数据库专题开篇:零基础迈入 MySQL 的第一步
如果说高效的并发程序是快速流动、充满活力的"河流",那么数据库就是承载这些河流的"水库"。在云原生与微服务时代,不管你的业务逻辑写得多漂亮,如果不会高效、安全地存储和读取数据,一切都是空谈。
今天,我们就从零开始,为你铺平一条从"小白"到"掌控数据"的通畅之路。
一、 看清世界:什么是数据库?(用 Excel 降维理解)
初学者听到"关系型数据库"、"结构化查询语言"这些词往往会觉得头大。其实,你完全可以把以 MySQL 为代表的数据库,想象成一个超级进化版、运行在远程服务器上的 Excel 软件。
我们可以做个非常直观的对齐类比:
| Excel 的概念 | MySQL 数据库的概念 | 核心本质 |
|---|---|---|
一个 .xlsx 文件/项目 |
数据库 (Database) | 存放一整个项目所有数据的容器。 |
| 工作表 (Sheet,如用户表) | 数据表 (Table) | 规定了结构和行列的二维矩阵。 |
| 表头列名 (如 姓名、年龄) | 字段/列 (Column / Field) | 定义每一列数据叫什么、是什么数据类型。 |
| 单行数据 (如 张三, 18岁) | 记录/行 (Row / Record) | 真正写入的每一条具体业务数据。 |

1. 广阔的生态:关系型 vs 非关系型
在市面上,你会听到各种各样的数据库名词,它们主要分为两大阵营:
-
关系型数据库(SQL,如 MySQL、PostgreSQL、Oracle):
-
特点:就像 Excel,数据必须一行一列、规规矩矩地存放在"二维表"里。表与表之间可以通过某个字段(如用户ID)建立"关联关系"。
-
场景:大总管。适合存放结构严谨、错一点都不行的核心资产,比如账号、订单、银行余额。
-
非关系型数据库(NoSQL,如 Redis、MongoDB):
-
特点:放飞自我。不搞表格那一套,有的像 Go 语言里的 Map(键值对),有的像大文本(JSON)。
-
场景:特种兵。适合追求极致速度(如 Redis 纯内存操作缓存)或存放极其杂乱的数据。

而 MySQL,正是目前全球互联网占有率最高、最经典的关系型数据库王者。
2. 为什么不用 Excel 存网站数据,非要用 MySQL?
- 高并发支持 :Excel 同一时间只能一个人编辑,后面的人开就会提示"只读";而 MySQL 支持成千上万个用户同时读写。
- 海量吞吐 :Excel 超过几十万行就会卡死崩掉;而 MySQL 能够轻松应对千万级、亿级的数据存储。
- 数据安全:MySQL 拥有严格的事务机制,能保证哪怕服务器突然断电,银行转账数据也绝对不会出错。
二、 搬回工具:MySQL 的安装、启动与连接
要想让 MySQL 为你干活,首先得在电脑(服务器)上把它跑起来。
1. 安装与服务启动
- 安装 :在 Windows 上,初学者建议直接下载官方的
MySQL Installer,一路 Next 傻瓜式安装,期间它会让你设置一个 root 用户(即超级管理员)的密码,请务必死死记住这个密码。 - 服务的本质 :MySQL 安装好后,在系统中是以一个"后台服务/守护进程"(Windows 下叫
MySQL服务,Linux 下叫mysqld)的形式默默运行的。 - 如何启动:
- Windows:打开任务管理器 → \rightarrow → 服务 → \rightarrow → 找到
MySQL→ \rightarrow → 右键启动。 - 命令行(管理员权限):
net start mysql。
1. 🚀 核心:MySQL 数据库服务端下载(最常用)
进入后可以根据你的系统(Windows / macOS / Linux)选择对应的安装包。
- 最新 GA / LTS 版本直达:可疑链接已删除
- 经典 8.0 稳定版直达 (目前国内企业生产环境占有率极高):MySQL Community Server 8.0 下载页
2. 🛠️ 辅助:周边生态官方下载(按需选择)
如果你需要官方自带的图形化工具或打包安装器,可以走以下通道:
- Windows 一键打包安装器 :MySQL Installer for Windows
注:官方提供的这个 Installer 适合懒人一键安装服务端 + 图形化界面。
- 官方自带的图形化管理软件 :MySQL Workbench 下载页
虽然它是官方的,但正如我们博客中所说,日常开发中更推荐你使用 Navicat 或免费开源的 DBeaver,界面和操作会更加人性化。
- 全套社区版组件总览 :MySQL Community Downloads 总目录
💡 初学者下载小贴士
- Windows 用户 :在下载页面选择系统为
Microsoft Windows后,建议优先下载带有.msi后缀的安装包(这是安装向导版,类似软件安装下一步下一步即可),不建议直接下.zip压缩包(那个需要自己手动配环境变量和写初始化配置文件,容易把新手劝退)。 - 下载速度慢的平替方案 :如果官方网站下载速度极慢,可以直接去国内各大高校的镜像站(如清华大学开源软件镜像站、华为开源镜像站)搜
mysql,直接拉取安装包,速度会起飞。
2. 客户端连接:谁来发号施令?
