CUDA访存优化完全指南:全局内存合并与共享内存Bank冲突深度解析
在上一篇文章中,我们系统学习了CUDA的内存模型和基础内存管理API。今天,我们将进入CUDA性能优化的核心战场------访存优化。
对于90%以上的CUDA程序来说,真正的性能瓶颈不是计算能力,而是内存访问效率。一个未经访存优化的程序,往往只能发挥GPU不到10%的理论性能。而掌握了本文讲解的全局内存合并访问和共享内存优化技术,你可以轻松将程序性能提升几倍甚至几十倍。
本文将从硬件原理出发,通过大量代码示例和性能对比,彻底搞懂什么是合并访问、为什么会产生Bank冲突、以及如何系统地进行访存优化。
一、为什么访存优化如此重要?
我们先回顾一下A100 GPU的关键数据:
- 单精度浮点计算能力:19.5 TFLOPS
- HBM2e全局内存带宽:1.5 TB/s
如果每次浮点运算需要读取4字节数据,那么喂饱19.5 TFLOPS的计算能力需要78 TB/s 的内存带宽。而实际带宽只有1.5 TB/s,这意味着98%的时间GPU都在等待内存数据!
这就是著名的内存墙 (Memory Wall)问题。GPU的计算能力增长速度远远超过了内存带宽的增长速度,访存效率已经成为制约GPU性能的最主要因素。
CUDA访存优化的核心目标就是:最大限度地减少对全局内存的访问次数,同时提高每次全局内存访问的效率。
二、全局内存合并访问:最基础也最重要的优化
全局内存合并访问(Coalesced Memory Access)是所有CUDA优化的第一步,也是投入产出比最高的优化。一个不满足合并访问的程序,无论其他方面优化得多么好,性能都会非常差。
2.1 什么是合并访问?
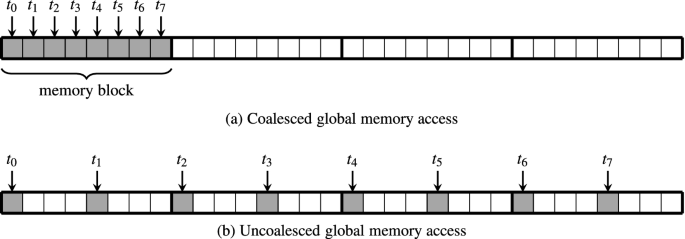
要理解合并访问,我们首先需要回顾GPU的执行模型:GPU以warp(32个线程)为基本执行单元。当一个warp执行全局内存加载指令时,GPU会将这32个线程的内存访问请求合并成尽可能少的内存事务。
合并访问的定义 :当一个warp中的32个线程访问连续且对齐 的内存地址时,GPU可以将这32个访问合并成一个或两个内存事务,从而最大化内存带宽利用率。
反之,如果线程访问的地址不连续或不对齐,GPU就需要发起多个内存事务,导致带宽利用率急剧下降。
2.2 合并访问的硬件原理
从Fermi架构(计算能力2.0)开始,NVIDIA引入了更灵活的合并机制:
- 全局内存以128字节为一个缓存行(Cache Line)
- 一个warp的32个线程,每个线程访问4字节数据,正好是128字节
- 如果这32个线程访问的地址正好落在同一个128字节的缓存行内,并且地址连续,那么GPU只需要发起1个内存事务
- 如果地址跨了两个缓存行,就需要发起2个内存事务
- 如果地址完全随机,最坏情况下需要发起32个内存事务
这意味着,最坏情况下的非合并访问带宽利用率只有最好情况的1/32!
