| 字段 | 值 |
|---|---|
| title | California Housing 可复现回归实验:随机森林预测加州房价 |
| slug | california-housing-random-forest-regression |
| summary | 基于 California Housing 数据集,使用随机森林回归模型预测加州各县房价中位数,完整记录数据探索、建模过程、误差分析与特征重要性解读。 |
| description | 本文基于 scikit-learn California Housing 数据集,使用随机森林回归模型预测房价中位数,涵盖数据探索、模型训练、误差评估与特征解释,提供完整可复现代码与实验输出。 |
| coverImage | assets/actual_vs_predicted.png |
本项目由 星枢 支持
星枢官网:https://claudeaihub.cloud/技术交流 秋秋:1097156200

California Housing 可复现回归实验:随机森林预测加州房价
做完分类项目之后,很自然想试试回归。分类是判断"是或不是",回归是预测"具体是多少"。这次用经典的 California Housing 数据集,训练一个随机森林回归模型来预测加州各地区的房价中位数。
项目已开源:
text
https://github.com/coderWang404/xingshuProjects/tree/main/2026-06-06-california-housing-regression核心结论先放前面:
- 数据规模:20,640 条记录,8 个特征
- 模型:RandomForestRegressor
- R²:0.7930(能解释约 79% 的房价方差)
- RMSE:0.5208(约 $52,083)
- 最强特征 :
MedInc(地区收入中位数)
1. 数据集长什么样
California Housing 是 scikit-learn 内置的经典数据集,记录了加州 20,640 个地区(census block group)的 8 项指标:
| 特征 | 含义 |
|---|---|
| MedInc | 地区收入中位数(万美元) |