MySQL 服务在后台跑起来后,它只是个默默等待连接的"木疙瘩"(Server 端)。我们需要一个"客户端(Client)"去连接它、向它发送指令。
- 方式 A:自带的黑窗口命令行(最硬核)
打开终端输入连接命令,输入你安装时设定的密码:
bash
mysql -u root -p当看到终端变成 mysql> 开头时,说明你已经成功潜入数据库内部!
- 方式 B:图形化客户端(初学者强烈推荐)
日常开发中,我们一般不看黑窗口,而是使用 Navicat 、DataGrip 或免费开源的 DBeaver 等图形化软件。你只需要在软件里输入 IP(本地填127.0.0.1或localhost)、端口(默认3306)、用户名root和你的密码,就能像操作 Excel 一样点点点来看数据了。
三、 建立领地:如何创建一个数据库和一张表?
连接成功后,里面是一片虚无。我们需要通过指令来圈地建楼。
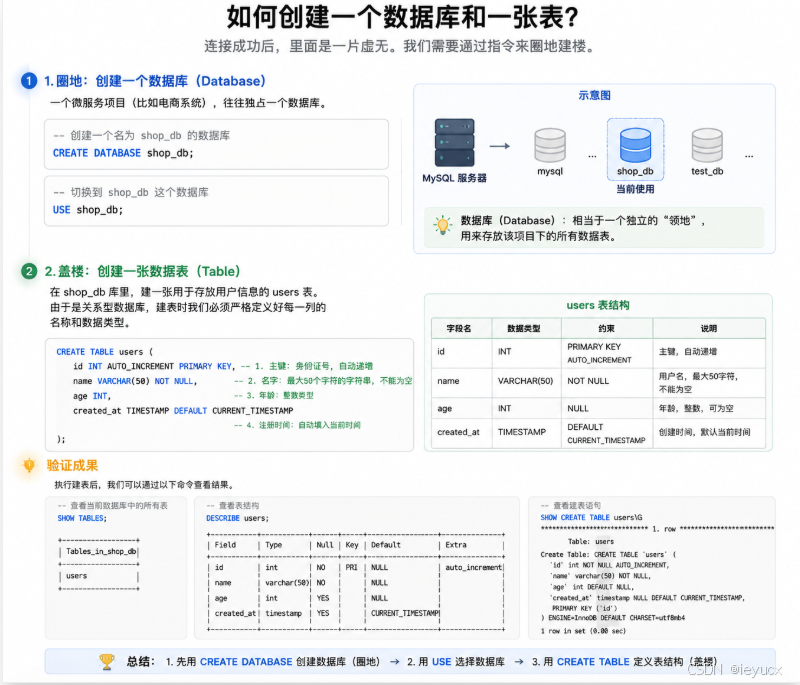
1. 圈地:创建一个数据库(Database)
一个微服务项目(比如电商系统),往往独占一个数据库。
sql
CREATE DATABASE shop_db;建好之后,告诉 MySQL 我们接下来的指令要在哪个领地执行:
sql
USE shop_db;2. 盖楼:创建一张数据表(Table)
现在我们在 shop_db 库里,建一张用于存放用户信息的 users 表。由于是关系型数据库,建表时我们必须严格定义好每一列叫什么、是什么数据类型:
sql
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY, -- 1. 主键:身份证号,自动递增
name VARCHAR(50) NOT NULL, -- 2. 名字:最大50个字符的字符串,不能为空
age INT, -- 3. 年龄:整数类型
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 4. 注册时间:自动填入当前时间
);四、 核心深挖:彻底厘清库表设计的"黄金四角"
在刚才的建表语句中,你看到了 PRIMARY KEY 等字眼。在真实的数据库设计中,有四个概念被称为数据架构的"黄金四角"。它们天天出现在建表单里,不仅决定了数据的安全,更决定了查询的速度。
我们继续用通俗的"公司员工档案表"和"新华字典"来做降维类比,把它们一次性说透:
1. 候选键 (Candidate Key) ------ 备选的"政审委员"
-
大白话类比 :在公司的员工档案里,哪些信息可以唯一确定一个人,绝对不会有第二个人和他在这一项上完全一样?