在这里插入图片描述
2.3 常见的访问模式及性能对比
我们通过一个简单的例子来对比不同访问模式的性能差异。假设我们有一个一维数组A,一个warp的32个线程访问这个数组。
1. 完全合并访问(最佳情况)
cpp
__global__ void kernel(const float* A) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
float val = A[i]; // 线程0访问A[0], 线程1访问A[1], ..., 线程31访问A[31]
}- 访问模式:连续、对齐
- 内存事务数:1
- 带宽利用率:100%
2. 跨缓存行访问
cpp
__global__ void kernel(const float* A) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
float val = A[i + 1]; // 线程0访问A[1], ..., 线程31访问A[32]
}- 访问模式:连续但不对齐,跨两个缓存行
- 内存事务数:2
- 带宽利用率:50%
3. 步长为2的访问
cpp
__global__ void kernel(const float* A) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
float val = A[i * 2]; // 线程0访问A[0], 线程1访问A[2], ..., 线程31访问A[62]
}- 访问模式:间隔访问,覆盖两个缓存行
- 内存事务数:2
- 带宽利用率:50%
4. 步长为32的访问(最坏情况)
cpp
__global__ void kernel(const float* A) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
float val = A[i * 32]; // 线程0访问A[0], 线程1访问A[32], ..., 线程31访问A[992]
}- 访问模式:每个线程访问不同的缓存行
- 内存事务数:32
- 带宽利用率:3.125%
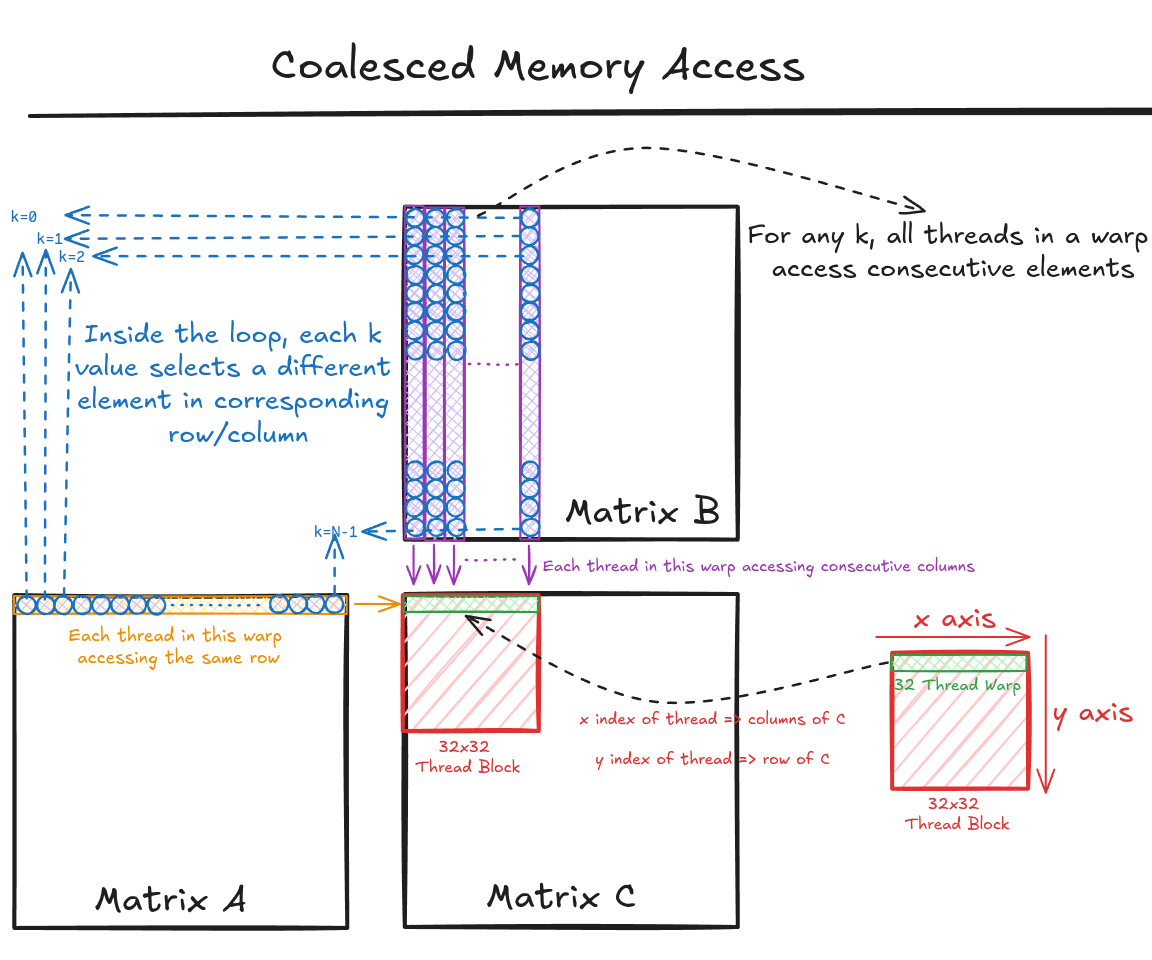
2.4 二维数组的合并访问
二维数组是图像处理和科学计算中最常用的数据结构,但也是最容易产生非合并访问的地方。
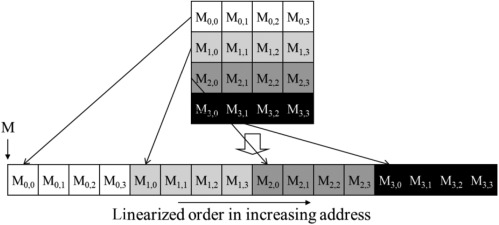
在C/C++中,二维数组是按行优先存储的。这意味着同一行的元素在内存中是连续的,而同一列的元素在内存中是不连续的。
cpp
// 错误示例:按列访问,完全非合并
__global__ void kernel(float** A, int rows, int cols) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < cols && y < rows) {
float val = A[x][y]; // 同一warp的线程访问不同行的同一列,完全非合并
}
}
// 正确示例:按行访问,完全合并
