
本文涉及主要函数包括,使用详情可查看具体章节:
一、基本概念
NDVI(归一化植被指数 Normalized Difference Vegetation Index),是一种通过遥感数据量化植被覆盖与生长状态的常用指标,应用于遥感影像,反映农作物长势和营养信息。
其计算公式为NDVI = (NIR - Red) / (NIR + Red)。
- NIR:近红外波段的反射率,健康植被在此波段的反射率较高。
- Red:红光波段的反射率,健康植被在此波段的反射率较低。数值范围:−1∼+1
| NDVI 取值 | 地表含义 |
|---|---|
| −1∼0 | 水体、冰雪、裸岩、建筑(无植被) |
| ≈0 | 裸土、稀疏荒地 |
| 0.2∼0.5 | 稀疏草地、农田、低矮灌木 |
| 0.5∼0.8 | 茂密森林、长势旺盛植被 |
二、场景背景
对武汉行政区范围内的 Landsat8 遥感影像数据进行处理,计算 NDVI 植被指数,并将植被覆盖分为三个等级:
- 低覆盖:NDVI < 0.2
- 中覆盖:0.2 ≤ NDVI < 0.5
- 高覆盖:NDVI ≥ 0.5
最终统计各区不同植被覆盖等级的面积,为生态环境评估和保护规划提供数据支撑。
三、数据准备
1. 常用数据:
- MODIS (如 MOD13Q1):时间分辨率高(16 天),适合大范围长时序分析。
- Landsat8/9 (OLI):空间分辨率 30 米,适合中等尺度细节分析。
- Sentinel-2 (MSI):空间分辨率 10-20 米,重访周期短(5 天),适合精细农业或森林监测。
注意:植被监测对云非常敏感,建议将云量限制在 10% 以下,甚至 5% 以内,确保影像有效。
2. Landsat8数据下载处理
本文使用数据为 Landsat8,选取其中 Band 4(红)、Band 5(近红外)两个波段。
数据来源地理空间数据云 L2 级别数据,空间范围覆盖武汉地区,时间尺度为2025年的数据,包括三景数据,经过坐标转换、镶嵌、合并、掩膜提取等处理,得到武汉市 Landsat8 的 B4,B5 波段数据,然后再合并为多波段数据,具体过程本节不做详细介绍,需要数据可以留言。
处理后的数据如图所示:
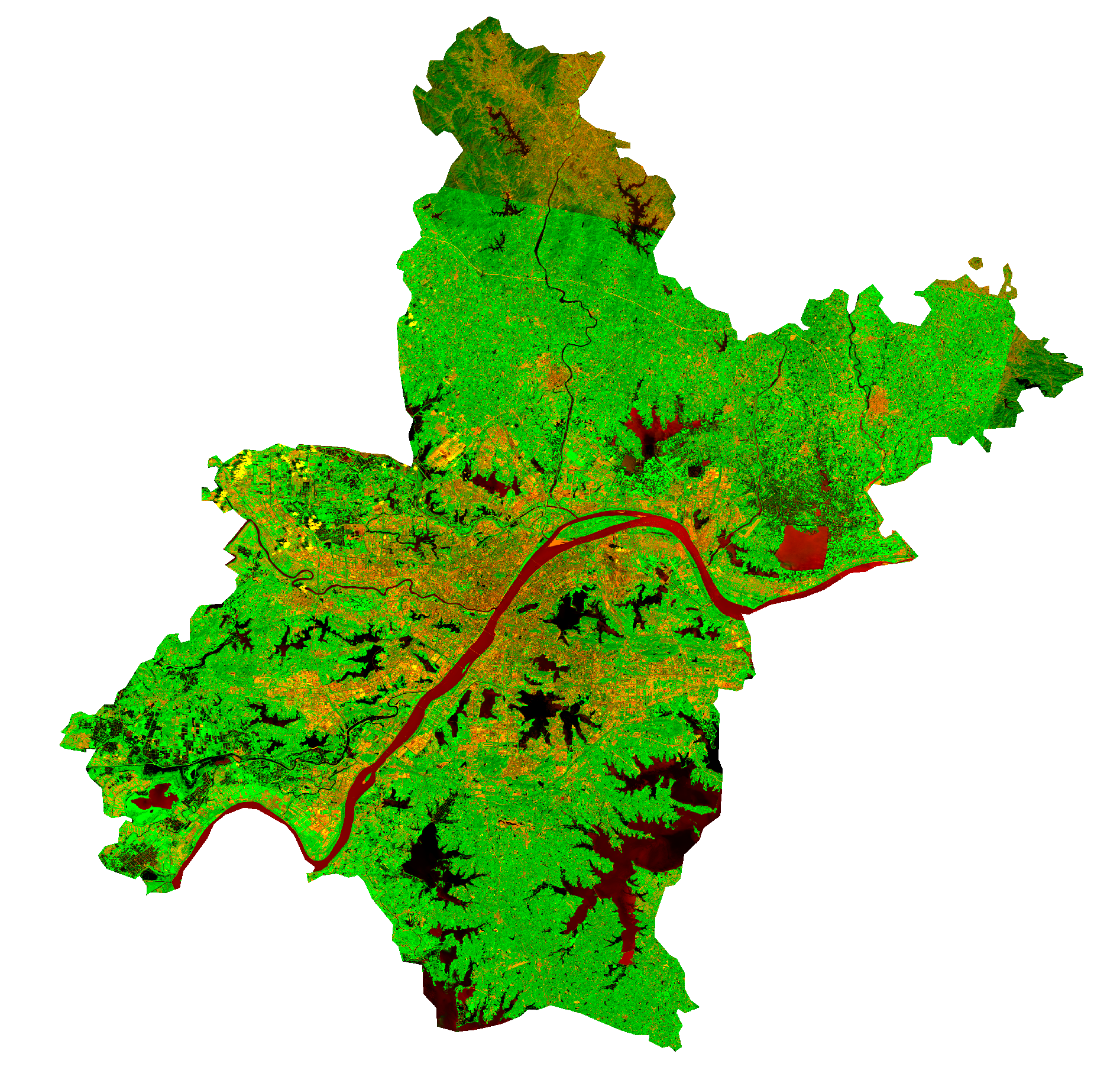
导入数据库:
bash
raster2pgsql -s 4326 -I -C -M -t 512x512 wuhan_landsat8_b45.tif public.wuhan_landsat8_b45 | psql -d gisdata导入数据后的表:wuhan_landsat8_b45
| 字段名 | 类型 | 说明 |
|---|---|---|
| rid | integer | 影像 ID (512x512 切片) |
| rast | raster | 栅格切片(波段 1=B4,波段 2=B5) |
查看元数据信息:
sql
select
(ST_MetaData(rast)).*
from
public.wuhan_landsat8_b45
where
rid = 1 --选取一个切片
-- 返回结果:
Name |Value |
----------+-------------------+
upperleftx|114.1471106333912 |
upperlefty|31.36259281420371 |
width |512 |
height |512 |
scalex |0.0002922537488873 |
scaley |-0.0002922537488873|
skewx |0.0 |
skewy |0.0 |
srid |4326 |
numbands |2 |3. 行政区划数据
