
AI 视频的进化速度突飞猛进。是否想过有一天能真正走进这些由 AI 生成的世界里,亲自感受一下?
像这样,在月球上自由漫步,是什么感觉?它们是真的理解了世界,还是仅仅在模仿视频?目前的模型距离这个目标还有多远?
为了彻底搞清这个问题,美团 LongCat 团队提出了 WBench,它是首个面向交互式视频世界模型的系统性多轮评测基准。它就像一台"CT扫描仪",能精准定位当前世界模型在从"被动观看"到"主动交互"的过程中,到底卡在了哪里。
我们用 WBench 对 20 个前沿模型(包括 Kling 3.0、HY-World 1.5、Genie 3 等)进行了全面"扫描",最核心的发现可以总结为以下几点:
- 不存在全能模型: 不同模型各有专长,文本驱动模型更擅长理解场景,而专用世界模型在交互控制上突出。
- 导航是一项独立的技能: 模型的视频画质好坏,和它的导航控制能力基本没关系。
- 多轮交互是核心难点: 所有模型在连续交互后表现都会变差,导航能力尤其严重,平均分下降了整整 33 点。
- 开源模型表现出色: 在一些特定能力上,开源模型甚至超过了闭源模型,比如 HY-World 1.5 的导航能力在所有模型里突出。
01 WBench 是如何测出这些问题的?
能得出这些结论,得益于 WBench 的核心设计。我们认为,一个强大的世界模型评测框架,应包含四大核心要素:
世界模型评测框架 = 世界定义 (World Definition) + 指令集 (Instruction Set) + 统一交互接口 (Unified Interaction Interface) + 评测套件 (Evaluation Suite)。
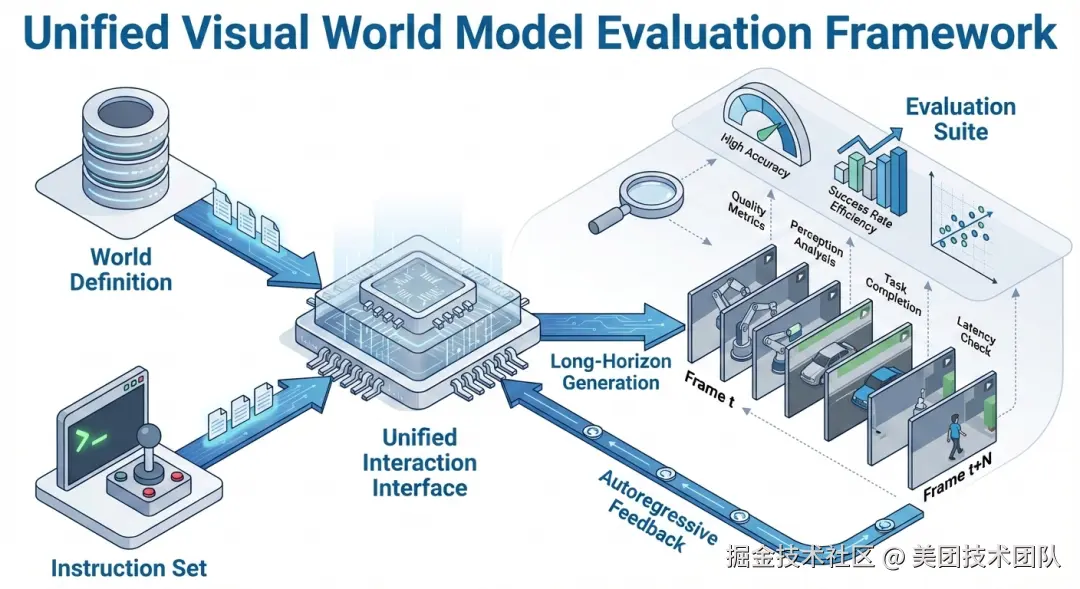
WBench 正是基于这一理念构建的,下图完整展示了它的设计蓝图:
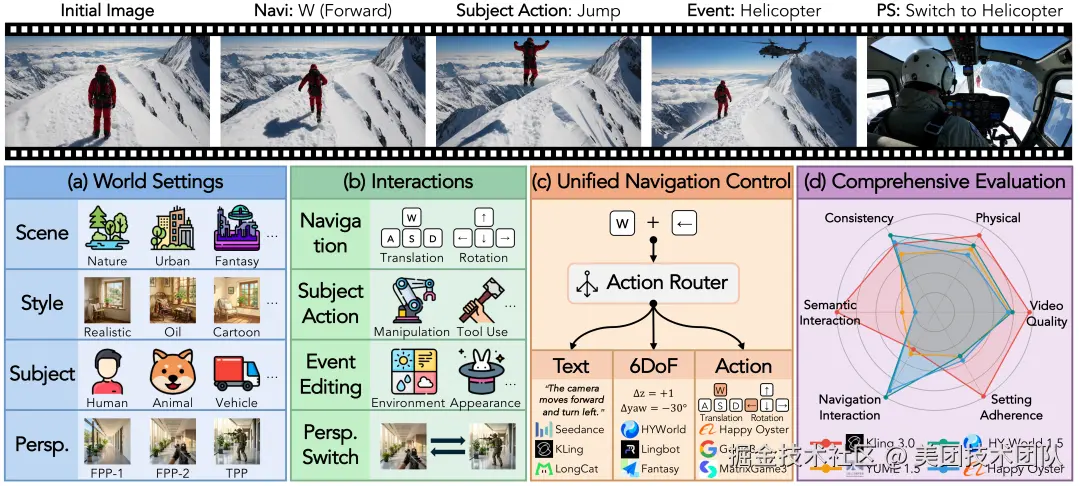
1.1 全面多样的"测试用例"
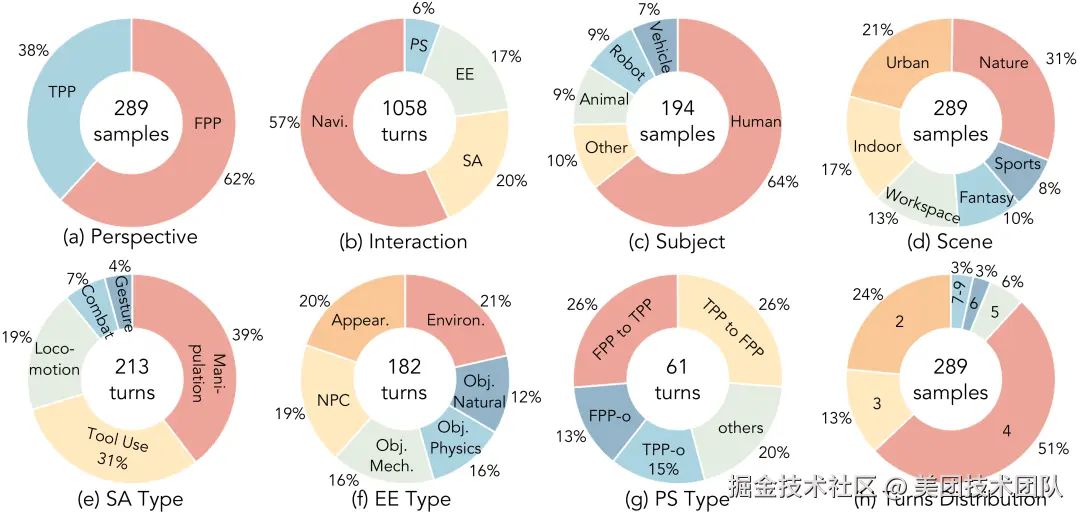
WBench 包含 289 个测试案例 和 1058 个交互轮次,覆盖了丰富的世界定义和指令集。
你可以让 AI 在充满未来感的城市中穿梭,也可以让它置身于一幅流动的油画里。

你不仅可以选择成为游戏中的主角,以第三人称视角掌控一切;还可以化身第一人称,身临其境地探索世界。


1.2 交互方式:在舞台上设计丰富的"剧本"
有了舞台,还需要丰富的"剧本"。WBench 设计了导航、主体动作、事件编辑和视角切换这四种核心交互方式,它们可以像搭积木一样自由组合,形成一个复杂的多轮任务。
比如,除了常规的移动(导航),你还可以让角色完成特定动作(主体动作)。
甚至改变整个环境(事件编辑)。
最酷的是,你还可以在不同视角间无缝切换(视角切换),比如从第一人称视角瞬间切换到第三人称视角。
