流程挖掘(Process Mining)这件事,说白了就是从系统日志里"还原"真实发生的业务流程------不是你以为的流程,而是数据说话的流程。PM4Py 是目前最主流的 Python 流程挖掘开源库,由 RWTH Aachen 大学与 Fraunhofer FIT 研究所联合开发,下载量已突破百万次,覆盖流程发现、合规检查、性能分析等核心场景。这篇教程带你从零上手,配合完整代码和可视化案例,把核心概念讲清楚。
一、安装与环境准备
PM4Py 对环境要求不高,Python 3.8+ 均可运行。可视化功能依赖 Graphviz,需要额外安装。
bash
# 安装 PM4Py
pip install pm4py
# 安装可视化依赖(macOS)
brew install graphviz
# Ubuntu/Debian
sudo apt-get install graphviz
# Windows 用户请到 https://graphviz.org/download/ 下载安装包验证安装是否成功:
python
import pm4py
print(pm4py.__version__) # 应输出 2.7.x 或更高版本二、核心概念:流程挖掘的三大支柱
在动手写代码之前,有必要先把三个核心概念搞清楚,这是整个 PM4Py 的理论基础。
2.1 事件日志(Event Log)
事件日志是流程挖掘的原材料。每条记录至少包含三个字段:
| 字段 | 含义 | 示例 |
|---|---|---|
| Case ID | 一次流程实例的唯一标识 | order_001 |
| Activity | 该步骤执行的活动名称 | 审核订单 |
| Timestamp | 活动发生的时间 | 2024-01-15 09:30:00 |
2.2 流程发现(Process Discovery)
从事件日志中自动推断出流程模型,常用算法包括 Alpha Miner、Heuristics Miner、Inductive Miner 等。
2.3 合规检查(Conformance Checking)
将真实日志与理论模型对比,找出偏差------哪些案例走了"野路子",哪些步骤被跳过了。
三、数据加载:从 CSV 到事件日志
PM4Py 支持 XES(标准流程挖掘格式)和 CSV 两种主要输入格式。实际工作中 CSV 更常见。
3.1 使用内置示例数据集
PM4Py 自带了几个经典数据集,入门练手非常方便:
python
import pm4py
import urllib.request
import os
# 从 PM4Py GitHub 仓库下载示例文件
url = "https://raw.githubusercontent.com/pm4py/pm4py-core/release/tests/input_data/running-example.xes"
local_path = "running-example.xes"
if not os.path.exists(local_path):
print("正在下载示例文件...")
urllib.request.urlretrieve(url, local_path)
print("下载完成")
# 正常加载
log = pm4py.read_xes(local_path)
print(f"案例数量: {len(log)}")
print(f"事件总数: {sum(len(case) for case in log)}")3.2 从 CSV 文件加载
python
import pm4py
import pandas as pd
# 读取 CSV
df = pd.read_csv("process_log.csv")
# 转换为 PM4Py 事件日志格式
# 指定列名映射:case_id, activity, timestamp
log = pm4py.format_dataframe(
df,
case_id="case:concept:name",
activity_key="concept:name",
timestamp_key="time:timestamp"
)
# 转换为正式事件日志对象
event_log = pm4py.convert_to_event_log(log)
print(f"成功加载 {len(event_log)} 个案例")3.3 手动构造示例数据(教学用)
为了让后续案例可以直接运行,我们手动构造一个"贷款审批"流程的事件日志:
python
import pm4py
import pandas as pd
from datetime import datetime, timedelta
# 构造贷款审批流程的事件日志
data = {
"case:concept:name": [
"loan_001", "loan_001", "loan_001", "loan_001",
"loan_002", "loan_002", "loan_002",
"loan_003", "loan_003", "loan_003", "loan_003", "loan_003",
"loan_004", "loan_004", "loan_004",
],
"concept:name": [
"提交申请", "初步审核", "信用评估", "批准放款",
