想象这样一个场景:你是一位新来的快递分拣员(AI编程助手),被派到一个巨大的物流仓库(你的代码仓库)工作。主管让你找出"用户登录功能"这个包裹在哪里。在没有仓库地图的情况下,你只能一个货架一个货架地翻找,每打开一个抽屉都要向主管汇报一次:"第一个抽屉没有"、"第二个抽屉也没有"......直到第50个抽屉才找到。每次汇报都会消耗主管的耐心和精力------这就像AI编程助手在大型代码库中反复执行文件读取和搜索,每次操作都在消耗宝贵的Token。
CodeGraph 的出现,解决了这个"盲目翻箱倒柜"的问题。它提前为整个仓库绘制了一张精确的货架地图,把每个函数、类、方法、调用关系都标注清楚。AI 第一次进入仓库时,只需要看一眼地图就能直接走到正确的位置------搜索效率从50步缩到了1步。
那 CodeGraph 是怎么做到的呢?答案藏在它的技术逻辑里。
核心原理:三步走,让"暴力搜索"变成"精准定位"
第一步:建图------把代码库变成一张"城市地图"
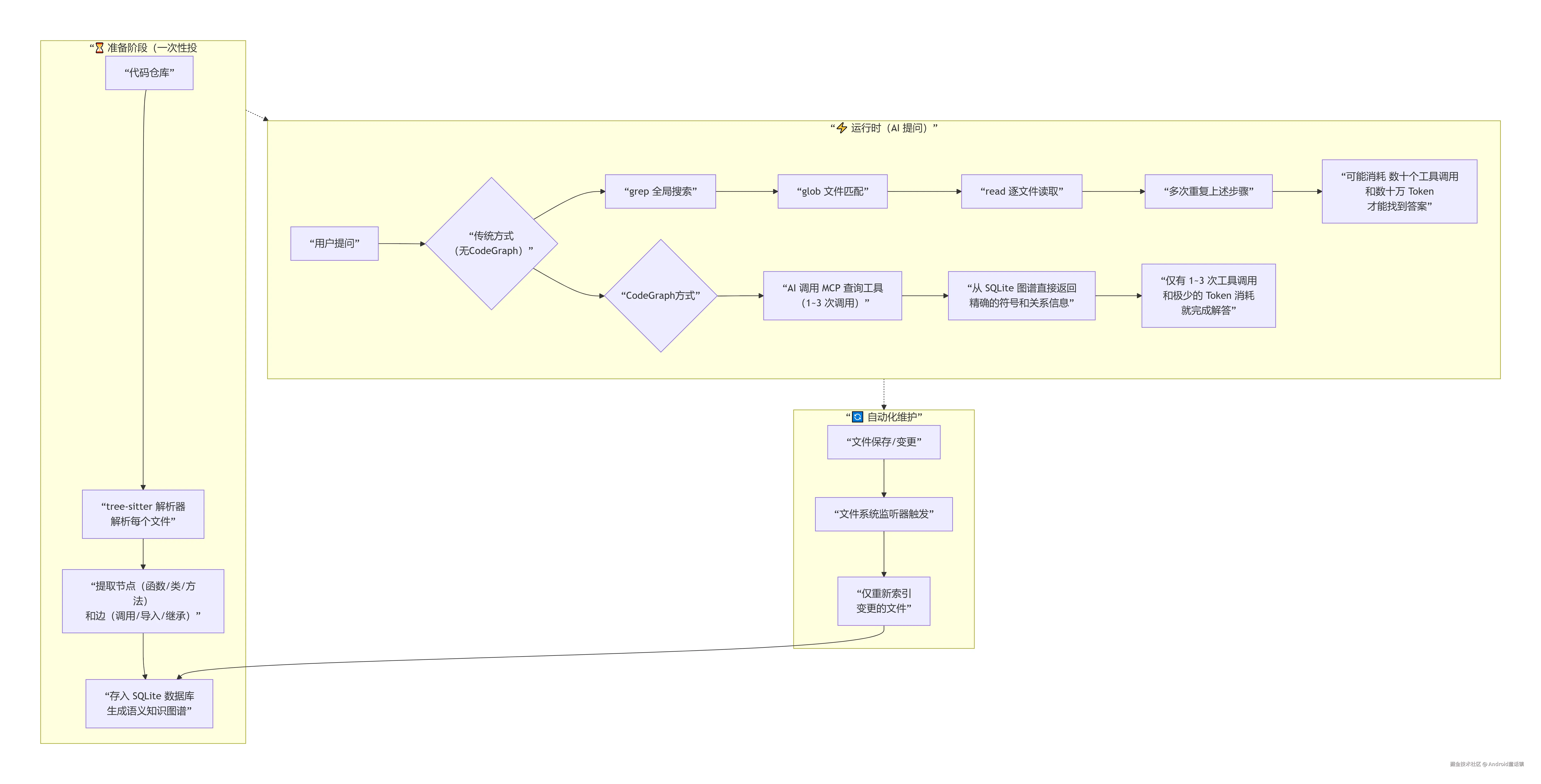
CodeGraph 在工作开始之前,会对整个代码库进行一次前置索引 (Pre-indexing),就像在修建一座城市之前先把道路、街区、地标都画到地图上。
具体来说,CodeGraph 使用了一个叫 tree-sitter 的解析器,把每个源代码文件拆解成一颗 AST(抽象语法树) ------你可以把它想象成代码的"家族树",清晰地标注出函数、类、方法、变量等所有元素的层级结构和关系。
遍历这颗 AST 之后,CodeGraph 提取出两类信息:
- 节点:每一个函数、类、方法、接口、路由等代码实体
- 边:节点之间的关系,如 CALLS(调用)、IMPORTS(导入)、INHERITS(继承)等
所有这些信息被存入一个本地 SQLite 数据库 中,形成了一个语义知识图谱 。参考实际开源数据,一个中型以上的代码库(如 10,000+ 个文件的 VS Code 仓库),其图谱文件大小也不到 200 MB------占用空间相当小,却能覆盖海量的代码关系。
第二步:提供查询工具------给AI一副"望远镜"
索引建立好之后,CodeGraph 通过 MCP(模型上下文协议) 向AI编程工具(如 Claude Code、Cursor、Codex CLI 等)暴露出一系列查询工具 ,就像给AI配了一副能看到所有代码结构关系的"望远镜"。AI 可以随时调用这些工具来查询图谱,而不是自己去翻文件。
第三步:精准响应------答案直达,浪费为零
当 AI 接到用户的提问(比如"用户认证模块在整个项目中被哪些地方调用了?")时,它不再发起 grep、read、glob 等一系列探索操作,而是直接向 CodeGraph 发起一次结构化查询。CodeGraph 在数据库中找到答案后,只返回几个最核心的函数和它们的关系------AI 得到了它恰好需要的那一小部分信息,而不是一大堆无关代码。
源码实战:扒开CodeGraph的"内脏"看看
下面我们从 GitHub 项目 colbymchenry/codegraph 的核心源码出发,看看上述机制在代码层面是如何落地的。
1. 解析阶段:tree-sitter + AST 提取
CodeGraph 对不同编程语言使用对应的 tree-sitter 解析器。以下是核心解析逻辑的思路(简化代码):
typescript
// 核心解析逻辑示意
async function indexFile(filePath: string, languageParser: Parser) {