__global__ void kernel(float** A, int rows, int cols) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < cols && y < rows) {
float val = A[y][x]; // 同一warp的线程访问同一行的不同列,完全合并
}
}重要结论 :对于二维数组,总是让x方向对应列,y方向对应行 ,这样才能保证合并访问。
注意:在CUDA编程中,threadIdx.y 代表行索引,threadIdx.x 代表列索引。可以通过XY轴坐标进行联想
2.5 全局内存访问优化方法
- 保证访问的连续性和对齐:这是最基本也是最重要的原则
- 调整数据布局:将数组的维度交换,让访问最快的维度对应内存中连续的维度
- 使用向量类型 :使用
float2、float4等向量类型可以增加每个线程访问的数据量,提高合并效率 - 避免跨步访问:尽量减少步长大于1的访问
- 使用共享内存进行转置:对于必须进行的非连续访问,可以先将数据加载到共享内存,然后在共享内存中进行转置
三、共享内存基础与分块思想:数据复用的艺术
如果说合并访问是提高单次全局内存访问效率的方法,那么共享内存就是减少全局内存访问次数的最有力武器。
共享内存位于SM内部,访问速度比全局内存快100倍以上。它的核心价值在于数据复用:当多个线程需要访问同一个全局内存数据时,我们可以只从全局内存加载一次到共享内存,然后所有线程都从共享内存访问,从而大大减少全局内存的访问次数。
3.1 共享内存的核心特性回顾
- 位置:SM内部,与寄存器同级别
- 访问延迟:~1-5ns,与寄存器相当
- 容量:每个SM几十KB到几百KB(A100每个SM有192KB)
- 共享范围:同一个线程块内的所有线程
- 生命周期:与线程块相同
3.2 分块(Tiling)思想:共享内存的核心应用
分块(也叫分块矩阵乘法、Tiling)是共享内存最经典也是最重要的应用。它的核心思想是:将大的计算任务划分为多个小的块,每个块的数据加载到共享内存中,然后在共享内存中完成计算。
我们以矩阵乘法为例来详细讲解分块思想。矩阵乘法是深度学习和科学计算的基础运算,也是最能体现分块思想价值的算法。
基础版矩阵乘法(无共享内存)
首先看一下最基础的矩阵乘法实现:
cpp
// C = A * B
// A: MxK, B: KxN, C: MxN
__global__ void matrixMulNaive(const float* A, const float* B, float* C, int M, int N, int K) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < M && col < N) {
float sum = 0.0f;
for (int k = 0; k < K; k++) {
sum += A[row * K + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}这个实现非常直观,但性能非常差。为什么?因为对于每个C的元素,我们需要从全局内存读取K个A的元素和K个B的元素。 总的全局内存访问次数是:
- A: M * N * K 次
- B: M * N * K 次
- 总计:2 * M * N * K 次
对于一个1024x1024的矩阵乘法,这意味着需要进行20亿次全局内存访问!