"提交申请", "初步审核", "拒绝申请",
"提交申请", "初步审核", "信用评估", "补充材料", "批准放款",
"提交申请", "信用评估", "批准放款", # loan_004 跳过了初步审核(偏差案例)
],
"time:timestamp": [
datetime(2024, 1, 1, 9, 0), datetime(2024, 1, 1, 10, 0),
datetime(2024, 1, 1, 14, 0), datetime(2024, 1, 2, 9, 0),
datetime(2024, 1, 3, 9, 0), datetime(2024, 1, 3, 10, 30),
datetime(2024, 1, 3, 15, 0),
datetime(2024, 1, 5, 8, 0), datetime(2024, 1, 5, 9, 0),
datetime(2024, 1, 5, 13, 0), datetime(2024, 1, 6, 10, 0),
datetime(2024, 1, 7, 9, 0),
datetime(2024, 1, 8, 9, 0), datetime(2024, 1, 8, 11, 0),
datetime(2024, 1, 9, 9, 0),
]
}
df = pd.DataFrame(data)
df = pm4py.format_dataframe(df,
case_id="case:concept:name",
activity_key="concept:name",
timestamp_key="time:timestamp"
)
log = pm4py.convert_to_event_log(df)
print(f"构造完成:{len(log)} 个贷款案例")四、核心案例一:直接跟随图(DFG)可视化
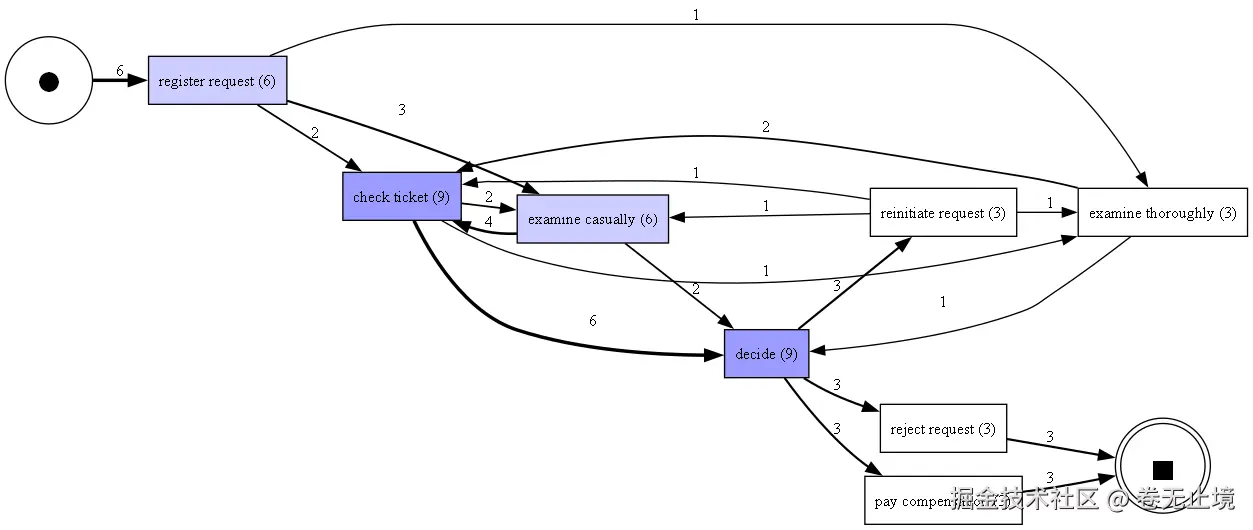
直接跟随图(Directly-Follows Graph,DFG)是最直观的流程可视化方式------节点是活动,边表示"A 之后紧接着发生 B",边上的数字是频次。
python
import pm4py
# 发现 DFG
dfg, start_activities, end_activities = pm4py.discover_dfg(log)
# 可视化 DFG(频次视图)
pm4py.view_dfg(dfg, start_activities, end_activities)
# 保存为图片
pm4py.save_vis_dfg(
dfg, start_activities, end_activities,
"output/dfg_frequency.png"
)
性能视图(显示平均处理时间而非频次):
python
# 发现性能 DFG(显示平均时间)
performance_dfg, start_activities, end_activities = pm4py.discover_performance_dfg(log)
pm4py.view_performance_dfg(performance_dfg, start_activities, end_activities)
pm4py.save_vis_performance_dfg(
performance_dfg, start_activities, end_activities,
"output/dfg_performance.png"
)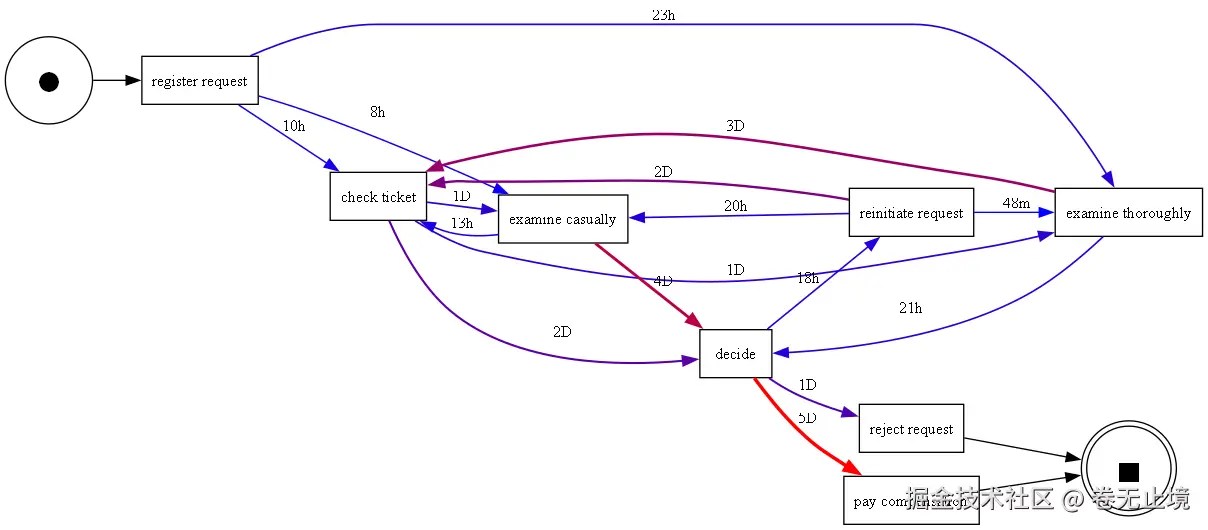
📊 图示说明:频次 DFG 中,边越粗代表该路径被走得越多;性能 DFG 中,边上标注的是两个活动之间的平均等待时间,红色边通常意味着瓶颈所在。
五、核心案例二:流程发现算法对比
PM4Py 实现了三种主流流程发现算法,各有适用场景。
5.1 Alpha Miner(经典算法)
Alpha Miner 是流程挖掘领域的奠基性算法,输出 Petri 网模型:
python
import pm4py
# Alpha Miner 发现 Petri 网
net, initial_marking, final_marking = pm4py.discover_petri_net_alpha(log)
# 可视化 Petri 网
pm4py.view_petri_net(net, initial_marking, final_marking)
pm4py.save_vis_petri_net(
net, initial_marking, final_marking,
"output/petri_net_alpha.png"
)
⚠️ Alpha Miner 对噪声敏感,适合日志质量较高的场景。
5.2 Inductive Miner(推荐算法)
Inductive Miner 鲁棒性更强,能处理噪声数据,输出流程树再转换为 Petri 网:
python
# Inductive Miner - 直接得到 Petri 网
net, initial_marking, final_marking = pm4py.discover_petri_net_inductive(log)
pm4py.view_petri_net(net, initial_marking, final_marking)
