从 B+ 树到应用层分表:MySQL 海量数据架构解析
为什么单表超过千万行会变慢?InnoDB 页面分裂/合并如何影响性能?分库分表到底怎么选?五种分片策略各自的优劣?分表后如何解决分布式 ID、跨片查询、扩容迁移?
引言:为什么数据库越来越慢?
很多开发者都遇到过这样的场景:项目初期一切正常,随着用户量增长,某张表的数据从百万级冲向千万级,突然------查询变慢了,加索引要锁表半小时,备份恢复耗时越来越长。
这不是个例,而是 B+ 树结构 的固有特性决定的。理解 B+ 树,才能理解为什么分表是解决海量数据问题的终极手段。
本文将从底层原理出发,带你完整走一遍:B+ 树 → InnoDB 物理存储 → 页面分裂/合并 → 分库分表 → 分片策略 → 核心挑战。
一、什么是应用层分表
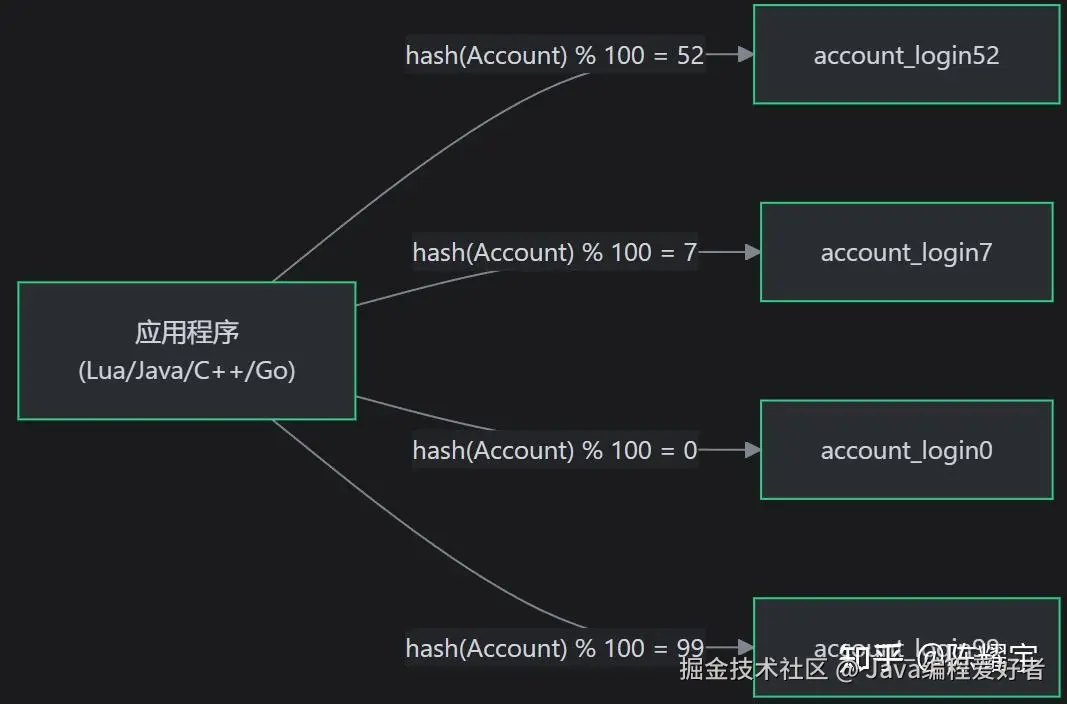
应用层分表是指在应用程序代码中实现数据分片路由逻辑,而非依赖数据库中间件或数据库自身分片能力。应用程序根据分片键(Shard Key)计算目标分表,直接操作对应的物理表。
与中间件分片的区别:
| 维度 | 应用层分表 | 中间件分表(ShardingSphere-Proxy/MyCat) |
|---|---|---|
| 路由位置 | 应用代码内 | 独立代理服务 |
| 性能开销 | 无额外网络跳转 | 多一跳网络转发 |
| 多语言支持 | 每种语言需各自实现 | 对应用透明,多语言通用 |
| 运维复杂度 | 分片规则分散在各应用 | 集中管理 |
| 适用场景 | 单一技术栈、性能要求极高 | 多语言、大规模集群 |
二、B+ 树:数据库性能的底层密码
InnoDB 存储引擎使用 B+ 树 作为索引结构。理解 B+ 树的工作原理,才能理解为什么单表数据量增长会导致性能下降。
2.1 为什么 MySQL 选择 B+ 树?
存储引擎是数据库的核心组件,定义数据如何组织、存储和检索。常见的存储数据结构有四种候选方案:
| 数据结构 | 单点查询 | 范围查询 | 写入性能 | 适用场景 | 代表 |
|---|---|---|---|---|---|
| 哈希表 | O(1) 最优 | 不支持(只能全表扫描) | O(1) | Key-Value 精确查找 | Redis、Memcached |
| 平衡二叉树 | O(log n) | 支持,但 IO 次数多 | O(log n) | 内存中小数据集 | AVL Tree、红黑树 |
| B 树 | O(1)~O(log n) 不稳定 | 支持,但随机 IO 多 | O(log n) | 早期文件系统 | 早期 MyISAM |
| B+ 树 | O(log n) 稳定 | 高效(链表顺序扫描) | O(log n) | 关系型数据库索引 | InnoDB、PostgreSQL |
哈希表的致命缺陷:不支持范围查询和排序。
sql
-- 这类查询哈希表只能全表扫描
SELECT*FROM commodity WHERE price >10AND price <100;
SELECT*FROM commodity WHEREORDERBY price DESC;平衡二叉树的问题:每个节点只存一个数据,树高度大→磁盘 IO 次数多。磁盘读取时间远超内存比较时间,程序大部分时间阻塞在磁盘 IO 上。
B 树的范围查询问题(以查询"大于 10 小于 30 的数据"为例):
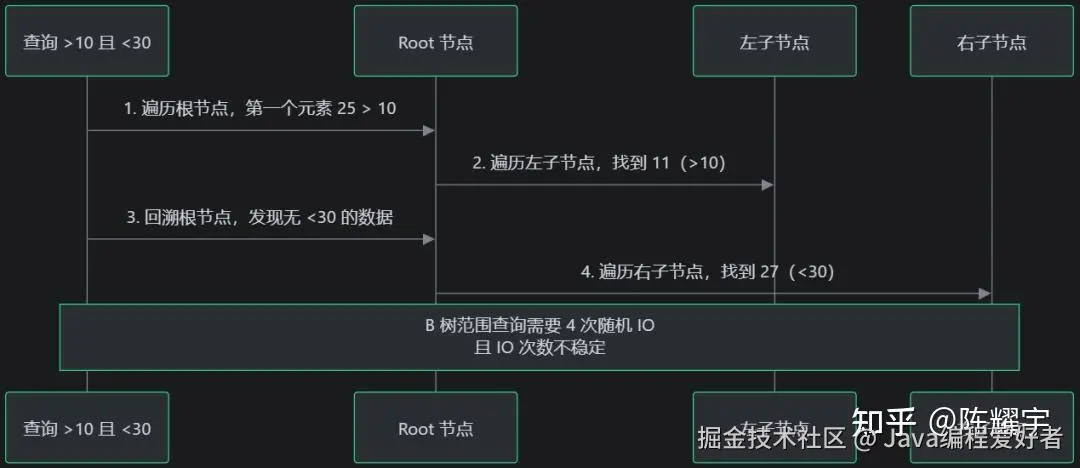
B+ 树的优势:叶子节点通过链表顺序连接,范围查询只需定位起点后沿链表顺序扫描,且磁盘预读机制会提前加载相邻页,IO 效率远高于 B 树。
B+ 树 vs B 树 IO 效率对比:
B+ 树非叶节点只存索引(键值+指针),单页能存更多索引项,树更矮,IO 更少:
scss
B+ 树非叶节点:key(8B) + pointer(6B) = 14B/条目
单页可存:16KB / 14B ≈ 1170 个索引项
B 树非叶节点:key(8B) + pointer(6B) + data(约1KB) ≈ 1018B/条目
单页可存:16KB / 1018B ≈ 16 个索引项| 指标 | B+ 树 | B 树 |
|---|---|---|
| 非叶节点单页索引项数 | ~1170 | ~16 |
| 3 层树可存行数 | ~2190 万 | ~4096 |
| 范围查询 IO 模式 | 顺序 IO(链表扫描) | 随机 IO(回溯父节点) |
(天呐,简直碾压~)
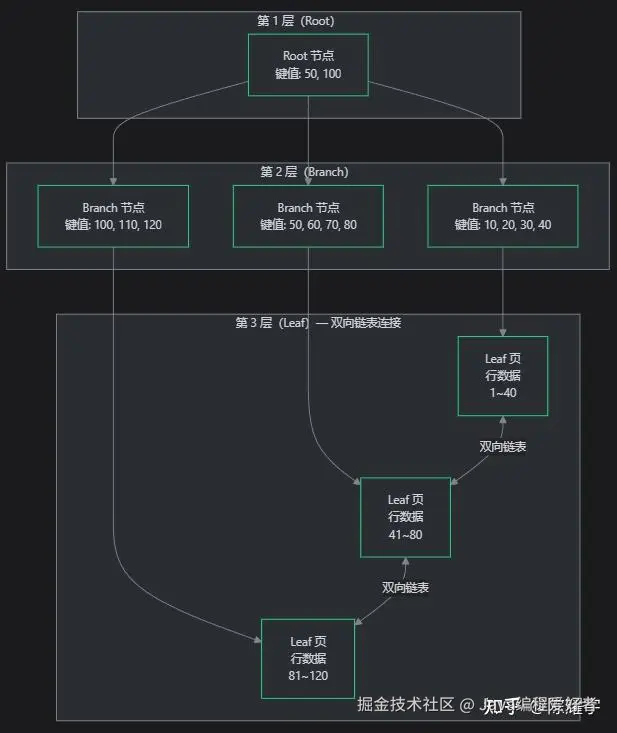
2.2 B+ 树结构详解
B+ 树是一种多路平衡查找树,核心设计围绕"减少磁盘 IO"展开。与 B 树的关键区别:
| 特性 | B 树 | B+ 树 |
|---|---|---|
| 数据存储位置 | 所有节点都存数据 | 只有叶子节点存数据,内部节点只存键值 |
| 叶子节点链接 | 无 | 叶子节点通过双向链表连接 |
| 查询路径 | 可能在中间节点就命中 | 必须走到叶子节点,查询路径稳定 |
| 范围查询 | 需要中序遍历整棵树 | 沿叶子节点链表顺序扫描即可 |
以阶数 m(每个节点最多 m 个子节点)为例:
节点规则:
| 节点类型 | 存储内容 | 子节点/关键字范围 |
|---|---|---|
| 非叶子节点 | 仅存索引键值 + 子节点指针,不存数据 | 子节点数 k:⌈m/2⌉ ≤ k ≤ m;关键字数 k-1 |
| 叶子节点 | 键值 + 数据(或主键值),双向链表连接 | 关键字数 k:⌈m/2⌉-1 ≤ k ≤ m-1 |
| 根节点 | 同非叶子节点(或叶子节点,当数据很少时) | 至少 2 个子节点(非叶时) |
内部节点结构:
css
[P1, K1, P2, K2, ..., Pn-1, Kn-1, Pn]
P1 指向的子树:所有键值 < K1
Pi 指向的子树:所有键值 >= Ki-1 且 < Ki(1 < i < n)
Pn 指向的子树:所有键值 >= Kn-1B+ 树性质:
- 每个节点最多有 m 个子节点
- 每个非叶子节点(除根)至少有 ⌈m/2⌉ 个子节点
- 根节点至少有 2 个子节点(除非是叶子节点)
- 所有叶子节点在同一层(保证查询深度一致)
- 有 k 个子节点的非叶子节点包含 k-1 个键
B+ 树结构示意:
2.3 B+ 树的构建:插入与分裂
B+ 树通过逐条插入 数据构建,当节点满时触发分裂。以阶数 m=3 为例:
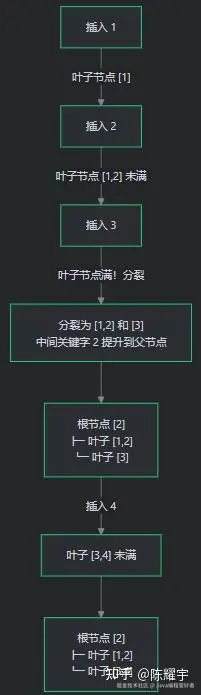
分裂对性能的影响:
| 影响维度 | 说明 |
|---|---|
| 磁盘 IO | 分裂需要写入新页 + 修改原页 + 修改父页,至少 3 次随机 IO |
| 页碎片 | 分裂后两个页各约 50% 满,空间利用率下降 |
| 锁竞争 | 分裂期间持有页锁,阻塞并发访问 |
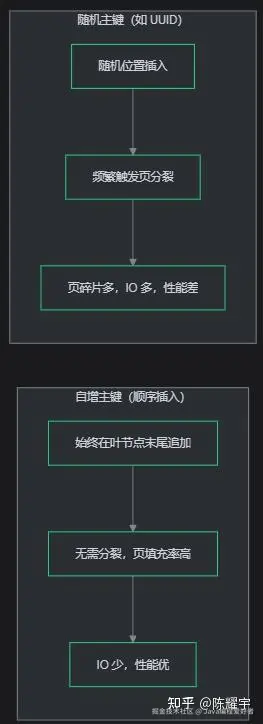
自增主键 vs 随机主键的插入差异:
2.4 B+ 树的维护:删除与合并
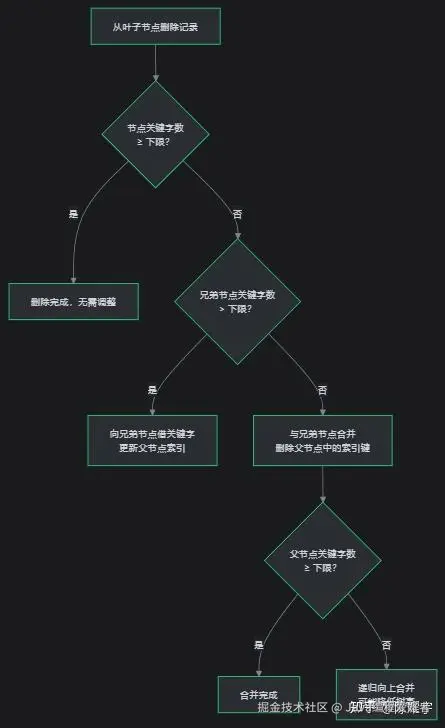
删除操作从叶子节点移除记录,若节点关键字数低于下限,触发借键 或合并:
合并对性能的影响:
| 影响维度 | 说明 |
|---|---|
| 磁盘 IO | 合并需要读取兄弟页 + 修改两个页 + 修改父页 |
| 空间回收 | 合并后释放空页,提高空间利用率 |
| 触发频率 | 实际生产中删除操作较少触发合并,InnoDB 通过 MERGE_THRESHOLD(默认 50%)控制 |
另外,借键操作用 > 而不是 ≥,这不是写错,是 B+ 树删除算法的正确逻辑。原因如下:
B+ 树节点的关键字下限 为 ⌈m/2⌉ - 1 (m 为阶数)。
借键操作会从兄弟节点 拿走一个关键字 。如果兄弟节点恰好只有下限个关键字( 等于下限 ),借走一个后它会变成 下限 - 1 , 低于下限 ,违反 B+ 树性质。
ini
假设阶数 m=5,关键字下限 = ⌈5/2⌉ - 1 = 2
兄弟节点有 3 个关键字(> 下限)→ 借走 1 个,剩 2 个,≥
下限,合法 ✓
兄弟节点有 2 个关键字(= 下限)→ 借走 1 个,剩 1 个,<
下限,违法 ✗
所以只能用 >,不能用 ≥兄弟节点关键字数 能否借键 原因 > 下限 能借 借走后兄弟仍 ≥ 下限 = 下限 不能借 借走后兄弟 < 下限,只能合并
简单说: > 保证借键后兄弟节点不会跌破下限, ≥ 会导致兄弟节点也违规 。
2.5 聚簇索引 vs 非聚簇索引:数据到底存在哪?
理解聚簇索引和非聚簇索引的区别,是理解 InnoDB 性能特征的关键。两者的核心差异只有一句话:数据行存在哪里?
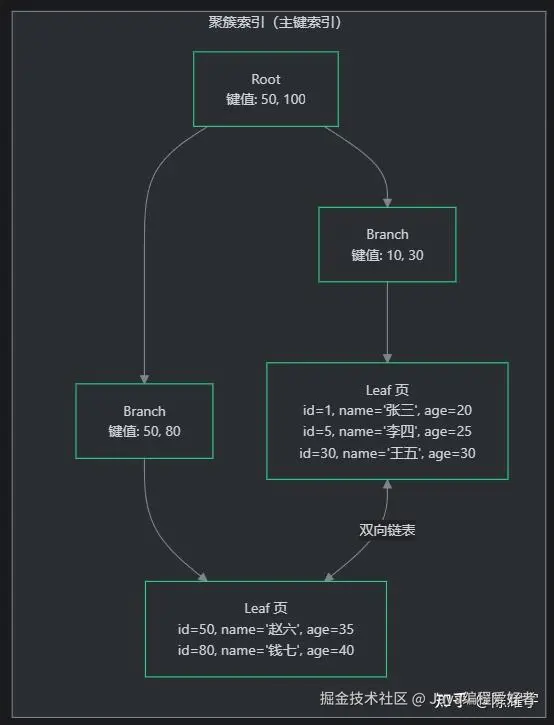
聚簇索引(Clustered Index):数据就是索引
聚簇索引的 B+ 树叶子节点直接存储整行数据,索引和数据是同一棵树。就像一本字典按拼音排序,拼音索引的条目旁边直接印着释义------你找到了拼音,就找到了释义,不需要再去翻另一页。
关键特征:
- 每张表只能有一个聚簇索引(因为数据只能按一种顺序物理存储)
- InnoDB 中主键就是聚簇索引;若无主键,选第一个唯一非空索引;若都没有,InnoDB 隐式创建 6 字节 ROWID
- 数据行按主键顺序物理存储,因此主键查询和范围查询极快
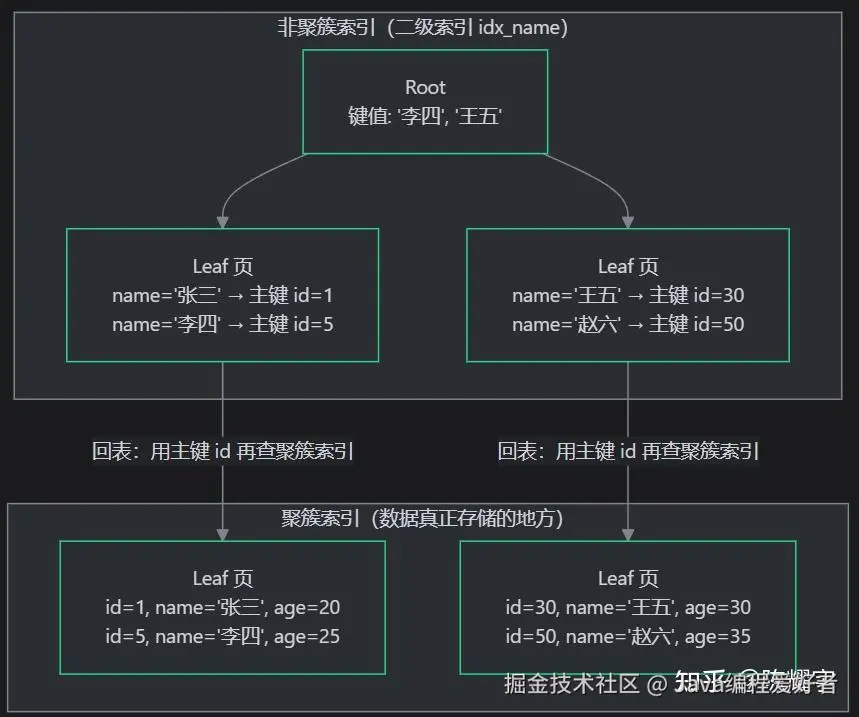
非聚簇索引(Non-Clustered Index / 二级索引):索引指向数据
非聚簇索引的 B+ 树叶子节点不存数据,存的是"指向数据的地址" 。就像书末尾的关键词索引,关键词旁边印的是页码------你找到了关键词,还得翻到对应页码才能看到内容。
关键特征:
- 一张表可以有多个非聚簇索引(每个二级索引都是非聚簇索引)
- InnoDB 的二级索引叶子节点存主键值 (而非物理地址),MyISAM 的索引叶子节点存数据物理地址
- 查询非索引列时需要回表:先查二级索引拿到主键值,再用主键值查聚簇索引获取整行数据
回表:非聚簇索引的性能代价
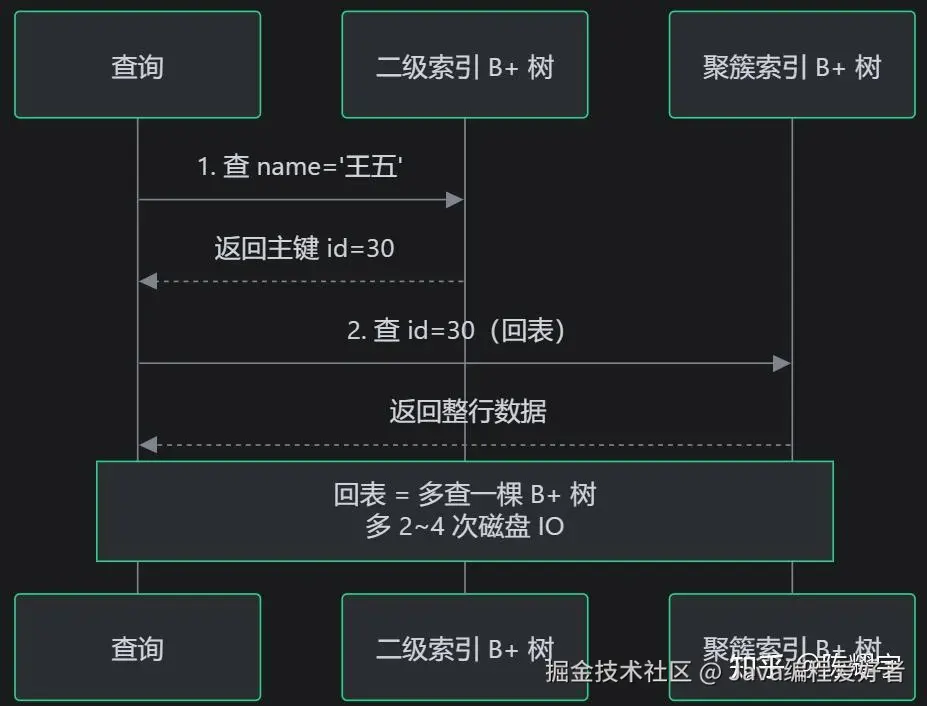
回表的性能影响:
| 场景 | 是否回表 | IO 开销 | 性能 |
|---|---|---|---|
| 主键查询(走聚簇索引) | 否 | 1 棵 B+ 树的 IO | 快 |
| 二级索引查索引列(覆盖索引) | 否 | 1 棵 B+ 树的 IO | 快 |
| 二级索引查非索引列(需回表) | 是 | 2 棵 B+ 树的 IO | 慢 |
覆盖索引 :如果查询所需的所有列都包含在二级索引中,就不需要回表。例如索引
idx_name_age(name, age),查询SELECT age FROM user WHERE name = '王五'只需查二级索引即可,因为 name 和 age 都在索引里。
聚簇索引对性能的全面影响
| 维度 | 聚簇索引(InnoDB) | 非聚簇索引(MyISAM) |
|---|---|---|
| 主键等值查询 | 极快(1 棵树,数据就在叶节点) | 快(1 棵树,叶节点存地址,需额外寻址) |
| 主键范围查询 | 极快(叶节点链表顺序扫描,数据物理相邻) | 慢(地址不连续,随机 IO) |
| 二级索引查询 | 可能回表(多查 1 棵树) | 无需回表(直接存地址) |
| 插入性能 | 依赖主键类型(自增快,随机慢) | 与主键类型关系不大 |
| 页分裂频率 | 高(数据在聚簇索引中,随机主键触发分裂) | 低(索引与数据分离,分裂只影响索引树) |
| 空间占用 | 二级索引存主键值(可能较大) | 所有索引存物理地址(固定小) |
为什么 InnoDB 二级索引存主键值而非物理地址?
聚簇索引会发生页分裂,数据行物理地址会变化。如果二级索引存物理地址,每次页分裂都要更新所有二级索引中受影响行的地址,维护成本极高。存主键值则页分裂不影响二级索引------代价是回表时多查一棵树,但维护成本大幅降低。
聚簇索引 + 自增主键 = 最佳拍档:
自增主键保证数据按插入顺序追加到聚簇索引末尾,无需页分裂,页填充率高达 ~94%。如果用 UUID 做主键,随机插入会频繁触发页分裂,页填充率降至 50%,而且二级索引存的是 36 字节的 UUID 字符串(vs 8 字节的 BIGINT),索引体积膨胀 45 倍。
如何设置聚簇索引和非聚簇索引
SQL 中通过不同的关键字来设置:
| 类型 | SQL 关键字 | 说明 | 每表数量 |
|---|---|---|---|
| 聚簇索引 | PRIMARY KEY | 主键即为聚簇索引,数据按主键物理存储 | 只能 1 个 |
| 非聚簇索引 | KEY / INDEX | 普通索引,叶节点存主键值 | 可以多个 |
| 唯一非聚簇索引 | UNIQUE KEY | 唯一索引,也是非聚簇索引 | 可以多个 |
sql
-- 聚簇索引:PRIMARY KEY(只能有一个)
PRIMARY KEY (`IncrementNumber`) USING BTREE
-- 非聚簇索引:KEY / INDEX(可以有多个)
KEY `User` (`UserName`,`ServerId`) USING BTREE
-- 唯一非聚簇索引:UNIQUE KEY
UNIQUE KEY `uk_user_name` (`UserName`) USING BTREEInnoDB 选择聚簇索引的优先级:
markdown
1. 显式定义的 PRIMARY KEY → 聚簇索引
2. 第一个 UNIQUE NOT NULL 索引 → 聚簇索引
3. 都没有 → InnoDB 隐式创建 6 字节 ROWID → 聚簇索引举个案例:用户表
| IncrementNumber | UserName | ServerId | FieldA | FieldB | ... |
sql
PRIMARY KEY (`IncrementNumber`) USING BTREE, -- 聚簇索引:数据按 IncrementNumber 物理存储
KEY `User` (`UserName`,`ServerId`) USING BTREE -- 非聚簇索引:叶节点存 IncrementNumberIncrementNumber是自增主键,天然就是聚簇索引,数据按自增顺序物理追加,页填充率高、分裂少User是复合二级索引,查UserName时先在二级索引树找到IncrementNumber,再回表到聚簇索引取整行数据- 复合索引
(UserName, ServerId)遵循最左前缀原则:查UserName或UserName + ServerId都能命中,但只查ServerId则索引失效
2.6 InnoDB vs MyISAM 的 B+ 树差异

| 对比维度 | InnoDB(B+ 树) | MyISAM(B+ 树) |
|---|---|---|
| 索引类型 | 聚簇索引 + 二级索引 | 仅非聚簇索引,无聚簇索引 |
| 叶节点存储内容 | 聚簇索引存整行数据,二级索引存主键值 | 所有索引均存数据物理地址 |
| 数据与索引关系 | 数据与聚簇索引绑定,存储在一起 | 数据与索引分离,单独存储 |
| 查询性能 | 主键查询快,二级索引需回表,范围查询高效 | 无需回表,但无聚簇索引,范围查询性能差 |
InnoDB 聚簇索引规则:每张表有且只有一个聚簇索引------若显式定义主键,主键即为聚簇索引;若无主键,选择第一个唯一非空索引;若都没有,InnoDB 隐式创建 6 字节 ROWID。
为什么二级索引存主键值而非物理地址? 因为聚簇索引会发生页分裂,数据行物理地址会变化;若二级索引存物理地址,页分裂时需更新所有二级索引,维护成本极高;存主键值则页分裂不影响二级索引。
2.7 基于 B+ 树的实战优化技巧
优化 1:主键优先选择自增有序主键
B+ 树有序插入时仅需在叶节点末尾添加数据,无需分裂节点;UUID 等无序主键会导致频繁节点分裂,产生碎片。
sql
推荐:bigint auto_increment 自增主键
避免:UUID、随机字符串主键优化 2:复合索引遵循最左前缀原则
B+ 树复合索引按"先第一列、再第二列"排序,查询条件必须从最左列开始匹配。
sql
-- 复合索引 idx_name_age (user_name, age)
SELECT*FROMuserWHERE user_name ='张三'; -- 命中索引
SELECT*FROMuserWHERE user_name ='张三'AND age =20; -- 命中索引
SELECT*FROMuserWHERE age =20; -- 索引失效!未用第一列
SELECT*FROMuserWHERE user_name LIKE'%三'; -- 索引失效!右模糊优化 3:利用覆盖索引避免回表
覆盖索引 = 索引包含查询所需的所有字段,无需回表查聚簇索引,减少一次磁盘 IO。
ini
-- 二级索引 idx_name_age (user_name, age),查询 phone 需回表
SELECT age, phone FROMuserWHERE user_name ='张三';
-- 覆盖索引 idx_name_age_phone (user_name, age, phone),无需回表
CREATE INDEX idx_name_age_phone ONuser(user_name, age, phone);
SELECT age, phone FROMuserWHERE user_name ='张三';优化 4:避免索引失效
| 失效场景 | 示例 | 优化方案 |
|---|---|---|
| 对索引列使用函数 | WHERE YEAR(create_time) = 2026 | WHERE create_time >= '2026-01-01' AND create_time < '2027-01-01' |
| 隐式类型转换 | WHERE phone = 13800138000(varchar 列) | WHERE phone = '13800138000' |