本文行政区数据来自从天地图下载标的准行政区地图, 审图号GS(2024)0650号
执行命令导入数据库:
shell
shp2pgsql -s 4326 /opt/wuhan/wuhan_districts.shp wuhan_districts | psql -h localhost -p 5432 -U postgres -d gisdata导入后的表:wuhan_districts
| 字段名 | 类型 | 说明 |
|---|---|---|
| gid | serial4 | 区县 ID |
| name | varchar | 区名称 |
| gb | varchar | 区代码 |
| geom | geometry | 区边界多边形 |
四、处理步骤与 SQL 代码
步骤 1:计算 NDVI 指数
sql
-- 计算NDVI,并存在wuhan_ndvi表中
create table wuhan_ndvi AS
select
rid,
ST_SetBandNoDataValue(
ST_MapAlgebra(
rast, 1, -- B4(红)
rast, 2, -- B5(近红外)
-- L2数据核心:除以10000转换为真实反射率 + NDVI公式
'(([rast2.val]/10000.0 - [rast1.val]/10000.0) / NULLIF([rast2.val]/10000.0 + [rast1.val]/10000.0, 0))::float',
'32BF' -- 32位浮点,保证精度
),
0
) AS ndvi_rast
from wuhan_landsat8_b45;
-- 统计信息,验证 NDVI 数值是否在标准范围 -1 ~ 1 内:
select
(ST_SummaryStats(ST_Union(ndvi_rast))).* AS avg_ndvi
from wuhan_ndvi;
-- 返回结果:
Name |Value |
------+--------------------+
count |9451823 |
sum |2263389.4665057836 |
mean |0.23946591747494464 |
stddev|0.15803264609365525 |
min |-0.28179025650024414|
max |0.6725857853889465 |步骤 2:NDVI 分级(植被覆盖等级)
sql
create table vegetation_grade AS
select ST_MapAlgebra(
ndvi_rast,
'8BUI', -- 输出8位无符号整数(1=低,2=中,3=高)
'CASE
WHEN [rast] < 0.2 THEN 1
WHEN [rast] >= 0.2 AND [rast] < 0.5 THEN 2
WHEN [rast] >= 0.5 THEN 3
ELSE 0
END',
0 -- NODATA值设为0
) as grade_rast
from wuhan_ndvi;
-- 统计信息
select
(ST_SummaryStats(ST_Union(grade_rast))).* AS avg_ndvi
from vegetation_grade;
-- 返回结果:
Name |Value |
------+------------------+
count |9451823 |
sum |15404309 |
mean |1.6297712092154075|
stddev|0.5029906828659698|
min |1.0 |
max |3.0 |
-- 像素值频数统计,记得先合并
select
(ST_ValueCount((ST_Union(grade_rast)),array[1,2,3])).* AS avg_ndvi
