
只有任务导向的主动观测,才是空间推理的关键。
------感知‑行动闭环
目录
[01 核心定位:ESI‑BENCH到底在测什么?](#01 核心定位:ESI‑BENCH到底在测什么?)
[02 基准设计:任务、环境、动作、评测范式全解析](#02 基准设计:任务、环境、动作、评测范式全解析)
仿真环境:OmniGibson+BEHAVIOR‑1K,保证物理真实
[03 当前MLLM的具身空间智能,真相很残酷](#03 当前MLLM的具身空间智能,真相很残酷)
[结论4:模型与人类的核心差距,在元认知(Epistemic Calibration)](#结论4:模型与人类的核心差距,在元认知(Epistemic Calibration))
[04 如何保证无偏见、无捷径、高难度?](#04 如何保证无偏见、无捷径、高难度?)
[05 只有任务导向的主动观测,才是空间推理的关键](#05 只有任务导向的主动观测,才是空间推理的关键)
近两年来,多模态大模型在视觉感知、空间关系理解与场景问答等任务上不断突破,VSR、BLINK、3DSRBench、VSI‑Bench等空间智能基准持续提升评测上限,但它们几乎都建立在同一前提上:
模型仅需被动处理预设好的最优视角输入,无需与环境进行任何主动交互。
真实世界的空间智能本质是感知‑行动闭环,物体会因为移动、操作、变换视角而出现关键信息的遮挡。
而现有基准恰恰缺失这一核心环节,只评测视觉能力,不考核具身空间能力。
针对这一缺口,斯坦福、UCLA、西北大学联合团队推出ESI‑BENCH基准,首次将空间智能评测从被动观察转向主动探索,以10大类、29子类、3081个任务闭合感知‑行动回路,并通过严谨对照实验定位模型行动失明与元认知缺陷。
01 核心定位:ESI‑BENCH到底在测什么?
ESI‑BENCH全称Embodied Spatial Intelligence Benchmark ,定位是面向具身空间智能、闭合感知‑行动回路的综合评测基准。
它与过往空间/具身基准的本质差异,可浓缩为三点:
- 从被动感知到主动能力
不再给模型预设视角,智能体必须自主选择感知(转头/俯仰)、移动(前后左右)、操作(拾取/放置/倒水),并按序执行,才能收集到解题证据。
- 从显式信息到隐藏属性
任务全部聚焦被动观测无法解决的问题:遮挡计数、镜面虚实、容积比较、稳定性预测、封闭空间变化、导航连通性等,必须通过交互才能揭示答案。
- 从单一能力到全认知维度
严格遵循Spelke核心知识体系,覆盖物体表示、布局与几何、数量表示、智能体与目标导向行动四大人类核心空间认知维度,评测更接近人类水平。

▲ESI‑BENCH 任务大类定义与所需动作类型
简单说:过往基准测"视力",ESI‑BENCH测"空间智商+行动智商"。
02 基准设计:任务、环境、动作、评测范式全解析
任务体系:10大类+29子类,覆盖全空间推理链
ESI‑BENCH共10个任务大类、29个子类,总计3081个任务实例,所有任务都满足:
单视角无法解、必须主动探索。