| HouseAge | 房龄中位数 |
| AvgRooms | 每户平均房间数 |
| AvgBedrms | 每户平均卧室数 |
| Population | 地区人口 |
| AvgOccup | 每户平均居住人数 |
| Latitude | 纬度 |
| Longitude | 经度 |
目标值是 MedHouseVal,即该地区房价中位数,单位是 $100,000。也就是说,目标值 2.0 代表房价中位数 20 万美元。
我扫了一眼数据分布,target 的均值是 2.07,标准差 1.15。换算成美元,加州这批地区的房价中位数大约是 20.7 万美元,但差异很大------最低的不到 1.5 万,最高的超过 50 万。
2. 环境准备
依赖和上一个项目一样,四个包:
text
pandas
numpy
scikit-learn
matplotlib
bash
git clone https://github.com/coderWang404/xingshuProjects.git
cd xingshuProjects/2026-06-06-california-housing-regression
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt3. 运行实验
bash
python experiments/california-housing/run_experiment.py脚本会自动从 sklearn 加载数据,训练模型,输出所有图表和指标到 outputs/ 目录。
4. 为什么用随机森林做回归
树模型做回归有一个天然优势:它不需要假设特征和目标之间是线性关系。房价和收入之间可能是非线性的------收入高到一定程度,房价增长会放缓;或者地理位置的影响也不是简单的加减关系。
具体参数:
python
model = RandomForestRegressor(
n_estimators=300,
max_depth=12,
min_samples_leaf=3,
random_state=42,
n_jobs=-1,