pm4py.save_vis_petri_net(
net, initial_marking, final_marking,
"output/petri_net_inductive.png"
)
# 也可以先得到流程树,再转换
process_tree = pm4py.discover_process_tree_inductive(log)
pm4py.view_process_tree(process_tree)
pm4py.save_vis_process_tree(process_tree, "output/process_tree.png")
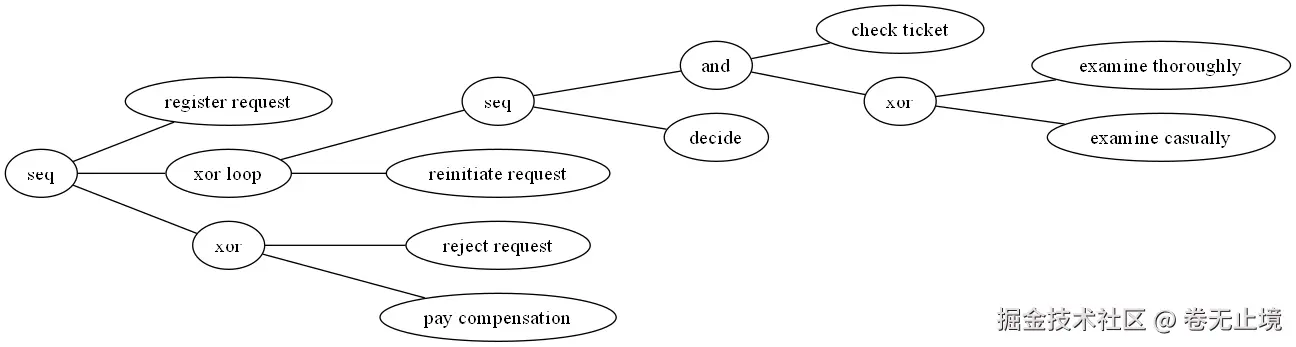
5.3 Heuristics Miner(处理复杂日志)
Heuristics Miner 对频次低的行为有过滤能力,适合真实业务日志:
python
# Heuristics Miner
net, initial_marking, final_marking = pm4py.discover_petri_net_heuristics(
log,
dependency_threshold=0.5 # 依赖阈值,越高过滤越严格
)
pm4py.view_petri_net(net, initial_marking, final_marking)
pm4py.save_vis_petri_net(
net, initial_marking, final_marking,
"output/petri_net_heuristics.png"
)
5.4 转换为 BPMN 图(业务友好)
发现的流程树可以直接转换为标准 BPMN 图,方便与业务人员沟通:
python
# 流程树 → BPMN
bpmn_model = pm4py.convert_to_bpmn(process_tree)
pm4py.view_bpmn(bpmn_model)
pm4py.save_vis_bpmn(bpmn_model, "output/bpmn_model.png")
六、核心案例三:合规检查
发现了流程模型之后,下一步就是检查真实日志有没有"按规矩走"。PM4Py 提供了 Token-based Replay 和 Alignments 两种方法。
6.1 Token-based Replay(令牌回放)
python
import pm4py
# 先用 Inductive Miner 得到参考模型
net, im, fm = pm4py.discover_petri_net_inductive(log)
# 执行令牌回放
replayed_traces = pm4py.conformance_diagnostics_token_based_replay(
log, net, im, fm
)
# 查看每个案例的合规情况
for i, trace_result in enumerate(replayed_traces):
fitness = trace_result["trace_fitness"]
is_fit = trace_result["trace_is_fit"]
print(f"案例 {i+1}: 适配度={fitness:.2f}, 合规={'✅' if is_fit else '❌'}")
yaml
案例 1: 适配度=1.00, 合规=✅
案例 2: 适配度=1.00, 合规=✅
案例 3: 适配度=1.00, 合规=✅
案例 4: 适配度=1.00, 合规=✅
案例 5: 适配度=1.00, 合规=✅
案例 6: 适配度=1.00, 合规=✅6.2 计算整体适配度(Fitness)
python
# 计算整体 fitness 指标
fitness = pm4py.fitness_token_based_replay(log, net, im, fm)
print(f"\n整体适配度报告:")
print(f" 平均 Fitness: {fitness['average_trace_fitness']:.4f}")
print(f" 完美适配案例比例: {fitness['percentage_of_fitting_traces']:.1f}%")
makefile
整体适配度报告:
平均 Fitness: 1.0000
完美适配案例比例: 100.0%6.3 基于对齐的合规检查(更精确)
python
# Alignments 方法(计算代价更高但更精确)
aligned_traces = pm4py.conformance_diagnostics_alignments(log, net, im, fm)
for i, alignment in enumerate(aligned_traces):
cost = alignment["cost"]
print(f"案例 {i+1}: 对齐代价={cost}(0 表示完全合规)")
yaml
案例 1: 对齐代价=2(0 表示完全合规)
案例 2: 对齐代价=2(0 表示完全合规)
案例 3: 对齐代价=3(0 表示完全合规)
案例 4: 对齐代价=2(0 表示完全合规)
案例 5: 对齐代价=4(0 表示完全合规)
案例 6: 对齐代价=2(0 表示完全合规)七、核心案例四:流程统计与性能分析
