel 缓存。 --no-cache强制重新下载。验证是否成功
pythonimport torch import torchvision import vllm print(torch.__version__) print(torchvision.__version__) print(vllm.__version__) # 检查 ROCm 是否可用 print(torch.cuda.is_available()) # 对 ROCm 也返回 True如果无报错且能正常加载,说明环境修复成功。
注意事项
uvvspip:uv是第三方的快速包管理器,并非所有环境都有。如果没有,直接换成pip即可,功能完全等效。- vLLM ROCm 支持 :确保你使用的 vLLM 版本确实支持你的 ROCm 版本(如 ROCm 5.6/5.7/6.0)。如果
--extra-index-url中没有适合你 ROCm 版本的 wheel,可能需要从源码编译。- PyTorch ROCm 版 :在执行上述命令前,应已通过
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.6类似命令安装好 ROCm 版 PyTorch。vLLM 会依赖该 PyTorch。
总结
- 这条命令是为了修复云环境中 torchvision 与 vLLM 的兼容性问题 ,并安装 ROCm 版本的 vLLM。
- 它结合了换源加速、清除缓存、额外索引等技术,是一种典型的"AI 环境故障修复"操作。
- 如果你遇到
vllm无法在 AMD GPU 上运行,或者torchvision报类似undefined symbol错误,这个命令就是标准解决方案。
-
继续复制命令,粘贴命令运行
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it
执行的
vllm serve命令是正确的,它会使用你预先下载好的 Gemma 模型,启动一个兼容 OpenAI API 协议的本地推理服务器。📋 命令详解:
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it这个命令由几个核心部分组成,用于定义模型位置和API服务的行为。理解下面这几个部分,就能完全掌握这个命令了。
vllm serve:这是 vLLM 提供的子命令,专门用于启动一个高性能模型推理服务器。它会加载模型,对外提供标准的 OpenAI API 接口供应用程序调用。./models/google/gemma-4-E4B-it/:模型路径,告诉服务器到本地的./models/google/gemma-4-E4B-it/这个目录去加载你之前已经下载好的模型文件。这是当前最推荐的方法。请注意,这里不应该再用--model参数来指定路径。--served-model-name gemma-4-E4B-it:API 模型别名,它是一个非常有用的参数。当客户端通过 API 访问时,用这个自定义的别名(例如gemma-4-E4B-it)来代替冗长的本地路径。这让你可以随时更换模型版本而无需修改客户端代码,非常灵活。
⚙️ 最常用参数参考
当执行
vllm serve时,你还可以通过添加一些参数来灵活地控制服务行为,以下是几个最常用参数的对比,方便你查阅:
参数类别 参数与示例值 作用说明 模型与API配置 --host 0.0.0.0服务监听地址, 0.0.0.0允许外部访问;默认127.0.0.1则只允许本地请求。--port 8000API 服务端口,可按需修改。 --api-key xxx设置 API 密钥,增强服务安全。 性能优化 --tensor-parallel-size 2启用张量并行,使用多个GPU(如2个)来共同推理一个模型,是应对大模型的核心参数之一。 --gpu-memory-utilization 0.9控制 vLLM 可使用GPU显存的比例(范围0-1),调高可以处理更大并发。 --max-model-len 8192设置模型的最大上下文长度,可根据你的应用需求调整。 高级功能 --trust-remote-code信任并执行模型仓库中的自定义代码,通常需要开启。 --dtype bfloat16指定模型权重和激活的数据类型(如 bfloat16,float16),影响性能和精度。--enable-prefix-caching启用自动前缀缓存,适合有大量共享前缀的对话场景。
🚀 如何使用你启动的API服务
服务启动后,它就成为一个标准的 API 服务器。你可以通过多种客户端(如
curl、requests、openai库)向它发送请求。1. 使用 curl 发送请求
这是最直接的方法,用于快速测试。
bashcurl http://localhost:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma-4-E4B-it", "prompt": "你好,请介绍一下自己。", "max_tokens": 100, "temperature": 0.7 }'
"model":在请求体中,model字段的值必须 与你启动时--served-model-name设置的名称完全一致。2. 使用 Python openai 库
在你的代码中,可以像调用 OpenAI 的 API 一样调用本地模型,这非常适合集成到复杂的应用中。
pythonfrom openai import OpenAI # 配置客户端指向你的本地 vLLM 服务器 client = OpenAI( base_url="http://localhost:8000/v1", # 修改为你的服务器地址 api_key="EMPTY", # 如果未设置 --api-key,此项可留空 ) completion = client.chat.completions.create( model="gemma-4-E4B-it", # 必须与 --served-model-name 一致 messages=[ {"role": "system", "content": "你是一个有用的助手。"}, {"role": "user", "content": "你好!"}, ], max_tokens=100, ) print(completion.choices[0].message.content)vLLM 的 API 服务器默认是 OpenAI 兼容的,同时它也提供了对 Anthropic API 的实验性支持。
🔵 一、默认模式:OpenAI 兼容的 API
从执行的
vllm serve命令官方描述Launch a local OpenAI-compatible API server就能看出,其核心就是提供一个 OpenAI 格式的 HTTP 接口。这意味着:
- 无需改动客户端 :现有的、为 OpenAI API 编写的代码或工具(例如使用
openai库的脚本)只需要将base_url改为你本地 vLLM 服务的地址,就能直接使用。- 调用示例 :你之前的回复中提供的 Python 示例,用
openai库连接http://localhost:8000/v1进行调用,就是标准用法。🟤 二、备用模式:切换至 Anthropic API
可以改成 Anthropic 风格。vLLM 内部实现了对 Anthropic Messages API 的处理逻辑,能将收到的 Anthropic 请求自动转换成模型可以处理的格式,使得兼容 Anthropic 格式的客户端(如 Claude Code)也能调用它。
切换方式不是 通过
vllm serve命令的参数直接指定,而是需要从客户端下手,主要用来对接那些专为 Anthropic API 设计的应用:
- 主要用途 :可以让 Anthropic 的官方工具,如 Claude Code,直接使用你本地 vLLM 部署的开源模型作为后端引擎。
- 配置方法:将客户端的请求地址和 API 密钥通过环境变量指向你的 vLLM 服务即可。
bash# 1. 启动 vLLM 服务器(保持默认启动命令即可) vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it # 2. 在另一个终端,为 Claude Code 设置环境变量 export ANTHROPIC_BASE_URL="http://localhost:8000" # 指向你的 vLLM 服务器 export ANTHROPIC_API_KEY="any-placeholder-value" # vLLM 默认不需要鉴权 # 3. 然后正常启动 Claude Code 即可 claude总的来说,默认的 OpenAI 模式 适用性更广,可以无缝对接现有应用和库。而 Anthropic 模式更像一个可选的转换层,主要是为了让那些原生为 Anthropic API 设计的应用能接入使用,通常不会作为主要的开发接口。
理解"为什么兼容"以及"背后发生了什么",能帮你真正掌握这类推理服务器的设计思路。
简单说:兼容格式是为了让不同厂商的模型服务能够"讲同一种语言" ,就像 USB-C 接口统一了各种外设的连接方式。具体到 vLLM,它做的是格式转换 + 协议适配,而不是重新发明一套调用规则。
下面分别解释为什么做 和过程发生了什么。
一、为什么要兼容 OpenAI 的 API 格式?