)300 棵树对于 2 万条数据来说完全够用。深度限制在 12 是为了防止过拟合------California Housing 只有 8 个特征,如果让树无限生长,它会记住训练数据里的噪声,而不是学到真正的规律。min_samples_leaf=3 也是一个保险:要求每个叶子节点至少有 3 个样本,避免模型对极端值过于敏感。
5. 结果分析:R² = 0.793 意味着什么
测试集 4,128 条记录,核心指标:
| 指标 | 数值 | 解释 |
|---|---|---|
| MSE | 0.27126 | 均方误差 |
| RMSE | 0.52083 | 约 $52,083 |
| MAE | 0.34322 | 约 $34,322 |
| R² | 0.79299 | 解释 79.3% 方差 |
R² = 0.793 的意思是:模型能解释房价变异的约 79%,剩下的 21% 由数据中没有包含的因素决定------比如学区质量、房屋装修水平、距离商圈的远近、海景/山景等。
RMSE 0.52 意味着预测值和真实值平均偏差约 5.2 万美元。MAE 0.34 意味着平均绝对偏差约 3.4 万美元。这两个数字差得不少(0.52 vs 0.34),说明误差分布是不对称的------有一些极端误差拉高了 RMSE,但大多数样本的误差在 3.4 万左右。
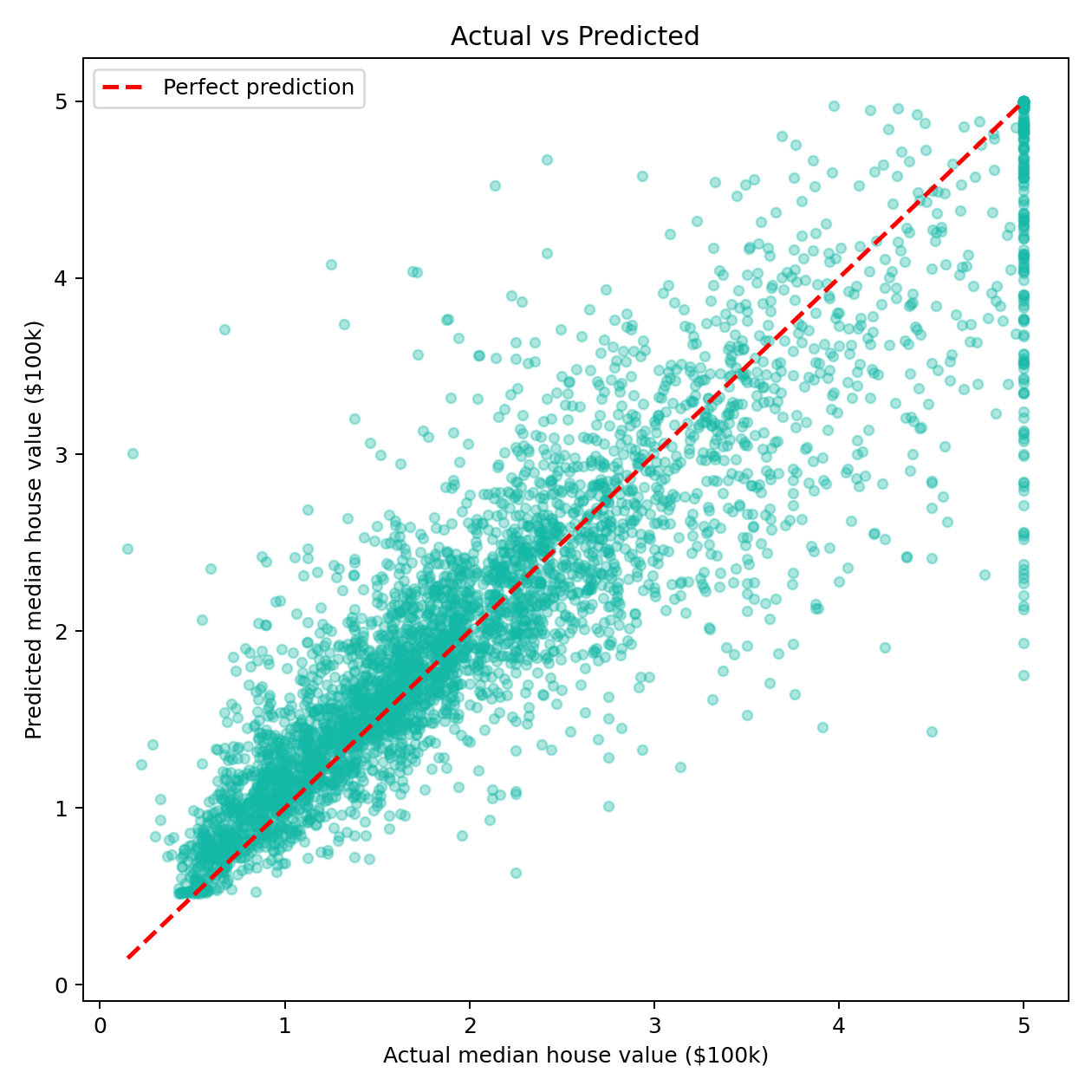
从 Actual vs Predicted 散点图能看出几个规律:
- 低价房区域(左下角)点非常密集,模型预测也比较准。
- 随着房价升高,点的散布明显变大------高价房的预测误差更大。这和数据分布一致:高价房样本少,模型学得不充分。
- 最上方有几个点明显偏离对角线,这些是模型"看走眼"的极端案例。
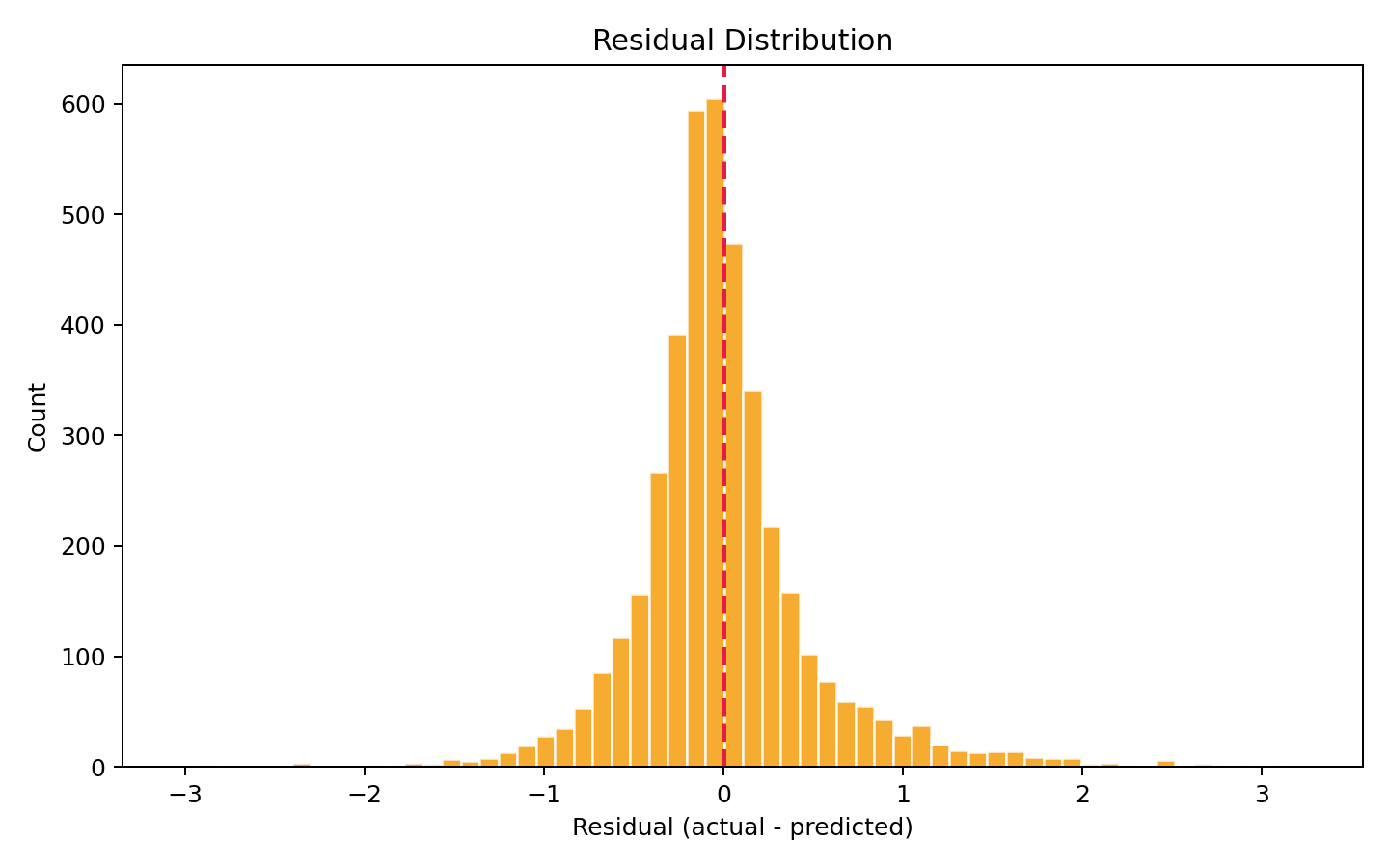
残差分布基本以 0 为中心,近似正态分布,说明模型没有明显的系统性偏差。但右侧有一个长尾------存在少量正残差很大的样本,即模型低估了这些地区的房价。这可能就是那些"好学区+好地段"但数据里没有体现出来的房子。
6. 特征重要性:收入是碾压级的王者
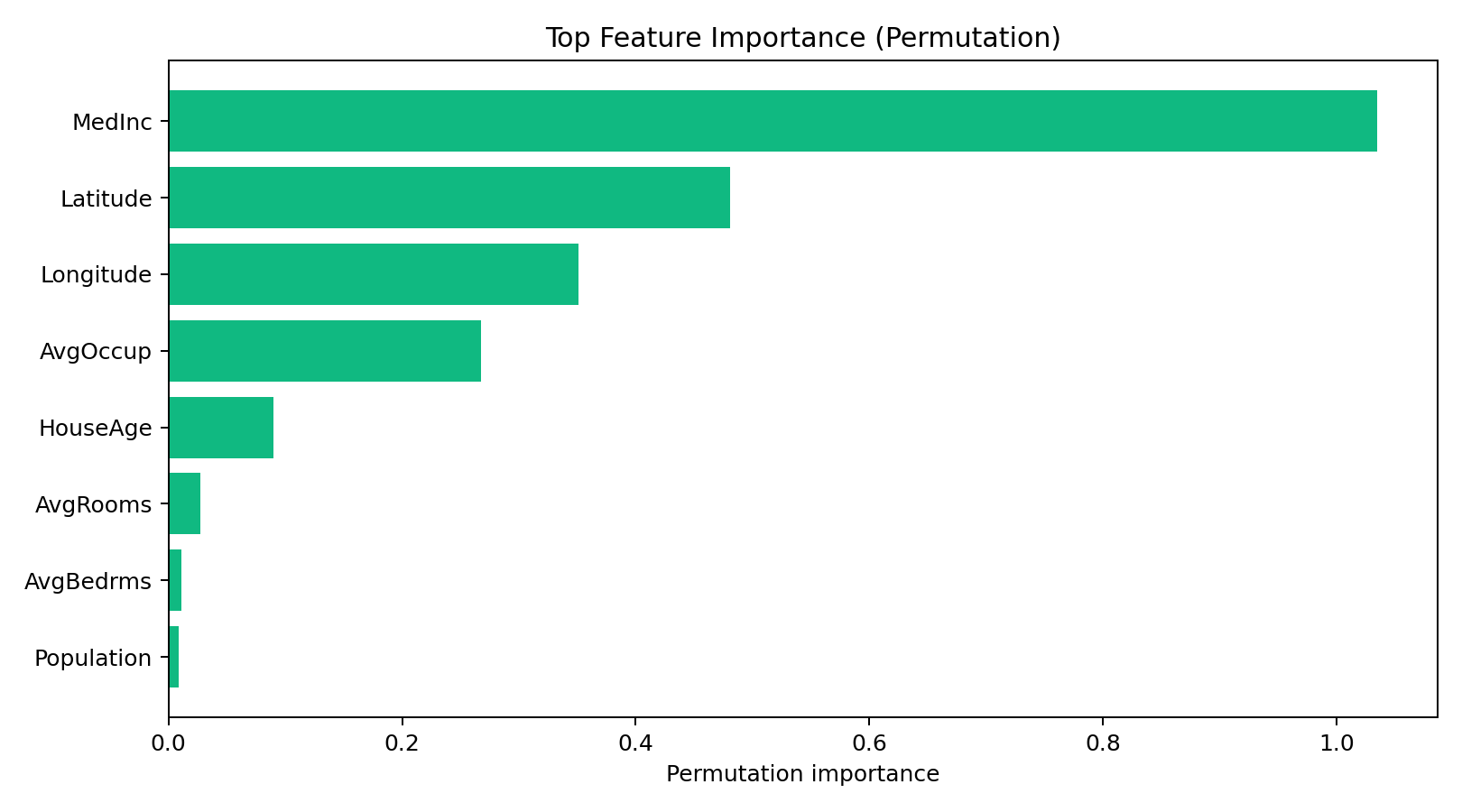
Permutation Importance 排名:
| 排名 | 特征 | 重要性 | 标准差 |
|---|---|---|---|