▲ESI‑BENCH 任务总览图(覆盖 10 大任务类别与 29 个子类示意图)
这套任务设计的严谨性在于:每类任务都对应一种人类空间认知缺陷,能精准定位模型短板:是看不清、不会动,还是不会推理、不会修正。
仿真环境:OmniGibson+BEHAVIOR‑1K,保证物理真实
ESI‑BENCH基于OmniGibson 仿真器(NVIDIA Isaac Sim+PhysX 5),场景来自BEHAVIOR‑1K:
- 51个交互式3D场景,覆盖住宅、商业、公共设施;
- 300+房间、9000+物体实例、1829个物体类别;
- 支持刚体物理、粒子流体、透明渲染、真实光照与反射、容器填充/开关状态。
这种环境选择不是随意的:**只有仿真能提供精确Ground Truth,**遮挡关系、接触标记、容纳状态、导航连通性、物体位姿,保证评测无歧义。
动作空间:高层离散动作,聚焦空间推理而非运动控制
为避免"动作执行失败"掩盖"空间推理失败",ESI‑BENCH采用高层离散动作空间,屏蔽底层运动学细节,让评测聚焦"选什么动作"而非"怎么做动作":
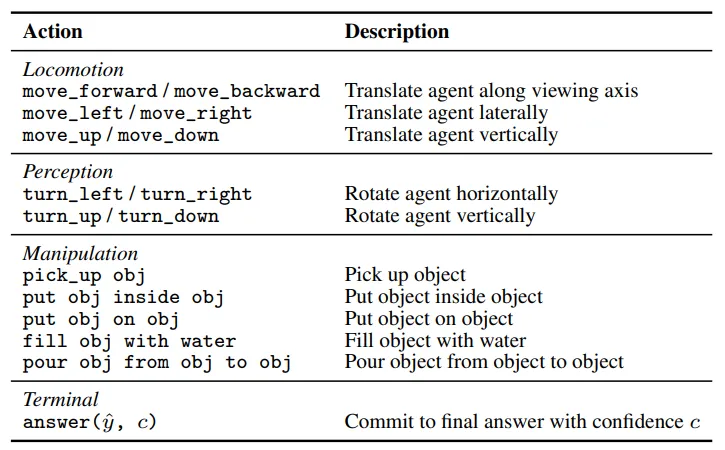
▲ESI‑BENCH 智能体动作空间说明表
- **移动:**前后左右、上下平移;
- **感知:**左右转头、上下俯仰;
- **操作:**拾取、放置(内部/表面)、注水、倾倒;
- **终止:**提交答案+置信度。
最大步数限制 ,经消融实验验证:
15--20步已足够完成绝大多数探索,30步后性能趋于饱和,过长步数只会引入冗余观测。
评测范式:四范式对照,精准分离"感知错误"与"行动错误"
这是ESI‑BENCH最具创新性的设计:通过四种评测范式的对照,把模型失败原因拆解得一清二楚:
- Passive Single‑View:单固定视角,对标传统空间基准;
- Passive Multi‑View:30个随机视角,无主动选择,测"多图是否有用";
- Active Exploration:主动探索, full动作空间,测"真实具身能力";
- Ground‑Truth Passive:最优轨迹视角,Oracle设置,分离感知与行动瓶颈。
03 当前MLLM的具身空间智能,真相很残酷
团队在GPT‑5、Gemini 3.1等SOTA MLLM,以及3D增强模型(VGGT+Gemini、GT 3D+Gemini)上做了零样本评测,配合人类基线,得到五个结论。
结论1:主动探索确实有效,且能涌现空间策略
在无任何显式指令的情况下,主动智能体自发形成多种探索策略:

▲主动探索涌现空间策略示意图(栗子是否在玻璃内)
- 判断容纳:移到背后、俯视、拾取、倾倒;
- 判断距离/尺寸:移动消除透视、靠近对比;
- 判断遮挡:换角度、揭开覆盖物。
这些策略直接带来显著性能增益:
- 视角幻觉(View Hallucination):从39.9%→68.1%;
- 刚性容纳(Rigid Containment):从47.5%→67.5%。
