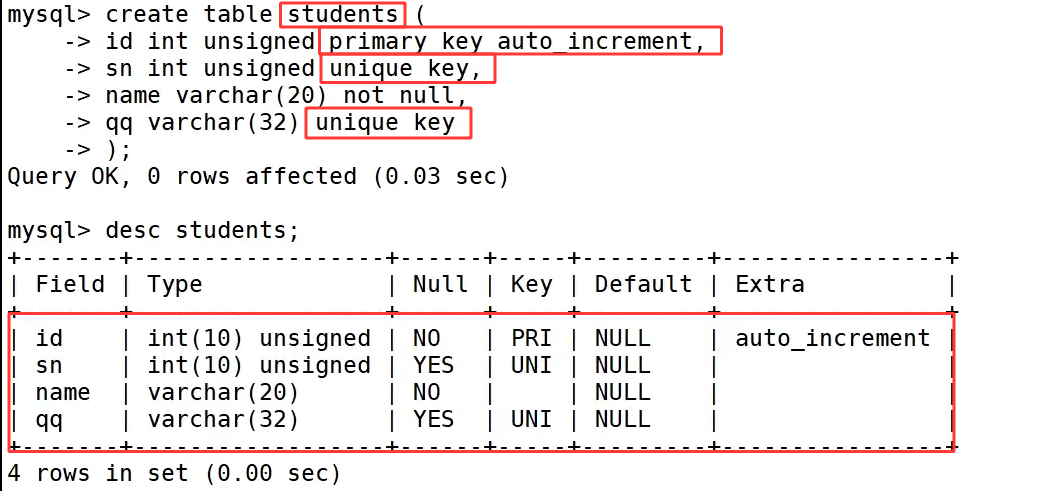
insert 拥有固定标准书写格式 INSERT INTO table_name (col1,col2,...) VALUES (值列表),(值列表)...,其中 INTO 关键字可以省略不写,values 前的字段列表和 values 后的值列表需要在数量、数据顺序、数据类型上一一匹配。
举例:
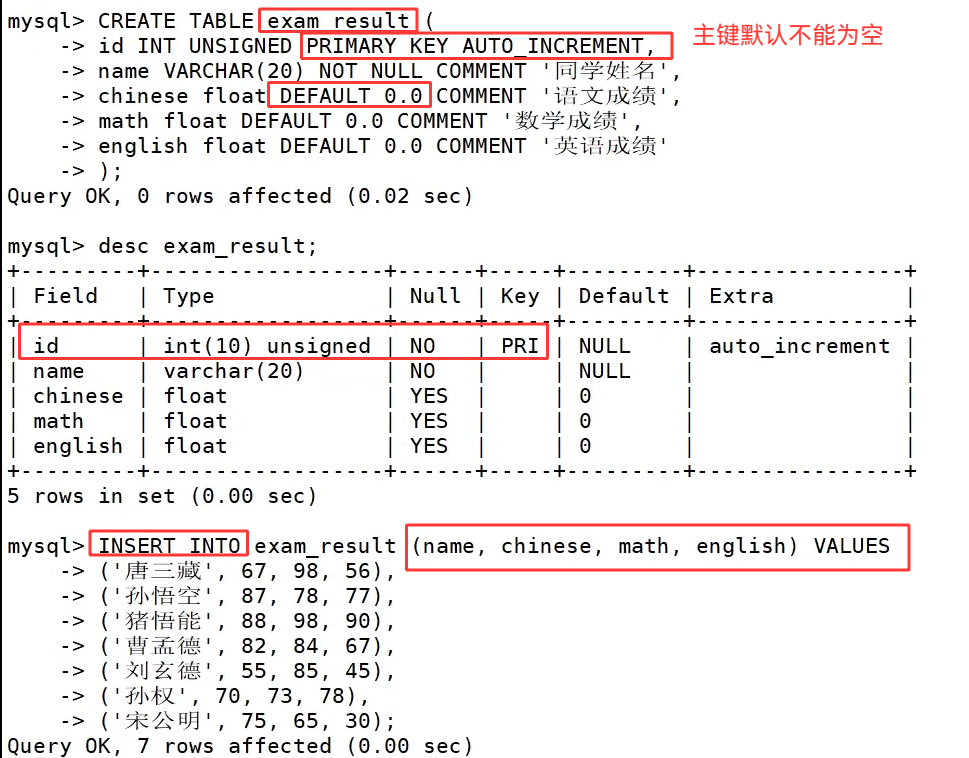
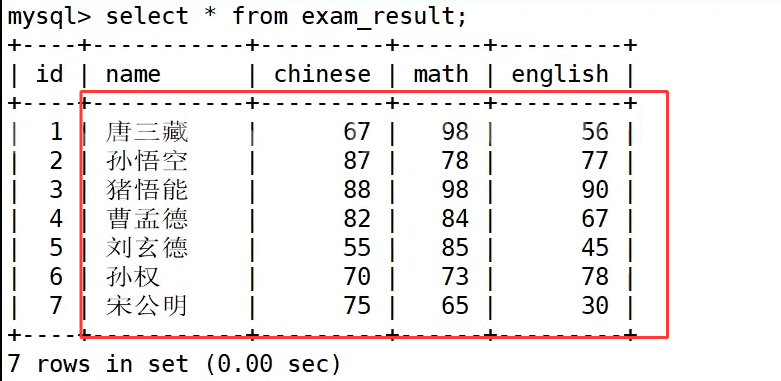
我们创建表 students,表中 id 为自增主键、sn 和 qq 是唯一键、name 字段为非空 not null。
下面进行数据的插入,我们先进行指定列的单行数据插入 :
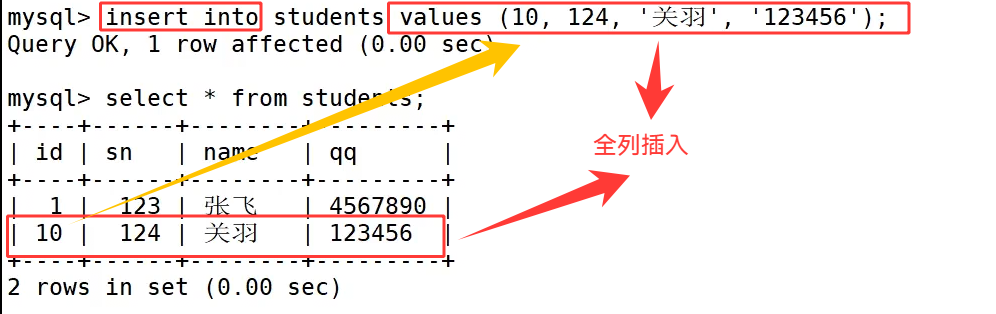
执行 insert into students**(sn,name,qq) values (123,'张飞','4567890')**; 进行指定字段插入,由于明确写明了需要赋值的三个字段,自增 id 不需要手动填写,MySQL 会自动生成主键值完成数据插入,这也是工程开发中比较推荐的插入写法。
当我们省略 values 左侧的字段列表时,就代表 values 右侧的字段值都需要插入,此时就需要按照建表时字段从上到下的定义顺序补齐全部字段的数据,就像 insert into students values (10, 124, '关羽', '123456'); 这条语句,四个字段的数据完整依次填写,任意缺省或者顺序错乱都会触发语法报错。
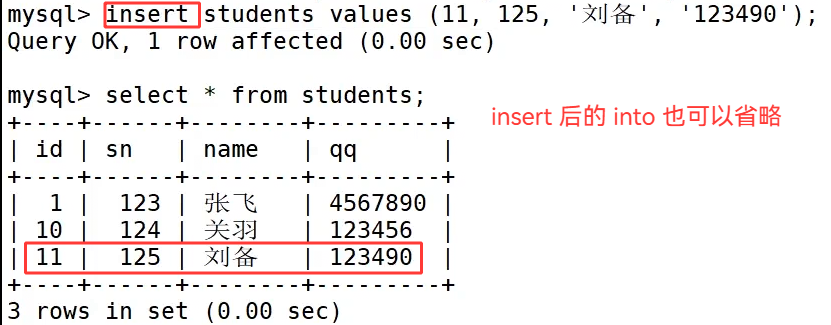
MySQL 也做了语法兼容优化,支持省略 insert 后的 into 关键字,insert students values (11, 125, '刘备', '123490'); 这条简写语句也可以正常执行,但是我们在写时尽量带上 into。
那如果我们一次性想插入多列数据呢?
