目录
[Fermi 架构](#Fermi 架构)
[Kepler 架构](#Kepler 架构)
概述
一个优秀的赛车手(CUDA 程序员),不能只会转动方向盘(编程模型),他必须深刻理解这辆车的四驱特性和涡轮介入时机(执行模型),才能在赛道上开出极限速度。
前面我们了解了基础的编程模型,一个核函数如何启动如何编写,我们知道了一些简单的工具的使用,接下来我们将深入底层,去了解CUDA执行模型
硬件物理设计 → CUDA 执行模型 → CUDA 编程模型
第一层:硬件物理设计
这是地基。指的是我们聊过的 GPU 内部物理实现:SM 怎么组成、CUDA 核心数量、内存控制器、线程束调度器、共享内存大小等。这一切都是物理上刻在硅片上的,决定了性能的根本上限。
第二层:CUDA 执行模型
这是连接硬件和软件的抽象层和"使用说明书"。它告诉你:硬件是按照"线程束(Warp)"为单位来调度线程的;SM 是通过快速切换 Warp 来掩盖访存延迟的;内存有全局、共享、寄存器等层级。
第三层:CUDA 编程模型
这是给你用的工具和规则 。比如
__global__、<<<>>>、threadIdx、__syncthreads()等。它让你能以一种相对容易的方式,去指挥硬件干活。你的程序(比如如何划分线程块、如何组织内存访问)如果能顺应硬件的脾性(如内存合并访问、Warp 调度),就能跑出接近理论峰值的性能。如果背离,性能就会大打折扣。
架构发展图
架构名称 发布年份 计算能力 每个 SM 最大线程数 核心硬件突破 代表显卡(消费级 / 专业卡 / 数据中心) Tesla(特斯拉) 2006 1.x 768 第一个支持 CUDA 的通用计算架构,首次引入 SM 概念 GeForce 8800 GTX、Tesla C870 Fermi(费米) 2010 2.x 1536 第一个完整的 CUDA 架构,统一缓存层次,支持 ECC 显存 GeForce GTX 480、Tesla C2070 Kepler(开普勒) 2012 3.x 2048 动态并行、Hyper-Q 技术,SM 线程上限首次达到 2048 GeForce GTX 680/780 Ti、Tesla K80 Maxwell(麦克斯韦) 2014 5.x 2048 能效比革命,优化 SM 调度,引入统一内存雏形 GeForce GTX 980、Tesla M40 Pascal(帕斯卡) 2016 6.x 2048 原生 FP16 支持、NVLink 1.0、统一内存正式版 GeForce GTX 1080 Ti、Tesla P100 Volta(伏特) 2017 7.0 2048 第一代张量核心,独立整数单元,开启 AI 加速时代 无消费级,Tesla V100 Turing(图灵) 2018 7.5 2048 第一代光追核心、第二代张量核心,实时光追落地 GeForce RTX 2080 Ti/GTX 1660、Quadro RTX 6000 Ampere(安培) 2020 8.0/8.6 2048 第三代张量核心(TF32/BF16)、第二代光追核心、结构化稀疏 消费级:RTX 3090/3060数据中心:A100/A800 Ada Lovelace(阿达・洛芙莱斯) 2022 8.9 2048(高端)1536(中低端) 第四代张量核心(原生 FP8)、第三代光追核心、DLSS 3 消费级:RTX 4090/4080/4070 Ti(2048 线程 / SM) **RTX 4060(AD107,1536 线程 / SM)**数据中心:L4/L40 Hopper(霍珀) 2022 9.0 2048 数据中心专属,第五代张量核心、Transformer 引擎、NVLink 4.0 无消费级,H100/H200 Blackwell(布莱克韦尔) 2024 10.x 2048 第六代张量核心(FP4/FP6)、第四代光追核心、多芯片设计 消费级:RTX 5090/5080数据中心:B100/B200/GB200
