一、引言
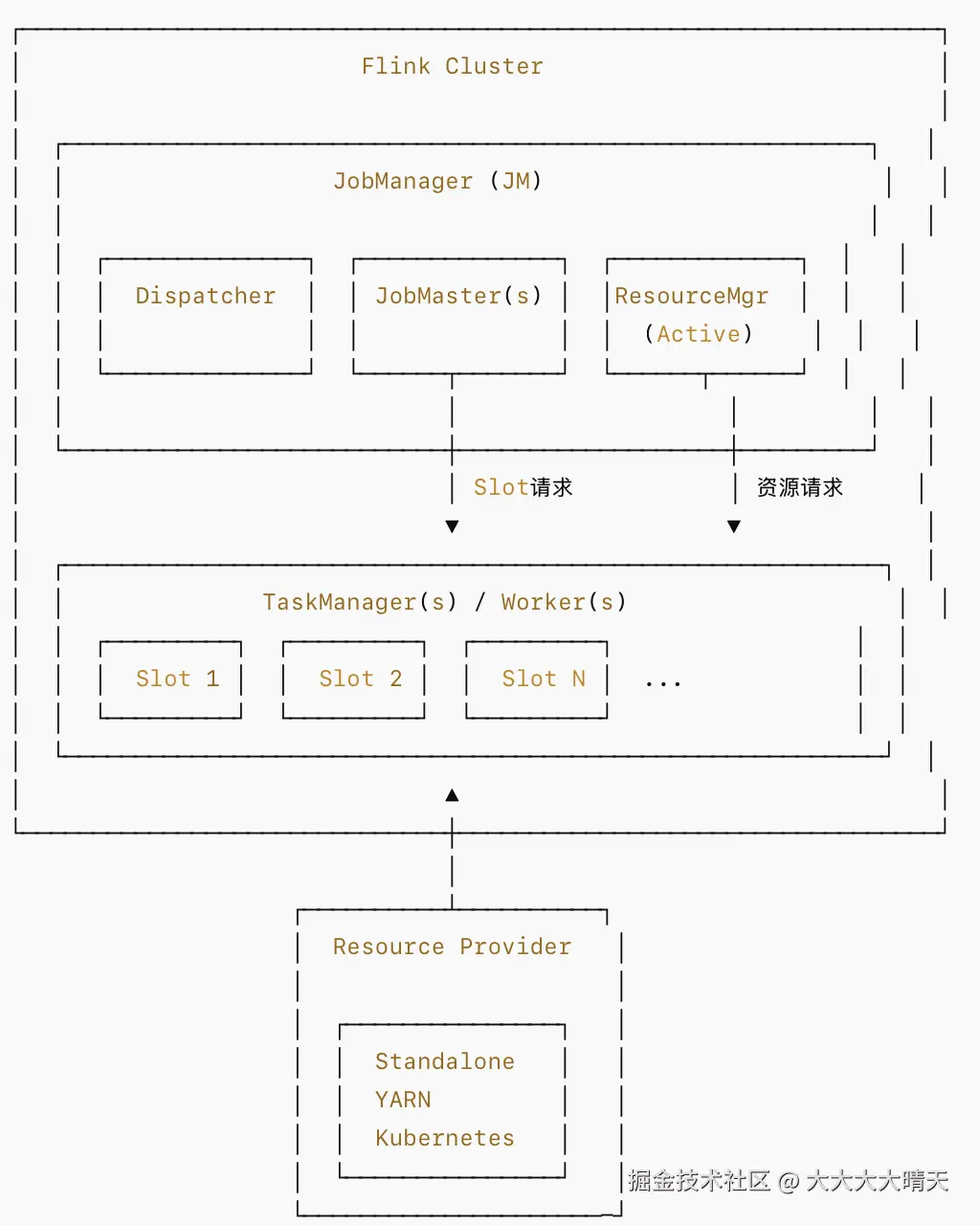
一个 Flink 作业运行起来,至少需要两类进程:
- JobManager(含 Dispatcher、ResourceManager、JobMaster):负责协调、调度、检查点协调、故障恢复。
- TaskManager:真正执行算子、提供 Task Slot 的工作进程。
问题是:这些进程的「机器/容器」从哪来?谁来启动、监控、回收它们?
