博主介绍:程序喵大人
- 35 - 资深C/C++/Rust/Android/iOS客户端开发
- 10年大厂工作经验
- 嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手
- 《C++20高级编程》《C++23高级编程》等多本书籍著译者
- 更多原创精品文章,首发gzh,见文末
- 👇👇记得订阅专栏,以防走丢👇👇
😉C++基础系列专栏
😃C语言基础系列专栏
🤣C++大佬养成攻略专栏
🤓C++训练营
👉🏻个人网站
设想一个典型的工程场景:在开发高性能后台服务时,我们通常需要统计系统处理的请求总量。最直观的方法是声明一个全局变量 int counter = 0,每当处理完一个请求,就执行一次自增 ++counter。
在单线程环境下,这套逻辑无可挑剔,一千万次请求对应的一定是精确的一千万。无论程序在什么样的 CPU 架构上运行,计算结果都具备确定性。
然而,当我们引入多线程来分担计算压力时,结果就会变得非常诡异。假设我们创建了两个工作线程,每个线程负责累加 10 万次。按照常理,最终的 counter 应该等于 20 万。
但实际运行这个程序,你会得到诸如 187462、193781 或者 191055 这样毫无规律的值------它不仅每次都在变,而且总是达不到预期的 20 万。
cpp
#include <iostream>
#include <thread>
// 声明全局变量,用作全局计数器
int counter = 0;
// 工作线程的入口函数
void Worker() {
// 每个线程各自循环累加 10 万次
for (int i = 0; i < 100000; ++i) {
// 自增操作,表面上是一行代码,实则非原子
++counter;
}
}
int main() {
// 启动第一个工作线程
std::thread t1(Worker);
// 启动第二个工作线程
std::thread t2(Worker);
// 主线程等待线程 t1 执行结束
t1.join();
// 主线程等待线程 t2 执行结束
t2.join();
// 打印最终的累加结果
std::cout << counter << std::endl;
}这段代码在编译时不会产生任何语法错误或警告信息,运行时也不会发生崩溃或异常。但它的计算结果是完全错误的,且表现出随机性。
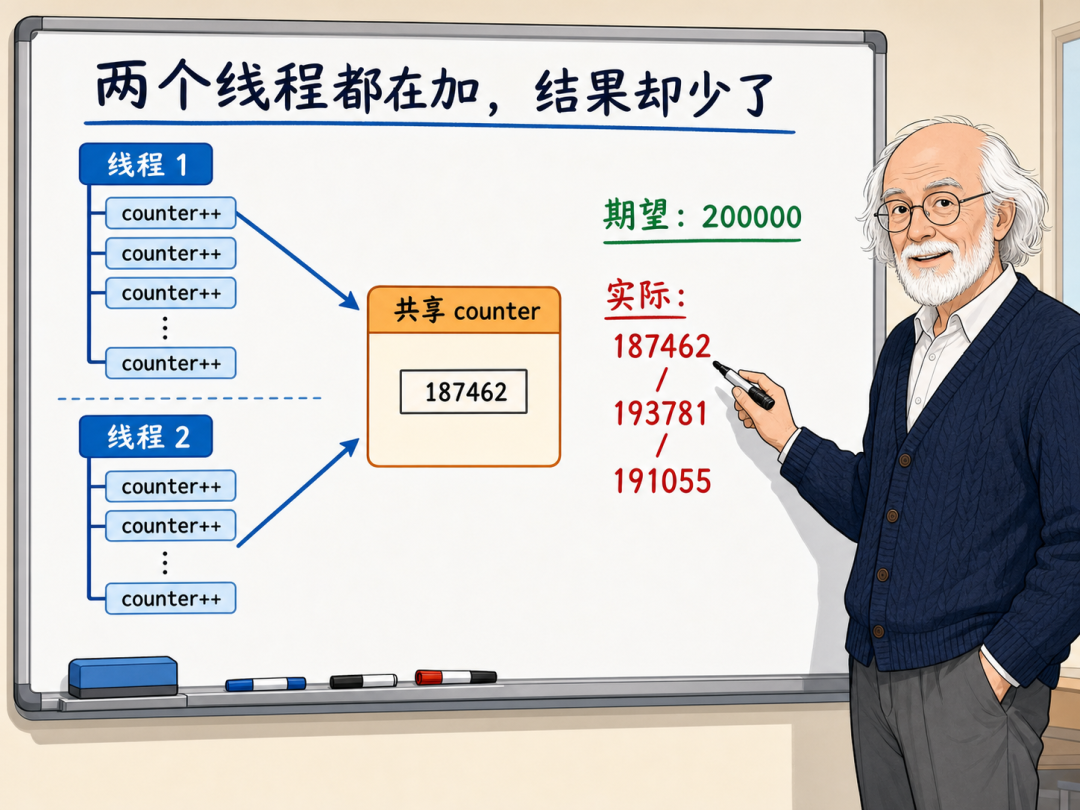
这种不破坏程序运行状态但悄悄破坏数据正确性的错误,是并发编程中最典型、最难以定位的一种情况。
++counter 底层执行步骤
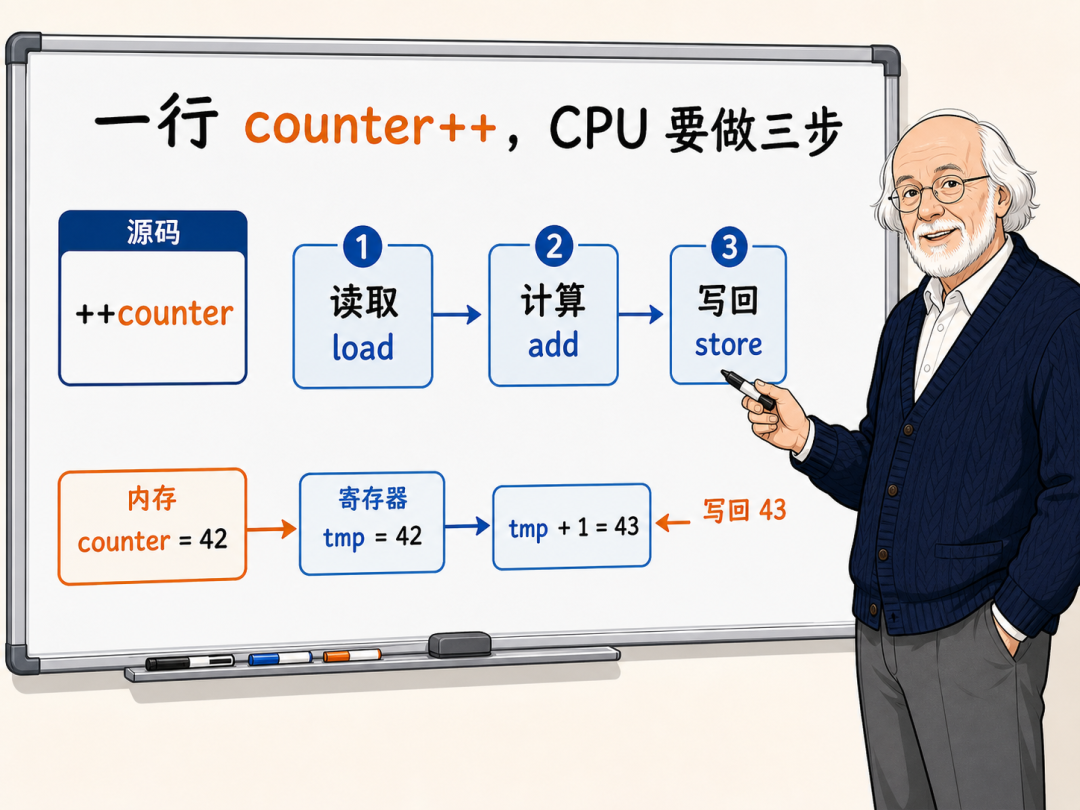
从 C++源码上看,++counter 是一行极为简单的操作。编译器在构建时甚至不需要生成任何复杂的类型转换。然而在 CPU 看来,这个看似单一的自增动作,其实包含了三个完全独立的物理步骤。
在 x86-64 架构下,针对非原子的全局变量自增,编译器生成的汇编指令通常会被拆分为:
cpp
mov eax, DWORD PTR counter[rip]
add eax, 1