-
方案A:你的身份证号(全局唯一)
-
方案B:公司发给你的工号(公司内唯一)
-
方案C:你的手机号(通常也是唯一的)
-
数据库定义 :表中的某一个字段(或几个字段的组合),它能够唯一地标识表中的一条记录。只要这一列的值不重复,它就有资格成为候选人。
-
特点 :一张表里,候选键可以有零个或多个。比如上述的"身份证号"、"工号"、"手机号"全是候选键。
2. 主键 (Primary Key) ------ 最终登基的"真命天子"
- 大白话类比 :虽然身份证号、工号、手机号都能唯一标识你,但公司大总管(MySQL)嫌麻烦,说:"我每天要管理几万条数据,不能一会儿用身份证查,一会儿用手机号查,我必须在候选人里挑一个 ,作为全表至高无上的'一号核心绑定项'!" 最终,大总管挑中了"工号",这就是主键。
- 数据库定义 :从众多"候选键"中选出来、作为唯一标识符的那一个字段。
- 铁律:
- 一张表有且仅能有一个主键。
- 主键的值绝对不能为空(NOT NULL) ,也绝对不能重复。
- 为什么类型不能乱选? :如果图省事把所有列全设为字符串(VARCHAR),不仅空间暴涨,还无法让数据库去过滤"年龄大于20岁"这种范围比较。同样,最推荐的做法是搞一个没有任何业务含义的自增整数
id INT AUTO_INCREMENT PRIMARY KEY。AUTO_INCREMENT让它在每次塞入新数据时自动变 1, 2, 3... 无需手动去算,它是 MySQL 帮数据在磁盘上建立排列表格的物理依据。
3. 唯一键 / 唯一约束 (Unique Key) ------ 落选者的"终身爵位"
- 大白话类比:工号成功登基成了"主键"。那落选的"身份证号"和"手机号"怎么办呢?虽然它们没当上主键,但它们的属性依然是唯一的啊,总不能允许两个员工填同一个手机号吧?大总管说:"给它们颁发'唯一键'称号,帮它们加上约束,谁要是敢填重复的手机号,系统直接报错弹开!"
- 数据库定义 :用来确保表中某一列(或多列组合)的数据不重复。
- 它与主键的区别:
- 主键全表只能有一个,而唯一键(Unique)在一张表里可以设置无数个。
- 主键的值绝对不能为空,而唯一键的值允许为空(NULL)。在 MySQL 中,唯一键甚至允许出现多个 NULL 值,因为数据库认为"空"和"空"是无法比较、不相等的。
4. 索引 (Index) ------ 畅游数据海的"新华字典目录"
如果说上面三个"键(Key)"主要是为了做安全约束(防止数据重复) ,那么"索引(Index)"的唯一目的就是为了天下武功,唯快不破(提升查询速度)。
-
大白话类比:想象一本 1000 页的《新华字典》,里面收录了几万个汉字。如果你想找"张"这个字:
-
没有索引(全表扫描) :你必须从第 1 页开始,一页一页往后翻,直到在第 600 页找到了它。在数据库里这叫 Full Table Scan(全表扫描),数据量一上百万,服务器当场卡死。
-
有索引(目录查询) :你先花 2 秒钟翻到字典最前面的《拼音音节索引》,找到
Z→ \rightarrow →zhang,上面写着"第 600 页"。你直接哗啦一下翻到第 600 页。搞定! -