分块版矩阵乘法(使用共享内存和线程块特性)
现在我们使用分块思想来优化这个矩阵乘法。我们将矩阵划分为多个32x32的块,每个线程块负责计算C的一个32x32块。
利用共享内存(Shared Memory):
- 将一个 tile(块)的数据加载到共享内存
- 线程块内所有线程重复使用这些数据
共享内存特点:
- 共享范围:同一线程块(block)内的所有线程
- 不共享:不同线程块之间的线程看不到对方的共享内存
- 每个线程块有自己独立的共享内存副本
- 创建:当线程块启动时,共享内存自动分配
- 存活:整个 kernel 执行期间(从 block 开始到结束)
- 销毁:线程块执行完毕后,共享内存自动释放
- 不同 block 的共享内存相互独立,互不影响
计算 Cyx 需要:
- A 的第 y 行的所有元素
- B 的第 x 列的所有元素
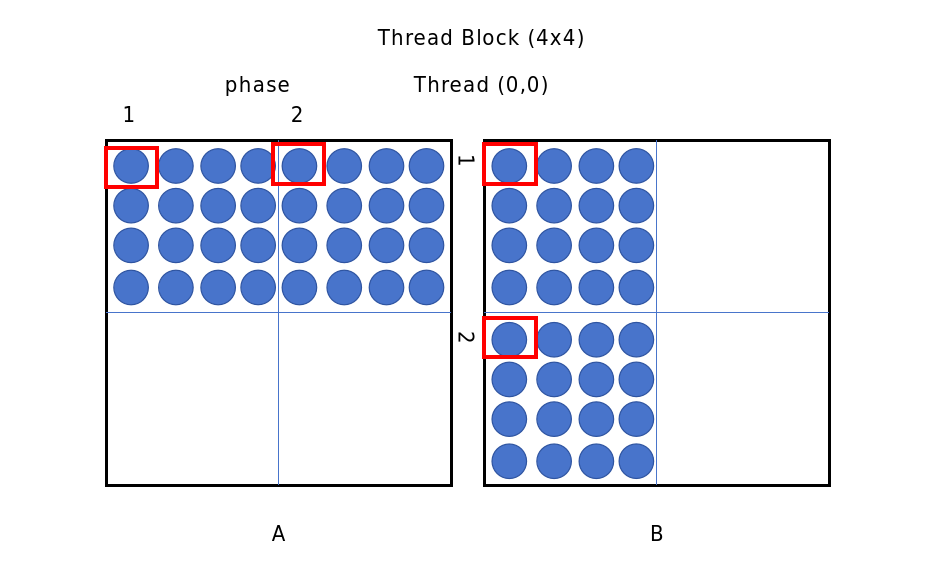
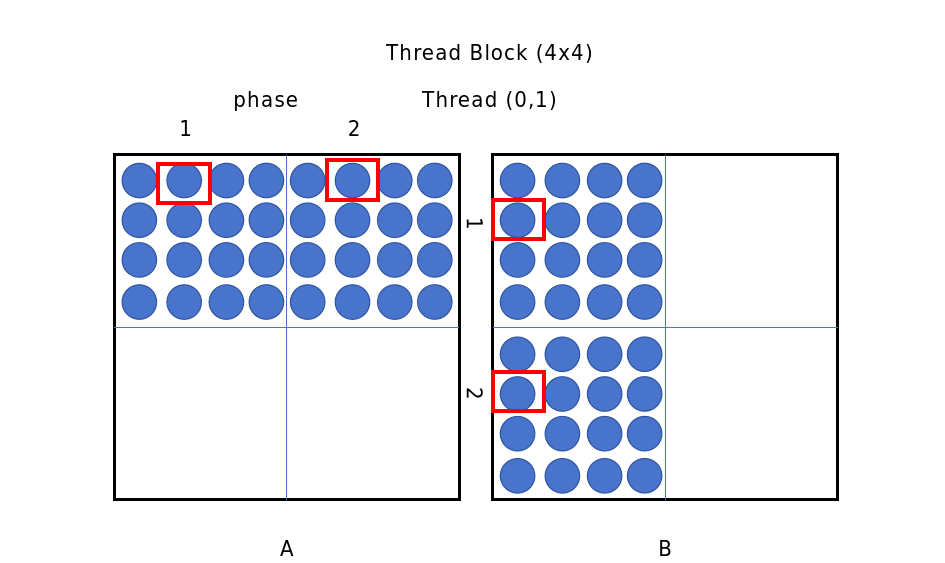
将矩阵分块后,可以分阶段计算,每个阶段:
- 加载 A 的一个 tile(大小 BLOCK × BLOCK)到共享内存,同一个线程块内所有线程共享该内存
- 加载 B 的一个 tile(大小 BLOCK × BLOCK)到共享内存,同一个线程块内所有线程共享该内存
- 使用这两个 tile 进行局部累加
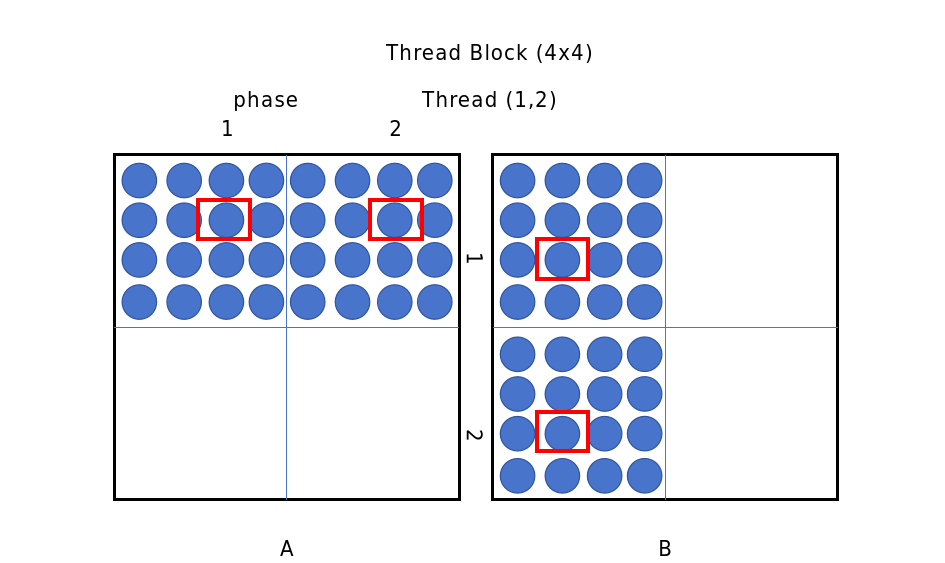
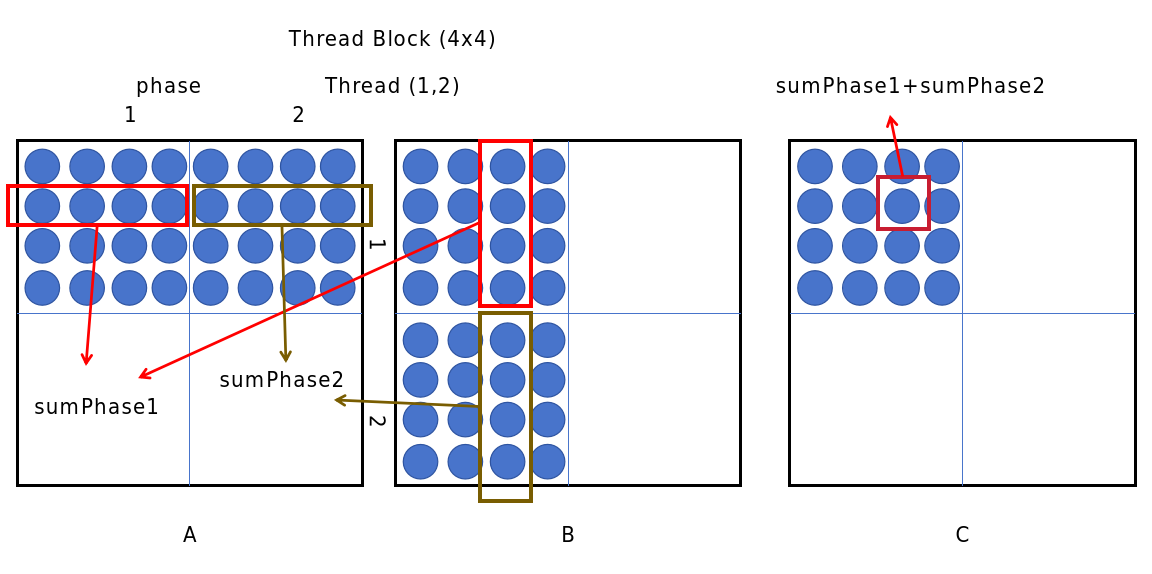
cpp
// 分块大小(通常 16 或 32)
// M:矩阵 A 的行数,也是矩阵 C 的行数。
// K:矩阵 A 的列数,也是矩阵 B 的行数。(这是"内维度",即需要求和的长度)
// N:矩阵 B 的列数,也是矩阵 C 的列数。
// A B C 展平后的一维数组
#define BLOCK_SIZE 16
__global__ void matrixMulTiled(float* A, float* B, float* C,
int M, int N, int K) {
// 线程索引
int row = blockIdx.y * BLOCK_SIZE + threadIdx.y;
int col = blockIdx.x * BLOCK_SIZE + threadIdx.x;
// 共享内存:每个线程块加载一个 tile
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
float sum = 0.0f;
// 分块循环
