你不做算法研究,但你写 Agent。理解 LLM 怎么工作,能帮你写出更好的 @Tool 描述、更准的 SystemMessage、更省的 Prompt。
为什么工程师也要懂 LLM 原理?
Agent 开发者的日常不是训练模型,而是调模型------写 Prompt、设计 Tool、控制输出。这些操作的质量,直接取决于你对 LLM 内部机制的理解程度。
几个例子:
- 为什么 Temperature=0.3 时 Agent 更「听话」?------你需要知道 LLM 输出的是概率分布,不是「确定的文本」
- 为什么 Token 计费方式会导致同样的 Prompt 有时便宜有时贵?------你需要知道 Tokenization 和 Context Window 的关系
- 为什么 LLM 能理解「查询 CNC-001 的告警」和「CNC-001 有什么问题」是同一件事?------你需要知道 Attention 在做什么
这篇的目标:给你一个工程师级别的理解框架。不推公式,用类比讲原理。
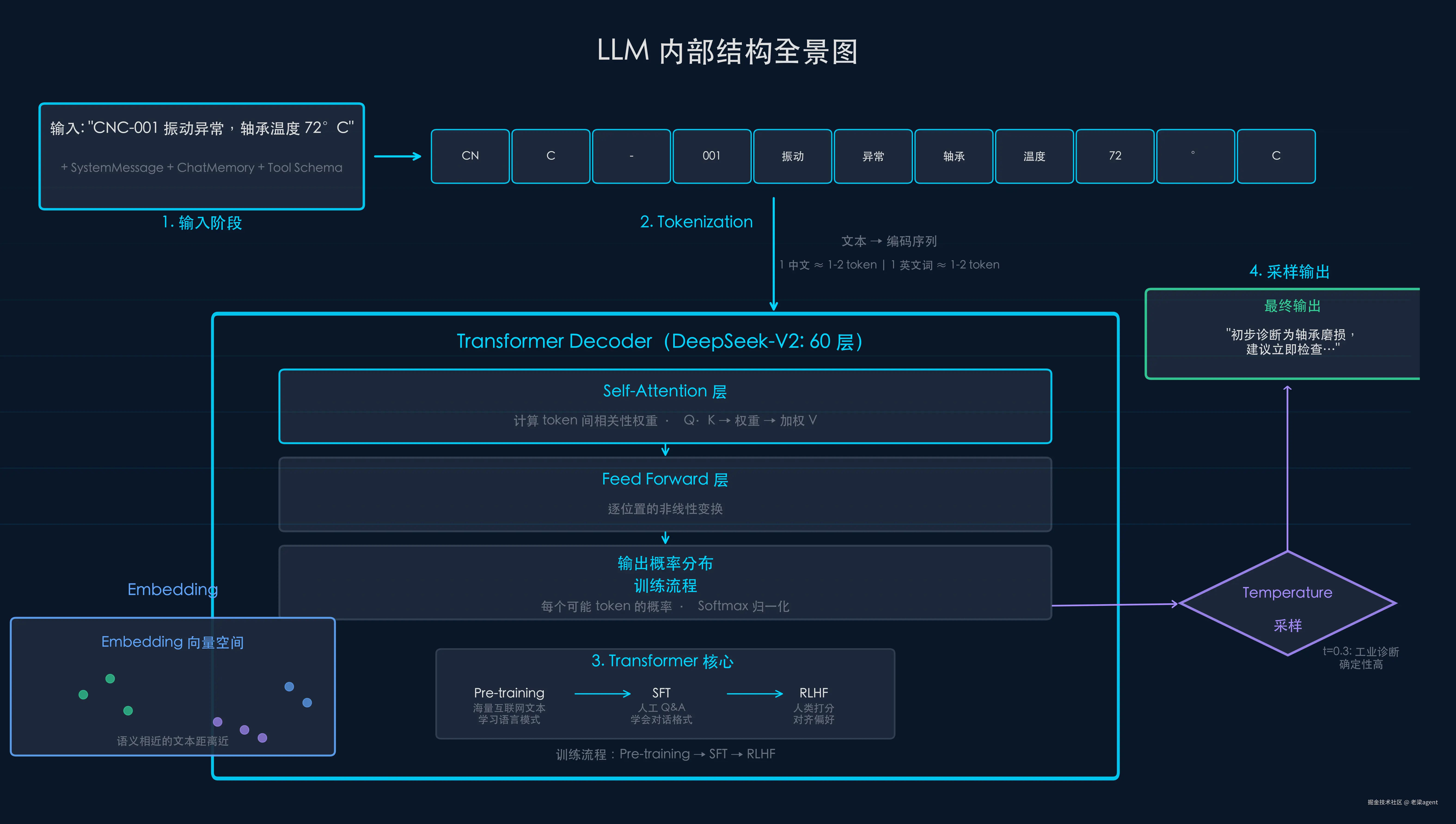
1. Transformer:LLM 的骨架
Transformer 是 2017 年 Google 提出的神经网络架构。所有现代 LLM(GPT-4、DeepSeek、Claude、Gemini)都基于它。
1.1 从外面看:黑盒视角
如果只记住一件事,记住这个:
css
输入文本 → [LLM 黑盒] → 输出概率分布 → 采样 → 输出文本你给 LLM 一段文字,它返回的不是「答案」,而是**「下一个 token 应该是什么」的概率分布**。然后从这个分布中采样,得到实际输出的 token。重复这个过程,直到输出结束------这就是「自回归生成」。
1.2 从里面看:Encoder + Decoder
Transformer 内部有两个主要组件(简化版):
csharp
输入:"CNC-001 振动异常"
↓
[Encoder:理解输入]
- 把每个 token 转成向量
- 计算 token 之间的关联(Attention)
- 输出:一组「理解后」的表示
↓
[Decoder:生成输出]
- 基于 Encoder 的理解 + 已生成的内容
- 逐 token 预测下一个 token
- 输出:"可能是轴承磨损,建议..."现代 LLM 大多只用 Decoder(GPT-4、DeepSeek 都是 Decoder-Only)。Encoder 的「理解」能力和 Decoder 的「生成」能力被合并到一个模型中。
1.3 关键概念:上下文窗口
Transformer 的核心限制是上下文窗口------模型一次能「看到」的 token 数量上限。
- DeepSeek-V2:128K tokens
- GPT-4 Turbo:128K tokens
- Claude 4:200K tokens
这对 Agent 意味着什么?
你的 SystemMessage + 对话历史 + Tool 定义 + Tool 返回结果,全部都在这个窗口里。超出窗口的,模型「看不见」。这就是 ChatMemory 必须存在的根本原因------用淘汰策略把对话控制在窗口内。
2. Attention:LLM 怎么理解上下文
2.1 用 IoT 类比理解
作为 IoT 工程师,这个类比应该很亲切:
传感器相关性矩阵
假设工厂有 100 个传感器(温度、振动、压力、电流......)。你想判断「CNC-001 是否可能故障」,不需要看全部 100 个------你会给最相关的传感器加权重:
- CNC-001 的振动传感器:权重 0.6(最相关)