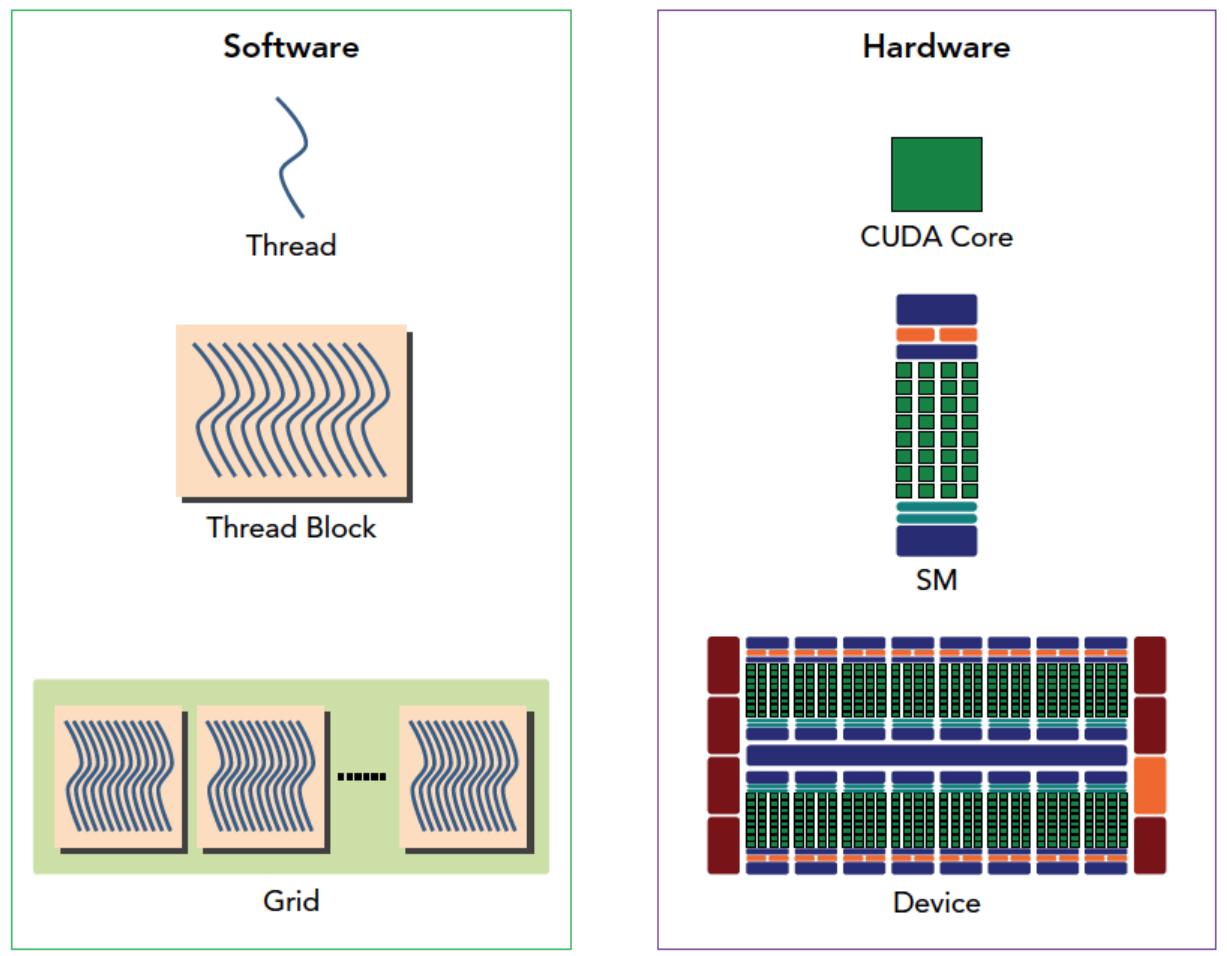
SM
cpp1.完整 GPU 芯片(比如 RTX 4060) │ ├── 2. 显存(VRAM,8192 MB) │ │ 全局内存(Global Memory) │ │ L2 缓存(所有 SM 共享) │ └── 3. N 个流多处理器(SM,4060卡有 24 个) │ 每个 SM 是独立、并行的计算车间 │ ├── 指令缓存(I-Cache) ├── 线程束调度器(Warp Scheduler) ├── 寄存器文件(Register File) ├── 共享内存 / L1 缓存(Shared Memory / L1 Cache) │ └── 4. M 个 CUDA 核心(每个 SM 有 多 个) 以及其他功能单元(Tensor Core、特殊函数单元 SFU 等)接下来我们将重点介绍SM(Streaming Multiprocessor,流式多处理器)
Instruction Cache(指令缓存):
存储即将执行的核函数指令,大小通常是 16-32KB。因为同一个核函数的指令会被成千上万的线程重复执行,所以指令缓存命中率极高。
Warp Scheduler(Warp 调度器):
- 每个 SM 有 2 个独立的 Warp 调度器
- 每个调度器管理自己的 Warp 队列,里面存放着所有就绪的 Warp
- 当一个 Warp 因为等待内存访问而阻塞时,调度器会零开销地切换到下一个就绪的 Warp,不需要保存和恢复上下文
- 每个周期,每个调度器可以发射 1 个 Warp 的指令
Dispatch Unit(指令分发单元):
把调度器选中的指令,分发到对应的执行单元(CUDA 核心、LD/ST、SFU)去执行。
寄存器文件(蓝色大框)
这是 SM 最重要的资源,它的大小直接决定了
maxThreadsPerMultiProcessor的数值。每个线程的私有变量都存这里,速度最快。(注意这里是硬件统一大小,但是软件进行了划分,以线程束为单位进行分配大小,从而达到每个线程独占自己的寄存器)
CUDA 核心(左边两个绿色大框)
不同的架构的CUDA核心数量是不同的
LD/ST 单元(第三个绿色框)
- LD = Load(加载),ST = Store(存储)
- 专门负责执行内存读写指令:从共享内存、L1 缓存、全局显存加载数据,或者把结果写回去
- 每个周期可以执行 32 个 32 位的内存操作
SFU 单元(第四个绿色框)
- SFU = Special Function Unit(特殊功能单元)
- 专门负责执行复杂的数学运算:正弦、余弦、指数、平方根、倒数等
- 这些运算在 CUDA 核心上执行会非常慢,所以专门做了硬件加速
注意:这张图是老架构的,没有画出张量核心和光追核心。Ada 架构的 SM 每个都有 4 个张量核心和 1 个光追核心,在这张图的执行单元区域旁边。
Interconnect Network(内部互连网络):
一个高速交叉开关,连接所有执行单元和存储单元,允许任意执行单元访问任意存储位置。
Shared Memory / L1 Cache(共享内存 / L1 缓存):
这是一个统一的 64KB 存储块,可以动态划分成共享内存和 L1 缓存:
作为共享内存:由程序员手动管理,同一个线程块内的所有线程可以共享访问
作为 L1 缓存:由硬件自动管理,缓存全局内存的访问
Ada 架构 :这里已经升级到 128KB,比图里的 64KB 大一倍
Uniform Cache(统一缓存):
专门用来存储常量数据和纹理数据,这些数据是所有线程共享的只读数据。
注意所有的硬件的数量和大小,要查自己当下的硬件配置,图中只是把重要部分罗列,并且数量和大小不是每张显卡都是这样
当你启动一个核函数的时候,执行<<<grid,block>>>的时候就会开始分配资源然后开始调度
Block(线程块) :是最小的调度单位 。一个 Block 一旦被分配给某个 SM,它就会一直在那个 SM 上执行,直到完成。Block 内部的线程共享该 SM 的资源(共享内存、寄存器),并且可以通过