int numPhases = K / BLOCK_SIZE; // 总阶段数
for (int phase = 0; phase < numPhases; phase++) {
// 1. 协作加载 A 的 tile 到共享内存
int aRow = row;
int aCol = phase * BLOCK_SIZE + threadIdx.x;
As[threadIdx.y][threadIdx.x] = A[aRow * K + aCol];
// 2. 协作加载 B 的 tile 到共享内存
int bRow = phase * BLOCK_SIZE + threadIdx.y;
int bCol = col;
Bs[threadIdx.y][threadIdx.x] = B[bRow * N + bCol];
__syncthreads(); // 确保整个 tile 加载完成
// __syncthreads() 是一个同步屏障(barrier),它保证同一线程块内的所有线程都执行到该位置后,才允许任何线程继续执行。
// 3. 计算该阶段的局部点积
for (int k = 0; k < BLOCK_SIZE; k++) {
sum += As[threadIdx.y][k] * Bs[k][threadIdx.x];
}
__syncthreads(); // 确保在下一轮加载前用完共享内存
}
// 写回结果
if (row < M && col < N) {
C[row * N + col] = sum;
}
}现在我们来计算一下分块版的全局内存访问次数:
- 每个块需要加载BLOCK_SIZEBLOCK_SIZE个A的元素和BLOCK_SIZEBLOCK_SIZE个B的元素
- 总共有(M/BLOCK_SIZE)*(N/BLOCK_SIZE)个块
- 每个块需要循环(K/BLOCK_SIZE)次
- 总计:2 * (M/BLOCK_SIZE) * (N/BLOCK_SIZE) * (K/BLOCK_SIZE) * BLOCK_SIZE * BLOCK_SIZE = 2 * M * N * K / BLOCK_SIZE 次
对于BLOCK_SIZE=32,全局内存访问次数减少到了原来的1/32!这就是共享内存分块的威力。
3.3 分块大小的选择
分块大小对性能有很大影响,选择合适的分块大小需要考虑以下几个因素:
- 共享内存容量:每个SM的共享内存容量有限,分块太大可能导致每个SM只能运行很少的线程块
- 寄存器使用:分块太大也会增加每个线程的寄存器使用量,导致寄存器溢出
- warp对齐:分块大小应该是32的倍数,这样才能保证warp的高效执行