1. 生态复用:成千上万的现成工具直接可用
OpenAI 的 API 规范(
/v1/chat/completions、/v1/completions、/v1/embeddings)已经成为事实上的工业标准。几乎所有与大模型交互的软件------
- 开发框架:LangChain、LlamaIndex
- 应用工具:ChatBox、NextChat、Open WebUI
- SDK:openai-python、openai-node、curl 示例
- 生产组件:API 网关、监控、限流中间件
默认都支持 OpenAI 格式。如果你的本地模型服务也兼容这种格式,就可以零修改直接接入整个生态。否则,你需要为每个工具写适配层,这是巨大的重复劳动。
2. 降低迁移成本:一次写代码,到处运行
团队开发 AI 应用时,可以先使用 OpenAI 的云端 API 快速验证原型,随后只需修改一行
base_url就能切换到本地 vLLM 服务(成本更低、数据不外传)。代码不需要变动,因为请求和响应的 JSON 结构完全一致。3. 避免供应商锁定
如果模型服务都采用私有 API,换一个模型就需要重写所有调用逻辑。兼容 OpenAI 格式意味着你可以自由在云端 GPT、本地 Llama、vLLM 托管的任意模型之间切换,而应用程序无感知。
二、兼容格式时,底层发生了什么过程?
当你在终端执行:
bashvllm serve ./my-model --served-model-name gemma然后客户端发送一个 OpenAI 格式的 HTTP 请求,vLLM 内部经历了以下转换流水线:
阶段1:接收请求(HTTP 层)
- vLLM 启动一个基于 FastAPI 的 web 服务器,监听
/v1/chat/completions、/v1/completions等路由。- 客户端发送 POST 请求,Body 是 JSON,例如:
json{ "model": "gemma", "messages": [{"role": "user", "content": "Hello"}], "temperature": 0.7, "max_tokens": 100 }阶段2:请求解析与映射(OpenAI → 内部格式)
vLLM 将 OpenAI 的通用字段映射到自己的
SamplingParams和Prompt结构:
OpenAI 字段 vLLM 内部字段 说明 messagesprompt(通过 tokenizer 转换为文本)对话历史转为模型能理解的字符串格式(如 `< temperaturetemperature直接传递 max_tokensmax_tokens直接传递 top_p/frequency_penalty等对应参数 直接映射 关键一步:将 messages 数组转换为纯文本 prompt 。
例如 Gemma 的对话模板可能是:
<start_of_turn>user Hello<end_of_turn> <start_of_turn>modelvLLM 内置了常见模型的 tokenizer 和模板(通过 Hugging Face
tokenizer.apply_chat_template)。阶段3:模型推理(vLLM 核心引擎)
- 将生成的 prompt 送入 vLLM 的高性能推理引擎(PagedAttention、continuous batching)。
- 模型输出 token 序列(不直接返回文本,而是整数 ID 序列)。
阶段4:响应转换(内部格式 → OpenAI 格式)
vLLM 将模型输出的 token ID 解码为文本,然后组装成 OpenAI 规定的响应结构:
json{ "id": "cmpl-xxxx", "object": "chat.completion", "created": 1712345678, "model": "gemma", "choices": [ { "index": 0, "message": { "role": "assistant", "content": "Hello! How can I help you?" }, "finish_reason": "stop" } ], "usage": { "prompt_tokens": 10, "completion_tokens": 8, "total_tokens": 18 } }阶段5:返回 HTTP 响应
JSON 响应通过 HTTP 发回客户端。客户端使用标准 OpenAI SDK 就能自动解析。
三、改为兼容 Anthropic API 时,过程类似
当你设置环境变量
ANTHROPIC_BASE_URL=http://localhost:8000并发送 Anthropic 格式请求(如POST /v1/messages),vLLM 同样会做请求体转换:
- 输入转换 :Anthropic 的
messages数组 +system字段 → 合并成某种对话模板字符串。- 参数映射 :
max_tokens→max_tokens,temperature→temperature,top_p→top_p。- 输出转换 :模型生成的文本 → Anthropic 的
content块结构(type: "text"等)。但注意 :vLLM 对 Anthropic 的支持是实验性的,且主要为了兼容 Claude Code 等特定工具。大部分生产场景仍优先使用 OpenAI 兼容模式。
总结一张表
方面 OpenAI 兼容模式(默认) Anthropic 兼容模式(可选) 动机 复用整个 AI 工具生态 让 Claude Code 等工具能用本地模型 实现 成熟的完全实现 实验性,部分功能可能缺失 使用方式 客户端改 base_url即可设置特定环境变量,请求路径不同 内部转换 请求体 → 内部参数 → 推理 → 响应体 同样流程,但字段结构不同 核心思想 :vLLM 作为一个翻译层,把模型内部的输入输出格式"适配"成主流厂商的标准。这样模型可以千变万化,但对外永远说"OpenAI 语"或"Anthropic 语",让开发者获得最大的便利。
如果你希望手动测试请求转换,可以用
curl分别发 OpenAI 格式和 Anthropic 格式的请求到 vLLM 服务,观察返回的 JSON 结构差异。这也是理解格式适配最直接的方法。
⚠️ 常见问题与解决思路
在启动或使用服务时,可能会遇到一些常见问题,可以参考下面的解决方案进行排查:
模型路径错误 :