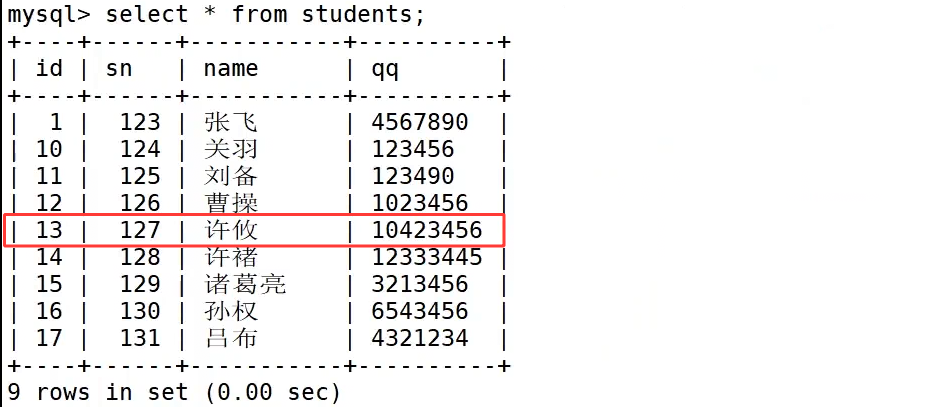
我们可以在一条 insert 语句的 values 后,用英文逗号分隔多组括号数据,就能实现一次性批量插入多条记录,如上图 insert into students values (13, 127, '许攸','10423456'),(14, 128, '许褚','12333445'),(15,129,'诸葛亮','3213456'); 就是全字段批量插入,每组括号完整填写表内全部四个字段的值,执行后数据库一次性新增三条数据,查询数据表能够看到三条记录全部成功入库。同时每一组括号里的数据必须严格按照建表时字段的先后顺序填写字段内容,多组行数据之间依靠逗号隔开,相较于多次单行 insert,批量插入可以减少数据库连接交互开销,大批量导入数据时执行效率更高。
我们也可以在 values 的前面写明指定字段,完成多记录插入,insert into students (sn,name,qq) values (130,'孙权','6543456'),(131,'吕布','4321234'); 这条 SQL 只标注 sn、name、qq 三个字段,自增 id 依旧交由数据库自动生成,执行结束后查询表格,孙权、吕布两条数据自动生成 id 为 16、17,顺利完成数据新增。
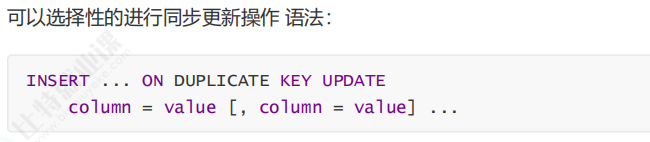
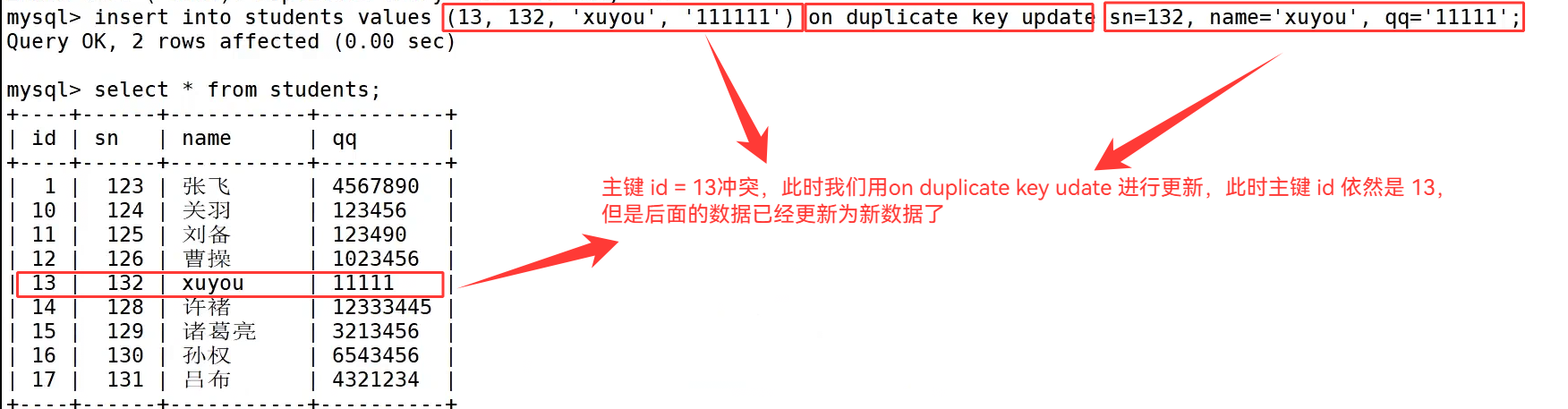
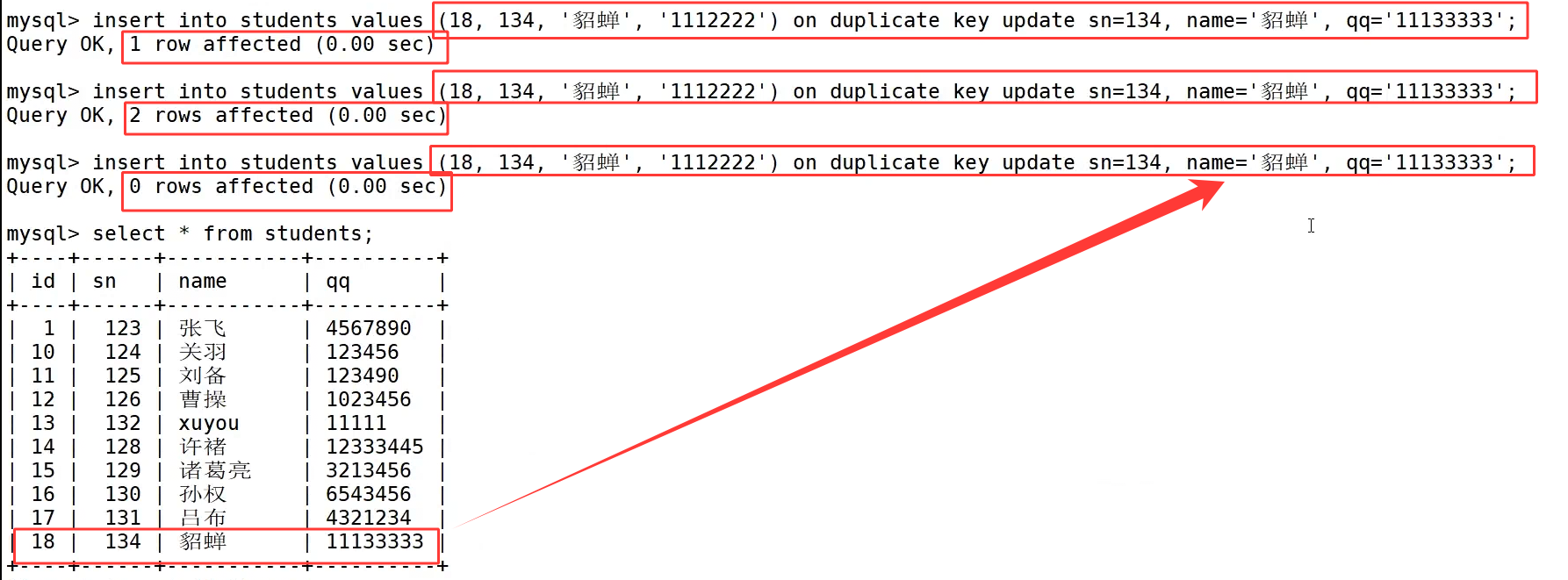
原有数据表中 id=13、sn=127 的记录是许攸的相关数据,我们执行 insert into students values(13,132,'xuyou','111111') on duplicate key update sn=132,name='xuyou',qq='111111';,因为主键 id=13 已经存在触发主键冲突,语句不再插入新行,而是把原记录的 sn、name、qq 更新为我们指定的新内容,主键 id 保持 13 不变,查询数据表能看到该行数据完成更新。
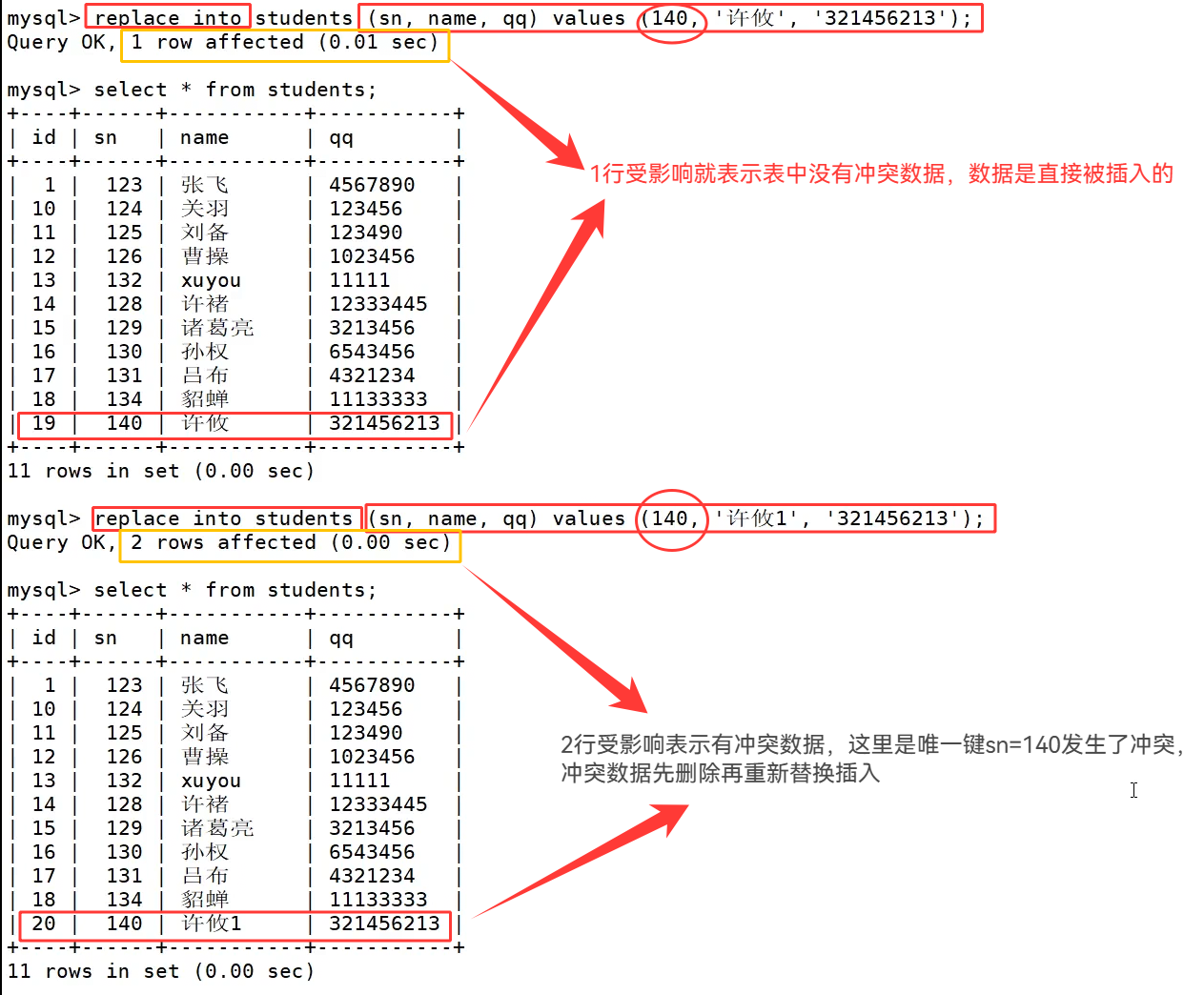
on duplicate key update 是在原有行基础上原地修改字段内容,主键 id 不会变化;而 replace 是删整行再新增,主键 id 会发生改变,后续实际开发时,如果需要保留原主键编号就选用 on duplicate key update,需要彻底替换整行数据就选择 replace。
三、Retrieve
CRUD 中的 R 对应 Retrieve 数据查询,在 MySQL 里核心实现语句就是 select,它是整套 SQL 语法里功能最丰富的指令,能够实现全表数据提取、指定字段筛选、数据去重、条件过滤、结果排序、分页截取等各类数据查询需求,也是日常项目开发中编写频次最高的 SQL。
select
select 可以按照各种条件和各种列进行筛选,查询,去重,排序等。
先看语法:
select 的完整基础语法结构,SELECT DISTINCT {*|字段名列表} FROM 数据表WHERE筛选条件ORDER BY 排序字段LIMIT分页限制,其中 DISTINCT 用来实现查询结果去重,* 代表查询全部字段,FROM 指定需要查询的数据来源表,后续 WHERE、ORDER BY、LIMIT 分别对应条件筛选、排序、分页功能,整串语法从左到右遵循固定的执行顺序。
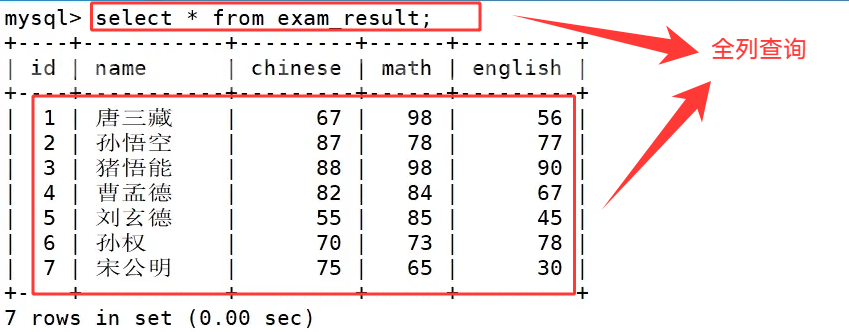
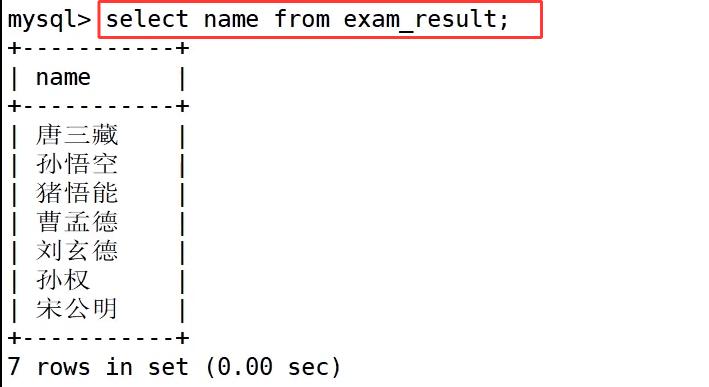
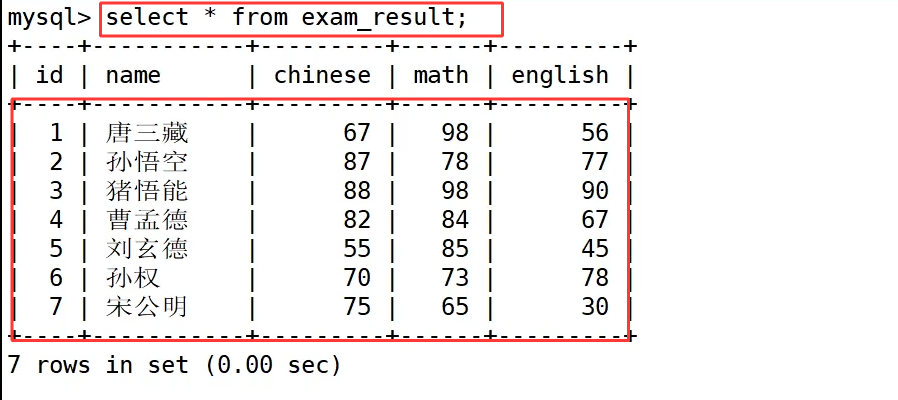
select * from exam_result; 是全字段查询写法,*是通配符,代表匹配数据表中所有列,执行后一次性查出整张表里全部字段与所有行数据,虽然书写简便,但在实际应用中不推荐使用,因为当数据表字段繁多、数据量大时,全字段查询会读取大量无用字段,浪费服务器 IO 与内存资源,仅适合临时调试查看表数据。
指定列查询:
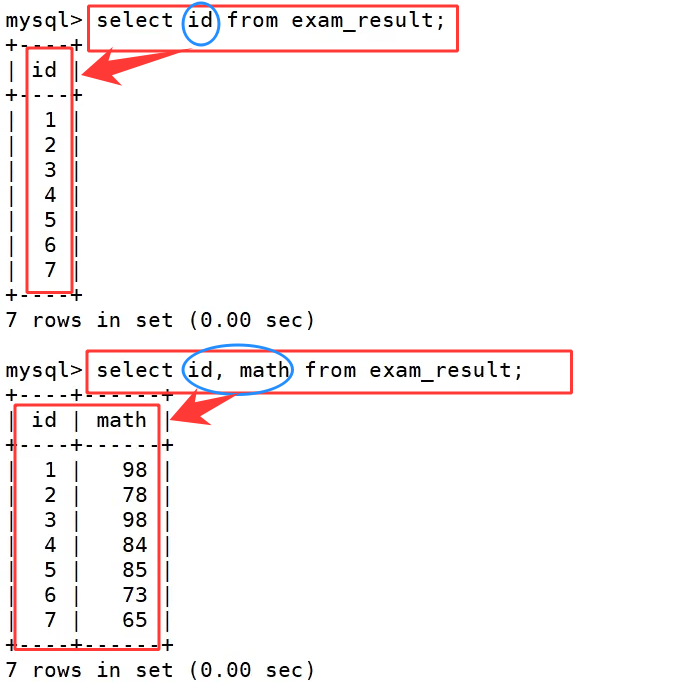
如果我们想要精准获取需要的字段就手动书写字段名,select id from exam_result; 只单独查询 id 一列数据,select id,math from exam_result; 同时查询 id 和数学成绩两列数据,指定字段查询只会读取我们需要的列资源,这是我们比较推荐的线上写法;从底层执行逻辑来说,数据库会先把符合条件的整行原始数据读取出来,再按照我们指定的字段筛选展示对应列内容。