- CNC-001 的温度传感器:权重 0.3
- 隔壁 CNC-002 的振动传感器:权重 0.1(可能相关)
- 三楼空调温度传感器:权重 0(不相关)
Attention 做的就是这件事------对于输入中的每个 token(词),计算它和所有其他 token 的「相关性权重」,然后按权重聚合信息。
2.2 Q/K/V:三个矩阵
Attention 的具体实现靠三个矩阵:Q(Query)、K(Key)、V(Value)。
用检索系统类比:
| 概念 | 类比 | 作用 |
|---|---|---|
| Q(Query) | 你的搜索词 | 「我正在处理这个 token,什么信息对我有用?」 |
| K(Key) | 每条记录的索引 | 「我是另一个 token,我包含这类信息」 |
| V(Value) | 每条记录的内容 | 「这是我的实际含义」 |
计算过程:Q 和 K 做点积 → 得到相关性分数 → 用 Softmax 归一化为权重 → 对 V 加权求和 → 输出。
python
# 伪代码(不是真正的实现,但原理如此)
def attention(query_token, all_tokens):
scores = []
for token in all_tokens:
score = dot_product(query_token.Q, token.K) # 相关性
scores.append(score)
weights = softmax(scores) # 归一化为 0-1 权重
output = sum(w * token.V for w, token in zip(weights, all_tokens))
return output2.3 Self-Attention:每个词看所有词
「The crane lifted the load because it was strong.」
「it」指什么?Self-Attention 让每个 token 都能「看到」句子中的所有其他 token,并计算出**「it」对「crane」的注意力权重最高**,从而正确理解句意。
这对 Agent 开发者的意义:LLM 天然擅长理解上下文关联。你的 @Tool 描述里的关键词,会通过 Attention 和用户消息中的意图建立关联------这就是为什么「查询告警」比「获取数据」更容易被 LLM 正确调用。描述越具体,Attention 越容易建立正确的关联。
3. Tokenization:LLM 不识字
LLM 处理的不是「文字」,而是 token------文本被切分的编码单元。
3.1 Token 不是字
arduino
"CNC-001 振动异常" → tokenize → ["CN", "C", "-", "001", "振动", "异常"]中文一个字通常是一个 token,但英文单词可能被拆成多个:
arduino
"industrial agent" → ["indust", "rial", "agent"]3.2 Token 就是钱
LLM API 按 token 计费。DeepSeek 的定价(2026-5月打折):
- 输入(Prompt):$0.14 / 1M tokens
- 输出(Completion):$0.28 / 1M tokens
你的 Prompt 长度 × 调用次数 = 你的账单。Agent 的一次对话可能产生 5-10 次 API 调用(用户消息 → LLM → Tool Call → LLM → 回复),每次都消耗 token。
3.3 Token 数计算方法
java