__syncthreads()进行同步。Grid(网格) :是你启动核函数时的所有 Block 的集合。硬件的任务就是把这些 Block 分发到各个 SM 上去执行。
这里就有点像线程是基础的调度单元一样,gpu的调度单元就是线程块,注意是一块一块的不是一个线程一个线程的
当你调用
kernel<<<grid, block>>>(...)时,GPU 的 GigaThread Engine(全局调度器) 会做这件事:
检查你定义了总共多少个 Block(
grid.x × grid.y × grid.z)。检查每个 SM 上有多少空闲资源(可容纳多少个 Block、多少线程、多少共享内存)。
把 Block 尽可能均匀地分配到所有可用的 SM 上。
比如我的 RTX 4060 有 24 个 SM。 如果网格有 131,072 个 Block,调度器会把它们拆成一批一批,发送给这 24 个 SM。每个 SM 可能同时容纳多个 Block(比如 2~8 个不等),当某个 SM 上的 Block 执行完毕后,调度器会立刻再分配新的 Block 给它,直到所有 Block 执行完毕。
一个SM到底分配多少个Block呢?这取决于你的SM中的资源是否充足
资源限制 我的 RTX 4060 每个 SM 的限制 说明 最大线程数 1536 个线程 所有活跃 Block 的线程总数不能超过这个值。 最大线程束数 48 个 Warp 1536 / 32 = 48。 最大 Block 数 硬件直接限制 通常为 8、16 或 32 个,具体取决于架构。 寄存器数量 65536 个 32 位寄存器 每个线程用到的寄存器越多,能同时容纳的线程就越少。 共享内存大小 最大约 100 KB(可配置) 每个 Block 使用的共享内存越多,能同时容纳的 Block 就越少。 单个block不能配置超过1024个线程,配置超过了你的核函数压根启动不起来,这是启动前的检查
如果你配置了多个block,但是每个block占的资源都非常多,导致不能并行计算,全局调度器会等上批block计算完之后释放资源,下一批在进去(它只会分配SM当前能容纳的block)
要启动足够多的 Block:Block 数量远大于 SM 数量时,所有 SM 才能被喂饱,整个 GPU 的计算能力才能被充分利用。如果只启动 1 个 Block,你只能用 1 个 SM,浪费了其余 23 个 SM 的能力。
Block 不能跨 SM 执行:这就是为什么同一个 Block 内的线程可以共享内存、做同步,而跨 Block 的线程完全独立。
Block 的执行顺序是不确定的:调度器根据资源情况动态分配,你不能假设哪个 Block 会先执行完。

线程束
线程束(Warp)是一个由 32 个线程组成的、不可分割的调度和执行单元。
无论你在
<<< >>>里定义多少个线程,GPU 硬件都会自动把它们划分成一个又一个的线程束。每个线程束里的 32 个线程,由 SM(流多处理器)内部的线程束调度器统一指挥。GPU是SIMT架构,也就是单指令多线程,SM 里的线程束调度器,一次只会选择一个就绪的线程束 ,然后向它发射一条指令。这条指令会被广播给这个线程束里的所有 32 个线程,它们同时执行同一条指令,但各自处理不同的数据。(本质就是一条指令直接下发给多个线程,不需要一个一个线程单独发,这样可以简化硬件面积,把面积让给给多的计算单元)
比如定义了一个线程块
block(256),硬件会自动把它均匀地切成 8 个线程束(256 ÷ 32 = 8)。这 8 个线程束会被分配给同一个 SM。SM 的线程束调度器会盯住这 8 个线程束,任何一个准备好执行了(所需数据已经就位),就立刻把指令发给它。
如果我把block定义成不是32的整数倍,那就会有槽位浪费,什么都不做,所有的指令针对这个线程束下发,剩下的浪费槽位是不可以利用的
线程束是用你block的总线程数量/32,然后排列成一个一维的,然后32个32个一组,先x方向,然后y方向,然后z方向