| 1 | MedInc | 1.03488 | 0.01976 |
| 2 | Latitude | 0.48061 | 0.00817 |
| 3 | Longitude | 0.35107 | 0.00637 |
| 4 | AvgOccup | 0.26749 | 0.00740 |
| 5 | HouseAge | 0.08981 | 0.00487 |
| 6 | AvgRooms | 0.02725 | 0.00197 |
| 7 | AvgBedrms | 0.01111 | 0.00184 |
| 8 | Population | 0.00879 | 0.00114 |
MedInc(收入中位数)的重要性是 1.03,是第二名 Latitude(0.48)的 2 倍多。而且这个结果极其稳定------标准差只有 0.02,意味着换不同的测试集,MedInc 永远是第一。
这个结果完全符合直觉,也符合经济学常识:一个地区的收入水平,是决定房价的最核心因素。不是房龄,不是房间数,而是住在这里的人赚多少钱。
但后面几个特征的排名更有意思:
Latitude + Longitude 排第二、第三(合计重要性约 0.83)。这说明在加州,地理位置是硬通货。北纬 37 度附近的湾区(San Francisco、San Jose)房价明显高于内陆地区。模型不需要知道"这是硅谷",它只需要知道纬度和经度,就能大致判断房价水平。
AvgOccup(平均居住人数)排第四(0.27),这有点反直觉。直觉上"住的人多"应该和房价无关,甚至正相关才对。但数据里 AvgOccup 和房价是负相关的------居住人数多的地区,往往是多户合租或住房条件较差的社区,房价反而更低。
AvgRooms(平均房间数)只有 0.027,几乎可以忽略。这似乎违反常识------大房子不应该更贵吗?但注意这是"每户平均房间数",它跟 AvgOccup 高度相关(住的人多,房间数通常也多)。随机森林已经通过 AvgOccup 捕捉了这部分信息,所以 AvgRooms 的独立贡献很小。这也解释了为什么 AvgBedrms(卧室数)和 Population(人口)的重要性几乎可以忽略------它们的信息已经被更强的特征覆盖了。
7. 这个模型能用来买房吗