光知道流程长什么样还不够,还得知道哪里慢、哪里堵。
python
import pm4py
import statistics
# ── 基础统计 ──────────────────────────────────────────
activities = pm4py.get_event_attribute_values(log, "concept:name")
print("活动频次统计:")
for act, count in sorted(activities.items(), key=lambda x: -x[1]):
print(f" {act}: {count} 次")
# ── 案例持续时间统计 ───────────────────────────────────
case_durations = pm4py.get_all_case_durations(log)
print(f"\n案例持续时间统计:")
print(f" 平均: {statistics.mean(case_durations)/3600:.1f} 小时")
print(f" 中位数: {statistics.median(case_durations)/3600:.1f} 小时")
print(f" 最长: {max(case_durations)/3600:.1f} 小时")
# ── 变体分析(兼容新旧版本)────────────────────────────
variants = pm4py.get_variants(log)
print(f"\n发现 {len(variants)} 种流程变体:")
# 判断 value 是 int(新版)还是 list(旧版),统一处理
def get_count(v):
return v if isinstance(v, int) else len(v)
for variant, val in sorted(variants.items(), key=lambda x: -get_count(x[1])):
count = get_count(val)
# variant 可能是 tuple,也可能是逗号分隔的字符串,统一处理
if isinstance(variant, tuple):
path = " → ".join(variant)
else:
path = " → ".join(str(variant).split(","))
print(f" [{count} 个案例] {path}")
yaml
活动频次统计:
check ticket: 9 次
decide: 9 次
register request: 6 次
examine casually: 6 次
reinitiate request: 3 次
examine thoroughly: 3 次
pay compensation: 3 次
reject request: 3 次
案例持续时间统计:
平均: 268.6 小时
中位数: 226.7 小时
最长: 437.9 小时
发现 6 种流程变体:
[1 个案例] register request → examine thoroughly → check ticket → decide → reject request
[1 个案例] register request → check ticket → examine casually → decide → pay compensation
[1 个案例] register request → examine casually → check ticket → decide → reinitiate request → examine thoroughly → check ticket → decide → pay compensation
[1 个案例] register request → check ticket → examine thoroughly → decide → reject request
[1 个案例] register request → examine casually → check ticket → decide → reinitiate request → check ticket → examine casually → decide → reinitiate request → examine casually → check ticket → decide → reject request
[1 个案例] register request → examine casually → check ticket → decide → pay compensation7.1 可视化点图(Dotted Chart)
点图是观察流程时间分布的利器,每个点代表一个事件:
python
import pm4py
import pandas as pd
from datetime import datetime
import os
os.makedirs("output", exist_ok=True)
# ── Step 1: 构造原始数据 ──────────────────────────────
data = {
"case:concept:name": [