这正是 Resource Provider 要解决的问题,Flink 自身不绑定任何特定的集群管理系统,而是通过一层抽象来对接不同底座:
- 你可以手动在几台机器上启动进程(Standalone);
- 也可以让 Flink 直接对接 Kubernetes API(Native Kubernetes);
- 还可以跑在 Hadoop YARN 上,复用已有大数据集群(YARN)。
二、核心架构与机制原理
1.整体架构图
2.资源请求流程
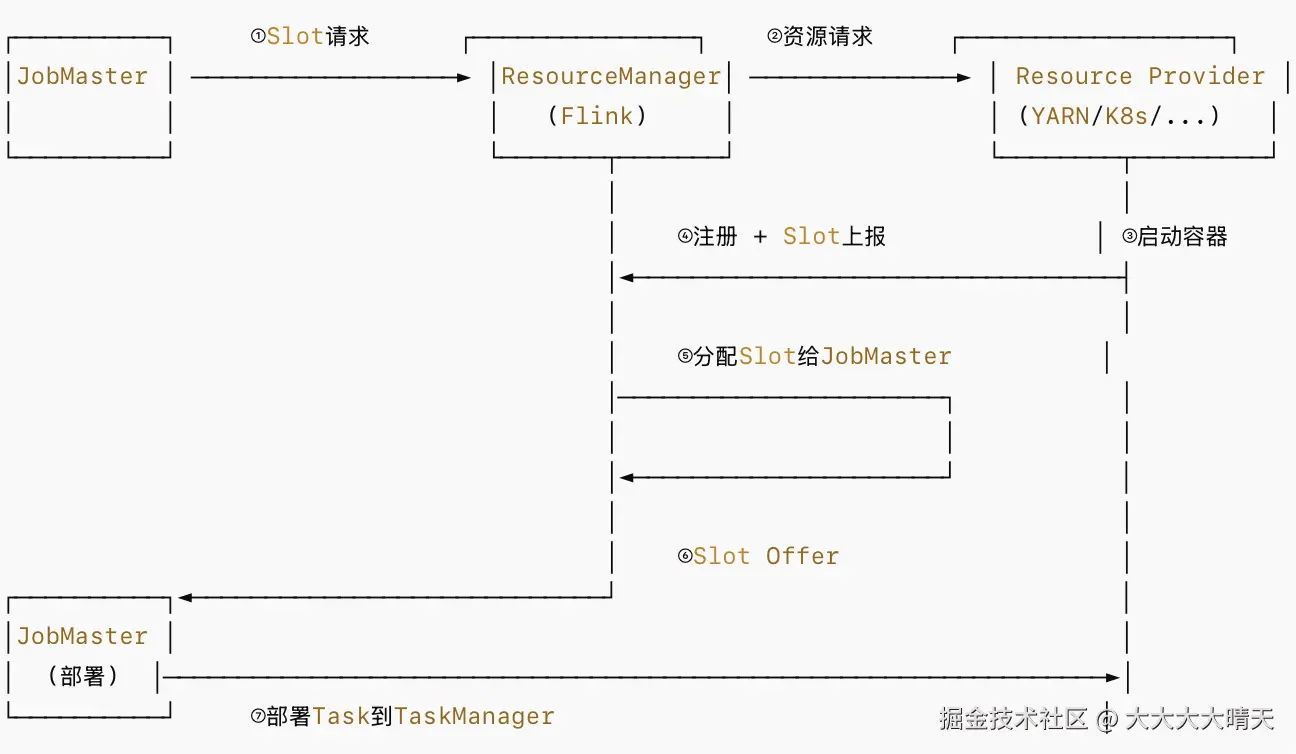
流程说明如下:
| 步骤 | 动作 | 说明 |
|---|---|---|
| ① | JobMaster → ResourceManager | 作业调度器发现缺少 Slot,发起请求 |
| ② | ResourceManager → Provider | Flink RM 向外部资源系统申请新容器 |
| ③ | Provider 启动容器 | YARN 分配 Container / K8s 创建 Pod |
| ④ | TaskManager 注册 | 新 TM 启动后向 RM 注册并上报可用 Slot |
| ⑤ | RM 内部分配 | 将 Slot 匹配到等待中的请求 |
| ⑥ | Slot Offer | RM 将 Slot 提供给 JobMaster |
| ⑦ | 部署 Task | JobMaster 将 Task 部署到对应 Slot |
3.Active vs Passive 资源管理
Flink 资源管理有两种范式:
- 被动式资源管理(Passive Resource Management):Flink 只能使用「外部已经准备好」的资源。它不会主动去申请或释放 TaskManager。典型代表是 Standalone:你手动启动多少个 TaskManager,Flink 就用多少个 Slot,不够就报资源不足。
- 主动式资源管理(Active Resource Management):Flink 的 ResourceManager 会根据作业需求,主动向底层资源提供方申请新的 TaskManager 容器,作业结束或缩容时再主动释放。典型代表是 Native Kubernetes 和 YARN。
| 特性 | Passive(Standalone) | Active(YARN / K8s Native) |
|---|---|---|
| TM 启动方式 | 预先手动启动 | 按需动态请求 |
| 弹性伸缩 | 不支持 | 支持 |
| 资源释放 | 不自动释放 | 空闲超时自动释放 |
| 故障恢复 | 需外部机制 | 自动重新请求容器 |
| 典型场景 | 开发测试 / 固定规模生产 | 生产环境弹性部署 |
三、Resource Providers 分类详解
1.Standalone
原理:用户手动启动固定数量的 TaskManager 进程,Flink ResourceManager 被动等待它们注册。
scss
┌─────────────────────────────────────────┐
│ Standalone Cluster │
│ │
│ ┌───────────┐ ┌───────────────┐ │
│ │ JM │ │ TM-1 (手动) │ │
│ │ │◄────│ TM-2 (手动) │ │
│ │ │ │ TM-3 (手动) │ │
│ └───────────┘ └───────────────┘ │