更关键的是:被动随机多视图几乎无增益,甚至负增益。
比如GPT‑5在空间距离任务上,从单视角53.9%降到多视角49.1%。
原因很直白:数量≠质量。
30张随机图大多是冗余/干扰信息,MLLM无法有效整合,反而稀释有效信号。
只有任务导向的主动观测,才是空间推理的关键。
结论2:行动失明>感知失明,行动是核心瓶颈
Oracle实验得出:给最优视角,模型准确率暴涨。
- 刚性容纳:GPT‑5从42.5%→95.0%;
- 物理接触:从64.2%→90.0%。
这意味着:大多数任务中,感知不是瓶颈,不会选动作才是。

▲动作与感知错误级联示意图(足球大小判断)
研究把这种缺陷命名为Action Blindness(行动失明):
模型不知道"哪一步动作能获得关键证据",只会重复无效移动,导致错误级联:
- 坏动作→坏观测→更坏的后续动作→在步数预算内无法挽回。
只有少数任务(如几何构型、镜面对应)存在硬感知上限,再好的动作也无法弥补视觉理解缺陷。

▲硬感知上限任务示意图(几何构型、镜面对应)
结论3:完美3D有用,瑕疵3D比2D更坑
实验对3D增强给出非常务实的结论:
- 完美3D(Ground‑Truth 3D):在深度敏感任务(几何构型、遮挡计数)大幅增益,几何构型从27.5%→70.8%,计数从3.3%→33.3%;
- 瑕疵3D(VGGT重建):反而大幅掉点,几何构型降到9.9%,计数降到0.0%。
**噪声3D会扭曲精细空间关系:**物体重复、幻觉、位置偏移,让LLM基于错误场景图推理,错得更自信、更彻底。
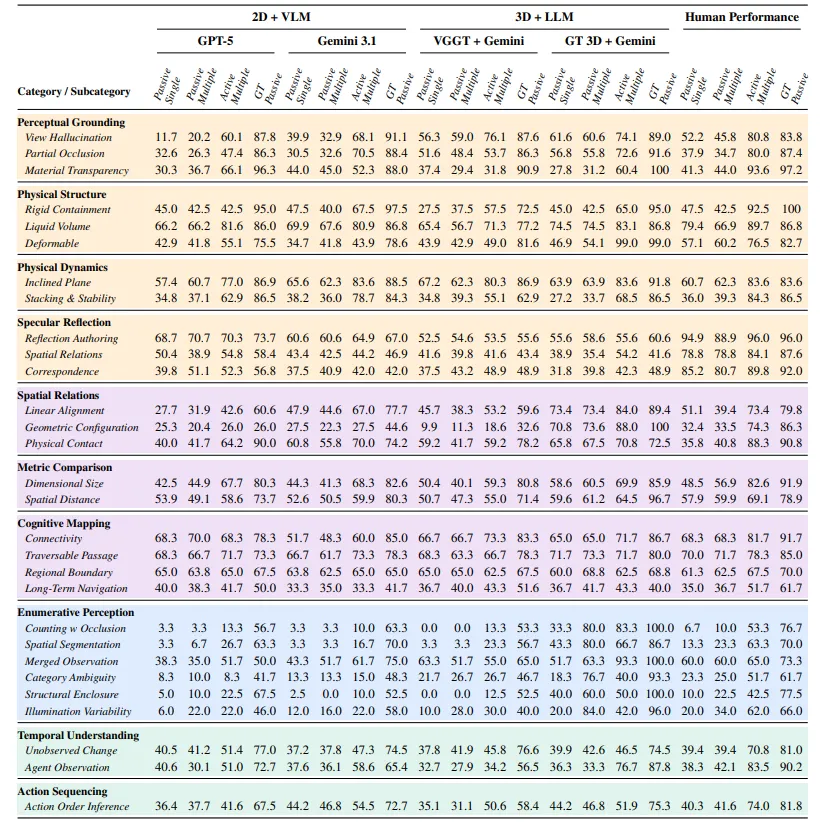
▲被动 / 主动 / Oracle 范式下 2D‑VLM/3D‑LLM / 人类准确率总表
这意味着,3D不是万能药,在重建精度不够可靠时,盲目加3D模态反而是负收益。
结论4:模型与人类的核心差距,在元认知(Epistemic Calibration)
人类对照实验揭示了一个最致命的差距:元认知能力。
- 人类:模糊时会寻找证伪视角,证据不足不轻易下结论,矛盾时修正信念;
- 模型:几步后就过早承诺,高置信度给出错误答案,只找证实自己初始判断的视角,无视矛盾观测。
例举一个典型失败案例:

▲模型认知偏差与证据确认偏差示意图
问"是橱柜还是钢琴"。
模型第一眼猜橱柜,随后只向后、向左移动强化判断,从不换角度验证,最终高置信答错。
这种缺陷既不是感知差,也不是动作弱,是"不知道自己不知道",是更高层级的认知缺陷,单靠提升视觉或增加交互步数无法解决。
结论5:任务难度差异极大,暴露模型能力短板
从结果看,模型表现呈明显分层:
- **易:**液体容积、认知地图(连通性/通行通道),准确率60%+;
- **中:**物理动态、镜面反射、度量比较,准确率40%--60%;
- **难:**枚举感知(遮挡计数、结构封闭)、几何构型、空间关系,准确率长期低于30%。
最难的集中在计数、精细几何、遮挡、封闭空间,这些恰恰是真实机器人最常遇到的场景。
04 如何保证无偏见、无捷径、高难度?
