用语种检测、翻译、纠错和情感分析构建多语言内容审核 Agent
摘要:多语言内容审核不只是翻译。一个实用的 Agent 需要先识别语种,再决定是否翻译,接着做纠错、格式化和情感分析,最后把结果交给人工审核或自动发布流程。
关键词:多语言内容审核 Agent、语种检测 API、AI 翻译 API、文本纠错 API、情感分析 API
问题背景
内容平台、客服系统和跨境业务经常会收到多语言文本。直接把所有内容翻译成中文再处理,既浪费调用成本,也可能丢失原文语气。更合理的方式是让 Agent 根据语言和业务规则选择工具。
Agent 工作流
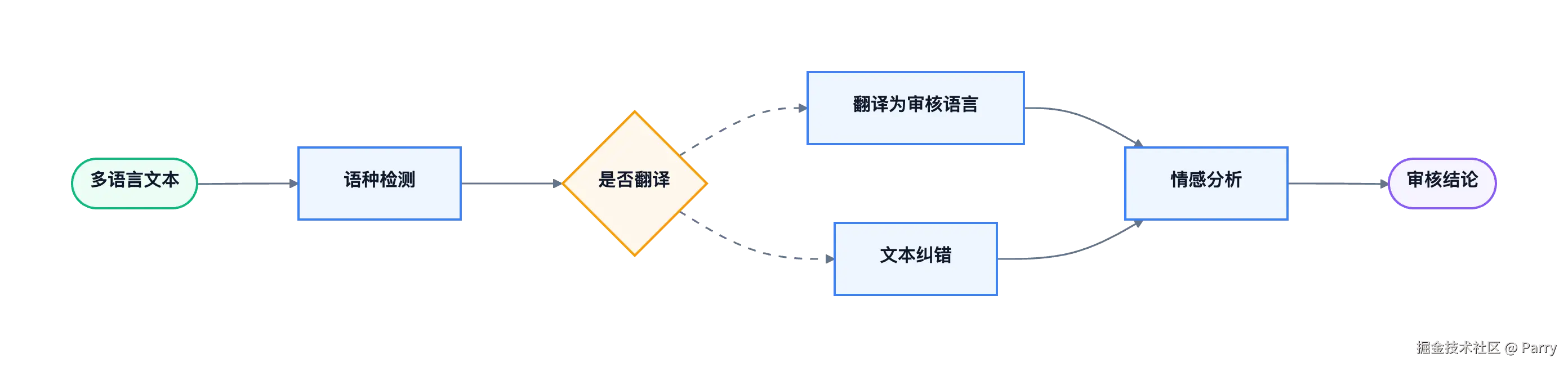
接口编排
| 步骤 | 接口 | 请求方式 | 用途 |
|---|---|---|---|
| 识别语言 | NLP 语种检测 | POST | 判断文本语言,决定后续路线 |
| 翻译内容 | 多语言 AI 翻译 | POST | 把文本翻译成目标语言 |
| 纠错格式化 | 多语言文本 AI 纠错格式化 | POST | 修复语法、拼写和格式问题 |
| 情感判断 | 多语言文本 AI 情感分析 | POST | 给客服或审核流程提供情绪信号 |
调用示例
vbnet
curl -X POST "https://api.gugudata.com/text/detectlanguage" \
-H "Content-Type: application/json" \
-d '{
"appkey": "YOUR_APPKEY",
"content": "The delivery was late, but the support team replied quickly."
}'
vbnet
curl -X POST "https://api.gugudata.com/ai/sentiment-analysis?appkey=YOUR_APPKEY&streaming=false" \
-H "Content-Type: application/json" \
-d '{
"textContent": "The delivery was late, but the support team replied quickly.",
"streaming": false
}'Agent 中可以用语言判断决定是否翻译:
python
def should_translate(language_code: str, target_language: str = "zh-cn") -> bool:
"""Decide whether translation is needed."""
return language_code.lower() != target_language审核输出
建议输出为一组清晰字段:
| 字段 | 说明 |
|---|---|
| source_language | 原文语种 |
| normalized_text | 纠错和格式化后的文本 |
| translated_text | 如有必要,保存翻译结果 |
| sentiment | 情感倾向 |
| review_action | 放行、人工复核、优先处理或拒绝 |
错误处理
语种检测置信度低时,不要自动走发布流程。翻译失败时应保留原文并进入人工复核。情感分析结果只作为信号,不适合作为唯一的审核依据。
工程注意点
- 保留原文,避免翻译结果覆盖用户真实表达。
- 对客服场景可以把负向情绪内容优先分配给人工处理。
- 对内容发布场景,纠错后的文本应经过业务规则校验。
- 不要在前端暴露 APPKEY,多语言处理应在服务端完成。
标准架构拆解
多语言内容审核 Agent 适合拆成"语言识别、文本标准化、情绪判断、审核决策"四层:
| 层级 | 责任 |
|---|---|
| 语言识别 | 判断原文语言和置信度 |
| 文本标准化 | 翻译、纠错、格式化和保留原文 |
| 内容理解 | 情感分析、关键词提取和业务分类 |
| 审核决策 | 输出放行、人工复核或优先处理建议 |
这里的核心不是把所有内容翻译成中文,而是让不同语言进入同一套审核框架。原文、翻译文本和纠错文本都要保留,便于人工复核和后续质量评估。
数据流与接口边界
推荐流程:
- 接收用户文本和业务场景,例如评论、客服、反馈或审核队列。
- 调用语种检测,得到语言和置信度。
- 如果语言不是目标处理语言,再调用翻译接口。
- 对目标文本做纠错格式化,减少噪声。
- 调用情感分析,生成情绪标签。
- 根据业务规则输出审核动作。
接口边界上,语种检测解决"是什么语言",翻译解决"是否可读",纠错解决"是否规范",情感分析解决"倾向是什么"。审核结论仍然应该由业务规则和人工策略共同决定。
可靠性与观测
建议记录:
| 指标 | 用途 |
|---|---|
| language_confidence_avg | 语种识别稳定性 |
| translation_required_rate | 需要翻译的内容比例 |
| correction_change_rate | 纠错前后文本变化比例 |
| negative_sentiment_rate | 负向内容比例 |
| manual_review_rate | 人工复核压力 |
当语种置信度低或文本过短时,情感分析结果可能不稳定。Agent 应把这类内容打上低置信度标记,而不是直接进入自动处理。
落地清单
- 保存原文、翻译文本和纠错文本三份内容。
- 每条内容记录语言、情绪、处理动作和处理时间。
- 低置信度和负向内容优先进入人工队列。
- 翻译失败时不要丢弃原文,应保留并标记失败原因。
- 对外回复前必须经过业务规则校验。
可扩展方向
这个 Agent 可以接入关键词提取接口,生成内容标签;也可以接入 PII 去除接口,在进入模型分析前先处理敏感信息。