| 前导模糊查询 | WHERE name LIKE '%张三' | WHERE name LIKE '张三%' 或用全文索引 |
| 索引列含 NULL | WHERE col IS NULL | 索引列设为 NOT NULL,用默认值替代 |
2.8 面试高频题速查
| 题目 | 核心答案 |
|---|---|
| MySQL 为什么用 B+ 树不用 B 树? | ① 非叶节点纯索引,树更矮,IO 更少;② 叶节点链表,范围查询高效;③ 查询路径固定,性能稳定;④ 数据集中存储,缓存利用率高 |
| B 树与 B+ 树核心区别? | ① 关键字:B 树分散所有节点,B+ 树仅叶节点;② 叶节点:B 树独立,B+ 树双向链表;③ 查询:B 树可在非叶节点返回,B+ 树必须到叶节点 |
| InnoDB 和 MyISAM 的 B+ 树区别? | InnoDB 有聚簇索引(数据与索引绑定),MyISAM 仅有非聚簇索引(索引与数据分离) |
| 什么是回表?如何避免? | 二级索引查到主键值后再查聚簇索引获取整行数据。避免方法:覆盖索引 |
| 为什么推荐自增主键? | 有序插入无需节点分裂,UUID 无序导致频繁分裂和碎片 |
| 最左前缀原则? | 复合索引查询必须从最左列开始匹配,跳过则索引失效 |
三、InnoDB 物理存储:从逻辑树到磁盘页
来源参考:InnoDB B+树页面分裂与合并:物理结构、机制与优化 - 华为云
上一章从逻辑层面 介绍了 B+ 树的分裂与合并。本章深入到 InnoDB 的物理存储层面,详细分析页面分裂与合并的实现机制、性能影响和优化策略------这是理解"为什么分表能提升性能"的关键。
3.1 物理存储四层结构
InnoDB 的 B+ 树通过多层结构映射在磁盘上:
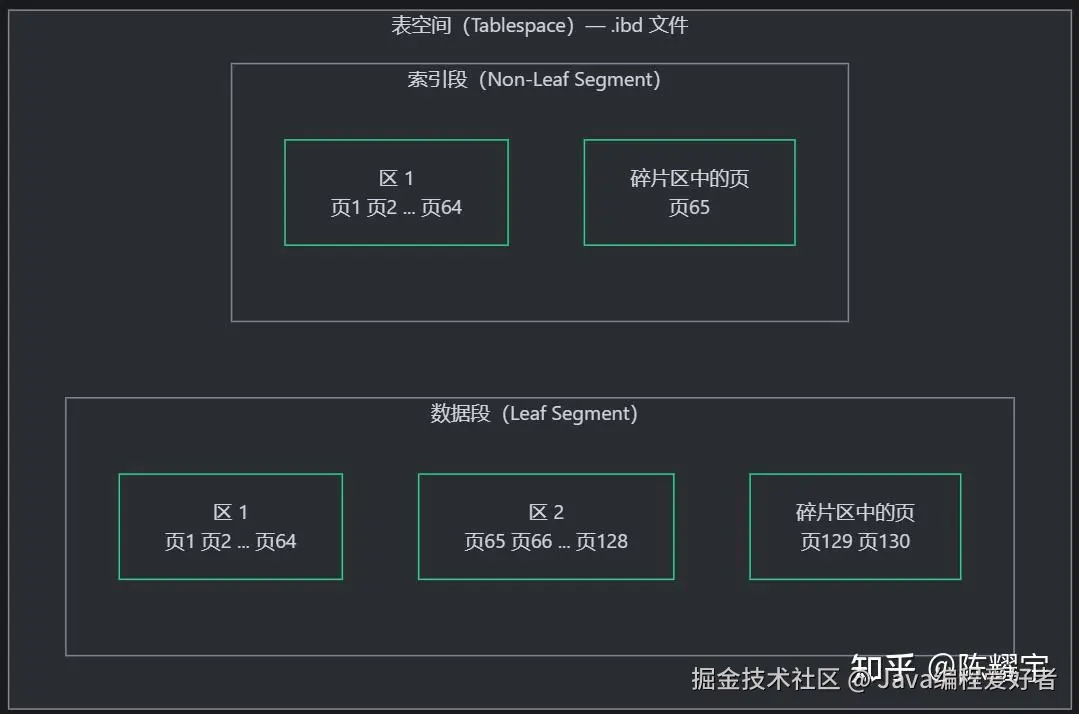
| 层次 | 大小 | 说明 |
|---|---|---|
| 表空间(Tablespace) | 不定 | 逻辑容器,每个表一个 .ibd 文件(独立表空间模式) |
| 段(Segment) | 不定 | 每棵 B+ 树使用 2 个段:索引段(非叶节点)+ 数据段(叶节点) |
| 区(Extent) | 1MB | 64 个连续页,空间分配以区为单位 |
| 页(Page) | 16KB | 基础 IO 单元,B+ 树每个节点对应一个页 |
InnoDB 页内部结构:
| 区域 | 大小 | 说明 |
|---|---|---|
| File Header | 38B | 页号、前后页指针、校验和、LSN |
| Page Header | 56B | 页类型、行数、空闲空间起点 |
| Infimum + Supremum | 26B | 虚拟最小/最大记录,构成页内链表哨兵 |
| User Records | 可变 | 实际数据行,按主键顺序组织为单向链表 |
| Free Space | 可变 | 未分配空间,插入时从此区域分配 |
| Page Directory | 可变 | 页内目录,二分查找加速页内搜索 |
| File Trailer | 8B | 校验和,防止页写入不完整 |
3.2 段与页的关系和区别
段和页是 InnoDB 物理存储中不同层次 的概念,容易混淆。核心区别:段是逻辑上的空间管理单位,页是物理上的 IO 操作单位。
段(Segment)是什么:
段是 InnoDB 为 B+ 树分配和管理空间的逻辑单位。每棵 B+ 树(即每个索引)使用 2 个段:
| 段类型 | 存储内容 | 为什么分开 |
|---|---|---|
| 数据段(Leaf Segment) | B+ 树的所有叶子节点页 | 叶子节点存储行数据,访问频率高,集中存储有利于范围扫描的顺序 IO |
| 索引段(Non-Leaf Segment) | B+ 树的所有非叶子节点页 | 非叶子节点存储索引键值+指针,通常常驻 Buffer Pool,集中存储有利于缓存命中 |
段的核心职责 :记录"哪些区/页属于我",并在需要时向表空间申请新的区或页。段本身不存储数据,数据存储在段所管理的页中。
页(Page)是什么:
页是 InnoDB 磁盘 IO 和数据存储的最小单位。每页默认 16KB,B+ 树的每个节点对应一个页。页内存储实际的行数据或索引键值。
段与页的关系:
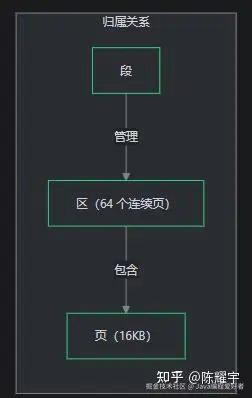
| 维度 | 段(Segment) | 页(Page) |
|---|---|---|
| 本质 | 逻辑空间管理单位 | 物理数据存储单位 |
| 大小 | 不固定,动态增长 | 固定 16KB |
| 数量关系 | 一个段管理多个区(每个区 64 页)+ 碎片页 | 一个页属于一个段(通过段的区或碎片区) |
| 存储内容 | 不直接存数据,只管理空间分配 | 存储行数据或索引键值 |
| IO 层面 | 不参与 IO 操作 | 是磁盘 IO 的最小单位 |
| 生命周期 | 随索引创建而创建,随索引删除而删除 | 随段分配而创建,随段释放而归还 |
| 分配粒度 | 以区(1MB)为单位向表空间申请 | 以页(16KB)为单位向段申请 |
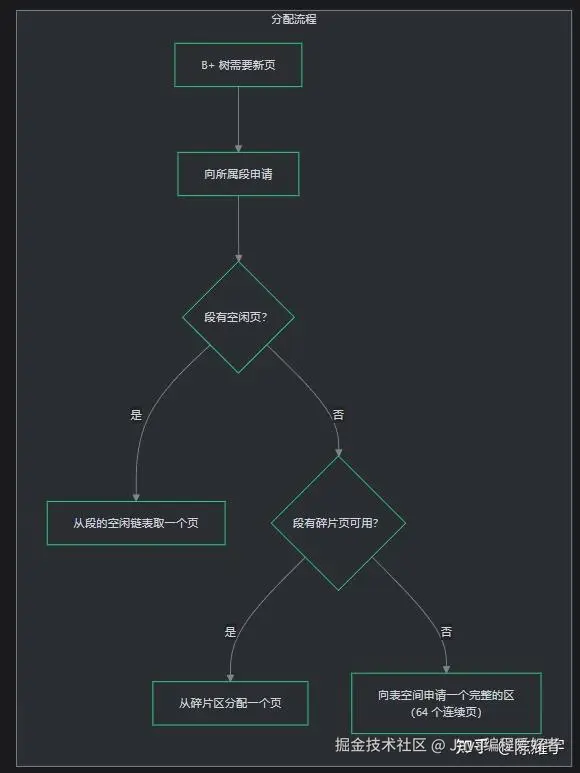
为什么需要段这个中间层?
没有段的话,每个页都直接向表空间申请,会产生严重的管理开销和碎片。段作为中间层提供三个关键能力:
- 局部性:段优先从自己已有的区中分配页,保证同一 B+ 树的页在物理上尽量连续,提升范围扫描性能
- 批量分配:段以区(1MB = 64 页)为单位申请空间,减少频繁向表空间申请的开销
- 碎片页管理:段初期不需要完整区时,可以从碎片区借用单个页,避免浪费空间
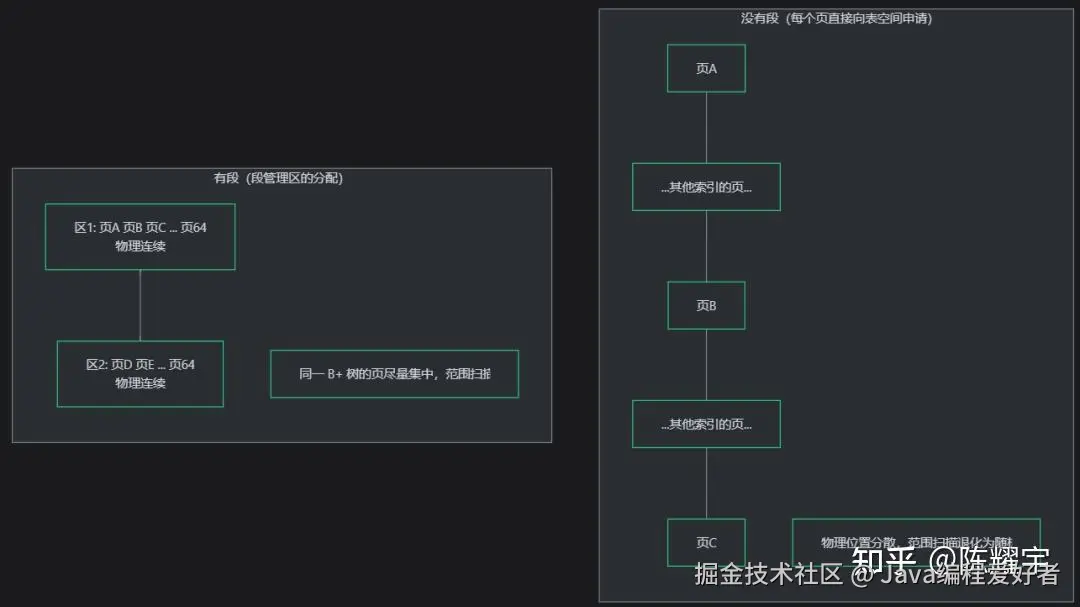
有段(段管理区的分配)
区1: 页A 页B 页C ... 页64物理连续
区2: 页D 页E ... 页64物理连续
同一 B+ 树的页尽量集中,范围扫描高效
没有段(每个页直接向表空间申请)
页A
...其他索引的页...