一项好的基准,难点不在任务设计,而在无偏见、无捷径、可复现。
ESI‑BENCH做了三层保障:
1. LLM辅助+人工校验
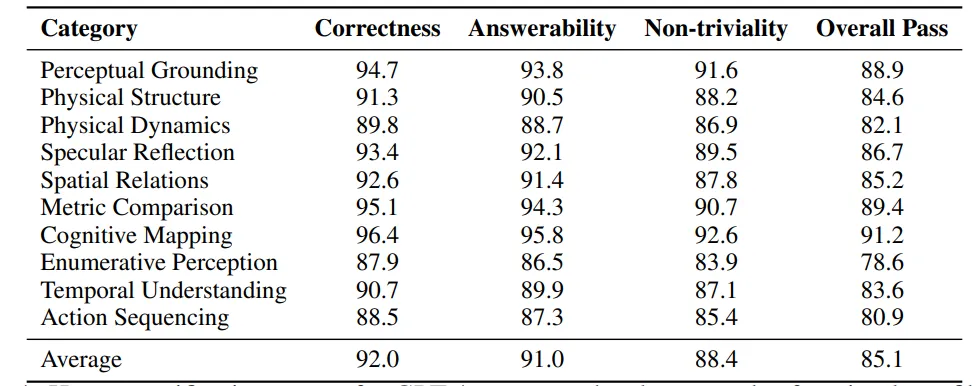
▲GPT‑4o 生成任务人工验证得分表
- **用GPT‑4o生成候选任务,再经三位标注者独立审核:**正确性、物理合理、答案与仿真状态一致;
- **可解性:**在动作空间+步数预算内可解;
- **非平凡性:**不能靠初始视角/语言先验猜答案。
- 最终整体通过率85.1%,剔除大量无效/歧义任务。
2. 捷径基线测试
- 测试两种极端捷径:
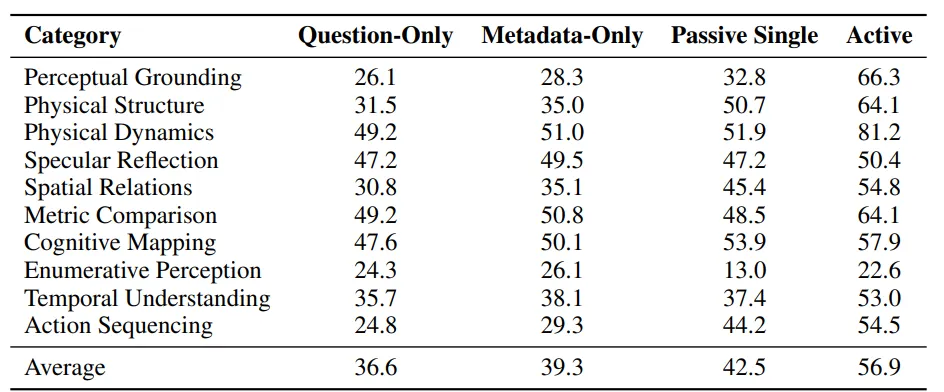
▲仅问题 / 仅元数据 / 被动单视角 / 主动探索捷径基线表
① 仅问题:准确率36.6%;
② 问题+物体类别:准确率39.3%;
均远低于主动探索(56.9%)。
证明模型无法靠语言偏见或物体先验蒙答案,必须靠视觉+行动。
3. 人类生成对照
GPT‑4o生成任务与人类生成任务难度差距<4%,证明LLM辅助构建不会引入难度偏差。
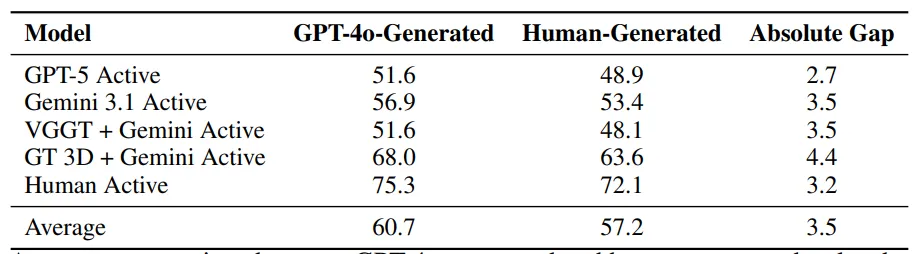
▲GPT 生成任务与人类生成任务准确率对比表
05 只有任务导向的主动观测,才是空间推理的关键
ESI‑BENCH首次把空间智能评测从"被动看图"转向"主动闭环",重新定义具身空间智能的评测标准;用对照实验实锤"行动失明>感知失明""瑕疵3D有害""元认知缺失"。
但同时也存在渲染质感、物理细节、传感器噪声与真实世界的差异;屏蔽底层控制,无法评测端到端具身智能体的完整能力。
具身空间智能的未来,不属于只会看图的模型,而属于能闭合感知‑行动回路、会主动找证据、会怀疑自己、会修正信念的智能体。
Ref
论文题目:ESI‑BENCH: Towards Embodied Spatial Intelligence that Closes the Perception‑Action Loop