from vegetation_grade;
-- 返回结果:
value|count |
-----+-------+
1.0|3593100|
2.0|5764960|
3.0| 93763|步骤 3:按区统计各等级植被面积
sql
SELECT
d.name AS district_name,
-- 低覆盖面积(等级1)这里计算乘以1.0转换为浮点数
SUM(CASE WHEN pixel_val = 1 THEN 1 ELSE 0 END) * 30 * 30 * 1.0/ 1000000 AS low_cover_km2,
-- 中覆盖面积(等级2)
SUM(CASE WHEN pixel_val = 2 THEN 1 ELSE 0 END) * 30 * 30 * 1.0 / 1000000 AS mid_cover_km2,
-- 高覆盖面积(等级3)
SUM(CASE WHEN pixel_val = 3 THEN 1 ELSE 0 END) * 30 * 30 * 1.0 / 1000000 AS high_cover_km2
FROM wuhan_districts d
JOIN (
SELECT -- 这里使用ST_PixelAsPolygons,计算每一个像素,可以参考以前的介绍
(ST_PixelAsPolygons(grade_rast)).geom AS pixel_geom,
(ST_PixelAsPolygons(grade_rast)).val AS pixel_val
FROM vegetation_grade
) v ON ST_Intersects(d.geom, v.pixel_geom)
GROUP BY d.name
ORDER BY high_cover_km2 DESC;
-- 返回结果:
name|low_cover_km2 |mid_cover_km2 |high_cover_km2|
-------+--------------+--------------+----------------+
蔡甸区 |396.10170| 665.41950| 23.81400|
新洲区 |449.22960| 998.56350| 22.13730|
江夏区 |707.46570|1273.15260| 11.19870|
汉南区 |114.30270| 165.09060| 8.28360|
黄陂区 |794.77650|1436.70240| 8.02260|
东西湖区 |220.54140| 257.26140| 6.12540|
洪山区 |262.54800| 251.11440| 3.49830|
汉阳区 | 71.51760| 41.66280|0.704700000|
武昌区 | 71.28630| 24.32700|0.424800000|
青山区 | 56.14470| 33.52590|0.318600000|
江岸区 | 51.99750| 29.32740|0.012600000|
硚口区 | 28.51020| 12.28950|0.004500000|
江汉区 | 22.81320| 7.13700|0.003600000|五、案例结果分析
- NDVI 计算:成功生成全武汉市 NDVI 栅格,数值范围在 - 1 到 1 之间,符合植被指数的物理意义;
- 植被分级:将 NDVI 栅格转换为 3 级植被覆盖栅格,直观展示植被分布情况;
- 面积统计:得到武汉市各区不同等级植被的覆盖面积,其中高覆盖面积
- 最大的区为 蔡甸区 23.814 km²,
- 第二是 新洲区22.137 km²,
- 第三的是 江夏区11.198 km²,分析结果可为生态环境评估和保护规划提供了数据支撑。