mov DWORD PTR counter[rip], eax这三条汇编指令分别对应 CPU 执行的三个物理阶段:
- 读取阶段(Load):
CPU 将内存中变量 counter 的当前值加载到当前核心的通用寄存器(如 eax)中。如果该变量尚未缓存在当前核心的缓存行中,则需要触发缓存行填充。
- 修改阶段(Modify):
CPU 在寄存器内部将该值执行加 1 计算。这是一个纯粹的算术逻辑单元操作,运行在 CPU 核心内部,不涉及总线交互。
- 写回阶段(Store):
CPU 将计算后的新值从寄存器写回到通用缓存中,并根据一致性协议在合适的时候刷新到对应的物理内存地址。
在单线程模型中,这三条汇编指令是一气呵成执行完的,中途不会受到任何打扰。
但在多线程环境下,操作系统通过分时调度在核心间频繁切换线程,CPU 也不承诺会原子性地执行完这一串指令后再去调度其他执行流。由于现代多核处理器在硬件层面是并行运行的,这三条指令完全有可能在半路被其他 CPU 核心执行的执行流插足。
当多个核心同时对同一内存地址进行读取、修改、写回操作时,硬件底层的时序重叠就会直接导致计算结果被覆盖。
数据更新丢失的过程分析

如果我们将这两个并发线程的指令流在时间线上展开,数据丢失的整个过程就会非常直观。假设初始时,内存中的 counter 为 0:
- 线程 1 首先发起了读取指令,它从内存中拿到了当前值 0,存入了自己的通用寄存器
eax中。 - 就在线程 1 准备做加法之前,线程 2 在另一个核心上并发运行,也发起了读取指令。由于线程 1 尚未写回任何新值,线程 2 从同一内存地址读取到的同样是旧值 0,并存入了自己的寄存器中。
- 随后,线程 1 执行修改指令,在自己的寄存器中将值加 1 得到 1。
- 线程 2 执行修改指令,在其独立的寄存器中将值加 1 同样得到 1。
- 线程 1 执行写回指令,将计算结果 1 写入内存。此时,内存中的
counter值变为 1。 - 紧跟着,线程 2 也将自己算好的新值 1 写入同一内存。虽然它执行了一次写操作,但只是将本就已经写入的 1 再次覆盖了一遍。
结果就是,两个线程各自进行了一次自增操作,但 counter 最终却只增加了 1。这就是并发编程中经典的"丢失更新"(Lost Update)现象。
这种指令交错的具体形态是完全不可控的。在程序运行期间,指令到底如何咬合,完全取决于当时的系统负载、CPU 缓存一致性状态以及操作系统的调度机制。
这也就是为什么每次运行的结果都像随机数一样波动,且几乎永远达不到 20 万。
数据竞争(Data Race)的定义与判定
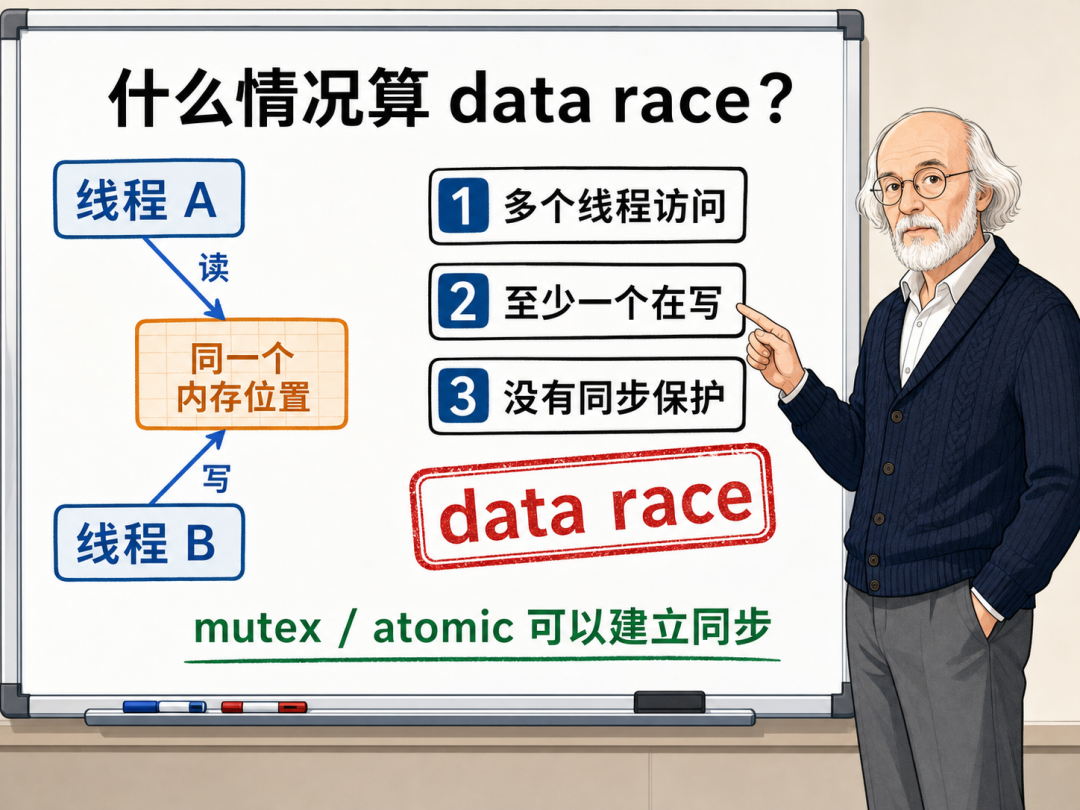
在 C++ 内存模型中,这种多线程无同步地读写同一共享变量的行为,被冠以了一个非常严谨的技术术语:数据竞争(Data Race)。
根据标准的严格定义,发生数据竞争必须同时满足以下三个要素:
- 两个或多个线程并发访问了同一个内存位置。
- 这些访问操作中至少包含一个写入操作。
- 这些操作之间没有使用任何同步手段来协调先后顺序。
只要这三个要素同时成立,数据竞争就发生了。回到我们之前的代码:两个线程并发读写全局变量 counter,自增操作包含了对内存的写入,且完全没有采取任何保护措施。这无疑是一个标准的数据竞争现场。