ValueError或FileNotFoundError。
- 原因 :
./models/google/gemma-4-E4B-it/路径不存在或缺少关键配置文件(如config.json)。- 解决 :使用
ls ./models/google/gemma-4-E4B-it/确认路径完整且文件齐全。API 模型名称不匹配 :客户端调用时返回
404 Not Found。
- 原因 :客户端代码中
model字段的值与启动时的--served-model-name不一致。- 解决 :修改客户端
model字段,确保与--served-model-name完全相同。显存不足 (OOM) :
CUDA out of memory错误。
原因:GPU显存不够。
解决:
- 降低
--gpu-memory-utilization的值,例如设为0.7。- 启用
--enable-prefix-caching来节省部分显存。- 使用
--quantization参数加载量化模型。端口已被占用 :
OSError: [Errno 98] Address already in use。
- 原因 :
8000端口已被其他程序占用。- 解决 :通过
--port参数更换一个未使用的端口,如--port 8080。依赖库缺失 :
ModuleNotFoundError: No module named 'vllm'。
- 原因:未安装vLLM库。
- 解决 :执行
pip install vllm进行安装。
💡 针对你的 ROCm 环境的特别说明
鉴于你之前的命令行中使用了
vllm并涉及了rocm,这里补充几点特别提醒:
- 验证 GPU 可用性 :服务启动前务必先确认 ,可以在命令行执行
python -c "import torch; print(torch.cuda.is_available())",如果返回True说明 GPU 已被 PyTorch 正确识别。- ROCm 支持 :vLLM 官方支持 AMD GPU,要求 ROCm 版本在 6.3 及以上。若使用 Docker,AMD 官方提供了开箱即用的镜像(如
rocm/vllm:rocm7.13.0_gfx950-dcgpu_ubuntu24.04_py3.13_pytorch_2.10.0_vllm_0.19.1),这通常是最简单可靠的部署方式。- 安装特定版本 :确保 vLLM 是通过正确的 ROCm 安装方式配置的,例如使用预构建的 wheel 文件
pip install vllm --index-url https://wheels.vllm.ai/rocm/。- 留意兼容性 :不同版本的 PyTorch、ROCm 和 vLLM 之间可能存在兼容性问题,如果遇到意外错误,可以调整包版本来解决。

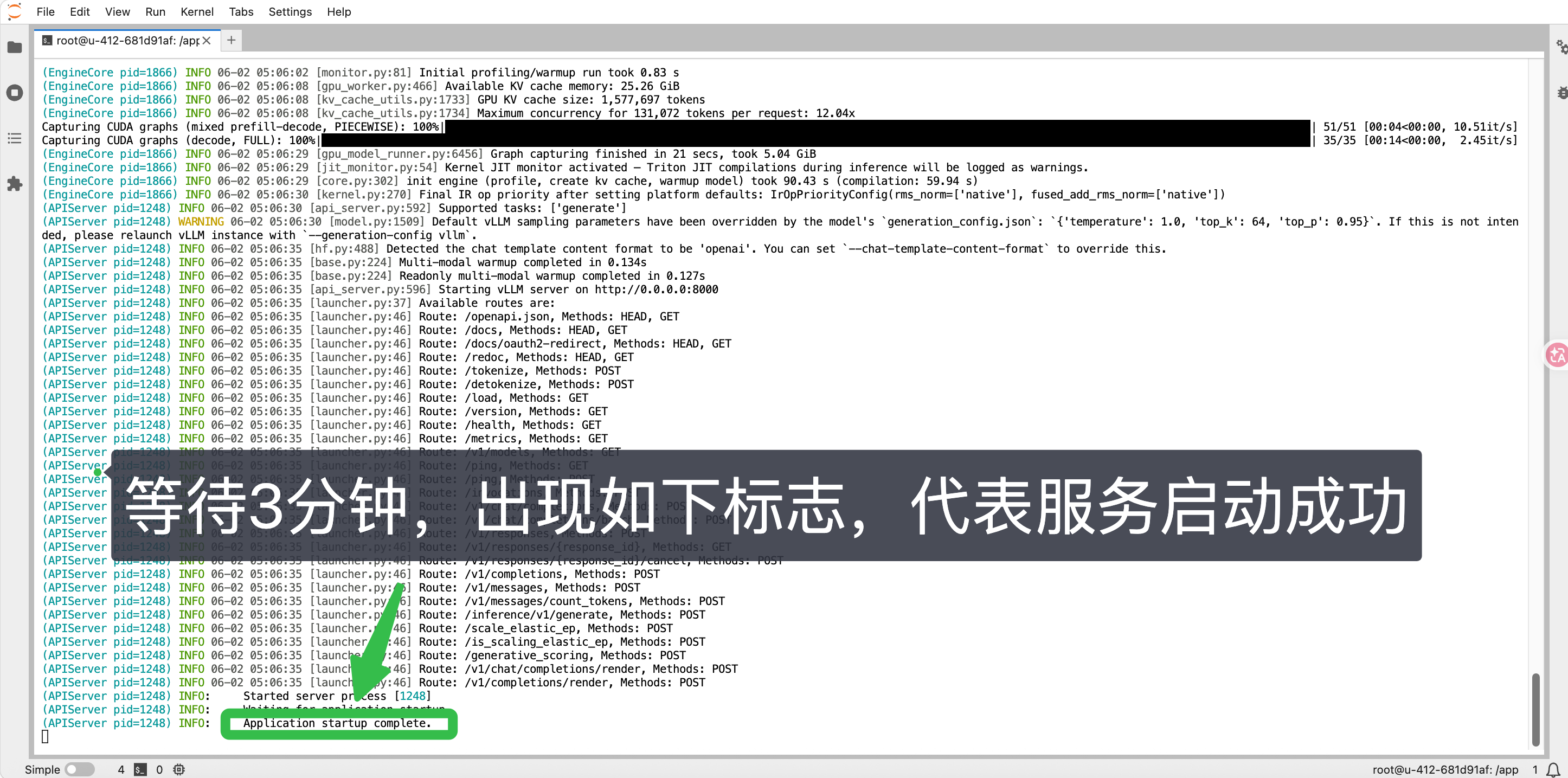
注意:运行这个命令后,这个终端窗口就会 被大模型服务"死死占满" 。请 保持运行,绝对不要关闭它 ,也不要按 Ctrl+C ,否则大模型服务就会立刻停止。
第四步:打开新终端进行对话测试
💡 为什么要打开一个"新终端"?
第一个终端正在跑模型服务,像后台厨师在做饭,被占住了不能再输命令。所以要再开一个新终端当"前台",专门用来给模型发命令、跟它对话。
当你启动服务(如vllm serve)后,它会一直"霸占"当前终端,直到你手动停止它。为什么会霸占终端?
- 绝大多数服务程序(包括 vLLM、Flask、FastAPI 等)在前台运行时会持续输出日志 (请求信息、错误、推理进度等),并且会阻塞命令行,让你无法输入新的命令。
- 如果你在当前终端按
Ctrl+C,服务就会被终止。所以为了既让服务保持运行,又能执行其他命令(比如发送测试请求),就需要另开一个终端。打开新终端的替代方案(不必须开新终端)
如果你不想开新终端,也可以用以下几种方式:
方法 命令示例 说明 后台运行 vllm serve ... &在命令末尾加 &,服务会在后台运行,但关闭终端时服务可能终止。脱离终端 nohup vllm serve ... > log.txt 2>&1 &nohup让服务忽略挂断信号,关闭终端后服务继续运行。终端复用器 tmux或screen创建一个独立会话,在会话里启动服务,然后切回主终端做其他事。这是最推荐的专业做法。 这个命令是在 Linux/Unix 系统 中将
vllm serve服务放到后台运行,并使其不受终端关闭影响的标准写法。下面逐部分拆解。
命令全貌
bashnohup vllm serve ... > log.txt 2>&1 &其中
...代表你原本的模型路径和参数(比如./models/google/gemma-4-E4B-it/ --served-model-name gemma)。
各部分作用
部分 含义 为什么需要 nohupNo Hang Up(不挂断)的缩写 使进程忽略 SIGHUP信号。当你关闭终端窗口或退出 SSH 会话时,系统会向该终端启动的所有子进程发送SIGHUP信号,默认行为是终止进程。nohup让进程继续运行。vllm serve ...你要运行的命令 启动 vLLM 推理服务器。 > log.txt标准输出重定向 将原本打印到屏幕的正常日志信息写入 log.txt文件。如果不重定向,后台进程的输出会无处可去(或被丢弃)。2>&1标准错误重定向到标准输出 2代表标准错误(stderr),1代表标准输出(stdout)。2>&1表示将错误信息也重定向到1的目标(即log.txt)。这样正常日志和错误日志都保存在同一个文件里,方便排查问题。&后台运行 将命令放到后台执行,立刻释放当前终端,让你可以继续输入其他命令。如果不加 &,终端仍会被vllm进程占用,直到你按Ctrl+C。
组合后的效果
- 即使你退出 SSH 会话或关闭终端窗口,
vllm serve依然在服务器后台运行。- 所有输出(包括错误)都被追加到
log.txt文件。- 你可以随时查看日志:
tail -f log.txt。- 需要停止服务时,先找到进程 ID:
ps aux | grep vllm,然后kill <PID>。
更进一步的写法(可选)
如果想将输出同时显示在屏幕并保存到文件 ,可以用
tee:
bashnohup vllm serve ... 2>&1 | tee log.txt &但简单场景下
> log.txt 2>&1 &已经足够。
常见疑问
1. 为什么
2>&1要写在> log.txt后面?