数据库定义 :索引是数据库管理系统(DBMS)中一个独立的数据结构(MySQL 默认使用的是 B+ 树 结构),它就像字典的目录,默默地把数据排好序放在一旁。
-
天生光环:主键、唯一键自带索引
你不需要手动去给主键加索引。当你声明
PRIMARY KEY或UNIQUE的那一刻,MySQL 会自动在后台为这一列创建索引。所以,当你在百万级数据中执行SELECT * FROM users WHERE id = 9999时,由于id是主键,有目录可查,MySQL 可以耗时 0 毫秒 瞬间精准揪出结果。
🌟 总结一张口诀表,彻底打牢地基:
| 概念 | 核心目的 | 一张表可以有几个? | 允许重复吗? | 允许为空吗? |
|---|---|---|---|---|
| 候选键 | 找出有唯一性潜力的列 | 0 个、1 个 或 多个 | 绝不重复 | 绝不能为空 |
| 主键 | 确定全表的唯一物理标识 | 有且仅能有 1 个 | 绝不重复 | 绝不能为空 |
| 唯一键 | 防止非主键列的数据录入重复 | 可以有无数个 | 绝不重复 | 允许为空 (NULL) |
| 索引 | 像字典目录一样,疯狂提速查询 | 可以有无数个 | 视具体索引类型而定 | 视具体列属性而定 |

五、 调遣兵将:什么是 SQL?掌控生死的 CRUD 基本功
我们刚刚写下的 CREATE DATABASE、CREATE TABLE 属于 SQL(Structured Query Language,结构化查询语言)。
- 定义 :SQL 是人类、你的 Go/Java 程序与关系型数据库沟通的唯一通用普通话。
- 核心分类 :对于初学者来说,你只需率先攻克最核心的四个操作(业界俗称 CRUD:增加、读取、更新、删除),就能搞定 80% 的日常开发。
下面,我们对着刚才建好的 users 表,依次执行 CRUD 指令:
1. C (Create) - 插入数据:INSERT
把新数据塞进水库:
sql
INSERT INTO users (name, age) VALUES ('张三', 18);
INSERT INTO users (name, age) VALUES ('李四', 25);- 解释 :往
users表里的name和age列,分别塞入一条张三(18岁)和李四(25岁)的记录。此时系统会自动为它们分配id=1和id=2。
2. R (Read) - 查询数据:SELECT(用得最多)
把数据从水库里捞出来:
sql
-- 捞出所有人的所有信息(* 代表所有列)
SELECT * FROM users;
-- 条件精准捞:只捞大于 20 岁的人的名字
SELECT name FROM users WHERE age > 20;运行结果输出模拟:
text
+------+
| name |
+------+
| 李四 |
+------+- 解释 :
WHERE是过滤器。MySQL 扫描全表发现只有"李四"满足大于20岁的条件,于是把他的名字摘出来打包返回给客户端。
3. U (Update) - 修改数据:UPDATE