const sourceCode = await fs.readFile(filePath, 'utf-8');
const ast = languageParser.parse(sourceCode);
const extractor = new SymbolExtractor();
extractor.traverse(ast.rootNode);
const nodes = extractor.getNodes(); // 函数/类/方法节点
const edges = extractor.getEdges(); // 调用/继承关系边
await db.insertNodes(nodes);
await db.insertEdges(edges);
}每个文件解析后会生成若干个 节点 和 边 。实际运行中,索引整个项目只需要一次性投入,后续文件变更时,CodeGraph 会通过监听本地文件系统的变更事件(FSEvents on macOS、inotify on Linux),自动增量更新 有变化的文件------仅更改的那几个文件重新走一遍解析流程,而不是全量重建。这种增量机制意味着第一次建图后,日常开发几乎不需要再付出额外的时间成本。
2. 存储阶段:SQLite 结构化存储
所有提取出的节点和边被存储到项目根目录下的 .codegraph/codegraph.db 中。CodeGraph 使用 SQLite 的 FTS5(全文搜索)扩展 ,让查询可以在几毫秒内完成,无需遍历文件系统。
数据库设计非常精妙:一个 nodes 表记录每个符号的名称、类型(function/class/method)、所在文件位置、起止行号等元信息;一个 edges 表记录每两个符号之间的关系类型(CALLS、IMPORTS、INHERITS 等)。通过这两个表格,整个代码库的结构化关系被完整地"拍照保存"。
3. 查询阶段:MCP Server 提供8个工具
通过 MCP 协议,CodeGraph 向 AI 工具暴露一系列查询接口。其中最主要的包括:
| 工具 | 用途 |
|---|---|
codegraph_context |
获取某段代码的上下文信息 |
codegraph_search_symbol |
查找某个符号的定义 |
codegraph_find_references |
查找某个符号被引用的所有位置 |
codegraph_call_hierarchy |
展开某个函数的调用链 |
当 AI 需要代码信息时,只需要调用一次 codegraph_context,就能直接拿到相关符号及其关系。相比传统方式(AI可能触发 1530 次甚至更多的 3 次** MCP 调用。每少一次工具调用,就意味着少消耗大量 Token。grep、read、glob 调用才能完成任务),CodeGraph 把这个过程压缩到了 **1
4. 更新阶段:实时增量同步
CodeGraph 通过监听本地文件系统事件来保持图谱的实时性:
typescript
// 增量同步核心示意
const watcher = chokidar.watch(projectRoot, {ignored: /node_modules|.git/});
watcher.on('change', debounce(async (filePath) => {
await indexFile(filePath); // 仅重新索引变更的文件
console.log(`Updated: ${filePath}`);