页B
...其他索引的页...
页C
物理位置分散,范围扫描退化为随机 IO
碎片区的作用:
当段刚创建、数据量很少时,分配一个完整区(1MB)会浪费空间。InnoDB 的解决方案是碎片区(Fragment Extent) :
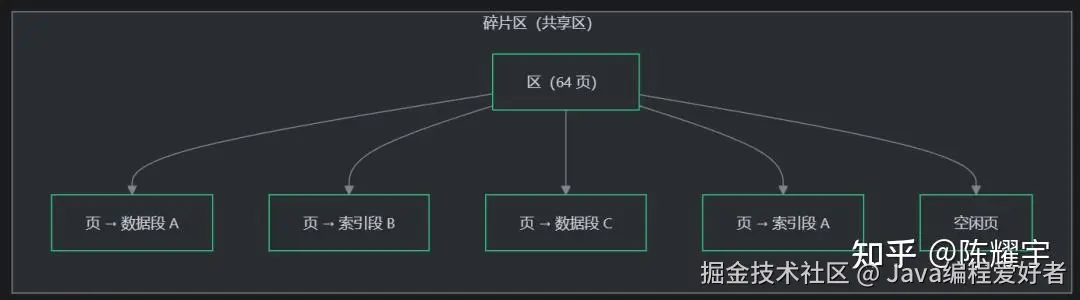
| 阶段 | 分配策略 | 原因 |
|---|---|---|
| 段数据量 < 32 页 | 从碎片区借用单个页 | 避免分配完整区浪费空间 |
| 段数据量 ≥ 32 页 | 申请专属的完整区 | 32 页 = 半个区,此时分配完整区不再浪费,且专属区保证物理连续 |
3.3 页面分裂机制
当页达到填充上限时触发分裂,主要场景:
- 插入满页(INSERT) :新记录需按序插入但页面空闲空间不足
- 更新扩容(UPDATE) :更新存量记录,数据长度增加导致页无法容纳(如 VARCHAR 填充)
分裂详细流程:
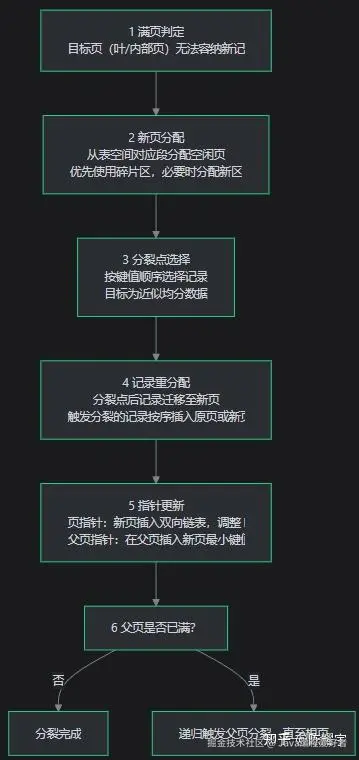
顺序插入 vs 随机插入的分裂差异:
| 维度 | 顺序插入(AUTO_INCREMENT PK) | 随机插入(UUID / Hash PK) |
|---|---|---|
| 插入位置 | 始终在最左页或最右页 | 随机发生在任意页面位置 |
| 分裂时记录迁移 | 仅迁移少量记录,原页维持满页 | 页面中部分裂,约 50% 记录需移动 |
| 页填充率 | ~15/16(约 94%) | ~50% |
| 分裂频率 | 低 | 高,且进一步加剧碎片化 |
| 物理有序性 | 有序 | 无序 |
关键结论:插入模式从根本上决定了页分裂频率、存储密度(页填充率)以及索引碎片化程度。顺序键插入(如 AUTO_INCREMENT)在降低分裂频率与维持高存储密度方面具有显著优势。
3.4 页面合并机制
页面合并是页面分裂的互补操作,通过合并可以释放低填充页占用的物理存储,提升页内有效数据占比。
触发条件 :页内记录占比低于 MERGE_THRESHOLD(默认 50%)时触发,主要场景:
- 删除(DELETE) :物理删除记录并释放页面内空间
- 更新缩容(UPDATE) :更新导致记录物理长度降低,降低页面填充率
合并详细流程:
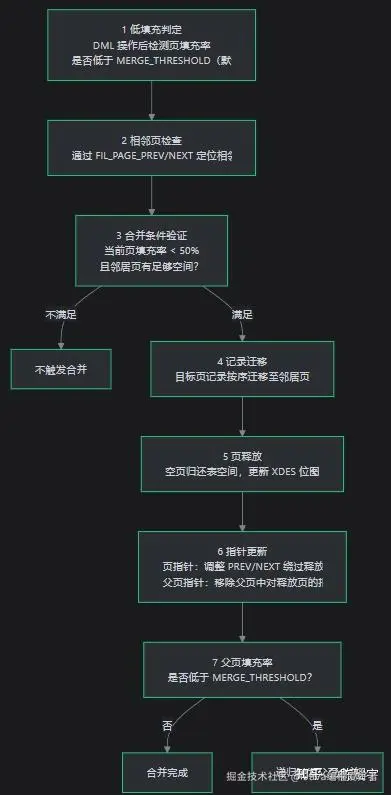
页面合并的效果与局限:
| 维度 | 说明 |
|---|---|
| 优势 | 减少内部碎片,提升页密度,降低磁盘空间占用,使缓冲池缓存更多有效页面 |
| 局限 1 | 内部碎片清理不彻底------仅当页面填充率 < 50%(默认)时触发,填充率长期大于 50% 的碎片无法回收 |
| 局限 2 | 无法解决外部碎片化(物理存储无序),页面合并后释放页再复用时,可能导致外部碎片化加剧 |
3.5 分裂/合并的性能影响
| 影响维度 | 详细说明 |
|---|---|
| 索引碎片化(内部碎片) | 页面分裂和合并都会带来页内空间浪费:随机插入触发分裂导致 50% 填充率;合并阈值限制导致删除操作的残留碎片不能马上回收 |
| 索引碎片化(外部碎片) | 页面分裂时新页随机分配会破坏物理连续性;页面合并时释放页会加剧物理离散性。逻辑连续的页在磁盘物理位置上离散,范围扫描性能劣化 |
| I/O 操作增加 | 读放大:内部碎片化导致需要更多页来存储相同数据。随机 I/O:外部碎片化打破页面物理连续性,影响 InnoDB 预读效率,顺序扫描退化为随机 IO |
| 缓冲池效率下降 | 碎片页与高密度页占用相同的缓冲池槽位,碎片页过多时缓冲池内大量空间空闲,命中率降低 |
| 锁竞争 | 分裂/合并需短暂持有闩锁(Latch),高并发写入时可能引发竞争 |
外部碎片化示意:
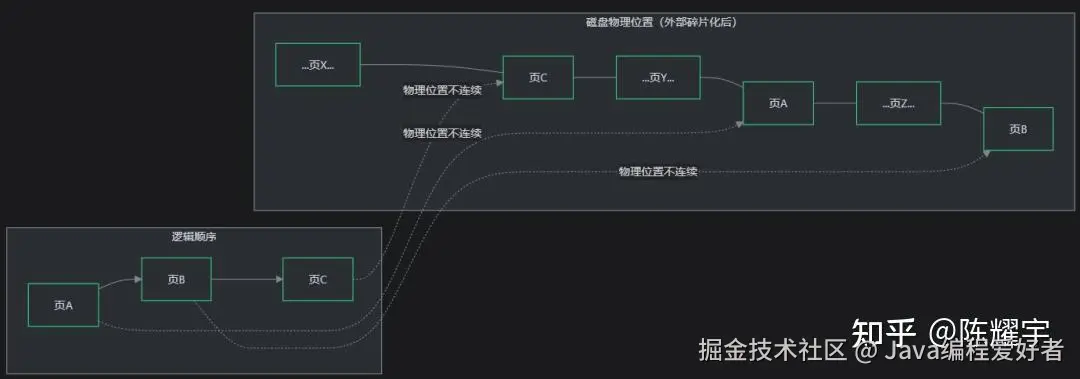
3.6 四大优化策略
策略 1:主键设计优化(最重要)
| 主键类型 | 页填充率 | 分裂频率 | 碎片化程度 | 推荐度 |
|---|---|---|---|---|
| AUTO_INCREMENT(INT/BIGINT) | ~94% | 低 | 低 | 最推荐 |
| 有序 UUID(UUIDv6/v7) | 中等 | 中等 | 中等 | 妥协方案 |
| 随机 UUID(UUIDv4)/ Hash | ~50% | 高 | 严重 | 避免使用 |
分布式系统必须使用 UUID 时,采用时序 UUID(UUIDv1/v6/v7)+ BINARY(16) 存储 + 字节重排(时间戳前置),效果显著优于完全随机键,但仍无法达到纯自增主键的性能水平。
策略 2:调整 innodb_fill_factor
| 参数 | 作用 | 代价 | 适用场景 |
|---|---|---|---|
| innodb_fill_factor | 控制索引创建/重建过程中的页填充百分比 | 页初始密度低,范围扫描初始性能下降,空间膨胀 | 预期重建后存在高频随机 DML 操作的表,可延缓页面首次分裂 |
默认行为:未指定时叶页初始化填充率为 100%,存储密度最大化,仅保留 InnoDB 默认强制预留的 1/16 空间。适用于以顺序插入为主或重建后只读/低频更新的表。
策略 3:表重组(定期重建)
对于有随机主键或高频 DML 的表,长期运行会导致碎片化严重,需定期重建:
ini
OPTIMIZE TABLE table_name;
ALTERTABLE table_name ENGINE=InnoDB;
ALTERTABLE table_name FORCE;| 效果 | 说明 |
|---|---|
| 消除内部碎片 | 按序生成紧凑页 |
| 消除外部碎片 | 尽可能保证新的 .ibd 文件内页面物理有序 |
| 注意 | 大表重建可能导致持锁时间较长,可使用 pt-online-schema-change 或 gh-ost 降低锁影响 |
策略 4:行格式选择
| 行格式 | 大字段处理方式 | 分裂影响 | 推荐 |
|---|---|---|---|
| DYNAMIC / COMPRESSED | 大字段完全存储到溢出页,B+ 树页仅存 20 字节指针 | 减少因更新大字段引发的页面分裂 | 推荐(MySQL 8 默认) |
| COMPACT / REDUNDANT | B+ 树页存储大字段前缀(≤768 字节)+ 溢出页指针 | 字段前缀频繁更新时易触发分裂 | 避免用于大字段频繁更新场景 |
3.7 为什么分表能解决这些问题
理解 InnoDB 页面分裂/合并机制,就能理解为什么分表能有效提升性能:
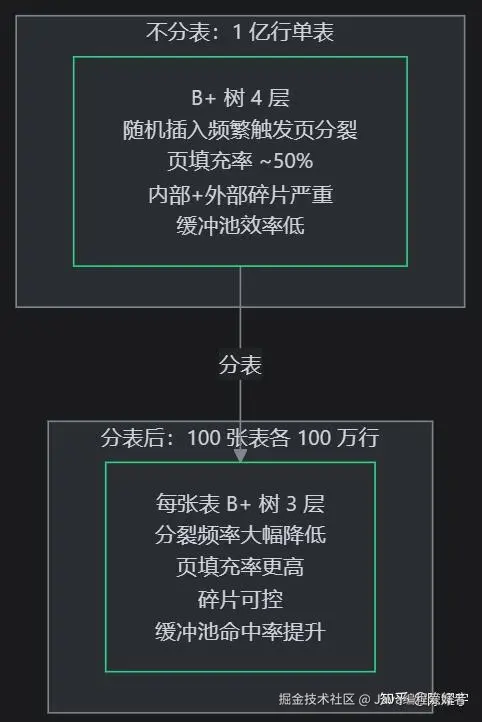
| 维度 | 不分表(1 亿行) | 分表后(100 × 100 万行) |
|---|---|---|
| B+ 树层级 | 4 层(多 1 次磁盘 IO) | 3 层 |
| 页分裂频率 | 高(随机插入命中满页概率大) | 低(单表数据少,满页概率小) |
| 页填充率 | ~50%(随机插入) | ~94%(AUTO_INCREMENT 顺序插入) |
| 碎片化程度 | 严重(分裂频繁+合并不彻底) | 轻微 |
| 缓冲池效率 | 低(碎片页浪费缓存槽位) | 高(紧凑页缓存更多有效数据) |
| DDL 耗时 | 加索引可能 30 分钟+ | 每张表数秒,可分批执行 |
四、单表到底能存多少行?