当然 select 后面的查询字段路可以为表达式:
select 关键字后面不局限于填写数据表字段,还能直接书写数学运算表达式,哪怕不加 from 指定数据表也可以执行计算,例如 select 1+1;、select 7*8; 数据库会直接算出运算结果并生成临时结果集,这是 MySQL 独有的便捷写法。同时我们也可以在字段旁搭配固定常量,像 select name,math,10 from exam_result;,查询结果里会额外新增一列、所有行数据固定取值 10。
继续:
我们也可以把表中多个数值字段拼接为算术表达式,依托每行自身字段的值动态运算,select name,math,math+chinese+english from exam_result; 这条语句会自动把每条学生记录的语文、数学、英语三科分数相加,实时算出总分并作为新的查询列展示。未了维护更好的可读性,我们也可以通过 as 为列自定义别名,select name,math,math+chinese+english as totalfrom exam_result; 执行后,原本的公式列名就替换为 total,MySQL 语法中 as 关键字
可以省略不写,直接空格后跟别名同样生效。
继续:
不光运算表达式可以起别名,原生数据表字段也能自定义列名,select name 姓名,math 数学,math+chinese+english 总分 from exam_result;,语句中将 name 改为姓名、math 改为数学、总分作为计算列别名,最终查询表头全部换成中文名称,方便阅读查看数据。
当然 select 也可以搭配 distinct 进行去重:
我们直接查询数学成绩 select math from exam_result; 时,表中存在多条数值相同的分数,结果会原样展示全部重复数据;但在字段前添加 distinct 关键字,写成 select distinct math from exam_result;,数据库会自动合并重复的值,相同分数只保留一条,实现查询结果的去重操作。
where 条件
在实际的业务查询中,绝大多数场景其实并不需要查询全表所有的数据,而是需要依靠指定条件过滤出符合要求的数据,where 子句就是 select 语句里用来实现条件筛选的核心模块,它的作用类似编程语言里的 if 判断,数据库会逐行校验 where 后的条件表达式,条件成立的数据才会被保留到最终查询结果,不带 where 时默认返回整张表全部数据。
我们先来看看常见的比较运算符:
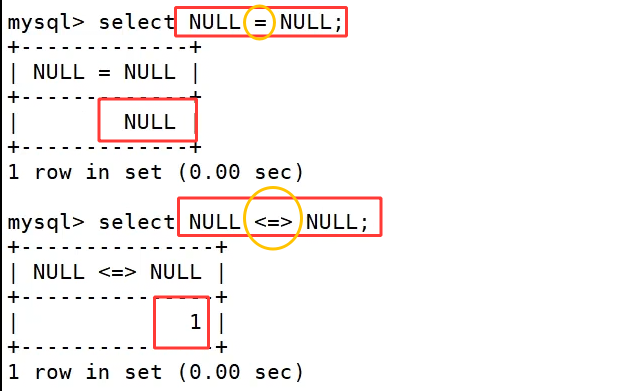
where 筛选依托各类比较运算符完成字段匹配,基础大小符号 >、>=、<、<= 用来做数值大小对比;单等号 = 做等值匹配,但无法判断 NULL,NULL=NULL结果为空不成立,<> 和 != 代表不等于,<> 可以安全处理 NULL 判等;between a0 and a1 用来限定闭区间范围,匹配数值处在 a0,a1 之间的数据;in(数值列表) 匹配字段取值落在括号内任意一项的记录;is null、is not null 专门用来判断字段为空或非空,不能用=去查询 NULL 数据;like实现模糊匹配,% 匹配任意长度字符、_只匹配单个字符。
还有常见的逻辑运算符:
多条件组合筛选需要逻辑运算符串联条件,and 是逻辑与,前后所有条件全部满足,整行数据才会被筛选出来;or 是逻辑或,多个条件里任意一条成立即可命中数据;not 是逻辑取反,原本成立的条件经过 not 修饰后变为不成立,用来反向筛选数据。
下面我们就来举例:
比如我们要筛选英语不及格的同学及英语成绩****( < 60 ):****
我们还是以上面已经建好的表为例,我们以筛选英语成绩小于 60 分的学生为例,先执行无条件语句 select name,english from exam_result;,这条语句会查出全部 7 名学生的姓名与英语成绩,数据没有经过任何过滤;追加 where 条件后写成 select name,english from exam_result where english<60;,数据库逐行判断 english 字段数值,只保留成绩小于 60 的唐三藏、刘玄德、宋公明三条记录,直观体现 where 按条件精准过滤数据的效果。整个查询的执行顺序为先通过 from 锁定目标数据表,再用 where 按条件过滤行数据,最后按照 select 后指定的字段展示结果,where 从源头过滤无效数据,减少不必要的数据读取,提升查询效率。