}, 2000));当开发者保存一个文件后,CodeGraph 仅对该文件重新解析并更新图谱,整个过程通常只需 几十毫秒 。这种毫秒级的更新速度,使得 CodeGraph 几乎对日常开发零干扰,用户完全感知不到"维护"的过程。
Mermaid 流程图:从暴力搜索到精准定位
下面这张流程图完整呈现了 CodeGraph 的工作原理,以及它是如何从源头节省 Token 的:
关键指标对比
根据官方在 7 个真实开源代码库上进行的基准测试,接入 CodeGraph 后效果显著:
| 指标 | 传统方式 | CodeGraph 方式 | 优化幅度 |
|---|---|---|---|
| 工具调用次数 | 基准 | 减少 | ~71% |
| Token 消耗 | 基准 | 减少 | ~57% |
| 任务执行速度 | 基准 | 提升 | ~46% |
注意,不同场景下的实际节省效果可能有所不同:
- 成本节省(平均 35%) 小于 Token 节省(平均 59%),是因为 CodeGraph 的 instructions 本身会常驻 context、Claude 的 prompt caching 有一定折扣。
- 在大型仓库 + 架构级问题上(如 VS Code 场景),Token 节省可以高达 70% 。
这些实测数据说明,项目规模越大、代码关系越复杂,CodeGraph 的"地图效应"就越明显------AI 不需要大海捞针,只需要看地图就知道针在哪里。
用故事串起来,彻底理解 Token 为什么节省
我们来回顾一下整个流程,把一个"AI 查代码"的过程用两个故事版本对比一下:
没有 CodeGraph 的时候(旧路) :
小明(AI 代理)要在一个 1,000 多个文件的仓库里找"订单支付逻辑"。他挨个打开文件夹(ls),在文件里搜索关键词(grep),每找到一个可能的文件就完整读一遍(read)。读完了发现不是,继续找下一个。整个过程中的每一步------搜索、列表、读取------都会占用 Token,并且每次交互都产生网络往返的延迟。最终花了 15 次工具调用、吃掉了 5 万个 Token,才找到真正需要的那 3 个函数。90% 的成本都花在了"找"的过程上,真正"改代码"只用了最后几步。
有了 CodeGraph 之后(新路) :
小明的"主管"在一天开始前已经用 CodeGraph 把整个代码库的"城市地图"准备好了,存入本地 SQLite。小明接到任务后,直接调用 codegraph_find_references 工具,一次查询后地图立刻告诉他"支付逻辑在第 5 层第 3 排第 2 个包裹里"。然后只把那 3 个核心函数拿出来交给小明。全程只花费 1~3 次工具调用,极少 Token 消耗。同样的问题,之前的 1.4M Token 下降到了 393k,成本从 0.64降到0.64降到0.42。
节省的本质 :CodeGraph 省的不是"模型推理"的 Token,而是"寻找相关代码 "而浪费的 Token。当 AI 不再盲目翻箱倒柜,只做精确的按图索骥,每一分 Token 都用在最核心的思考和生成环节上。
一句话总结
CodeGraph 通过"前置索引 (建图)+ 结构化存储 (SQLite)+ MCP 精准查询 (而不是暴力搜索)"的三步架构,把 AI 在代码库中的探索成本从指数级降到常数级。它让 AI 从一个"在黑暗中不断打开抽屉的快递员",变成了一张"地图在手、一步到位的高级调度员"。
有了 CodeGraph,Token 不再浪费在机械的"翻抽屉"上,而是用在真正有价值的地方------理解你的需求、写出高质量的代码。