│ │
│ 资源固定,无弹性伸缩能力 │
└─────────────────────────────────────────┘优点:
- 部署简单,无外部依赖
- 启动速度快
- 适合开发调试与功能验证
缺点:
- 无弹性伸缩
- 资源利用率低(预分配)
- 故障恢复依赖外部监控
适用场景:本地开发、CI/CD 测试、小规模固定负载生产环境。
2.YARN (Hadoop YARN)
原理:Flink 的YarnResourceManager通过 YARN 的 AMRMClient 向 YARN ResourceManager 申请 Container,在 Container 中启动 TaskManager。
scss
┌──────────────────────────────────────────────────────────┐
│ Hadoop YARN Cluster │
│ │
│ ┌──────────────┐ ┌────────────────────────────┐ │
│ │YARN Resource │ │ Flink Application Master │ │
│ │ Manager │◄──────►│ (JM + Flink RM) │ │
│ └──────┬───────┘ └────────────┬───────────────┘ │
│ │ │ │
│ │ 分配Container │ 管理 │
│ ▼ ▼ │
│ ┌────────────┐ ┌────────────┐ ┌────────────┐ │
│ │ NodeMgr-1 │ │ NodeMgr-2 │ │ NodeMgr-3 │ │
│ │ ┌────────┐ │ │ ┌────────┐ │ │ ┌────────┐ │ │
│ │ │ TM-1 │ │ │ │ TM-2 │ │ │ │ TM-3 │ │ │
│ │ └────────┘ │ │ └────────┘ │ │ └────────┘ │ │
│ └────────────┘ └────────────┘ └────────────┘ │
└──────────────────────────────────────────────────────────┘优点:
- 与 Hadoop 生态深度集成
- 支持资源弹性伸缩
- 多租户资源隔离(Queue)
- 成熟稳定,社区经验丰富
缺点:
- 依赖 Hadoop 集群基础设施
- Container 启动速度相对较慢(JVM 启动 + 资源下载)
- 与 YARN 版本耦合,升级需要协调
- 在云原生场景逐渐被 K8s 取代
适用场景:已有 Hadoop 基础设施的企业、离线+实时统一资源池、大型企业多租户场景。
3.Native Kubernetes
原理:Flink 的KubernetesResourceManager通过 Kubernetes API Server 直接创建 TaskManager Pod。"Native"意味着 Flink 自身作为控制面直接与 K8s API 交互,而非通过外部 Operator 编排。
arduino
┌────────────────────────────────────────────────────────────┐
│ Kubernetes Cluster │
│ │
│ ┌──────────────┐ ┌─────────────────────────────┐ │