经验值:32x32是最常用的分块大小,在大多数GPU上都能取得很好的性能。对于一些新的GPU,64x64或128x128的分块可能会有更好的性能,但需要更多的共享内存。
四、Bank Conflict深度解析:共享内存的隐形杀手
虽然共享内存的速度非常快,但如果使用不当,会产生Bank Conflict(存储体冲突),导致访问性能急剧下降。Bank Conflict是共享内存优化中最容易被忽视但影响最大的问题。
4.1 什么是Bank?
为了实现高带宽,共享内存被划分为多个独立的内存块,称为Bank(存储体)。每个Bank可以同时独立地进行读写操作。
从Fermi架构开始,所有NVIDIA GPU的共享内存都被划分为32个Bank ,正好对应一个warp的32个线程。每个Bank的宽度是4字节(32位)。
共享内存的地址按照以下方式映射到Bank:
Bank编号 = 地址 / 4 % 32也就是说,连续的4字节地址会映射到连续的Bank,每32个4字节地址就会循环一次。
4.2 什么是Bank Conflict?
当一个warp中的多个线程同时访问同一个Bank的不同地址时,就会产生Bank Conflict。
因为每个Bank同一时间只能处理一个访问请求,所以当多个线程访问同一个Bank时,这些访问会被串行化,导致访问延迟增加。冲突的线程数越多,性能下降越严重。
理想情况 :一个warp的32个线程访问32个不同的Bank,没有冲突,只需要1个时钟周期就能完成访问。
最坏情况:一个warp的32个线程都访问同一个Bank,产生32-way冲突,需要32个时钟周期才能完成访问。
4.3 常见的Bank Conflict类型及示例
我们通过具体的代码示例来讲解各种常见的Bank Conflict类型。假设我们有一个共享内存数组__shared__ float s_data[32][32],一个warp的32个线程访问这个数组。
1. 完全无冲突(最佳情况)
cpp
// 线程tx访问s_data[ty][tx]
float val = s_data[ty][tx];- 访问模式:每个线程访问不同的列
- Bank映射:线程0访问Bank 0,线程1访问Bank 1,...,线程31访问Bank 31
- 冲突情况:无冲突
- 访问延迟:1个周期
2. 2-way冲突
cpp
// 线程tx访问s_data[ty][tx * 2]
float val = s_data[ty][tx * 2];- 访问模式:步长为2的访问
- Bank映射:线程0→Bank0,线程1→Bank2,...,线程15→Bank30,线程16→Bank0,线程17→Bank2,...