- 顺序很重要:
> log.txt先改变标准输出(1)的目标为文件;然后2>&1把标准错误(2)指向和标准输出(1)相同的位置(即log.txt)。- 如果写成
2>&1 > log.txt,则2>&1会把错误指向当前的标准输出(此时可能还是终端),然后标准输出才被重定向到文件,导致错误依然打印到终端。2.
nohup会默认生成nohup.out吗?
- 如果你没有手动重定向 (即直接写
nohup vllm serve ... &),nohup会自动将输出写入当前目录下的nohup.out。- 因为我们已经用
> log.txt 2>&1明确指定了重定向,所以不会产生nohup.out。3. 如何验证服务已经在后台运行?
bashps aux | grep vllm | grep -v grep或使用
jobs命令(如果还在同一个 shell 会话中)。
示例:完整命令
假设你原本的启动命令是:
bashvllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it想要后台持久化运行,并保存日志到
vllm.log:
bashnohup vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it > vllm.log 2>&1 &执行后终端会输出类似:
[1] 12345其中
12345是后台进程的 PID(进程号)。你可以记录它,以便日后停止服务。
停止后台服务的方法
bash# 方法1:通过 PID 杀进程 kill 12345 # 方法2:通过进程名杀(谨慎使用,避免误杀) pkill -f "vllm serve" # 方法3:先查 PID 再杀 ps aux | grep "vllm serve" | grep -v grep | awk '{print $2}' | xargs kill
总结
nohup:保活,不怕退出终端。> log.txt 2>&1:合并保存所有输出到文件。&:后台运行,释放终端。- 这是生产环境部署推理服务 的常用方式,配合
tail -f log.txt实时查看日志,非常实用。示例:使用
tmux(最优雅)
bashtmux new -s vllm # 创建名为 vllm 的会话 vllm serve ./models/... # 在会话中启动服务 # 按 Ctrl+B 然后按 D (脱离会话,服务继续运行) # 回到主终端,可以自由测试 tmux attach -t vllm # 需要查看日志时重新连接会话为什么教程通常让你"打开新终端"?
- 简单、零学习成本 :不用解释
&、nohup、tmux等概念,适合刚接触服务的用户。- 避免意外:后台运行时如果直接关闭终端窗口,服务可能被杀掉;开一个新终端则更直观。
- 日志清晰:每个终端窗口只干一件事,服务窗口专门看日志,测试窗口专门发请求,互不干扰。
总结:不是因为技术上必须开新终端,而是因为默认前台运行的方式最直观、最稳定,开新终端是最简单的"隔离日志+释放输入"的方法 。等你熟悉了,可以用
tmux或nohup来实现更专业的后台运行。
新建 一个 终端 , 在新终端里输入测试命令,发送消息给后台的 Gemma 4 模型,测试它的推理服务是否正常
【具体步骤】
-
打开新终端
-
复制命令, 在新终端中 粘贴命令运行
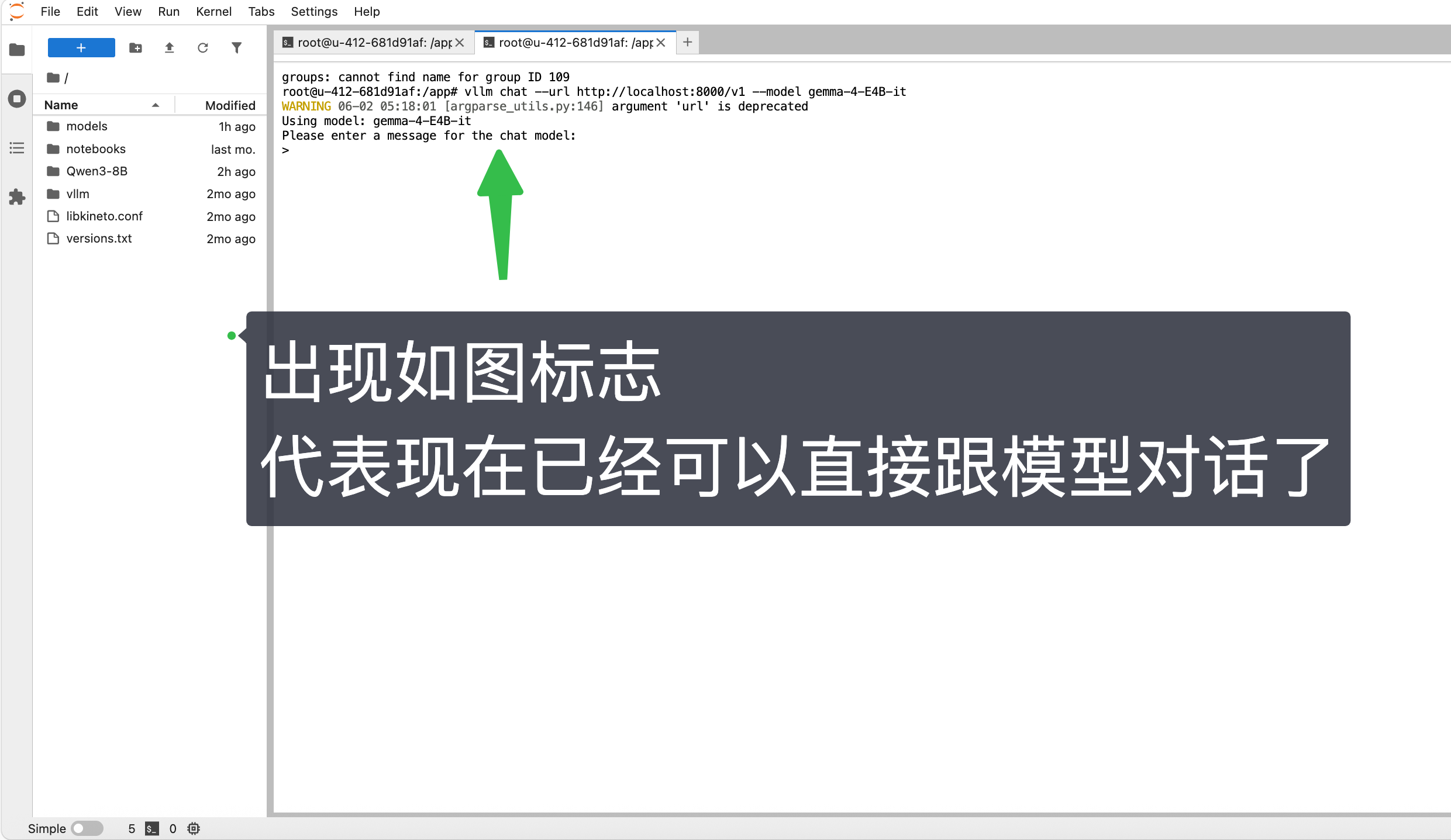
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it
执行的这条
vllm chat命令,是一个命令行聊天客户端 。它会连接到你已经启动的 vLLM 服务,实现直接在终端里进行对话。🧐 命令拆解
vllm chat:这是 vLLM 的聊天客户端子命令,执行后会打开一个交互式对话界面。--url http://localhost:8000/v1:指定 vLLM 服务的地址和版本路径,如果服务在其他地址需要相应修改。--model gemma-4-E4B-it:指定调用的模型名称 ,必须与你启动服务时用--served-model-name设置的名字完全一致。🚀 用法与操作
- 前提条件 :在另一个终端中已经使用
nohup或vllm serve命令成功启动了 vLLM 服务。- 执行命令 :在终端执行该命令后,会进入一个类似
User>>>的交互式提示符。- 开始对话:直接在提示符后输入你的问题,按回车键即可等待模型生成回复。
⚙️ 常用扩展参数
以下是
vllm chat中一些常用的扩展参数,可用于微调模型生成效果。你可以通过在命令后附加这些参数来调整模型的行为(例如,vllm chat ... --temperature 0.7 --max-tokens 512):
参数 作用 典型值 说明 --temperature控制生成文本的随机性或创造性 0 (确定) 到 2 (随机)之间 值越低,模型越保守,更适合事实性问答;值越高,输出越有创意。 --max-tokens限制模型单次回复的最大长度 取决于上下文长度,通常设为512-2048 用于控制模型的回复篇幅和生成时间。 --top-p核心采样,一个替代temperature的参数 通常设为0.8或0.9 模型只从累积概率达到 top_p的最小词汇集合中进行采样,有助于提高生成质量。--top-k限制模型在每一步生成时考虑的候选词数量 通常设为20-40 限制采样池的大小,避免模型考虑过于生僻的词汇,使输出更连贯。 总的来说,