│ │ K8s API │ │ JM Pod │ │
│ │ Server │◄───────►│ (Flink RM + JobMaster) │ │
│ └──────┬───────┘ └──────────────┬──────────────┘ │
│ │ │ │
│ │ 创建/删除Pod │ 管理 │
│ ▼ ▼ │
│ ┌────────────┐ ┌────────────┐ ┌────────────┐ │
│ │ TM Pod-1 │ │ TM Pod-2 │ │ TM Pod-3 │ │
│ │ ┌────────┐ │ │ ┌────────┐ │ │ ┌────────┐ │ │
│ │ │ TM进程 │ │ │ │ TM进程 │ │ │ │ TM进程 │ │ │
│ │ └────────┘ │ │ └────────┘ │ │ └────────┘ │ │
│ └────────────┘ └────────────┘ └────────────┘ │
│ │
│ ConfigMap / Service / RBAC / PVC ... │
└────────────────────────────────────────────────────────────┘优点:
- 云原生,与容器生态无缝对接
- 快速弹性伸缩(Pod 启动通常秒级)
- 天然支持镜像版本管理与滚动更新
- 利用 K8s 丰富的调度策略(亲和性、污点容忍等)
- 适配多云、混合云场景
缺点:
- 需要 Kubernetes 集群及运维能力
- RBAC 权限配置相对复杂
- Pod 间网络通信需要正确配置
- 日志/监控需要接入 K8s 体系(如 Prometheus + Grafana)
适用场景:云原生架构企业、容器化部署、多云/混合云环境、新建实时计算平台。
4.对比总结
| 维度 | Standalone | YARN | Kubernetes Native |
|---|---|---|---|
| 弹性伸缩 | ✗ | ✓ | ✓ |
| 启动速度 | 快 | 中 | 快 |
| 资源隔离 | 弱(进程级) | 强(Container) | 强(Pod) |
| 运维复杂度 | 低 | 中 | 中~高 |
| 生态集成 | 独立 | Hadoop 生态 | 云原生生态 |
| 社区趋势 | 稳定 | 维护 | 活跃发展 |
| 故障自愈 | 需外部 | 支持 | 支持 |
| 多租户 | 弱 | 强(Queue) | 强(Namespace) |
四、部署模式详解
Resource Provider 解决的是"资源从哪来",部署模式解决的是"如何组织作业与集群的关系"。
当前Flink主要提供两种部署模式:Session Mode 、Application Mode 。(Per-Job Mode 自 Flink 1.15 起已标记为废弃,建议使用 Application Mode 替代。Per-Job Mode 仅 YARN 支持。)
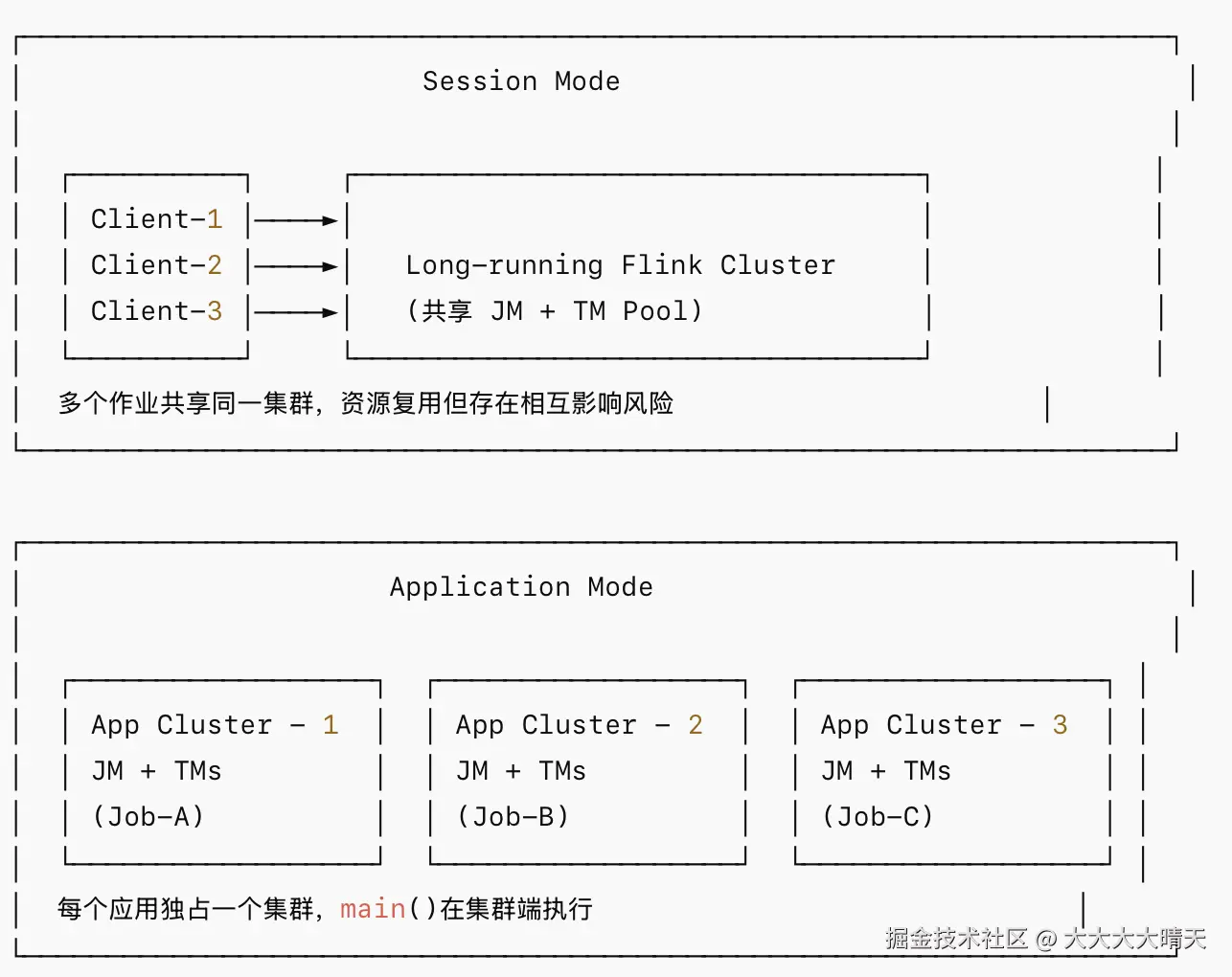
两者主要对比如下:
| 维度 | Session Mode | Application Mode |
|---|---|---|
| 集群生命周期 | 长期运行 | 与应用绑定 |
| 资源隔离 | 弱(共享) | 强(独占) |
| main() 执行位置 | Client 端 | Cluster 端(JM) |
| 适用场景 | 短生命周期作业、交互式开发 | 生产长时运行作业 |