通过这种"舞台"与"剧本"分离的设计,WBench 实现了对视频质量、设定遵循度、交互遵循度、一致性、物理真实性 这五个维度的精准测量。我们为每个指标都设计了严谨的计算方法,更多关于 NavScore、Gated Spatial Consistency 等硬核指标的实现细节,欢迎访问我们的项目主页。
02 核心洞察:用数据看清模型的"短板"
WBench 不仅给出了结论,更用数据揭示了这些问题的根源。从具体模型表现来看,普通用户最关心的"谁最强"这个问题,答案是"看情况"。
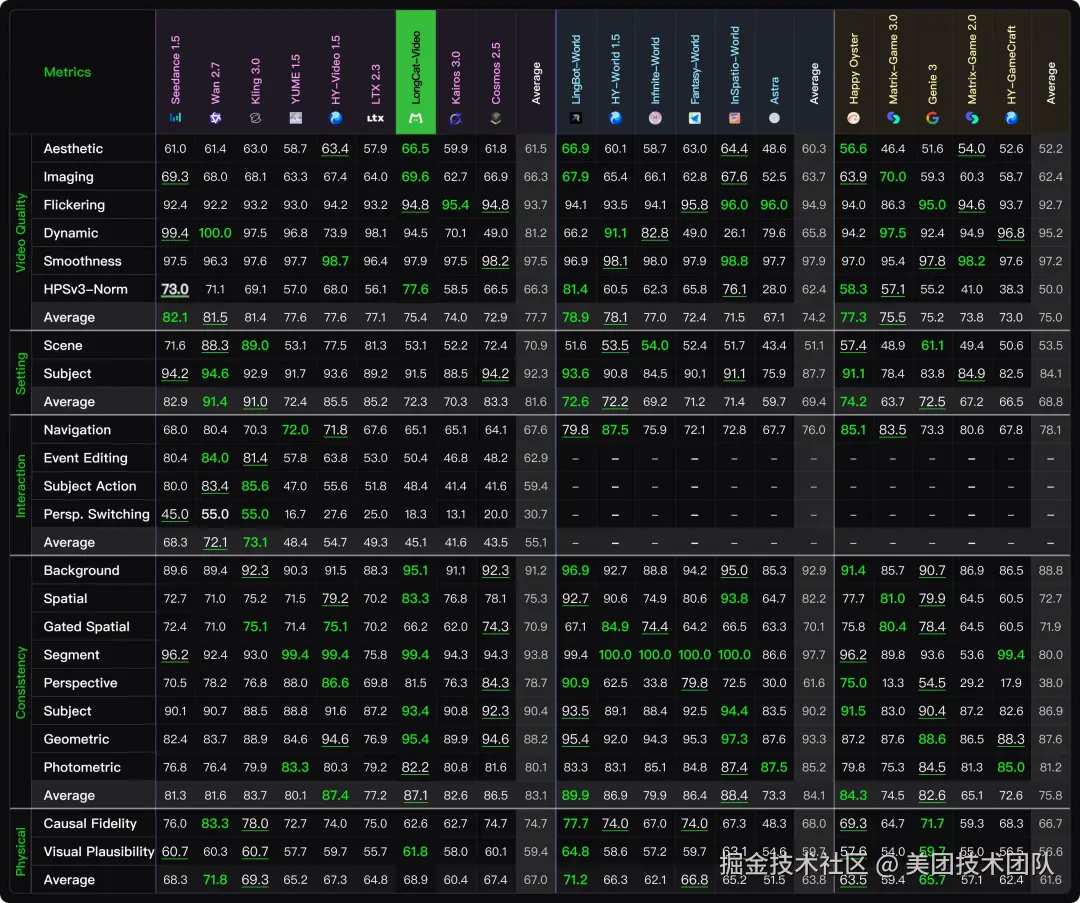
- 如果你追求模型能精准理解你的想法: 那么 Kling 3.0 和 Wan 2.7 无疑是第一梯队。它们在设定遵循度和主体动作/事件编辑上表现突出。
- 如果你想要丝滑的运镜和精准的导航控制: 那么专用的世界模型优势明显。HY-World 1.5 和 Genie 3 在这一项上遥遥领先,远超文本驱动模型。
- 在保持一致性上: LingBot-World 表现较为突出,是所有模型里最"稳"的。
- 在物理真实性方面: Wan 2.7 表现最佳,尤其在因果关系上理解得更深刻。
- 所有模型都面临一个共同的难题: 视角切换,这是所有交互类型中最难的一项,平均分只有 30.7,说明这块技术还远未成熟。
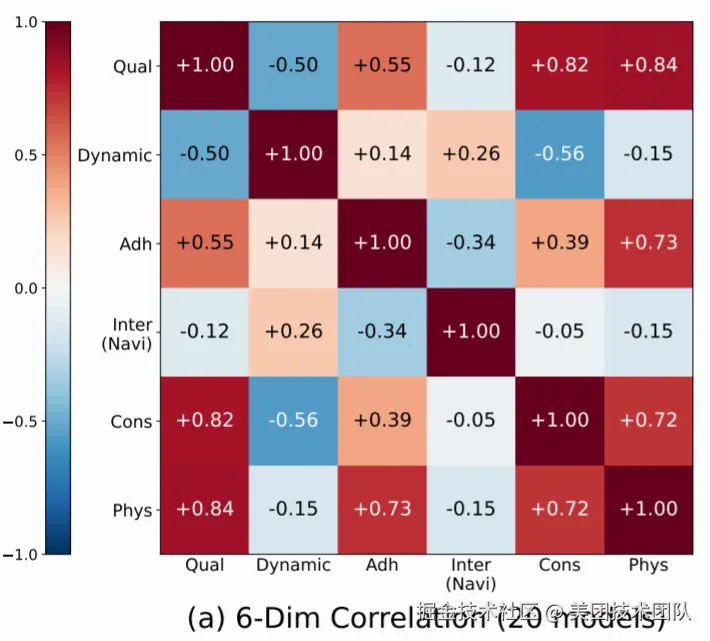
洞察一:导航能力为何与其他维度"脱钩"?