****继续,比如我们要筛选语文成绩在 80, 90****分的同学及语文成绩:
我们想要筛选语文成绩处在 80 分到 90 分之间的学生,先执行不带条件的 select name, chinese from exam_result;,这条语句会把全部七位学生的姓名与语文成绩全部展示出来,没有任何数据过滤。之后借助 AND 拼接两个大小判断条件,书写 where chinese>=80 and chinese <=90,只有同时满足语文大于等于 80、小于等于 90 两个条件的记录才会被筛选,最终筛选出孙悟空、猪悟能、曹孟德三条数据,AND 的规则就是所有条件必须同时成立才命中数据。
我们也可以用 between ... and ... :
MySQL 提供 between ... and ... 语法简化连续区间的筛选,where chinese between 80 and 90 等价于前面 >=、<= 加 AND 的写法,该语法是闭区间,会包含左右边界 80 和 90,执行后筛选结果和上一条 SQL 一致,在连续数值范围筛选时,使用 between and 代码更加简洁直观。
继续,比如我们要筛选数学成绩是58或者59或者98或者99分的同学及数学成绩:
接下来筛选数学成绩为 58、59、98、99 其中任意分数的学生,我们先不带条件查询展示出全部的数学成绩,然后采用 OR 拼接多个等值条件 where math=58 or math=59 or math=98 or math=99,只要字段满足任意一个等式就会被筛选出来,最终匹配到两条数学 98 分的数据,OR的逻辑是多个条件任意一个成立就会被筛选出来,但备选数值较多时大量拼接 or 语句会冗余繁琐。
所以我们也可以使用 in(....) 替代连续的 OR 写法:
当面对多个零散固定数值的筛选需求时,我们可以用 in(数值列表) 替代连续 OR 写法,where math in (58,59,98,99),字段的值只要落在括号内的集合中就符合筛选规则,执行效果和多条 or 完全一致,代码精简易维护。
继续,比如我们要筛选关于模糊匹配的问题:
比如名字中有姓孙的同学 及 孙某同学这种模糊的需求: 这时我们就是用 like %:
我们想要筛选姓名以 "孙" 开头的所有学生,先执行无条件查询 select name from exam_result; 展示全部姓名数据,然后借助 like '孙%' 完成模糊匹配,其中百分号 % 代表匹配任意长度、任意个数的字符,孙% 含义就是首字符为孙、后面字符不限的名字,执行 select name from exam_result where name like '孙%'; 后,成功匹配出孙悟空、孙权两条数据。
下划线_ 则是专用通配符,仅能匹配任意单个字符,'孙_' 代表固定开头是孙、姓名总共只有两个字的名字,执行 select name from exam_result where name like '孙_'; 就只会筛选出两字姓名的孙权,三字的孙悟空无法被匹配,借此区分 % 和_两种通配符的使用差异。
继续,比如我们要筛选语文成绩好于英语成绩的同学:
想要筛选语文分数高于英语分数的学生,where 后可以直接用两个字段做大小对比,where chinese > english 会逐行对比单条记录里 chinese 字段与 english 字段的数值,只要语文成绩数值更大就符合筛选条件,最终筛选出五条满足条件的学生数据,where 条件内不仅能和常量对比,也能字段之间互相运算比较。
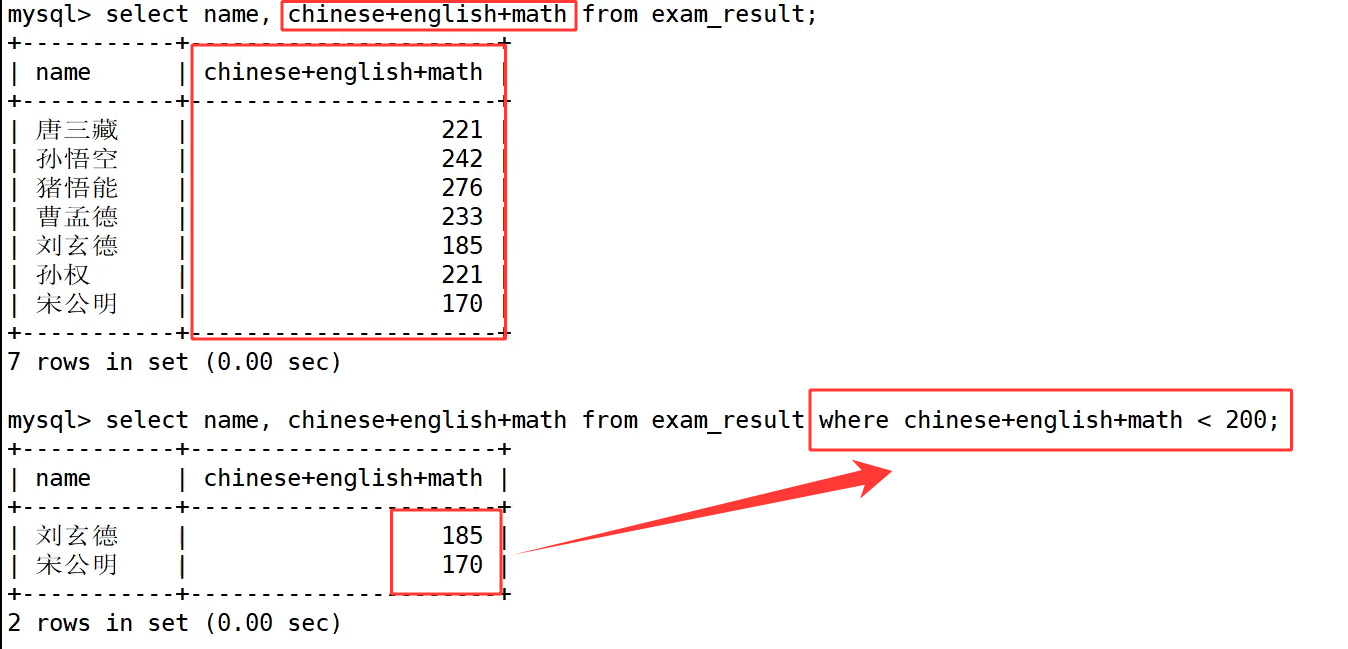
继续,比如我们要筛选总分在200分以下的同学:
筛选三科总分低于 200 分的学生时,where 子句内部能够直接使用 chinese+english+math < 200,数据库会先计算每条记录三科成绩的总和,再拿计算后的总分和 200 做大小判断,select name,chinese+english+math from exam_result where chinese+english+math<200; 最终筛选出刘玄德、宋公明两名总分不达 200 的学生。
下面我们继续:
我们先通过 select name,chinese+english+math total from exam_result; 给总分运算字段设置别名 total,查询结果可以正常展示别名表头,但是紧接着在 where 里直接使用别名做筛选,写成 select name,chinese+english+math total from exam_result where total < 200; 就会抛出字段不存在的报错。
这是为什么呢?