vllm chat是一个很方便的测试工具。现在,你应该已经可以开始提问了,对话体验会和在 ChatGPT 等工具中很相似~
vllm chat命令里的--model参数,并不是用来在同一个服务上切换模型的。🤔 核心概念:vLLM 实例与模型是一对一的
一个 vLLM 服务实例在启动时,只会把一个模型常驻 在 GPU 显存里,在整个生命周期里都只服务这一个模型。vLLM 官方文档和社区讨论都确认了这一点,目前不支持在单一服务进程里定义和切换多个不同的模型。
🎯
--model参数的作用它是在命令行客户端里用来指定 你要和哪个后端模型对话。正因为模型和服务实例是绑定的,通常这个模型名就是你启动服务时设定的API模型别名 (
--served-model-name),这样名字更直观。归根结底,客户端的作用是告诉网关自己想去哪儿,而不是直接给服务端发号施令。🚀 实现多模型服务的推荐方案
vLLM 目前不支持原生的多模型服务 。虽然可以通过其他工具如 llmux(一个 vLLM 多路复用器)来动态加载和切换模型,但它的稳定性和复杂性还是需要额外留意的。标准的部署方案有以下几种:
方案 操作方式 适用场景 启动多个 vLLM 实例 为每个模型独立启动服务,并分配不同的端口号 简单直接,模型之间完全隔离,便于管理和调试。 使用前端代理 部署一个代理(如 Nginx),根据客户端请求中的 model字段自动路由到不同的后端 vLLM 服务对外暴露一个统一的 API 端点,实现对客户端友好的入口。
它触及了 vLLM 服务设计的一个关键点:
--url和--model分别解决了"去哪里找"和"找谁"两个不同的问题。
🔍 为什么有了 URL 还不够,还需要
--model?1. 协议规定:OpenAI API 要求请求体中必须包含
model字段vLLM 服务兼容 OpenAI API 规范。当你向
http://localhost:8000/v1/chat/completions发送 POST 请求时,请求的 JSON 正文里必须 有一个model字段,例如:
json{ "model": "gemma-4-E4B-it", "messages": [...] }这是 API 本身的设计,即使服务端只有一个模型,客户端也必须显式告知"我要用哪个模型"。
vllm chat --model的作用就是帮你自动在请求体里填上这个字段。2. 实际用途:虽然单实例只能服务一个模型,但
--model仍有价值
- 验证匹配 :vLLM 服务端会检查客户端传来的
model是否与自己加载的模型一致。如果不一致(比如你写--model wrong-name),服务端会返回错误(如404或400)。这相当于一个安全校验,防止客户端误连。- 兼容未来扩展 :虽然 vLLM 目前不支持一个实例加载多个模型,但官方路线图中讨论过将来可能支持。届时,
--model就会真正用于路由到正确的模型。- 日志与可观测性 :服务端可以根据请求中的
model字段统计不同模型的调用量、延迟等指标。即便现在只有一个模型,这也为后续监控打下了基础。3. 类比:快递地址和收件人
--url好比快递站的地址("上海市 xx 路 123 号")。--model好比你要寄给的那个收件人名字 ("张三")。
即便这个快递站只服务张三一个人,你仍然需要写明"张三",因为快递单格式要求必须有收件人,而且以后如果快递站开始服务李四,你需要用名字区分。
🤖 技术上的运作流程
当你执行:
bashvllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it实际发生的事情:
vllm chat读取--url,构建请求目标:POST http://localhost:8000/v1/chat/completions。读取
--model,将其填入请求体:
json{ "model": "gemma-4-E4B-it", "messages": [{"role": "user", "content": "你好"}], ... }发送请求到服务端。
服务端收到后,检查
model字段是否与自己加载的模型名称(--served-model-name)匹配。
- 匹配 → 执行推理。
- 不匹配 → 返回
404或400错误。因此,
--model不是多余的,它是 API 协议的强制要求,也是安全校验的一部分。即使服务端只有一个模型,也必须填写。
💡 什么时候
--model可以省略?
某些极其简化的命令行客户端(如
curl直接调用)可能会硬编码模型名称,但vllm chat选择让用户明确指定,避免歧义。如果你自己写代码调用 OpenAI SDK,同样需要显式传
model参数:
pythonopenai.ChatCompletion.create(model="gemma-4-E4B-it", messages=...)