4.1 B+ 树层级与行数计算
计算推导:
makefile
3层B+树能存储的最大行数:
第1层(Root):1个页=1170个指针
第2层(Branch):1170个页×1170个指针=1,368,900个指针
第3层(Leaf):1,368,900个页×16行/页≈2190万行
4层B+树能存储的最大行数:
第4层(Leaf):1170×1170×1170×16≈256亿行| B+ 树层级 | 最大行数(理论值) | 磁盘 IO 次数 |
|---|---|---|
| 2 层 | ~1.8 万行 | 2 次 |
| 3 层 | ~2190 万行 | 3 次 |
| 4 层 | ~256 亿行 | 4 次 |
注意:实际行数取决于单行大小。如果单行更大(如含 varchar(207)),每页存储的行数更少,3 层能容纳的行数也会相应减少。1000 万~5000 万行处于 3 层到 4 层的过渡区间。
4.2 多一层就多一次磁盘 IO
B+ 树的每一层对应一次页读取。查询过程:
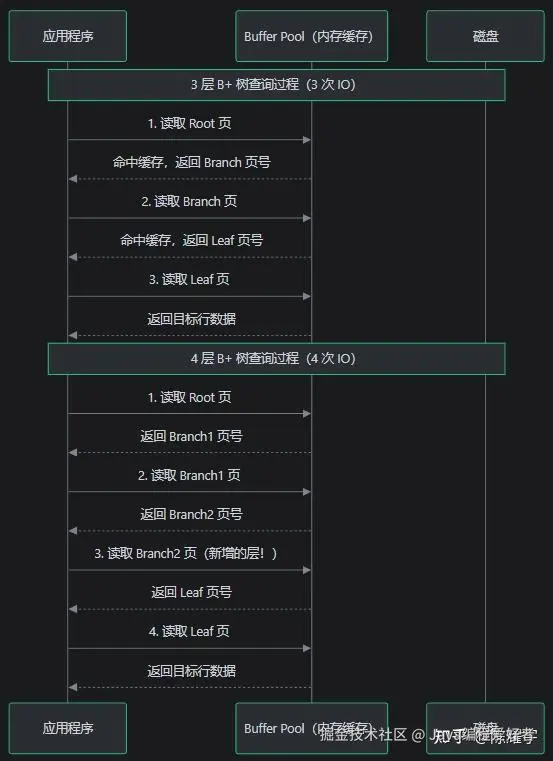
关键点:
- Root 页通常常驻内存(Buffer Pool 命中率高),第 1 次 IO 通常是内存读取
- Branch 页在热数据场景下也有较高缓存命中率
- Leaf 页 数量巨大(百万级),缓存命中率低,大概率需要磁盘 IO
- 每多一层,就多一次可能需要磁盘 IO 的页读取。磁盘随机 IO 一次约 10ms(机械硬盘)或 0.1ms(SSD)
4.3 性能影响量化
| 场景 | B+ 树层数 | 磁盘 IO 次数 | 机械硬盘延迟 | SSD 延迟 |
|---|---|---|---|---|
| < 1000 万行 | 3 层 | 2~3 次 | 20~30ms | 0.2~0.3ms |
| 1000 万 ~ 5000 万行 | 3~4 层 | 3~4 次 | 30~40ms | 0.3~0.4ms |
| > 5000 万行 | 4 层+ | 4+ 次 | 40ms+ | 0.4ms+ |
Buffer Pool 命中时为内存读取(微秒级),未命中时才需要磁盘 IO。数据量越大,Buffer Pool 命中率越低,磁盘 IO 越频繁。
4.4 单表的其他瓶颈
- DDL 操作困难:单表加索引、改结构可能耗时数小时并长时间锁表
- 备份恢复慢:单表过大,备份/恢复极为耗时
- 写入瓶颈:单机 CPU/磁盘 IO 有上限
- 连接数限制:MySQL 默认 max_connections=151
4.5 适用边界:什么时候该分表
- 不需要分表:单表 < 1000 万行,通过索引优化、读写分离、缓存即可解决
- 必须分表:单表 > 5000 万行,TPS/QPS 超过单库承载上限
五、分库与分表:概念、痛点与选型
5.1 分库 vs 分表
分库:将原本存储在一个数据库实例中的数据,按一定规则分散到多个数据库实例中。每个数据库实例独立部署,拥有独立的连接池、Buffer Pool、CPU 和磁盘 IO。
分表 :将原本存储在一张表中的数据,按一定规则分散到同一数据库内的多张物理表中。这些表结构相同,只是表名不同(如 user_0、user_1、user_2)。
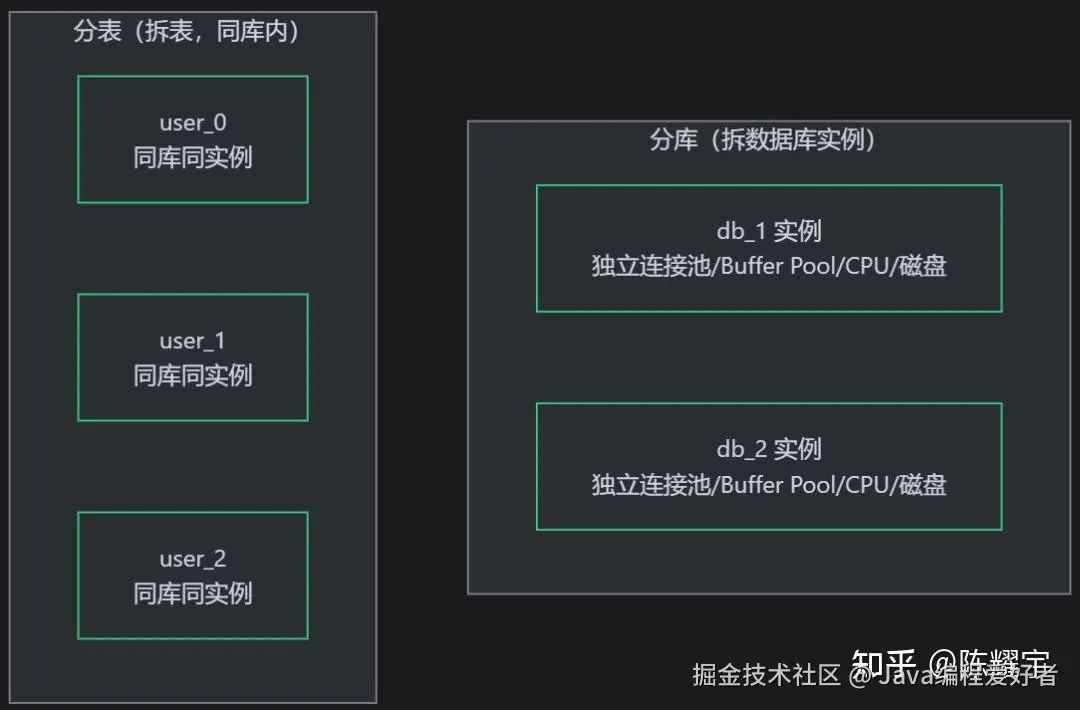
| 维度 | 分库 | 分表 |
|---|---|---|
| 拆分对象 | 数据库实例 | 物理表 |
| 资源隔离 | 完全隔离(连接池、Buffer Pool、CPU、磁盘各自独立) | 共享资源(同一实例) |
| 解决瓶颈 | 连接数瓶颈、IO 瓶颈、CPU 瓶颈 | 单表数据量过大导致的查询慢 |
| 网络开销 | 跨库查询需网络通信 | 同库查询,无额外网络开销 |
| 事务支持 | 跨库事务复杂(需分布式事务) | 同库内可用本地事务 |
5.2 分库解决的四大痛点
痛点 1:连接数瓶颈
单库3000连接上限
50台应用服务器×50连接/台=2500连接→接近上限
100台应用服务器×50连接/台=5000连接→超限!必须分库痛点 2:磁盘 IO 瓶颈 --- 单实例磁盘 IO 吞吐量有上限,分库后每个库实例使用独立磁盘。
痛点 3:CPU 瓶颈 --- 单实例 CPU 处理复杂查询可能满载,分库后每个库实例独立 CPU。
痛点 4:Buffer Pool 竞争 --- 单实例 Buffer Pool 被所有表共享,分库后每个库实例独立 Buffer Pool,业务模块间互不干扰。
5.3 分表解决的四大痛点
| 痛点 | 说明 | 分表效果 |
|---|---|---|
| 单表数据量过大 | B+ 树层级从 3 层增长到 4 层,每次查询多一次磁盘 IO | 1 亿行拆为 100 张表,每张表仅 100 万行,B+ 树稳定在 3 层 |
| DDL 操作耗时过长 | 单表 5000 万行加索引可能耗时 30 分钟以上 | 每张表 50 万行,加索引仅需数秒,且可分批执行 |
| 索引维护成本高 | 单表索引体积大,插入/删除时维护开销大 | 每张表的索引更小,维护更快 |
| 数据备份恢复慢 | 单表过大导致 mysqldump 备份耗时过长 | 可并行备份/恢复各分表,速度大幅提升 |
5.4 什么时候分库,什么时候分表
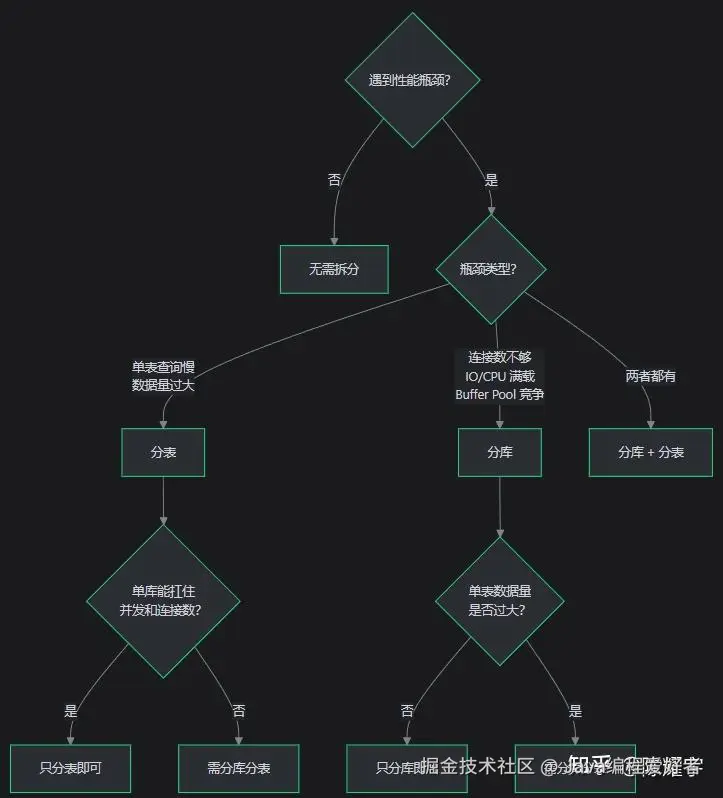
| 场景 | 瓶颈表现 | 方案 | 示例 |
|---|---|---|---|
| 用户表 5000 万行,查询变慢但 QPS 不高 | 单表数据量过大 | 只分表 | user_0~user_99 |