这张相关性矩阵图非常直观。导航那一列/行,与其他所有维度(如视频质量 Qual、一致性 Cons)的相关系数都接近于零。
这说明,当前模型在学习渲染一个好看的世界时,并没有顺便学会如何在其中可控地移动。究其原因,是因为导航能力依赖于一个独立的、专门的"空间状态表示"能力,而其他能力(如画质、语义理解)则更多依赖于模型的通用生成先验。
换句话说,模型"知道"世界长什么样,但并不"理解"自己在世界中的位置和方向。
洞察二:模型在多轮交互中如何"迷路"?
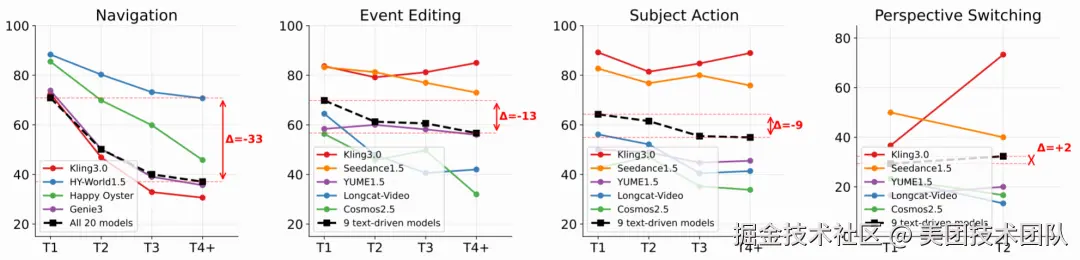
这张图展示了模型在连续交互中的能力衰减情况。导航曲线的"雪崩式"下跌清晰可见,从第一轮到第四轮及以后,分数下降了 33 点。这有力地证明了位姿误差逐轮累积是当前迭代式生成范式的结构性缺陷。
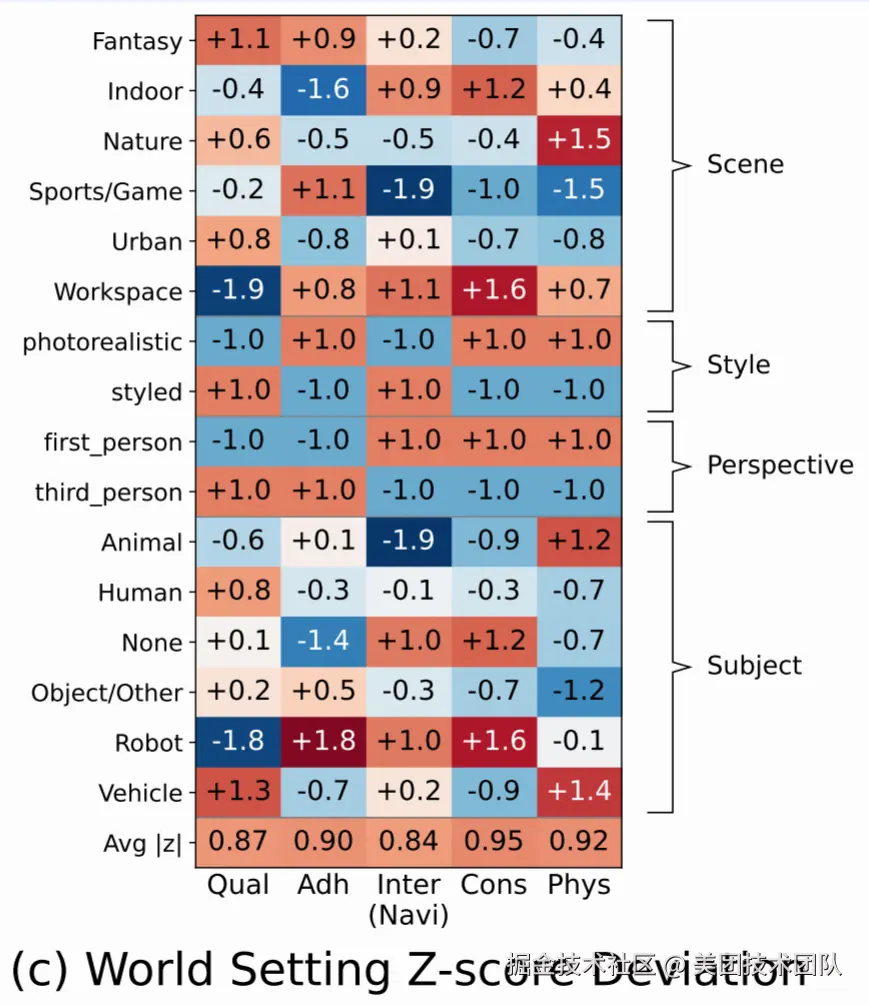
洞察三:并非所有"世界"都生而平等
分析还发现,不同的世界设定会带来结构性的难度差异。例如:第一人称视角让导航更容易(z=+1.0),但保持场景设定更难;动物主体(z=-1.9)因其复杂的动态性,对模型挑战最大。
03 WBench 的价值:定义下一代评测范式
3.1 范式转移:从"被动生成"到"主动交互"
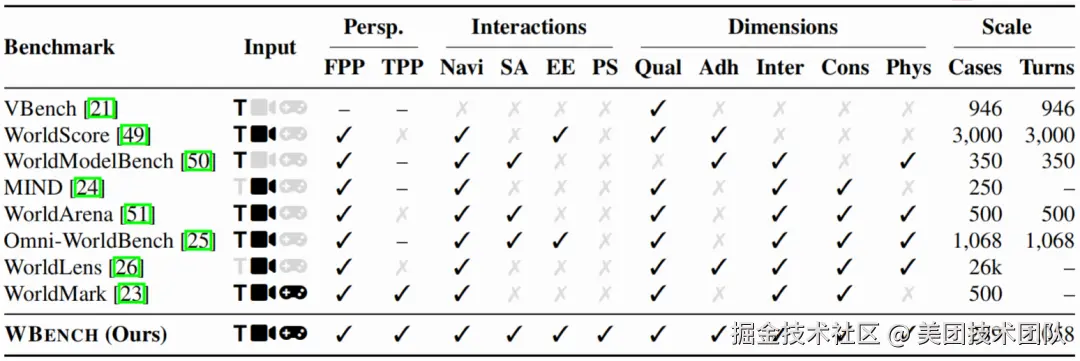
WBench 不仅是一个评测工具,更代表了研究范式的一次重要演进。通过与同类基准的对比可以看出,WBench 是目前唯一一个真正统一的评测基准。