✅ 总结
--url:告诉客户端去哪里发请求(网络地址)。--model:告诉服务端你想用哪个模型(API 请求体字段)。- 二者缺一不可 ,即使当前服务只有一个模型,API 协议和实现逻辑也要求客户端必须声明
model。所以,你观察到的"有了 URL 还不够"是正确的,因为这是分布式 API 设计的常见做法:地址定位 + 资源标识 = 完整请求 。
-
输入 文本进行测试 :复制如下命令,粘贴命令运行
你是谁,你能做什么
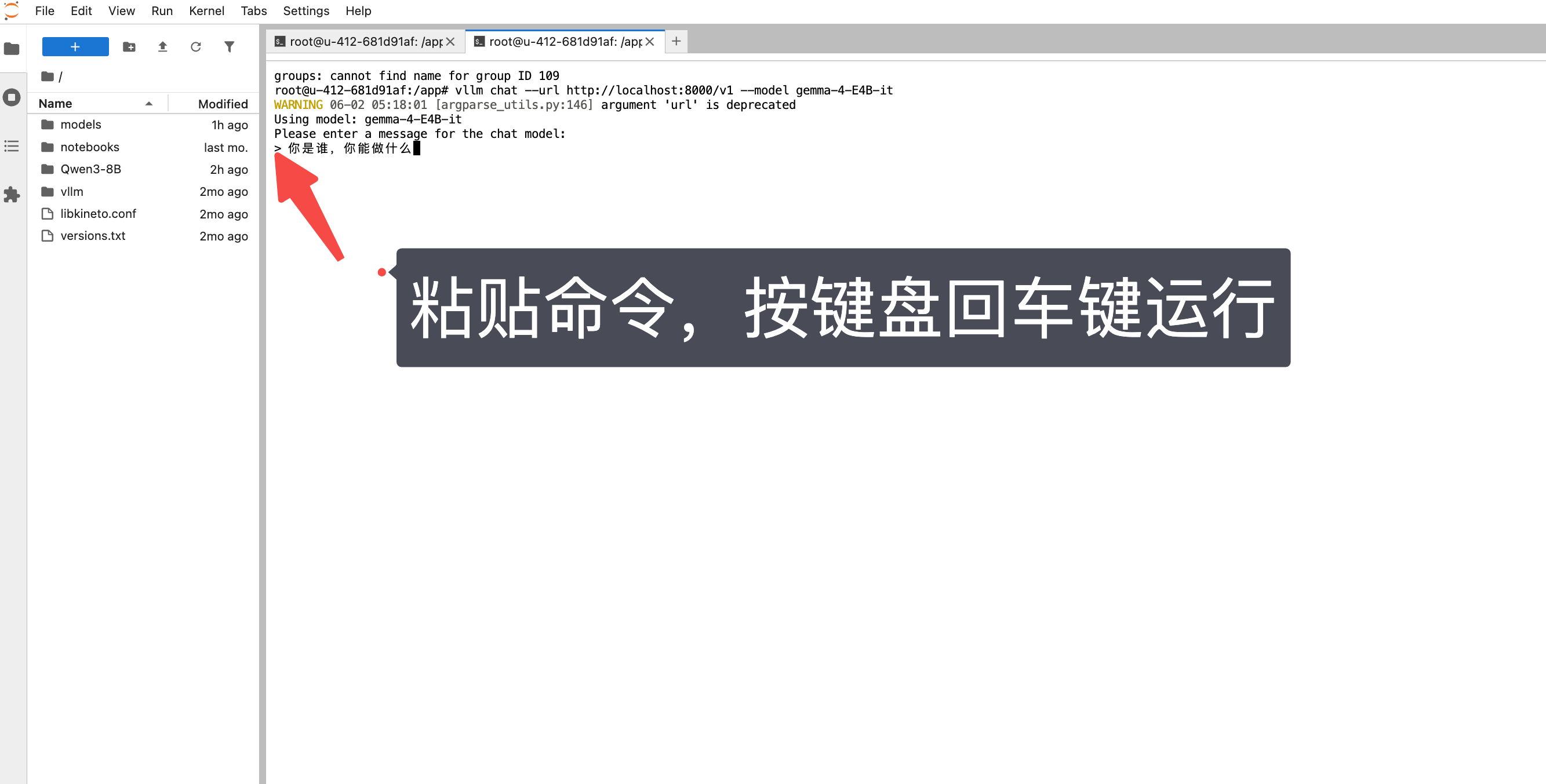
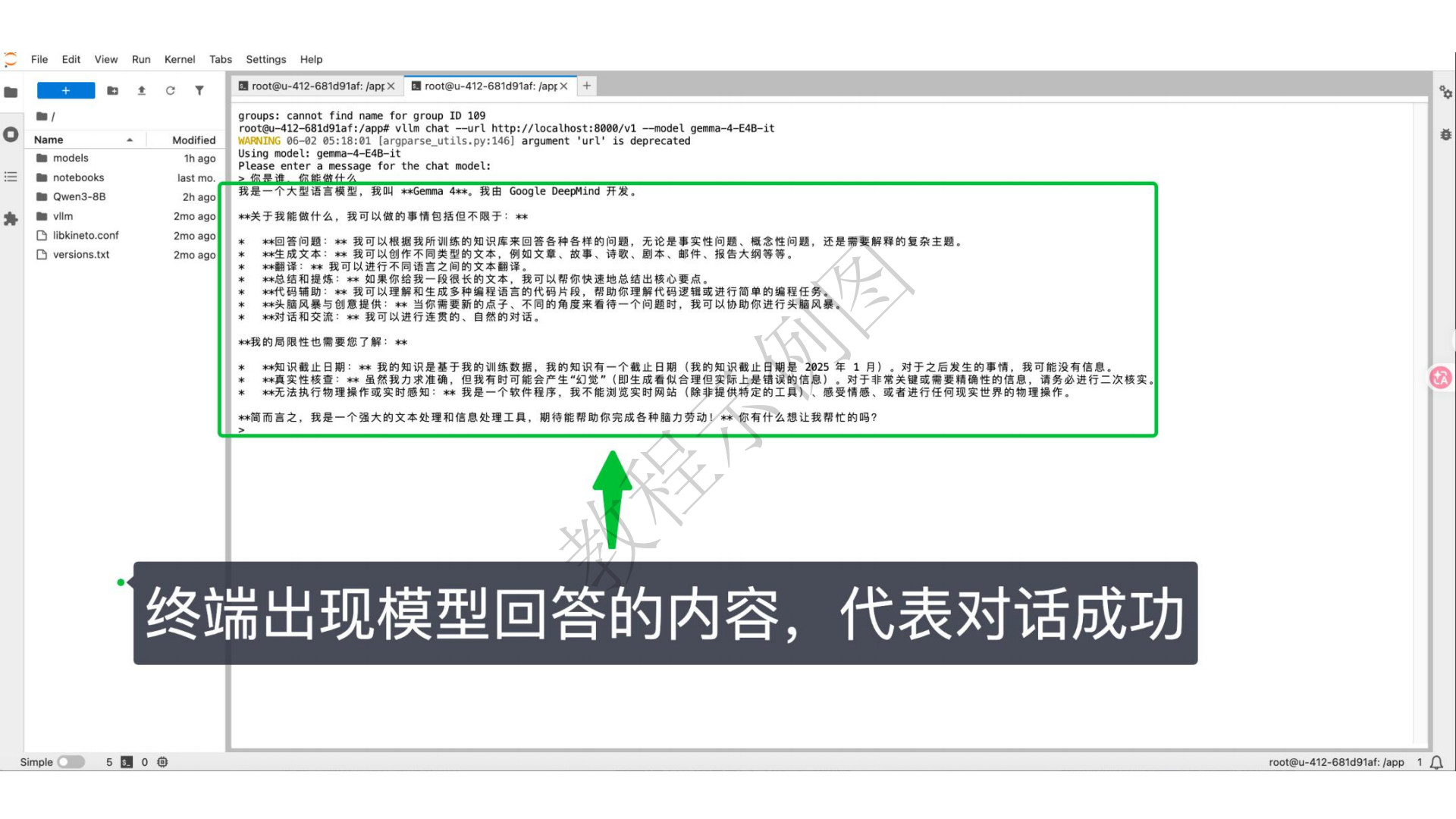
终端返回模型回答的内容,说明Gemma4已经在 AMD ROCm 云环境中正常运行!