| 10 个业务模块共用 1 个库,连接数不够 | 连接数瓶颈 | 只分库 | user_db、order_db、product_db |
| 订单表日增百万,查询慢且写入 QPS 高 | 数据量 + 并发双重瓶颈 | 分库分表 | order_db_0.order_0~order_db_3.order_24 |
| 日志表只写不读,写入 QPS 极高 | 写入瓶颈 | 分库分表 或换 LSM | 日志库 + 按时间分表 |
| 配置表几百行,查询频繁 | 无瓶颈 | 不拆分 | 保持单表 |
量化参考标准:
| 指标 | 只分表 | 只分库 | 分库分表 |
|---|---|---|---|
| 单表行数 | > 1000 万 | < 500 万 | > 1000 万 |
| 单库 QPS | < 2000 | > 2000 | > 2000 |
| 单库连接数 | < 3000 | > 3000 | > 3000 |
| 单库数据量 | < 100GB | > 100GB | > 100GB |
5.5 分库分表带来的代价
| 代价 | 分库 | 分表 | 说明 |
|---|---|---|---|
| 跨库/跨表 JOIN | 严重 | 中等 | 分库后无法直接 JOIN,需应用层组装 |
| 分布式事务 | 严重 | 轻微 | 分库后跨库事务需 XA/TCC/Saga |
| 运维复杂度 | 高 | 中 | 多实例监控、备份、升级 |
| 全局唯一 ID | 需要 | 需要 | 自增主键不再全局唯一 |
| 数据迁移 | 复杂 | 复杂 | 扩容时需重新分布数据 |
| 跨库/跨表查询 | 全库扫描 | 全表扫描 | 不带分片键的查询性能极差 |
六、拆分维度
6.1 垂直拆分 vs 水平拆分
垂直拆分:按 列/业务模块 切分
水平拆分:按 行/数据记录 切分垂直分表(按列拆分) :
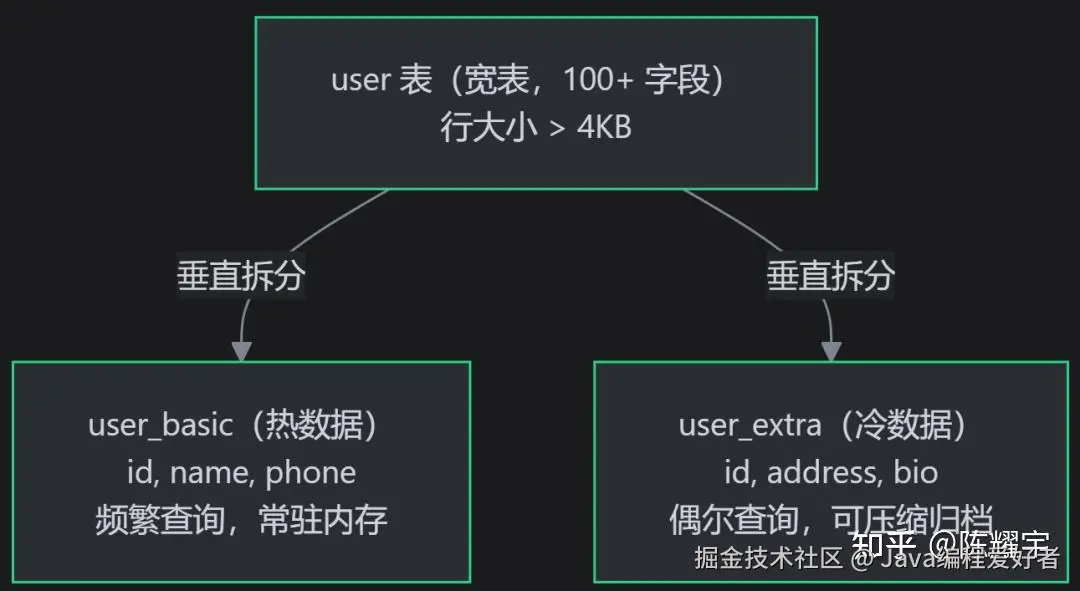
适用场景:单行数据过大(含 TEXT/BLOB),热冷字段访问频率差异大。
垂直分库(按业务模块拆分) :
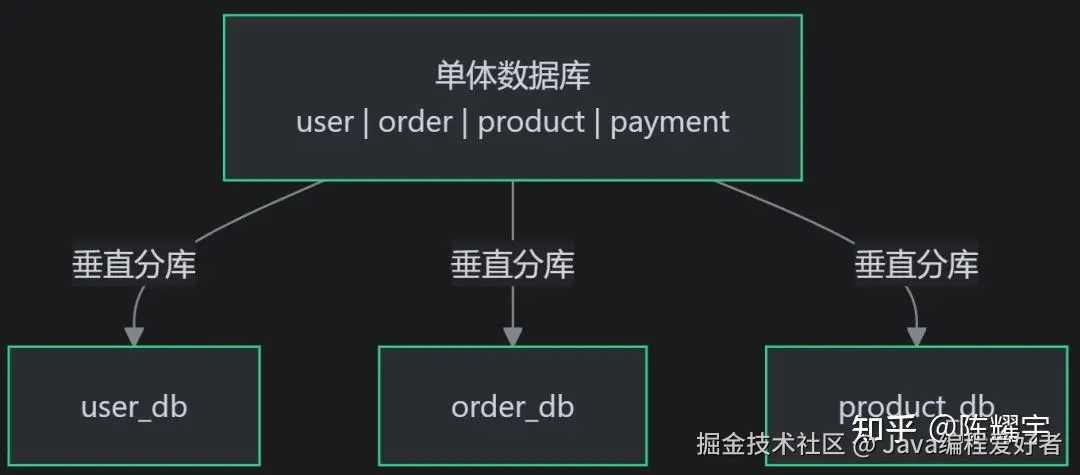
适用场景:业务模块耦合严重,单库连接数/IO/CPU 瓶颈。
水平分表(按行拆分,单库内) :
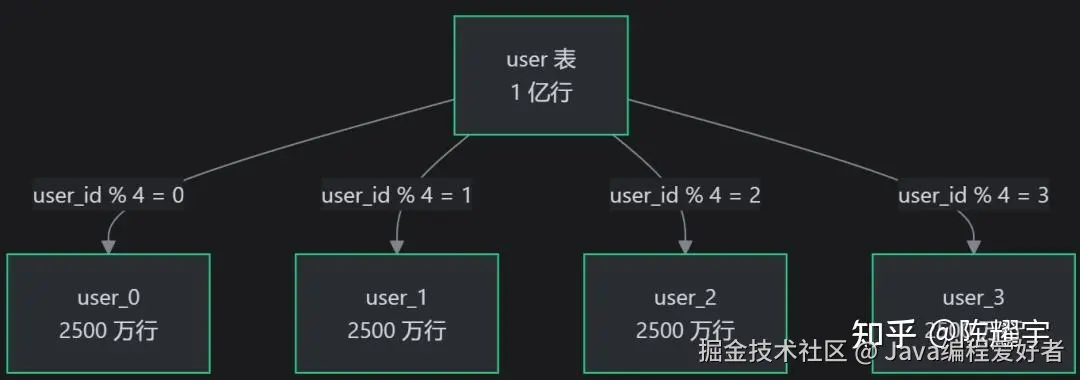
适用场景:单表数据量过大,但单库连接数/IO 尚可承受。
水平分库分表(按行拆分,多实例) :
适用场景:数据量 + 并发双重瓶颈。
6.2 四种拆分方式对比
| 方式 | 解决问题 | 复杂度 | 典型场景 |
|---|---|---|---|
| 垂直分表 | 单行数据过大 | 低 | 热/冷字段分离 |
| 垂直分库 | 单库连接数/IO 瓶颈 | 中 | 业务模块解耦 |
| 水平分表 | 单表数据量过大 | 中 | 同库内拆行 |
| 水平分库分表 | 数据量 + 并发双重瓶颈 | 高 | 海量数据高并发 |
七、分片策略(水平拆分核心)
7.1 分片键选择原则
分片键(Shard Key)是分表成败的关键,必须遵循:
- 高频查询覆盖:分片键必须覆盖 90%+ 的查询场景,避免全分片扫描
- 数据均匀分布:分片键取值必须均匀,避免用性别、状态等低基数字段
- 不可变更:分片键值一旦写入不可修改,否则需跨分片迁移数据
常见分片键 :user_id、order_id、account、shop_id
7.2 五种分片策略
策略一:Hash 取模分片
ini
table_index = hash(shard_key) % N
示例:hash("player_abc") % 100 = 52 → 写入 account_login52| 优点 | 缺点 |
|---|---|
| 数据分布非常均匀 | 扩容极其复杂(N 变化后所有数据需重新分布) |
| 实现简单直观 | 不支持范围查询 |
| 查询路由快速(O(1) 计算) | 扩容时数据迁移量大(几乎全量迁移) |
扩容问题 :原来 4 张表 hash(key) % 4,扩容到 8 张表 hash(key) % 8,约 75% 的数据需要迁移。
适用场景:分表数量固定、不需要频繁扩容的场景(如游戏按区服分表)。
策略二:范围分片(Range Sharding)
user_id1~1000万→user_0
user_id1000万~2000万→user_1
user_id2000万~3000万→user_2| 优点 | 缺点 |
|---|---|
| 扩容简单(新增范围即可,无需迁移历史数据) | 容易数据倾斜和热点(最新分片承担 90% 读写) |
| 支持范围查询 | 数据分布不均匀 |
| 便于数据归档 | 分片键必须是递增型 |
适用场景:日志表、订单流水表等时间序列数据。
策略三:一致性哈希分片(Consistent Hashing)
将分片键和分片节点都映射到 0~2^32 的哈希环上,数据顺时针路由到最近的节点。引入虚拟节点解决数据倾斜。
| 优点 | 缺点 |
|---|---|
| 扩容时只需迁移相邻节点数据(影响范围小) | 实现复杂 |
| 数据分布较均匀(配合虚拟节点) | 范围查询不支持 |
| 平滑扩缩容 | 节点数少时可能分布不均 |
扩容对比:Hash 取模 4→8 张表需迁移 ~75% 数据;一致性哈希 4→5 张表只需迁移 ~25%。
适用场景:缓存分片(Redis Cluster)、需要频繁扩缩容的场景。
策略四:枚举/查表分片(Directory-Based)
维护一张分片映射表,记录每条数据属于哪个分片。查询时先查映射表,再路由到目标分片。