利用这一判定规则,我们可以很容易地理清哪些场景是天然安全的:
- 纯并发读取:如果多个线程只是并发读取同一个变量,由于不存在任何写操作,条件 2 不成立,因此不构成数据竞争。这就是只读的全局配置或静态常量在多线程中不需要加锁的原因。
- 内存区域隔离:如果每个线程仅读写各自独立的内存区域(例如每个线程只操作属于自己的局部变量或访问数组中互不重叠的元素),条件 1 不成立,这同样是安全的。
- 显式引入同步:如果线程在读写共享内存时,通过显式引入互斥锁、原子操作或屏障等同步原语,使得并发的访问行为在物理上被转化为有先后顺序的排队操作,条件 3 就不再成立,从而消除了数据竞争。
在规范的 C++语义中,如果操作之间没有通过"发生在先"(Happens-Before)关系来限定顺序,那么两个存在写冲突的并发访问就是未定义的。这也是为什么 C++ 标准对于数据竞争的态度极其严厉。
数据竞争与竞态条件(Race Condition)的区别
在并发领域中,数据竞争(Data Race)和竞态条件(Race Condition)常常被混为一谈,但它们实际上是两个不同层面的问题。
数据竞争是一个内存模型层面的概念。当我们在没有同步的情况下对同一内存地址进行并发读写时,就触犯了 C++ 标准的底线。一旦发生数据竞争,就会被判为未定义行为(Undefined Behavior, UB),程序的执行结果将不再受到任何保障。
而竞态条件则是一个高层业务逻辑层面的缺陷。它指的是由于多线程执行的相对时序不确定,导致程序无法产生稳定的正确结果。即使你的程序经过了严密设计,确保在底层没有半分数据竞争,也依然可能掉进竞态条件的陷阱里。
为了说明这种区别,我们可以看一个具体的工程示例。假设我们使用了一个内部完全线程安全的队列,该队列的所有公共接口内部都通过互斥锁保护,以确保单次调用不会产生任何数据竞争。在此前提下,我们编写如下的消费者逻辑:
cpp
// 线程安全队列,但外部组合操作不具备原子性
if (!queue.empty()) {
// 如果在此处发生线程切换,队列可能变空
auto item = queue.front();
// 弹出队头元素
queue.pop();
// 业务处理
Process(item);
}虽然在这里的每一次单独调用(如 queue.empty() 或 queue.front())在底层都受到了互斥锁的保护,不存在任何内存级别的数据竞争,但这个组合逻辑本身在多线程环境下并非原子的。
假设队列中当前只有一个元素。线程 A 执行完 !queue.empty() 检查,得知队列不为空,但在它准备执行下一行 queue.front() 的间隙,操作系统将 CPU 时间片切换给了线程 B。
线程 B 迅速执行完整个代码块,检查通过并调用 queue.pop() 将仅有的一个元素取走并弹出。当线程 A 重新获得执行权时,它继续执行 queue.front(),但此时队列已空,这会导致程序跑出异常或访问越界错误。
这种现象即为竞态条件。它表明,尽管底层的内存读写是同步的(无数据竞争),但高层的业务步骤之间存在时序漏洞。
消除数据竞争靠的是锁或原子变量,而消除竞态条件则需要改变接口设计,将多个离散的步骤合并为一个无法被分割的复合原子操作。