这一报错的根源来自 MySQL select 语句固定的执行先后顺序,一条基础 select 的执行顺序固定为先执行 from 确定数据源数据表,之后执行 where 完成数据筛选,最后才执行 select 字段列表、字段运算与别名定义,这里 where 执行筛选时别名 total 还没有被创建,数据库无法识别这个临时名称,因此不允许在 where 子句中直接引用 select 里定义的列别名。
我们也不能在 where 的条件表达式中起别名,如上否则就会报错,别名是结果展示阶段的语法,where 处于数据筛选阶段,此时数据还未被整理成最终展示的结果,语法层面不支持在筛选环节定义字段别名,强行书写会直接触发语法错误。
所以我们想要筛选总分小于 200 的数据,只能在 where 中完整复写三科相加的表达式,语句写为select name,chinese+english+math as total from exam_result where chinese+english+math < 200;,where 依靠原始字段运算做条件判断,select 部分正常使用别名优化表头,最终成功筛选出总分低于 200 的两名学生。
本次需求是筛选语文成绩大于 80 并且姓名不姓孙的学生,AND 代表前后两个筛选条件必须同时成立。我们可以分步拆分验证,第一条 SQLselect name, chinese from exam_result where chinese > 80; 先单独过滤语文超 80 分的数据,筛选出孙悟空、猪悟能、曹孟德三条记录。
第二条 SQLselect name, chinese from exam_result where name not like '孙%'; 借助 not 取反模糊条件,筛选出所有名字不以孙开头的学生,排除孙悟空、孙权。
将两个独立条件通过 AND 拼接为 where chinese > 80 and name not like '孙%',要求一条数据既要语文分数高于 80,又不能以孙作为姓氏开头,双重条件叠加后,最终只剩下猪悟能、曹孟德两条符合要求的数据,直观体现AND全条件匹配的运算规则。
接下来的综合查询需求分为两大分支,满足任意一个分支即可命中数据:要么姓名是孙氏同学,要么同时满足总分>200、语文小于数学、英语大于 80 三个条件,这类多逻辑混杂的查询需要依靠括号划分条件优先级,区分 OR 和 AND 的作用范围。
我们先单独处理后半段复合条件,where chinese+math+english>200 and chinese < math and english>80,三个子条件全部由 AND 连接,必须同时满足三科总分超 200、语文分数低于数学、英语高于 80,执行后仅猪悟能一条数据符合该组规则。
我们可以使用括号把后半三个绑定在一起的条件封装成一个完整条件单元,再用 OR 和 name like '孙%' 拼接,最终条件写成 where name like '孙%' or (chinese+math+english>200 and chinese < math and english>80),OR 代表左右两大条件单元任选其一成立即可,因此姓孙的孙悟空、孙权,加上满足三项分数条件的猪悟能都会被查询出来,括号可以改变条件运算优先级,避免 AND、OR 混用时逻辑错乱。
最后我们再来看一下 NULL********的查询 :
下面我们重新建一张表:
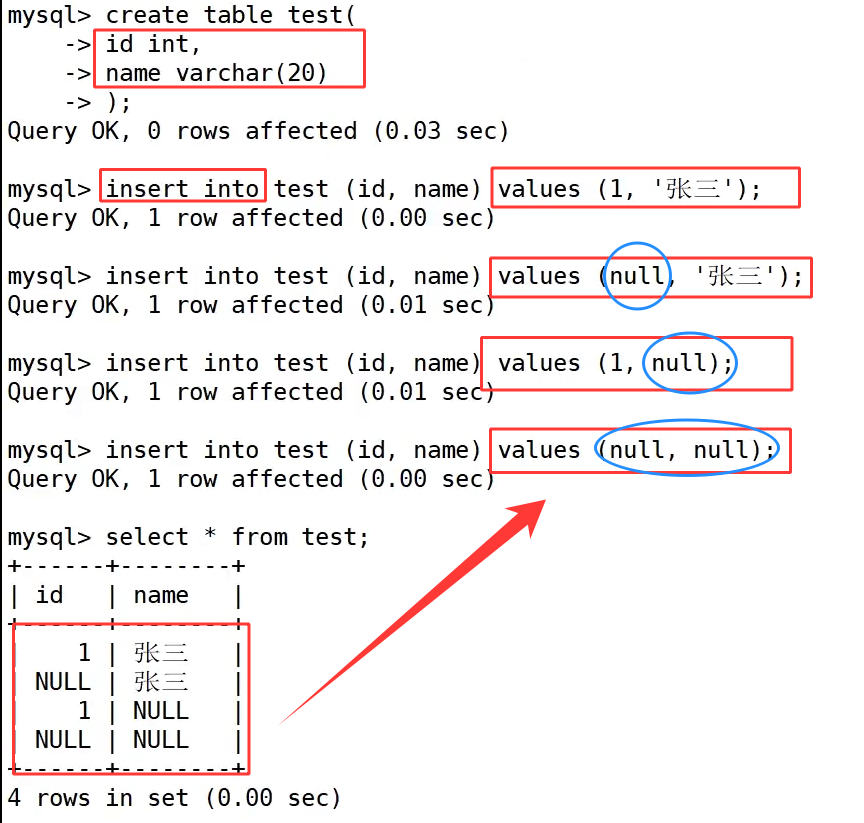
为了区分NULL与空字符串'',我们先创建只有 id、name 两个字段的 test 表,之后分四条语句插入不同组合的数据,分别是 id=1、name=' 张三 ';id 为 NULL、name=' 张三 ';id=1、name 为 NULL;id 和 name 全部为 NULL,此时全表四条数据涵盖了字段为空和有实际内容的多种情况,
后续我们再额外插入一条 id=1、name 是空字符串''的数据,用来做对照测试。
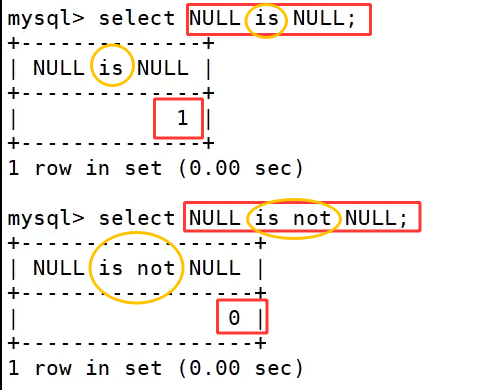
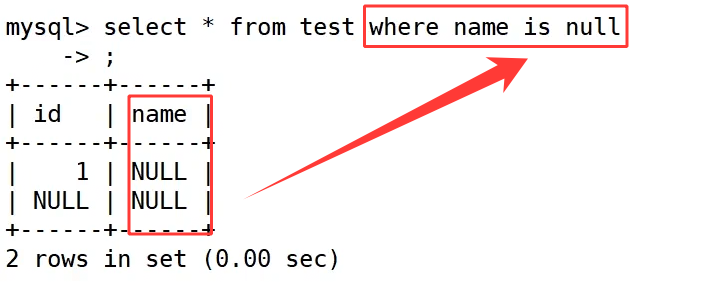
此时查询 name 字段是 NULL 的字段,语法必须使用 where name is null,不能使用 = 去匹配 NULL,这条语句执行后,只会筛选出 name 列物理值为 NULL 的两条数据,空字符串内容不会被这条条件命中,这是 MySQL 里 NULL 独有的匹配语法规则。
空字符串''是真实存在的空白文本数据,和 NULL 不属于同一种数据形态,筛选空字符串需要用等值判断 where name='',这条语句只会查出 name 字段是空字符串的单条记录,无法匹配任意 NULL 数据,直观区分 NULL 和空字符串的查询差异。
is not null 代表筛选字段不为 NULL 的全部数据,select * from test where name is not null; 执行后,姓名为张三、姓名为空字符串的三条数据都会被查询出来,因为空字符串是有效数据,不属于 NULL 范畴。NULL 代表字段没有存入任何数据、数据未知,只能依靠 is null /is not null 查询;空字符串是存入了长度为 0 的有效字符,使用=做等值查询,二者存储形式、查询语法完全不同,是开发里极易踩坑的知识点。