它不仅同时覆盖了开放域、双视角、四种交互类型和多轮闭环评测,更重要的是,它还首次实现了对不同输入范式模型的统一评测。无论模型是接收文本指令、相机位姿,还是离散的键盘按键,WBench 都能通过其统一交互接口进行公平评估。
这打破了不同技术流派之间的壁垒,让所有"选手"都能在同一个"赛场"上竞技。
3.2 可靠性验证:与人类偏好高度对齐
至关重要的是,WBench 的自动评分结果与 400 名人类标注者的偏好判断高度一致(Spearman ρ ≥ 0.94),证明了这把"标尺"的准确性和可靠性。

04 总结与展望
WBench 的提出,算是我们向真正的"交互世界"迈出的一小步尝试。它清晰地揭示了当前技术的边界。我们希望它能成为交互式世界模型走向系统化评测的一个起点,激发更多后续研究,推动世界模型的发展。
WBench 已开源,欢迎所有世界模型来跑分。
- Paper: huggingface.co/papers/2605...
- GitHub: github.com/meituan-lon...
- HomePage: meituan-longcat.github.io/WBench/
- HuggingFace: huggingface.co/datasets/me...
| 关注「美团技术团队」微信公众号(meituantech)或访问:tech.meituan.com/,阅读更多技术干货!

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明"内容转载自美团技术团队"。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。