对于这个队列例子,最彻底的修改方式就是重新设计接口。不要让调用者分别调用 empty、front 和 pop,而是提供一个原子性的复合接口,例如 bool try_pop(T& item)。
在 try_pop 内部,通过一把锁将检查、获取和弹出的全套动作包裹起来。对于外部调用者而言,这就是一个整体的原子步骤,中间没有任何可以被其他线程插足的间隙,从而在根本上消除了竞态条件。
数据竞争引发未定义行为(UB)的后果
在 C++ 中,数据竞争被明确划分为未定义行为。这并不只是意味着计算结果会有误差,而是意味着编译器和运行时环境对代码的执行结果不做任何正确性担保。
在编译器的世界里,优化器在进行复杂的指令重排和寄存器分配时,有一个不可动摇的基础假设:代码绝对不包含未定义行为。如果你的代码带入了数据竞争,这个假设就会破灭,而编译器优化出来的机器指令,可能会产生令人匪夷所思的行为。
例如,在多线程环境中使用一个普通的布尔变量 stop 作为线程退出的信号:
cpp
bool stop = false;
// 工作线程的循环体
void Worker() {
// 循环检查退出标志
while (!stop) {
DoWork();
}
}在非优化编译(如 Debug 模式下)时,编译器生成的代码比较保守,每次循环判断都会重新从内存中读取 stop 变量的值。如果另一个线程修改了 stop,该线程通常能够感知并正常退出。
但是,当使用优化选项(如 -O2 标志的 Release 模式)进行编译时,编译器会进行循环不变式外提(Loop-Invariant Code Motion)等优化。
编译器观察到在当前线程的整个循环体中并没有任何修改 stop 变量的代码,在假设程序没有数据竞争的前提下,编译器会认为 stop 的值在循环期间是恒定不变的。因此,为了提高性能,编译器可能会将 stop 的读取操作提到循环外部,或者将其缓存在 CPU 寄存器中,导致生成的实际执行指令类似于:
cpp
void Worker() {
// 将变量读取提到循环外部
if (!stop) {
// 陷入死循环
while (true) {
DoWork();
}
}
}一旦发生这种优化,即使另一个线程在内存中把 stop 改成了 true,正在运行的 Worker 线程也永远看不到这个变化。这种现象往往会导致线程直接陷入死循环。
这并不是编译器的缺陷,而是因为代码中对 stop 的并发读写构成了数据竞争,破坏了编译器优化的语义基础。
在大型软件工程中,由数据竞争引起的并发缺陷通常表现出极高的隐蔽性与调试难度,其特征通常包括:
- 优化级别敏感性(Debug 跑得通,Release 跑不通):因为只有在 Release 模式下,编译器的指令重排和缓存寄存器优化才会把潜在的时序漏洞放大。
- 观察者效应(加了日志 Bug 就消失):在问题代码附近插入一条
std::cout打印语句,Bug 往往会莫名其妙地隐藏起来。这是因为输出操作需要调用系统函数,它相当于在紧凑的 CPU 指令流中插入了一块极重的阻碍,强行改变了线程交错的节奏。 - 硬件环境依赖性极强:程序在开发机上运行完美,到了线上多核服务器上就频繁报错。因为核心数量和硬件拓扑会极大地影响缓存行同步的延迟,进而暴露隐藏的竞争。