order by 子句
排序:
order by 是 SQL 中实现查询结果排序的子句,包含两种排序标识,ASC 代表升序,数据从小到大排列,DESC 代表降序,数据从大到小排列,在不手动书写排序标识时,order by 默认采用ASC升序规则。同时需要记住关键注意点,没有添加 order by 的查询,数据展示顺序是数据库底层存储随机结果,顺序没有确定性。
下面我们继续举例:
继续,比如我们要排序 : 同学及数学成绩,按数学成绩升序显示
我们沿用 exam_result 学生成绩表,实现按照数学成绩升序展示姓名与分数,语句 select name, math from exam_result order by math asc; 执行后,数据库会以 math 字段数值为准从小到大重排结果,从 65 分的宋公明开始,依次向后排列到 98 分的猪悟能、唐三藏,完整实现升序整理,而 asc 关键字可以省略不写,省略后依旧默认升序。将排序标识替换为 desc 降序,写成 select name, math from exam_result order by math desc;,此时数学成绩从最高分 98 向下依次排布,高分数据排在查询结果最上方,和升序的展示顺序完全相反,直观区分 asc 与 desc 两种排序方向。
继续,比如我们要排序: 比如对之前一个表中的名字排序:
再切换到存有 NULL、空字符串、普通姓名的 test 表中时,我们对 name 字段升序 select name from test order by name asc;,MySQL 规则里 NULL 视作小于所有有效值,升序排列时全部 NULL 数据会排在结果最顶端,之后再依次排布空字符串与普通文字;改为 desc 降序 select name from test order by name desc;,普通姓名排在上方,所有 NULL 因为数值最小,统一落在查询结果的末尾。
所以我们就能得出结论:
在 MySQL 排序逻辑中,NULL 永远被判定为比任意字符、数字都小,升序置顶、降序置底,这条规则在后续多字段组合排序中同样生效。
继续,比如我们要排序: 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
如果两个或多个人的数学成绩是相等的,那就按照英语升序的方式来排,以此类推:
我们实现多级排序需求,优先数学成绩降序,数学同分则英语升序,英语一致再语文升序,语句书写为 select name, math, english, chinese from exam_result order by math desc, english asc, chinese asc;。多字段排序遵循从左往右的优先级,先依靠第一个字段 math 完成整体降序排布,遇到多条记录 math 数值相同时,才启用后一个字段 english 做升序排序,后续字段只有在前边所有排序字段全部重复的情况下才会生效。
当 order by 后面只写字段名、不添加 asc 或 desc 时,MySQL 默认采用升序排列,select name,math from exam_result order by math;执行后数学成绩从小到大依次展示,从 65 分到 98 分有序排布,这也是之前定下的语法默认规则。
继续,比如我们要排序: 查询同学及总分,由高到低
在查询中用 as 给三科总分起别名 total,select name,math+chinese+english as total from exam_result order by total; 可以直接在 order by 后引用别名,不加 desc 为总分升序,追加 desc 写成 order by total des c就可以实现总分由高到低降序排列。
其实这里最重要的是 : 为什么这里的 order by 后又能使用别名了呢? 上次我们在使用 where 筛选时 where 后面不是不能使用别名吗?
之所以 where 不能用别名、order by 可以,根源是 SQL 执行顺序:from→where→select→order by,order by 在 select 别名生成之后执行,能够识别别名,where 执行时别名还未创建无法使用。
继续,比如我们要排序: 查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
我们筛选姓孙或者姓曹的学生并按数学降序,语句 select name, math from exam_result where name like '孙%' or name like '曹%' order by math desc;,SQL 先通过 where 过滤出符合姓名条件的数据,再对筛选完成后的结果集执行数学分数降序,最终数据按 math 从大到小展示,where 负责行过滤、order by 负责结果排序,固定先筛选后排序。
筛选分页结果
什么是分页?
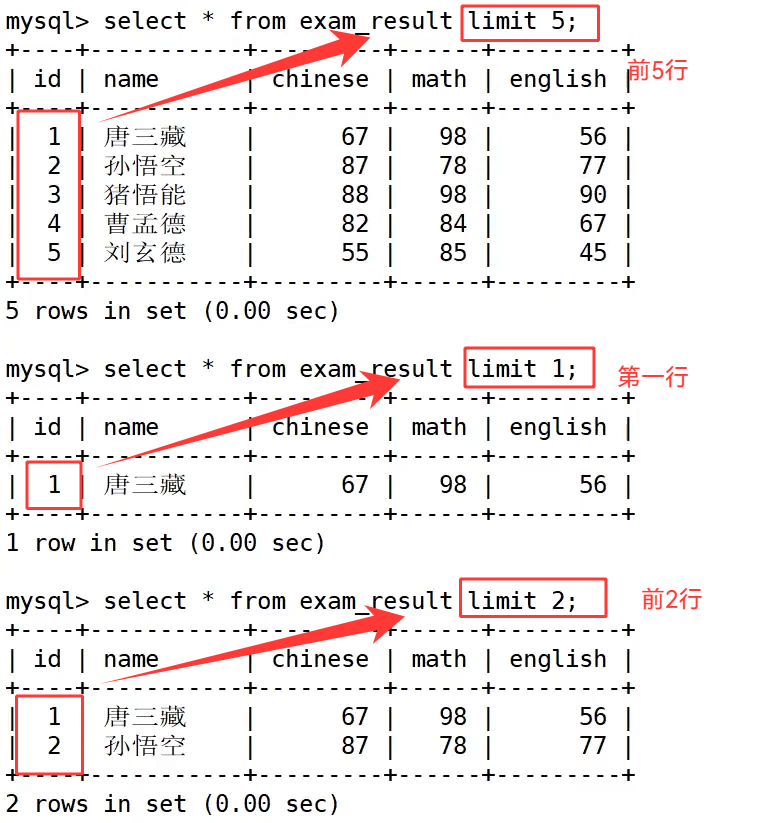
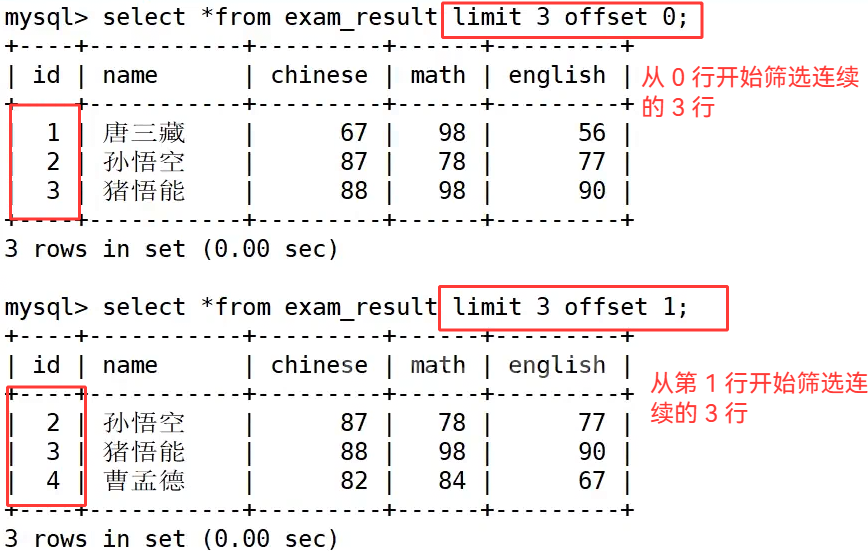
当查询出来的数据量很大,一次性展示全部数据不利于浏览与程序读取时,我们依靠 limit 关键字实现结果分页截取,limit 是 MySQL 专属分页语法,写在整条 select 语句的末尾,作用是从已经筛选、排序完毕的结果集中截取指定条数的数据。