"case_1","case_1","case_1","case_1","case_1",
"case_2","case_2","case_2","case_2",
"case_3","case_3","case_3","case_3","case_3","case_3",
"case_4","case_4","case_4","case_4",
"case_5","case_5","case_5","case_5","case_5",
"case_6","case_6","case_6","case_6",
],
"concept:name": [
"register request","examine thoroughly","check ticket","decide","pay compensation",
"register request","examine casually","check ticket","decide",
"register request","examine casually","check ticket","decide","reinitiate request","reject request",
"register request","examine casually","check ticket","decide",
"register request","examine thoroughly","check ticket","decide","reject request",
"register request","examine casually","check ticket","decide",
],
"time:timestamp": [
datetime(2024,1,1,9,0), datetime(2024,1,2,10,0),
datetime(2024,1,3,11,0), datetime(2024,1,4,14,0), datetime(2024,1,5,9,0),
datetime(2024,1,6,9,0), datetime(2024,1,7,10,0),
datetime(2024,1,8,11,0), datetime(2024,1,9,15,0),
datetime(2024,1,10,8,0), datetime(2024,1,11,9,0),
datetime(2024,1,12,10,0),datetime(2024,1,13,13,0),
datetime(2024,1,14,10,0),datetime(2024,1,15,9,0),
datetime(2024,1,16,9,0), datetime(2024,1,17,11,0),
datetime(2024,1,18,10,0),datetime(2024,1,19,9,0),
datetime(2024,1,20,9,0), datetime(2024,1,21,10,0),
datetime(2024,1,22,11,0),datetime(2024,1,23,14,0),datetime(2024,1,24,9,0),
datetime(2024,1,25,9,0), datetime(2024,1,26,10,0),
datetime(2024,1,27,11,0),datetime(2024,1,28,15,0),
]
}
raw_df = pd.DataFrame(data)
# ── Step 2: format_dataframe → EventLog → DataFrame ──
# 注意:必须走这条转换链,@@case_index 才会被正确注入
formatted_df = pm4py.format_dataframe(
raw_df,
case_id="case:concept:name",
activity_key="concept:name",
timestamp_key="time:timestamp"
)
event_log = pm4py.convert_to_event_log(formatted_df)
# ✅ 关键步骤:转回 DataFrame,此时 @@case_index 自动生成
df_for_chart = pm4py.convert_to_dataframe(event_log)
print("DataFrame 列名:", df_for_chart.columns.tolist())
print("@@case_index 存在:", "@@case_index" in df_for_chart.columns)
# ── Step 3: 画点图 ────────────────────────────────────
# 频次点图(默认)
pm4py.view_dotted_chart(df_for_chart, format="png")
# 保存到文件
pm4py.save_vis_dotted_chart(df_for_chart, "output/dotted_chart.png")
print("✅ 点图已保存至 output/dotted_chart.png")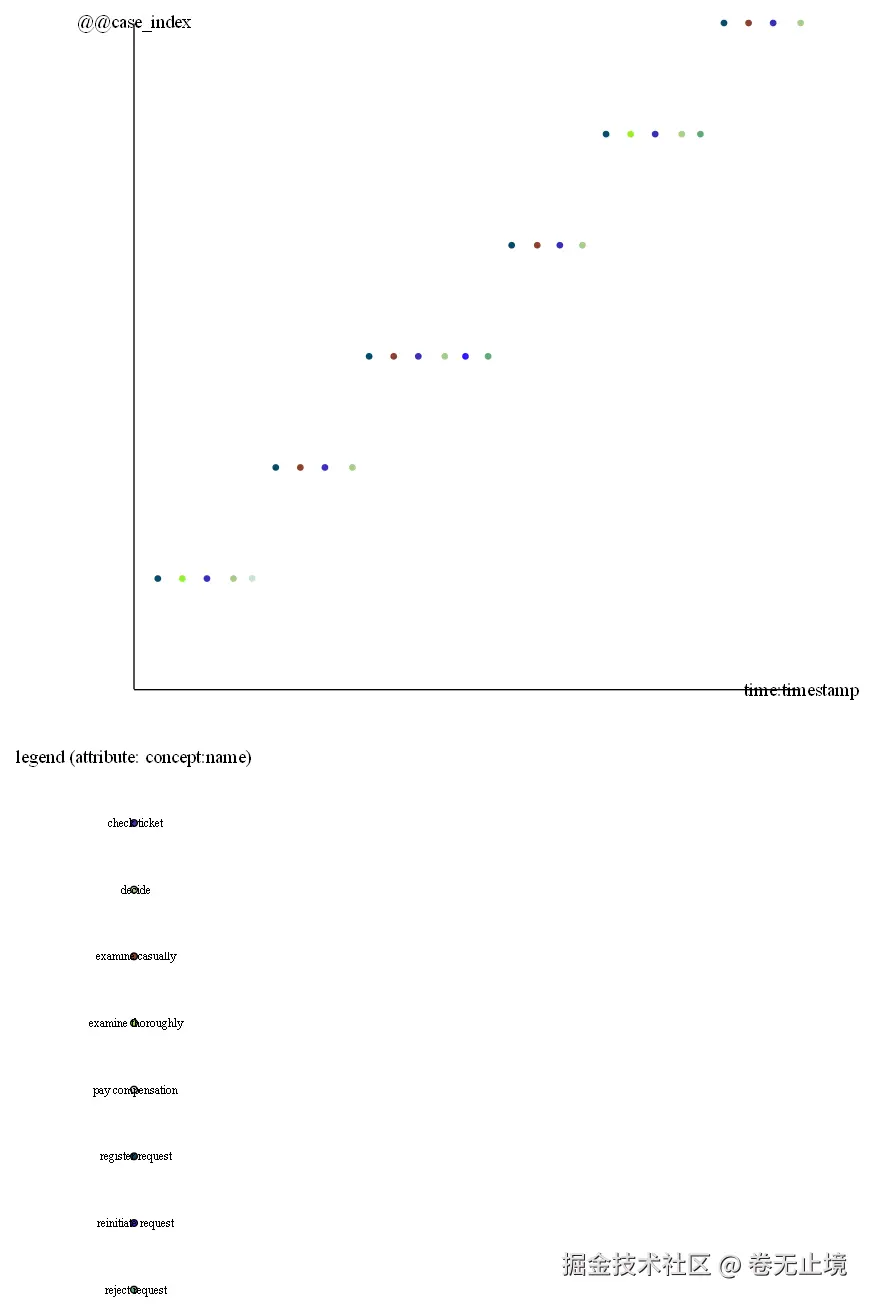
八、完整综合案例:贷款审批流程端到端分析
