一、单选题
-
常见的数据质量问题,不包括( )
(A) 噪声 (B) 异常点 (C) 缺失值 (D) 数据维度
-
常见的数据挖掘任务不包括( )
(A) 聚类分析 (B) 关联分析 (C) 预测分类 (D) 数据清洗
-
下列哪个不属于相似性度量( )
(A) 相关系数 (B) 余弦相似度 (C) Jaccard 系数 (D) 闵可夫斯基距离
-
设 X={a, b, c, d, e, f} 是频繁项集,则可由 X 产生( )个候选关联规则
(A) 60 (B) 62 (C) 64 (D) 32
-
簇评估的度量轮廓系数的取值范围是( )
(A) 0, 1 (B) -1, 1 (C) (0,1) (D) (-1,1)
-
下面选项中 t 不是 s 的子序列的是( )
(A) s=<{2,4}, {3,5,6}, {8}> t=<{2}, {3,6}, {8}>
(B) s=<{2,4}, {3,6,8}, {8}> t=<{2}, {6,8}>
(C) s=<{1,2}, {3,4}> t=<{2}, {2, 3}>
(D) s=<{2,4}, {2,4}> t=<{4}>
-
下列哪种方法或者模型不属于分类方法( )
(A) 神经网络 (B) 支持向量机 (C) 决策树 (D) DBSCAN
-
DBSCAN 在最坏情况下的时间复杂度是( )。(其中 n 为点的个数)
(A) O(n2)O(n^2)O(n2) (B) O(n)O(n)O(n) (C) O(logn)O(\log n)O(logn) (D) O(nlogn)O(n\log n)O(nlogn)
-
对于一颗决策树,若某个叶节点包含训练样本的数目为正类 8 个,负类 0 个,则这个叶节点的熵为( )
(A) 0 (B) 0.5 (C) 1 (D) 不确定
-
关于 Adaboost 算法,下列说法不正确的为( )
(A) 模型的权重和为 1 (B) 增加错误分类样本的权重
(C) 是一种集成算法 (D) 样本权重的和为 1
-
Scikit-learn 包提供了用于数据挖掘的各种模型 M,下列说法错误的是( )
(A)
M.fit()通常用于确定模型中的参数(B)
M.predict()用于新样本数据的预测(C)
M.score()用于计算预测准确度(D)
M.predict()通常需要传入测试集及其标签 -
在决策树中不纯度度量包括( )
(A) 基尼系数 (B) 熵 (C) 分类误差 (D) 以上都是
-
数据离散化方法不包括( )
(A) 等宽离散化 (B) 等频离散化 (C) K 均值离散化 (D) 方差离散化
-
被分类模型正确预测的负样本数用( )表示。
(A) FN (B) TP (C) FP (D) TN
-
以下关于分类和回归的说法中,错误的是( )
(A) 分类和回归都属于监督学习
(B) 决策树既可以用于分类也可以用于回归
(C) 分类和回归的评估均可使用均方误差(MSE)作为标准
(D) 分类和回归的区别在于输出变量的类型:分类输出离散值,回归输出连续值
二、简述题
-
叙述 DBSCAN 聚类的 5 个步骤。
-
(1)简述数据不平衡的概念及其对模型的影响;
(2)简述处理数据不平衡的方法。
三、计算题
- 给定数据集如下,假设属性 A,B 相互独立,且 A 的取值为 {1,2,3},B 的取值为 {S, M, L},Y 为类别。使用朴素贝叶斯方法预测测试样本(A=2, B=S)的类别标签。
| A | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 3 | 3 | 3 | 3 | 3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | S | M | M | S | S | S | M | M | L | L | L | M | M | L | L |
| Y | -1 | -1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | -1 |
-
假设 reg 是类
LogisticRegression的一个实例并用于二分类(0 或者 1),经过拟合之后,得到reg.coef_ = [-0.05, 0.67, 0.11],reg.intercept_ = -0.39,其中reg.coef_对应属性(x1,x2,x3)(x_1,x_2,x_3)(x1,x2,x3)的系数,设类别为 Y。写出逻辑斯蒂回归方程,并计算(x1,x2,x3)=(3.3,−3.5,1.1)(x_1,x_2,x_3)=(3.3,-3.5,1.1)(x1,x2,x3)=(3.3,−3.5,1.1)对应的类别。 -