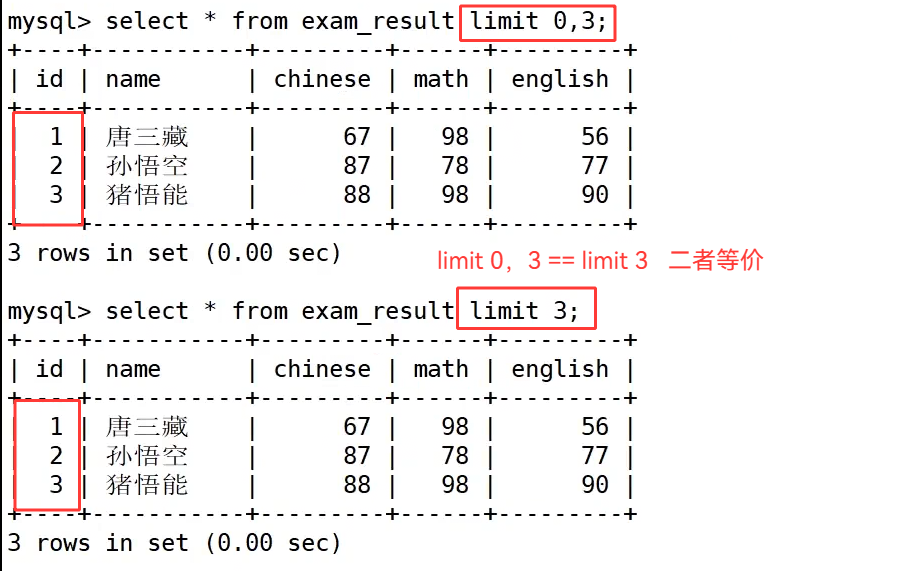
偏移量写 0 代表从结果集最开头开始取值,limit 0,3 等价于 limit 3,都是从第一条数据开始取出三条记录,这也印证了 limit 的下标规则:数据表逻辑第一条记录对应的下标是 0,不是 1。在完整查询语句 select ... from ... where ... order by ... limit ...中,limit 是最后执行的环节,会在筛选、排序全部完成之后,再对最终结果做数据截取,不会提前截断原始数据影响 where 与 order by 逻辑。
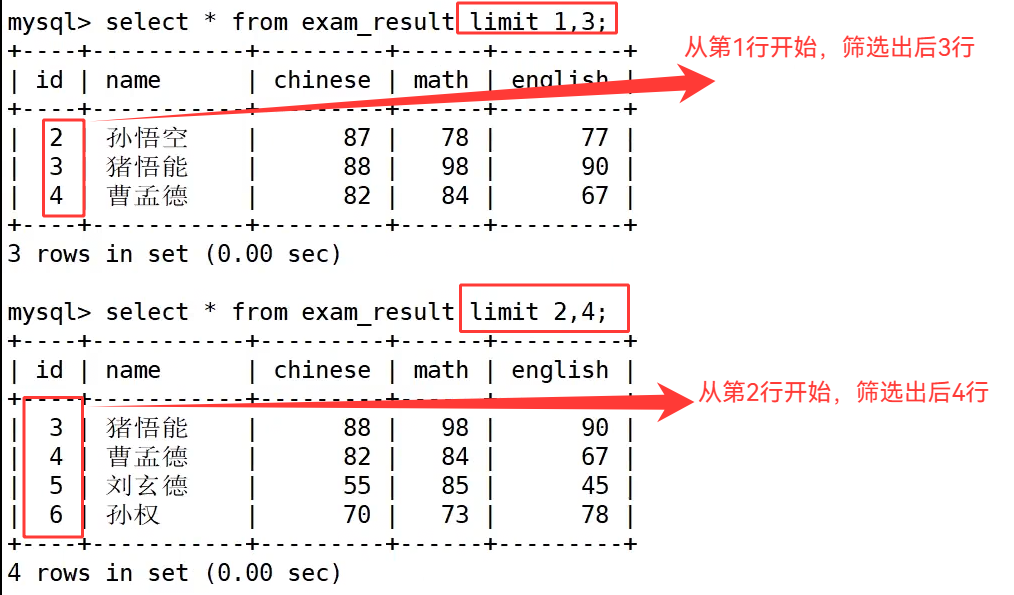
首先汇总 limit 三类分页语法,单参数 limit N 代表从结果起始下标 0 的位置向后读取 N 条数据;双参数 limit offset,count 中第一个数值是起始偏移下标(下标从 0 起始),第二个数值是单次取出的数据条数;limit count offset offset_num 是等价写法,前面数字代表展示行数,offset 后标注起始下标,两种多参数写法执行效果完全一致。
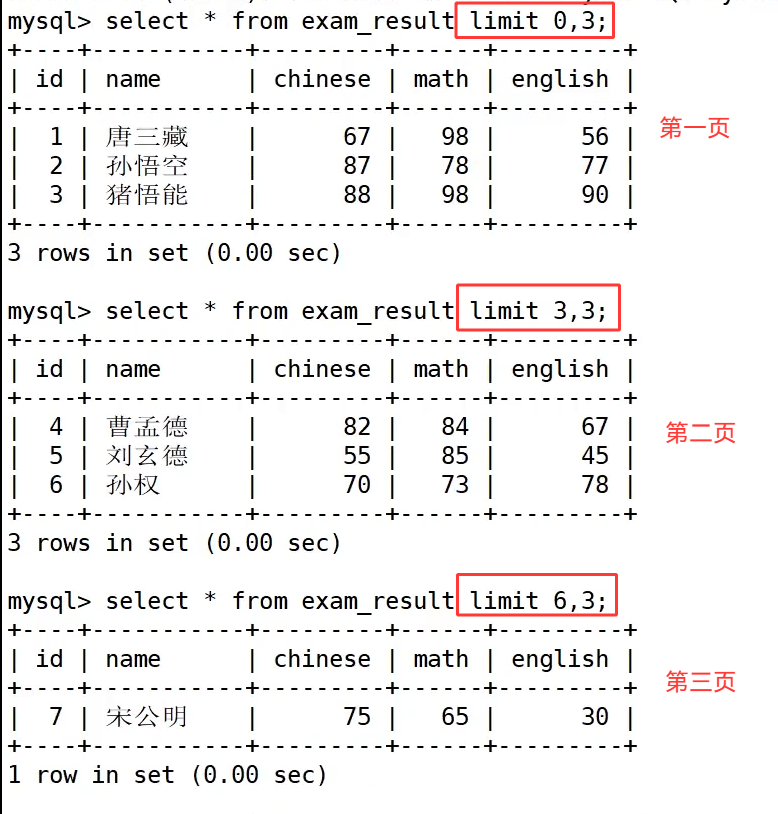
以总分筛选分页 SQLselect name, english+math+chinese total from exam_result where english+math+chinese>200 order by total desc limit 2 offset 0;为例,整条 SQL 严格遵循固定执行次序,最先执行 from 确定数据表,之后 where 按照总分条件过滤原始数据,筛选完毕后 order by 对合规数据做降序排序,排序完成后最后由 limit 截取对应分页数据,最终由 select 展示字段与别名。设定每页固定展示 2 条数据,第一页 limit 2 offset 0 从下标 0 取前两条,第二页偏移改为 2 写成 limit 2 offset 2 跳过前面两条数据,第三页 limit 2 offset 4 继续向后偏移,随着 offset 数值递增依次拿到后续分页数据,剩余数据不足页面条数时原样返回现存记录。所以数据必须先经过 where 条件筛选、再经过 order by 排序处理,所有数据整理完毕之后,limit 才会做结果截取,limit 只负责控制最终展示的数据范围,不属于前置筛选条件。
 CRUD 是数据库数据操作的统称缩写,四个字母分别对应四类核心数据操作:
CRUD 是数据库数据操作的统称缩写,四个字母分别对应四类核心数据操作:
我们可以在一条 insert 语句的 values 后,用英文逗号分隔多组括号数据,就能实现一次性批量插入多条记录,如上图 insert into students values (13, 127, '许攸','10423456'),(14, 128, '许褚','12333445'),(15,129,'诸葛亮','3213456'); 就是全字段批量插入,每组括号完整填写表内全部四个字段的值,执行后数据库一次性新增三条数据,查询数据表能够看到三条记录全部成功入库。同时每一组括号里的数据必须严格按照建表时字段的先后顺序填写字段内容,多组行数据之间依靠逗号隔开,相较于多次单行 insert,批量插入可以减少数据库连接交互开销,大批量导入数据时执行效率更高。
我们也可以在 values 的前面写明指定字段,完成多记录插入,insert into students (sn,name,qq) values (130,'孙权','6543456'),(131,'吕布','4321234'); 这条 SQL 只标注 sn、name、qq 三个字段,自增 id 依旧交由数据库自动生成,执行结束后查询表格,孙权、吕布两条数据自动生成 id 为 16、17,顺利完成数据新增。



select 的完整基础语法结构,SELECT DISTINCT {*|字段名列表} FROM 数据表 WHERE筛选条件 ORDER BY 排序字段 LIMIT分页限制,其中 DISTINCT 用来实现查询结果去重,* 代表查询全部字段,FROM 指定需要查询的数据来源表,后续 WHERE、ORDER BY、LIMIT 分别对应条件筛选、排序、分页功能,整串语法从左到右遵循固定的执行顺序。




where 筛选依托各类比较运算符完成字段匹配,基础大小符号 >、>=、<、<= 用来做数值大小对比;单等号 = 做等值匹配,但无法判断 NULL,NULL=NULL结果为空不成立,<> 和 != 代表不等于,<> 可以安全处理 NULL 判等;between a0 and a1 用来限定闭区间范围,匹配数值处在 a0,a1 之间的数据;in(数值列表) 匹配字段取值落在括号内任意一项的记录;is null、is not null 专门用来判断字段为空或非空,不能用=去查询 NULL 数据;like实现模糊匹配,% 匹配任意长度字符、_只匹配单个字符。

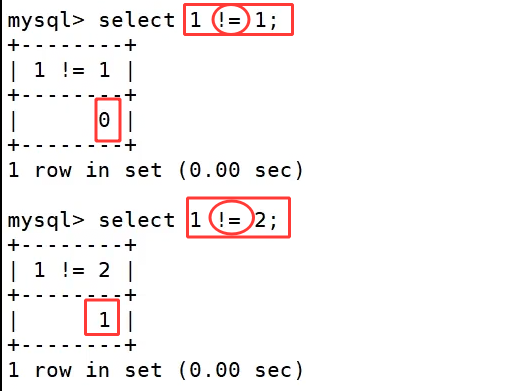
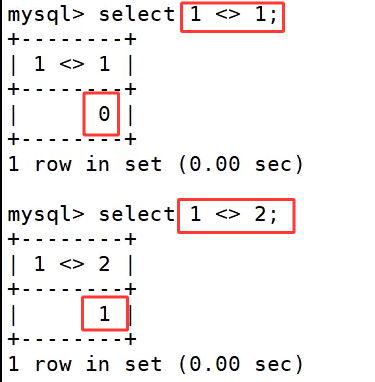