| 资源利用率 | 高(复用) | 中(独占) |
| 启动延迟 | 低(集群已就绪) | 较高(需启动集群) |
五、部署场景实践
- YARN 场景实践
ini
# Application Mode 提交(推荐)
./bin/flink run-application -t yarn-application \
-Dyarn.application.name="streaming-etl" \
-Dyarn.application.queue="realtime" \
-Dyarn.provided.lib.dirs="hdfs:///flink/libs" \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=8192m \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dparallelism.default=16 \
-c com.example.StreamingJob \
hdfs:///flink/apps/streaming-job.jar- Kubernetes 场景实践
ini
# Application Mode 提交(推荐)
./bin/flink run-application \
--target kubernetes-application \
-Dkubernetes.cluster-id=streaming-etl \
-Dkubernetes.namespace=flink-prod \
-Dkubernetes.container.image=registry.example.com/flink-jobs:v1.2.3 \
-Dkubernetes.service-account=flink-sa \
-Dkubernetes.pod-template-file=/opt/flink/pod-template.yaml \
-Dkubernetes.taskmanager.cpu=4 \
-Dtaskmanager.memory.process.size=8192m \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dhigh-availability=kubernetes \
-Dhigh-availability.storageDir=s3://flink/ha \
-Dstate.checkpoints.dir=s3://flink/checkpoints \
-Dkubernetes.rest-service.exposed.type=NodePort \
-c com.example.StreamingJob \
local:///opt/flink/usrlib/streaming-job.jar六、总结展望
Flink Resource Providers 是连接 Flink 计算引擎与底层基础设施的关键纽带:
- Standalone 适合开发测试和小规模固定场景,简单直接
- YARN 适合已有 Hadoop 生态的企业,多租户能力成熟
- Kubernetes Native 是云原生时代的主流方向,弹性和可移植性突出
- Application Mode 是当前推荐的生产部署模式,兼顾隔离性与资源管理便利性
选型核心原则:优先适配已有基础设施,新建平台优先选择 Kubernetes Native + Application Mode。