把前面所有内容串起来,做一次完整的流程挖掘分析:
python
import pm4py
import pandas as pd
from datetime import datetime
import os
import re
os.makedirs("output", exist_ok=True)
# ══════════════════════════════════════════════════════
# 核心工具函数:给 Graphviz dot 源码注入中文字体
# ══════════════════════════════════════════════════════
def inject_chinese_font(gviz, font="Microsoft YaHei"):
"""
直接修改 graphviz.Digraph 对象的 source,
在 graph/node/edge 属性中注入 fontname,
使 Graphviz 渲染时使用中文字体。
Windows 推荐: "Microsoft YaHei" 或 "SimHei"
macOS 推荐: "PingFang SC" 或 "Heiti SC"
Linux 推荐: "WenQuanYi Micro Hei" 或 "Noto Sans CJK SC"
"""
src = gviz.source
# 1. 在 graph [ ... ] 块里注入全局字体
if 'graph [' in src:
src = src.replace('graph [', f'graph [fontname="{font}" ', 1)
else:
# 没有 graph 属性块,手动插入
src = src.replace('digraph {', f'digraph {{\ngraph [fontname="{font}"]', 1)
src = src.replace('digraph {', f'digraph {{\ngraph [fontname="{font}"]', 1)
# 2. 在 node [ ... ] 块里注入节点字体
if 'node [' in src:
src = src.replace('node [', f'node [fontname="{font}" ', 1)
else:
src = re.sub(r'(digraph\s*\w*\s*\{)',
r'\1\n\tnode [fontname="' + font + r'"]', src, count=1)
# 3. 在 edge [ ... ] 块里注入边字体
if 'edge [' in src:
src = src.replace('edge [', f'edge [fontname="{font}" ', 1)
# 4. 重新构造 gviz 对象(保留原始引擎和格式)
import graphviz
new_gviz = graphviz.Source(src)
return new_gviz
def save_with_chinese_font(gviz, output_path, font="Microsoft YaHei"):
"""保存带中文字体的图片"""
fixed_gviz = inject_chinese_font(gviz, font=font)
# graphviz.Source 直接渲染到文件
fmt = output_path.rsplit(".", 1)[-1] # 提取格式 png/pdf 等
out_base = output_path.rsplit(".", 1)[0]
fixed_gviz.render(filename=out_base, format=fmt, cleanup=True)
print(f"✅ 已保存(含中文字体): {output_path}")
# ══════════════════════════════════════════════════════
# Step 1: 构造数据
# ══════════════════════════════════════════════════════
data = {
"case:concept:name": [
"loan_001","loan_001","loan_001","loan_001",
"loan_002","loan_002","loan_002",
"loan_003","loan_003","loan_003","loan_003","loan_003",
"loan_004","loan_004","loan_004",
],
"concept:name": [
"提交申请","初步审核","信用评估","批准放款",
"提交申请","初步审核","拒绝申请",
"提交申请","初步审核","信用评估","补充材料","批准放款",
"提交申请","信用评估","批准放款",
],
"time:timestamp": [
datetime(2024,1,1,9,0), datetime(2024,1,1,10,0),
datetime(2024,1,1,14,0), datetime(2024,1,2,9,0),
datetime(2024,1,3,9,0), datetime(2024,1,3,10,30),