- 系统负载依赖性:在系统空闲或压力测试不充分时表现正常,一旦生产环境的并发请求量激增,数据竞争的时间窗口被频繁触发,程序便开始出现随机性的逻辑错误。
为此,现代编译器提供了一柄斩断这种并发暗箭的利剑------ThreadSanitizer(简称 TSan)。在编译时开启 -fsanitize=thread,编译器就会在程序运行时植入内存访问监控。
TSan 的基本工作原理是,为程序访问的每块内存分配额外的影子内存(Shadow Memory)。每当有线程执行读或写操作时,TSan 就会拦截该操作,并检查对应的影子内存。
影子内存中存储了最近访问该地址的线程 ID、操作类型(读或写)以及时间戳向量。如果 TSan 发现有两个线程并发访问了同一地址,且至少有一个是写操作,同时这两个操作之间不存在明确的 Happens-Before 屏障保护,它就会在终端输出详细的冲突堆栈信息。
虽然启用该工具会让程序的运行速度降低 5 到 15 倍,并增加数倍的内存占用,但它在开发阶段和持续集成测试中是定位数据竞争不可或缺的利器。
解决数据竞争的常用同步手段
要消除数据竞争,就必须破坏其判定的第三个条件,即引入同步机制。在 C++ 中,最基础且常用的同步手段是互斥锁(Mutex)与原子操作(Atomic)。
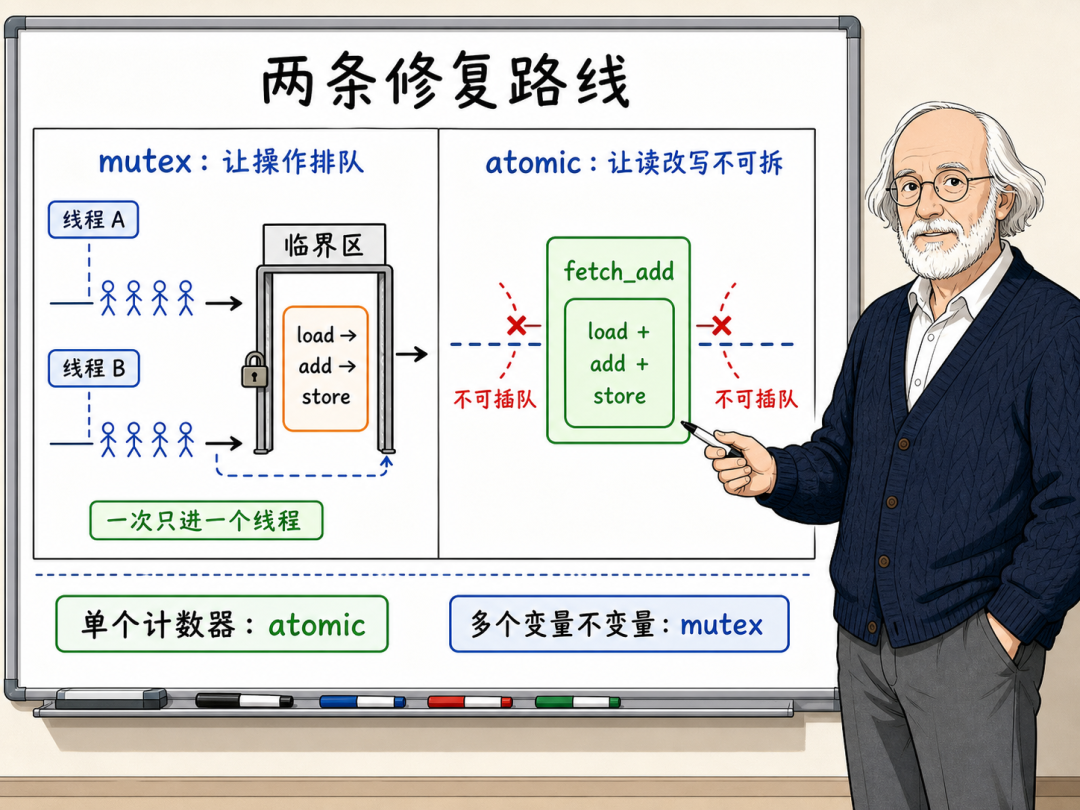
互斥锁(std::mutex)
互斥锁(Mutex)的策略是"空间隔离与强制排队"。它在代码中划分出一块被称为临界区(Critical Section)的安全地带,并确保在同一时刻,最多只能有一个线程持有该锁并进入临界区执行操作。
cpp
#include <iostream>
#include <mutex>
#include <thread>
int counter = 0;
// 声明互斥锁,用以保护全局计数器
std::mutex counter_mutex;
void Worker() {
for (int i = 0; i < 100000; ++i) {
// 利用 RAII 锁管理类自动加锁
std::lock_guard<std::mutex> lock(counter_mutex);
// 临界区操作,保证排队执行
++counter;
// 离开作用域,lock 自动析构并解锁
}
}
int main() {
std::thread t1(Worker);
std::thread t2(Worker);
t1.join();
t2.join();
std::cout << counter << std::endl;
}在上述代码中,我们引入了 std::mutex 变量 counter_mutex,并在 Worker 线程的循环体中使用 std::lock_guard 进行了封装。
std::lock_guard 是一种应用了 RAII(Resource Acquisition Is Initialization,资源获取即初始化)设计模式的模板类。在其构造时会自动调用 lock() 获取锁,在离开作用域发生析构时则会自动调用 unlock() 释放锁。