000 001 002 010 011 012 ......然后每32个划分一组包装成线程束被SM的线程束调度器进行调度
线程束是理解 GPU 性能的钥匙。
① 分支发散
同一个线程束里的 32 个线程,如果遇到
if-else走了不同的分支,会发生什么?因为所有线程都被迫执行同一条指令,所以它们只能先集体执行if路径(走else的线程干等),再集体执行else路径(走if的线程干等)。一个线程束内出现分支,会导致执行时间翻倍,性能直接腰斩。优化 CUDA 代码的一个重要目标,就是尽量避免让同一个线程束内的线程走上不同的分支路径。
② 内存合并访问
同一个线程束里的 32 个线程,当它们执行访存指令时,硬件会尽力将它们的 32 次独立请求合并成一次或几次大块的连续访问。只有当这 32 个线程访问的地址是连续、对齐的时候,合并访问才能实现,带宽利用率才能接近峰值。 如果地址散乱,就会退化成 32 次单独访问,性能暴跌。
SIMD与SIMT
SIMD 的核心是显式操作向量。程序员需要明确使用向量类型和向量指令。这里用 Intel 的 SSE 指令集举例:
cpp#include <xmmintrin.h> // SSE 头文件 void add_arrays_simd(float* a, float* b, float* c, int n) { // 每次循环处理 4 个 float (SSE 寄存器是 128 位) for (int i = 0; i < n; i += 4) { // 1. 从内存加载 4 个数到向量寄存器 __m128 va = _mm_loadu_ps(&a[i]); __m128 vb = _mm_loadu_ps(&b[i]); // 2. 一条指令把两个向量里的 4 对数同时相加 __m128 vc = _mm_add_ps(va, vb); // 3. 把结果向量存回内存 _mm_storeu_ps(&c[i], vc); } }SIMT 的核心是写标量代码,用多线程伪装成向量执行。
cpp__global__ void add_arrays_simt(float* a, float* b, float* c, int n) { // 我完全是一个标量线程,我只负责一个元素! int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) { c[i] = a[i] + b[i]; // 这看起来就是普通的标量加法 } }SIMD 的死板 :你用 SSE 指令
_mm_add_ps一次操作 4 个 float。如果这 4 个数里,有些需要加、有些需要乘,你没法用一条 SIMD 指令搞定。你必须把数据从向量寄存器里拆出来,用标量判断,再用条件移动或掩码绕过去,非常笨拙。不同批次的 4 个数据之间,也只能串行处理,毫无灵活性。SIMT 的灵活 :你的代码对每个线程是标量的。硬件把 32 个线程打包成一个 Warp,用一条指令同时执行。如果某个 Warp 里的 32 个线程恰好都走同一条路径 ,那么它们就一次性高效完成,没有分化。不同的 Warp 可以同时走完全不同的分支,互不干扰。 这是 SIMD 无法想象的------SIMD 的向量指令只能串行处理不同的分支路径,而 SIMT 可以用多个 Warp 并行处理不同的分支。
cpp每个线程独享: ├── 自己的寄存器(局部变量优先放这里) ├── 自己的局部内存(寄存器不够用时,编译器自动分配) ├── 自己的程序计数器(逻辑上独立)当发生分支时,硬件通过活跃掩码来串行化不同路径。 └── 自己的坐标(threadIdx, blockIdx)------ 只读 同一个 Block 内共享: ├── 共享内存(__shared__) └── L1 缓存 所有线程共享: ├── 全局内存(cudaMalloc) ├── 常量内存 └── 纹理内存
CUDA编程的组件与逻辑
线程块内线程通过共享内存 和全局内存 通信,通过寄存器各自独立计算,寄存器是私有计算空间。