- 关闭 vLLM 服务
因为我们后续还要对 Gemma4 模型进行微调,因此需关闭这个 vLLM 来为微调任务腾出计算资源
(1)新终端: ( Mac电脑: 按 Control+C ;Windows电脑: 按 Ctrl +C )退出聊天
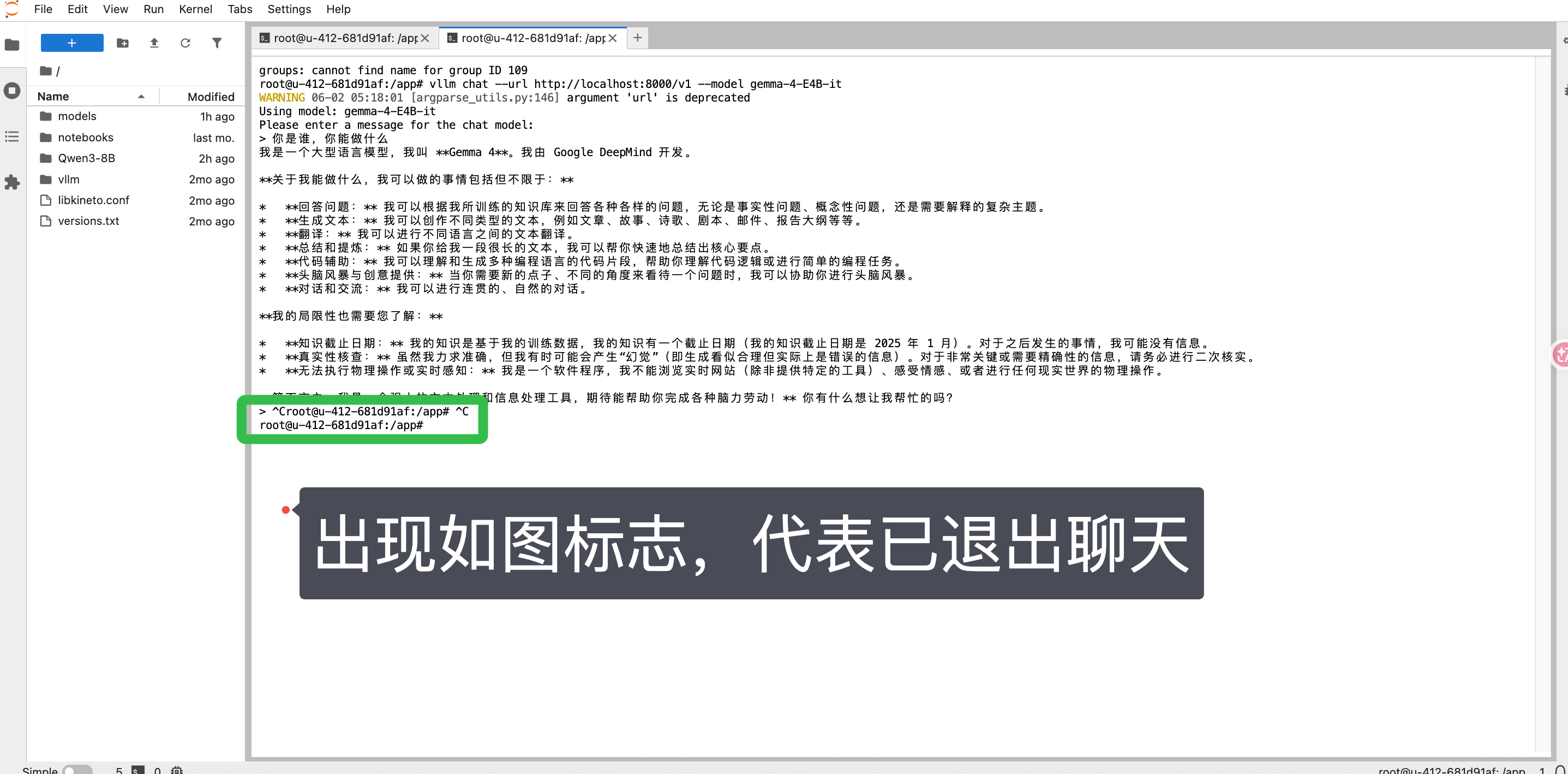
(2)上一个终端: 回到第一个终端( Mac电脑: 按 Control+C ;Windows电脑: 按 Ctrl +C ),结束 vLLM 服务
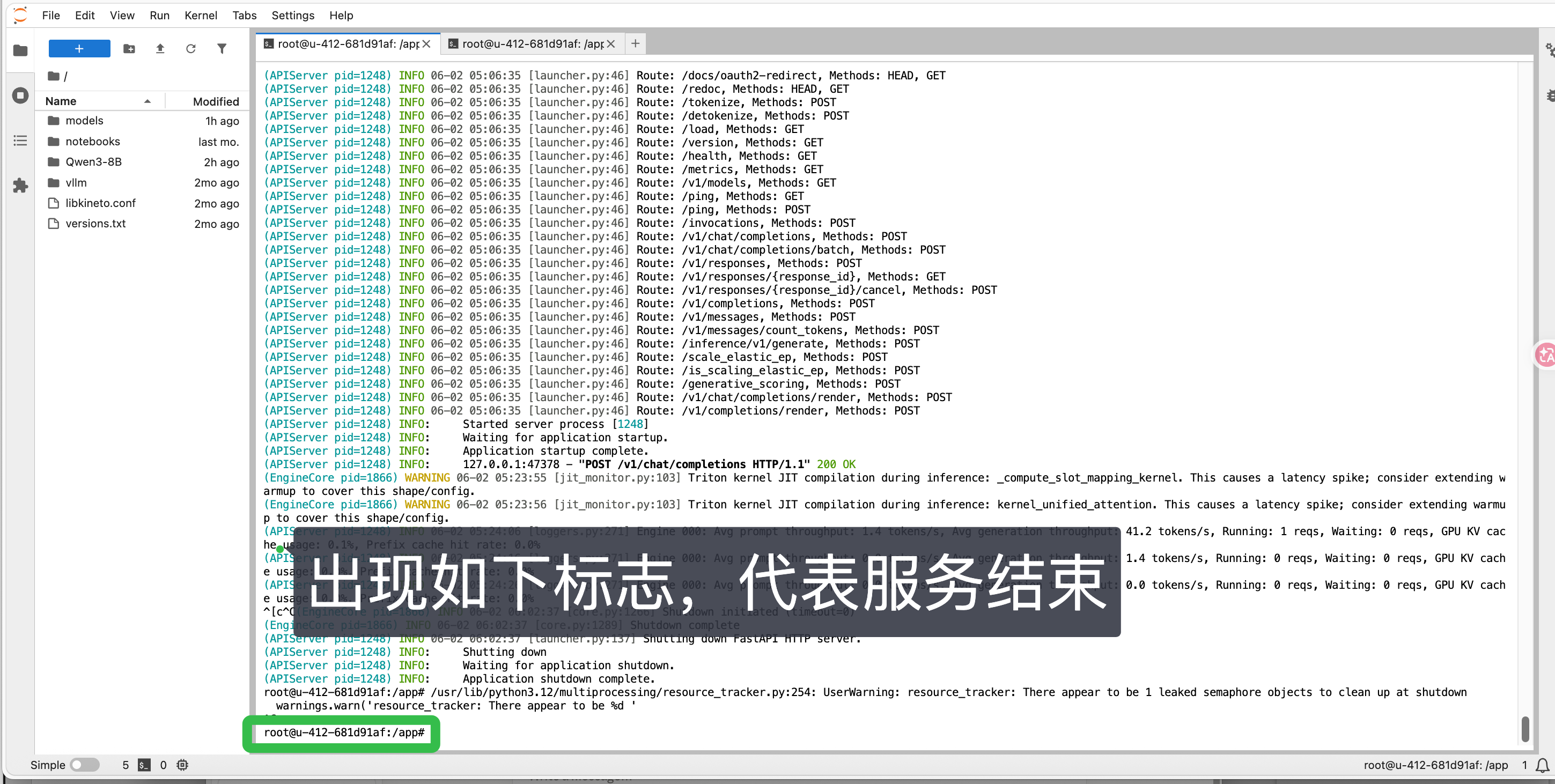
二、常见问题排查
1. vllm serve 启动很慢怎么办?
