渐进发现模式适用于这类场景:Agent 接到任务,但不知道相关信息在哪。比如陌生代码库的 bug 调试、陌生客户的合同审阅、陌生事故的根因排查。具体渐进加载的信息可以是代码、文档、工具以及 Skills 等等。
当任务的相关信息已经被预先索引好,而且可以一次性传给 Agent,就不需要强行渐进发现模型。比如客服 Agent 接的是当前用户的工单上下文(已经在上下文分诊模式的 P1 里了)、研究 Agent 看的是用户上传的某份文档(已经在上下文分诊模式的 P0 里了)。这种场景下 Agent 不需要探索,因为它已经看到了。
工程现场
1、Claude Code 为什么一度放弃 RAG,转向 Agentic Search?
Claude Code 早期用过 RAG + local vector db。这条链路里,vector db 变成了代码仓库之外的第二份知识副本。Agentic Search 的链路更短:它不是没有风险,而是少维护一份"影子仓库"。安全、隐私、过期、可靠性问题,大多就出在这份影子仓库上。
当前任务
→ grep / search / read file / follow imports
→ 读当前工作区里的真实文件
-
安全 (Security): RAG 要先把代码库嵌入到向量数据库(vector db)中。代码、配置、商业逻辑都多了一层暴露面。
-
隐私 (Privacy): 代码进入向量存储后,即使是私有部署,也会带来额外的数据治理问题。
-
过期 (Staleness): 索引一旦建好就会过时。代码每天提交,索引就必须持续更新。索引慢一步,Agent 看到的就是旧代码。
-
可靠 (Reliability): RAG 召回依赖 embedding 模型、查询表达、top-K 和阈值。任何一个环节抖动,结果就会变。grep / read 虽然朴素,但稳定、可解释、可复现。
并且,代码探索不能只靠语义召回。代码库不同于普通文档库。bug 往往藏在变量名、调用链、缓存 key、配置文件、测试路径这些结构关系里。RAG 看的是语义相似,而 grep + read + follow imports 看的是代码结构。前者(RAG)可能召回一堆"语义相关"的文档,后者能顺着真实调用链往下追踪。所以在中小型代码库里,如果目标是 bug 定位、调用链追踪、陌生模块理解,agentic search 往往更直接。先别急着上复杂 RAG,grep + read 应该能解决 70% 的探索问题。
2、Augment Code 为什么又走了持久化的索引(persistent indexing)路线。
Augment Code 把 Context Engine 做成一个工业级索引系统。它可以索引 400K+ 文件,支持较快的全量索引、增量更新和跨 repo 依赖追踪。后来它还把自己的 Context Engine 通过 MCP 暴露给 Claude Code 和 Cursor 使用。Augment 是在补足 Agentic Search 的边界:中小型代码库可以现场探索,超大规模、跨 repo、强依赖追踪的代码库,需要工业级 indexing 托底。Augment 处理的是另一个极端的情况:代码库非常大,跨 repo 依赖非常多,单靠 grep 一轮轮扫描,交互体验会变差。
-
第一,Agentic Search 已经是 Coding Agent 的主流共识。代码里的关键信息经常藏在结构关系里,而非藏在语义相似度里。
-
第二,持久化索引是 Agentic Search 的规模化补丁。小中型代码库可以现场探索,超大代码库和跨 repo 场景需要提前维护一张代码地图。
-
第三,深挖时不应该污染主 Agent 的上下文。更成熟的做法,是把这个深入探索过程隔离出去:让 Sub-Agent 或独立 search worker 负责广扫和初筛,主 Agent 只拿回压缩后的发现、证据链和候选文件。这一点非常重要。长期运行的 Agent 最怕把探索过程中的中间垃圾全部塞进主上下文,最后真正有用的信息反而被淹没。
Agentic search 真正落地时,绝对不能让 Agent 碰运气乱搜。它真正的工程骨架,是广扫、聚焦、深挖(forage-focus-deepen)三阶段循环。
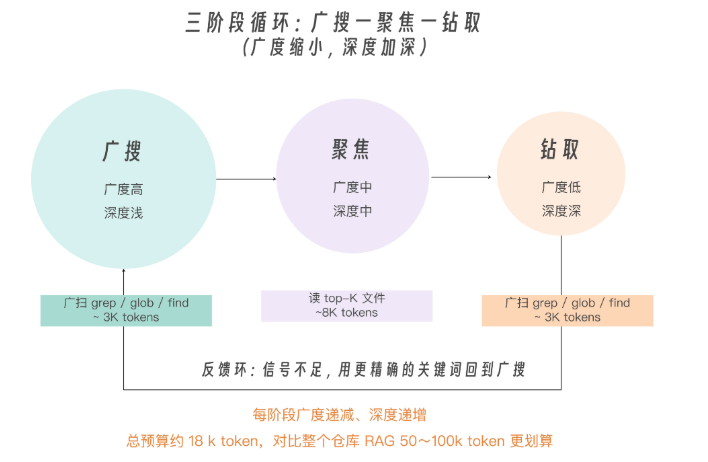
1、第一阶段是广扫(Forage)
Agent 用 grep / glob / find 这种低成本工具扫陌生空间。先拿到 30-50 个候选。这个阶段主要看文件名、路径、匹配行和周边上下文,不读完整文件。代价通常在几千 token 级别。
2、第二阶段是聚焦(Focus)
Agent 从候选里挑 5-10 个最可能的文件完整读。这个阶段开始建立局部理解:谁调用谁,关键函数在哪里,哪个文件可能处在主路径上。
3、第三阶段是深挖(Deepen)
Agent 沿着 focus 阶段发现的可疑链继续追下去。比如读被调用函数、配置文件、测试用例、历史 commit。这个阶段不能再铺开,只追一两条最有信号的链。