当线程 1 抢先获取了 counter_mutex 的控制权并进入临界区执行 ++counter 时,如果线程 2 也执行到此处,它会在构造 lock_guard 时被阻塞挂起。
直到线程 1 执行完累加、离开当前循环层级并析构 lock_guard 释放锁后,线程 2 才有机会被唤醒并获取锁,进而安全地执行自增操作。这使得两个线程的操作在物理上实现了顺序排队,从而排除了任何指令交错的可能。
互斥锁的优势在于其通用性强,不仅能保护简单的整型变量,还能保护涉及多个数据结构、复杂状态流转的大段临界区逻辑。但是,互斥锁在性能上是有代价的。在 Linux 操作系统中,C++ 的 std::mutex 通常基于 Futex(Fast Userspace Mutex,快速用户空间互斥体)机制实现。
Futex 的核心思想是将同步分为快速路径(Fast Path)和慢速路径(Slow Path):
- 快速路径(Fast Path): 在无锁竞争的理想状态下,加锁和解锁操作完全由用户空间的原子指令(如 Compare-And-Swap, CAS)独立完成,不需要进入内核,因此性能开销极低。
- 慢速路径(Slow Path): 一旦发生锁竞争,夺锁失败的线程无法在用户空间完成操作,就必须通过系统调用(如
sys_futex)陷入内核态,由操作系统将其状态置为挂起,并打入对应的等待队列中。当持有锁的线程释放锁时,再次发起系统调用唤醒等待队列中的线程。
由于慢速路径涉及内核态和用户态的来回切换,以及随之而来的 CPU 上下文切换,在高并发或竞争激烈的场景下,这会显著拉低系统的整体吞吐量。因此,对于锁的粒度控制是高并发工程中的核心难题。
同时,我们也必须遵守开发纪律:永远通过 RAII 来管理锁的生命周期。手动调用 lock() 和 unlock() 在面对异常或提前 return 时,极易发生锁泄漏,进而导致整个系统陷入无法唤醒的永久死锁。
原子操作(std::atomic)
如果需要保护的仅仅是一个简单的数字或状态,使用互斥锁未免有些大材小用。此时,std::atomic 是一种更为精巧的方案。
cpp
#include <atomic>
#include <iostream>
#include <thread>
// 声明原子类型的计数器,并初始化为 0
std::atomic<int> counter{0};
void Worker() {
for (int i = 0; i < 100000; ++i) {
// 调用原子自增函数,保证操作原子性
counter.fetch_add(1);
}
}
int main() {
std::thread t1(Worker);
std::thread t2(Worker);
t1.join();
t2.join();
std::cout << counter << std::endl;
}在声明 counter 为 std::atomic<int> 后,执行 counter.fetch_add(1)(或直接写 ++counter)会被编译器翻译成硬件级别的原子指令。
在 x86-64 架构下,针对普通的 ++counter,编译器会将其翻译成多条指令。但如果是对 std::atomic 执行的操作,编译器会生成带有 lock 前缀的单条指令:
cpp
lock add DWORD PTR counter[rip], 1这里的 lock 是一个特殊的指令前缀。当 CPU 核心执行带有 lock 前缀的指令时,它会触发硬件级别的锁定机制。
在现代 CPU 中,这主要通过缓存锁(Cache Locking)来实现:执行核心会独占性地锁住包含 counter 变量的缓存行(Cache Line),并通过缓存一致性协议(如 MESI 协议)通知其他 CPU 核心将各自缓存中对应的缓存行置为无效状态。
在当前核心完成"读取-修改-写回"的整个周期之前,其他核心无法对该缓存行进行读写操作。这就确保了整个操作在硬件层面上是不可分割的。
相比之下,如果是在 ARM 架构(如 ARMv8-A 之前)上,由于其采用弱内存模型,并没有像 x86 那样粗暴的全局锁指令。ARM 通常会使用 LL/SC(Load-Link/Store-Conditional,在 ARM 中具体表现为 LDREX 和 STREX 指令对)来实现原子操作。
LDREX指令(Load-Link): 读取目标内存地址的值,并在 CPU 的监视器(Exclusive Monitor)中标记该地址处于独占监控状态。STREX指令(Store-Conditional): 尝试向该地址写入新值。在此之前,监视器会检查该地址自上次LDREX以来是否被其他核心修改过。如果未被修改,则写入成功并返回 0;如果已被其他核心抢先修改,则写入失败并返回 1。程序需要在一个循环中重复这一过程,直到写入成功。
而在现代 ARMv8.1 架构中,引入了大系统扩展(Large System Extensions, LSE)原子指令(如 LDADD),这使得原子操作在 ARM 上也可以像 x86 那样通过单条硬件指令高效完成。
与互斥锁相比,原子操作完全在硬件指令级完成同步,不需要依赖操作系统进行线程的挂起、上下文切换与重新调度,因此其执行效率极高。在频繁修改单个共享计数器的场景下,原子操作的吞吐量通常会比互斥锁高出数倍甚至数十倍。
然而,原子操作的局限性在于其表达能力有限。它只能保证单个变量在单次原子指令下的操作完整性。如果我们需要在修改变量 A 的同时修改变量 B,并要求这两个修改动作具有事务性特征,原子操作就无法直接保证了。在这种多变量联动或复杂业务逻辑下,依然需要依靠互斥锁来界定宏观的临界区。
优化策略:从架构设计减少数据共享
无论是用互斥锁把线程挡在门外,还是用原子操作在硬件级硬抗,本质上都是在对"多线程抢占同一数据"进行被动的弥补。其实在并发系统设计中,还有一条更高级的准则:尽量避免共享状态。如果线程之间没有数据交集,自然也就没有并发冲突的可能。
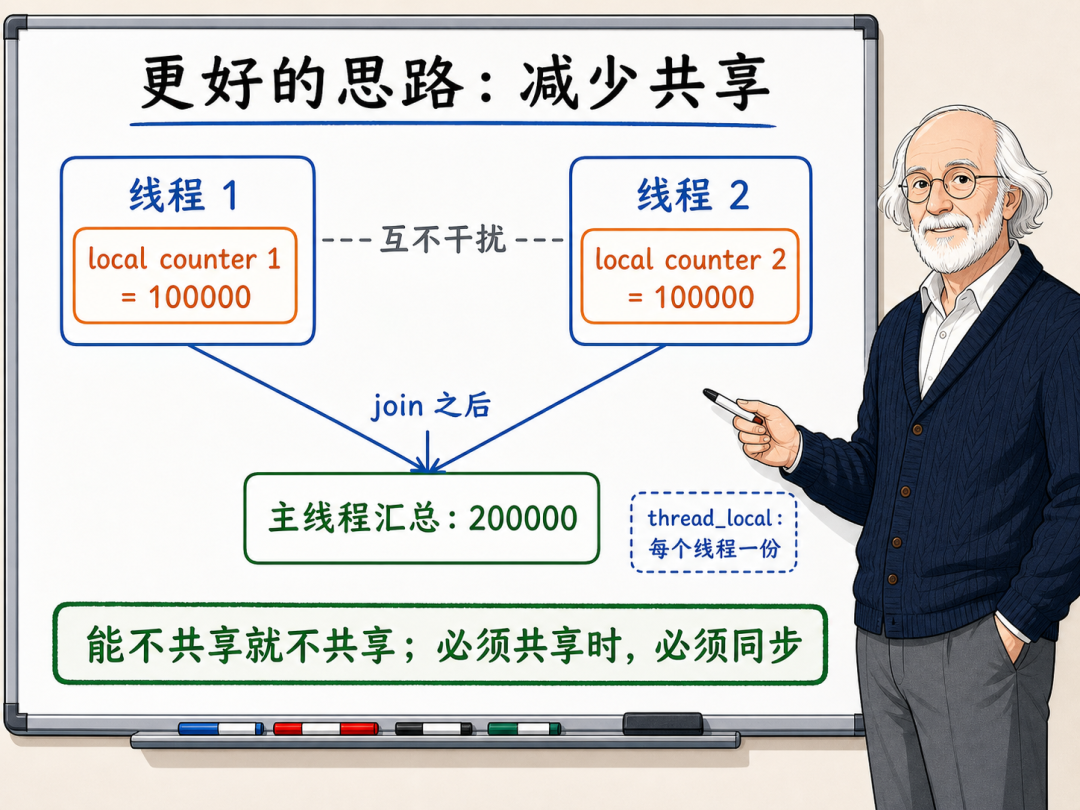
在统计计数这个具体的工程场景中,我们可以改变原有的多线程直接修改同一个全局变量的结构。更好的方案是为每个工作线程分配一个独立的局部计数器,让它们在运行期间仅写各自对应的局部内存。等到所有线程执行完毕、完成主线程的同步(join)之后,再由主线程将各个局部计数器的值累加起来:
cpp
#include <iostream>