- 冲突情况:每个Bank有2个线程访问,2-way冲突
- 访问延迟:2个周期
3. 4-way冲突
cpp
// 线程tx访问s_data[ty][tx * 4]
float val = s_data[ty][tx * 4];- 访问模式:步长为4的访问
- Bank映射:每个Bank有4个线程访问
- 冲突情况:4-way冲突
- 访问延迟:4个周期
4. 广播访问(特殊的无冲突情况)
cpp
// 所有线程访问同一个地址
float val = s_data[ty][0];- 访问模式:所有线程访问同一个地址
- Bank映射:所有线程都访问Bank 0
- 冲突情况:无冲突!
- 访问延迟:1个周期
重要说明 :当多个线程访问同一个Bank的同一个地址时,不会产生Bank Conflict。GPU硬件支持广播机制,可以将同一个地址的数据同时发送给所有请求的线程。
5. 错位访问
cpp
// 线程tx访问s_data[ty][tx + 1]
float val = s_data[ty][tx + 1];- 访问模式:连续但错位1个元素
- Bank映射:线程0→Bank1,线程1→Bank2,...,线程31→Bank0
- 冲突情况:无冲突
- 访问延迟:1个周期
这是一个非常容易被误解的情况。很多人认为错位访问会产生冲突,但实际上,只要每个线程访问不同的Bank,无论地址是否连续,都不会产生冲突。
4.4 Bank Conflict的解决方法
最常用也是最有效的解决Bank Conflict的方法是填充(Padding)。通过在共享内存数组的每一行末尾添加一个额外的元素,改变地址到Bank的映射,从而避免冲突。
Padding :如果你声明 shared float tile1616,在声明时把宽度增加 1(比如 tile1617)。这就强制让每行数据的起始地址偏移,避免行末和下一行开头的地址映射到同一个 Bank,从而避免冲突。
我们以步长为2的访问为例,看看如何通过填充解决冲突:
cpp
// 有冲突的版本
__shared__ float s_data[32][32];
float val = s_data[ty][tx * 2]; // 2-way冲突
// 无冲突的版本(添加1个元素的填充)
__shared__ float s_data[32][33]; // 每一行多了1个元素
float val = s_data[ty][tx * 2]; // 无冲突为什么添加一个填充元素就能解决冲突?我们来计算一下新的Bank映射:
- 原来的Bank映射:
Bank = (ty * 32 + tx * 2) / 4 % 32 = (8 * ty + tx / 2) % 32 - 新的Bank映射:
Bank = (ty * 33 + tx * 2) / 4 % 32 = (8 * ty + ty/4 + tx/2) % 32
添加了填充后,每一行的起始Bank都会偏移1个位置,这样步长为2的访问就不会再映射到同一个Bank了。
通用填充公式:对于大小为N x N的共享内存数组,添加1个元素的填充(N x (N+1))可以解决大多数常见的Bank Conflict。
4.5 矩阵乘法中的Bank Conflict及解决
回到我们之前的分块矩阵乘法例子,你可能已经注意到了,在计算阶段有一个访问会产生Bank Conflict:
cpp
for (int k = 0; k < BLOCK_SIZE; k++) {
sum += s_A[ty][k] * s_B[k][tx];
}其中s_B[k][tx]的访问是完全无冲突的,因为每个线程访问不同的列。但是s_A[ty][k]的访问呢?
对于s_A[ty][k],同一个warp的32个线程(不同的ty)访问同一列k的不同行。这意味着所有32个线程都访问同一个Bank!因为同一列的所有元素都映射到同一个Bank。
这会产生32-way的Bank Conflict,导致性能下降32倍!这是分块矩阵乘法中最严重的性能问题。
解决方法:对共享内存数组A进行填充:
cpp
// 原来的声明
__shared__ float s_A[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float s_B[BLOCK_SIZE][BLOCK_SIZE];
// 填充后的声明
__shared__ float s_A[BLOCK_SIZE][BLOCK_SIZE + 1]; // 添加1个元素的填充
__shared__ float s_B[BLOCK_SIZE][BLOCK_SIZE];添加填充后,同一列的元素会映射到不同的Bank,完全消除了Bank Conflict。这个简单的修改可以让矩阵乘法的性能提升几倍!
五、高级共享内存优化技巧
5.1 数据预取
数据预取是指在计算当前块的同时,提前加载下一个块的数据到共享内存,从而隐藏内存访问延迟。
cpp
__global__ void matrixMulPrefetch(const float* A, const float* B, float* C, int M, int N, int K) {
__shared__ float s_A[2][BLOCK_SIZE][BLOCK_SIZE + 1];
__shared__ float s_B[2][BLOCK_SIZE][BLOCK_SIZE];
int tx = threadIdx.x;
int ty = threadIdx.y;
int row = blockIdx.y * BLOCK_SIZE + ty;
int col = blockIdx.x * BLOCK_SIZE + tx;
// 预加载第一个块
if (row < M && tx < K) {
s_A[0][ty][tx] = A[row * K + tx];
} else {
s_A[0][ty][tx] = 0.0f;
}
if (ty < K && col < N) {
s_B[0][ty][tx] = B[ty * N + col];
} else {
s_B[0][ty][tx] = 0.0f;
}
__syncthreads();
float sum = 0.0f;
int current = 0;
int next = 1;
for (int t = 0; t < (K + BLOCK_SIZE - 1) / BLOCK_SIZE; t++) {
// 预加载下一个块
if (t + 1 < (K + BLOCK_SIZE - 1) / BLOCK_SIZE) {
if (row < M && (t + 1) * BLOCK_SIZE + tx < K) {
s_A[next][ty][tx] = A[row * K + (t + 1) * BLOCK_SIZE + tx];
} else {
s_A[next][ty][tx] = 0.0f;
}
if ((t + 1) * BLOCK_SIZE + ty < K && col < N) {
s_B[next][ty][tx] = B[((t + 1) * BLOCK_SIZE + ty) * N + col];
} else {
s_B[next][ty][tx] = 0.0f;
}
}
// 计算当前块
for (int k = 0; k < BLOCK_SIZE; k++) {
sum += s_A[current][ty][k] * s_B[current][k][tx];
}
__syncthreads();
// 交换当前和下一个块
current ^= 1;
next ^= 1;
}
if (row < M && col < N) {
C[row * N + col] = sum;
}
}5.2 双缓冲技术
双缓冲技术是数据预取的一种特殊形式,使用两个共享内存缓冲区,一个用于计算,另一个用于加载数据,从而完全隐藏内存访问延迟。
六、最佳实践与常见误区
6.1 访存优化优先级
- 首先保证全局内存合并访问:这是所有优化的基础,没有合并访问,其他优化都是徒劳
- 使用共享内存减少全局内存访问次数:对于有数据复用的算法,分块是必须的
- 消除共享内存的Bank Conflict:这是共享内存优化的最后一步,也是最容易被忽视的一步
6.2 常见误区
- 认为只要使用了共享内存就一定能提高性能:如果使用不当,比如产生了严重的Bank Conflict,共享内存的性能可能还不如全局内存
- 分块越大越好:分块太大会导致共享内存不足或寄存器溢出,反而降低性能
- 所有的错位访问都会产生Bank Conflict:只有当多个线程访问同一个Bank的不同地址时才会产生冲突
- 忽略边界检查:在分块算法中,边界检查是必须的,否则会访问越界内存
6.3 性能分析工具
- nvprof:NVIDIA官方的性能分析工具,可以查看全局内存带宽利用率、Bank Conflict次数等关键指标
- Nsight Compute:新一代的GPU性能分析工具,提供更详细的硬件级性能数据
- cuda-memcheck:内存错误检查工具,可以帮助发现非法内存访问和越界错误
七、总结
访存优化是CUDA编程中最核心也最有挑战性的部分。本文详细讲解了:
- 全局内存合并访问的原理和优化方法,这是所有CUDA优化的基础
- 共享内存的分块思想,以矩阵乘法为例展示了如何通过数据复用减少全局内存访问
- Bank Conflict的产生原理、常见类型和解决方法,这是共享内存优化的关键
- 高级共享内存优化技巧,如数据预取和双缓冲
掌握了这些技术,你就能够编写出高效的CUDA程序,充分发挥GPU的计算能力。在下一篇文章中,我们将继续深入CUDA的高级特性,讲解CUDA流和异步编程,这是实现计算与数据传输重叠、进一步提高性能的关键。