Block 不是一次性全部在 GPU 上启动的,而是根据 SM 的空闲资源情况,一批一批地分配到 SM 上执行。当某个 SM 上的 Block 执行完、释放资源后,调度器再给它分配新的 Block。同一个线程束内的线程拥有相同的进度,但是针对不同的线程束就不一定了
一个Block里面可能有多个线程束,但是可能进度不一样,并行就会引起竞争,多线程以未定义的顺序访问同一个数据,就导致了不可预测的行为,CUDA只提供了一种块内同步的方式,块之间没办法同步!(块内同步__syncthreads(),或可以通过 warp shuffle 指令 直接交换寄存器数据)
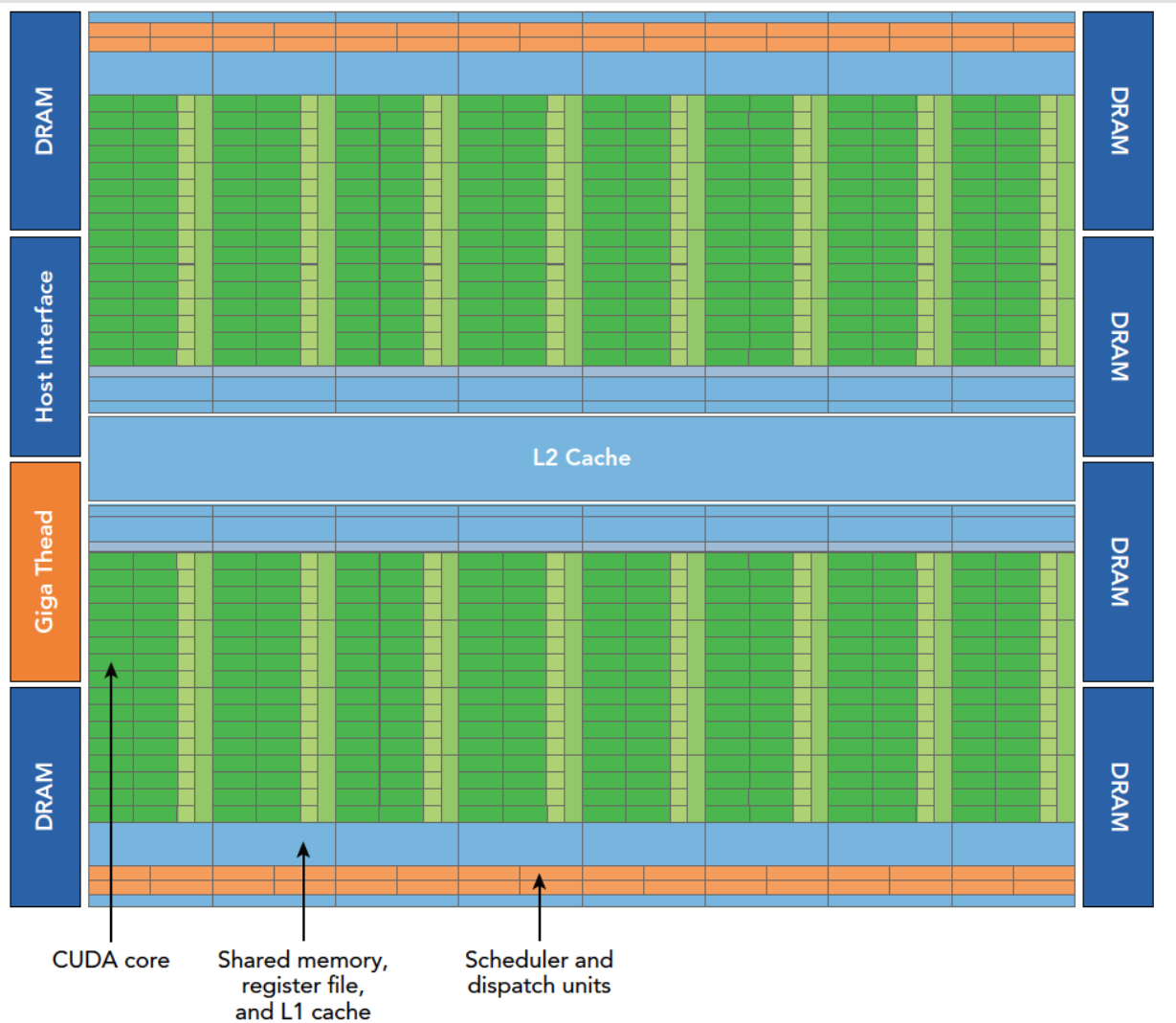
Fermi 架构
这不是一个SM,这是经典的 Fermi(费米,2010 年)架构 全局框图,是 NVIDIA 第二代完整 CUDA 架构
图中可以看出
- 接口层:主机接口(GPU 和 CPU 之间的通信桥梁,通过 PCIe 总线和 CPU 主机连接)、显存控制器,负责和 CPU、显存通信
- 全局调度层:Giga Thread 千兆线程引擎,负责全局任务分配
- 全局缓存层:L2 二级缓存,所有 SM 共享
- 计算核心层:由16个 SM 组成的并行计算阵列,是算力的来源,512个CUDA核心
Giga Thread 千兆线程引擎
- 接收 CPU 发来的核函数启动请求,拿到整个网格(Grid)的线程配置
- 把网格拆成一个个线程块(Block),按照负载均衡原则,分配到空闲的 SM 上去执行
- 动态监控所有 SM 的负载,哪个 SM 跑完了线程块,就立刻给它分配新的
- 管理全局线程状态,处理异常、中断和同步
DRAM 显存控制器
GPU 显存的控制接口,连接 GPU 芯片和 PCB 板上的物理显存颗粒
- 容量大:从几 GB 到几十 GB
- 速度慢:访问延迟几百个时钟周期,是寄存器的上百倍
- 所有
cudaMalloc分配的空间、全局变量、纹理数据,最终都存在这里L2 Cache(二级缓存)
全 GPU 所有 SM 共享的全局缓存,是显存和 SM 之间的「中间缓冲层」
- 缓存显存的热点数据,大幅减少对低速显存的访问次数
- 不同 SM 之间可以通过 L2 共享数据,不用每次都绕回显存
SM 计算阵列(绿色区域)
流程解析
- CPU 发命令 :CPU 执行核函数
kernel<<<gridDim, blockDim>>>(args),通过 PCIe 总线把启动命令和参数传给 GPU 的 Host Interface。- 全局分配任务:Host Interface 把命令交给 Giga Thread 引擎;引擎把整个 Grid 拆成一个个 Block,按照负载均衡分配到各个空闲的 SM 上。
- SM 内拆解调度:每个 SM 收到 Block 后,把 Block 拆成若干个 Warp(32 线程一组),由内部的 Warp 调度器管理。
- 指令执行:调度器把 Warp 的指令发射给 CUDA 核心;数据按「寄存器→共享内存 / L1→L2→显存」的顺序读取,优先用高速存储。
- 结果写回:计算完成后,结果按原路写回,最终存入显存。
- 完成通知:所有 Block 执行完毕后,Giga Thread 通过 Host Interface 通知 CPU,核函数执行结束。
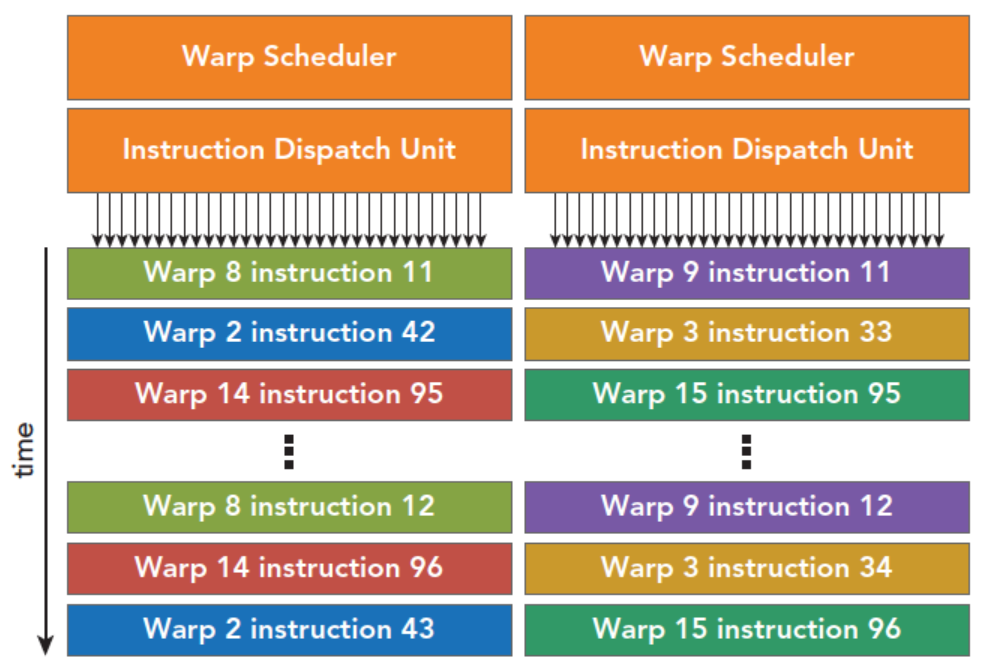
每个SM有两个线程束调度器,和两个指令调度单元,当一个线程块被指定给一个SM时,线程块内的所有线程被分成线程束,两个线程束调度器选择其中两个线程束,在用指令调度器存储两个线程束要执行的指令
像第一张图上的显示一样,每16个CUDA核心为一个组,还有16个加载/存储单元(LD/ST)或4个特殊功能单元(SFU)。当某个线程块被分配到一个SM上的时候,会被分成多个线程束,线程束在SM上交替执行
学Linux内核的时候,我们知道一个线程切换的时候,是需要换上下文数据的,为什么?