#include <thread>
#include <vector>
// 工作线程传入各自独立的局部变量引用
void Worker(int& local_counter) {
for (int i = 0; i < 100000; ++i) {
// 只累加局部变量,无数据竞争
++local_counter;
}
}
int main() {
// 线程 1 专用的局部计数器
int counter1 = 0;
// 线程 2 专用的局部计数器
int counter2 = 0;
// 启动线程,并传入各自的计数器引用
std::thread t1(Worker, std::ref(counter1));
std::thread t2(Worker, std::ref(counter2));
// 等待全部线程运行结束
t1.join();
t2.join();
// 在主线程中单线程安全地进行汇总
std::cout << counter1 + counter2 << std::endl;
}在这种设计中,每个工作线程只对自己传入的局部变量进行修改,不同线程访问的内存空间是物理隔离的。由于破坏了数据竞争判定条件中的"并发访问同一个内存位置",所以不需要任何同步原语保护,且完全没有性能损耗。最后的汇总累加动作是在主线程单线程运行的状态下进行的,不存在并发竞争。
此外,C++ 还引入了 thread_local 关键字,用于定义线程局部存储(Thread-Local Storage, TLS)变量:
cpp
// 声明线程局部变量,每个线程拥有一份独立拷贝
thread_local int local_counter = 0;声明为 thread_local 的变量会在每个线程启动时独立创建一份副本。每个线程对该变量的读写操作都只作用于本线程的副本上,从根本上消除了数据竞争。
从硬件层面来看,不共享数据还能避免严重的"缓存行颠簸"(Cache Line Bouncing)性能惩罚。在多核 CPU 中,如果多个核心高频读写同一个变量(即便使用了 std::atomic),缓存一致性协议(如 MESI)会强迫该变量所在的整个缓存行在不同核心的 L1/L2 缓存之间来回搬运,导致极高的系统总线带宽消耗和延迟开销。
而使用局部变量或 thread_local 之后,各个核心各自在其独立的私有缓存中修改数据,没有任何总线级别的同步流量,这极大地释放了多核处理器的并发潜能。
在实际工程实践中,虽然完全消除共享状态是不现实的(例如多线程之间必须进行任务分发与数据流转),但我们应当在设计上尽可能缩窄共享数据的范围,并降低数据同步的频次。将并发交互点收拢到少数几个经过严密测试的同步组件(如并发队列)中,而不是让线程随意读写全局变量,这是保障并发软件正确性与高性能的关键手段。
总得来说,并发编程中的核心原则可以概括为:尽量设计无共享的架构;对于无法避免的共享状态,必须实施明确且正确的同步机制。
在解决了多线程访问冲突后,我们不禁要问:互斥锁究竟是通过什么硬件机制来保证临界区内的修改能被其他线程及时看到的?那些性能损耗的具体源头又在哪里?下一章我们将深入互斥锁的内部实现机制,探寻其底层的执行原理。
码字不易,欢迎大家点赞,关注,评论,谢谢!