坦率说,不能直接用来买房。
RMSE 约 5.2 万美元,对于 20 万美元级别的房子来说,误差比例约 25%。如果你拿这个模型去估价,一套真实价值 20 万的房子,模型可能报 15-25 万------这个区间太宽了,无法指导具体交易。
但这个模型非常适合做初步的市场分析:
- 快速筛选"明显被低估"或"明显被高估"的区域
- 理解不同因素对房价的相对影响
- 作为更复杂模型的 baseline(比如加入学区、交通、POI 数据后,R² 应该能进一步上升)
8. 实验输出
运行脚本后 experiments/california-housing/outputs/ 会生成:
text
metrics.json # 完整指标 JSON
regression_report.txt # 回归报告
dataset_profile.csv # 数据统计
feature_importance.csv # 全部特征重要性
actual_vs_predicted.png # 预测 vs 真实值散点图
residual_distribution.png # 残差分布图
feature_importance.png # 特征重要性图
summary.md # 实验摘要所有输出都是自动生成的,随机种子固定为 42,结果完全一致。
9. 总结
这个实验的核心收获:
- 收入是房价的绝对主导因素,重要性是地理位置的 2 倍以上。
- 地理位置(经纬度)是第二硬通货,在加州这种沿海经济带尤其明显。
- 房间数、卧室数、人口数量对房价的独立预测力很弱,它们的信息已经被收入水平和居住密度覆盖了。
- R² = 0.793 是一个不错的 baseline,但要用于实际估价还差得远------需要更多特征和更复杂的模型。
如果你想拿它当学习模板,建议试试这几个改动:
- 把
max_depth从 12 改成 20,观察过拟合迹象(训练 R² 会上升,测试 R² 可能下降) - 加入特征交叉(比如 MedInc × Latitude),看 R² 能不能提升
- 换成 GradientBoostingRegressor 或 XGBoost,对比不同树模型的表现
本项目由 星枢 支持
星枢官网:https://claudeaihub.cloud/
技术交流 秋秋:1097156200