多条件组合筛选需要逻辑运算符串联条件,and 是逻辑与,前后所有条件全部满足,整行数据才会被筛选出来;or 是逻辑或,多个条件里任意一条成立即可命中数据;not 是逻辑取反,原本成立的条件经过 not 修饰后变为不成立,用来反向筛选数据。
MySQL 提供 between ... and ... 语法简化连续区间的筛选,where chinese between 80 and 90 等价于前面 >=、<= 加 AND 的写法,该语法是闭区间,会包含左右边界 80 和 90,执行后筛选结果和上一条 SQL 一致,在连续数值范围筛选时,使用 between and 代码更加简洁直观。
接下来筛选数学成绩为 58、59、98、99 其中任意分数的学生,我们先不带条件查询展示出全部的数学成绩,然后采用 OR 拼接多个等值条件 where math=58 or math=59 or math=98 or math=99,只要字段满足任意一个等式就会被筛选出来,最终匹配到两条数学 98 分的数据,OR的逻辑是多个条件任意一个成立就会被筛选出来,但备选数值较多时大量拼接 or 语句会冗余繁琐。
当面对多个零散固定数值的筛选需求时,我们可以用 in(数值列表) 替代连续 OR 写法,where math in (58,59,98,99),字段的值只要落在括号内的集合中就符合筛选规则,执行效果和多条 or 完全一致,代码精简易维护。
想要筛选语文分数高于英语分数的学生,where 后可以直接用两个字段做大小对比,where chinese > english 会逐行对比单条记录里 chinese 字段与 english 字段的数值,只要语文成绩数值更大就符合筛选条件,最终筛选出五条满足条件的学生数据,where 条件内不仅能和常量对比,也能字段之间互相运算比较。
我们先通过 select name,chinese+english+math total from exam_result; 给总分运算字段设置别名 total,查询结果可以正常展示别名表头,但是紧接着在 where 里直接使用别名做筛选,写成 select name,chinese+english+math total from exam_result where total < 200; 就会抛出字段不存在的报错。
所以我们想要筛选总分小于 200 的数据,只能在 where 中完整复写三科相加的表达式,语句写为select name,chinese+english+math as total from exam_result where chinese+english+math < 200;,where 依靠原始字段运算做条件判断,select 部分正常使用别名优化表头,最终成功筛选出总分低于 200 的两名学生。










is not null 代表筛选字段不为 NULL 的全部数据,select * from test where name is not null; 执行后,姓名为张三、姓名为空字符串的三条数据都会被查询出来,因为空字符串是有效数据,不属于 NULL 范畴。NULL 代表字段没有存入任何数据、数据未知,只能依靠 is null /is not null 查询;空字符串是存入了长度为 0 的有效字符,使用=做等值查询,二者存储形式、查询语法完全不同,是开发里极易踩坑的知识点。







我们实现多级排序需求,优先数学成绩降序,数学同分则英语升序,英语一致再语文升序,语句书写为 select name, math, english, chinese from exam_result order by math desc, english asc, chinese asc;。多字段排序遵循从左往右的优先级,先依靠第一个字段 math 完成整体降序排布,遇到多条记录 math 数值相同时,才启用后一个字段 english 做升序排序,后续字段只有在前边所有排序字段全部重复的情况下才会生效。
当 order by 后面只写字段名、不添加 asc 或 desc 时,MySQL 默认采用升序排列,select name,math from exam_result order by math;执行后数学成绩从小到大依次展示,从 65 分到 98 分有序排布,这也是之前定下的语法默认规则。



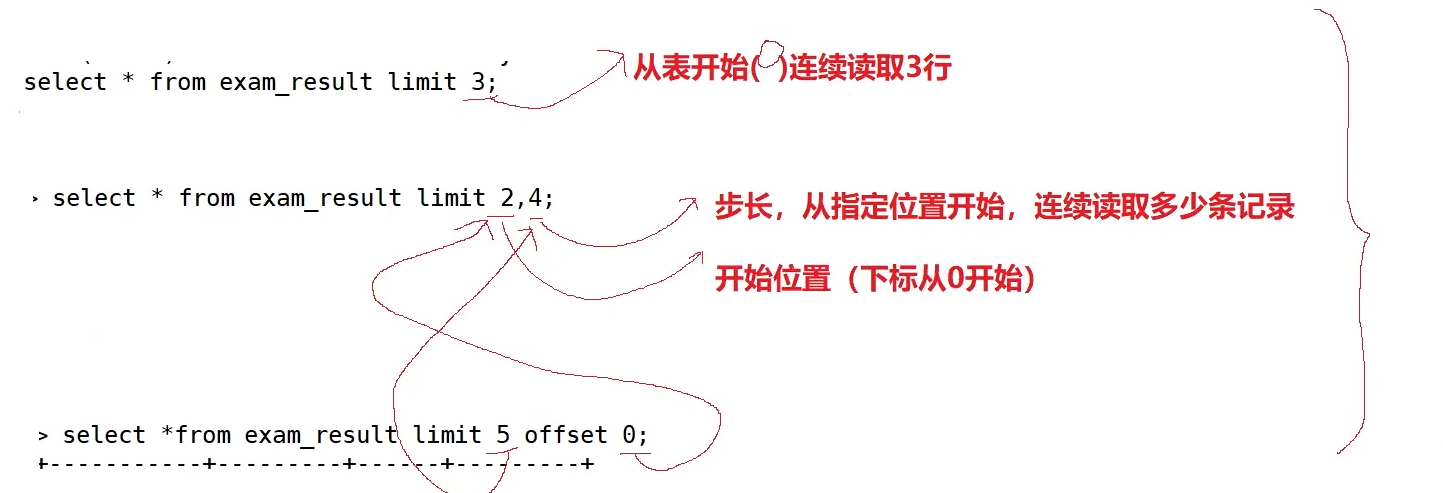 首先汇总 limit 三类分页语法,单参数 limit N 代表从结果起始下标 0 的位置向后读取 N 条数据;双参数 limit offset,count 中第一个数值是起始偏移下标(下标从 0 起始),第二个数值是单次取出的数据条数;limit count offset offset_num 是等价写法,前面数字代表展示行数,offset 后标注起始下标,两种多参数写法执行效果完全一致。
首先汇总 limit 三类分页语法,单参数 limit N 代表从结果起始下标 0 的位置向后读取 N 条数据;双参数 limit offset,count 中第一个数值是起始偏移下标(下标从 0 起始),第二个数值是单次取出的数据条数;limit count offset offset_num 是等价写法,前面数字代表展示行数,offset 后标注起始下标,两种多参数写法执行效果完全一致。