给定如下训练样本集,使用基尼系数作为不纯度度量,计算:
(1)整个训练样本集关于类属性的基尼系数;
(2)a1a_1a1为序数型属性,如何二元划分a1a_1a1信息增益最大,画出此时对应的决策树(高度为 1);
(3)对于连续属性a2a_2a2,划分点为 3.8 时的信息增益。
| 实例 | a1a_1a1 | a2a_2a2 | 目标类 |
|---|---|---|---|
| 1 | 高 | 1.0 | + |
| 2 | 低 | 6.0 | + |
| 3 | 低 | 5.0 | - |
| 4 | 中 | 4.0 | + |
| 5 | 中 | 5.0 | - |
| 6 | 高 | 2.3 | - |
| 7 | 中 | 3.0 | + |
- 下表给出了一个二分类问题的分类模型M1M_1M1,表格中给出的是把模型应用到数据集上得到的后验概率(表中为正类的概率),XXX为属性向量。

详细写出 ROC 曲线所需要数据的计算过程并画出模型M1M_1M1的 ROC 曲线,并计算面积 AUC。
-
下图是一棵包括 15 个候选 3 - 项集的哈希树,其使用的哈希函数为h(p)=(p−1)mod 3h(p)=(p-1)\mod 3h(p)=(p−1)mod3,给定事务 {1, 2, 4, 5, 8, 9},计算该事务会使得哪些 3 - 项集的支持度计算加 1。要求写出详细过程。
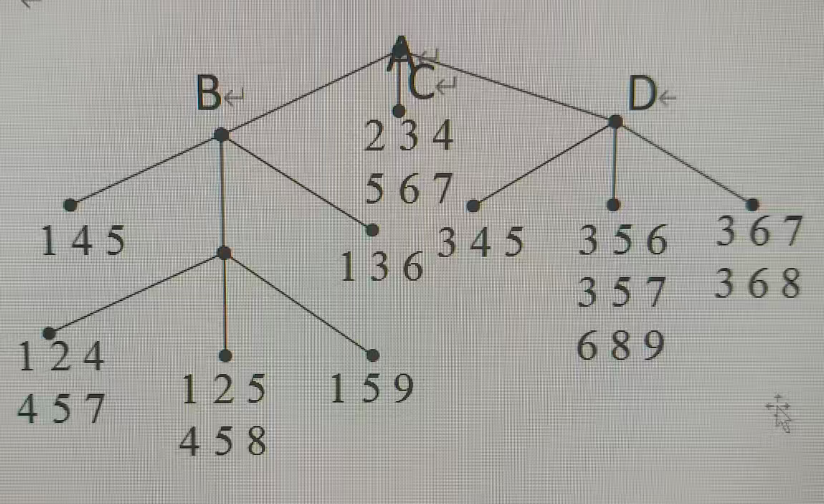
-
梯度提升算法(GBDT)的流程如下图所示,对于下表中给定的数据集,使用梯度提升树对yyy进行拟合(即属性为xxx,回归目标为yyy),写出最终的拟合函数。
- 要求:(1) 使用决策树桩(高度为 1 的决策树);(2) 损失函数LLL使用误差平方和;(3) 学习率α=0.1\alpha=0.1α=0.1;(4) M=2M=2M=2
| 序号 | xxx | yyy |
|---|---|---|
| 1 | 5 | 2 |
| 2 | 7 | 3.2 |
| 3 | 10 | 4 |
| 4 | 15 | 6 |
算法流程(GBDT)
输入:训练数据T=(x1,y1),...,(xN,yN), xi∈Rn,yi∈RT={(x_1,y_1),\dots,(x_N,y_N)},\ x_i\in R^n,y_i\in RT=(x1,y1),...,(xN,yN), xi∈Rn,yi∈R
输出:提升树f^(x)\hat{f}(x)f^(x)
(1) 初始化 f0(x)=argminc∑i=1NL(yi,c)f_0(x)=\arg\min_{c}\sum_{i=1}^N L(y_i,c)f0(x)=argminc∑i=1NL(yi,c)
(2) 对 m=1,2,3,...,Mm=1,2,3,\dots,Mm=1,2,3,...,M
(a) 对 i=1,2,...,Ni=1,2,\dots,Ni=1,2,...,N,计算 rmi=−∂L(yi,f(xi))∂f(x)∣f(x)=fm−1(x)r_{mi}=-\left.\frac{\partial L(y_i,f(x_i))}{\partial f(x)}\right|{f(x)=f{m-1}(x)}rmi=−∂f(x)∂L(yi,f(xi)) f(x)=fm−1(x)
(b) 对 rmir_{mi}rmi 拟合一棵回归树,得到第mmm棵树,其叶节点记为 Rmj,j=1,2,...,JR_{mj},j=1,2,\dots,JRmj,j=1,2,...,J
(c) 对 j=1,2,...,Jj=1,2,\dots,Jj=1,2,...,J,计算 cmj=argminc∑xi∈RmjL(yi,fm−1(xi)+c)c_{mj}=\arg\min_{c}\sum_{x_i\in R_{mj}} L(y_i,f_{m-1}(x_i)+c)cmj=argminc∑xi∈RmjL(yi,fm−1(xi)+c)
(d) 更新 fm(x)=fm−1(x)+α∑j=1Jcmj⋅δ(x∈Rmj)f_m(x)=f_{m-1}(x)+\alpha\sum_{j=1}^J c_{mj}\cdot\delta(x\in R_{mj})fm(x)=fm−1(x)+α∑j=1Jcmj⋅δ(x∈Rmj),其中α\alphaα为学习率
(3) 得到回归树 f^(x)=f0(x)+α∑m=1M∑j=1Jcmj⋅δ(x∈Rmj)\hat{f}(x)=f_0(x)+\alpha\sum_{m=1}^M\sum_{j=1}^J c_{mj}\cdot\delta(x\in R_{mj})f^(x)=f0(x)+α∑m=1M∑j=1Jcmj⋅δ(x∈Rmj)
(注:文档部分内容可能由 AI 生成)