datetime(2024,1,3,15,0),
datetime(2024,1,5,8,0), datetime(2024,1,5,9,0),
datetime(2024,1,5,13,0), datetime(2024,1,6,10,0),
datetime(2024,1,7,9,0),
datetime(2024,1,8,9,0), datetime(2024,1,8,11,0),
datetime(2024,1,9,9,0),
]
}
df = pd.DataFrame(data)
df = pm4py.format_dataframe(
df,
case_id="case:concept:name",
activity_key="concept:name",
timestamp_key="time:timestamp"
)
log = pm4py.convert_to_event_log(df)
# ══════════════════════════════════════════════════════
# Step 2: DFG 可视化(注入中文字体)
# ══════════════════════════════════════════════════════
from pm4py.visualization.dfg import visualizer as dfg_visualizer
dfg, start_acts, end_acts = pm4py.discover_dfg(log)
# 用底层 API 拿到 gviz 对象
gviz_dfg = dfg_visualizer.apply(
dfg,
parameters={
"start_activities": start_acts,
"end_activities": end_acts,
"format": "png"
}
)
save_with_chinese_font(gviz_dfg, "output/01_dfg.png")
# ══════════════════════════════════════════════════════
# Step 3: Petri 网(注入中文字体)
# ══════════════════════════════════════════════════════
from pm4py.visualization.petri_net import visualizer as pn_visualizer
net, im, fm_marking = pm4py.discover_petri_net_inductive(log)
gviz_pn = pn_visualizer.apply(
net, im, fm_marking,
parameters={"format": "png"}
)
save_with_chinese_font(gviz_pn, "output/02_petri_net.png")
# ══════════════════════════════════════════════════════
# Step 4: BPMN(注入中文字体)
# ══════════════════════════════════════════════════════
from pm4py.visualization.bpmn import visualizer as bpmn_visualizer
process_tree = pm4py.discover_process_tree_inductive(log)
bpmn = pm4py.convert_to_bpmn(process_tree)
gviz_bpmn = bpmn_visualizer.apply(
bpmn,
parameters={"format": "png"}
)
save_with_chinese_font(gviz_bpmn, "output/03_bpmn.png")
# ══════════════════════════════════════════════════════
# Step 5: 合规检查
# ══════════════════════════════════════════════════════
replayed = pm4py.conformance_diagnostics_token_based_replay(log, net, im, fm_marking)
fitness = pm4py.fitness_token_based_replay(log, net, im, fm_marking)
print(f"\n📊 合规检查结果:")
print(f" 整体适配度: {fitness['average_trace_fitness']:.2%}")
print(f" 完美合规案例: {fitness['percentage_of_fitting_traces']:.1f}%")
for i, r in enumerate(replayed):
status = "✅ 合规" if r["trace_is_fit"] else "❌ 偏差"
print(f" {status} | 案例{i+1} 适配度: {r['trace_fitness']:.2f}")