数据变了,去表里更新它:
sql
UPDATE users SET age = 19 WHERE name = '张三';运行结果输出模拟:
text
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0- 🔥 初学者第一死穴 :千万不要漏掉
WHERE! 如果你写成UPDATE users SET age = 19;,由于没有指定WHERE过滤器,MySQL 会把整张表所有用户 的年龄瞬间全部改成 19 岁!在生产环境漏写WHERE是直接导致"开除+卷铺盖走人"的顶级事故。
4. D (Delete) - 删除数据:DELETE
不需要的数据,从表里抹去:
sql
DELETE FROM users WHERE name = '张三';- 🔥 初学者第二死穴 :同样,千万不要漏掉
WHERE! 如果不加WHERE,整张表的所有行数据会被瞬间清空(删库跑路的经典现场)。
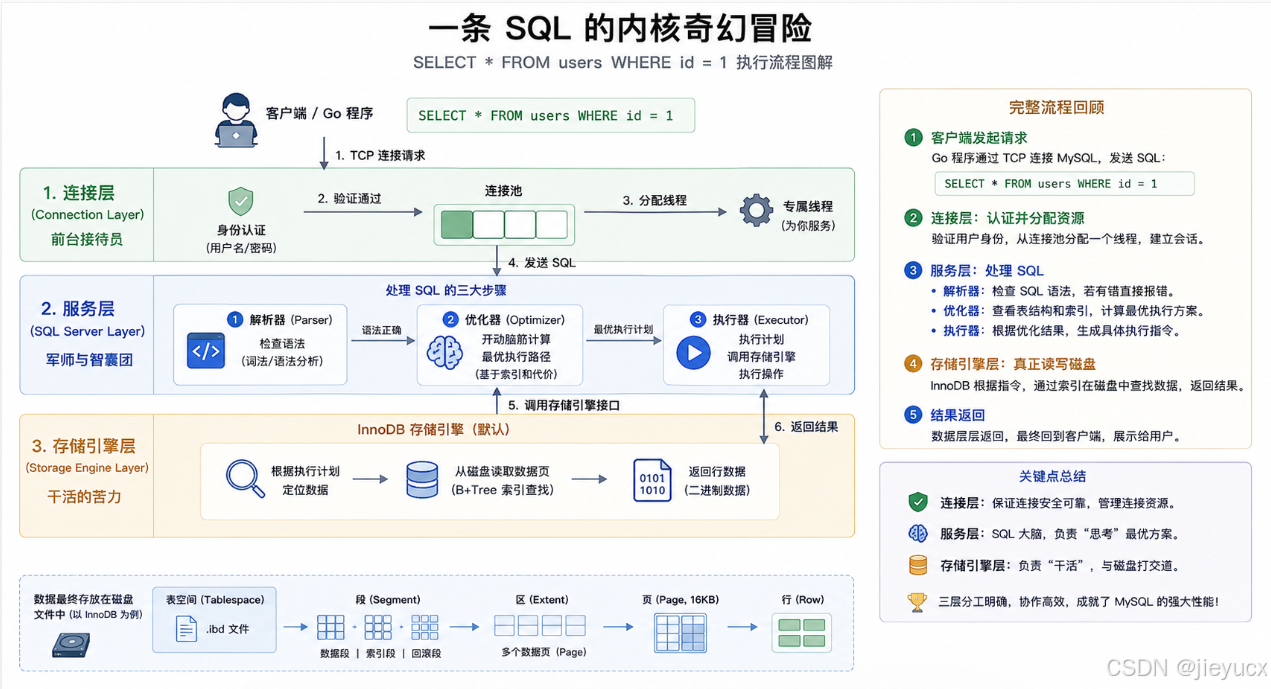
六、 进阶序章:一条 SQL 的内核奇幻冒险
当你已经能在客户端熟练地敲下 SELECT * FROM users WHERE id = 1 并拿到结果时,你终于有资格去一窥 MySQL 引擎底层的秘密了。
MySQL 的内部,其实分成了井然有序的三层架构:
1. 连接层 (Connection Layer) ------ 前台接待员
当你的 Go 程序通过 TCP 握手连过来时,连接层负责检查你的用户名密码对不对。验证通过后,它会从内部的连接池里划拨一个专属线程为你服务,维持通信。
2. 服务层 (SQL Server Layer) ------ 军师与智囊团
它拿到你发送的 SQL 语句后,主要做三件事:
- 解析器:检查语法。如果你少写了个分号或拼错了单词,这里会直接报错拒绝。
- 优化器(关键):开动脑筋算计。它会查看你表里有什么索引(也就是看字典目录),计算出一条"耗时最短、代价最小"的执行路径。
- 执行器:根据优化器的方案,向底层的苦力发出最终指令。
3. 存储引擎层 (Storage Engine Layer) ------ 干活的苦力
MySQL 的数据最终是写在硬盘文件里的。存储引擎层(默认是全行业标准的 InnoDB 引擎 )接收到服务层的指令,真正把触手伸向硬盘的 SSD,把那行二进制数据捞上来返回,或者把新数据擦写进磁盘。
🎯 总结与后续剧透
恭喜你!读到这里,你已经平稳、系统地跨过了 MySQL 的大门。此时在你的脑海里,主键在当顶梁柱,唯一键在抓防重,索引在后台开挂提速,而一万个并发请求正在通过连接层、服务层向存储引擎层疯狂进发。
这只是我们数据库专题的第一步。有了这个坚实的地基,接下来我们就要切入最核心、最影响后端程序员薪资的深水区了。
欢迎在评论区留下你的脚印:你第一次在本地成功安装并连上 MySQL 的时候,遇到的第一个报错是什么?下一期,我们将正式踏入技术面试的绝对核心------《MySQL 核心双子星:彻底扒光 B+ 树索引与事务隔离级别的底层底裤》,敬请期待!