第一次启动需要加载模型和编译内核,等待几分钟是正常现象。只要日志还在输出,通常不需要中断。
2. 提示显存不足怎么办?
可以降低最大上下文长度后再启动:
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it --max-model-len 8192如果仍然显存不足,可以继续降低到 4096 。
3. modelscope download 命令找不到怎么办?
先确认 ModelScope 是否安装成功:
pip show modelscope如果没有安装成功,重新执行:
pip install -U modelscope也可以直接使用本文提供的 Python 下载命令。
4. 聊天命令连接失败怎么办?
先确认第一个终端中的 vLLM 服务仍在运行,并且已经出现 Application startup complete. 。如果服务没有启动完成,等待启动完成后再运行 vllm chat 。
【科普卡片】一文读懂大模型核心概念
1. 大模型是什么?
先说它和普通软件的区别,这是理解一切的起点。
普通软件,是程序员把规则一条一条写死的。比如一个计算器,程序员写明"看到加号就做加法",它才会做加法。程序员没想到的情况,它就不会处理。
大模型不一样:没有人给它写规则。它是从海量文字里,自己总结出语言规律的。
那它具体在做什么?它的核心工作其实只有一件事:
看着前面的文字,预测下一个词最可能是什么。
听起来太简单了,但请先记住这件事,因为它就是大模型的全部底层逻辑。展开来看,模型每生成一个词,内部都走了这么五步:
一个词一个词地往下接,接成句子、接成段落,就是我们看到的"会聊天、会写作"的样子。
为什么这样就显得聪明? 因为要把"下一个词"猜得准,模型在学习时必须暗暗掌握很多东西:语法、常识、事实、甚至简单的推理。举例:要正确续写"中国的首都是____",它就必须"知道"答案是北京。它不是被人手把手教的,而是在海量文字里反复见到这个搭配,自己总结出来的规律。
2. Gemma 4 是什么?
Gemma 4 是 Google(旗下 DeepMind 团队)在 2026 年推出的一个 开源大模型家族 。它和 Google 那款闭源、收费的 Gemini 3 用的是同一套底层技术,所以你可以把它看成 Gemini 3 的"开源师弟"------区别在于,Gemma 把模型权重公开放了出来,而且用的是商业友好的 Apache 2.0 许可 ,意味着 不光能免费下载,还能免费商用 。
"开源"这一点对本次教程特别关键 :任何人都能免费下载模型文件、装到自己环境里运行、甚至拿自己的数据去改造它 (也就是任务四要做的微调)。而闭源模型(比如 GPT、Gemini),你只能隔着网络调用,看不到也改不动里面的东西。顺带一提,Gemma 系列至今 已被下载超过 4 亿次、衍生出 10 万多个模型 , 是开源圈里用得最广的家族之一 。
Gemma 4 有好几种大小,从能塞进手机、树莓派的,到要用服务器才跑得动的都有,一共四款:E2B、E4B、26B 和 31B。本次教程用的是其中较小的 E4B :体积小到 单张显卡就能跑,又足够聪明,正好适合上手学习 。(型号里的"E"是"有效参数"的意思,E4B 大致是 40 亿参数这个量级。)
别看个头小,Gemma 4 这一代主打的就是" 单位参数下的高智能 "------按 Google 官方说法,它家最大的 31B 模型在权威的开放模型排行榜上能排进全球前三,甚至打赢比它大 20 倍的对手。能力上,它会做多步推理、能写代码、能看图、能听音频、一次能读进很长的内容,还支持 140 多种语言。
本次教程为什么选它? 开源 (能下能改、还能免费商用)、 够小 (单卡跑得动)、 够强 。
更多信息详见谷歌官方对Gemma 4 的介绍: https://mp.weixin.qq.com/s/9ocQ4g2v8zmKuIMcle3sDA
3. 顺便搞懂几个高频词!
这几个词在任务三里会反复出现,搞懂了,后面就不犯迷糊。
1️⃣ 参数 / 权重 / "多少 B"
- 参数(Parameter) :模型内部的数字,就像模型的大脑神经元的"记忆"。每个参数都是一个固定的数,模型就是靠这些数进行运算,算出答案。
- 权重(Weight) :参数的另一种叫法,完全等价。
- "多少 B" :B = 10 亿。模型名字里的 4B、15B,就是模型里参数的数量。例如,4B 模型有 40 亿个参数。
- 模型文件 :你下载的
model.safetensors文件里存的就是这些参数。文件大(比如 15G)是正常的,因为存储结构和精度决定了文件大小。
💡一句话理解: 参数 = 模型的"本体",模型会不会聊天、聪不聪明,全在这堆数字里。
2️⃣ 推理(Inference)与部署(Deploy)
推理 :用训练好的模型做实际工作(跟模型对话、生成内容)。
部署 :把模型放到服务器上,让别人可以访问、请求模型生成结果。
关系 :
训练 = 教模型 推理 = 用模型干活部署 = 把模型放到服务器上,别人也能用
3️⃣ 魔搭 ModelScope
一个国内的开源模型社区,相当于"国内的模型下载站"。 用它可以下载模型,速度快、稳定,不容易卡。任务三第二步,你就是用它把 Gemma 4 下载下来的。因为它的服务器在国内,下载又快又稳、不容易卡------这也是教程让你先把下载源切到国内镜像的原因。
4️⃣ vLLM
刚下载的模型文件,只是一堆"静止"的参数,没法直接聊天 。vLLM 就是负责把模型"装载起来、发动跑起来"的推理框架 ,而且它优化过运算流程, 同一个模型用它跑会更快 。
📌总结一句话:
模型 = 一堆参数(权重)
推理 = 模型开始用参数算东西
部署 = 模型可以被别人访问
ModelScope = 国内模型下载渠道
vLLM = 推理框架,让模型跑得快
4. 读懂这一连串操作到底在干嘛
这一节的命令看着多,其实是一条很清晰的链路。一句话概括目标: 把一个"挂在网上的模型文件",变成"一个能跟你对话的服务" 。理解了这条链路,你敲命令时就不是在盲抄,而是知道每一步在干嘛。
- 第一步,先检查显卡能不能用。 为什么放最前面?因为后面下载、运行、对话全靠显卡。先花几秒确认地基没问题,免得忙活半天才发现显卡用不了------相当于开工前先看看工具齐不齐。
- 第二步,把模型下载到本地。 模型得先待在你这台服务器上,才能被运行。先切换国内镜像、用魔搭来下载,都是为了又快又稳;下完确认那个 15G 的权重文件在,"原料"就到位了。
- 第三步,用 vLLM 把模型启动成一个服务。 有了模型文件(原料),还需要一个引擎(vLLM)把它点着:它会把模型加载进显存,然后开一个"窗口"停在那儿等人提问。注意启动后这个终端会被一直占住------因为服务得持续运行,不能关。
- 第四步,另开一个终端连上去对话。 这里藏着一个很真实的概念:大模型实际运行时,往往是" 服务端 + 客户端 "的模式。第三步启动的是服务端(像后厨,一直运转);你要跟它说话,得另开一个终端当客户端(像前台,负责传话)。所以让你"开新终端"不是麻烦,这套结构本来就这么设计的------你以后调用大模型 API,本质也是这个样子。