# ══════════════════════════════════════════════════════
# Step 6: 变体统计
# ══════════════════════════════════════════════════════
variants = pm4py.get_variants(log)
print(f"\n🔀 流程变体分析(共 {len(variants)} 种路径):")
def get_count(v):
return v if isinstance(v, int) else len(v)
for variant, val in sorted(variants.items(), key=lambda x: -get_count(x[1])):
count = get_count(val)
path = " → ".join(variant) if isinstance(variant, tuple) else str(variant)
print(f" [{count} 例] {path}")
print("\n🎉 分析完成!所有图表已保存至 output/ 目录")
csharp
✅ 已保存(含中文字体): output/01_dfg.png
✅ 已保存(含中文字体): output/02_petri_net.png
✅ 已保存(含中文字体): output/03_bpmn.png
replaying log with TBR, completed traces :: 100%
4/4 [00:00<00:00, 241.50it/s]
replaying log with TBR, completed traces :: 100%
4/4 [00:00<00:00, 231.51it/s]
📊 合规检查结果:
整体适配度: 100.00%
完美合规案例: 100.0%
✅ 合规 | 案例1 适配度: 1.00
✅ 合规 | 案例2 适配度: 1.00
✅ 合规 | 案例3 适配度: 1.00
✅ 合规 | 案例4 适配度: 1.00
🔀 流程变体分析(共 4 种路径):
[1 例] 提交申请 → 初步审核 → 信用评估 → 批准放款
[1 例] 提交申请 → 初步审核 → 拒绝申请
[1 例] 提交申请 → 初步审核 → 信用评估 → 补充材料 → 批准放款
[1 例] 提交申请 → 信用评估 → 批准放款
🎉 分析完成!所有图表已保存至 output/ 目录

 运行后,
运行后,output/ 目录下会生成三张核心图表:
| 文件名 | 内容 | 用途 |
|---|---|---|
01_dfg.png |
直接跟随图 | 快速了解活动顺序和频次 |
02_petri_net.png |
Petri 网模型 | 形式化流程模型,支持合规检查 |
03_bpmn.png |
BPMN 流程图 | 与业务人员沟通的标准语言 |
九、三大算法横向对比
选对算法能省很多力气,这张表帮你快速决策:
| 算法 | 输出格式 | 抗噪能力 | 适用场景 |
|---|---|---|---|
| Alpha Miner | Petri 网 | 弱(对噪声敏感) | 教学演示、高质量日志 |
| Inductive Miner | 流程树 / Petri 网 | 强 | 通用推荐,大多数场景首选 |
| Heuristics Miner | Petri 网 | 中(可调阈值) | 真实业务日志、含低频路径 |
十、进阶方向
掌握了基础之后,PM4Py 还有几个值得深入的方向:
-
对象中心流程挖掘(OCPM):突破传统"单案例"限制,处理多对象交互的复杂流程,是 PM4Py 2.x 的重点新特性
-
预测性流程挖掘:结合机器学习预测案例的下一步活动或完成时间
-
流程过滤 :用
pm4py.filter_*系列函数对日志做时间窗口、活动、变体等多维度过滤 -
社交网络分析:分析资源(人员)之间的协作关系
参考文献
-
Process Intelligence Solutions. PM4Py --- Process Mining for Python . processintelligence.solutions/pm4py
-
Berti, A., van Zelst, S. J., & van der Aalst, W. M. P. (2019). Process Mining for Python (PM4Py): Bridging the Gap Between Process- and Data Science . CEUR Workshop Proceedings, Vol. 2374. ceur-ws.org/Vol-2374/pa...
-
Hussam Al-Humsi. Introduction to Process Mining using Python (PM4PY) . GitHub Repository. github.com/Hussam1/int...
-
Berti, A., van Zelst, S., & Schuster, D. (2023). PM4Py: A process mining library for Python . Software Impacts, 17, 100556. doi.org/10.1016/j.s...