核心就是因为寄存器只有一套,你要把当前的线程的上下文保留然后写到内存,从别的线程的内存那里把上下文加载到cpu寄存器里面,这就是上下文切换的开销
但是针对gpu来说,每个线程束在同一时间执行同一指令,同一个块内的线程束互相切换是没有时间消耗的。
每个线程的上下文,物理上就常驻在 SM 的寄存器文件里。从线程被分配到 SM 上的那一刻起,它私有的所有寄存器就一直占据着寄存器文件中的固定物理位置,直到这个线程块执行完毕退出。
线程束调度器(Warp Scheduler)切换 Warp 时,完全不需要搬运任何数据。它只是改变一个内部的"指针",告诉取指单元:"下一个时钟周期,去寄存器文件的这一片区域取指令和操作数。"
本质就是因为有多套独属于自己的寄存器,这种"零开销切换"是用巨大的芯片面积和功耗换来的。SM 内部那个寄存器文件占据了芯片的很大一部分
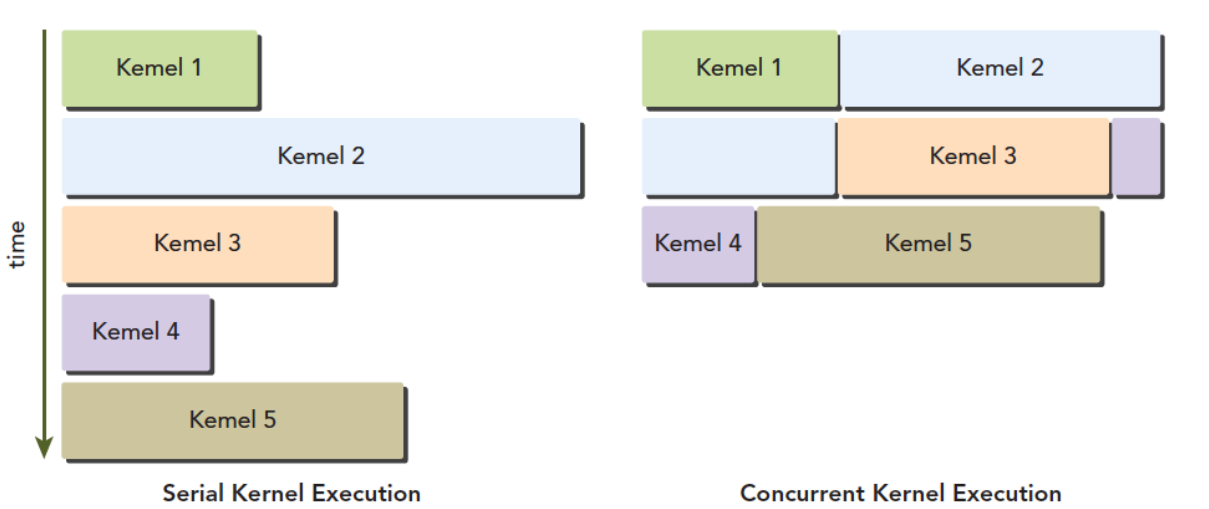
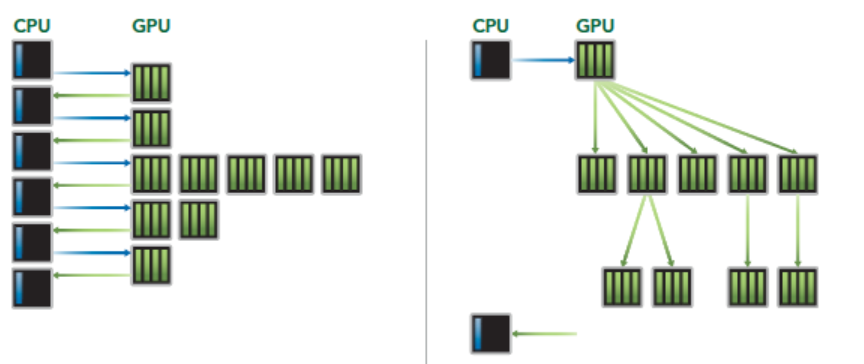
针对核函数:左边这种调度方式是串行的,右边是并行的
Serial Kernel Execution(串行执行)
这是 CUDA 的默认行为 :如果你不做任何特殊配置,所有核函数都会按代码顺序排队,前一个完全跑完,后一个才会开始。
- 同一时刻,整个 GPU 上只有 1 个核函数在运行
- 所有 SM 都只为这一个核函数服务
- 执行顺序和代码顺序完全一致,天然没有依赖问题
- 最大的问题:资源浪费
Concurrent Kernel Execution(并发执行)
通过 CUDA 流(CUDA Stream) 把不同的核函数提交到不同的任务队列,多个独立的核函数可以同时在 GPU 上运行 ,共享所有 SM 资源。(底层靠GigaThread全局调度引擎实现)
- 同一时刻,GPU 上有多个核函数同时运行
- 多个核函数共享全部 SM、缓存、显存带宽