// 我用 OpenAiTokenizer 估算 token 数
OpenAiTokenizer tokenizer = new OpenAiTokenizer();
int tokens = tokenizer.estimateTokenCountInText("CNC-001 振动异常");
// → 大约 6-8 个 token经验值:
- 1 个中文字符 ≈ 1-2 个 token
- 1 个英文单词 ≈ 1-2 个 token
- 1 个 JSON 对象的 token 数大约是字符数的 30-50%
4. Temperature:控制随机性
LLM 输出的是概率分布,不是确定的答案。
arduino
LLM 输出(简化):
"轴承磨损" → 概率 0.85
"转子不平衡" → 概率 0.10
"润滑不足" → 概率 0.03
"电源问题" → 概率 0.02Temperature 控制这个分布的「陡峭程度」:
| Temperature | 效果 | 适用场景 |
|---|---|---|
| 0.0 | 总是选最高概率的 token | 结构化数据提取、代码生成 |
| 0.3 | 略有波动,仍然稳定 | 工业诊断、事实性问答 |
| 0.7 | 多样化输出 | 创意写作、头脑风暴 |
| 1.0+ | 可能「跑偏」 | 不建议用于生产 |
我在 TemperatureExperiment 中做了测试:同一个诊断 Prompt,t=0.0 时 10 次输出几乎一致,t=0.7 时偶尔会出现不同诊断结论,t=1.0 时产生了明显不合理的建议。
经验规则:工业 Agent 用 0.1-0.3,对话聊天用 0.5-0.7。
5. Embedding:把文字变成数字
Embedding 是把文本转成固定长度的浮点数向量的技术。
scss
"CNC-001 轴承磨损" → embedding → [0.23, -0.45, 0.78, ..., 0.12] (1536 维)向量的几何意义:语义相近的文本,向量距离近。这是 RAG(检索增强生成)的基础------用户问题向量化 → 在向量数据库中找到最近的文档片段 → 作为上下文发给 LLM。
6. 训练流程:模型怎么来的
css
Pre-training(预训练)
海量互联网文本 → 学习语言模式和知识
↓
SFT(监督微调)
人工标注的高质量 Q&A → 学会「对话」格式
↓
RLHF(人类反馈强化学习)
人类对输出打分 → 对齐人类偏好工程师不需要做这些,但需要理解模型的能力边界来自哪个阶段:
- 通用知识(「轴承磨损的原因」)→ 来自 Pre-training
- 对话能力(「请帮我分析...」)→ 来自 SFT
- 拒绝胡说(「我不确定...」)→ 来自 RLHF
总结
| 概念 | 一句话 |
|---|---|
| Transformer | LLM 的骨架,Encoder「理解」+ Decoder「生成」 |
| Attention | 计算 token 之间的相关性,类似传感器加权 |
| Tokenization | 文本切分,token 就是钱 |
| Temperature | 控制输出的随机性,工业场景 0.1-0.3 |
| Embedding | 文字→向量,RAG 的基础 |
| 训练流程 | Pre-training → SFT → RLHF |
记住一句就够了:LLM 是概率机器,不是知识库。理解它的工作原理,你才能写出更好的 Prompt、更准的 Tool、更省的 Agent。
代码仓库:github.com/LaoLiang-ag...
本文由 LaoLiang 原创,首发于掘金/知乎/微信公众号。转载请联系作者。