| 优点 | 缺点 |
|---|---|
| 灵活度最高,可任意调整映射关系 | 多一次查询(映射表查询),有性能开销 |
| 扩容只需修改映射表 | 映射表本身成为单点和瓶颈 |
适用场景:按地域、按业务线分片,分片规则不规则。
策略五:复合分片
组合多种分片策略,先按一个维度粗分,再按另一个维度细分。
erlang
第一层:按 ZoneId 分库(枚举分片)
第二层:按 UserId 分表(Hash 取模)
最终:db_1.table_3, db_2.table_7 ...| 优点 | 缺点 |
|---|---|
| 精细控制数据分布 | 实现和运维复杂度最高 |
| 可同时满足多种查询模式 | 跨分片查询更复杂 |
适用场景:超大规模系统(如游戏多区服 + 多分表)。
7.3 五种策略总对比
| 策略 | 数据均匀性 | 扩容难度 | 范围查询 | 实现复杂度 | 典型场景 |
|---|---|---|---|---|---|
| Hash 取模 | 优 | 高(几乎全量迁移) | 不支持 | 低 | 游戏分表、用户表 |
| 范围分片 | 差(易倾斜) | 低(新增区间) | 支持 | 低 | 日志、订单流水 |
| 一致性哈希 | 良 | 低(相邻迁移) | 不支持 | 高 | 缓存、弹性扩缩容 |
| 枚举/查表 | 可控 | 低(改映射) | 取决于规则 | 中 | 地域分片、业务线分片 |
| 复合分片 | 可控 | 中 | 部分支持 | 最高 | 超大规模多维度 |
八、分表后的核心挑战
8.1 分布式 ID 生成
分表后自增主键不再全局唯一,需要分布式 ID 方案:
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| UUID | 随机生成 128 位 | 简单,无需协调 | 无序,索引性能差,存储大 |
| Snowflake 雪花算法 | 时间戳+机器ID+序列号 | 有序,高性能 | 依赖时钟,时钟回拨有问题 |
| 号段模式 | 数据库预分配号段 | 简单可靠 | 依赖数据库,有号段浪费 |
| Redis INCR | Redis 原子自增 | 高性能 | 依赖 Redis 可用性 |
8.2 跨分片查询
不带分片键的查询会触发全分片扫描,性能急剧下降:
sql
-- 带分片键:O(1) 定位
SELECT*FROM account_login52 WHERE Account ='xxx';
-- 不带分片键:全分片扫描,100 张表全查一遍
SELECT*FROM account_login*WHERE UserId =12345;解决方案:
| 方案 | 说明 |
|---|---|
| 建立反向索引表 | 维护 UserId → Account 的映射,先查映射再查分表 |
| 冗余宽表 | 将常用查询字段冗余到 ES 或汇总表 |
| 强制带分片键查询 | 业务层限制查询必须带分片键 |
8.3 跨分片事务
分表后无法使用本地事务保证跨表一致性:
| 方案 | 一致性 | 性能 | 复杂度 |
|---|---|---|---|
| XA 两阶段提交 | 强一致 | 低(锁等待长) | 中 |
| TCC(Try-Confirm-Cancel) | 最终一致 | 高 | 高 |
| 本地消息表 | 最终一致 | 中 | 中 |
| Saga 长事务 | 最终一致 | 高 | 高 |
8.4 扩容与数据迁移
Hash 取模扩容是最复杂的场景,常见方案:
| 方案 | 停机时间 | 复杂度 |
|---|---|---|
| 双倍扩容(停机迁移) | 长 | 低 |
| 预分片(一次性建好 1024 张表,映射到少量物理库) | 无 | 中 |
| 一致性哈希平滑迁移 | 短 | 高 |
| 成倍翻倍法(4→8→16,每次翻倍只迁移一半) | 短 | 中 |
预分片方案详解(推荐):
scss
逻辑分表:1024 张(一次性建好)
物理库:4 个(初期每个库承载 256 张逻辑表)
扩容时:4 库 → 8 库
只需将每个库的 128 张逻辑表迁移到新库,无需重新计算 Hash
因为 hash(key) % 1024 的结果不变,只是逻辑表到物理库的映射变了九、分表方案选型
9.1 三类实现方案对比
| 方案 | 代表 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 客户端分片(应用层) | ShardingSphere-JDBC | 无额外网络开销,性能最高 | 分片规则分散,多语言需各自实现 | 单一技术栈、性能要求极高 |
| 代理层分片 | ShardingSphere-Proxy、MyCat | 多语言透明接入,集中管理 | 多一跳网络转发,代理需高可用 | 多语言、大规模集群 |
| 分布式数据库 | TiDB、OceanBase | 完全透明,自动分片 | 成本高,厂商绑定 | 不想维护分片架构 |
9.2 选型决策树
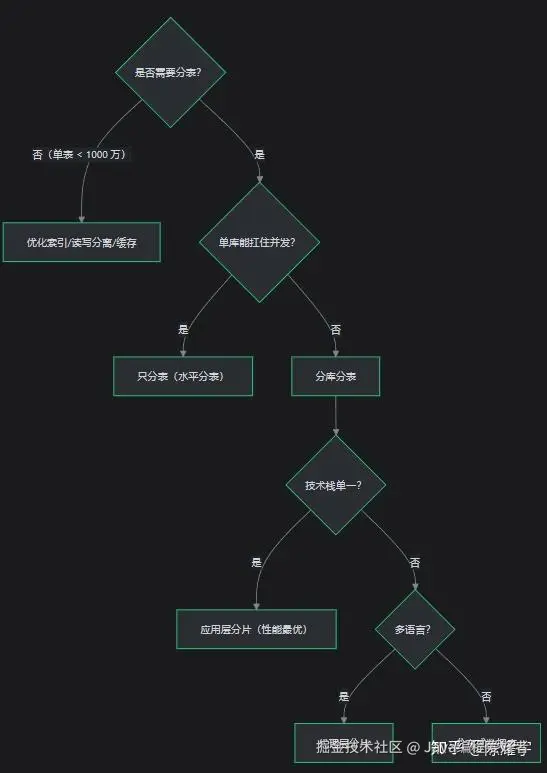
十、最佳实践总结
- 能不分就不分:优先索引优化、读写分离、缓存,分表是最后手段
- 分片键决定成败:覆盖 90%+ 查询、数据均匀、不可变
- 预分片优于后分片:一次性建好足够多的逻辑表,避免扩容时重新 Hash
- 代理键做主键:用无业务含义的自增 int 做聚簇主键,业务查询走二级索引
- 避免跨分片查询:建立反向索引、冗余宽表、强制带分片键
- 扩容方案提前设计:Hash 取模用成倍翻倍法或预分片,范围分片直接加区间
- 监控数据倾斜:定期检查各分片数据量,发现倾斜及时调整