- 总吞吐量大幅提升,硬件利用率更高
- 单个核函数的执行速度不会变快,甚至可能略慢(因为分到的资源变少了)
并发只对多个独立的小计算任务有意义,比如同时处理多张图片、多个独立的小矩阵运算。
Kepler 架构
化整为零,以量取胜
- 强化的SM
- 动态并行
- Hyper-Q技术
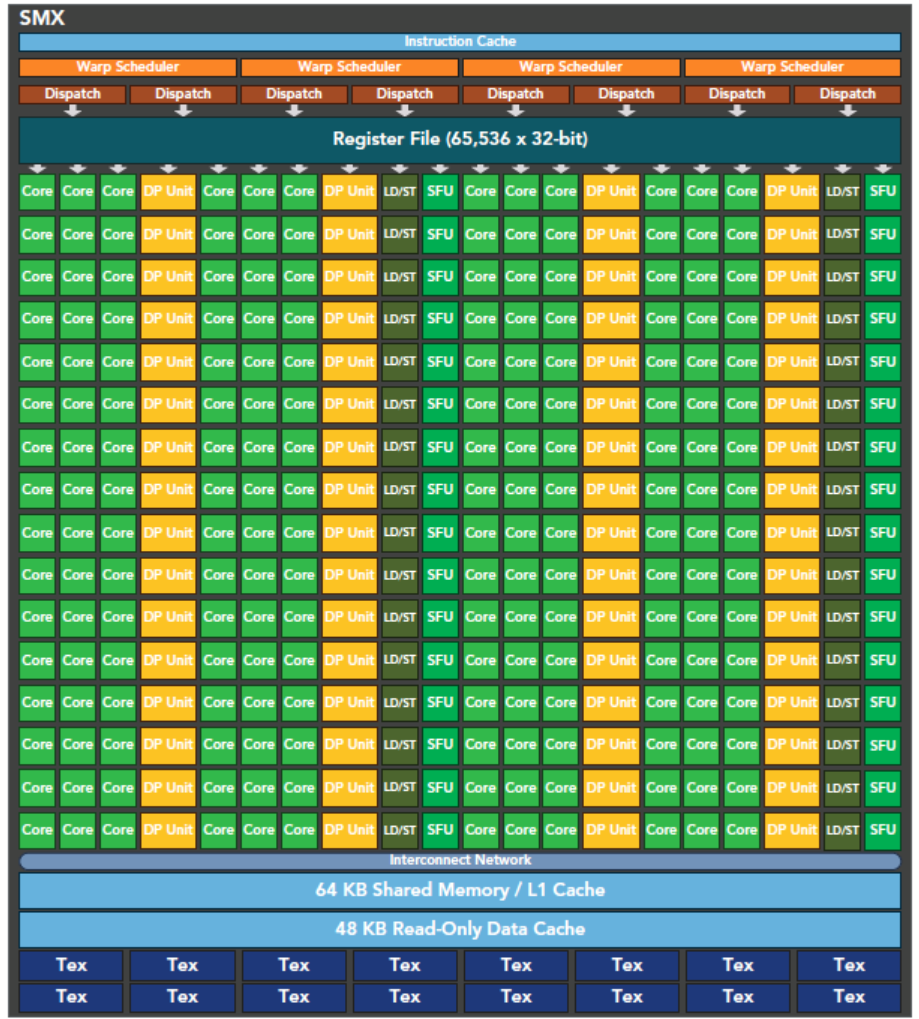
SMX(Streaming Multiprocessor eXtreme):核心计算单元
图中每一个竖向的长条,就是一个完整的 SMX。这是 Kepler 架构最核心的升级,取代了 Fermi 时代的 SM,单单元的并行规模和算力大幅提升。
整体规格
图中完整 GK110 核心共 15 个 SMX
每个 SMX 包含 192 个单精度 CUDA 核心,是 Fermi SM(32 个)的 6 倍
额外集成 64 个双精度计算单元、32 个特殊功能单元(SFU)、32 个加载 / 存储单元(LD/ST)
- SMX 大核心设计:堆出极致吞吐量
Kepler 没有提升核心频率,而是走了 "做大单个 SM、堆执行单元" 的路线:单个 SMX 的 CUDA 核心数量从 32 涨到 192,整体算力和能效比大幅提升。这也是 NVIDIA 第一次把 SM 做的这么大,因此命名为 SMX(eXtreme)。
- 双精度性能爆发
Kepler 消费级卡的 FP64 性能达到 FP32 的 1/3,计算卡更是完整 1:1,是 Fermi 的数倍。这让 Tesla K 系列计算卡成为当年超算、科学计算的绝对主力,也奠定了 NVIDIA 在高性能计算市场的地位。
- 动态并行(Dynamic Parallelism)
Kepler 首次支持:核函数内部可以直接启动新的核函数,不需要把调度权交回给 CPU。 这大幅减少了 CPU-GPU 的交互开销,非常适合递归类算法、自适应网格等需要动态生成任务的场景。
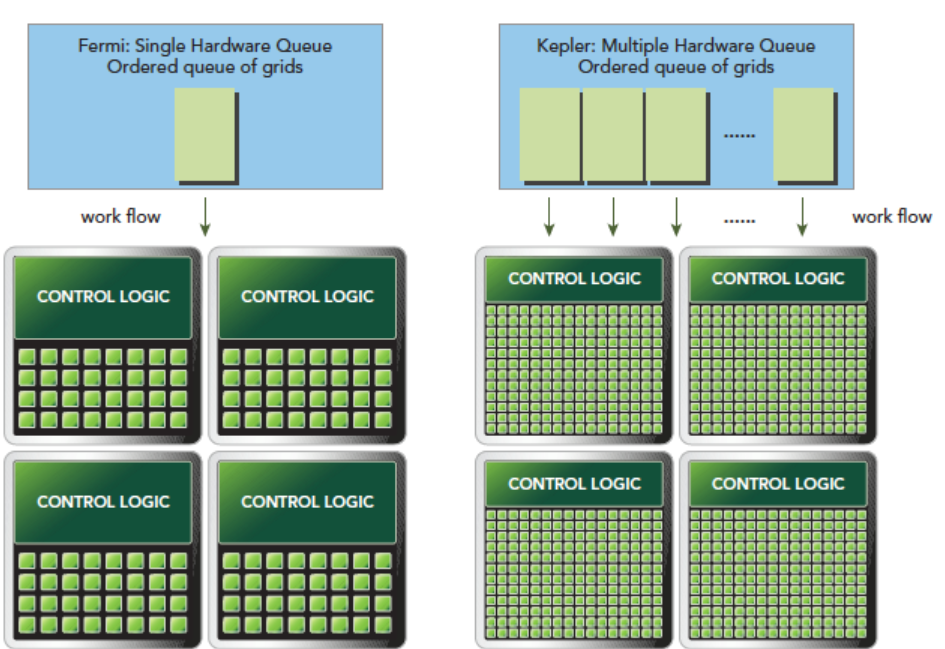
- Hyper-Q 多队列技术
硬件支持 32 个独立的工作队列,CPU 可以同时提交多个不同的任务,不会因为单个任务阻塞而浪费 GPU 资源,多任务并发效率比 Fermi 提升数倍。
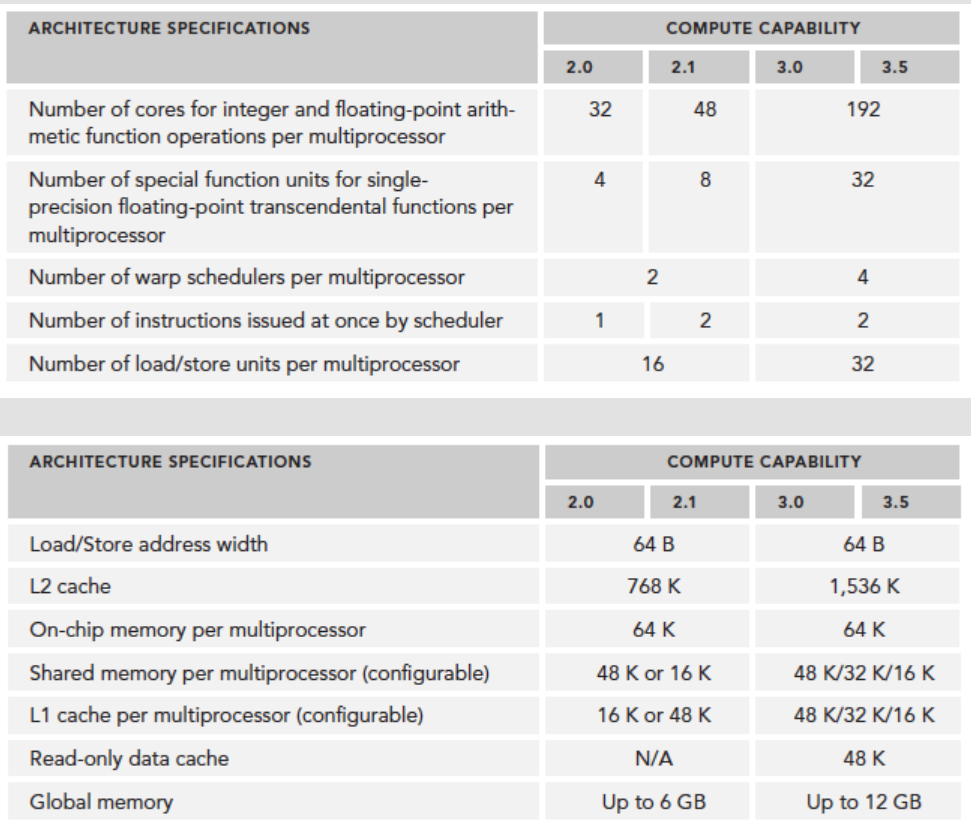
计算能力
简单来说硬件全面升级,软件方面也有策略升级

Profile
"Profile-Driven Optimization" 的真正含义是:根据性能分析工具采集到的客观数据来驱动你的优化决策。
性能分析通过以下方法来进行:
- 应用程序代码的空间(内存)或时间复杂度
- 特殊指令的使用
- 函数调用的频率和持续时间
理解平台的执行模型也就是硬件特点+算法,是优化性能的基础。
优化的两步走
先保证正确和健壮:结果必须对。
再追求速度
我们要学会使用性能分析工具,针对某个性能瓶颈,加上自己的硬件+算法的分析进行优化
Nsight Systems 和 Nsight Compute之前提到过的 写文章-CSDN创作中心
https://mp.csdn.net/mp_blog/creation/editor/161895970?spm=1001.2014.3001.9457
常见的瓶颈因素
存储带宽 (Memory Bandwidth) :数据搬运是最大瓶颈。比如你测出 70% 时间花在
cudaMemcpy上,就该想能否减少拷贝或用异步流。计算资源 (Compute Resources):SM 上 CUDA 核心、SFU 等的利用率。比如分支发散会导致一半核心闲着。
指令和内存延迟 (Instruction & Memory Latency):访存很慢。GPU 通过大量 Warp 快速切换来掩盖延迟。如果 SM 上活跃 Warp 不够,延迟就藏不住。
本节只是简单的把整个框架理解了,接下来就是深入理解每一部分,深入理解硬件的特性